(1)筆者在時間有限的情況下,想要多積累一些自身課題之外的新文獻、新知識,所以開了這一篇文章。
(2)想通過將文獻喂給大模型,并向大模型提問的方式來快速理解文獻的重要信息(如基礎idea、contribution、大致方法等)。
(3)計劃周更4-5篇文獻。
(4)文章內容大多由AI產生,經筆者梳理而成。如果有誤,敬請批評指正。
文章目錄
- 一、Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian Splatting
- 二、DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation
- 三、Sample2SQL: A Visual Interface for Querying Risky Enterprises
- 四、ReLive: Walking into Virtual Reality Spaces from Video Recordings of One’s Past Can Increase the Experiential Detail and Affect of Autobiographical Memories
一、Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian Splatting
作者:Boying Li, Zhixi Cai, Yuan-Fang Li, Ian Reid, and Hamid Rezatofighi
機構:Monash & MBZUAI
原文鏈接:https://arxiv.org/abs/2409.12518
代碼鏈接:https://github.com/LeeBY68/Hier-SLAM
發表:ICRA 2025
摘要:
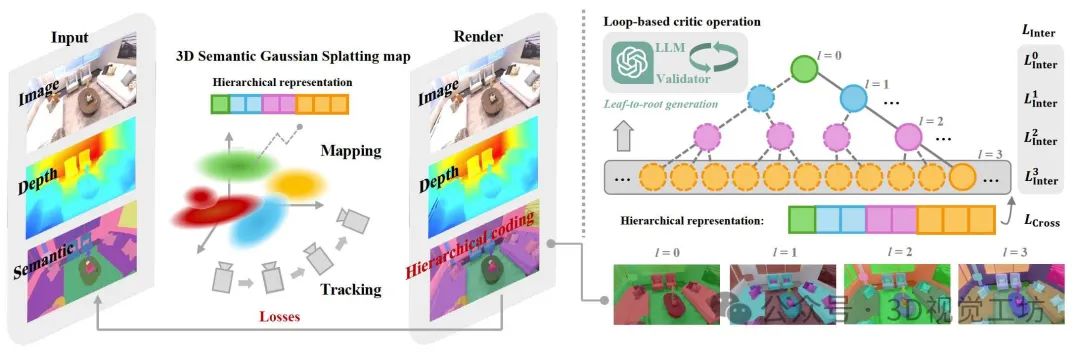
本文提出了 Hier-SLAM,這是一種基于語義的三維高斯濺射 SLAM 方法,具備全新的層級類別表示方式,能夠實現精準的全局三維語義建圖、良好的擴展性,以及三維世界中顯式的語義標簽預測。隨著環境復雜度的增加,語義 SLAM 系統的參數量急劇上升,使得場景理解變得尤為困難且成本高昂。
為了解決這一問題,本文引入了一種緊湊的層級語義表示,將語義信息有效嵌入到 3D Gaussian Splatting 中,并借助大語言模型(LLM)的能力構建結構化語義編碼。此外,本文設計了一種新的語義損失函數,通過層內(inter-level)和跨層(cross-level)聯合優化,進一步提升層級語義信息的學習效果。本文還對整個 SLAM 系統進行了全面優化,顯著提升了追蹤建圖性能及運行速度。
Hier-SLAM 在建圖和定位精度方面均超越現有的稠密 SLAM 方法,并在運行速度上實現了 2 倍加速。同時,在語義渲染性能上也達到了與現有方法相當的水平,同時在存儲開銷與訓練時間方面大幅下降。令人印象深刻的是,該系統的渲染速度可達每秒 2000 幀(含語義)或 3000 幀(無語義)。尤其重要的是,Hier-SLAM 首次展現了在超過 500 類語義場景中仍能高效運行的能力,充分體現了其強大的擴展性。
1. 什么是語義SLAM系統呢?
語義SLAM(Semantic SLAM)是同時定位與建圖(SLAM)技術的升級版,它不僅構建環境的幾何地圖,還能識別并標注地圖中物體的語義信息(如“椅子”“墻壁”“行人”),讓機器真正“理解”周圍場景。
2. 本文是如何實現層級語義表示與3D高斯潑濺的融合的?
(1)層級樹結構構建:
(i)語義樹定義:將語義類別組織為樹狀結構 G=(V,E),其中節點 V 表示不同層級的語義類(如“背景→結構→平面→墻”),邊 E 表示類別的從屬關系。
(ii)LLM輔助生成:
- 輸入一組語義標簽(如ScanNet的550類),利用LLM(如GPT-4)自底向上迭代聚類,生成層次結構。
- 通過循環校驗機制(Loop-based Critic)修正LLM輸出:對比LLM生成的聚類結果與輸入標簽,剔除無關類別(Unseen
Classes)并補全遺漏節點(Omitted Nodes),直至所有標簽被正確歸類。
(2)緊湊編碼設計:
每個3D高斯 primitive 的語義嵌入 h 由各層級嵌入h’拼接而成。

(3)語義優化策略:
- 層級內損失(Inter-level Loss):每層單獨計算交叉熵損失,確保層級內分類正確性。
- 跨層級損失(Cross-level Loss):通過共享線性層 F 將層級編碼映射為扁平概率分布,與真實標簽計算全局交叉熵損失,保證層級間一致性。
通俗易懂的解釋:
這篇文章的“語義壓縮”方法,可以類比為整理一個雜亂的文件柜:
步驟1:用AI給文件分類(LLM建樹)
把一堆未分類的文件(如550種物體標簽)交給AI(如ChatGPT),讓它按“大類→子類”自動整理。例如:第一層:“家具” vs “電器” 第二層:“家具”下分“椅子”“桌子”……
AI可能分錯,所以加了自動修正程序:檢查遺漏的標簽(如“漏了臺燈”),重新讓AI補分,直到所有文件歸位。
步驟2:給每個物體貼層級標簽(緊湊編碼)
以前:每個物體直接標記具體名稱(如“辦公椅”),需要大量標簽。
現在:改為層級路徑編碼(如“家具/椅子/辦公椅”),只需記錄每層的選擇(如1-2-3),大幅節省空間。
步驟3:雙重檢查(層級優化)
逐層檢查:確保“椅子”確實屬于“家具”。
整體檢查:最終生成的標簽(如“辦公椅”)要與真實名稱一致。
效果:
原本存1000種物體需要1000個標簽,現在只需20個數字編碼(類似壓縮成文件夾路徑)。
機器人看到“辦公椅”時,既能知道它是“椅子”,也能明白它屬于“家具”,適合高層決策(如“避開所有家具”)。
3.本文的核心貢獻是什么?
(1)層次化語義表示:提出一種樹狀層次結構編碼語義信息,利用大語言模型(LLM)生成語義類別的層次關系(如“背景→結構→平面→墻”),將語義信息壓縮為緊湊的符號編碼。例如,10層二叉樹可覆蓋1024個類別,僅需20維編碼(每層2維Softmax)。通過幾何與語義屬性聯合優化,構建多級樹結構,顯著減少存儲需求(相比扁平表示降低66%)。
(2)層次化語義損失函數:設計跨層級(Cross-level)和層級內(Inter-level)聯合優化損失,結合交叉熵損失,實現從粗到細的語義理解。
(3)高效SLAM系統:在3D高斯潑濺框架中集成層次化語義表示,優化跟蹤(Tracking)與建圖(Mapping)模塊。系統在保持高精度(ScanNet數據集上ATE RMSE為3.2cm)的同時,實現2000 FPS(帶語義)/3000 FPS(無語義)的實時渲染速度,存儲需求降低至910.5MB(原需2.7GB)。
(4)擴展性驗證:在包含550個語義類別的ScanNet數據集中,通過LLM輔助的層次化編碼將語義參數壓縮7倍,首次實現復雜場景的高效語義理解。
二、DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation

作者:Bangbang Yang, Wenqi Dong, Lin Ma, Wenbo Hu, Xiao Liu, Zhaopeng Cui, Yuewen Ma
機構:(1)PICO, ByteDance (2)State Key Lab of CAD&CG, Zhejiang University
文章鏈接:https://arxiv.org/abs/2310.13119
項目鏈接:https://ybbbbt.com/publication/dreamspace/
發表:IEEE VR 2024
摘要:
基于擴散模型的方法在二維媒體生成領域已取得顯著成功,然而在三維空間應用(如XR/VR)中實現同等水平的場景級網格紋理生成仍面臨挑戰,主要受限于三維幾何結構的復雜性及沉浸式自由視角渲染的技術要求。本文提出了一種創新的室內場景紋理生成框架,通過文本驅動生成具有精細細節與真實空間一致性的紋理。其核心思想是:首先從場景中心視角生成風格化的360°全景紋理,繼而通過修復與模仿技術將其擴散至其他區域。為確保紋理與場景的語義對齊,我們開發了一種新穎的雙重紋理對齊機制,采用由粗到細的全景紋理生成方法,同時考量場景的幾何特征與紋理線索。針對紋理傳播過程中的復雜幾何干擾,我們設計了分離式處理策略:先在置信區域執行紋理修復,再通過隱式模仿網絡合成被遮擋區域與微細結構的紋理。大量實驗及真實室內場景的沉浸式VR應用證明,該方法能生成高質量紋理,并為VR頭顯設備提供引人入勝的體驗。
1. 文章簡介
本文《DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation》提出了一種創新的文本驅動室內場景紋理生成框架,旨在解決三維空間應用中場景級網格紋理合成的關鍵挑戰。針對現有擴散模型在2D媒體生成的成功難以遷移到3D場景的問題,作者提出以下技術貢獻:
(1)全景紋理生成:采用自上而下的流程,首先生成中心視點的360°風格化全景紋理,通過改進的潛在擴散模型(LDM)實現粗到細的生成策略,結合非對稱環形填充和分塊擴散技術保障高分辨率與無縫投影。
(2)雙重紋理對齊:提出風格優先與對齊優先的雙通道紋理生成機制,通過深度邊緣感知的泊松混合解決幾何-紋理錯位問題,在保持風格質量的同時提升幾何一致性。
(3)全場景紋理傳播:設計分區域處理策略,對可見區域采用置信擴散修復,對遮擋/微小結構區域采用基于坐標的隱式紋理模仿網絡(MLP),實現紋理的空間連貫性填充。
實驗表明,該方法在真實場景數據集(DreamSpot/Replica)上顯著優于StyleMesh、TEXTure等方法(CLIP分數提升14.4%,美學評分提升9.6%),并通過VR應用驗證了其在頭顯設備中的沉浸式體驗。局限性包括對PBR材質支持不足及超大場景適配性問題。
通俗易懂版介紹
這篇文章開發了一個叫DreamSpace的"AI裝修神器",能用文字描述自動給3D房間模型換上夢幻風格的墻紙、地板和家具貼圖。比如輸入"星空主題",系統就會把房間變成銀河效果,沙發、電視等物品還能保持原有形狀但變成星空紋理。
核心技術有三招:
(1)全景照片生成:先站在房間中心,用AI生成一張包裹整個房間的360°全景風格圖(類似手機全景拍照,但內容是AI畫的星空/森林等主題)。
(2)智能對齊:通過"雙保險"策略讓貼圖完美貼合家具邊緣,避免出現扭曲或錯位。
(3)死角填充:對于柜子縫隙、沙發底部等死角,AI會參考已生成部分智能補全,而不是簡單復制。
實際效果:
(1)比傳統方法貼圖更精準,VR眼鏡中觀看時不會出現接縫或穿幫。
(2)支持實時渲染,生成的3D房間能直接導入VR設備漫游。
(3)目前局限是不能做金屬反光等復雜材質,超大教堂類場景也暫不支持。
2. 介紹一下這篇文章中的framework
DreamSpace 是一個基于擴散模型(Diffusion Model)的 文本驅動室內場景紋理生成框架,旨在為 3D 場景網格(Mesh)生成高質量、語義一致且空間連貫的紋理。其核心流程分為三個階段:
(1)全景紋理生成(Panoramic Texture Generation)
- 輸入:用戶文本描述(如“星空主題”)+ 真實場景的 3D 網格(帶初始紋理和幾何)。
- 方法:
粗到細生成:先用低分辨率全景擴散模型生成基礎結構,再通過超分辨率提升細節。
雙重紋理對齊(Dual Texture Alignment):生成“風格優先”和“對齊優先”兩種紋理,并用深度邊緣感知的泊松混合(Poisson Blending)優化幾何貼合。 - 輸出:高分辨率 360° 全景紋理(Equirectangular 投影)。
(2)初始紋理投影(Initial Texture Projection)
- 將全景紋理通過 UV 映射 投影到 3D 網格的可見部分,形成初步風格化場景。
(3)全場景紋理傳播(Holistic Texture Propagation)
- 置信區域修復(Confidential Inpainting):在少量新視角下,用擴散模型修復未被初始全景覆蓋的可見區域。
- 隱式紋理模仿(Implicit Texture Imitating):對遮擋區域(如家具底部、墻壁縫隙),訓練一個 MLP 網絡 從已風格化區域學習顏色映射,預測合理紋理。
- 最終輸出:完整 UV 紋理貼圖,可直接用于 3D 引擎(如 Unity/Unreal)或 VR 設備。
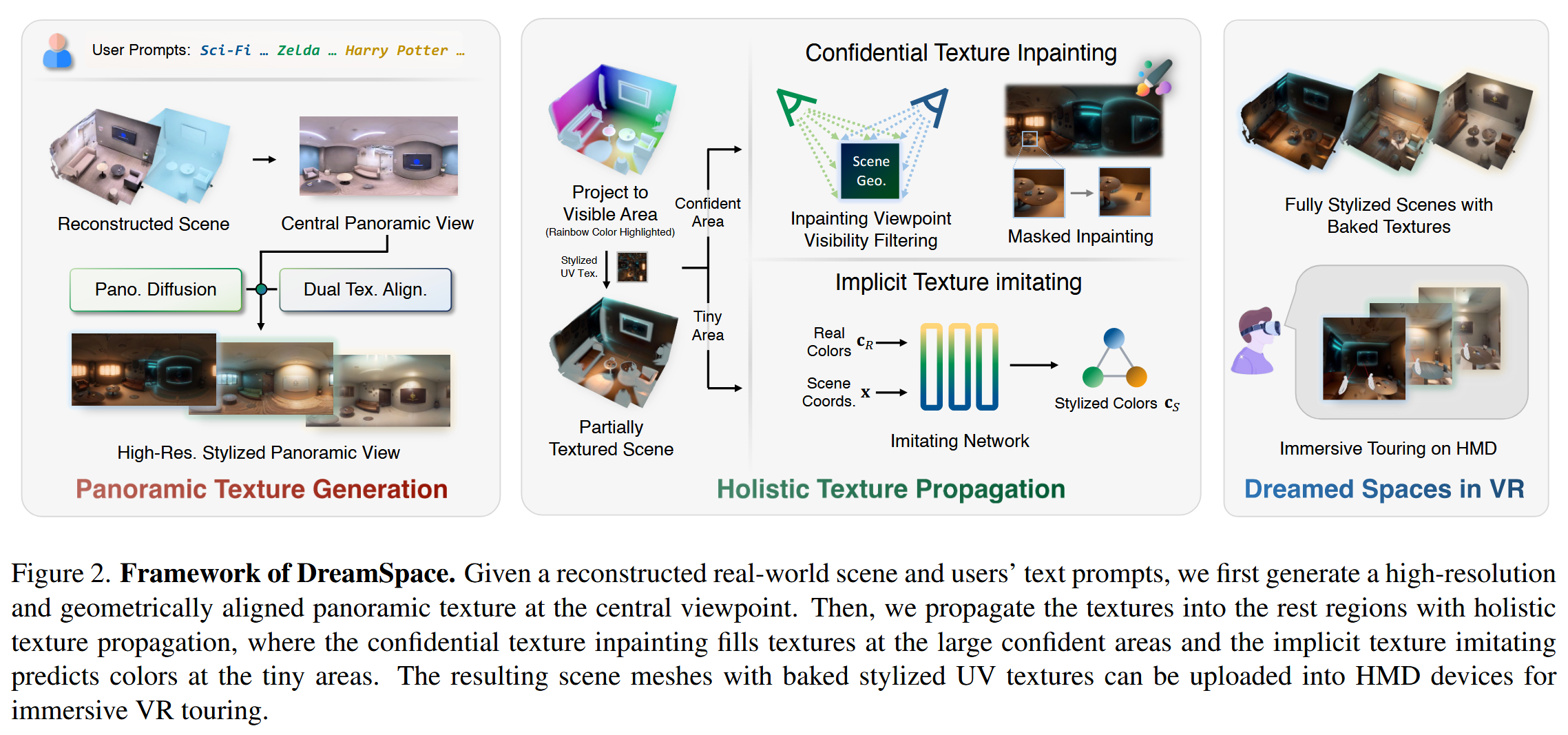
給定一個重建的真實場景和用戶的文本描述,我們首先在中心視點生成高分辨率且幾何對齊的全景紋理。隨后,通過整體紋理傳播技術將紋理擴展至其余區域——其中,置信紋理修復負責填充大范圍的可信區域,而隱式紋理模仿則預測細小區域的色彩。最終生成的場景網格附帶有烘焙后的風格化UV紋理,可直接上傳至頭戴顯示設備(HMD),用于沉浸式VR漫游體驗。

3. 文章是如何實現雙重紋理對齊的
(1)雙通道紋理生成
風格優先紋理(Style-first Panorama):使用全景擴散模型(LDM)生成高視覺質量的紋理,但幾何貼合較弱。(“好看但可能歪的圖”:AI自由發揮,保證星空效果炫酷,但可能沒對準家具邊緣。)
對齊優先紋理(Align-first Panorama):基于真實場景紋理,通過Canny邊緣控制強制幾何對齊,但風格質量較低。(對齊但略丑的圖":AI嚴格按真實家具輪廓生成,風格較單調。)
(2)深度感知混合
- 從全景深度圖提取深度邊緣(如家具輪廓),生成混合掩膜。(AI先用深度圖找到桌子/沙發的邊緣線(像描邊工具))
- 通過泊松圖像編輯將對齊優先紋理融合到風格優先紋理中。
邊緣區域:優先使用對齊優先紋理(保證幾何貼合)(在邊緣線附近,用"對齊圖"修正位置(確保紋理不穿幫)。)
平坦區域:保留風格優先紋理(維持視覺質量)(其他區域保留"好看圖"的絢麗效果。)
4.文章是如何“先用低分辨率全景擴散模型生成基礎結構,再通過超分辨率提升細節”的?
(1)低分辨率基礎結構生成
- 輸入條件:文本提示(如“星空主題”);場景中心視點的低分辨率(如512×1024)全景深度圖與邊緣圖。
- 模型:基于Latent Diffusion Model (LDM)的全景擴散模型,通過以下改進實現結構一致性:
水平環形填充(Horizontal Circular Padding):替換UNet的常規卷積,強制左右邊界連續。
多條件控制:聯合調節深度、邊緣和文本嵌入 - 輸出:低分辨率(如1024×2048)全景紋理,保留場景宏觀布局(如墻壁/家具位置),但缺乏細節。
(2)超分辨率細節增強
- 方法:
分塊擴散上采樣(Tiled Diffusion):將低分辨率全景圖分塊輸入通用LDM,通過擴散過程逐步提升分辨率(如3倍至3072×6144)。
極區修復(Polar Inpainting):將全景圖上下極區轉換為透視投影,修復扭曲的頂/底部分(如天花板/地板)。水平滾動圖像,修復左右邊界接縫。 - 輸出:高分辨率無縫全景圖,細節豐富(如家具木紋、星空的光點),符合等距柱狀投影(Equirectangular Projection)要求。

三、Sample2SQL: A Visual Interface for Querying Risky Enterprises
作者:Hongjia Wu, Shanchen Zou, Jiazhi Xia, Hongxin Zhang, Wei Chen
機構:(1)State Key Lab of CAD&CG, Zhejiang University (2)Central South University
文章鏈接:https://ieeexplore.ieee.org/document/10541717
發表:PacificVis 2024
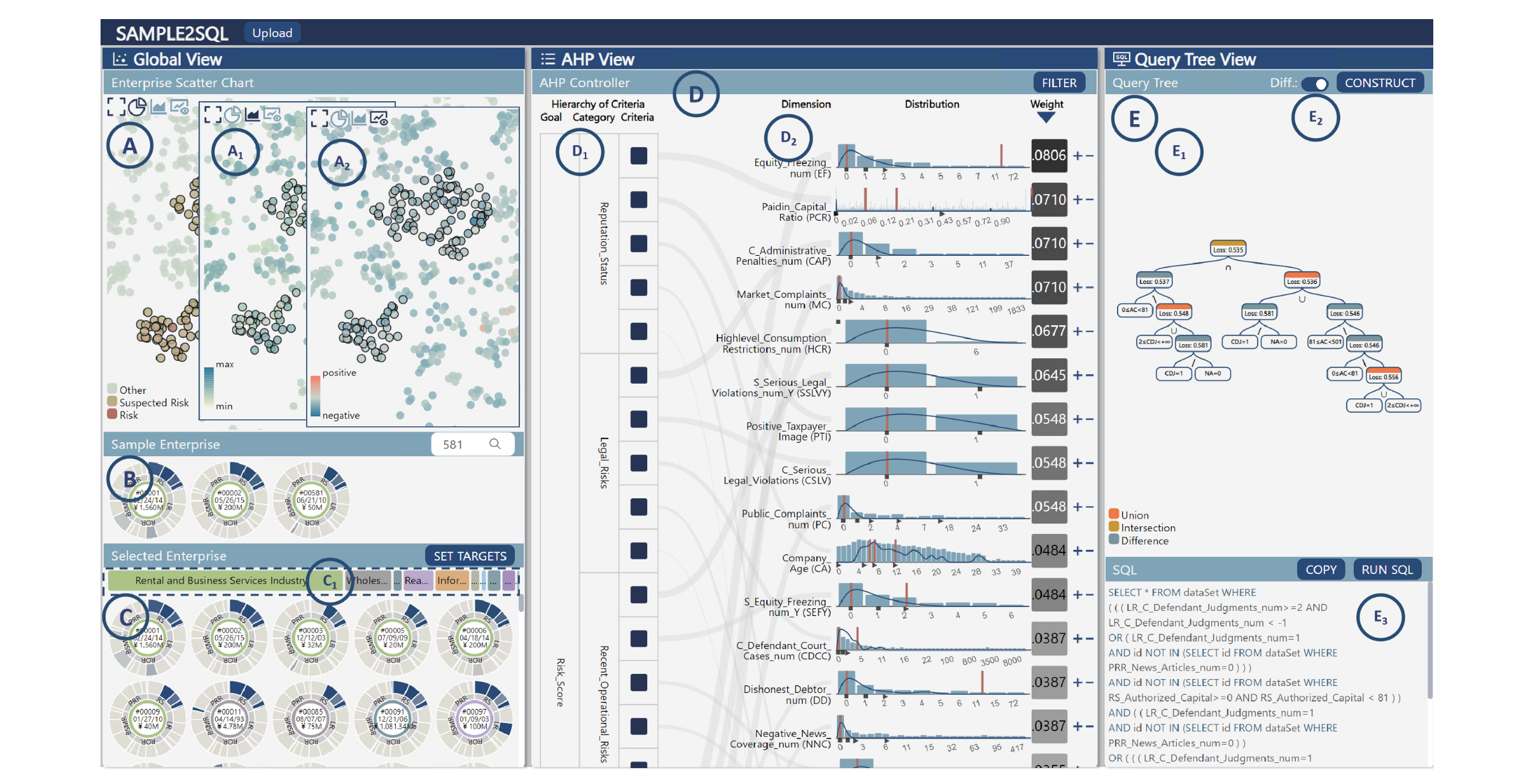
可視化界面包含三個主要視圖:全局視圖、AHP(層次分析法)視圖和查詢樹視圖。全局視圖展示了不同粒度級別的信息,包括企業散點圖 (A)、樣本企業列表 (B) 和選定企業列表 ?。AHP 視圖 (D) 分為兩個部分,左側 (D1) 顯示 AHP 模型的層次結構,右側 (D2) 顯示每個維度的數據分布。查詢樹視圖 (E) 用于構建 SQL 查詢語句,由上部的查詢樹 (E1) 和下部的 SQL 語句文本框 (E3) 組成。
摘要:
我們提出了一種針對高風險企業的可視化查詢系統。用戶只需輸入少量高風險企業的樣本,即可通過交互式分析獲得表達查詢結果的 SQL 語句,從而方便后續的任務操作和理解風險標準。由于企業的多樣性和經濟指標的復雜性,對于普通用戶來說,理解、評估和查詢高風險企業是一項具有挑戰性的任務。為了解決這個問題,我們的可視化查詢系統通過可視化分析界面集成了多標準決策技術和數據挖掘。該系統利用從少量已知風險公司樣本中獲得的知識,能夠高效地識別高風險企業。我們的系統包括一個用于表達領域知識的層次分析模型、一個查詢樹構建算法和一個精心設計的可視化界面。兩個真實案例證明了我們系統的有效性。
1. 簡要介紹一下這篇文章
區域企業法律風險評估需綜合分析政治、市場、法律等多維數據,但傳統方法面臨數據量大、維度高、信息不對稱等挑戰。現有系統多聚焦于風險模型設計或自然語言轉SQL,缺乏結合領域知識與可視化探索的端到端解決方案。
核心貢獻:
(1)交互式規則模型調整:
- 基于層次分析法(AHP)構建可解釋的風險評估模型,支持通過可視化界面動態調整維度權重(如“法律訴訟次數”權重提升)。
- 提出簡化的AHP計算流程,僅需專家排序維度重要性即可生成一致性矩陣,降低交互負擔。
(2)查詢樹構建算法:
- 將SQL語句抽象為樹結構,葉節點為離散化后的過濾條件(如2 < 企業年齡 < 5),非葉節點為布爾組合(AND/OR)。
- 定義目標函數(基于Jaccard指數)優化查詢條件,貪心算法生成近似最優SQL語句,支持對目標企業集合的語義匹配。
(3)可視化分析流水線:
- 全局視圖:UMAP降維散點圖展示區域企業分布,太陽圖(Sunburst)編碼企業多維度數據與AHP權重。
- AHP視圖:條形圖對比樣本企業與整體數據分布,突出關鍵風險維度(如“失信記錄數”分布偏移)。
- 查詢樹視圖:樹形結構可視化SQL條件組合,支持節點點擊預覽查詢結果。
實驗驗證:
- 使用中國杭州8,300家企業真實數據,案例顯示系統能快速識別高風險企業(如失信企業集群),生成可解釋SQL語句(如篩選失信記錄 > 5 AND 行業 = “租賃服務”)。
- 專家評估表明,系統將規則模型調整時間縮短60%,SQL構建效率提升75%。
局限性:
- 僅支持單表查詢,缺乏多表連接(JOIN)等復雜操作。
- 時間序列分析能力不足,未考慮企業動態風險變化。
通俗易懂版本介紹:
這是一款名為Sample2SQL的“企業風險掃描神器”,專為投資機構、政府監管部門設計。用戶只需輸入幾家已知的高風險企業(比如因違規被處罰的公司),系統就能自動分析這些企業的共同特征,并生成標準的數據庫查詢語句(SQL),快速找出其他具有相似風險的企業。
核心功能:
(1)智能風險打分:
系統內置一個評分模型(類似考試判卷規則),比如“法律訴訟次數多”的企業扣分多。用戶可以通過拖拽調整不同指標的權重(如把“失信記錄”的權重調高)。
(2)可視化分析:
- 全局地圖:所有企業顯示為散點圖,高風險企業標紅,點擊可查看詳情(如行業、注冊資本)。
- 對比功能:用條形圖對比高風險企業和普通企業的差異(比如高風險企業的“被告案件數”普遍偏高)。
- SQL生成器:系統自動將分析結果轉換成SQL查詢語句,像搭積木一樣組合條件(例如“找出租賃行業且失信記錄>5次的企業”)。
2. 什么是層次分析法?AHP模型是如何得到的?
層次分析法(Analytic Hierarchy Process, AHP)是一種結構化決策方法,用于處理多準則復雜問題,由Thomas Saaty于1970年代提出。其核心步驟包括:
(1)構建層次模型:目標層(如“評估企業風險”)、準則層(如“法律風險”“財務風險”)、方案層(如“涉訴案件數量”、“失信被執行人次數”、“稅務違規情況”等)。
(2)構造判斷矩陣:通過兩兩比較準則重要性(如“法律風險 vs 財務風險,哪個更重要?”),用1-9標度量化。
(3)計算權重:特征向量法求權重,一致性檢驗(CR<0.1)確保邏輯合理。
(4)綜合評分:加權計算各方案總分。
在Sample2SQL中,實現了:用戶輸入樣本 → AHP模型動態優化 → 自動生成SQL的無縫流程。
在這篇工作中,作者與領域專家(投資公司的量化分析師和投資經理)進行了長時間(8 個月)的合作,通過反復的討論來確定模型的結構和參數。
AHP 模型根據用戶設定的權重和企業在各個維度上的數據,計算出一個綜合的風險評分。這個評分可以用來對企業進行排序或分類,識別出潛在的高風險企業。系統使用“查詢樹構建算法”來自動生成 SQL 語句。該算法的輸入是目標企業集合,目標是找到一組 SQL 過濾條件,能夠盡可能精確地匹配這些目標企業。
3. 查詢樹構建算法是怎么實現的?
查詢樹構建算法旨在解決以下優化問題:給定企業數據集 D 和目標企業集合 No,尋找最優查詢條件 o?,使得通過 o? 查詢到的企業子集 No? 與 No 的相似度盡可能高。算法采用貪心策略,從基本查詢條件出發,通過布爾運算逐步構建復雜的查詢條件,并使用基于 Jaccard 指數的損失函數 L(o?) 評估每個查詢條件的優劣。為了防止查詢樹過于復雜,算法引入正則化項 λHeight,并限制查詢樹的最大高度 Hmax。算法迭代進行,每次選擇損失函數值最小的查詢條件加入查詢樹,直到損失函數收斂或達到最大迭代次數。
通俗易懂的描述:
想象一下,你有一堆企業的信息,你想從中找到一些“壞公司”(高風險企業)。你已經有一些“壞公司”的樣本(目標集合),你想找到和它們類似的公司。
“查詢樹構建算法”就像一個聰明的助手,它會幫你自動生成一個 SQL 查詢語句,來找到這些“壞公司”。
這個助手是怎么工作的呢?
(1)劃分特征: 助手會把每個公司的各種特征(例如,公司年齡、注冊資本)劃分成幾個范圍,例如“公司年齡小于 5 年”、“公司年齡在 5 到 10 年之間”等等。
(2)嘗試各種組合: 助手會嘗試各種特征的組合,例如“公司年齡小于 5 年 并且 涉訴案件數量大于 10 起”。
(3)評估效果: 助手會評估每種組合的效果,看看它能找到多少“壞公司”,以及找到的公司有多大程度上和已知的“壞公司”相似。
(4)構建查詢樹: 助手會把這些組合按照效果好壞組織成一棵樹,效果最好的組合放在樹的頂端。
(5)生成 SQL 語句: 最后,助手會把這棵樹轉換成一個 SQL 查詢語句,你就可以用這個語句在數據庫里找到和你已知的“壞公司”類似的公司了。
為了防止生成的 SQL 語句太復雜,助手會限制樹的高度,并且會盡量選擇簡單的組合。
總而言之,“查詢樹構建算法”就像一個自動化的 SQL 查詢生成器,它會根據你提供的一些“壞公司”的樣本,自動生成一個 SQL 查詢語句,幫你找到更多類似的“壞公司”。
四、ReLive: Walking into Virtual Reality Spaces from Video Recordings of One’s Past Can Increase the Experiential Detail and Affect of Autobiographical Memories

作者:Valdemar Danry, Eli Villa, Samantha Chan, Pattie Maes
機構:MIT Media Lab
文章鏈接:https://ieeexplore.ieee.org/abstract/document/10919245
發表:TVCG 2025
摘要
隨著先進機器學習方法在空間重建方面的快速發展,理解這些技術對自傳記憶的心理和情感影響變得愈發重要。在一項被試內研究中,我們發現允許用戶在從他們的視頻重建的舊空間中漫步,顯著增強了他們對過去記憶的旅行感,增加了這些記憶的生動性,并提升了情感強度,相較于僅僅觀看同一事件的視頻。這些發現強調,無論技術如何進步,虛擬現實的沉浸體驗都能深刻影響記憶現象學和情感參與。隨著能夠實現沉浸式記憶重建的系統變得愈加普及,批判性地審視它們對人類認知和現實感知的影響變得至關重要。
1. 簡要介紹一下文章和method
這篇文章探討了利用虛擬現實(VR)技術重建個人記憶的影響,特別是通過從個人視頻中生成沉浸式的3D環境。研究表明,參與者在這種重建的空間中行走時,比起單純觀看視頻,他們的記憶重溫感、情感強度和記憶的生動性均顯著提升。實驗結果顯示,沉浸式體驗能夠增強自傳記憶的現象學特征,改善記憶的連貫性和細節。文章強調,隨著這些技術的普及,深入研究其對人類認知和現實感知的影響至關重要。
這篇文章的方法主要包括以下幾個步驟:
(1)視頻轉化:首先,研究團隊使用FFmpeg將參與者提交的個人視頻轉化為一系列有序的圖像序列,設置幀率為10幀每秒,以便進行后續處理。
(2)3D重建:采用Meshroom這一光學測量軟件,通過光攝影測量技術(photogrammetry)將圖像序列轉化為3D可步行的虛擬環境。研究選擇Meshroom是因為它在處理短視頻時更具有效性。
(3)用戶研究設計:進行了一項被試內研究,邀請14名參與者。每位參與者提交至少三個與其個人經歷相關的視頻。隨機選擇一個視頻進行3D重建。
(4)實驗條件:參與者在兩個條件下進行實驗:一是觀看原始2D視頻,二是在重建的3D虛擬空間中行走。通過隨機順序控制實驗順序,以減少變量干擾。
(5)數據收集與分析:在每個實驗條件后,參與者填寫問卷,包括自傳記憶重溫測試(ART)、情感量表(PANAS)和重建準確性評估。數據通過普通最小二乘法(OLS)線性回歸分析進行處理,以評估不同條件對記憶和情感的影響。
(6)定性分析:研究還通過半結構化訪談收集參與者的反饋,以深入了解他們的體驗和感受。
2. 簡要介紹一下研究結果
這篇文章的研究結果主要包括以下幾個方面:
(1)記憶重溫感:參與者在虛擬現實(VR)環境中行走時,感受到的“重溫”記憶的程度顯著高于觀看視頻的情況。VR條件下的自傳記憶重溫評分明顯更高,表明沉浸式體驗增強了記憶的回溯感。
(2)情感強度:在VR環境中,參與者的情感反應顯著增強。情感量表(PANAS)的評分顯示,參與者在沉浸于重建的空間時,體驗到的情感強度要高于視頻觀看時的情感反應。
(3)記憶的生動性和連貫性:參與者在VR環境中對記憶的細節和連貫性評估也更高。自傳記憶重溫測試(ART)的結果顯示,參與者在VR條件下對空間布局的記憶更為清晰,且記憶內容的連貫性也得到了改善。
(4)重建準確性:研究還發現,虛擬環境的重建準確性與情感反應和記憶質量之間存在顯著關聯。重建得越準確,參與者的情感反應和記憶的生動性、連貫性就越強。
(5)定性反饋:通過訪談,參與者普遍表示在VR環境中體驗到的記憶更為生動,能夠更好地回憶起特定的物品和情境。盡管存在一些細節缺失,許多參與者能夠憑借想象力填補這些空白。
總體而言,研究結果表明,虛擬現實技術顯著提升了個人記憶的回憶體驗和情感參與,顯示出其在自傳記憶重建領域的潛力。






 力扣100 10.和為K的子數組(前綴和+哈希))

,向進程發送發送信號)

)

一維前綴和, 藍橋杯)
)





