注:本文為 “Xilinx FPGA 中 PCIe 技術與 XDMA IP 核的應用” 相關文章合輯。
圖片清晰度受引文原圖所限。
略作重排,未整理去重。
如有內容異常,請看原文。
FPGA(基于 Xilinx)中 PCIe 介紹以及 IP 核 XDMA 的使用
Njustxiaobai 已于 2023-11-22 16:10:41 修改
一、PCIe 總線概述
1. PCIe 總線架構
PCIe 總線架構與以太網的 OSI 模型類似,是一種分層協議架構,分為事務層(Transaction Layer)、數據鏈路層(Data Link Layer)和物理層(Physical Layer)。每一層又分為兩部分:一部分處理出站(發送)信息,另一部分處理入站(接收)信息。

事務層
事務層的主要職責是事務層包(TLP)的組裝和拆卸。它接收來自 PCIe 設備核心層的數據,并將其封裝為 TLP,用于傳達事務(如讀取和寫入),并確定事件類型。事務層還負責管理 TLP 的基于信用的流控制。每個需要響應的數據包都作為拆分事務實現,每個數據包都有唯一標識符,使響應數據包能夠定向到正確的始發者。數據包格式支持不同形式的尋址,具體取決于事務類型(內存、I/O、配置和消息)。數據包還可能具有諸如 No Snoop、Relaxed Ordering 和基于 ID 的排序(IDO)等屬性。事務層支持四個地址空間:包括三個 PCI 地址空間(內存、I/O 和配置)以及消息空間。消息空間用于支持所有先前 PCI 的邊帶信號(如中斷、電源管理請求等),作為帶內消息事務。
數據鏈路層
數據鏈路層是事務層和物理層之間的中間階段,主要職責包括鏈路管理和數據完整性,涵蓋錯誤檢測與糾正。數據鏈路層的發送方接收事務層組裝的 TLP,計算并應用數據保護代碼和 TLP 序列號,然后將其提交給物理層以在鏈路上傳輸。接收方數據鏈路層負責檢查接收到的 TLP 的完整性,并將其提交給事務層進行進一步處理。在檢測到 TLP 錯誤時,該層負責請求重發 TLP,直到正確接收信息或確定鏈路失敗為止。數據鏈路層還生成并使用用于鏈路管理功能的數據包。為了區分這些數據包與事務層(TLP)使用的數據包,將數據鏈路層生成和使用的數據包稱為“數據鏈路層數據包(DLLP)”。
物理層
PCIe 總線的物理層為 PCIe 設備間的數據通信提供傳輸介質,為數據傳輸提供可靠的物理環境。它包括用于接口操作的所有電路,如驅動器、輸入緩沖器、并行至串行和串行至并行轉換器、PLL 和阻抗匹配電路。物理層還包含與接口初始化和維護相關的邏輯功能。物理層以特定格式與數據鏈路層交換信息,負責將從數據鏈路層接收的信息轉換為適當的序列化格式,并以與連接到鏈路另一端的設備兼容的頻率和通道寬度在 PCIe 鏈路上傳輸。
在 PCIe 總線的物理鏈路中,一個數據通路(Lane)包含兩組差分信號,共 4 根信號線。發送端的 TX 與接收端的 RX 使用一組差分信號連接,該鏈路也被稱為發送端的發送鏈路和接收端的接收鏈路;而發送端的 RX 與接收端的 TX 使用另一組差分信號連接,該鏈路也被稱為發送端的接收鏈路和接收端的發送鏈路。一個 PCIe 鏈路可以由多個 Lane 組成,目前支持的 Lane 數量包括 1、2、4、8、12、16 和 32,即 ×1、×2、×4、×8、×12、×16 和 ×32 寬度的 PCIe 鏈路。每個 Lane 上使用的總線頻率與 PCIe 總線版本相關。
2. PCIe 不同版本的性能指標及帶寬計算
PCIe indicators
| PCIe 版本 | 編碼方式 | 總線頻率 | 傳輸速率 | 單 Lane 的峰值帶寬 (x1) | 雙 Lane 的峰值帶寬 (x2) |
|---|---|---|---|---|---|
| 1.x | 8/10b 編碼 | 2.5GHz | 2.5GT/s | 250MB/s | 500MB/s |
| 2.x | 8/10b 編碼 | 5GHz | 5GT/s | 500MB/s | 1GB/s |
| 3.0 | 128/130b 編碼 | 8GHz | 8GT/s | 984.6MB/s | 1.969GB/s |
| 4.0 | 128/130b 編碼 | 16GHz | 16GT/s | 1.969GB/s | 3.938GB/s |
| 5.0 | 128/130b 編碼 | 32GHz | 32GT/s or 25GT/s | 3.9GB/s or 3.08GT/s | 7.8GB/s or 6.16GB/s |
- GT/s(Giga Transitions per second):表示每秒傳輸的次數,描述物理層通信協議的速率屬性,與鏈路寬度無關。
- Gbps(Giga bits per second):表示每秒傳輸的比特數。GT/s 與 Gbps 之間沒有固定比例關系,需根據線路編碼方式計算。
吞吐量 = 傳輸速率 × 線路編碼方案
例如,PCIe 2.0 協議的傳輸速率為 5.0 GT/s,每條 Lane 每秒傳輸 5G 個比特。其物理層協議采用 8b/10b 編碼方案,因此每條 Lane 的帶寬為 5 GT/s × 8/10 = 4 Gbps = 500 MB/s。對于一個 PCIe 2.0 x2 通道,其可用帶寬為 4 Gbps × 2 = 8 Gbps = 1 GB/s。
同理,PCIe 3.0 協議的傳輸速率為 8.0 GT/s,每條 Lane 每秒傳輸 8G 個比特。其物理層協議采用 128b/130b 編碼方案,因此每條 Lane 的帶寬為 8 GT/s × 128/130 = 7.877 Gbps = 984.6 MB/s。
3. PCIe 接口信號
電源與地信號
PCIe 設備使用兩種電源信號供電:Vcc 和 Vaux,其額定電壓均為 3.3V。Vcc 是主電源,為 PCIe 設備的主要邏輯模塊供電;Vaux 用于供電與電源管理相關的邏輯。在 PCIe 設備中,一些特殊寄存器(如 Sticky Register)使用 Vaux 供電,即使 Vcc 被移除,這些寄存器的內容和相關邏輯狀態也不會改變。使用 Vaux 的主要目的是降低功耗并縮短系統恢復時間,因為 Vaux 在多數情況下不會被移除,設備在 Vcc 恢復后可以快速恢復到正常工作狀態。
鏈路信號
PCIe 鏈路的最大寬度為 ×32,但在實際應用中,×32 鏈路寬度極少使用。在一個處理器系統中,通常提供 ×16 的 PCIe 插槽,使用 PETp015、PETn015 和 PERp015、PERn015 共 64 根信號線組成 32 對差分信號,其中 16 對 PETxx 信號用于發送鏈路,16 對 PERxx 信號用于接收鏈路。此外,PCIe 總線還使用以下輔助信號:
PERST# 信號(低電平有效)
該信號為全局復位信號,由處理器系統提供,用于復位 PCIe 插槽和 PCIe 設備的內部邏輯。當該信號有效時,PCIe 設備將進行復位操作。PCIe 總線定義了多種復位方式,其中 Cold Reset 和 Warm Reset 的實現與該信號有關。
REFCLK+ 和 REFCLK- 信號
PCIe 總線物理鏈路間的數據傳輸采用基于時鐘的同步傳輸機制。PCIe 總線的接收端包含時鐘恢復模塊(CDR),用于從接收報文中提取接收時鐘,從而實現同步數據傳輸。值得注意的是,PCIe 設備除了從報文中提取時鐘外,還使用 REFCLK+ 和 REFCLK- 信號作為本地參考時鐘。
在 PCIe 設備配置空間的 Link Control Register 中,包含一個“CommonClockConfiguration”位。當該位為 1 時,表示設備與 PCIe 鏈路對端設備使用“同相位”的參考時鐘;如果為 0,則表示使用的參考時鐘是異步的。在使用 PCIe 進行機箱間互聯時,異步時鐘無需連接時鐘線,降低了連接難度。
WAKE# 信號(休眠喚醒信號)
當 PCIe 設備進入休眠狀態且主電源已停止供電時,設備使用該信號向處理器系統提交喚醒請求,使處理器系統重新為該設備提供主電源 Vcc。在 PCIe 總線中,WAKE# 信號是可選的,因此使用該信號喚醒 PCIe 設備的機制也是可選的。需要注意的是,產生該信號的硬件邏輯必須使用輔助電源 Vaux 供電。
SMCLK 和 SMDAT 信號
SMCLK 和 SMDAT 信號與 x86 處理器的 SMBus(System Management Bus)相關。SMBus 由 Intel 于 1995 年提出,由 SMCLK 和 SMDAT 信號組成。SMBus 源于 I2C 總線,但與 I2C 總線存在一些差異。SMBus 的最高總線頻率為 100 kHz,而 I2C 總線可以支持 400 kHz 和 2 MHz 的總線頻率。此外,SMBus 上的從設備具有超時功能,當從設備發現主設備發出的時鐘信號保持低電平超過 35 ms 時,將引發從設備的超時復位。在正常情況下,SMBus 的主設備使用的總線頻率最低為 10 kHz,以避免從設備在正常使用過程中出現超時。在 SMBus 中,如果主設備需要復位從設備,可以使用這種超時機制。而 I2C 總線只能通過硬件信號實現復位操作,在 I2C 總線中,如果從設備出現錯誤,單純通過主設備無法復位從設備。
SMBus 還支持 Alert Response 機制。當從設備產生一個中斷時,并不會立即清除該中斷,直到主設備向 0b0001100 地址發出命令。
SMBus 和 I2C 總線的區別主要體現在物理層和鏈路層上,但 SMBus 還包含網絡層。SMBus 在網絡層定義了 11 種總線協議,用于實現報文傳遞。SMBus 在 x86 處理器系統中得到了廣泛應用,主要用于管理處理器系統的外部設備,并收集外設的運行信息,特別是與智能電源管理相關的信息。PCI 和 PCIe 插槽也為 SMBus 預留了接口,以便于 PCI/PCIe 設備與處理器系統進行交互。
JTAG 信號
JTAG(Joint Test Action Group)是一種國際標準測試協議,與 IEEE 1149.1 兼容,主要用于芯片內部測試。目前,絕大多數器件都支持 JTAG 測試標準。JTAG 信號由 TRST#、TCK、TDI、TDO 和 TMS 信號組成,其中 TRST# 為復位信號,TCK 為時鐘信號,TDI 和 TDO 分別對應數據輸入和數據輸出,TMS 信號用于模式選擇。
JTAG 允許多個器件通過 JTAG 接口串聯在一起,形成一個 JTAG 鏈。目前,FPGA 和 CPLD 可以通過 JTAG 接口實現在線編程(ISP,In-System Programming)功能。處理器也可以使用 JTAG 接口進行系統級調試工作,例如設置斷點、讀取內部寄存器和存儲器等操作。此外,JTAG 接口還可用于“逆向工程”,分析產品的實現細節。因此,在正式產品中,一般不保留 JTAG 接口。
二、XDMA
1. XDMA 與其他 PCIe IP 的區別
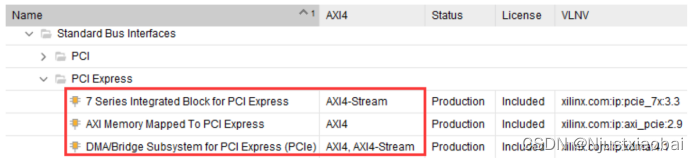
7 Series Integrated Block for PCI Express
7 Series Integrated Block for PCI Express 是最基礎的 PCIe IP,實現了 PCIe 的物理層、鏈路層和事務層,為用戶提供以 AXI4-stream 接口定義的 TLP 包。這是三種 IP 中資源占用最少且最靈活的,但開發難度最大。該 IP 將大部分開發工作留給用戶。如果用戶需要向主機發送數據,必須在邏輯端組好 MEM_WR 事務包并發送到 AXI4-stream 接口;同樣,如果需要從主機獲取數據,則必須發送 MEM_RD 事務包,并從 COMPLETE 事務包中提取數據。使用該 IP 核時,需要對 PCIe 協議有清晰的理解,尤其是對事務包 TLP 報文格式。
AXI Memory Mapped to PCI Express IP
該 IP 封裝了 7 Series Integrated Block for PCI Express IP,并提供了 AXI MM/S 橋。該橋不僅實現了 AXI4 to stream 的功能,還提供了事務層包 TLP 的組裝和拆卸、地址轉換、錯誤處理等功能。使用該 IP 時,用戶只需通過 AXI4 接口接收和發送 PCIe 數據,無需自行組裝和拆卸事務包。從邏輯資源消耗的角度來看,該 IP 居于三種 IP 之間,開發難度也居中。
DMA/Bridge Subsystem for PCI Express (PCIe)(XDMA)
該 IP 不僅完成了事務層的組包解包,還添加了完整的 DMA 引擎。XDMA 雖然簡單易用,但也存在局限性,主要表現在以下兩個方面:
- XDMA 適用于大批量數據傳輸場景,不適用于小數據場景。
- XDMA 僅用于 PCIe 的終端(endpoint)設備,不能用于 Root Port。其他兩種 IP 既可以用于終端設備,也可以用于 Root Port。
PCIe 的終端設備(如 PCIe 視頻采集卡、顯卡等)通常只有 PCIe 金手指,沒有 PCIe 插槽;而 Root Port 帶有 PCIe 插槽,可以插入 PCIe 終端設備。由于大多數 PCIe 應用開發針對的是 PCIe 終端設備,因此第二點局限性實際上影響較小。
2. XDMA 簡介
XDMA 通常使用 AXI4 接口,該接口可以連接到系統總線互聯,適用于大數據量異步傳輸,通常會使用到 BRAM 或 DDR 內存。AXI4-Stream 接口則適用于低延遲數據流傳輸。在配置頁面可以選擇 AXI4 或 AXI4-Stream 接口。
XDMA 不同接口的區別
- AXI-MM 接口:用于高性能、大帶寬的數據傳輸。
- AXI Lite Master 接口:是 AXI 接口的簡化版本,用于少量數據的通信,通常用于配置外設寄存器等輕量級數據傳輸場景。
DMA Bypass 是普通的 PCIe 傳輸。如果 DMA 的傳輸長度較短,其效率與 PCIe to AXI Lite 差不多;但如果傳輸長度較大,DMA 的性能通常更好。PCIe DMA Bypass 占用的是另一個 BAR,通常由主機直接發起操作,與 DMA 相比會消耗更多主機資源。如果這不是問題,則可以使用。
主機可以通過以下兩個接口直接訪問用戶邏輯:
- AXI4-Lite Master 配置接口:該端口是固定的 32 位端口,用于對用戶配置和狀態寄存器進行非關鍵性能訪問。
- AXI Memory Mapped Master CQ 旁路(Bypass)端口:該端口的寬度與 DMA 通道數據路徑相同,旨在用于點對點傳輸等應用程序中可能需要的對用戶內存的高帶寬訪問。
用戶邏輯可以通過 AXI4-Lite Slave 配置接口訪問 XDMA 內部配置和狀態寄存器。在此接口上發起的請求不會轉發到 PCI Express。
三、IP 核例化
參考文檔:XDMA 文檔 ~
BASIC 標簽頁
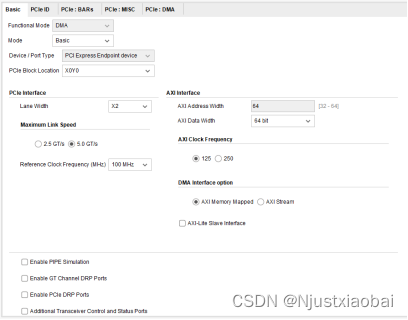
- Functional Mode:功能模式。對于 A7 系列 FPGA 芯片,僅支持 DMA 模式。
- Mode:配置模式,選擇 Basic 配置模式。
- Device/Port Type:設備/端口類型,僅支持 PCI Express Endpoint device。
- PCIe Block Location:FPGA 芯片中可選的 PCIe 塊位置,默認為 X0Y0。
PCIe 接口選項:
- Lane Width:鏈路寬度。對于 PCIe x2,選擇 x2。
- Max Link Speed:最大鏈路速度,對應 PCIe 版本的傳輸速率。對于 PCIe 2.*,為 5.0 GT/s。
- Reference Clock:參考時鐘頻率,選擇 100 MHz。
AXI 接口選項:
- AXI Address Width:AXI 地址寬度。目前,XDMA 僅支持 64 位寬度。
- AXI Data Width:AXI 數據寬度。
- AXI Clock Frequency:AXI 時鐘頻率。
- DMA Interface Option:DMA 接口選項,可選擇 AXI4 和 AXIS。
- AXI4-Lite Slave Interface:選擇是否啟用 AXI4-Lite Slave 接口以訪問 DMA 狀態寄存器。
PCIe ID 標簽頁
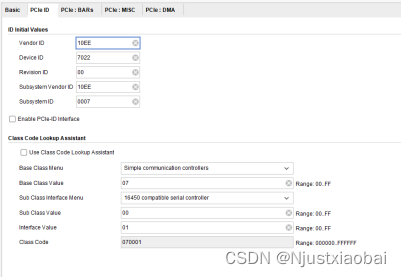
ID Initial Values:
-
Vendor ID(供應商 ID):用于識別器件或應用的制造商。有效標識由 PCI Special Interest Group 指定,以確保每個標識唯一。默認值 10EEh 為 Xilinx 的供應商標識。
-
Device ID(器件 ID):對應于應用的唯一標識。默認值為 70h,該值取決于所選配置。該字段可采用任何值,需根據應用進行更改。默認器件 ID 參數取決于以下因素:
- 器件系列:9 表示 UltraScale+,8 表示 UltraScale,7 表示 7 系列器件。
- EP 或 RP 模式。
- 鏈路寬度:1 表示 x1,2 表示 x2,4 表示 x4,8 表示 x8,F 表示 x16。
- 鏈路速度:1 表示 Gen1,2 表示 Gen2,3 表示 Gen3,4 表示 Gen4。
-
如果上述任意值發生更改,則將重新計算“器件 ID”值,以替換先前設置的值。
-
Revision ID(版本 ID):表示器件或應用的版本,作為器件 ID 的擴展。默認值為 00h,需根據應用輸入相應值。
-
Subsystem Vendor ID(子系統供應商 ID):進一步限定器件或應用的制造商。在此處輸入子系統供應商 ID,默認值為 10EEh。通常,該值與供應商 ID 相同。將該值設為 0000h 可能導致合規性測試出現問題。
-
Subsystem ID(子系統 ID):進一步限定器件或應用的制造商。該值通常與器件 ID 相同,默認值取決于所選通道寬度和鏈路速度。將該值設為 0000h 可能導致合規性測試出現問題。
-
Enable PCIe-ID Interface:啟用 PCIe-ID 接口。如果選中該參數,則根據選中的 PFx 數量,在 IP 頂層邊界處會顯示 PCIe ID 端口:
cfg_vend_id、cfg_subsys_vend_id、cfg_dev_id_pf*、cfg_rev_id_pf*和cfg_subsys_id_pf*,并可供用戶邏輯驅動。如果未選中該參數,則不會在頂層顯示這些端口,并根據自定義時設置的值來驅動這些端口。
Class Code Lookup Assistant:
- Class Code Look-up Assistant(類代碼查找助手):類代碼查找助手可針對選定的器件常規功能提供對應的基本類、子類和接口值。
- Class Code(類代碼):類代碼用于識別器件的常規功能,分為以下 3 個字節大小的字段:
- Base Class(基本類):用于廣泛識別器件執行的功能類型。
- Sub-Class(子類):進一步具體識別器件功能。
- Interface(接口):用于定義特定寄存器級別編程接口(如果有),允許不從屬于器件的軟件與器件進行連接。
PCIe:BARs 標簽頁
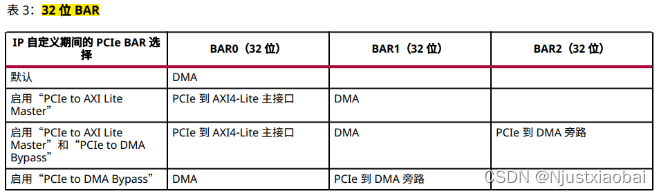
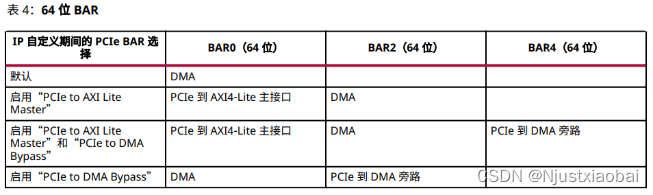
該標簽頁主要用于配置 BAR。BAR 是 Base Address Register 的縮寫,即 基址寄存器。通過將讀取或寫入請求映射到基址寄存器(BAR),可以從主機訪問 XDMA 內部的配置和狀態寄存器以及用戶邏輯中的配置和狀態寄存器。XDMA 根據 BAR 命中,將請求路由到適當的位置。例如,對于 PCIe to AXI-Lite Master (BAR0) 地址映射,命中 PCIe 到 AXI4-Lite Master 的事務將路由到 AXI4-Lite 內存映射用戶接口。該接口支持 32 位地址空間和 32 位讀取和寫入請求。PCIe to AXI-Lite Master (BAR0) 地址映射可由用戶邏輯定義。
BAR 分為兩種大小:
- 32 位 BAR:地址空間最小可達 128 字節,最大可達 2 GB(千兆字節)。用于內存或 I/O。
- 64 位 BAR:地址空間最小可達 128 字節,最大可達 8 EB(艾字節)。僅用于內存。
BAR 也可分為兩種類型(Type)——I/O 和內存:
- I/O:I/O BAR 只能采用 32 位;“可預取(Prefetchable)”選項不適用于 I/O BAR。僅限針對傳統 PCI Express 端點才能啟用 I/O BAR。
- 內存(Memory):內存 BAR 可采用 64 位或 32 位,并且可預取。
與 BAR 寄存器相關的選項含義:
- Size(大小):可用大小范圍取決于所選 PCIe 器件/端口類型和 BAR 類型。
- Value(值):基于當前選擇分配給 BAR 的值。
- 64bit Enable:是否使用 64 位 BAR。
- Prefetchable(可預取):識別內存空間預取功能。
每個 BAR 空間可以單獨選擇 64bit Enable 選項。每個 64 位 BAR 空間都可以選擇是否預取。
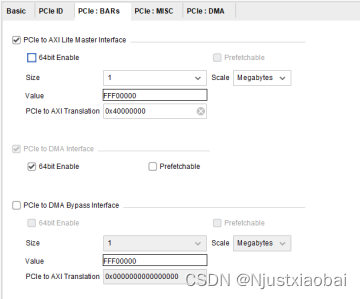
- PCIe to AXI Lite Master Interface:選擇是否啟用 AXI-Lite Master Interface 接口。該接口相當于顯卡的用戶接口,主機側可以通過該接口控制顯卡的風扇轉速、LED 開關和顯示效果等功能。因此,如果需要使用 PCIe 接口控制 FPGA 側的用戶邏輯(如控制 LED 燈等),則需要啟用該接口。
- Size 和 Value:定義用戶側空間的大小,與 AXI-Lite Master Interface 對接的 AXI4-Lite 總線設備的空間大小有關,可以根據實際需要自定義大小。Size 大小決定了主機能夠訪問的地址空間的大小。
- PCIe to AXI Translation:PCIe 到 AXI 的轉換。主機一側 BAR 地址為 0,用戶邏輯側 AXI Lite 的地址為 0x40000000,則主機訪問 AXI Lite 用戶邏輯時,XDMA 將根據該設置將主機側 BAR 地址 0 轉換到 AXI Lite 總線地址 0x40000000。對該值的設置有兩種方式:一種是手動指定,然后修改后面 AXI Lite 總線的偏移地址;另一種是先確定 AXI Lite 總線的偏移地址,然后根據偏移地址設置該值。例如,修改地址映射 AXI Lite 總線的偏移地址為 0x40000000,因此設置此值為 0x40000000。
- 此外,PCIe to AXI Translation 也是 AXI Lite 總線的基地址。當 AXI Lite 總線連接多個 AXI IP 核時,會有多個偏移地址。上位機訪問其他 IP 核時的偏移地址是以 PCIe to AXI Translation 的值為基址 0 進行參考的。例如,AXI Lite 總線連接的另一個 AXI IP 的偏移地址為 0x40010000,上位機訪問該 IP 核的偏移地址就是該 IP 核的偏移地址 0x40010000 - PCIe to AXI Translation 的值 0x40000000 = 0x10000。因此,當 AXI Lite 總線連接多個 AXI IP 核時,需確保 PCIe to AXI Translation 的值小于等于這些 AXI IP 核偏移地址的最小值。
- PCIe to DMA Interface:PCIe 至 DMA 接口,默認一直開啟,支持 prefetchable 和 nonprefetchable(可預取和不可預取)。
- PCIe to DMA Bypass Interface:選擇是否啟用 PCIe 至 DMA 旁路接口。DMA Bypass 是普通的 PCIe 傳輸,不使用 DMA 邏輯,而是直接通過 PCIe 進行通信,其傳輸效率通常高于 PCIe to AXI Lite。
關于 Prefetchable:傳統上,可預取性意味著預先將內存取出到一個小緩沖區中,以便讀取操作變得更快。例如,如果有兩個 PCIe 總線通過網橋連接,當主總線中的主機必須訪問次級總線中的內存時,網橋將從內存中獲取數據并將其存儲在網橋緩沖區中。然后主機可以定期訪問該緩沖區,從而提高讀取速度。然而,內存必須是可預取的。如果內存是不可預取的,一旦數據被加載到橋接器的緩沖區,數據將從內存中丟失。如果主機不能從網橋收集數據,那么數據就永遠丟失了。如果內存是可預取的,則不存在數據丟失的風險。
PCIe:MISC 標簽頁
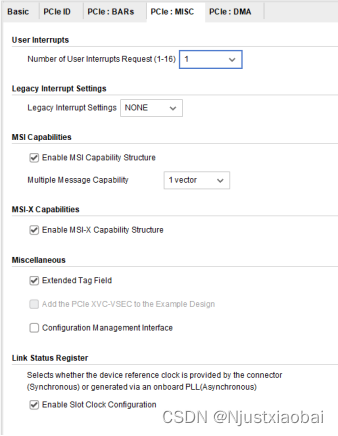
- Number of User Interrupt Requests:用戶中斷請求數,最多可以選擇 16 個用戶中斷請求。
- Legacy Interrupt Settings:可以選擇傳統中斷之一:INTA、INTB、INTC 或 INTD。
- MSI Capabilities:默認情況下,啟用 MSI 功能,并且啟用 1 個向量,最多可以選擇 32 個向量。通常,Linux 僅將 1 個向量用于 MSI,可以禁用此選項。
- MSI-X Capabilities:使能 MSI-X 功能。
- Finite Completion Credits(高級配置模式下有):在支持有限完成信用的系統上,可以啟用此選項以獲得更好的性能。
- Extended Tag Field:擴展標簽字段,默認情況下,使用 6 位完成標簽。對于 UltraScale 和 Virtex-7 器件,擴展標簽選項提供 64 個標簽。對于 UltraScale+ 器件,擴展標簽選項提供 256 個標簽。如果未選擇擴展標簽選項,則 DMA 將 32 個標簽用于所有設備。
- Configuration Management Interface:是否使用 PCIe 配置管理接口。
關于 MSI-X 中斷:用戶可以嘗試使用 MSI-X 中斷,而不是 MSI 或傳統中斷。使用 MSI-X 中斷時,數據速率優于使用 MSI 或基于傳統中斷的設計。
PCIe:DMA 標簽頁
- Number of Read Channels:主機到 PCIe 卡(H2C)的 DMA 讀通道數。對于 7 系列 Gen2 IP,最多兩個通道(通道數越多,同等情況下傳輸速率越快)。
- Number of Write Channels:PCIe 卡到主機(C2H)的 DMA 寫通道數。對于 7 系列 Gen2 IP,最多兩個通道(通道數越多,同等情況下傳輸速率越快)。
- Number of Request IDs for Read channel:讀通道的請求 ID 數,即每個通道的最大未完成請求數,可選范圍為 2 到 64。
- Number of Request IDs for Write channel:寫通道的請求 ID 數,即每個通道的最大未完成請求數,可選范圍為 2 到 32。
- Descriptor Bypass for Read (H2C):讀描述符旁路,適用于所有選定的讀通道。每個二進制數字對應一個通道,LSB 對應于通道 0。值為 1 的位表示相應的通道啟用了描述符旁路。
- Descriptor Bypass for Write (C2H):寫描述符旁路,適用于所有選定的寫通道。每個二進制數字對應一個通道,LSB 對應于通道 0。值為 1 的位表示相應的通道啟用了描述符旁路。
- AXI ID Width:默認值為 4 位寬,也可以選擇 2 位寬。
- DMA Status port:DMA 狀態端口可用于所有通道。
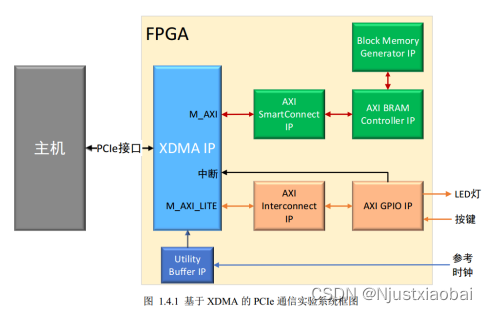
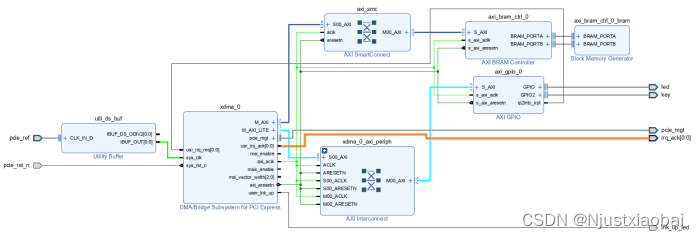
基于 XDMA 的 PCIe 子系統
用戶邏輯通過 AXI4 接口與 XDMA 進行交互。AXI4 Master 接口用于連接顯存,AXI Lite Master 接口用于控制 LED 燈和按鍵 KEY,按鍵用于中斷。
GPIO 的寄存器地址
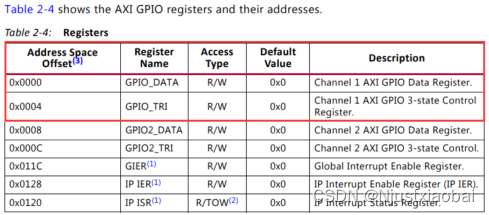
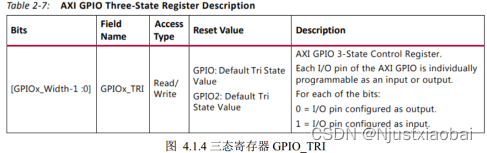
- GPIO_DATA:配置各個接口的值。
- GPIO_TRI:用于動態配置 GPIO 的狀態是輸入還是輸出。“0” 表示配置對應的 GPIO 為輸出。
參考手冊:AXI GPIO IP 核手冊。
中斷 usr_irq_req
當使能 AXI GPIO IP 的中斷寄存器后(在上位機中設置),按下按鍵 KEY 時,AXI GPIO IP 核的中斷輸出引腳 ip2intc_irpt 會輸出高電平,從而產生中斷。
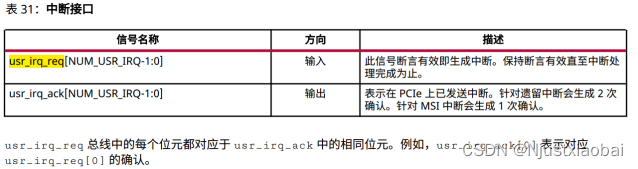
usr_irq_ack 信號的高電平時間很短,僅為納秒級,因此無法通過蜂鳴器判斷是否響應。usr_irq_ack 信號的典型用途是:當用戶設計的中斷源產生中斷時,可以通過 usr_irq_ack 信號的電平狀態來決定何時拉低 usr_irq_req 信號。
PCIe 支持三種中斷類型:
- Legacy 中斷:主要用于兼容傳統 PCI,現在很少使用,不推薦使用。Legacy 中斷設置可以選擇 INTA、INTB、INTC 或 INTD;通常選擇 None,即不使用 Legacy 中斷。
- MSI(Message Signaled Interrupt)中斷:基于消息的中斷機制,最多支持 32 個中斷請求,且要求中斷向量連續。
- MSI-X 中斷:是 MSI 的擴展,可以支持更多的中斷請求,且不要求中斷向量連續。對于 XDMA,MSI 和 MSI-X 最多支持 16 個可用的用戶中斷向量。
推薦使用 MSI-X 中斷,其數據速率優于 MSI 或傳統中斷的設計。MSI-X 中斷優先級高于 MSI 中斷,MSI 中斷優先級高于 Legacy 中斷。如果同時啟用了 Legacy 中斷、MSI 和 MSI-X 中斷,XDMA 只會產生 MSI-X 中斷。
關于 AXI GPIO IP 核的寄存器空間,可參考手冊 AXI GPIO IP 核手冊。
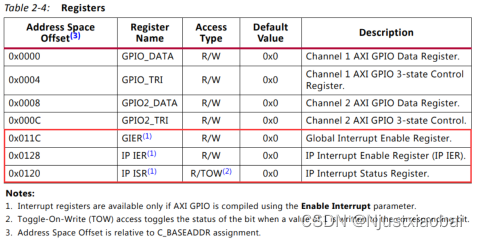
- GIER:全局中斷使能寄存器,控制 AXI GPIO IP 的總中斷開關,偏移地址為 0x11C。
- IPIER(IP Interrupt Enable):IP 中斷使能寄存器,用于控制每個通道的中斷使能與否,偏移地址為 0x128。
上位機可以通過讀取 IPISR 的值,判斷中斷來源于哪個通道。
Xilinx DMA 的幾種方式與架構
posted @ 2022-06-17 16:09 Hello-FPGA
DMA 是 Direct Memory Access 的縮寫。在 FPGA 系統中,常見的幾種 DMA 需求如下:
- 在 PL 內部無 PS(CPU 這里統一稱為 PS)持續干預搬移數據,常見的接口形態為 AXI Stream 與 AXI,以及 AXI 與 AXI。
- 從 PL 與 PS 之間搬移數據。對于 ZYNQ,這屬于單個芯片內部接口;對于 PCIe 等其他接口,則稍微復雜一些,屬于多個芯片之間的接口。
探索 DMA 方式的目的如下:
- 了解芯片內部數據搬移的方法,包括 DMA 的常用接口及實現方式。
- 了解芯片之間的數據搬移方法,包括 DMA 的常用接口及實現方式。
通過這些了解,可以建立一個系統數據搬移的框架結構。當出現類似需求時,實際上只需要調用已有的模塊去實現。
本文從 Xilinx 的各個 DMA IP 著手介紹,主要從接口的角度進行分析。
1 AXI4 TO AXI4
1.1 AXI Central DMA Controller
The AXI CDMA provides high - bandwidth Direct Memory Access (DMA) between a memory - mapped source address and a memory - mapped destination address using the AXI4 protocol. An optional Scatter Gather (SG) feature can be used to offload control and sequencing tasks from the system CPU. Initialization, status, and control registers are accessed through an AXI4 - Lite slave interface, suitable for the Xilinx MicroBlaze? processor.
“CDMA”這一名稱的由來是:它主要用于處理 CPU 掛載的 AXI 接口內存內部的數據傳輸,典型的場景是 MicroBlaze。為什么不提 ZYNQ 呢?ZYNQ 的 AXI 內部是直接掛載在 CPU 內部的,不需要一個 DMA 去控制。如果需要,直接通過軟件進行拷貝,拷貝的動作就會內部發起一次 AXI DMA 操作。但如果 ZYNQ 想要使用 PL 側的 DDR,那么就需要用 CDMA 來操作,因為 ZYNQ 沒有 AXI Master 接口,只有 SLAVE(這里說的是高性能 HP 接口,不是 GP 低速接口)。
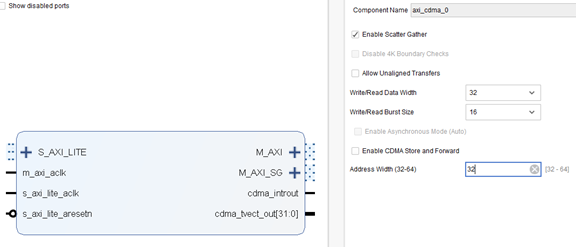
圖 1?1 AXI CDMA 接口與參數選項,其中 S_AXI_LITE 連接到主控 CPU,M_AXI 連接到存儲器,M_AXI_SG 連接到存儲器(用于存儲 SG DMA 模式下的 dma descriptor)
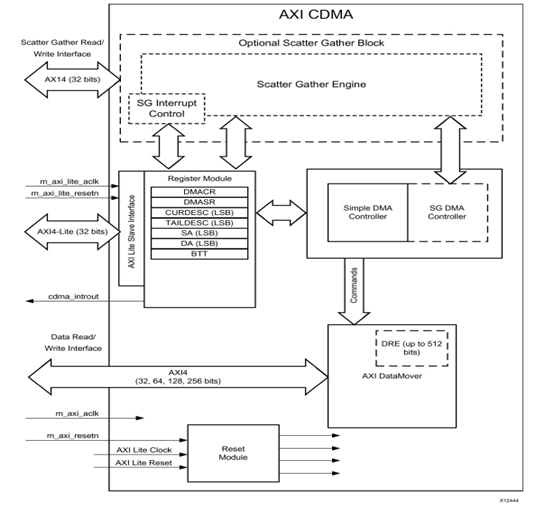
圖 1?2 CMDA 內部結構框圖
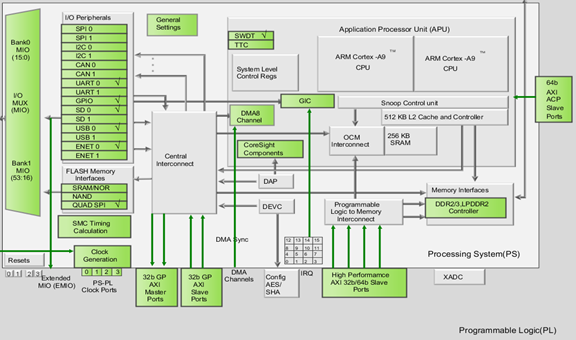
圖 1?3 ZYNQ 框圖,只有高性能的 AXI SLAVE,沒有 MASTER
我們來看一下內部寄存器,這實際上更加直觀,它告訴用戶使用該模塊的配置方法。從配置方法可以簡單估計使用該模塊的復雜程度。從寄存器定義來看,控制、狀態檢測、SG DMA 的 descriptor 指針、簡單 DMA 的起始地址、目標地址、長度等,使用起來并不復雜。那么對應的軟件代碼建議直接拷貝 Xilinx 的 ZYNQ 側 driver 代碼,然后稍作修改即可使用。
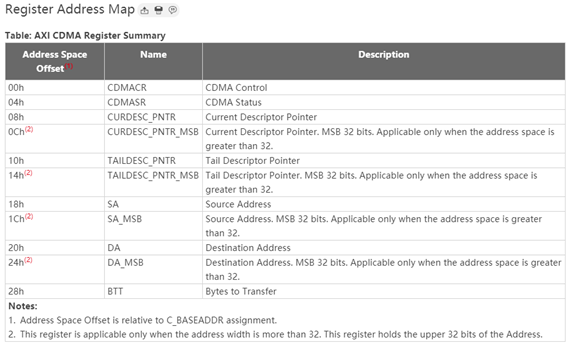
最后再來看一下資源占用情況。資源占用與位寬成正比。典型的在 64 bit 數據位寬下,占用大約 1500 個 LUT、2500 個 FF。從我的角度來看,這個資源相當不錯。
圖 1?4 資源占用

圖 1?5 傳輸效率、帶寬
2 AXI Stream to AXI4
2.1 AXI DataMover
The AXI Datamover is a key Interconnect Infrastructure IP which enables high - throughput transfer of data between AXI4 memory - mapped domain to AXI4 - Stream domain. The AXI Datamover provides MM2S and S2MM AXI4 - Stream channels which operate independently in a full - duplex - like manner. The AXI Datamover is a key building block for the AXI DMA core and enables 4 kbyte address boundary protection, automatic burst partitioning, as well as providing the ability to queue multiple transfer requests using nearly the full bandwidth capabilities of the AXI4 - Stream protocol. Furthermore, the AXI Datamover provides byte - level data realignment allowing memory reads and writes to any byte offset location.
AXI Datamover 是一個重要的基礎 IP,Xilinx 所有的 DMA IP 基本都包含這個模塊。該模塊可以將 AXI Stream 與 AXI 格式的數據進行轉換。類似 XDMA、VDMA、AXI DMA、AXI MCDMA 等幾乎所有 DMA IP 均包含該模塊。如果 Xilinx 的這些已有 DMA 不能滿足需求,那么用戶就可以自行設計一個 DMA 控制器完成 DMA 操作。
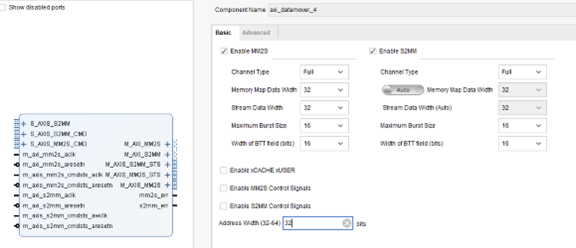
圖 2?1 AXI Datamover 接口與配置項
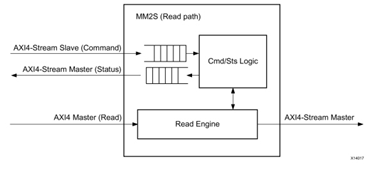
圖 2?2 MM2S 讀數據通道,讀取 AXI4 接口數據,轉換成 AXI Stream 數據輸出
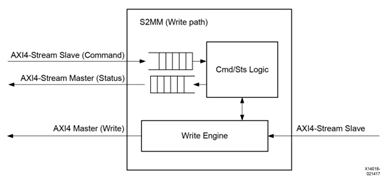
圖 2?3 S2MM 寫數據通道,AXI Stream 數據輸入,轉換成 AXI4 數據寫到 AXI4 接口存儲器
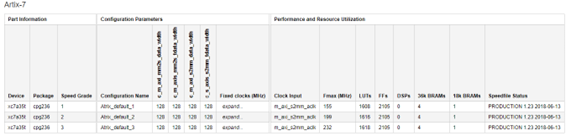
圖 2?4 資源占用
2.2 AXI DMA Controller
The AXI Direct Memory Access (AXI DMA) IP provides high - bandwidth direct memory access between memory and AXI4 - Stream - type target peripherals. Its optional scatter gather capabilities also offload data movement tasks from the Central Processing Unit (CPU) in processor - based systems. Initialization, status, and management registers are accessed through an AXI4 - Lite slave interface.
簡而言之,AXI DMA Controller 為 AXI Stream 和 AXI4 接口的轉換(數據存儲)提供了一個可由軟件控制(通過 AXI Lite 接口實現)的簡單方式。
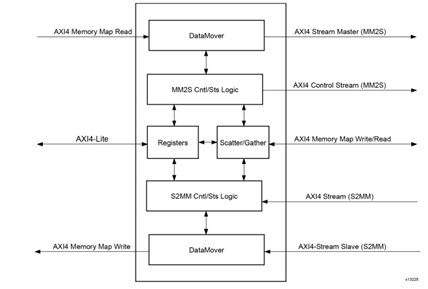
圖 2?5 AXI DMA 內部框圖
這里需要說明一下:如果選擇不使能 SG DMA 模式,而是單純的寄存器控制模式,對于 AXI DMA 這個 IP 來說,資源占用會減少,性能會降低(Xilinx 其他的 DMA IP 也是類似的)。為什么性能會降低呢?這是因為寄存器模式不支持預先設定傳輸指令,只能等一次傳輸結束后開啟下一次傳輸,這就降低了帶寬,增加了 CPU 的干預。不過這種模式也最為簡單,還是要看設計中的傳輸要求。
我們來看一下寄存器表格。表格列出了 SG DMA 和寄存器 DMA 兩種方式下的寄存器。從表中可以看出,要實際使用 AXI DMA 并不復雜。不過我還是建議直接參考 Xilinx SDK 的驅動代碼,裸機驅動、example 即可,簡單直接、易用。
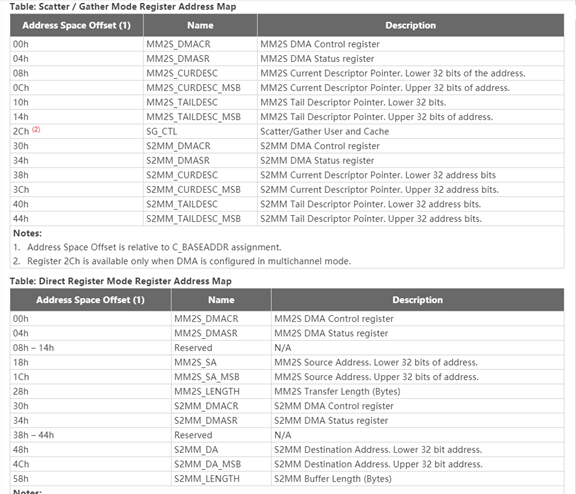
圖 2?6 表中給出了 SG 模式和寄存器模式下的相關寄存器及其含義
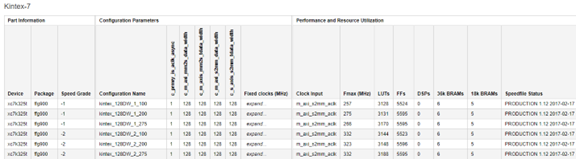
圖 2?7 資源占用上來看,還是不少的
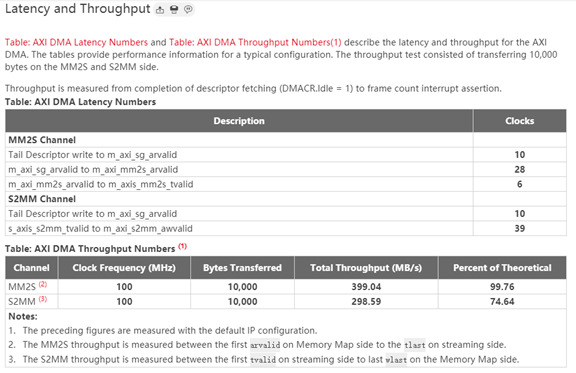
圖 2?8 延遲、性能、帶寬數據,帶寬數據還不錯,一般來說能做到 80% 是很好的,讀比寫快,因此 MM2S 的帶寬接近 100%,S2MM 只有 75%
2.3 AXI Multichannel DMA
簡單來說,AXI MCDMA 是 AXI DMA 的多通道版本,是為了應對多通道、低速的數據傳輸。AXI MCDMA 最多支持雙向各 16 通道,且各個通道間相互獨立,允許單獨配置,這給很多低速、多功能的應用提供了一個小面積 FPGA 的解決方案。
由于 AXI MCDMA 是 AXI DMA 的多通道版本,因此不做過多介紹。
The AXI MCDMA facilitates large data migration, offloading the task from the embedded processor. It sits as an intermediary between an AXI Memory - Mapped embedded subsystem and an AXI Streaming subsystem. The MCDMA IP is full - duplex, scatter - gather, and supports up to 16 channels. It may be configured as weighted round - robin or strict priority.
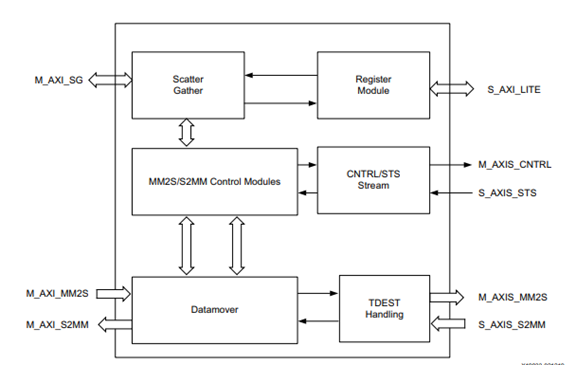
圖 2?9 AXI MCDMA 結構框圖
2.4 AXI Video DMA
The AXI Video Direct Memory Access (AXI VDMA) core is a soft Xilinx IP core that provides high - bandwidth direct memory access between memory and AXI4 - Stream - type video target peripherals. The core provides efficient two - dimensional DMA operations with independent asynchronous read and write channel operation. Initialization, status, interrupt, and management registers are accessed through an AXI4 - Lite slave interface.
為什么有了 AXI DMA 還要有 AXI VDMA 呢?從下面這段話可以看出原因:Xilinx 的視頻處理多用 AXI Stream 格式,而實際應用中很多需要改變幀速率、緩存幀的需求。直接使用 AXI DMA 也不是不可以,只是不能很好地與其他 AXI Stream 接口的 Video IP 匹配,因此專門開發了 AXI VDMA。主要是為了緩存圖像幀。有朋友可能會問,不能用 BRAM 緩存嗎?不能,因為圖像對應的每一幀可能很大,用 BRAM 資源不夠。
AXI VDMA 的使用方式與其他 DMA IP 大同小異,這里不做更多介紹,需要使用的可以直接查看官方手冊。
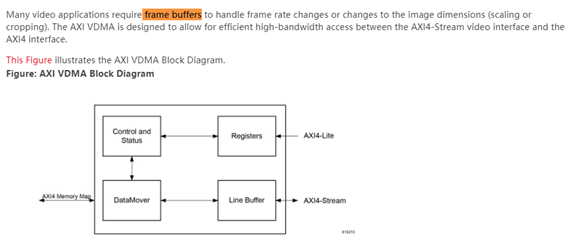
3 PCIe DMA
Xilinx 為 PCIe 接口推出了 AXI DMA 接口,對應為 Xilinx DMA for PCIe。同理,類似 USB、SRIO 等其他接口,用戶也可以設計出類似的 DMA 解決方案,構建高可靠、靈活的系統內部架構。
The Xilinx? LogiCORE? DMA for PCI Express? (PCIe) implements a high - performance, configurable Scatter Gather DMA for use with the PCI Express Integrated Block. The IP provides an optional AXI4 - MM or AXI4 - Stream user interface.
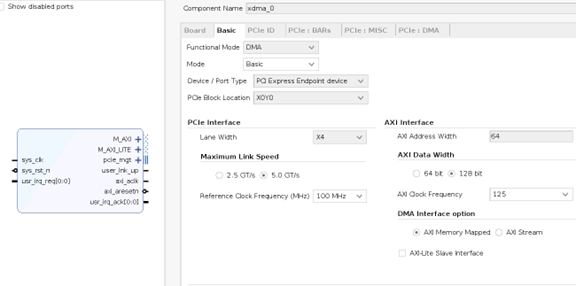
圖 3?1 XDMA 接口與參數配置項
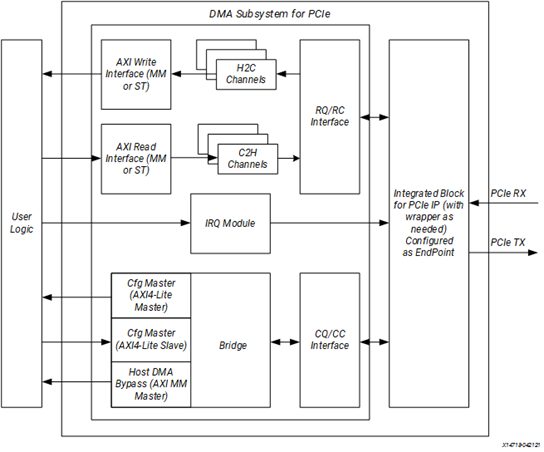
圖 3?2 XDMA 內部框圖
那么 XDMA 可以做什么事情呢?它有很多用途。有了這個模塊,你的 PCIe Endpoint 設備就可以構建在 AXI 總線的基礎之上,從而擁有一個靈活、可靠、高性能的片上系統架構。
4 啟發
用戶可以根據 Xilinx DMA 的框圖架構,在 AXI、AXI Stream 接口的互聯下,構建靈活可靠的 FPGA 系統。如果這些 IP 無法滿足要求,還可以模仿 PCIe XDMA 等 IP 的架構方式,搭建屬于自己的片上系統架構。
關于 DMA 環通實驗的 SDK 部分代碼理解
懶羊羊的奶油蛋糕于 2024-04-11 10:22:29 發布
一、定義部分
#include "xaxidma.h"
#include "xparameters.h"
#include "xil_printf.h"
#include "xscugic.h"#define DMA_DEV_ID XPAR_AXIDMA_0_DEVICE_ID
#define INT_DEVICE_ID XPAR_SCUGIC_SINGLE_DEVICE_ID
#define INTR_ID XPAR_FABRIC_AXI_DMA_0_S2MM_INTROUT_INTR // 中斷定義#define FIFO_DATABYTE 4 // 字節數
#define TEST_COUNT 80
#define MAX_PKT_LEN TEST_COUNT * FIFO_DATABYTE // 發送包長度#define TEST_START_VALUE 0xC // 開始值#define NUMBER_OF_TRANSFERS 2 // 傳輸次數/** Function declaration // 數據檢測函數*/
int XAxiDma_Setup(u16 DeviceId);
static int CheckData(void);
int SetInterruptInit(XScuGic *InstancePtr, u16 IntrID, XAxiDma *XAxiDmaPtr);XScuGic INST;
XAxiDma AxiDma;u8 TxBufferPtr[MAX_PKT_LEN]; // 發送
u8 RxBufferPtr[MAX_PKT_LEN]; // 接收
二、建立中斷代碼部分
思路:初始化,配置 ID 和地址 → 中斷處理函數:將 ID 和中斷處理函數連接 → 啟動中斷 → 中斷異常:初始化異常 → 處理異常函數 → 返回成功。
代碼解釋:
int SetInterruptInit(XScuGic *InstancePtr, u16 IntrID, XAxiDma *XAxiDmaPtr)
{XScuGic_Config *Config; // XAxiDma_Config 是一個 AXI_DMA 配置的信息結構體,它里面包含需要配置的各種信息,傳遞給 API 函數int Status;Config = XScuGic_LookupConfig(INT_DEVICE_ID); // 初始化,XScuGic_Config 其中的中斷函數Status = XScuGic_CfgInitialize(&INST, Config, Config->CpuBaseAddress); // 初始化,配置(cfg)地址,scugic:系統級中斷控制器if (Status != XST_SUCCESS)return XST_FAILURE;Status = XScuGic_Connect(InstancePtr, IntrID,(Xil_ExceptionHandler)CheckData,XAxiDmaPtr); // 中斷設置中斷處理函數:將中斷 ID 和中斷處理函數連接起來,當中斷被識別后執行相應的處理函數if (Status != XST_SUCCESS) {return Status;}XScuGic_Enable(InstancePtr, IntrID); // 啟動中斷Xil_ExceptionInit(); // 通用 API,用于 ARM 處理器中初始化異常處理程序Xil_ExceptionRegisterHandler(XIL_EXCEPTION_ID_INT,(Xil_ExceptionHandler)XScuGic_InterruptHandler,InstancePtr); // 為異常情況注冊一個處理器,當處理器遇到指定異常時,調用此處理程序。XIL_EXCEPTION_ID_INT 是 Xilinx 處理器定義的Xil_ExceptionEnable(); // 使能中斷(用于控制處理器是否響應中斷)異常return XST_SUCCESS;
}
三、DMA 部分(重要)
思路:初始化 DMA → 確認 SG/Simple 模式 → 建立中斷系統 → 啟動 S2MM 中斷 → 賦值 → Cache 刷新 → 開始傳輸接收。
代碼:
int XAxiDma_Setup(u16 DeviceId)
{XAxiDma_Config *CfgPtr;int Status;int Tries = NUMBER_OF_TRANSFERS;int Index;u8 Value;/* Initialize the XAxiDma device. */// 初始化 DMA 設備 cfg 配置文件 ptr 指針記錄CfgPtr = XAxiDma_LookupConfig(DeviceId); // 將 DMA 設備 ID 賦值給 XAxiDma_Config 結構體if (!CfgPtr) {xil_printf("No config found for %d\r\n", DeviceId);return XST_FAILURE;}/* 初始化 DMA 引擎,將 DMA 設備 ID 賦值給 XAxiDma_Config 結構體* 根據 PL 端對 DMA core 的配置參數,PS 對 DMA 進行真正的配置初始化過程,* axidma 還存儲在 PS 端的 AXI — DMA 配置表,根據對 PL 參數的讀取,* PS 運行對 PL 側的 DMA 配置,這個配置過程是通過 GP0 接口對 AXI_Lite4 總線的控制完成的*/Status = XAxiDma_CfgInitialize(&AxiDma, CfgPtr);if (Status != XST_SUCCESS) {xil_printf("Initialization failed %d\r\n", Status);return XST_FAILURE;}/* SG/Simple mode?,如果是 SG,則配置失敗。* 配置的是使用 PL 側 DMA 的直接寄存器訪問模式,所以數據傳遞也是通過該方式運行的,* 為了以防萬一,在這里運行一下 SG 查詢函數看看是不是配置成了 SG 模式*/if (XAxiDma_HasSg(&AxiDma)) {xil_printf("Device configured as SG mode \r\n");return XST_FAILURE;}// 建立中斷系統Status = SetInterruptInit(&INST, INTR_ID, &AxiDma);if (Status != XST_SUCCESS)return XST_FAILURE;/* 使能 DMA 中斷,啟動 S2MM 中斷 */XAxiDma_IntrEnable(&AxiDma, XAXIDMA_IRQ_IOC_MASK, XAXIDMA_DEVICE_TO_DMA);XAxiDma_IntrDisable(&AxiDma, XAXIDMA_IRQ_ALL_MASK, XAXIDMA_DMA_TO_DEVICE);// 對寫入數據進行賦值Value = TEST_START_VALUE;for (Index = 0; Index < MAX_PKT_LEN; Index++) {TxBufferPtr[Index] = Value;Value = (Value + 1) & 0xFF;}/* 在 DMA 傳輸前刷新 SrcBuffer,以防數據緩存。* 將要寫入 fifo 的數據刷入 Cache*/Xil_DCacheFlushRange((UINTPTR)TxBufferPtr, MAX_PKT_LEN); // 刷新 Data CacheXil_DCacheFlushRange((UINTPTR)RxBufferPtr, MAX_PKT_LEN); // 刷新到 ddr,Cache 關聯地址的數據寫入到 DDR 中,并把 Cache 里的數據清空,將 CACHE 數據更新到 MEMORYfor (Index = 0; Index < Tries; Index++) {// 開始傳輸Status = XAxiDma_SimpleTransfer(&AxiDma, (UINTPTR)TxBufferPtr,MAX_PKT_LEN, XAXIDMA_DMA_TO_DEVICE);if (Status != XST_SUCCESS) {return XST_FAILURE;}// 開始接收Status = XAxiDma_SimpleTransfer(&AxiDma, (UINTPTR)RxBufferPtr,MAX_PKT_LEN, XAXIDMA_DEVICE_TO_DMA);if (Status != XST_SUCCESS) {return XST_FAILURE;}while ((XAxiDma_Busy(&AxiDma, XAXIDMA_DEVICE_TO_DMA)) ||(XAxiDma_Busy(&AxiDma, XAXIDMA_DMA_TO_DEVICE))) {/* Wait */}}/* Test finishes successfully */return XST_SUCCESS;
}
四、數據檢測
思路:請求待處理的中斷 → 刷新 Cache → 檢查數據緩沖區 → 數據驗證
XDMA 傳輸模式
浩瀚之水_csdn 于 2025-03-17 14:45:18 發布
XDMA 傳輸模式 是 Xilinx(AMD)FPGA 通過 PCIe 與主機(CPU)之間進行數據傳輸的核心機制,其性能和應用場景因模式不同而有所差異。
以下是 XDMA 支持的 主要傳輸模式、配置方法及適用場景的詳細解析:
1. XDMA 傳輸模式分類
XDMA 支持以下三種主要傳輸模式:
| 傳輸模式 | 特點 | 適用場景 |
|---|---|---|
| 塊傳輸模式(Block DMA) | 基于 AXI4 Memory-Mapped(AXI-MM) 接口,傳輸連續大塊數據。 | 大文件傳輸、圖像幀處理、批量計算 |
| 流傳輸模式(Streaming DMA) | 基于 AXI4-Stream(AXI-S) 接口,實時流式傳輸,無固定地址。 | 傳感器數據流、視頻流、網絡包處理 |
| Scatter-Gather(SG)模式 | 支持 非連續內存傳輸,通過描述符鏈表管理多塊數據。 | 分散數據聚合、數據庫操作 |
2. 塊傳輸模式(Block DMA)
2.1 工作原理
- AXI-MM 接口:通過 FPGA 的 DDR 或 BRAM 緩存數據,主機與 FPGA 通過物理地址直接讀寫。
- 單次傳輸:每個 DMA 請求傳輸一塊連續的物理內存數據。
- 方向控制:
- 主機到 FPGA(H2C):主機寫入 FPGA 內存。
- FPGA 到主機(C2H):FPGA 讀取主機內存。
2.2 配置步驟(Vivado)
- 在 XDMA IP 核配置中啟用 AXI-MM 接口。
- 設置 AXI-MM 數據位寬(通常 512-bit 以匹配 PCIe 帶寬)。
- 定義 BAR(Base Address Register)空間,供主機映射 FPGA 內存。
2.3 示例代碼(主機端)
// Linux 用戶層代碼(H2C 傳輸)
int fd = open("/dev/xdma0_h2c_0", O_RDWR);
void *host_buf = malloc(4096);
void *fpga_buf = mmap(NULL, 4096, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);// 主機填充數據
memcpy(host_buf, data, 4096);
// 啟動 DMA 傳輸(主機到 FPGA)
write(fd, host_buf, 4096);
2.4 性能優化
- 對齊內存:DMA 緩沖區按 4KB 對齊(避免分頁開銷)。
- 批量傳輸:單次傳輸盡量接近 PCIe 最大負載(如 256 Bytes/TLP)。
3. 流傳輸模式(Streaming DMA)
3.1 工作原理
- AXI-S 接口:數據按流式傳輸,無固定地址,適用于實時性要求高的場景。
- 雙工傳輸:
- H2C 流:主機發送數據到 FPGA 的 AXI-S 接口。
- C2H 流:FPGA 發送數據到主機的內存。
3.2 配置步驟(Vivado)
- 在 XDMA IP 核中啟用 AXI4-Stream 接口。
- 配置流接口位寬(如 64-bit)和 FIFO 深度(防止數據溢出)。
3.3 FPGA 邏輯設計
// 示例:FPGA 接收 AXI-S 流數據
axis_slave #(.DATA_WIDTH(64)) stream_in ();
xdma_core xdma_inst (.s_axis_c2h_tdata (stream_in.tdata),.s_axis_c2h_tkeep (stream_in.tkeep),.s_axis_c2h_tlast (stream_in.tlast),.s_axis_c2h_tvalid(stream_in.tvalid),.s_axis_c2h_tready(stream_in.tready)
);
3.4 適用場景
- 實時視頻處理:將攝像頭數據流直接傳輸到 FPGA 進行編解碼。
- 高頻交易:FPGA 處理網絡包并實時回傳結果。
4. Scatter-Gather(SG)模式
4.1 工作原理
- 描述符鏈表:主機或 FPGA 構建鏈表,定義多個非連續數據塊的傳輸任務。
- 自動執行:XDMA 引擎按鏈表順序自動完成傳輸,減少 CPU 干預。
4.2 配置流程
-
硬件啟用 SG 模式:在 Vivado 中勾選 XDMA IP 的 Enable Scatter-Gather。
-
驅動支持:Linux 需使用
dmaengine框架,Windows 需配置 SG 描述符寄存器。 -
構建描述符鏈表:
struct sg_desc {uint64_t src_addr;uint64_t dst_addr;uint32_t length;uint32_t flags; // 方向(H2C/C2H)、中斷使能等uint64_t next_desc; // 下一個描述符物理地址 };
4.3 性能優勢
- 減少拷貝次數:直接傳輸分散數據,無需合并到連續緩沖區。
- 高吞吐量:通過鏈表預取和并行傳輸最大化 PCIe 帶寬利用率。
5. 傳輸模式選擇建議
| 場景 | 推薦模式 | 理由 |
|---|---|---|
| 大數據塊傳輸(>1MB) | 塊傳輸模式 | 連續地址傳輸效率高,適合 DDR 緩存。 |
| 實時流數據(如音頻) | 流傳輸模式 | 低延遲,無地址管理開銷。 |
| 非連續數據(如網絡包) | SG 模式 | 自動聚合分散數據,減少 CPU 負擔。 |
| 混合負載 | 塊 + 流混合模式 | 同時處理批量計算和實時流(需 FPGA 邏輯支持多接口)。 |
6. 常見問題與調試
6.1 傳輸失敗
- 原因:PCIe 鏈路不穩定、地址越界、驅動未正確加載。
- 調試:
- 使用
lspci -vvv檢查 PCIe 設備狀態。 - 通過 XDMA 的狀態寄存器查看錯誤碼。
- 使用
6.2 性能瓶頸
- PCIe 帶寬:計算理論帶寬(如 PCIe Gen3 x8 = 8 GB/s),對比實際傳輸速率。
- FPGA 邏輯瓶頸:檢查 AXI 接口是否滿帶寬運行(使用 Vivado 邏輯分析儀)。
6.3 內存對齊錯誤
- 癥狀:傳輸速度遠低于預期。
- 解決:使用
posix_memalign或cudaMallocHost(GPU 緩沖區)確保內存對齊。
7. 進階應用
7.1 多通道并行傳輸
- 配置多個 DMA 通道:在 Vivado 中實例化多個 XDMA 通道,獨立處理不同任務。
- 負載均衡:將數據按優先級分配到不同通道(如視頻流和控制信號分離)。
7.2 與 RDMA 結合
- RoCE over FPGA:在 FPGA 中實現 RDMA 協議,繞過主機 CPU,直接與其他節點通信。
7.3 動態重配置
- Partial Reconfiguration:在不重啟 FPGA 的情況下切換傳輸模式,適應動態負載。
8. 總結
XDMA 的傳輸模式選擇直接影響系統性能與實時性:
- 塊傳輸適合大數據塊,流傳輸適合低延遲實時數據,SG 模式解決非連續內存問題。
- 合理配置 PCIe 參數、內存對齊和多通道并發是優化關鍵。
- 結合 FPGA 邏輯設計和主機端驅動調優,可充分發揮 PCIe 帶寬潛力,滿足 AI、金融、通信等領域的高性能需求。
Xilinx XDMA 說明和測試 - MM
?斌賦? 已于 2023-10-08 17:36:04 修改
1. 測試工程
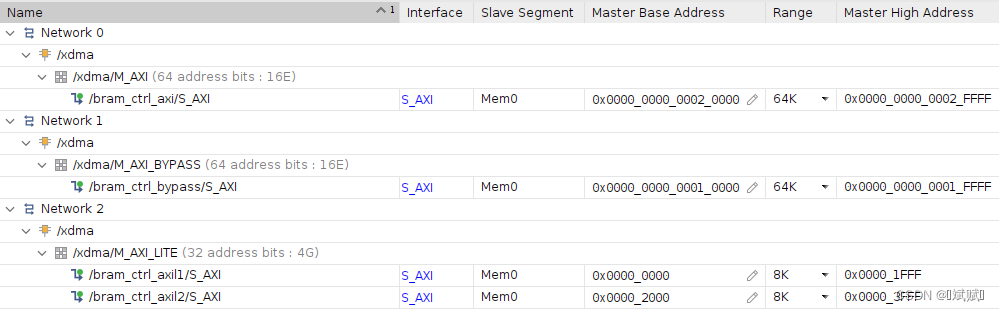
使用 Vivado 創建的 XDMA 測試工程如下圖所示。XDMA IP 的設置如下,其他保持默認。XDMA 的 AXI、AXI Lite 和 AXI Bypass 都連接到 BRAM,每個 BRAM 的地址設置如下圖。該工程可以從 Github 下載,使用的 FPGA 板卡為浪潮的 F37X 加速器。運行工程目錄下的 run.sh 執行 run.tcl 即可完成工程的創建和編譯。注意:AXI Lite 接口需要連接,如果不連接,系統重啟時 XDMA 的驅動可能無法通過 AXI Lite 接口讀取配置信息,從而導致重啟失敗。
- PCIe Block Location:PCIE4C X1Y0
- Lane Width:X16
- Maximum Link Speed:8.0 GT/s
- Reference Clock Frequency:100 MHz
- AXI Data Width:512 bit
- AXI Clock Frequency:250 MHz
- Vendor ID:10EE
- Device ID:903F
- 勾選:
- PCIe to AXI Lite Master Interface 和 64bit Enable
- PCIe to DMA Interface 和 64bit Enable
- PCIe to DMA Bypass Interface 和 64bit Enable
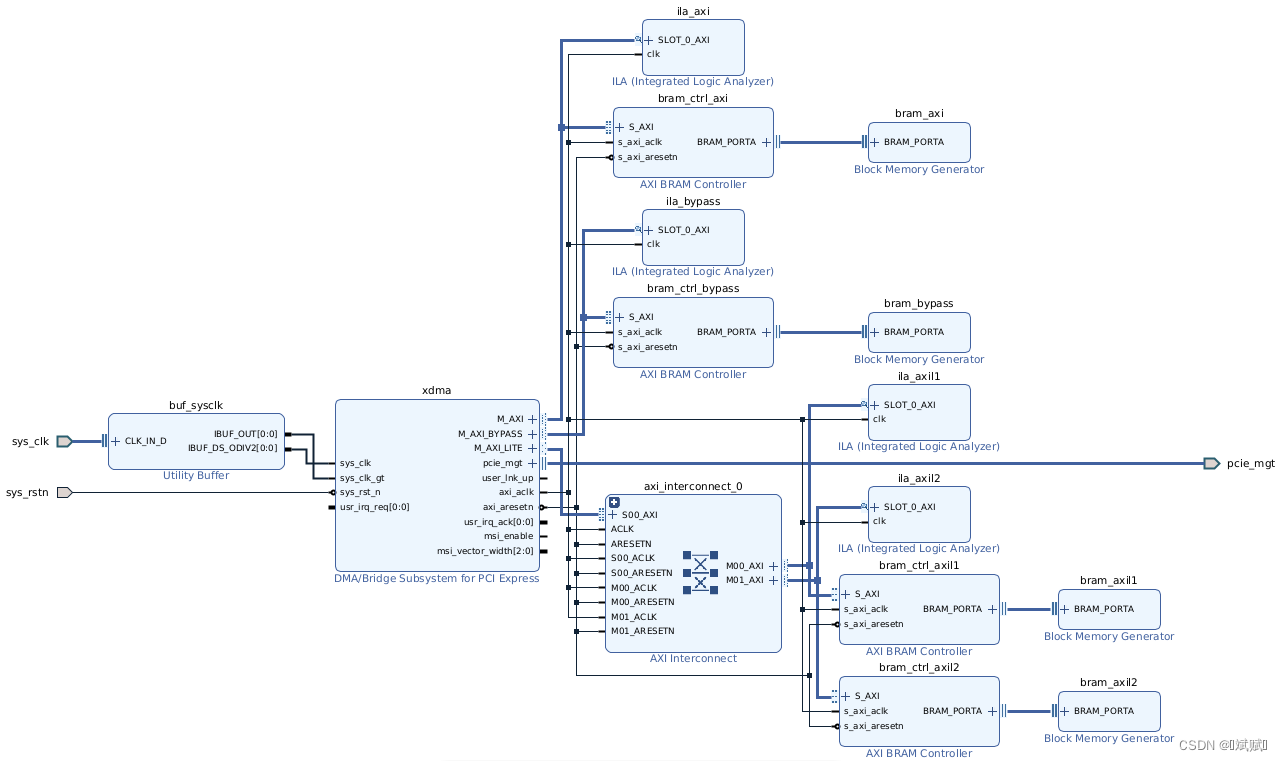
2. 驅動安裝
本節主要介紹 XDMA 驅動的源文件、編譯和安裝過程。
2.1 源文件說明
- 下載地址:DMA 驅動下載
- 文件說明
| 文件 | 說明 |
|---|---|
| include | 編譯依賴文件 |
| tests | 測試文件 load_driver:加載驅動 run_test.sh:執行 DMA 測試 dma_memory_mapped_test:MM 測試調用的腳本 dma_streaming_test.sh:Stream 測試調用的腳本 data:測試數據 |
| tools | 工具文件 reg_rw.c:AXI Lite 和 AXI Bypass 通道讀寫寄存器工具 dma_to_device.c:AXI 通道寫寄存器工具 dma_from_device.c:AXI 通道讀寄存器工具 |
| xdma | 驅動源文件 xdma_mod.c:添加新設備的 Vendor ID 和 Device ID |
| readme.txt | 說明文件 |
| RELEASE | 版本說明 |
| COPYING | 權限 |
| LICENSE | 證書 |
2.2 驅動編譯安裝
- 驅動編譯:在
xdma目錄中執行sudo make install命令編譯驅動,生成xdma.ko文件。 - 編譯工具:在
tools目錄中執行make命令編譯工程,生成reg_rw、dma_to_device、dma_from_device可執行文件。 - 驅動加載:在
tests目錄中執行sudo ./load_driver.sh加載驅動。 - 增加設備 ID:如果需要增加設備 ID,需要修改
xdma/xdma_mod.c文件,在“pci_device_id”結構體中增加PCI_DEVICE的 Vendor ID 和 Device ID。
3. 測試說明
本節介紹 XDMA 的測試結果。
3.1 設備管理
- 下載 FPGA 程序:重新啟動系統后,執行
sudo ./load_driver.sh加載驅動。顯示如下信息表示驅動加載和設備識別成功。執行rmmod xdma可卸載驅動。

- 查看驅動加載狀態:執行
lsmod | grep xdma查看 xdma 驅動是否成功加載。

- 查看 xdma 設備:執行
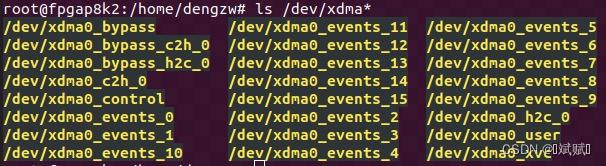
ls /dev/xdma*查看 xdma 設備是否存在。xdma0_h2c_0是 AXI 主機到卡的通道,xdma0_c2h_0是 AXI 卡到主機的通道。由于 XDMA IP 中只啟用了一個 H2C 和 C2H 通道,因此這里只有一個通道。xdma0_user是 AXI Lite 通道,xdma0_bypass是 AXI Bypass 通道,xdma0_control是 PCIe 配置空間的讀寫通道,xdma0_event_*是 16 個用戶中斷(在 IP 核配置時啟用才有用)。
- 多設備沖突:當主機系統中有兩塊加速卡,都下載了 XDMA 工程時,執行
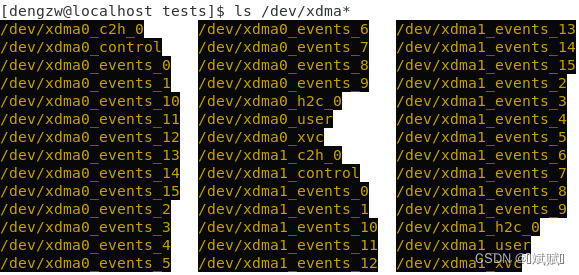
ls /dev/xdma*會列出多個設備。直接使用腳本run_test.sh進行測試會導致失敗。
- 查看設備信息:使用命令
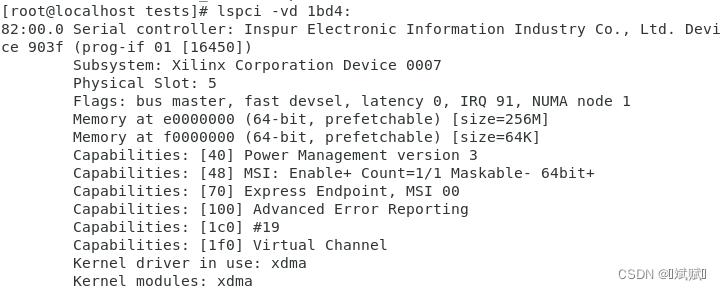
lspci -vd 1bd4:可查看設備的信息,其中 1bd4 是 XDMA IP 設置時設置的 Vendor ID。“Memory at e0000000…” 表示 BAR0 上 AXI Lite 通道的存儲空間,可以在 IP 設置時進行修改。“Memory at f0000000…” 表示 BAR2 上 AXI 通道的存儲空間。不同設置下各通道占據的 BAR 空間位置如下圖所示。
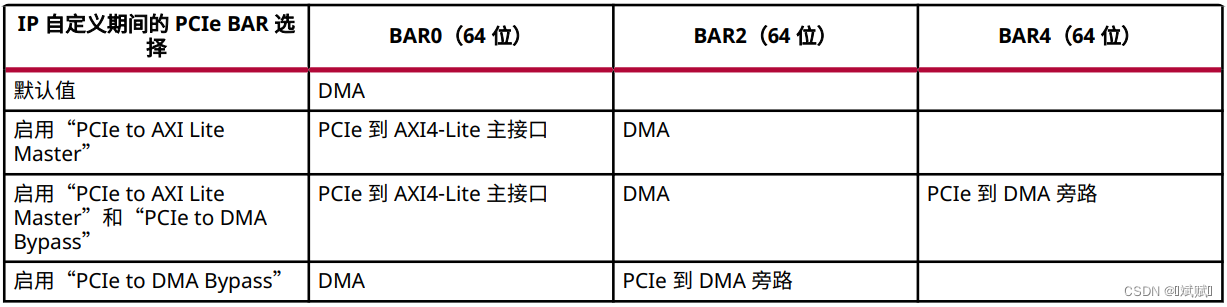
3.2 數據讀寫
- reg_rw 工具:執行
reg_rw -h可查看使用說明
reg_rw <device> <address> <type> <data>
--<device>: ls /dev/xdma* 中的設備
--<address>: 寄存器地址
--<type>: 數據類型:b (byte)-8 字節;h (halfword)-16 字節;w (word)-32 字節
--<data>: 寫入數據,如果沒有這一項,則表示讀取數據
1.1 寫入數據


1.2 讀出數據


- dma_to_device:執行
./dma_to_device -h可查看使用說明
dma-to-device [OPTIONS]
-d:ls /dev/xdma* 中的設備
-f:發送給卡的數據文件
-w:從卡中讀數據寫入的文件
-s:發送數據的字節數
-a:寄存器地址
-c:傳輸次數
-o:offset
-k:aperture


- dma_from_device:執行
./dma_from_device -h可查看使用說明
dma-from-device [OPTIONS]
-d:ls /dev/xdma* 中的設備
-f:發送給卡的數據文件
-w:從卡中讀數據寫入的文件
-s:發送數據的字節數
-a:寄存器地址
-c:傳輸次數
-o:offset
-k:aperture


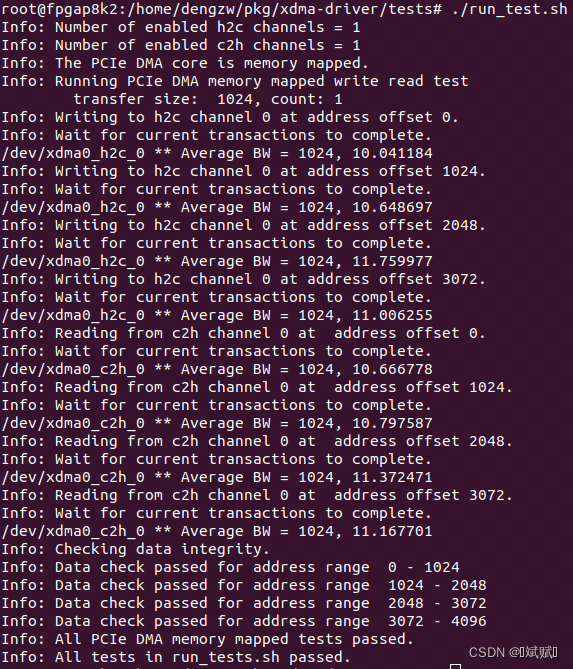
3.3 測試結果
執行 tests 文件夾下的腳本 run_test.sh 完成對 XDMA 的測試。整個測試流程包括查詢使能通道、確定接口方式(MM 或 ST),根據接口方式調用腳本 dma_memory_mapped_test.sh 或 dma_streaming_test。dma_memory_mapped_test.sh 和 dma_streaming_test 腳本首先使用 dma_to_device 命令發送測試數據到 BRAM,然后使用 dma_from_device 命令從 BRAM 中取出數據,最后對比兩個文件的數據是否一致。測試結果如下圖所示。
XDMA 使用小結
mu_guang_ 于 2020-10-07 17:28:23 發布
1. XDMA IP 核的功能
完成 PC 和 FPGA 通過 PCIe 接口的通信,主要進行數據傳輸。數據讀寫分為兩種:一種是數據的讀寫,另一種是配置數據的讀寫。在數據讀寫部分,DMA 通過 MIG 控制 DDR 完成數據讀寫。配置數據讀寫通過與 BRAM 通過 AXI-Lite 總線連接完成。XDMA 將 PCIe 配置信息存儲在 BRAM 中,在進行配置信息讀寫時,將主機地址映射到用戶邏輯的地址,然后與偏移地址處理(物理地址 = 段地址 << 4 + 偏移地址)。因此,在 BRAM 設置時,需要將其偏移地址設置為與主機地址映射的偏移地址相同。
2. AXI 總線傳輸模式
- AXI4.0-lite:AXI4.0-full 的簡化版,用于簡單、低吞吐量的內存映射通信。由于沒有突發傳輸相關的信號線,因此不能進行突發傳輸,每次傳輸只能傳輸一個數據(數據寬度取決于帶寬)。例如,對于 32 位寬度的總線,一次可以傳輸 4 個字節。
- AXI4.0-full:用于高性能內存映射需求。包含突發控制信號,可以進行突發傳輸。在指定一次地址后,可以一次傳輸多達 256 個數據(數據寬度取決于帶寬)。
- AXI_stream:用于高速流數據傳輸。由于沒有地址總線,因此用于數據流傳送,允許無限制的數據突發傳輸規模。
應用場景
- AXI4.0-lite:主要用于內核和外設寄存器之間的通信。
- AXI4.0-full:主要用于向 DDR 或 OCM 中寫入大量數據。
- AXI_stream:主要用于向 FIFO 等沒有地址的數據緩沖區傳送大量數據。
3. IP 核配置
3.1 Basic
- Functional Mode:功能模式,即 DMA 模式。
- Mode:模式,選擇 Basic。Basic 與 Advanced 的區別在于 Advanced 模式開放更多的可選選項與功能,而 Basic 是默認模式。
- Device/Port Type:選擇設備與端口類型,為端點設備。
- PCIe Block Location:從可用的集成塊中選擇,以啟用生成特定位置的約束文件和輸出。通常使用 X0Y0。

- Lane Width:通道寬度,根據接口進行選擇。
- AXI Address Width:AXI 地址寬度選擇,僅支持 64 bit(參考用戶手冊第 73 頁)。
- AXI Data Width:AXI 總線上傳輸的數據寬度,可以是 64 bit、128 bit、256 bit、512 bit(此選項僅適用于 UltraScale+,具體配置需參考 datasheet 第 249 頁)。

- DMA Interface Option:DMA 的接口類型用于數據傳輸,有兩種選擇:AXI MM(memory mapped)與 AXI ST(stream)。一般情況下,AXI MM 用于與 DDR 之間的通信,AXI stream 用于 FIFO。

3.2 PCIe BARs
- PCIe to AXI Lite Master Interface:使能后,可以在主機一側通過 PCIe 訪問用戶邏輯側寄存器或其他 AXI-Lite 總線設備。配置信息存儲在 BRAM 中,通過 AXI-Lite 總線讀寫 BRAM。
- BAR 類型:32 bit,不使能 64 bit,不使能 prefetchable。
- 映射空間:選擇 1M,大小可根據實際需求自定義。
- PCIe to AXI Translation:主機側 BAR 地址與用戶邏輯側地址不同,通過設置轉換地址實現 BAR 地址到 AXI 地址的轉換。例如,主機側 BAR 地址為 0,則主機訪問 BAR 地址 0 轉換到 AXI-Lite 總線地址為 0x80000000。
- PCIe to DMA Interface:數據傳輸寬度為 64 bit,DMA 控制器通常只支持數據 8 字節對齊的情況。當數據從上位機通過 PCIe 接口發送到端點設備時,XDMA 內部自行解包并對數據與指令進行分析,得到讀寫操作的指令地址,并對 DDR 進行讀寫操作。操作結果通過 AXI 接口返回 XDMA,XDMA 對數據進行組包后通過物理層發出,實現數據的 DMA 控制。

4. XDMA 連接
主要連接部分為 M_AXI 和 M_AXI_LITE,通常連接到 AXI Interconnect。M_AXI 一般與 DDR 或 FIFO 相連,用于數據通信;M_AXI_LITE 用于配置信息傳輸,訪問用戶邏輯側寄存器。

5. 使用原理解析
5.1 PC 寫數據
- PC 通過調用函數寫數據,更新
dsTail,并寫入對應的寄存器中。 writeReg相當于一條指令down_tail+1,XDMA 會進行地址映射。在 PC 上對寄存器進行操作時,會通過 AXI-Lite 總線傳輸,從而對目標地址上的數據進行加 1 操作。- 控制模塊
queue對 AXI-Lite 數據進行解析,對down_tail進行 +1 操作。 - 計算
down_cnt,從而控制 AXI 從 DDR 上對數據進行讀取。 - AXI 從 DDR 上讀取數據后,
down_head+1,然后反饋給控制模塊queue,計算down_cnt。
void updateDsTail (int pkgCnt)
{for (; pkgCnt > 0; pkgCnt--){dsTail += DS_PSIZE;if (dsTail >= DS_ADDR_LIMIT)dsTail = DS_BASE_ADDR;}writeReg (DS_TAIL_REG, dsTail);
}

5.2 PC 讀數據
- PC 讀取數據,對
up_head寄存器進行 +1 操作。 - 通過 XDMA 對相關寄存器地址進行映射,并通過 AXI-Lite 總線對相應的地址寫入數據。
- 控制模塊
queue通過up_cnt = tail - head計算up_cnt。 up_cnt用于控制 FPGA 將數據寫入 DDR,up_cnt也是一個滿標志。
20 基于 XDMA 實現 PCIe 通信方案
posted @ 2023-12-27 20:13 米聯客(milianke)
軟件版本
- Vivado 2021.1
- 操作系統:WIN10 64bit
硬件平臺
- 適用 XILINX A7/K7/Z7/ZU/KU 系列 FPGA
1. 概述
本方案作為通用教程,適用于 XILINX 各類支持 PCIe 通信的板卡。米聯客在 XDMA 中使用了自行編寫的 FDMA 控制 IP,可以簡單方便地完成數據交換。
2. 系統構架
本系統的關鍵在于編寫了一個 uixdmairq IP,用于配合驅動處理中斷。uixdmairq 提供了 AXI-Lite 接口,上位機通過訪問用戶空間地址讀寫 uixdmairq 的寄存器。該 IP 在 user_irq_req_i 輸入的中斷位上寄存中斷位號,并輸出給 XDMA IP。當上位機的驅動響應中斷時,在中斷中寫入 uixdmairq 的寄存器,清除已處理的中斷。
此外,本方案通過 AXI-BRAM 演示用戶空間的讀寫訪問測試。
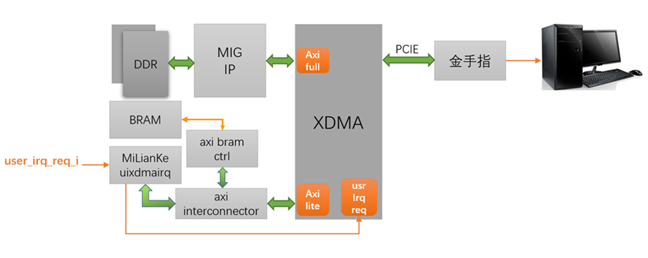
3. XDMA 概述
Xilinx 提供的 DMA Subsystem for PCI Express IP 是一個高性能、可配置的適用于 PCIe 2.0 和 PCIe 3.0 的 SG 模式 DMA,提供用戶可選擇的 AXI4 接口或 AXI4-Stream 接口。一般情況下,配置為 AXI4 接口可以加入系統總線互聯,適用于大數據量異步傳輸,通常會使用到 DDR。AXI4-Stream 接口適用于低延遲數據流傳輸。
XDMA 是 SGDMA(Scatter-Gather DMA),并非 Block DMA。在 SG 模式下,主機會將要傳輸的數據組成鏈表的形式,然后將鏈表首地址通過 BAR 傳送給 XDMA。XDMA 會根據鏈表結構首地址依次完成鏈表所指定的傳輸任務。
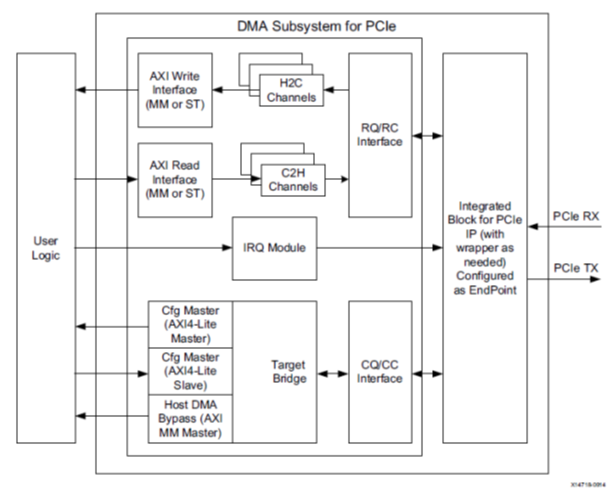
- AXI4、AXI4-Stream:必須選擇一個,用于數據傳輸。
- AXI4-Lite Master:可選,用于實現 PCIe BAR 地址到 AXI4-lite 寄存器地址的映射,可以用于讀寫用戶邏輯寄存器。
- AXI4-Lite Slave:可選,用于將 XDMA 內部寄存器開放給用戶邏輯,用戶邏輯可以通過此接口訪問 XDMA 內部寄存器,不會映射到 BAR。
- AXI4 Bypass:可選,用于實現 PCIe 直通用戶邏輯訪問,適用于低延遲數據傳輸。
4. 基于 XDMA 的 PCIe FPGA 工程搭建
4.1 XDMA IP 配置
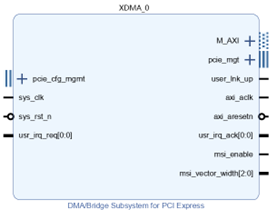
1. 添加 XDMA IP 核
2. 配置 XDMA IP
雙擊 XDMA IP 進行配置:
- Mode:配置模式,選擇 BASE 配置。
- Lane Width:選擇 PCIe 的通道數量。對于 MA703FA 為 2 個通道。每個開發板支持的通道數量不同,通道數量越多,通信速度越快。用戶需要根據硬件的實際通道數量選擇正確的通道數。
- Max Link Speed:選擇 5.0 GT/s,即 PCIe 2.0。
- Reference Clock:100 MHz,參考時鐘為 100 MHz。
- DMA Interface Option:接口選擇 AXI4 接口。
- AXI Data Width:128 bit,即 AXI4 數據總線寬度為 128 bit。
- AXI Clock:125 MHz,即 AXI4 接口時鐘為 125 MHz。
- DMA Interface Option:設置為 AXI Memory Mapped 方式。
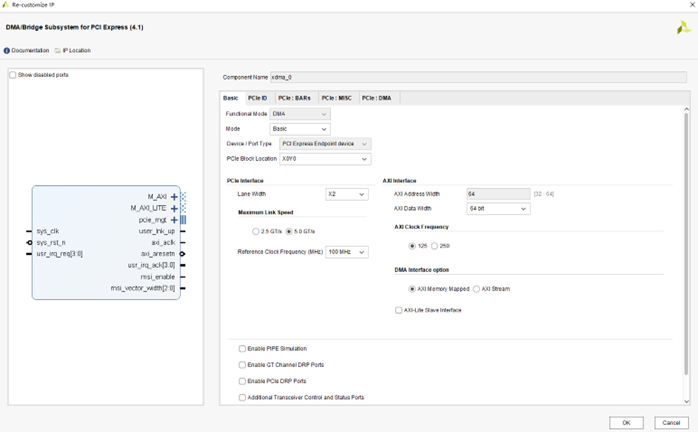
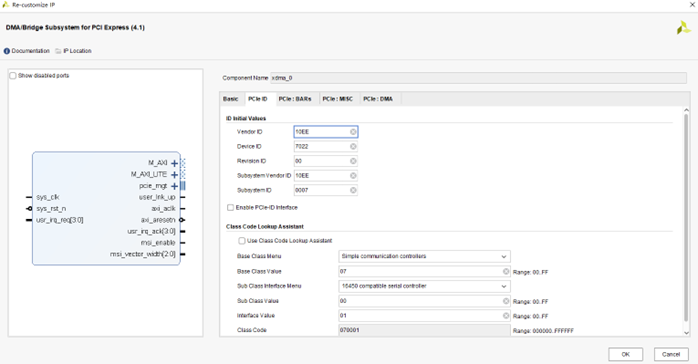
- PCIE ID 配置:選擇默認配置即可。默認設備類型為 Simple communication controllers。
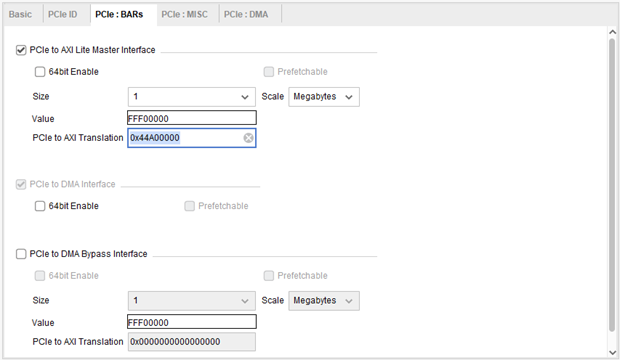
- PCIE BAR 配置:此部分配置較為重要。首先使能 PCIe to AXI Lite Master Interface,這樣可以在主機一側通過 PCIe 訪問用戶邏輯側寄存器或其他 AXI4-Lite 總線設備。映射空間選擇 1M,用戶也可以根據實際需求自定義大小。
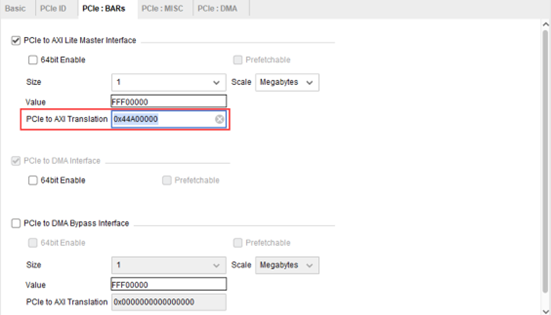
- PCIe to AXI Translation:此設置較為重要。通常情況下,主機側 PCIe BAR 地址與用戶邏輯側地址不同,此設置用于進行 BAR 地址到 AXI 地址的轉換。例如,主機側 BAR 地址為 0,IP 內部轉換設置為 0x44A00000,則主機訪問 BAR 地址 0 轉換到 AXI Lite 總線地址為 0x44A00000。
- PCIe to DMA Interface:選擇 64 bit 使能。
- DMA Bypass:暫時不使用。
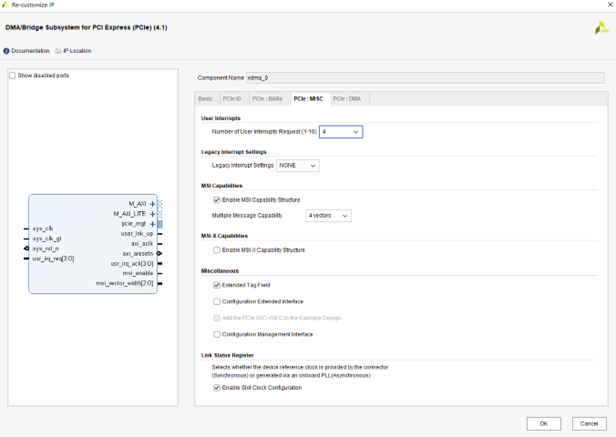
- PCIE 中斷設置:
- User Interrupts:用戶中斷。XDMA 提供 16 條中斷線給用戶邏輯,此處可以配置使用幾條中斷線。
- Legacy Interrupt:XDMA 支持 Legacy 中斷,此處不選。
- MSI Capabilities:選擇支持 MSI 中斷,支持 4 個中斷消息向量。
注意:MSI 中斷和 MSI-X 中斷只能選擇一個,否則會報錯。如果選擇了 MSI 中斷,則可以選擇 Legacy 中斷;如果選擇了 MSI-X 中斷,則 MSI 必須取消選擇,同時 Legacy 也必須選擇 None。此 IP 對于 7 系列設置有此問題,如果使用 Ultrascale 系列,則可以全部選擇。
- MSI-X Capabilities:不選。
- Miscellaneous:選 Extended Tag Field。
- Link Status Register:選 Enable Slot Clock Configuration。
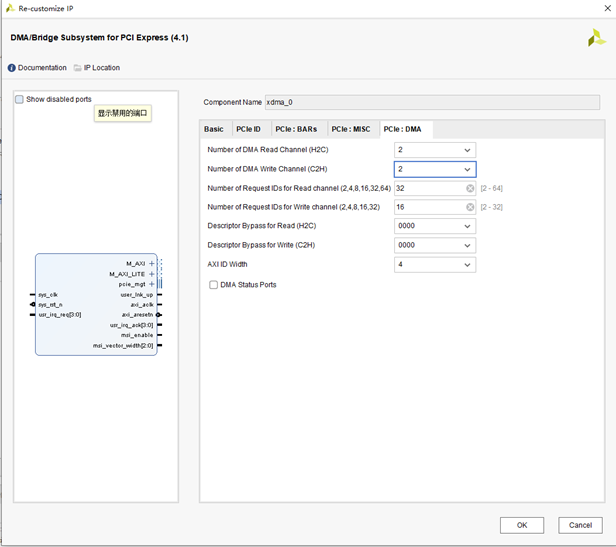
- 配置 DMA 相關內容:
- Number of DMA Read Channel(H2C)和 Number of DMA Write Channel(C2H)通道數:對于 PCIe 2.0,最大只能選擇 2。XDMA 可以提供最多兩個獨立的寫通道和兩個獨立的讀通道。獨立通道在實際應用中具有重要意義,在帶寬允許的前提下,一個 PCIe 可以實現多種不同的傳輸功能,并且互不影響。此處選擇 1。
- Number of Request IDs for Read(Write)channel:每個通道設置允許的最大 outstanding 數量,按照默認值即可。
4.2 完成自動連線
配置完成后,點擊 Run Block Automation,可以看到之前的配置信息。如果發現與目標配置不一致,需要手動修改。點擊 OK,完成配置。
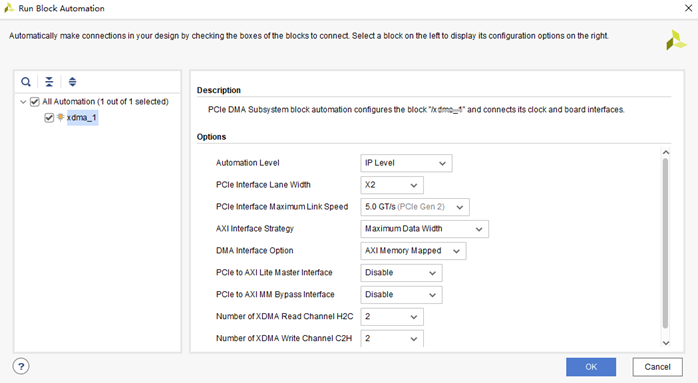
配置完成后,Vivado 會自動進行必要的連線。
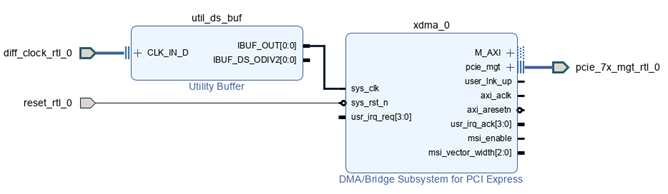
到此為止,XDMA IP 配置完成。為了讓 XDMA 和上位機密切配合工作,還需要繼續搭建其他部分的功能模塊。
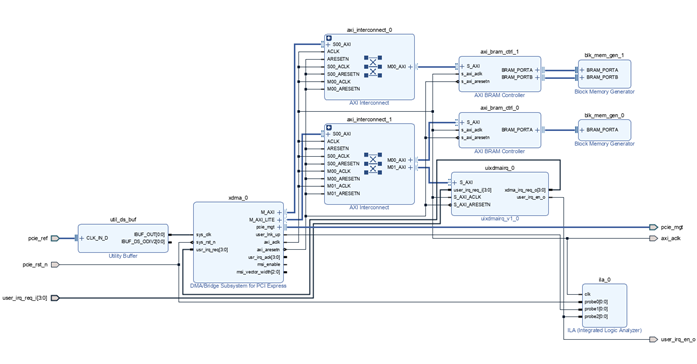
4.3 基于圖形設計的 XDMA 工程
4.4 添加中斷測試代碼
`timescale 1ns / 1ps/*******************************MILIANKE*******************************
* Company : MiLianKe Electronic Technology Co., Ltd.
* WebSite: https://www.milianke.com
* TechWeb: https://www.uisrc.com
* tml-shop: https://milianke.tmall.com
* jd-shop: https://milianke.jd.com
* taobao-shop1: https://milianke.taobao.com
* Create Date: 2022/05/01
* File Name: pcie_top.v
* Description:
* Declaration:
* The reference demo provided by Milianke is only used for learning.
* We cannot ensure that the demo itself is free of bugs, so users
* should be responsible for the technical problems and consequences
* caused by the use of their own products.
* Copyright: Copyright (c) MiLianKe
* All rights reserved.
* Revision: 1.0
* Signal description
* 1) _i input
* 2) _o output
* 3) _n active low
* 4) _dg debug signal
* 5) _r delay or register
* 6) _s state machine
*********************************************************************/
module pcie_top
(// PCIe 串行數據端口input [1:0] pcie_mgt_rxn,input [1:0] pcie_mgt_rxp,output [1:0] pcie_mgt_txn,output [1:0] pcie_mgt_txp,// PCIe 參考時鐘input [0:0] pcie_ref_clk_n,input [0:0] pcie_ref_clk_p,input pcie_rst_n
);wire axi_aclk;
wire user_irq_en_o;// 內部計數器產生一個延遲復位
reg [21:0] timer_cnt;
reg timer_r1, timer_r2;
reg [1:0] int_p;
reg [3:0] user_irq_req_i;
wire inter = !timer_r2 && timer_r1;always @(posedge axi_aclk) beginif (!axi_aresetn || !user_irq_en_o) begintimer_cnt <= 22'd0;end else begintimer_cnt <= timer_cnt + 1'b1;end
endalways @(posedge axi_aclk) beginif (!axi_aresetn || !user_irq_en_o) begintimer_r1 <= 1'd0;timer_r2 <= 1'd0;end else begintimer_r1 <= timer_cnt [20];timer_r2 <= timer_r1;end
end// 產生用戶中斷
always @(posedge axi_aclk) beginif (!axi_aresetn || !user_irq_en_o) beginint_p [1:0] <= 4'd0;user_irq_req_i <= 4'd0;end else beginif (inter) int_p <= int_p + 1'b1;user_irq_req_i <= 4'd0;user_irq_req_i [int_p] <= 1'b1;end
end// 接口例化
pcie_system pcie_system_i
(.pcie_mgt_rxn (pcie_mgt_rxn),.pcie_mgt_rxp (pcie_mgt_rxp),.pcie_mgt_txn (pcie_mgt_txn),.pcie_mgt_txp (pcie_mgt_txp),.pcie_ref_clk_n (pcie_ref_clk_n),.pcie_ref_clk_p (pcie_ref_clk_p),.pcie_rst_n (pcie_rst_n),.axi_aclk (axi_aclk),.user_irq_en_o (user_irq_en_o),.user_irq_req_i (user_irq_req_i)
);
endmodule
4.5 地址分配
進行地址分配:
- 將掛在 M_AXI 上的 DDR(對于 MA703-35T 掛 BRAM)地址分配從 0 開始(對于 Windows 系統必須為 0)。M_AXI 用于進行 DMA 操作。
- M_AXI_LITE 掛載的 BRAM 和
uixdmairq中斷控制單元映射到用戶 BAR 地址空間,該地址是前面 XDMA IP 中設置的地址。默認情況下,需要設置uixdmairq中斷控制單元的地址與 XDMA 中設置的用戶 BAR 地址空間一致,例如 0x44A00000。BRAM 的地址空間為 0x44A010000。
關于地址空間的具體含義,結合軟件的使用會更加清晰。初學者暫且根據教程設置。
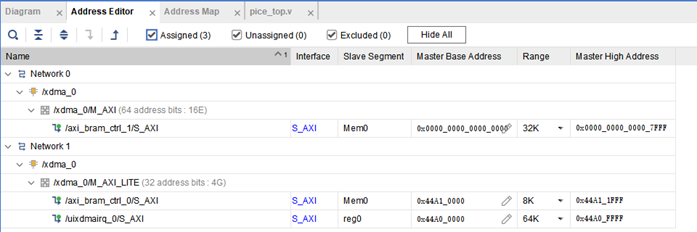
5. 硬件安裝
先下載程序,調試階段下載 bit 文件,然后再開電腦。這樣才能正確識別并確保后續測試工作正常開展。

6. 硬件識別
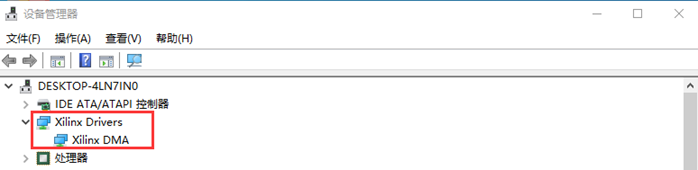
7. 應用程序測試
7.1 xdma_rw.exe 功能介紹
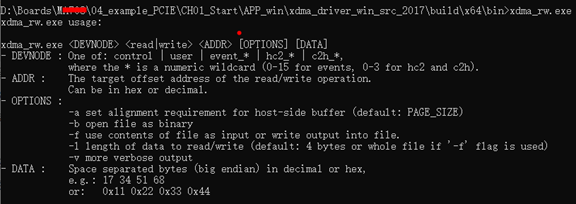
打開一個終端(如果雙擊運行會很快退出),進入到上一節編譯生成的應用程序目錄,找到 xdma_rw.exe。該應用程序用于操作所有 PCIe 設備。在終端中僅輸入 xdma_rw.exe,可以查看程序的使用說明。
參數說明
-
DEVNODE:
control:控制通道,用于控制 XDMA 的寄存器。由于精力原因,米聯客對控制通道對 XDMA 寄存器的設置沒有深入研究。event_*:中斷事件,其中*表示中斷號。user:用戶空間,數據通過 AXI4-LITE 接口傳輸。h2c_*:主機到卡(Host to Card),PC 發送 DMA 數據到板卡,其中*表示通道號,通常使用通道 0。數據通過 AXI4-FULL 通道傳輸。c2h_*:卡到主機(Card to Host),板卡發送數據到 PC,其中*表示通道號,通常使用通道 0。數據通過 AXI4-FULL 通道傳輸。
-
ADDR:讀寫地址偏移。
- 對于 DMA 通道,地址從 0 開始。
- 對于 PS DDR 內存,必須偏移至少 20 MB 開始讀寫 PS DDR。
- 對于
user的讀寫,偏移地址是 AXI-LITE 接口的 IP 地址,減去在 XDMA IP 中配置的 PCIe to AXI Translation 地址。對于米聯客的 XDMA 方案,由于修改了驅動中對于中斷的響應,因此 PCIe to AXI Translation 必須和默認的uixdmairq地址一致。之后再分區其他 AXI-LITE 接口外設。
-
OPTION:
a:設置內存對齊。b:打開一個二進制文件。f:讀取或寫入文件。l:數據長度。v:更詳細的輸出。
-
DATA:十進制或十六進制數,必須用空格間隔。例如:
17 34 51 680x11 0x22 0x33 0x44
DMA 批量數據測試
DMA 傳輸是使用最頻繁的一種方式,需要用到 h2c 或 c2h 通道。
當前目錄下有一個 datafile4k.bin 文件,可以測試將該文件傳輸到 FPGA 的 DDR(或 MA703FA-35T 的 BRAM),然后讀取出來。
在終端輸入以下指令:
xdma_rw.exe h2c_0 write 0x0000000 -b -f datafile4K.bin -l 4096
該指令的含義是:使用 h2c_0 設備,以二進制形式讀取文件 datafile4k.bin,將其寫入到 BRAM 內存地址 0x0000000,長度為 4096 字節。

使用以下命令讀取數據:
xdma_rw.exe c2h_0 read 0x0000000 -b -f datafile4K_recv.bin -l 4096

接下來可以使用 WinHex 等軟件檢查兩個文件的數據是否一致。如果一致,則說明傳輸功能正常。
7.2 user 通道測試
通過 AXI-LITE 接口寫入 2 個數據到掛在 AXI-LITE 接口的 BRAM 中:
xdma_rw.exe user write 0x10000 0x11 0x22
通過 AXI-LITE 接口讀取 2 個數據從掛在 AXI-LITE 接口的 BRAM 中:
xdma_rw.exe user read 0x10000 -l 2
7.3 event 中斷測試
1. XDMA 中斷 FPGA 部分代碼
首先需要理解 XDMA 的中斷類型及控制時序:
-
Legacy Interrupts:
- 對于 Legacy Interrupts,當中斷請求
user_irq_ack第一次為 1 時,usr_irq_req可以清 0。當中斷請求user_irq_ack第二次為 1 時,可以重新設置usr_irq_req發起中斷。 - 在 PCI 總線中,INTx 中斷由四條可選的中斷線決定。這種中斷方式是共享式的,所有 PCI 設備將中斷信號在一條中斷線上相與,再上報給 CPU。CPU 收到中斷后,需要查詢具體是哪個設備產生了中斷。
- 在 PCIe 總線中,已經沒有實體的 INTx 物理中斷線了。PCIe 標準使用專門的 Message 事務包來實現 INTx 中斷,這是為了兼容以前的 PCI 軟件。INTx 是共享式的,CPU 響應中斷后還需要查詢具體中斷源,效率較低。

- 對于 Legacy Interrupts,當中斷請求
-
MSI Interrupts:
- MSI 發出
usr_irq_req中斷請求后,user_irq_ack為 1 只是說明中斷已經被主機接收,但不代表已經處理。軟件或驅動層可以清零usr_irq_req。 - MSI 和 MSI-X 都是通過向配置的 CPU 中斷寄存器寫入內存操作來產生中斷,效率比共享式的 INTx 高。MSI 最多支持 32 個中斷向量,而 MSI-X 最多支持 2048 個中斷向量。

- MSI 發出
-
MSI-X Interrupts:
- 當
usr_irq_req中斷請求后,user_irq_ack為 1 時可以清零usr_irq_req,但沒有說明何時可以置 1,重啟下次中斷。

- 當
經過以上所有中斷方式測試,發現使用 Legacy 和 MSI 已經足夠,且相對穩定。上位機驅動通過訪問用戶 BAR 地址空間和米聯客編寫的 Uixdmairq IP-core 一起管理接收的中斷。
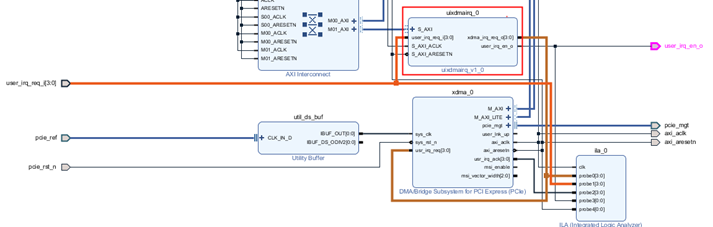
Uixdmairq.v 源碼:
/*******************************MILIANKE*******************************
* Company : MiLianKe Electronic Technology Co., Ltd.
* WebSite: https://www.milianke.com
* TechWeb: https://www.uisrc.com
* tml-shop: https://milianke.tmall.com
* jd-shop: https://milianke.jd.com
* taobao-shop1: https://milianke.taobao.com
* Create Date: 2022/05/01
* Module Name: uixdmairq
* File Name: uixdmairq.v
* Description:
* The reference demo provided by Milianke is only used for learning.
* We cannot ensure that the demo itself is free of bugs, so users
* should be responsible for the technical problems and consequences
* caused by the use of their own products.
* Copyright: Copyright (c) MiLianKe
* All rights reserved.
* Revision: 1.0
* Signal description
* 1) _i input
* 2) _o output
* 3) _n active low
* 4) _dg debug signal
* 5) _r delay or register
* 6) _s state machine
*********************************************************************/
`timescale 1ns / 1psmodule uixdmairq #(parameter integer XMDA_REQ_NUM = 8
) (// Users to add ports hereinput wire [XMDA_REQ_NUM-1:0] user_irq_req_i,output wire [XMDA_REQ_NUM-1:0] xdma_irq_req_o,output wire user_irq_en_o,input wire S_AXI_ACLK,input wire S_AXI_ARESETN,input wire [3:0] S_AXI_AWADDR,input wire [2:0] S_AXI_AWPROT,input wire S_AXI_AWVALID,output wire S_AXI_AWREADY,input wire [31:0] S_AXI_WDATA,input wire [3:0] S_AXI_WSTRB,input wire S_AXI_WVALID,output wire S_AXI_WREADY,output wire [1:0] S_AXI_BRESP,output wire S_AXI_BVALID,input wire S_AXI_BREADY,input wire [3:0] S_AXI_ARADDR,input wire [2:0] S_AXI_ARPROT,input wire S_AXI_ARVALID,output wire S_AXI_ARREADY,output wire [31:0] S_AXI_RDATA,output wire [1:0] S_AXI_RRESP,output wire S_AXI_RVALID,input wire S_AXI_RREADY
);reg [XMDA_REQ_NUM-1:0] user_irq_req;
reg [XMDA_REQ_NUM-1:0] user_irq_req_r1;
reg [XMDA_REQ_NUM-1:0] user_irq_req_r2;
reg [XMDA_REQ_NUM-1:0] user_irq_req_r3;
reg [XMDA_REQ_NUM-1:0] xdma_irq_ack_r1;
reg [XMDA_REQ_NUM-1:0] xdma_irq_ack_r2;
reg [XMDA_REQ_NUM-1:0] xdma_irq_ack_r3;
// reg [XMDA_REQ_NUM-1:0] xdma_irq_ack;reg [XMDA_REQ_NUM-1:0] xdma_irq_req;// AXI4LITE signals
reg [3:0] axi_awaddr;
reg axi_awready;
reg axi_wready;
reg [1:0] axi_bresp;
reg axi_bvalid;
reg [3:0] axi_araddr;
reg axi_arready;
reg [31:0] axi_rdata;
reg [1:0] axi_rresp;
reg axi_rvalid;// Example-specific design signals
// local parameter for addressing 32 bit / 64 bit C_S_AXI_DATA_WIDTH
// ADDR_LSB is used for addressing 32/64 bit registers/memories
// ADDR_LSB = 2 for 32 bits (n downto 2)
// ADDR_LSB = 3 for 64 bits (n downto 3)
localparam integer ADDR_LSB = 2;
localparam integer OPT_MEM_ADDR_BITS = 1;//----------------------------------------------
//-- Signals for user logic register space example
//------------------------------------------------
//-- Number of Slave Registers 4
reg [31:0] slv_reg0;
reg [31:0] slv_reg1;
wire slv_reg_rden;
wire slv_reg_wren;
reg [31:0] reg_data_out;
integer byte_index;
reg aw_en;// I/O Connections assignments
assign S_AXI_AWREADY = axi_awready;
assign S_AXI_WREADY = axi_wready;
assign S_AXI_BRESP = axi_bresp;
assign S_AXI_BVALID = axi_bvalid;
assign S_AXI_ARREADY = axi_arready;
assign S_AXI_RDATA = axi_rdata;
assign S_AXI_RRESP = axi_rresp;
assign S_AXI_RVALID = axi_rvalid;// Implement axi_awready generation
// axi_awready is asserted for one S_AXI_ACLK clock cycle when both
// S_AXI_AWVALID and S_AXI_WVALID are asserted. axi_awready is
// de-asserted when reset is low.
always @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0) beginaxi_awready <= 1'b0;aw_en <= 1'b1;end else beginif (!axi_awready && S_AXI_AWVALID && S_AXI_WVALID && aw_en) begin// slave is ready to accept write address when// there is a valid write address and write data// on the write address and data bus. This design// expects no outstanding transactions.axi_awready <= 1'b1;aw_en <= 1'b0;end else if (S_AXI_BREADY && axi_bvalid) beginaw_en <= 1'b1;axi_awready <= 1'b0;end else beginaxi_awready <= 1'b0;endend
end// Implement axi_awaddr latching
// This process is used to latch the address when both
// S_AXI_AWVALID and S_AXI_WVALID are valid.
always @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0) beginaxi_awaddr <= 0;end else beginif (!axi_awready && S_AXI_AWVALID && S_AXI_WVALID && aw_en) begin// Write Address latchingaxi_awaddr <= S_AXI_AWADDR;endend
end// Implement axi_wready generation
// axi_wready is asserted for one S_AXI_ACLK clock cycle when both
// S_AXI_AWVALID and S_AXI_WVALID are asserted. axi_wready is
// de-asserted when reset is low.
always @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0) beginaxi_wready <= 1'b0;end else beginif (!axi_wready && S_AXI_WVALID && S_AXI_AWVALID && aw_en) begin// slave is ready to accept write data when// there is a valid write address and write data// on the write address and data bus. This design// expects no outstanding transactions.axi_wready <= 1'b1;end else beginaxi_wready <= 1'b0;endend
endassign slv_reg_wren = axi_wready && S_AXI_WVALID && axi_awready && S_AXI_AWVALID;always @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0) beginslv_reg0 <= 0;end else if (slv_reg_wren) beginif (axi_awaddr [3:2] == 2'd0) slv_reg0 [31:0] <= S_AXI_WDATA [31:0];else if (axi_awaddr [3:2] == 2'd1) slv_reg1 [31:0] <= S_AXI_WDATA [31:0];end else beginslv_reg0 <= 0;slv_reg1 <= slv_reg1;end
end// Implement write response logic generation
// The write response and response valid signals are asserted by the slave
// when axi_wready, S_AXI_WVALID, axi_wready and S_AXI_WVALID are asserted.
// This indicates the acceptance of the write transaction and the status of
// the write transaction.
always @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0) beginaxi_bvalid <= 0;axi_bresp <= 2'b0;end else beginif (axi_awready && S_AXI_AWVALID && !axi_bvalid && axi_wready && S_AXI_WVALID) begin// indicates a valid write response is availableaxi_bvalid <= 1'b1;axi_bresp <= 2'b0; // 'OKAY' responseend else if (S_AXI_BREADY && axi_bvalid) beginaxi_bvalid <= 0;endend
end// Implement axi_arready generation
// axi_arready is asserted for one S_AXI_ACLK clock cycle when
// S_AXI_ARVALID is asserted. axi_arready is de-asserted when reset is low.
// The read address is also latched when S_AXI_ARVALID is asserted.
always @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0) beginaxi_arready <= 0;axi_araddr <= 32'b0;end else beginif (!axi_arready && S_AXI_ARVALID) begin// indicates that the slave has accepted the valid read addressaxi_arready <= 1'b1;// Read address latchingaxi_araddr <= S_AXI_ARADDR;end else beginaxi_arready <= 0;endend
end// Implement axi_rvalid generation
// axi_rvalid is asserted for one S_AXI_ACLK clock cycle when both
// S_AXI_ARVALID and axi_arready are asserted. The slave registers
// data are available on the axi_rdata bus at this instance. The
// assertion of axi_rvalid marks the validity of the read data on the
// bus and axi_rresp indicates the status of the read transaction.
always @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0) beginaxi_rvalid <= 0;axi_rresp <= 0;end else beginif (axi_arready && S_AXI_ARVALID && !axi_rvalid) begin// Valid read data is available on the read data busaxi_rvalid <= 1'b1;axi_rresp <= 2'b0; // 'OKAY' responseend else if (axi_rvalid && S_AXI_RREADY) begin// Read data is accepted by the masteraxi_rvalid <= 0;endend
end// Implement memory mapped register select and read logic generation
// Slave register read enable is asserted when valid address is available
// and the slave is ready to accept the read address.
assign slv_reg_rden = axi_arready & S_AXI_ARVALID & !axi_rvalid;always @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0) beginaxi_rdata <= 0;end else if (slv_reg_rden) beginif (axi_araddr [3:2] == 2'd0) axi_rdata [31:0] <= slv_reg0 [31:0];else if (axi_araddr [3:2] == 2'd1) axi_rdata [31:0] <= slv_reg1 [31:0];end
end// Add user logic here
reg [4:0] i;
reg [4:0] j;
reg [4:0] k;assign xdma_irq_req_o = xdma_irq_req;
assign user_irq_en_o = slv_reg1 [31];
assign xdma_irq_ack = slv_reg0 [XMDA_REQ_NUM-1:0];always @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0 || user_irq_en_o == 1'b0) beginuser_irq_req_r1 <= 0;user_irq_req_r2 <= 0;user_irq_req_r3 <= 0;end else beginuser_irq_req_r1 <= user_irq_req_i;user_irq_req_r2 <= user_irq_req_r1;user_irq_req_r3 <= user_irq_req_r2;end
endalways @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0 || user_irq_en_o == 1'b0) beginj <= 5'd0;user_irq_req <= 0;end else beginfor (j = 0; j <= XMDA_REQ_NUM-1; j = j + 1) beginuser_irq_req [j] <= !user_irq_req_r3 [j] & user_irq_req_r2 [j];endend
endalways @(posedge S_AXI_ACLK) beginif (S_AXI_ARESETN == 1'b0 || user_irq_en_o == 1'b0) begini <= 5'd0;xdma_irq_req <= 0;end else beginfor (i = 0; i <= XMDA_REQ_NUM-1; i = i + 1) beginif (xdma_irq_ack [i]) beginxdma_irq_req [i] <= 1'b0;end else if (user_irq_req [i]) beginxdma_irq_req [i] <= 1'b1;endendend
end// User logic ends
endmodule
為了方便測試中斷,在 pcie_top.v 中增加了定時產生用戶中斷的程序。
wire axi_aclk;
wire axi_aresetn;
wire user_irq_en_o;// 內部計數器產生一個延遲復位
reg [21:0] timer_cnt;
always @(posedge axi_aclk) beginif (!axi_aresetn || !user_irq_en_o) begintimer_cnt <= 22'd0;end else begintimer_cnt <= timer_cnt + 1'b1;end
endreg timer_r1, timer_r2;
wire inter = !timer_r2 && timer_r1;always @(posedge axi_aclk) beginif (!axi_aresetn || !user_irq_en_o) begintimer_r1 <= 1'd0;timer_r2 <= 1'd0;end else begintimer_r1 <= timer_cnt [20];timer_r2 <= timer_r1;end
endreg [1:0] int_p;
reg [3:0] user_irq_req_i;always @(posedge axi_aclk) beginif (!axi_aresetn || !user_irq_en_o) beginint_p <= 4'd0;user_irq_req_i <= 4'd0;end else beginif (inter) beginint_p <= int_p + 1'b1;user_irq_req_i <= 4'd0;user_irq_req_i [int_p] <= 1'b1;endend
end
7.4 上位機中斷測試代碼
實現中斷程序的源碼 intr_event.c:
#include <Windows.h>
#include <assert.h>
#include <stdlib.h>
#include <stdio.h>
#include <strsafe.h>
#include <stdint.h>
#include <SetupAPI.h>
#include <INITGUID.H>
#include <WinIoCtl.h>
#include <io.h>
#include "xdma_public.h"#pragma comment (lib, "setupapi.lib")
#pragma warning (disable:4996)BYTE start_en;
HANDLE h_user;
HANDLE h_event0;
HANDLE h_event1;
HANDLE h_event2;
HANDLE h_event3;BYTE user_irq_ack[1];char base_path[MAX_PATH + 1] = "";static int verbose_msg(const char* const fmt, ...) {int ret = 0;va_list args;if (1) {va_start(args, fmt);ret = vprintf(fmt, args);va_end(args);}return ret;
}static BYTE* allocate_buffer(size_t size, size_t alignment) {if (size == 0) {size = 4;}if (alignment == 0) {SYSTEM_INFO sys_info;GetSystemInfo(&sys_info);alignment = sys_info.dwPageSize;}verbose_msg("Allocating host-side buffer of size %d, aligned to %d bytes\n", size, alignment);return (BYTE*)_aligned_malloc(size, alignment);
}static int get_devices(GUID guid, char* devpath, size_t len_devpath) {SP_DEVICE_INTERFACE_DATA device_interface;PSP_DEVICE_INTERFACE_DETAIL_DATA dev_detail;DWORD index;HDEVINFO device_info;wchar_t tmp[256];device_info = SetupDiGetClassDevs((LPGUID)&guid, NULL, NULL, DIGCF_PRESENT | DIGCF_DEVICEINTERFACE);if (device_info == INVALID_HANDLE_VALUE) {fprintf(stderr, "GetDevices INVALID_HANDLE_VALUE\n");exit(-1);}device_interface.cbSize = sizeof(SP_DEVICE_INTERFACE_DATA);for (index = 0; SetupDiEnumDeviceInterfaces(device_info, NULL, &guid, index, &device_interface); ++index) {ULONG detailLength = 0;if (!SetupDiGetDeviceInterfaceDetail(device_info, &device_interface, NULL, 0, &detailLength, NULL) &&GetLastError() != ERROR_INSUFFICIENT_BUFFER) {fprintf(stderr, "SetupDiGetDeviceInterfaceDetail - get length failed\n");break;}dev_detail = (PSP_DEVICE_INTERFACE_DETAIL_DATA)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, detailLength);if (!dev_detail) {fprintf(stderr, "HeapAlloc failed\n");break;}dev_detail->cbSize = sizeof(SP_DEVICE_INTERFACE_DETAIL_DATA);if (!SetupDiGetDeviceInterfaceDetail(device_info, &device_interface, dev_detail, detailLength, NULL, NULL)) {fprintf(stderr, "SetupDiGetDeviceInterfaceDetail - get detail failed\n");HeapFree(GetProcessHeap(), 0, dev_detail);break;}StringCchCopy(tmp, len_devpath, dev_detail->DevicePath);wcstombs(devpath, tmp, 256);HeapFree(GetProcessHeap(), 0, dev_detail);}SetupDiDestroyDeviceInfoList(device_info);return index;
}HANDLE open_devices(char* device_base_path, char* device_name, DWORD accessFlags) {char device_path[MAX_PATH + 1] = "";wchar_t device_path_w[MAX_PATH + 1];HANDLE h;verbose_msg("Device base path: %s\n", device_base_path);strcpy_s(device_path, sizeof(device_path), device_base_path);strcat_s(device_path, sizeof(device_path), device_name);verbose_msg("Device node: %s\n", device_name);mbstowcs(device_path_w, device_path, sizeof(device_path));h = CreateFile(device_path_w, accessFlags, 0, NULL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, NULL);if (h == INVALID_HANDLE_VALUE) {fprintf(stderr, "Error opening device, win32 error code: %ld\n", GetLastError());}return h;
}static int read_device(HANDLE device, long address, DWORD size, BYTE* buffer) {DWORD rd_size = 0;unsigned int transfers;unsigned int i;if (INVALID_SET_FILE_POINTER == SetFilePointer(device, address, NULL, FILE_BEGIN)) {fprintf(stderr, "Error setting file pointer, win32 error code: %ld\n", GetLastError());return -3;}transfers = (unsigned int)(size / MAX_BYTES_PER_TRANSFER);for (i = 0; i < transfers; i++) {if (!ReadFile(device, (void*)(buffer + i * MAX_BYTES_PER_TRANSFER), (DWORD)MAX_BYTES_PER_TRANSFER, &rd_size, NULL)) {return -1;}if (rd_size != MAX_BYTES_PER_TRANSFER) {return -2;}}if (!ReadFile(device, (void*)(buffer + i * MAX_BYTES_PER_TRANSFER), (DWORD)(size - i * MAX_BYTES_PER_TRANSFER), &rd_size, NULL)) {return -1;}if (rd_size != (size - i * MAX_BYTES_PER_TRANSFER)) {return -2;}return size;
}static int write_device(HANDLE device, long address, DWORD size, BYTE* buffer) {DWORD wr_size = 0;unsigned int transfers;unsigned int i;transfers = (unsigned int)(size / MAX_BYTES_PER_TRANSFER);if (INVALID_SET_FILE_POINTER == SetFilePointer(device, address, NULL, FILE_BEGIN)) {fprintf(stderr, "Error setting file pointer, win32 error code: %ld\n", GetLastError());return -3;}for (i = 0; i < transfers; i++) {if (!WriteFile(device, (void*)(buffer + i * MAX_BYTES_PER_TRANSFER), MAX_BYTES_PER_TRANSFER, &wr_size, NULL)) {return -1;}if (wr_size != MAX_BYTES_PER_TRANSFER) {return -2;}}if (!WriteFile(device, (void*)(buffer + i * MAX_BYTES_PER_TRANSFER), (DWORD)(size - i * MAX_BYTES_PER_TRANSFER), &wr_size, NULL)) {return -1;}if (wr_size != (size - i * MAX_BYTES_PER_TRANSFER)) {return -2;}return size;
}DWORD WINAPI thread_event0(LPVOID lpParam) {BYTE val0[1] = "";DWORD i = 0;char* device_name1 = "\\event_0";HANDLE h_event0 = open_devices(base_path, device_name1, GENERIC_READ);while (1) {if (start_en) {read_device(h_event0, 0, 1, val0); // wait for irqSleep(1);if (val0[0] == 1)printf("event_0 done!\n");elseprintf("event_0 timeout!\n");i++;}}CloseHandle(h_event0);return 0;
}DWORD WINAPI thread_event1(LPVOID lpParam) {BYTE val0[1] = "";DWORD i = 0;char* device_name1 = "\\event_1";HANDLE h_event1 = open_devices(base_path, device_name1, GENERIC_READ);while (1) {if (start_en) {read_device(h_event1, 0, 1, val0); // wait for irqSleep(1);if (val0[0] == 1)printf("event_1 done!\n");elseprintf("event_1 timeout!\n");i++;}}CloseHandle(h_event1);return 0;
}DWORD WINAPI thread_event2(LPVOID lpParam) {BYTE val0[1] = "";DWORD i = 0;char* device_name1 = "\\event_2";HANDLE h_event2 = open_devices(base_path, device_name1, GENERIC_READ);while (1) {if (start_en) {read_device(h_event2, 0, 1, val0); // wait for irqSleep(1);if (val0[0] == 1)printf("event_2 done!\n");elseprintf("event_2 timeout!\n");i++;}}CloseHandle(h_event2);return 0;
}DWORD WINAPI thread_event3(LPVOID lpParam) {BYTE val0[1] = "";DWORD i = 0;char* device_name1 = "\\event_3";HANDLE h_event3 = open_devices(base_path, device_name1, GENERIC_READ);while (1) {if (start_en) {read_device(h_event3, 0, 1, val0); // wait for irqSleep(1);if (val0[0] == 1)printf("event_3 done!\n");elseprintf("event_3 timeout!\n");i++;}}CloseHandle(h_event3);return 0;
}int __cdecl main(int argc, char* argv[]) {HANDLE h_event0;HANDLE h_event1;HANDLE h_event2;HANDLE h_event3;char* device_name = "\\user";DWORD num_devices = get_devices(GUID_DEVINTERFACE_XDMA, base_path, sizeof(base_path));verbose_msg("Devices found: %d\n", num_devices);if (num_devices < 1) {printf("No devices found\n");return -1;}h_user = open_devices(base_path, device_name, GENERIC_READ | GENERIC_WRITE);if (h_user == INVALID_HANDLE_VALUE) {fprintf(stderr, "Error opening device, win32 error code: %ld\n", GetLastError());return -1;}h_event0 = CreateThread(NULL, 0, thread_event0, NULL, 0, NULL);h_event1 = CreateThread(NULL, 0, thread_event1, NULL, 0, NULL);h_event2 = CreateThread(NULL, 0, thread_event2, NULL, 0, NULL);h_event3 = CreateThread(NULL, 0, thread_event3, NULL, 0, NULL);user_irq_ack[0] = 0xffff0000;write_device(h_user, 0x00004, 4, (BYTE*)user_irq_ack); // start irqstart_en = 1;printf("Start interrupts\n");WaitForSingleObject(h_event0, INFINITE);WaitForSingleObject(h_event1, INFINITE);WaitForSingleObject(h_event2, INFINITE);WaitForSingleObject(h_event3, INFINITE);user_irq_ack[0] = 0x00000000;write_device(h_user, 0x00004, 4, (BYTE*)user_irq_ack); // stop irqCloseHandle(h_user);CloseHandle(h_event0);CloseHandle(h_event1);CloseHandle(h_event2);CloseHandle(h_event3);return 0;
}
以下指令啟動中斷:
user_irq_ack[0] = 0xffff0000;
write_device(h_user, 0x00004, 4, (BYTE*)user_irq_ack);
以下指令關閉中斷:
user_irq_ack[0] = 0x00000000;
write_device(h_user, 0x00004, 4, (BYTE*)user_irq_ack);
以上程序設置了 4 個中斷事件,每個事件開啟了一個線程。當中斷等待時,線程處于掛起狀態;當中斷產生后,線程繼續執行。XDMA 最大支持 16 個中斷。
7.5 XDMA 中斷測試
執行 xdma_event.exe 程序。
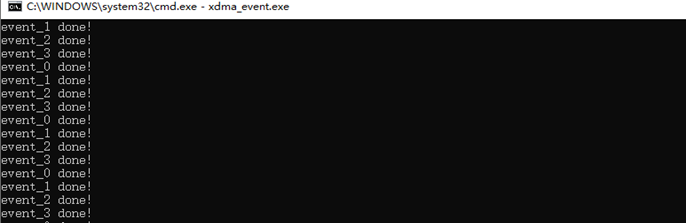
可以看到運行結果是 4 個中斷事件。實際上,XDMA 最大支持 16 個中斷事件。更多的中斷事件可以更好地發揮 CPU 多核多線程的性能。
查看 FPGA 抓取的波形信號:

到此,XDMA 的 PCIe 方案核心內容已經介紹完畢。Xilinx 官方提供的資料往往沒有細化,米聯客對驅動進行了修改,以更好地支持中斷。
8. PCIe 速度測試
8.1 測試碼表上位機程序設計
感謝網友貢獻的測試碼表控件源碼。筆者對其進行了修改,使其能夠適用于本次的例子。設計思路很簡單:在 Qt 中開啟了 2 個定時器,分別用于 h2c 和 c2h 通道,每 100 ms 定時器進行一次讀操作或寫操作。在 pcie_fun.c 文件中,有測試函數,完成傳輸測試后,將結果輸出到 myspeed 測速碼表控件。
以上代碼中,顯示速度的控件代碼是 myspeed.c 和 myspeed.h。關于 PCIe 通信的核心代碼是 pcie_fun.c 和 pcie_fun.h。詳細的實現過程可以閱讀程序源碼。
8.2 實驗結果
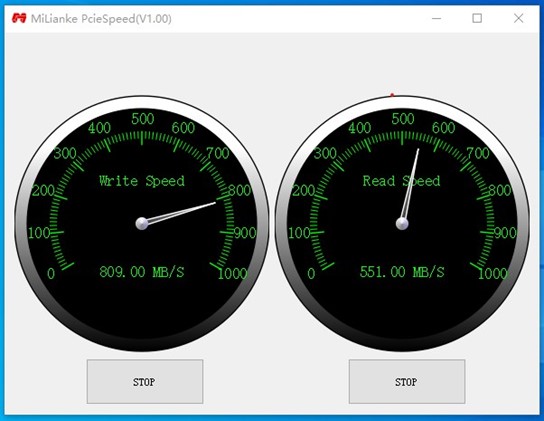
不同的板卡,PCIe 的最大帶寬不同,以實際為準。以下是 PCIEX2 2.0 的測速指標。
9. 內存讀寫測試
9.1 上位機程序設計
以下代碼中,on_TestDDR_clicked 是對 AXI4 接口的 DDR 或 BRAM 的測試,on_TestBAR_clicked 是對用戶 BAR 空間的測試。
void MainWindow::on_TestDDR_clicked() {unsigned int buf1[1024];unsigned int buf2[1024];unsigned int i = 0;unsigned int error_cnt = 0;for (i = 0; i < 1024; i++) {buf1[i] = i;}h2c_transfer(0, 1024 * 4, (unsigned char*)buf1);c2h_transfer(0, 1024 * 4, (unsigned char*)buf2);for (i = 0; i < 1024; i++) {if (buf1[i] != buf2[i]) error_cnt++;}if (error_cnt) {QString str = QString("%1 %2").arg("DDR bad data =").arg(error_cnt);ui->labelDDRPASS->setText(str);} else {m_pass1++;QString str = QString("%1 %2").arg("DDR PASS Times =").arg(m_pass1);ui->labelDDRPASS->setText(str);}
}void MainWindow::on_TestBAR_clicked() {unsigned int val;unsigned int i = 0;unsigned int error_cnt = 0;for (i = 0; i < 1024; i++) {user_write(0x10000 + i * 4, 4, (unsigned char*)&i);}for (i = 0; i < 1024; i++) {user_read(0x10000 + i * 4, 4, (unsigned char*)&val);if (i != val) error_cnt++;}if (error_cnt) {QString str = QString("%1 %2").arg("BAR bad data =").arg(error_cnt);ui->labelBARPASS->setText(str);} else {m_pass2++;QString str = QString("%1 %2").arg("BAR PASS Times =").arg(m_pass2);ui->labelBARPASS->setText(str);}
}
9.2 實驗結果
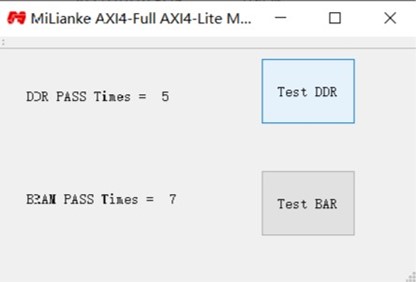
本文來自米聯客 (milianke),作者:米聯客 (milianke)。
登錄米聯客 (MiLianKe) FPGA 社區 - www.uisrc.com 觀看免費視頻課程、在線答疑解惑!
posted @ 2023-12-27 20:13 米聯客 (milianke)
linux 驅動框架與驅動開發實戰
開發者認證為什么要改昵稱呢 已于 2025-04-05 21:12:35 修改
一、Linux 驅動框架概述
Linux 驅動是操作系統內核與硬件設備之間的橋梁,它使得硬件設備能夠被操作系統識別和管理。Linux 內核提供了一套完善的驅動框架,開發者可以基于這些框架開發各種硬件設備的驅動程序。
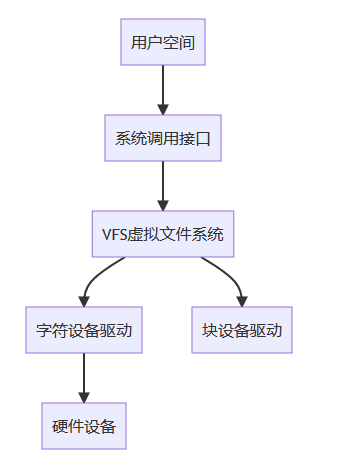
1.1 Linux 驅動的分類
Linux 驅動主要分為以下幾類:
- 字符設備驅動:以字節流形式進行數據讀寫,如鍵盤、鼠標等
- 塊設備驅動:以數據塊為單位進行讀寫,如硬盤、SSD 等
- 網絡設備驅動:用于網絡通信的設備,如網卡
- 其他特殊類型:如 USB 驅動、PCI 驅動等框架驅動
Linux 驅動模型分層:
1.2 Linux 驅動的基本框架
無論哪種類型的驅動,Linux 都提供了相應的框架和接口。一個典型的 Linux 驅動包含以下組成部分:
- 模塊加載和卸載函數:
module_init ()和module_exit () - 文件操作接口:
file_operations結構體 - 設備注冊與注銷:
register_chrdev ()等函數 - 中斷處理:
request_irq ()和中斷處理函數 - 內存管理:
kmalloc (),ioremap ()等函數 - 同步機制:自旋鎖、信號量、互斥鎖等
二、Linux 驅動關鍵 API 詳解
2.1 模塊相關 API
module_init (init_function); // 指定模塊加載時執行的函數
module_exit (exit_function); // 指定模塊卸載時執行的函數
MODULE_LICENSE ("GPL"); // 聲明模塊許可證
MODULE_AUTHOR ("Author"); // 聲明模塊作者
MODULE_DESCRIPTION ("Desc"); // 聲明模塊描述
2.2 字符設備驅動 API
// 注冊字符設備
int register_chrdev (unsigned int major, const char *name, const struct file_operations *fops);// 注銷字符設備
void unregister_chrdev (unsigned int major, const char *name);// 文件操作結構體
struct file_operations {struct module *owner;loff_t (*llseek) (struct file *, loff_t, int);ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);int (*open) (struct inode *, struct file *);int (*release) (struct inode *, struct file *);// 其他操作...
};
2.3 內存管理 API
// 內核內存分配
void *kmalloc (size_t size, gfp_t flags);
void kfree (const void *objp);// 物理地址映射
void *ioremap (phys_addr_t offset, unsigned long size);
void iounmap (void *addr);// 用戶空間與內核空間數據拷貝
unsigned long copy_to_user (void __user *to, const void *from, unsigned long n);
unsigned long copy_from_user (void *to, const void __user *from, unsigned long n);
2.4 中斷處理 API
// 申請中斷
int request_irq (unsigned int irq, irq_handler_t handler, unsigned long flags,const char *name, void *dev);// 釋放中斷
void free_irq (unsigned int irq, void *dev_id);// 中斷處理函數原型
irqreturn_t irq_handler (int irq, void *dev_id);
2.5 PCI 設備驅動 API
// PCI 設備 ID 表
static const struct pci_device_id ids [] = {{ PCI_DEVICE (VENDOR_ID, DEVICE_ID) },{ 0, }
};
MODULE_DEVICE_TABLE (pci, ids);// PCI 驅動結構體
static struct pci_driver pci_driver = {.name = "xdma_driver",.id_table = ids,.probe = xdma_probe,.remove = xdma_remove,// 其他回調...
};// 注冊 PCI 驅動
pci_register_driver (&pci_driver);// 注銷 PCI 驅動
pci_unregister_driver (&pci_driver);
三、Xilinx XDMA 驅動開發詳解
3.1 XDMA 概述
Xilinx DMA (XDMA) 是一種高性能的 DMA 控制器,用于在 FPGA 和主機內存之間傳輸數據。XDMA 驅動通常作為 PCIe 設備驅動實現,支持 DMA 傳輸、中斷處理等功能。
其實現 DMA 傳輸流程如下:
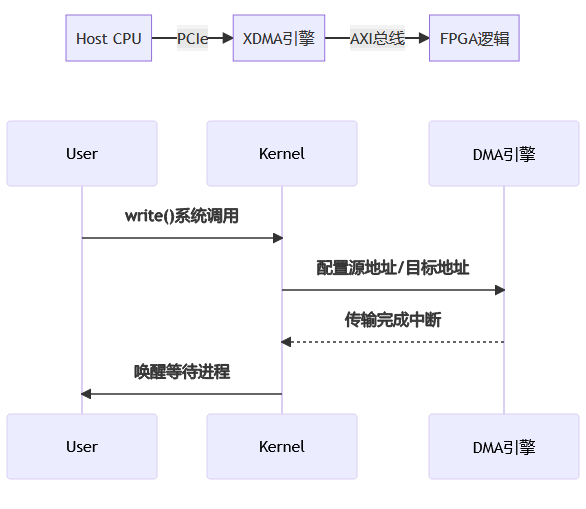
User Kernel DMA 引擎 write () 系統調用 配置源地址 / 目標地址 傳輸完成中斷 喚醒等待進程 User Kernel DMA 引擎
3.2 XDMA 驅動開發步驟
步驟 1:定義 PCI 設備 ID
#define PCI_VENDOR_ID_XILINX 0x10ee
#define PCI_DEVICE_ID_XDMA 0x7028static const struct pci_device_id xdma_pci_ids [] = {{ PCI_DEVICE (PCI_VENDOR_ID_XILINX, PCI_DEVICE_ID_XDMA) },{ 0, }
};
MODULE_DEVICE_TABLE (pci, xdma_pci_ids);
步驟 2:定義驅動主結構體
struct xdma_dev {struct pci_dev *pdev;void __iomem *bar [MAX_BARS]; // PCI BAR 空間映射int irq; // 中斷號struct cdev cdev; // 字符設備dev_t devno; // 設備號struct dma_chan *dma_chan; // DMA 通道// 其他設備特定數據...
};
步驟 3:實現 PCI probe 函數
PCI 設備探測流程:
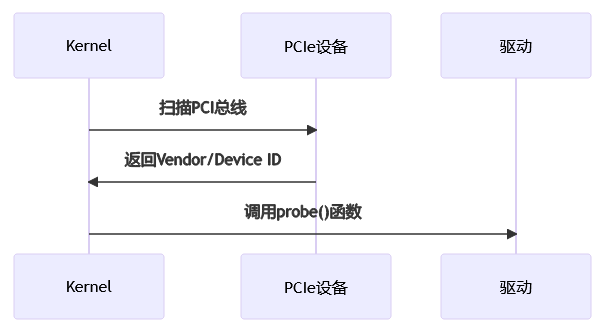
具體探測函數(probe)實現:
static int xdma_probe (struct pci_dev *pdev, const struct pci_device_id *id)
{struct xdma_dev *xdev;int err, i;// 1. 分配設備結構體xdev = devm_kzalloc (&pdev->dev, sizeof (*xdev), GFP_KERNEL);if (!xdev)return -ENOMEM;xdev->pdev = pdev;pci_set_drvdata (pdev, xdev);// 2. 使能 PCI 設備err = pci_enable_device (pdev);if (err) {dev_err (&pdev->dev, "Failed to enable PCI device\n");goto fail;}// 3. 請求 PCI 資源err = pci_request_regions (pdev, "xdma");if (err) {dev_err (&pdev->dev, "Failed to request PCI regions\n");goto disable_device;}// 4. 映射 BAR 空間for (i = 0; i < MAX_BARS; i++) {if (!pci_resource_len (pdev, i))continue;xdev->bar [i] = pci_iomap (pdev, i, pci_resource_len (pdev, i));if (!xdev->bar [i]) {dev_err (&pdev->dev, "Failed to map BAR% d\n", i);err = -ENOMEM;goto release_regions;}}// 5. 設置 DMA 掩碼err = pci_set_dma_mask (pdev, DMA_BIT_MASK (64));if (err) {err = pci_set_dma_mask (pdev, DMA_BIT_MASK (32));if (err) {dev_err (&pdev->dev, "No suitable DMA available\n");goto unmap_bars;}}// 6. 申請中斷xdev->irq = pdev->irq;err = request_irq (xdev->irq, xdma_irq_handler, IRQF_SHARED, "xdma", xdev);if (err) {dev_err (&pdev->dev, "Failed to request IRQ\n");goto unmap_bars;}// 7. 初始化 DMA 引擎err = xdma_init_dma (xdev);if (err)goto free_irq;// 8. 注冊字符設備err = xdma_setup_cdev (xdev);if (err)goto deinit_dma;dev_info (&pdev->dev, "XDMA driver loaded successfully\n");return 0;// 錯誤處理...
}// 初始化 DMA 引擎
static int xdma_init_dma (struct xdma_dev *xdev)
{dma_cap_mask_t mask;dma_cap_zero (mask);dma_cap_set (DMA_MEMCPY, mask);xdev->dma_chan = dma_request_channel (mask, NULL, NULL);if (!xdev->dma_chan) {dev_err (&xdev->pdev->dev, "Failed to get DMA channel\n");return -ENODEV;}return 0;
}// 設置字符設備
static int xdma_setup_cdev (struct xdma_dev *xdev)
{int err;dev_t devno;err = alloc_chrdev_region (&devno, 0, 1, "xdma");if (err < 0) {dev_err (&xdev->pdev->dev, "Failed to allocate device number\n");return err;}xdev->devno = devno;cdev_init (&xdev->cdev, &xdma_fops);xdev->cdev.owner = THIS_MODULE;err = cdev_add (&xdev->cdev, devno, 1);if (err) {dev_err (&xdev->pdev->dev, "Failed to add cdev\n");unregister_chrdev_region (devno, 1);return err;}return 0;
}
步驟 4:實現文件操作接口
static const struct file_operations xdma_fops = {.owner = THIS_MODULE,.open = xdma_open,.release = xdma_release,.read = xdma_read,.write = xdma_write,.unlocked_ioctl = xdma_ioctl,.llseek = no_llseek,
};static int xdma_open (struct inode *inode, struct file *filp)
{struct xdma_dev *xdev = container_of (inode->i_cdev, struct xdma_dev, cdev);filp->private_data = xdev;return 0;
}static int xdma_release (struct inode *inode, struct file *filp)
{filp->private_data = NULL;return 0;
}static ssize_t xdma_read (struct file *filp, char __user *buf, size_t count, loff_t *f_pos)
{struct xdma_dev *xdev = filp->private_data;// 實現 DMA 讀取操作...return count;
}static ssize_t xdma_write (struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{struct xdma_dev *xdev = filp->private_data;// 實現 DMA 寫入操作...return count;
}static long xdma_ioctl (struct file *filp, unsigned int cmd, unsigned long arg)
{struct xdma_dev *xdev = filp->private_data;switch (cmd) {case XDMA_IOCTL_START_DMA:// 啟動 DMA 傳輸break;case XDMA_IOCTL_STOP_DMA:// 停止 DMA 傳輸break;case XDMA_IOCTL_GET_STATUS:// 獲取 DMA 狀態break;default:return -ENOTTY;}return 0;
}
步驟 5:實現中斷處理
static irqreturn_t xdma_irq_handler (int irq, void *dev_id)
{struct xdma_dev *xdev = dev_id;u32 status;// 讀取中斷狀態寄存器status = ioread32 (xdev->bar [0] + XDMA_IRQ_STATUS_REG);if (status & XDMA_IRQ_DONE) {// DMA 傳輸完成中斷complete (&xdev->dma_complete);}if (status & XDMA_IRQ_ERROR) {// DMA 錯誤中斷dev_err (&xdev->pdev->dev, "DMA error occurred\n");}// 清除中斷狀態iowrite32 (status, xdev->bar [0] + XDMA_IRQ_STATUS_REG);return IRQ_HANDLED;
}
步驟 6:實現 DMA 傳輸
static int xdma_do_transfer (struct xdma_dev *xdev, dma_addr_t src, dma_addr_t dst, size_t len)
{struct dma_async_tx_descriptor *tx;struct dma_device *dma_dev = xdev->dma_chan->device;enum dma_ctrl_flags flags = DMA_CTRL_ACK | DMA_PREP_INTERRUPT;dma_cookie_t cookie;int err;// 準備 DMA 描述符tx = dma_dev->device_prep_dma_memcpy (xdev->dma_chan, dst, src, len, flags);if (!tx) {dev_err (&xdev->pdev->dev, "Failed to prepare DMA descriptor\n");return -EIO;}tx->callback = xdma_dma_callback;tx->callback_param = xdev;// 提交 DMA 傳輸cookie = dmaengine_submit (tx);err = dma_submit_error (cookie);if (err) {dev_err (&xdev->pdev->dev, "Failed to submit DMA transfer\n");return err;}// 觸發 DMA 傳輸dma_async_issue_pending (xdev->dma_chan);// 等待傳輸完成if (!wait_for_completion_timeout (&xdev->dma_complete, msecs_to_jiffies (1000))) {dev_err (&xdev->pdev->dev, "DMA transfer timeout\n");dmaengine_terminate_all (xdev->dma_chan);return -ETIMEDOUT;}return 0;
}static void xdma_dma_callback (void *data)
{struct xdma_dev *xdev = data;complete (&xdev->dma_complete);
}
步驟 7:實現 remove 函數
static void xdma_remove (struct pci_dev *pdev)
{struct xdma_dev *xdev = pci_get_drvdata (pdev);int i;// 1. 移除字符設備cdev_del (&xdev->cdev);unregister_chrdev_region (xdev->devno, 1);// 2. 釋放 DMA 資源if (xdev->dma_chan)dma_release_channel (xdev->dma_chan);// 3. 釋放中斷free_irq (xdev->irq, xdev);// 4. 取消 BAR 空間映射for (i = 0; i < MAX_BARS; i++) {if (xdev->bar [i])pci_iounmap (pdev, xdev->bar [i]);}// 5. 釋放 PCI 資源pci_release_regions (pdev);// 6. 禁用 PCI 設備pci_disable_device (pdev);// 7. 釋放設備結構體devm_kfree (&pdev->dev, xdev);dev_info (&pdev->dev, "XDMA driver unloaded\n");
}
步驟 8:定義 PCI 驅動結構體并注冊
static struct pci_driver xdma_driver = {.name = "xdma",.id_table = xdma_pci_ids,.probe = xdma_probe,.remove = xdma_remove,
};static int __init xdma_init (void)
{return pci_register_driver (&xdma_driver);
}static void __exit xdma_exit (void)
{pci_unregister_driver (&xdma_driver);
}module_init (xdma_init);
module_exit (xdma_exit);MODULE_LICENSE ("GPL");
MODULE_AUTHOR ("Your Name");
MODULE_DESCRIPTION ("Xilinx XDMA Driver");
3.3 步驟總結
上文以 xilinx XDMA 為例介紹了 Linux PCI 設備驅動開發步驟,總結成流程圖如下:
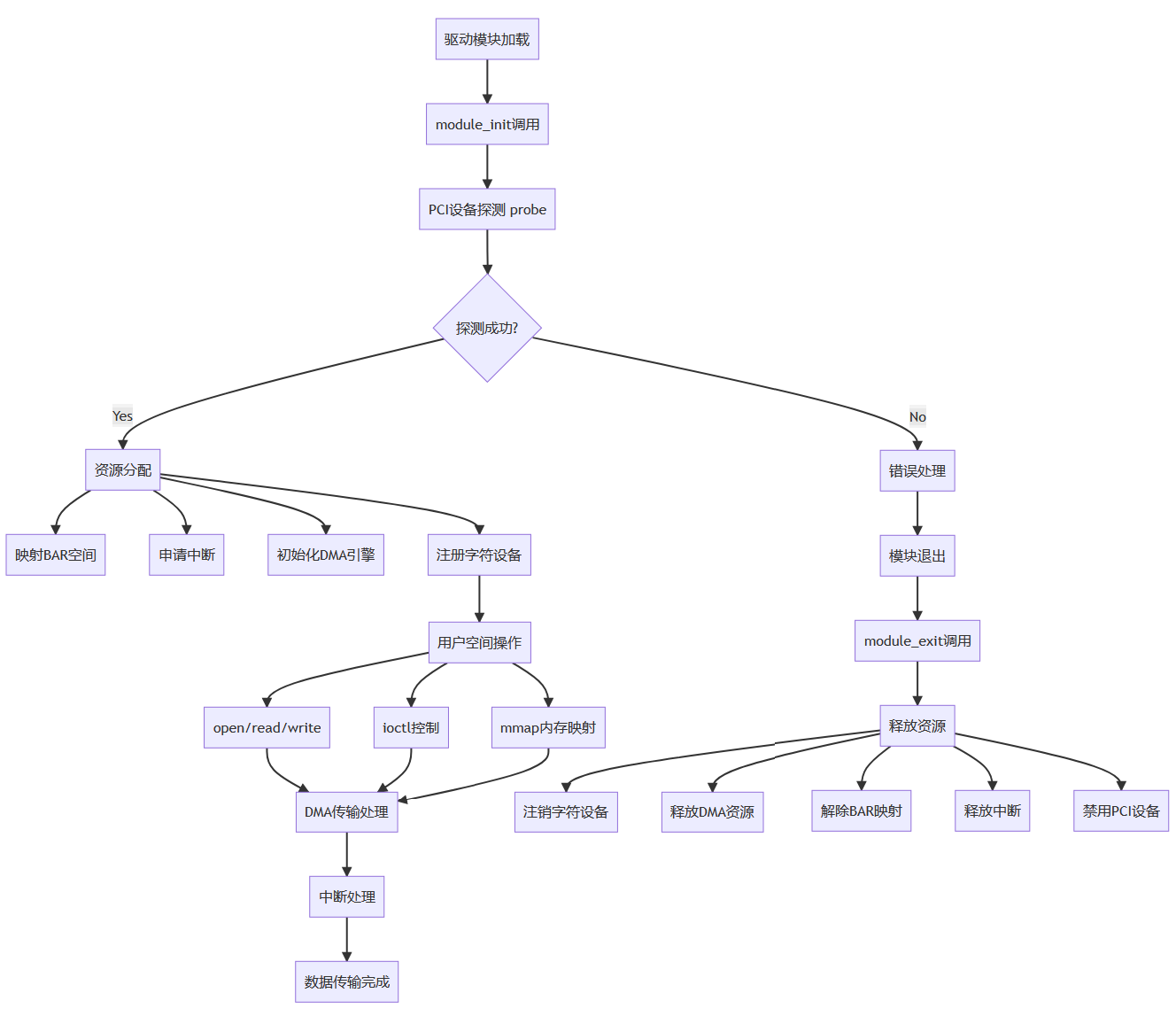
四、XDMA 驅動測試與調試
4.1 加載驅動模塊
# 加載驅動
sudo insmod xdma.ko# 查看加載的模塊
lsmod | grep xdma# 查看內核日志
dmesg | tail
4.2 測試 DMA 傳輸
可以使用簡單的用戶空間程序測試 DMA 功能:
//test_xdma.c
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/ioctl.h>#define XDMA_DEV "/dev/xdma"
#define BUF_SIZE (1024 * 1024) // 1MBint main ()
{int fd = open (XDMA_DEV, O_RDWR);if (fd < 0) {perror ("Failed to open device");return -1;}// 分配測試緩沖區char *src = malloc (BUF_SIZE);char *dst = malloc (BUF_SIZE);if (!src || !dst) {perror ("Failed to allocate buffers");close (fd);return -1;}// 填充源緩沖區memset (src, 0xAA, BUF_SIZE);memset (dst, 0, BUF_SIZE);// 寫入數據到設備ssize_t written = write (fd, src, BUF_SIZE);printf ("Written % zd bytes to device\n", written);// 從設備讀取數據ssize_t readed = read (fd, dst, BUF_SIZE);printf ("Read % zd bytes from device\n", readed);// 驗證數據if (memcmp (src, dst, BUF_SIZE) {printf ("Data verification failed!\n");} else {printf ("Data verification passed!\n");}free (src);free (dst);close (fd);return 0;
}
4.3 常見問題調試
-
PCI 設備未識別:
- 檢查
lspci -nn確認設備 ID 是否正確 - 確認內核配置中啟用了 PCI 支持
- 檢查
-
DMA 傳輸失敗:
- 檢查 DMA 掩碼設置
- 確認物理地址是否正確
- 檢查 DMA 引擎是否支持所需操作
-
中斷不觸發:
- 確認中斷號是否正確
- 檢查中斷狀態寄存器
- 確認中斷處理函數已正確注冊
五、性能優化技巧
5.1 使用分散 / 聚集 DMA
static int xdma_sg_transfer (struct xdma_dev *xdev, struct scatterlist *sg_src,struct scatterlist *sg_dst,int sg_count)
{struct dma_async_tx_descriptor *tx;struct dma_device *dma_dev = xdev->dma_chan->device;enum dma_ctrl_flags flags = DMA_CTRL_ACK | DMA_PREP_INTERRUPT;dma_cookie_t cookie;int err;tx = dma_dev->device_prep_dma_sg (xdev->dma_chan, sg_dst, sg_count,sg_src, sg_count,flags);if (!tx) {dev_err (&xdev->pdev->dev, "Failed to prepare SG DMA descriptor\n");return -EIO;}tx->callback = xdma_dma_callback;tx->callback_param = xdev;cookie = dmaengine_submit (tx);err = dma_submit_error (cookie);if (err) {dev_err (&xdev->pdev->dev, "Failed to submit SG DMA transfer\n");return err;}dma_async_issue_pending (xdev->dma_chan);if (!wait_for_completion_timeout (&xdev->dma_complete, msecs_to_jiffies (1000))) {dev_err (&xdev->pdev->dev, "SG DMA transfer timeout\n");dmaengine_terminate_all (xdev->dma_chan);return -ETIMEDOUT;}return 0;
}
5.2 實現零拷貝
static int xdma_mmap (struct file *filp, struct vm_area_struct *vma)
{struct xdma_dev *xdev = filp->private_data;unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;unsigned long size = vma->vm_end - vma->vm_start;int ret;// 將 BAR 空間映射到用戶空間if (offset >= pci_resource_len (xdev->pdev, 0) || size > pci_resource_len (xdev->pdev, 0) - offset) {return -EINVAL;}ret = remap_pfn_range (vma, vma->vm_start,(pci_resource_start (xdev->pdev, 0) + offset) >> PAGE_SHIFT,size, vma->vm_page_prot);if (ret)return -EAGAIN;return 0;
}
5.3 使用 DMA 池
// 初始化 DMA 池
xdev->dma_pool = dma_pool_create ("xdma_pool", &xdev->pdev->dev,POOL_SIZE, POOL_ALIGN, 0);
if (!xdev->dma_pool) {dev_err (&xdev->pdev->dev, "Failed to create DMA pool\n");return -ENOMEM;
}// 從 DMA 池分配內存
void *buf = dma_pool_alloc (xdev->dma_pool, GFP_KERNEL, &dma_handle);
if (!buf) {dev_err (&xdev->pdev->dev, "Failed to allocate from DMA pool\n");return -ENOMEM;
}// 釋放 DMA 池內存
dma_pool_free (xdev->dma_pool, buf, dma_handle);// 銷毀 DMA 池
dma_pool_destroy (xdev->dma_pool);
六、總結
本文詳細介紹了 Linux 驅動框架和關鍵 API,并以 Xilinx XDMA 驅動為例,展示了 Linux 驅動開發的完整流程。關鍵點包括:
- 理解 Linux 驅動框架:掌握字符設備、塊設備和網絡設備驅動的基本結構
- 熟悉關鍵 API:模塊加載、文件操作、內存管理、中斷處理等核心 API
- PCI 驅動開發:從設備發現到資源管理的完整流程
- DMA 傳輸實現:包括標準 DMA 和分散 / 聚集 DMA
- 驅動調試技巧:日志分析、用戶空間測試程序等
通過 XDMA 驅動的實例,我們可以看到 Linux 驅動開發需要綜合考慮硬件特性、內核 API 和性能優化等多個方面。希望本文能為 Linux 驅動開發者提供有價值的參考。
via:
-
FPGA(基于 xilinx)中 PCIe 介紹以及 IP 核 XDMA 的使用_xilinx pcie-CSDN 博客
https://blog.csdn.net/Njustxiaobai/article/details/132874083 -
Xilinx DMA 的幾種方式與架構 - Hello-FPGA - 博客園
https://www.cnblogs.com/xingce/p/16386108.html -
關于 DMA 環通實驗的 SDK 部分代碼理解_sdk dma-CSDN 博客
https://blog.csdn.net/2301_80250829/article/details/137629092 -
XDMA 傳輸模式_xdma 數據傳輸原理 - CSDN 博客
https://blog.csdn.net/a8039974/article/details/146314970 -
Xilinx XDMA 說明和測試 - MM-CSDN 博客
https://blog.csdn.net/weixin_43956013/article/details/128608551 -
xdma 使用小結 - PCIe 與 FPGA 通信:XDMA IP 核配置與 AXI 總線解析 - CSDN 博客
https://blog.csdn.net/mu_guang_/article/details/108951919 -
20 基于 XDMA 實現 PCIE 通信方案 - 米聯客 (milianke) - 博客園
https://www.cnblogs.com/milianke/p/17931352.html -
[實戰] linux 驅動框架與驅動開發實戰 - CSDN 博客
https://blog.csdn.net/jz_ddk/article/details/147015183 -
Xilinx 中 PCIe 簡介以及 IP 核 XDMA 的使用 - CSDN 博客
https://blog.csdn.net/bingcheby/article/details/136186955
— -
【DMA 使用指南】設計說明 | 立創開發板技術文檔中心
https://wiki.lckfb.com/zh-hans/hspi-d133ebs/rtos-sdk/system/dma-operating-guide/design-description.html -
GitHub - Xilinx/dma_ip_drivers: Xilinx QDMA IP Drivers
https://github.com/Xilinx/dma_ip_drivers -
PCIe 基礎篇——PCIe 傳輸速率計算-CSDN博客
https://blog.csdn.net/u013253075/article/details/108926633 -
PCIe speed table (from gen 1 to gen 6) – NAS Compares
https://nascompares.com/answer/what-is-pcie-speed-from-gen1-to-gen6/









 力扣100 10.和為K的子數組(前綴和+哈希))

,向進程發送發送信號)

)

一維前綴和, 藍橋杯)
)


