在近年來,深度學習尤其在計算機視覺領域取得了巨大的進展,而 Vision Transformer(ViT)作為一種新的視覺模型,它的表現甚至在許多任務中超過了傳統的卷積神經網絡(CNN),如
ResNet。在這篇博客中,我們將詳細介紹 Vision Transformer 的工作原理,并解釋它如何在各種公開數據集上超越最好的 ResNet,尤其是在大數據集上的預訓練過程中,ViT 展現出的優勢。
什么是 Vision Transformer (ViT)?
1. 背景與起源
Vision Transformer(ViT)是從 Transformer 模型發展而來的,最初的 Transformer 模型主要應用于自然語言處理(NLP)任務,尤其是機器翻譯。在 NLP 中,Transformer 展現出了其強大的序列建模能力,能夠捕捉長距離的依賴關系。
在計算機視覺領域,傳統的卷積神經網絡(CNN)一直是圖像分類、目標檢測等任務的主力。然而,ViT 在提出后,尤其是在大型數據集上進行預訓練時,憑借其在長距離依賴建模上的優勢,迅速展示了其強大的能力。ViT 把 Transformer 模型應用于圖像數據,并通過某些創新技巧,解決了傳統卷積神經網絡的局限性。
2. ViT 的基本原理
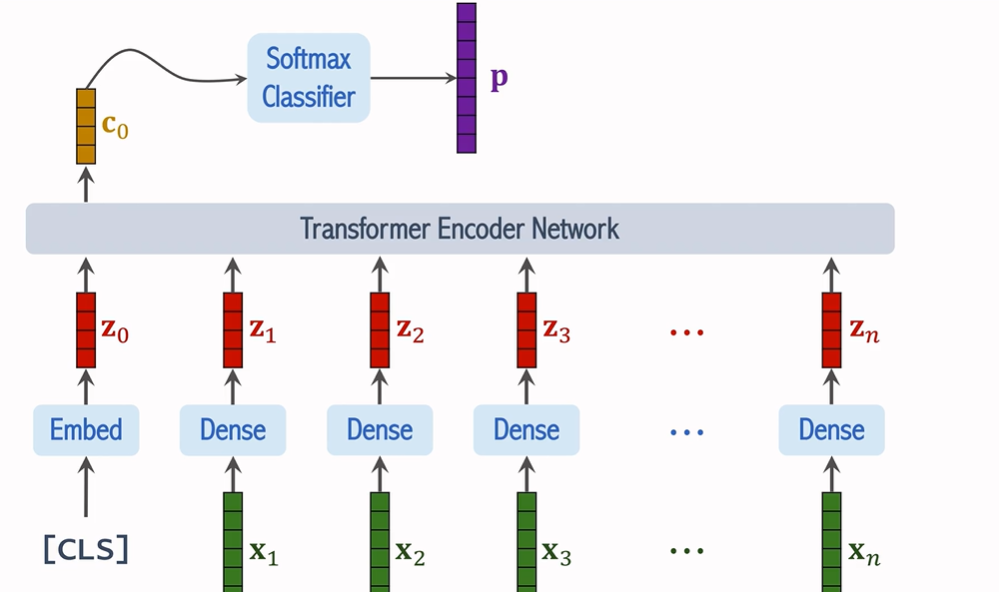
ViT 將圖像輸入視為一系列小的圖像塊(patch),而不是傳統的像素級輸入。通過這種方法,ViT 將圖像的局部信息轉換為序列數據,使得 Transformer 可以通過自注意力機制對圖像進行處理。下面我們將詳細介紹 ViT 的工作流程。
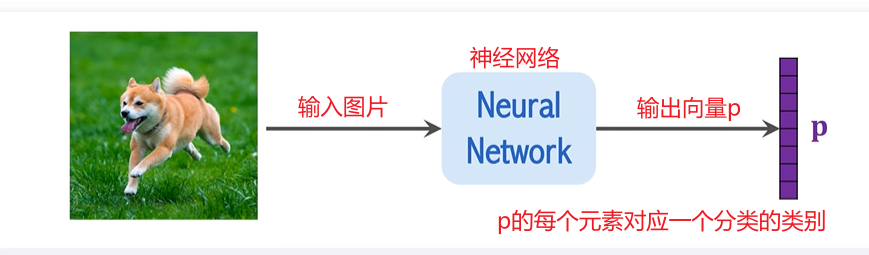
ViT 的工作流程
1. 圖像分塊(Patch Splitting)
首先,將輸入圖像劃分為固定大小的塊(patch),每個塊的尺寸通常為 16x16 或更大,具體取決于模型的設計。在處理過程中,每個圖像塊被視為一個獨立的單元,這與自然語言處理中的“單詞”相似。
假設原圖的尺寸為 224x224 像素,ViT 將其劃分為 14x14 個 16x16 的小塊。這樣,原始圖像就被轉化為 196 個圖像塊(14 * 14 = 196),每個塊有 3 個通道(RGB)。

2. 向量化(Flattening)
每個小塊通過 Flatten 操作(拉伸)變成一個向量。例如,一個 16x16 大小的 RGB 圖像塊經過拉伸后將變為一個 768 維的向量(16x16x3 = 768)。這些向量作為 Transformer 的輸入。

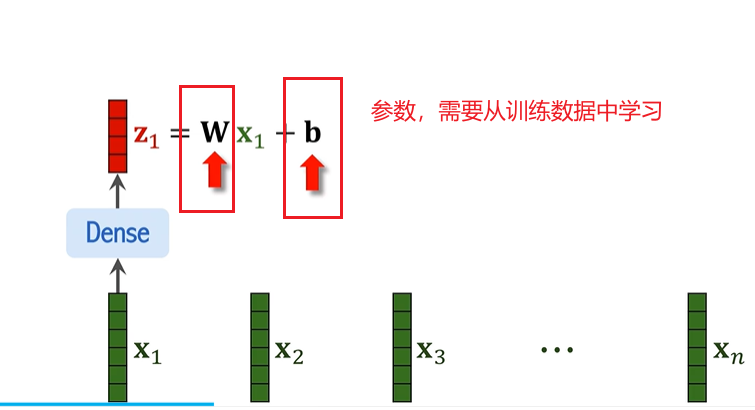
3. 線性變換(Linear Transformation)
每個圖像塊向量通過一個線性變換,映射到一個新的維度,這個操作通常由一個全連接層完成。此時,所有塊的特征空間被轉換到新的表示空間中,得到新的表示向量 z_i。
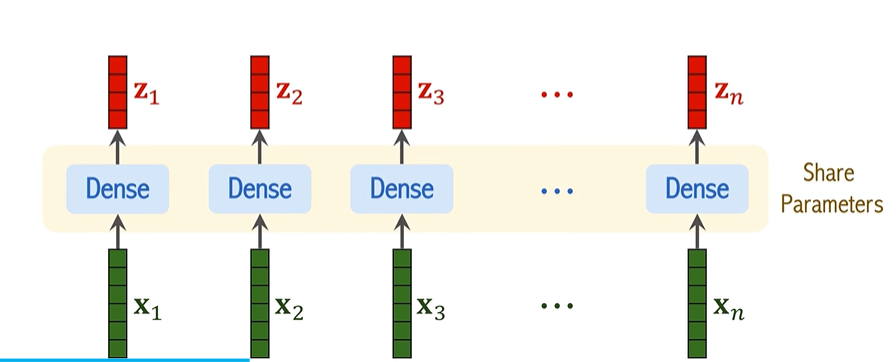
4. 添加位置編碼(Positional Encoding)
由于 Transformer 本身并不具備處理序列中元素位置的能力,ViT 通過添加位置編碼來保留位置信息。每個圖像塊的向量 z_i 會加上相應的位置信息,這樣每個塊的表示就不僅包含了圖像內容的信息,還包含了該塊在圖像中的位置信息。
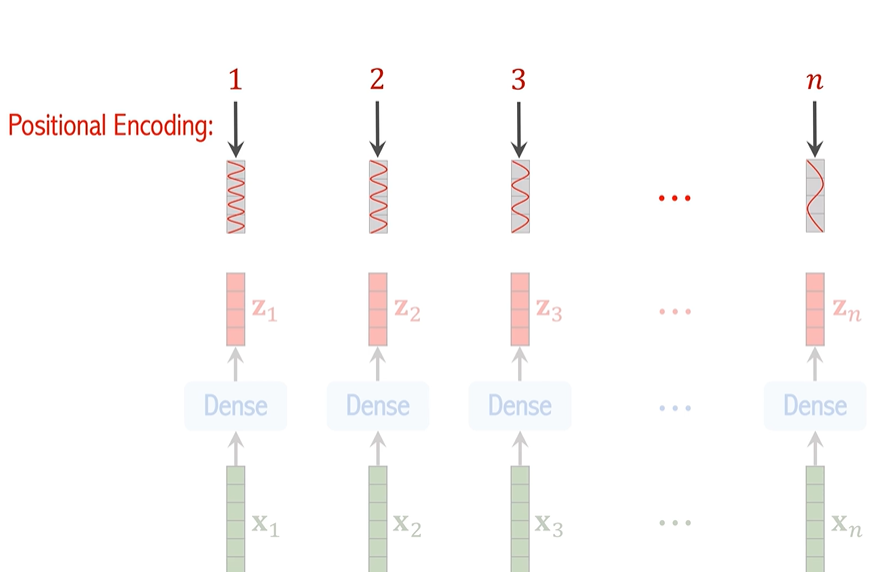
如果不包含位置信息,那么左右兩張圖對transformer眼里是一樣的,所有要給圖片位置做編號


x1-xn是圖片中n個小塊向量化后得到的結果,把他們做線性變換并且得到位置信息得到向量z1-zn,(既包含內容信息又包含位置信息)
5. CLS Token 和最終的輸入
為了最終的圖像分類,ViT 引入了一個特殊的分類標記(CLS Token)。該標記是一個額外的向量,通常初始化為零,并與圖像塊的表示一起作為輸入送入 Transformer。最終,CLS Token 會作為圖像的整體表示,進行分類任務。
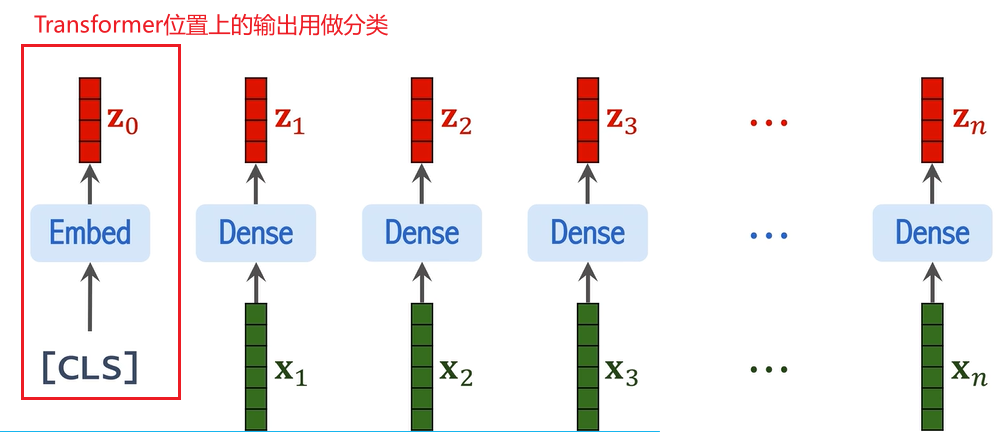
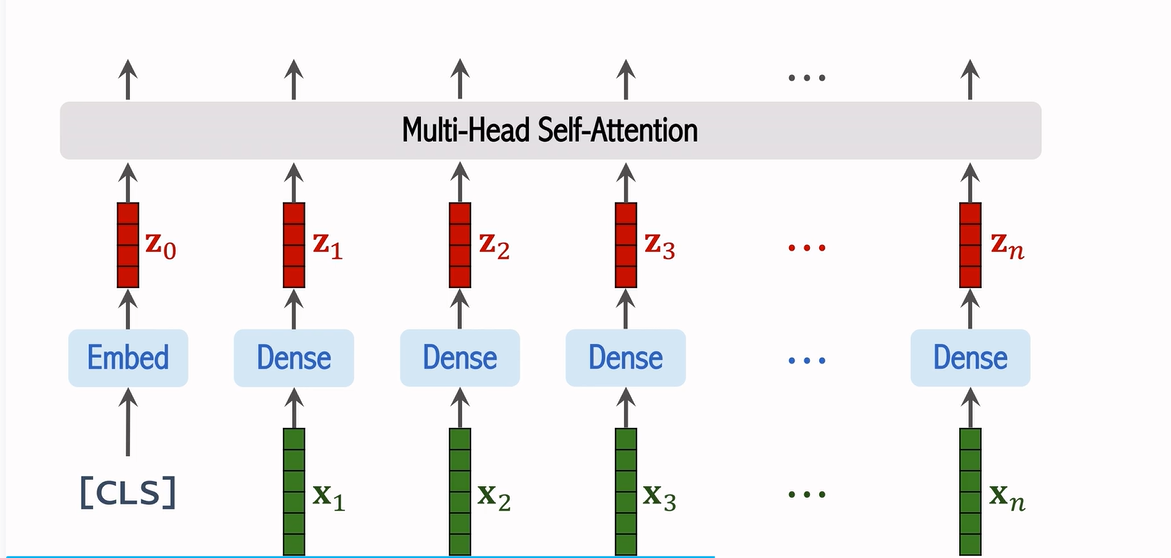
6. Transformer 編碼器(Encoder)
輸入經過位置編碼和 CLS Token 的處理后,所有的圖像塊向量會被送入 Transformer 編碼器。ViT 使用多層的自注意力機制(Self-Attention)來處理這些向量。每一層的輸出都會被送入下一層,直到所有的信息被充分聚合。
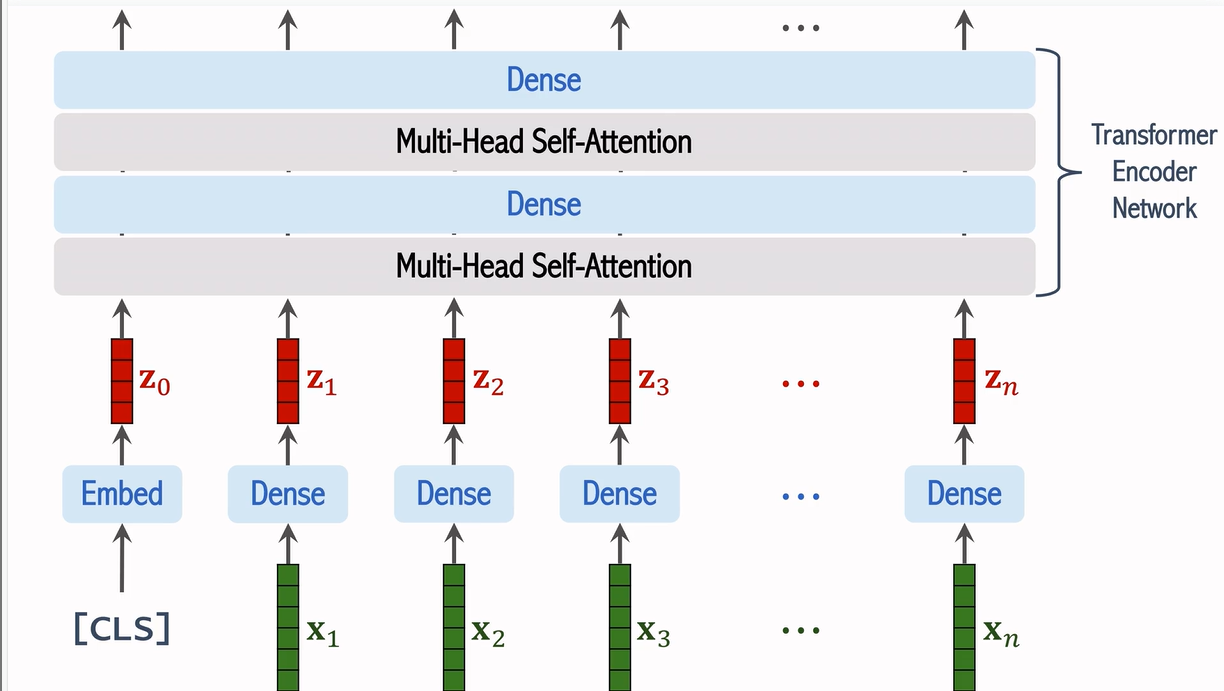
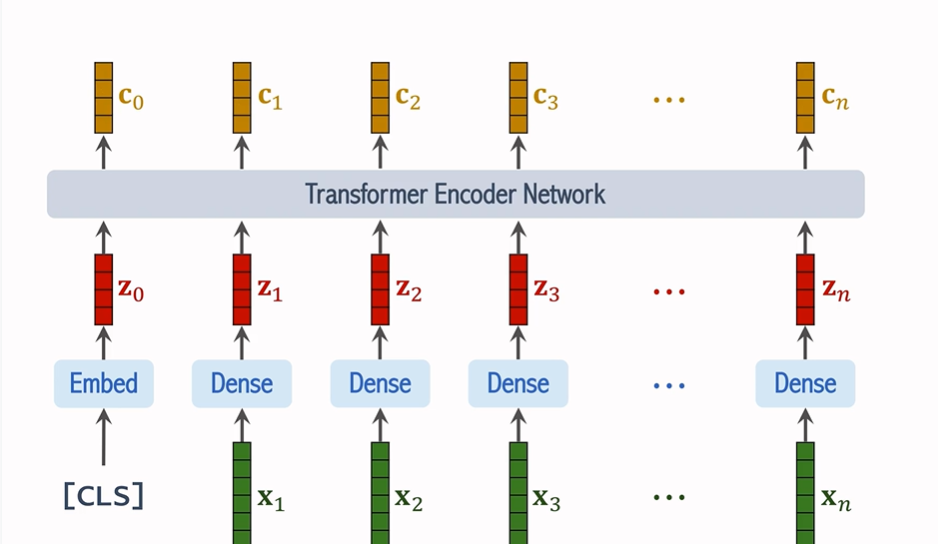
7. 分類與輸出
經過多次的自注意力處理后,最終的 CLS Token 會被送入一個全連接層,該層輸出一個包含所有類別概率的向量 p。通過與真實標簽進行比較,ViT 利用交叉熵損失函數來計算誤差,并通過梯度下降優化網絡參數。
8. 訓練過程:預訓練與微調
ViT 的訓練過程可以分為兩個階段:預訓練和微調。
預訓練(Pretraining)
預訓練階段是在一個大規模的數據集上進行的,通常會使用像 ImageNet 或 JFT-300M 這樣的龐大數據集。這一階段的目標是讓模型學習到通用的視覺特征。通常,預訓練時使用的模型參數是隨機初始化的,隨著訓練的進行,模型不斷優化,學習到有用的圖像特征。
微調(Fine-tuning)
預訓練完成后,模型會在較小的任務特定數據集(如 CIFAR-10、ADE20K 等)上進行微調。通過在這些特定任務上繼續訓練,模型能夠調整參數,以適應特定的應用場景。
ViT 與 ResNet 的比較
傳統的卷積神經網絡,如 ResNet,依靠卷積層通過局部感受野捕捉圖像特征。而 ViT 的核心優勢在于 Transformer 的自注意力機制。自注意力機制允許模型在處理每個圖像塊時,能夠關注到其他位置的信息,因此能夠捕捉更遠距離的圖像依賴。
當在大規模數據集上預訓練時,ViT 展現出比 ResNet 更好的性能,尤其是在較大的數據集上。隨著數據集規模的擴大,ViT 的優勢變得更加明顯。
為什么 ViT 在大數據集上效果更好?
-
全局依賴建模: ViT 的自注意力機制允許它同時關注整個圖像,而不像 CNN 那樣依賴局部卷積操作。這樣,ViT 可以捕捉到更多的全局信息,對于大數據集的圖像分析更具優勢。
-
更強的表示能力: 由于 ViT 處理的是圖像塊的向量表示,因此它的表示能力比 CNN 更強,特別是在任務復雜或者圖像間關系較遠的場景下。
-
更好的擴展性: Transformer 的設計使得它能夠輕松地擴展到更大的數據集和更復雜的任務上,尤其是當計算資源足夠時。
總結
Vision Transformer(ViT)是計算機視覺領域的一項創新,它將 Transformer 模型從自然語言處理應用擴展到了圖像處理任務。通過將圖像分塊、向量化、加位置編碼,再通過 Transformer 編碼器進行處理,ViT 能夠有效地提取圖像中的全局特征,并在大規模數據集上展現出超越傳統卷積神經網絡(如 ResNet)的性能。
盡管 ViT 在計算上要求較高,尤其是需要大量數據來訓練,但在預訓練后,它在圖像分類、目標檢測等任務中提供了顯著的提升。隨著大數據集和計算能力的不斷提升,ViT 很可能成為未來計算機視覺領域的主流方法之一。








)









)
)