原文標題:Multi-view Dense Correspondence Learning (MvDeCor)
引言
在計算機視覺與圖形學領域,3D形狀分割一直是一個基礎且具有挑戰性的任務。如何在標注稀缺的情況下,實現對3D模型的細粒度分割?近期,斯坦福大學視覺實驗室提出的"MvDeCor"方法給我們帶來了啟示:通過多視圖密集對應學習,自監督預訓練2D網絡,并將2D嵌入反投影到3D,實現高精度的細粒度分割。本文將從方法原理、技術細節、實驗驗證及應用場景等多方面進行深入解讀,并給出在CSDN發布的美觀排版建議,幫助大家快速上手并沖上熱搜。
背景與挑戰
-
細粒度3D分割需求:
-
將3D模型按更小、更具體的部件分割(如將椅子分割為椅背、椅座、椅腿)。
-
能夠捕捉微小結構差異,如螺絲、鉚釘等。
-
-
標注數據稀缺:
-
手工標注3D模型成本高昂且耗時。
-
大規模標注難以推廣到多類別與多場景。
-
-
3D網絡難以表達高分辨率細節:
-
點云/體素網絡在細節捕捉上受限。
-
普通3D自監督方法(如PointContrast)mIoU提升有限。
-
-
借助2D視覺先驗的潛力:
-
2D圖像領域自監督與對比學習技術成熟:ImageNet預訓練、DenseCL等。
-
2D CNN具備高分辨率處理能力,可為3D任務提供豐富的特征。
-
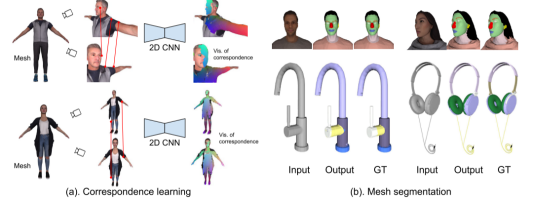
MvDeCor 方法概覽
核心思想:利用多視圖渲染的2D圖像,在像素級別建立密集對應,通過自監督對比學習訓練2D CNN,再將2D嵌入聚合為3D分割。
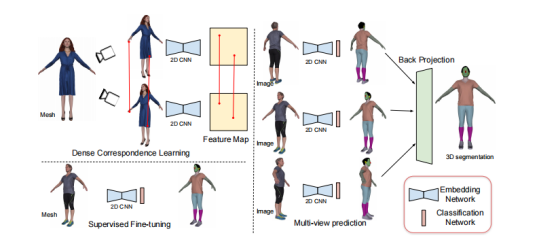
主要流程:
-
多視圖渲染:從多個視角渲染3D模型,生成RGB圖、深度圖、法線圖,以及對應的三角形索引。
-
密集對應采樣:利用光線追蹤記錄像素對應的3D點,在不同視圖中找到落在同一3D點鄰域內的像素對。
-
對比學習預訓練:基于InfoNCE損失,鼓勵匹配像素嵌入相似,不匹配像素嵌入相異。
-
少量標注微調:在有限的帶標簽3D模型上,對預訓練網絡添加分割頭,結合交叉熵與輔助自監督正則化訓練。
-
多視圖加權投票聚合:計算每個視圖的熵權重,將2D分割結果反投影到3D三角面片,進行加權多數投票,得到最終3D語義標簽。
關鍵技術細節
1. 自監督對比學習
-
嵌入網絡Φ:基于 DeepLabV3+,輸出 H×W×64 的像素級特征。
-
正負樣本構造:
-
正樣本:同一3D點投影到兩視圖的像素對 (p,q)。
-
負樣本:同視圖內其他像素與跨視圖的不匹配像素。
-
-
InfoNCE損失:
?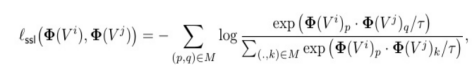
-
溫度系數τ = 0.07
-
每對視圖采樣 ≥4K匹配點對,視圖重疊 ≥15%
-
2. 微調與正則化
-
監督損失:多視圖交叉熵 ?sl\ell_{sl}。
-
輔助損失:保留 ?ssl\ell_{ssl} 正則項,權重λ = 0.001。
-
優化策略:Adam, 初始LR=0.001, 驗證損失飽和時LR衰減0.5,批量歸一化 + ReLU + 雙線性上采樣。
3. 熵加權投票聚合
-
視圖權重:
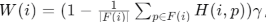
-
最終標簽:
lt=arg?max?c∈C∑I∈It,p∈tW(I,p)p(I,p)lt=argmaxc∈C?∑I∈It?,p∈t?W(I,p)p(I,p),
實驗驗證
| 數據集 | 預訓練方式 | 微調方式 | mIoU (%) | 相對提升 |
|---|---|---|---|---|
| PartNet (K=10) | DenseCL (2D) | 2D CNN微調 | 30.3 | +? |
| PointContrast (3D) | 3D CNN微調 | 31.0 | +1.6 | |
| MvDeCor (Ours) | 2D自監督+微調 | 35.9 | +4.0 | |
| RenderPeople (K=5,V=3) | ImageNet (RGB) | 2D微調 | ? | ? |
| MvDeCor (RGB) | 2D自監督+微調 | ? | ? |
應用與拓展
-
3D內容編輯:細粒度分割可用于精確選取模型局部進行紋理、變形、物理仿真等處理。
-
動畫與影視制作:自動分割減少藝術家手工標注成本,加速流水線。
-
虛擬試衣與電商:人像模型分割助力服裝、配飾的精準試穿效果。
-
機器人抓取與仿真:識別可抓取部件,實現更精細的操作策略。
結語與展望
MvDeCor 提出了將 2D 自監督對比學習與 3D 分割任務相結合的全新范式,顯著提升了少樣本條件下的細粒度分割性能。未來,可進一步探索:
-
視圖選擇優化:自動化選擇最具信息量的視角,降低冗余計算。
-
3D-2D 互補學習:融合 3D 點云/體素的自監督損失,強化空間幾何先驗。
-
跨域遷移:將 MvDeCor 應用于室內場景、醫療影像、遙感等多領域。














![[ctfshow web入門] web68](http://pic.xiahunao.cn/[ctfshow web入門] web68)




詳解)