文章目錄
- 一、簡介
- 二、如何安裝
- 2.1 安裝
- 2.2 校驗
- 三、開始使用
- 3.1 可視化界面
- 3.2 使用命令行
- 3.2.1 模型微調訓練
- 3.2.2 模型合并
- 3.2.3 模型推理
- 3.2.4 模型評估
- 四、高級功能
- 4.1 分布訓練
- 4.2 DeepSpeed
- 4.2.1 單機多卡
- 4.2.2 多機多卡
- 五、日志分析
一、簡介
LLaMA-Factory 是一個用于訓練和微調模型的工具。它支持全參數微調、LoRA 微調、QLoRA 微調、模型評估、模型推理和模型導出等功能。
二、如何安裝
2.1 安裝
# 構建虛擬環境
conda create -n llamafactory python=3.10 -y && conda activate llamafactory
# 下載倉庫
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 安裝
pip install -e .
2.2 校驗
llamafactory-cli version
三、開始使用
3.1 可視化界面
# 啟動可視化界面
llamafactory-cli webui
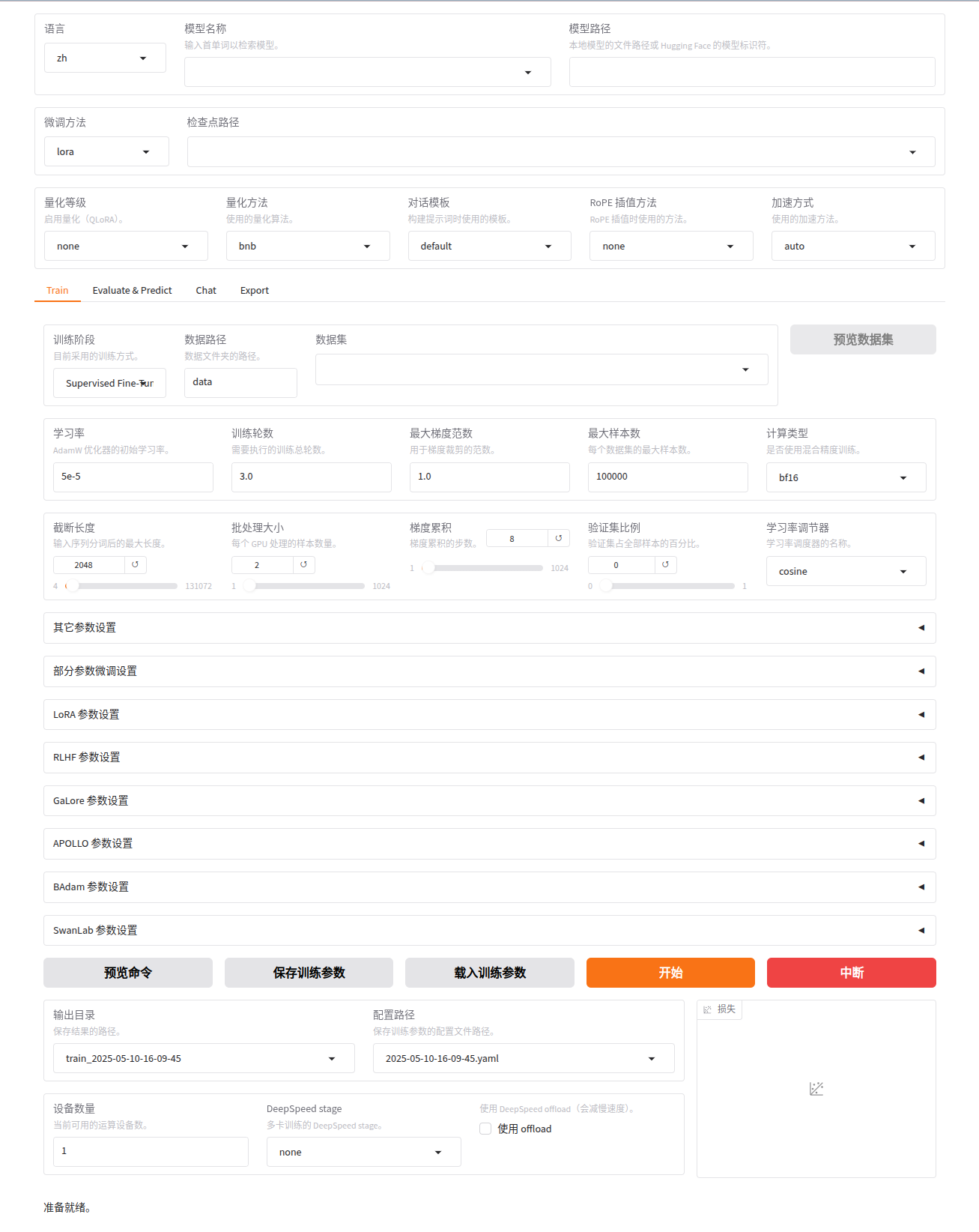
WebUI 主要分為四個界面:訓練、評估與預測、對話、導出。
- 訓練:
- 在開始訓練模型之前,您需要指定的參數有:
- 模型名稱及路徑
- 訓練階段
- 微調方法
- 訓練數據集
- 學習率、訓練輪數等訓練參數
- 微調參數等其他參數
- 輸出目錄及配置路徑
隨后,點擊 開始 按鈕開始訓練模型。
備注:
關于斷點重連:適配器斷點保存于output_dir目錄下,請指定檢查點路徑以加載斷點繼續訓練。
如果需要使用自定義數據集,需要在data/data_info.json中添加自定義數據集描述并確保數據集格式正確,否則可能會導致訓練失敗。
-
評估預測
- 模型訓練完畢后,可以通過在評估與預測界面通過指定
模型及檢查點路徑在指定數據集上進行評估。
- 模型訓練完畢后,可以通過在評估與預測界面通過指定
-
對話
- 通過在對話界面指定
模型、檢查點路徑及推理引擎后輸入對話內容與模型進行對話觀察效果。
- 通過在對話界面指定
-
導出
- 如果對模型效果滿意并需要導出模型,您可以在導出界面通過指定
模型、檢查點路徑、分塊大小、導出量化等級及校準數據集、導出設備、導出目錄等參數后點擊導出按鈕導出模型。
- 如果對模型效果滿意并需要導出模型,您可以在導出界面通過指定
3.2 使用命令行
3.2.1 模型微調訓練
在 examples/train_lora 目錄下有多個LoRA微調示例,以 llama3_lora_sft.yaml 為例,命令如下:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
備注:
LLaMA-Factory 默認使用所有可見的計算設備。根據需求可通過CUDA_VISIBLE_DEVICES或ASCEND_RT_VISIBLE_DEVICES指定計算設備。
參數說明:
| 名稱 | 描述 |
|---|---|
| model_name_or_path | 模型名稱或路徑(指定本地路徑,或從 huggingface 上下載) |
| stage | 訓練階段,可選: rm(reward modeling), pt(pretrain), sft(Supervised Fine-Tuning), PPO, DPO, KTO, ORPO |
| do_train | true用于訓練, false用于評估 |
| finetuning_type | 微調方式。可選: freeze, lora, full |
| lora_target | 采取LoRA方法的目標模塊,默認值為 all。 |
| dataset | 使用的數據集,使用”,”分隔多個數據集 |
| template | 數據集模板,請保證數據集模板與模型相對應。 |
| output_dir | 輸出路徑 |
| logging_steps | 日志輸出步數間隔 |
| save_steps | 模型斷點保存間隔 |
| overwrite_output_dir | 是否允許覆蓋輸出目錄 |
| per_device_train_batch_size | 每個設備上訓練的批次大小 |
| gradient_accumulation_steps | 梯度積累步數 |
| max_grad_norm | 梯度裁剪閾值 |
| learning_rate | 學習率 |
| lr_scheduler_type | 學習率曲線,可選 linear, cosine, polynomial, constant 等。 |
| num_train_epochs | 訓練周期數 |
| bf16 | 是否使用 bf16 格式 |
| warmup_ratio | 學習率預熱比例 |
| warmup_steps | 學習率預熱步數 |
| push_to_hub | 是否推送模型到 Huggingface |
目錄說明:
examples/train_full:包含多個全參數微調示例。examples/train_lora:包含多個LoRA微調示例。examples/train_qlora:包含多個QLoRA微調示例。
3.2.2 模型合并
在 examples/merge_lora 目錄下有多個模型合并示例,以 llama3_lora_sft.yaml 為例,命令如下:
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
adapter_name_or_path 需要與微調中的適配器輸出路徑 output_dir 相對應。
export_quantization_bit 為導出模型量化等級,可選 2, 3, 4, 8。
目錄說明:
examples/merge_lora:包含多個LoRA合并示例。
3.2.3 模型推理
在 examples/inference 目錄下有多個模型推理示例,以 llama3_lora_sft.yaml 為例,命令如下:
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
參數說明:
| 名稱 | 描述 |
|---|---|
| model_name_or_path | 模型名稱或路徑(指定本地路徑,或從HuggingFace Hub下載) |
| adapter_name_or_path | 適配器檢查點路徑(用于LoRA等微調方法的預訓練適配器) |
| template | 對話模板(需與模型架構匹配,如LLaMA-2、ChatGLM等專用模板) |
| infer_backend | 推理引擎(可選:vllm、transformers、lightllm等) |
3.2.4 模型評估
-
通用能力評估
llamafactory-cli eval examples/train_lora/llama3_lora_eval.yaml -
NLG 評估
llamafactory-cli train examples/extras/nlg_eval/llama3_lora_predict.yaml獲得模型的
BLEU和ROUGE分數以評價模型生成質量。 -
評估相關參數
| 參數名稱 | 類型 | 描述 | 默認值 | 可選值/備注 |
|---|---|---|---|---|
| task | str | 評估任務名稱 | - | mmlu_test, ceval_validation, cmmlu_test |
| task_dir | str | 評估數據集存儲目錄 | “evaluation” | 相對或絕對路徑 |
| batch_size | int | 每個GPU的評估批次大小 | 4 | 根據顯存調整 |
| seed | int | 隨機種子(保證可復現性) | 42 | - |
| lang | str | 評估語言 | “en” | en(英文), zh(中文) |
| n_shot | int | Few-shot學習使用的示例數量 | 5 | 0表示zero-shot |
| save_dir | str | 評估結果保存路徑 | None | None時不保存 |
| download_mode | str | 數據集下載模式 | DownloadMode.REUSE_DATASET_IF_EXISTS | 存在則復用,否則下載 |
四、高級功能
4.1 分布訓練
LLaMA-Factory 支持 單機多卡 和 多機多卡 分布式訓練。同時也支持 DDP , DeepSpeed 和 FSDP 三種分布式引擎。
- DDP (DistributedDataParallel) 通過實現模型并行和數據并行實現訓練加速。 使用
DDP的程序需要生成多個進程并且為每個進程創建一個DDP實例,他們之間通過torch.distributed庫同步。 - DeepSpeed 是微軟開發的分布式訓練引擎,并提供
ZeRO(Zero Redundancy Optimizer)、offload、Sparse Attention、1 bit Adam、流水線并行等優化技術。 - FSDP 通過全切片數據并行技術(Fully Sharded Data Parallel)來處理更多更大的模型。在
DDP中,每張 GPU 都各自保留了一份完整的模型參數和優化器參數。而FSDP切分了模型參數、梯度與優化器參數,使得每張GPU只保留這些參數的一部分。 除了并行技術之外,FSDP還支持將模型參數卸載至CPU,從而進一步降低顯存需求。
| 引擎 | 數據切分 | 模型切分 | 優化器切分 | 參數卸載 |
|---|---|---|---|---|
| DDP | 支持 | 不支持 | 不支持 | 不支持 |
| DeepSpeed | 支持 | 支持 | 支持 | 支持 |
| FSDP | 支持 | 支持 | 支持 | 支持 |
4.2 DeepSpeed
由于 DeepSpeed 的顯存優化技術,使得 DeepSpeed 在顯存占用上具有明顯優勢,因此推薦使用 DeepSpeed 進行訓練。
DeepSpeed 是由微軟開發的一個開源深度學習優化庫,旨在提高大模型訓練的效率和速度。在使用 DeepSpeed 之前,您需要先估計訓練任務的顯存大小,再根據任務需求與資源情況選擇合適的 ZeRO 階段。
- ZeRO-1: 僅劃分優化器參數,每個GPU各有一份完整的模型參數與梯度。
- ZeRO-2: 劃分優化器參數與梯度,每個GPU各有一份完整的模型參數。
- ZeRO-3: 劃分優化器參數、梯度與模型參數。
簡單來說:從ZeRO-1到ZeRO-3,階段數越高,顯存需求越小,但是訓練速度也依次變慢。此外,設置offload_param=cpu參數會大幅減小顯存需求,但會極大地使訓練速度減慢。因此,如果您有足夠的顯存, 應當使用ZeRO-1,并且確保offload_param=none。
4.2.1 單機多卡
啟動 DeepSpeed 引擎,命令如下:
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml
該配置文件中配置了 deepspeed 參數,具體如下:
deepspeed: examples/deepspeed/ds_z3_config.json
4.2.2 多機多卡
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
備注
關于hostfile:
hostfile的每一行指定一個節點,每行的格式為 slots=<num_slots> , 其中 是節點的主機名, <num_slots> 是該節點上的GPU數量。下面是一個例子:worker-1 slots=4 worker-2 slots=4請在 https://www.deepspeed.ai/getting-started/ 了解更多。
如果沒有指定
hostfile變量,DeepSpeed會搜索/job/hostfile文件。如果仍未找到,那么DeepSpeed會使用本機上所有可用的GPU。
五、日志分析
在訓練過程中,LLaMA-Factory 會輸出詳細的日志信息,包括訓練進度、訓練參數、訓練時間等。這些日志信息可以幫助我們更好地了解訓練過程,并針對問題進行優化和調整。以下解釋訓練時的一些參數:
[INFO|trainer.py:2409] 2025-04-01 15:49:20,010 >> ***** Running training *****
[INFO|trainer.py:2410] 2025-04-01 15:49:20,010 >> Num examples = 205
[INFO|trainer.py:2411] 2025-04-01 15:49:20,010 >> Num Epochs = 1,000
[INFO|trainer.py:2412] 2025-04-01 15:49:20,010 >> Instantaneous batch size per device = 8
[INFO|trainer.py:2415] 2025-04-01 15:49:20,010 >> Total train batch size (w. parallel, distributed & accumulation) = 64
[INFO|trainer.py:2416] 2025-04-01 15:49:20,010 >> Gradient Accumulation steps = 8
[INFO|trainer.py:2417] 2025-04-01 15:49:20,010 >> Total optimization steps = 3,000
[INFO|trainer.py:2418] 2025-04-01 15:49:20,013 >> Number of trainable parameters = 73,859,072
參數解釋:
-
單設備批大小(Instantaneous batch size per device)
- 指單個 GPU(或設備)在每次前向傳播時處理的樣本數量。
- 例如,如果
instantaneous_batch_size_per_device=8,則每個 GPU 一次處理 8 條數據。
-
設備數(Number of devices)
- 指并行訓練的 GPU 數量(數據并行)。
- 例如,使用 4 個 GPU 時,
device_num=4。
-
梯度累積步數(Gradient accumulation steps)
- 由于顯存限制,可能無法直接增大單設備批大小,因此通過多次前向傳播累積梯度,再一次性更新參數。通過梯度累積,用較小的單設備批大小模擬大總批大小的訓練效果。
- 例如,若
gradient_accumulation_steps=2,則每 2 次前向傳播后才執行一次參數更新。
-
總批大小(Total train batch size)
- 是參數更新時實際使用的全局批量大小。總批大小越大,梯度估計越穩定,但需調整學習率(通常按比例增大)
在 LLaMA Factory 中,總批大小(Total train batch size)、單設備批大小(Instantaneous batch size per device)、設備數(Number of devices) 和 梯度累積步數(Gradient accumulation steps) 的關系可以用以下公式表示:
[
\text{總批大小} = \text{單設備批大小} \times \text{設備數} \times \text{梯度累積步數}
]
例如:
- 單設備批大小 = 8
- 設備數 = 4
- 梯度累積步數 = 2
- 則總批大小 = ( 8 \times 4 \times 2 = 64 )。
參考資料:
- Github
- README_zh.md
- 數據集文檔
- 說明文檔







)


丟失MFA的解決方案)

)


)



