
【作者主頁】Francek Chen
【專欄介紹】 ? ? ?PyTorch深度學習 ? ? ? 深度學習 (DL, Deep Learning) 特指基于深層神經網絡模型和方法的機器學習。它是在統計機器學習、人工神經網絡等算法模型基礎上,結合當代大數據和大算力的發展而發展出來的。深度學習最重要的技術特征是具有自動提取特征的能力。神經網絡算法、算力和數據是開展深度學習的三要素。深度學習在計算機視覺、自然語言處理、多模態數據分析、科學探索等領域都取得了很多成果。本專欄介紹基于PyTorch的深度學習算法實現。
【GitCode】專欄資源保存在我的GitCode倉庫:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目錄
- 一、模型
- 二、實現
- 小結
??在實踐中,當給定相同的查詢、鍵和值的集合時,我們希望模型可以基于相同的注意力機制學習到不同的行為,然后將不同的行為作為知識組合起來,捕獲序列內各種范圍的依賴關系(例如,短距離依賴和長距離依賴關系)。因此,允許注意力機制組合使用查詢、鍵和值的不同子空間表示(representation subspaces)可能是有益的。
??為此,與其只使用單獨一個注意力匯聚,我們可以用獨立學習得到的 h h h組不同的線性投影(linear projections)來變換查詢、鍵和值。然后,這 h h h組變換后的查詢、鍵和值將并行地送到注意力匯聚中。最后,將這 h h h個注意力匯聚的輸出拼接在一起,并且通過另一個可以學習的線性投影進行變換,以產生最終輸出。這種設計被稱為多頭注意力(multihead attention)。對于 h h h個注意力匯聚輸出,每一個注意力匯聚都被稱作一個頭(head)。圖1展示了使用全連接層來實現可學習的線性變換的多頭注意力。

一、模型
??在實現多頭注意力之前,讓我們用數學語言將這個模型形式化地描述出來。給定查詢 q ∈ R d q \mathbf{q} \in \mathbb{R}^{d_q} q∈Rdq?、鍵 k ∈ R d k \mathbf{k} \in \mathbb{R}^{d_k} k∈Rdk?和值 v ∈ R d v \mathbf{v} \in \mathbb{R}^{d_v} v∈Rdv?,每個注意力頭 h i \mathbf{h}_i hi?( i = 1 , … , h i = 1, \ldots, h i=1,…,h)的計算方法為:
h i = f ( W i ( q ) q , W i ( k ) k , W i ( v ) v ) ∈ R p v (1) \mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v} \tag{1} hi?=f(Wi(q)?q,Wi(k)?k,Wi(v)?v)∈Rpv?(1) 其中,可學習的參數包括 W i ( q ) ∈ R p q × d q \mathbf W_i^{(q)}\in\mathbb R^{p_q\times d_q} Wi(q)?∈Rpq?×dq?、 W i ( k ) ∈ R p k × d k \mathbf W_i^{(k)}\in\mathbb R^{p_k\times d_k} Wi(k)?∈Rpk?×dk?和 W i ( v ) ∈ R p v × d v \mathbf W_i^{(v)}\in\mathbb R^{p_v\times d_v} Wi(v)?∈Rpv?×dv?,以及代表注意力匯聚的函數 f f f。 f f f可以是注意力評分函數中的加性注意力和縮放點積注意力。多頭注意力的輸出需要經過另一個線性轉換,它對應著 h h h個頭連結后的結果,因此其可學習參數是 W o ∈ R p o × h p v \mathbf W_o\in\mathbb R^{p_o\times h p_v} Wo?∈Rpo?×hpv?:
W o [ h 1 ? h h ] ∈ R p o (2) \mathbf W_o \begin{bmatrix}\mathbf h_1\\\vdots\\\mathbf h_h\end{bmatrix} \in \mathbb{R}^{p_o} \tag{2} Wo? ?h1??hh?? ?∈Rpo?(2)
??基于這種設計,每個頭都可能會關注輸入的不同部分,可以表示比簡單加權平均值更復雜的函數。
import math
import torch
from torch import nn
from d2l import torch as d2l
二、實現
??在實現過程中通常選擇縮放點積注意力作為每一個注意力頭。為了避免計算代價和參數代價的大幅增長,我們設定 p q = p k = p v = p o / h p_q = p_k = p_v = p_o / h pq?=pk?=pv?=po?/h。值得注意的是,如果將查詢、鍵和值的線性變換的輸出數量設置為 p q h = p k h = p v h = p o p_q h = p_k h = p_v h = p_o pq?h=pk?h=pv?h=po?,則可以并行計算 h h h個頭。在下面的實現中, p o p_o po?是通過參數num_hiddens指定的。
#@save
class MultiHeadAttention(nn.Module):"""多頭注意力"""def __init__(self, key_size, query_size, value_size, num_hiddens, num_heads, dropout, bias=False, **kwargs):super(MultiHeadAttention, self).__init__(**kwargs)self.num_heads = num_headsself.attention = d2l.DotProductAttention(dropout)self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)def forward(self, queries, keys, values, valid_lens):# queries,keys,values的形狀:# (batch_size,查詢或者“鍵-值”對的個數,num_hiddens)# valid_lens 的形狀:# (batch_size,)或(batch_size,查詢的個數)# 經過變換后,輸出的queries,keys,values 的形狀:# (batch_size*num_heads,查詢或者“鍵-值”對的個數,# num_hiddens/num_heads)queries = transpose_qkv(self.W_q(queries), self.num_heads)keys = transpose_qkv(self.W_k(keys), self.num_heads)values = transpose_qkv(self.W_v(values), self.num_heads)if valid_lens is not None:# 在軸0,將第一項(標量或者矢量)復制num_heads次,# 然后如此復制第二項,然后諸如此類。valid_lens = torch.repeat_interleave(valid_lens, repeats=self.num_heads, dim=0)# output的形狀:(batch_size*num_heads,查詢的個數,# num_hiddens/num_heads)output = self.attention(queries, keys, values, valid_lens)# output_concat的形狀:(batch_size,查詢的個數,num_hiddens)output_concat = transpose_output(output, self.num_heads)return self.W_o(output_concat)
??為了能夠使多個頭并行計算,上面的MultiHeadAttention類將使用下面定義的兩個轉置函數。具體來說,transpose_output函數反轉了transpose_qkv函數的操作。
#@save
def transpose_qkv(X, num_heads):"""為了多注意力頭的并行計算而變換形狀"""# 輸入X的形狀:(batch_size,查詢或者“鍵-值”對的個數,num_hiddens)# 輸出X的形狀:(batch_size,查詢或者“鍵-值”對的個數,num_heads,# num_hiddens/num_heads)X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)# 輸出X的形狀:(batch_size,num_heads,查詢或者“鍵-值”對的個數,# num_hiddens/num_heads)X = X.permute(0, 2, 1, 3)# 最終輸出的形狀:(batch_size*num_heads,查詢或者“鍵-值”對的個數,# num_hiddens/num_heads)return X.reshape(-1, X.shape[2], X.shape[3])#@save
def transpose_output(X, num_heads):"""逆轉transpose_qkv函數的操作"""X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])X = X.permute(0, 2, 1, 3)return X.reshape(X.shape[0], X.shape[1], -1)
??下面使用鍵和值相同的小例子來測試我們編寫的MultiHeadAttention類。多頭注意力輸出的形狀是(batch_size,num_queries,num_hiddens)。
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens, num_hiddens, num_heads, 0.5)
attention.eval()

batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
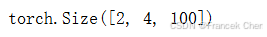
小結
- 多頭注意力融合了來自于多個注意力匯聚的不同知識,這些知識的不同來源于相同的查詢、鍵和值的不同的子空間表示。
- 基于適當的張量操作,可以實現多頭注意力的并行計算。

)






)










