數據分析涉及不同業務系統時就要做跨庫計算,而表間 JOIN 是最麻煩的,很多數據庫都不具備這樣的能力,用 Java 取數再計算又太復雜。用 esProc 完成跨庫 JOIN 會簡單很多。
數據與用例
車輛管理系統(DB_Vehicle)保存了車輛與車主等相關信息,其中車主信息表 owner_info 表結構簡化如下:

主鍵 owner_id 是車主身份證號。
車輛表 vehicle_master 簡化結構如下:
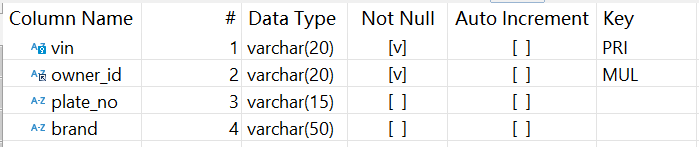
vin 設為主鍵,plate_no 也是唯一的,兩個字段在邏輯上都可以視為主鍵。
交管系統(DB_Traffic)存儲了車輛交通信息,其中違章記錄表 traffic_violation 結構如下:
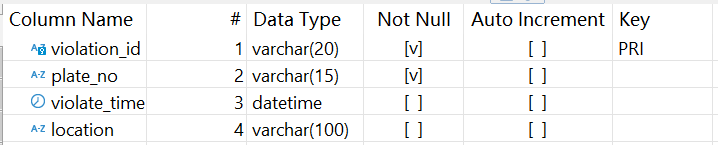
公民信息系統(DB_CitizenEvent)存儲了公民相關信息,其中公民事件表 citizen_event 結構如下:
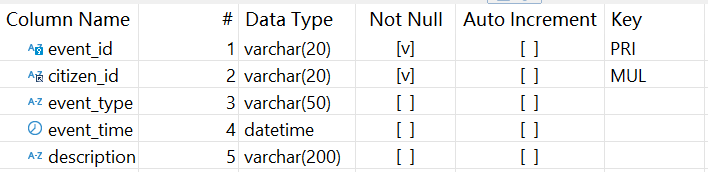
4 個表間邏輯關系簡單描述是這樣的:
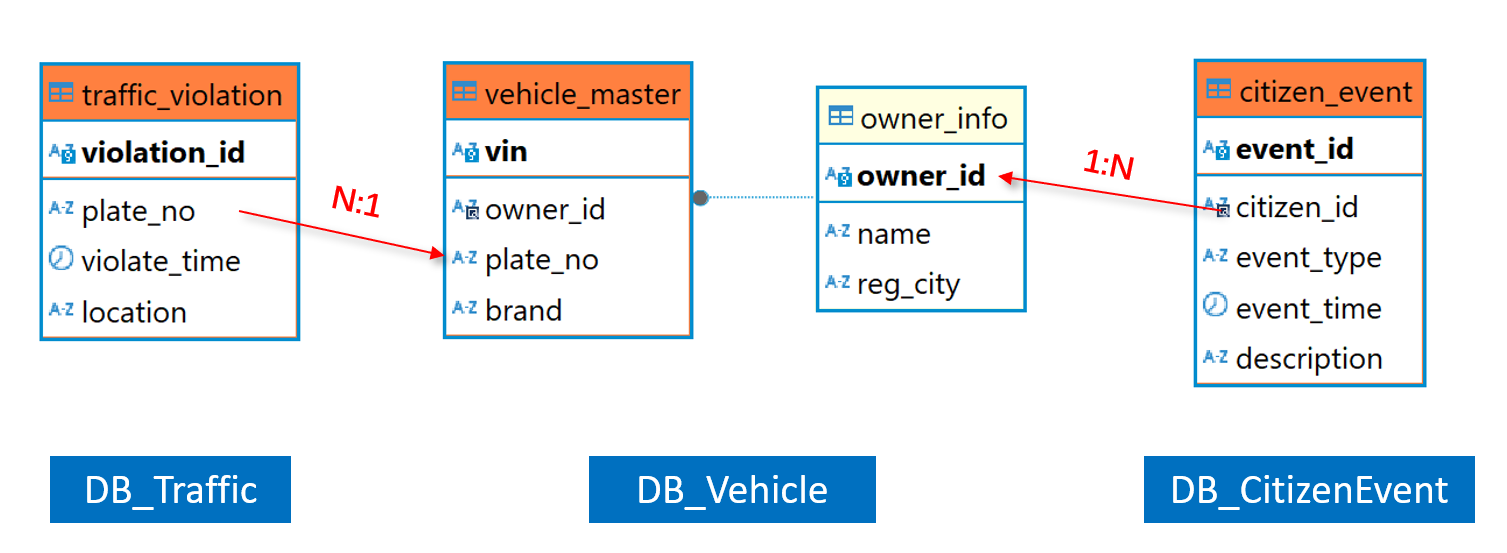
從邏輯上看,citizen_event 是 owner_info 是多對一的關系,作為維表的 owner_info 的規模要遠小于 citizen_event。
traffic_violation 和 vehicle_master 這兩個表也是一對多的關系,規模都可能很大,從后者的角度來看,traffic 更像一個子表,這兩個表構成主子關系(plato_no 是 vehicle 表的邏輯主鍵)。
為什么要區分表間關系呢?
日常的等值 JOIN 基本都會涉及主鍵(多對多的關聯基本沒有業務意義),大體可以分為兩種:維表關聯是一種,是普通字段和維表的主鍵關聯(如 citizen_event 和 owner_info);另一種是某個表的主鍵與另一個表的主鍵或部分主鍵的關聯(如 vehicle_master 和 traffic_violation,traffic_violation 表中,可以把 plate_no 和 violation_id 視為共同主鍵,即 violation_id 是從屬于 plate_no 的)。
esProc 在做 JOIN 運算時會根據不同的關聯情況選擇不同的方法,簡化編碼的同時還能提升計算效率。這里先有個印象就可以,來看具體例子。
要做這樣幾個計算:
1. 按城市統計最近一年有車公民的事件數量,用于分析各城市有車人的“行為活躍度”
2. 找出近一年獲得表彰(Commendation)的車主姓名和事件描述,用以識別“優秀市民”
3. 按年份和品牌統計車輛違章次數,用于分析某些品牌的車是否更容易違章,用于駕駛行為和車輛品牌的關聯研究
如果這些表在同一個數據庫,用 SQL 寫這些運算并不困難,大概是這樣:
1. SELECT o.city, COUNT(e.event_id) AS event_count
FROM citizen_event e
JOIN owner_info o ON e.citizen_id = o.citizen_id
WHERE e.event_time >= DATE_SUB(CURDATE(), INTERVAL 1 YEAR)
GROUP BY o.city
ORDER BY event_count DESC;2. SELECT o.name AS citizen_name, e.description
FROM citizen_event e
JOIN owner_info o ON e.citizen_id = o.citizen_id
WHERE e.event_type = 'Commendation'AND e.event_time >= DATE_SUB(CURDATE(), INTERVAL 1 YEAR);3. SELECT YEAR(v.violate_time) AS year, vi.brand, COUNT(v.violation_id) AS violation_count
FROM traffic_violation v
JOIN vehicle_info vi ON v.plate_no = vi.plate_no
GROUP BY YEAR(v.violate_time), vi.brand
ORDER BY year, violation_count DESC;但如果跨庫時就麻煩很多了。
安裝 esProc
先通過點擊下載免費的esProc標準版?
安裝后,配數據庫連接,這里三個數據庫都是 MySQL。
先把 MySQL JDBC 驅動包放到 [esProc 安裝目錄]\common\jdbc 目錄下(其他數據庫類似)。
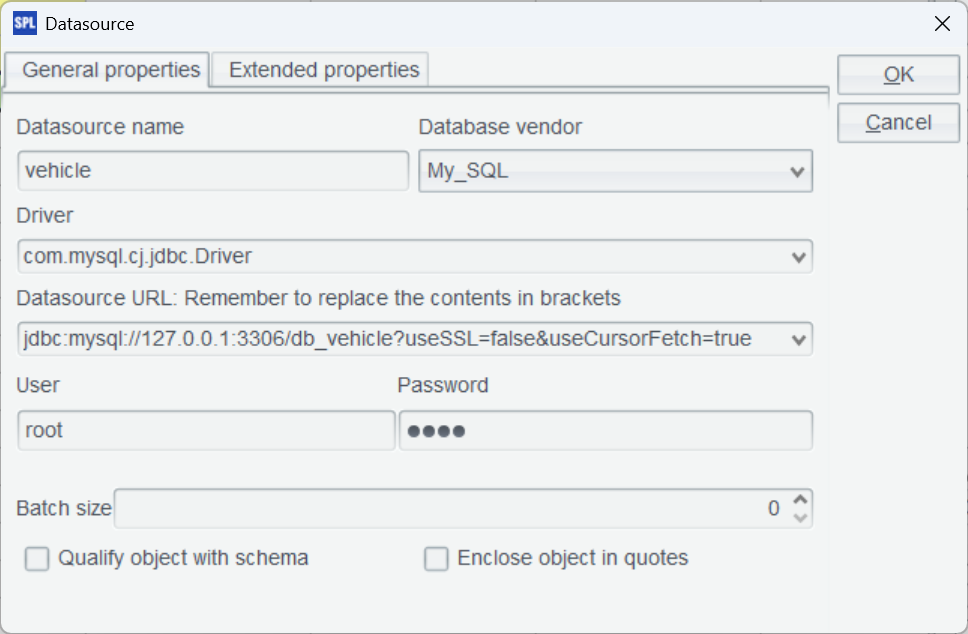
然后啟動 esProc IDE,菜單欄選擇 Tool-Connect to Data Source,配置 MySQL 標準 JDBC 連接。
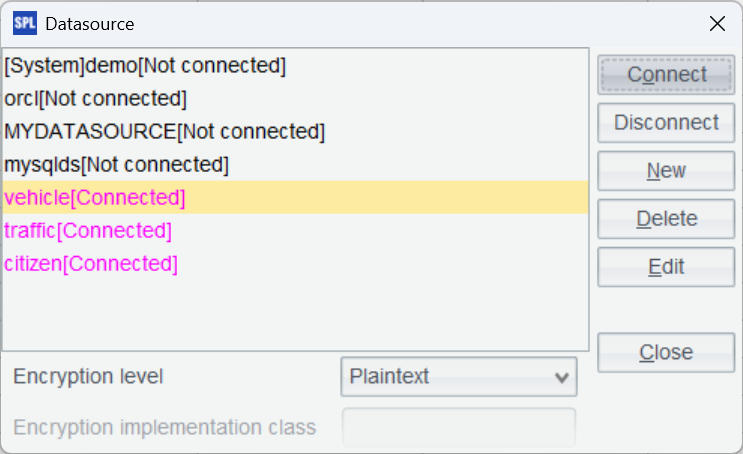
三個數據庫都采用如上方式配置,配置完成后,測試一下連接,點擊 Connect,發現剛剛配置的兩個數據源變成粉紅色證明連接成功。
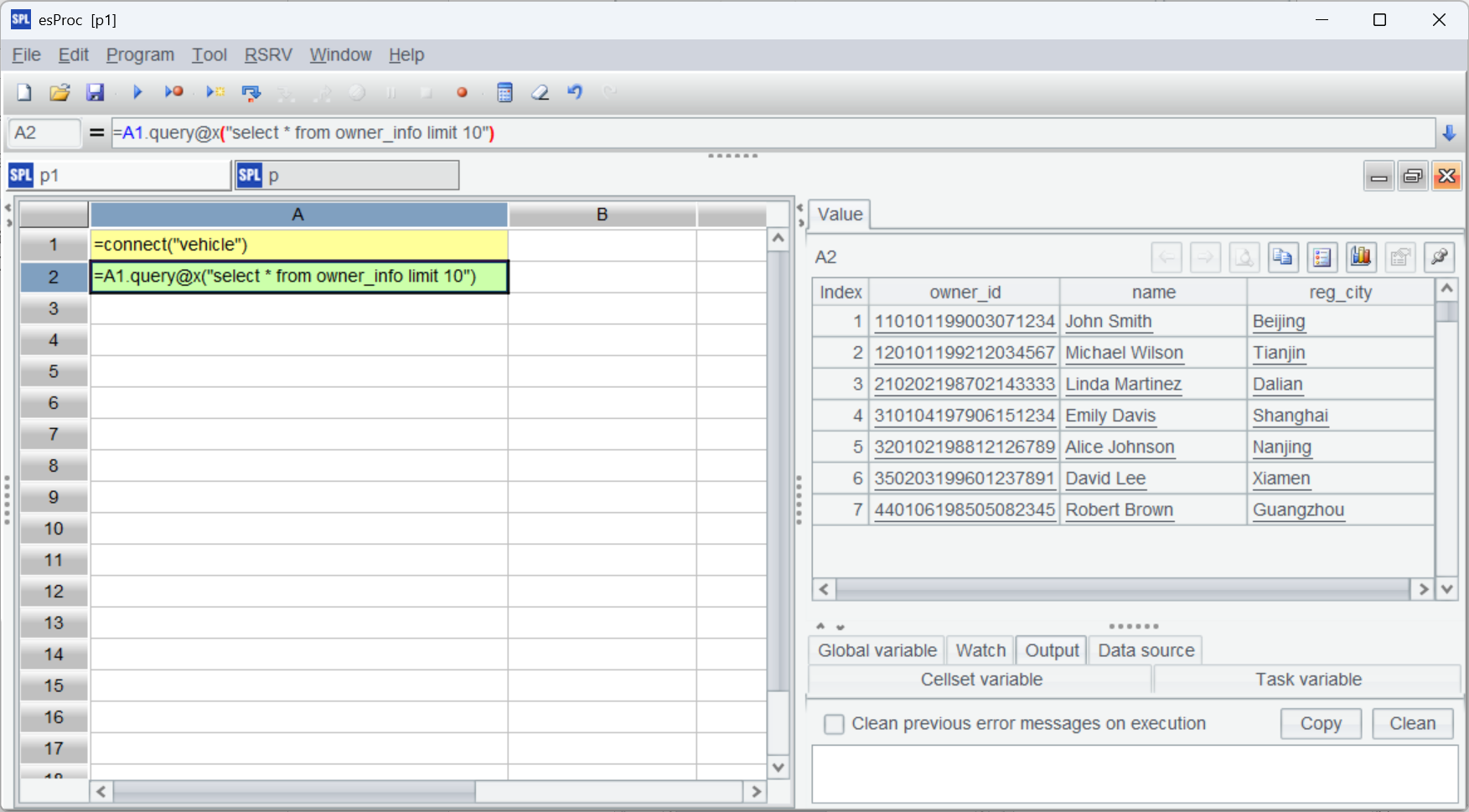
測試一下,按 ctrl+F9 執行腳本,可以正常查詢數據說明配置沒問題
用例實現
下面來實現前面第一個計算需求:按城市統計最近一年有車公民的事件數量。要關聯 owner_info 和 citizen_event 兩個表,也就是維表的關聯計算。
維表的關聯
esProc 實現:
| A | |
| 1 | =connect("vehicle") |
| 2 | =A1.query@x("select * from owner_info").keys@i(owner_id) |
| 3 | =connect("citizen") |
| 4 | =A3.query@x("select * from citizen_event where event_time >= DATE_SUB(CURDATE(), INTERVAL 1 YEAR)") |
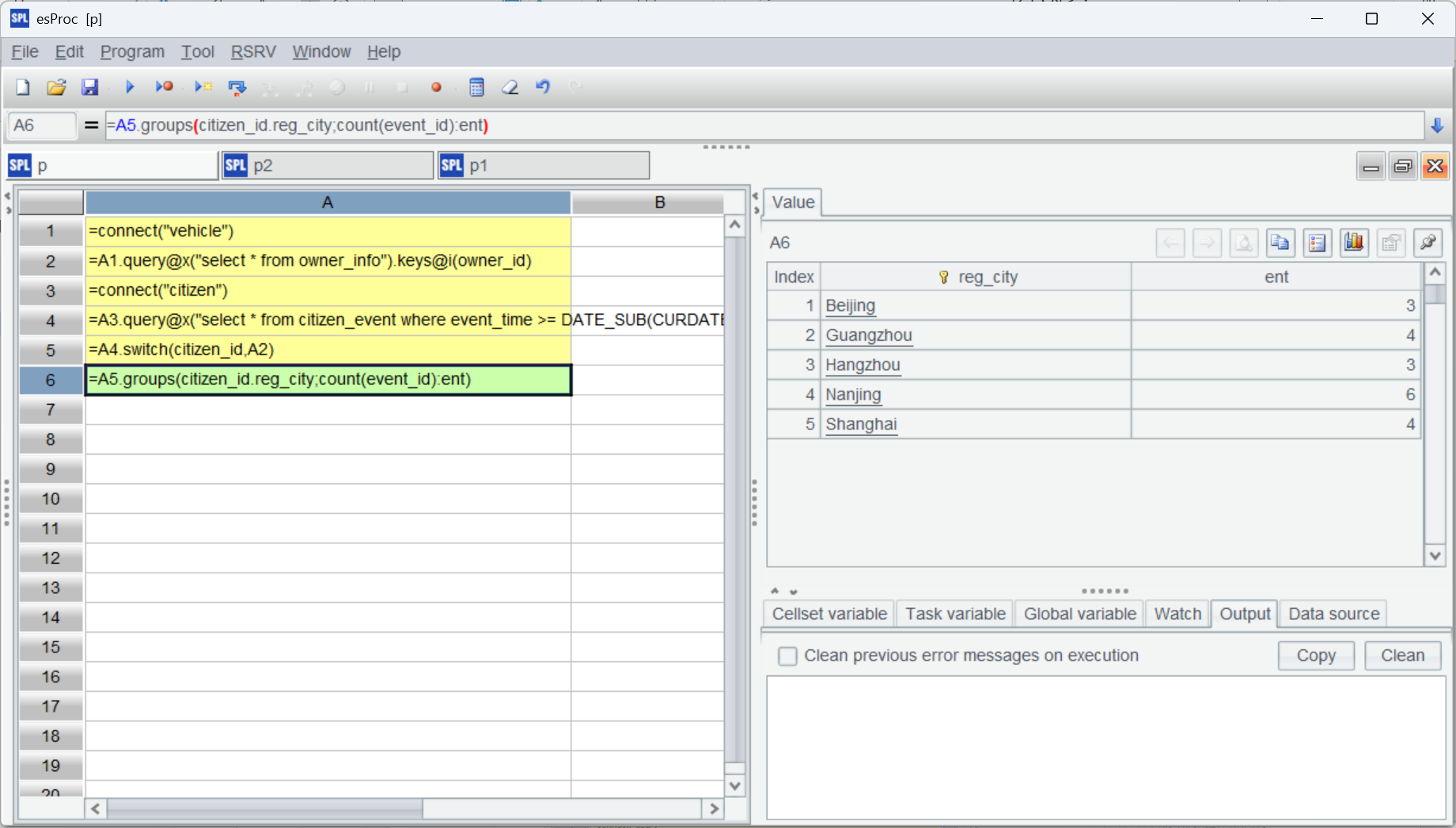
| 5 | =A4.switch(citizen_id,A2) |
| 6 | =A5.groups(citizen_id.reg_city;count(event_id):ent) |
A2 從 vehicle 庫查詢車主信息,query@x 表示數據全部加載內存后關閉數據庫連接,使用 keys@i 設置主鍵并建立索引,通常事實表會遠大于維表,這個索引會被復用很多次,能加快計算速度。
A4 查詢事件表,篩選最近一年的數據,都讀入內存。
A5 使用 switch 進行外鍵關聯。由于外鍵指向的維表記錄是唯一的,switch 直接將關聯字段 citizen_id 轉換成 A2 中的記錄(實際在內存中存儲的是維表記錄所在地址)。
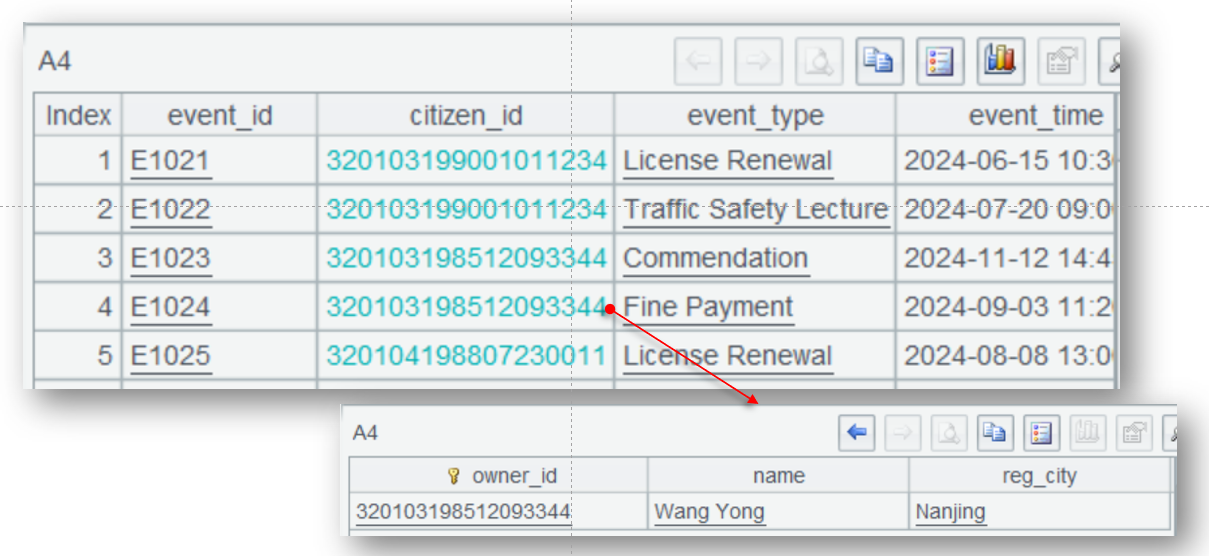
這種轉換是一次性的,后續可以重復使用,而且可以同時處理多個維表的外鍵關聯。關聯完成后通過“關聯字段. 維表字段”方式就能引用任意維表字段。A6 就通過 citizen_id.reg_city 獲得注冊地進行分組匯總。
整體運行如下:
接下來繼續:找出近一年獲得表彰的車主姓名和事件描述。
在前面代碼的基礎上增加:
| A | |
| … | … |
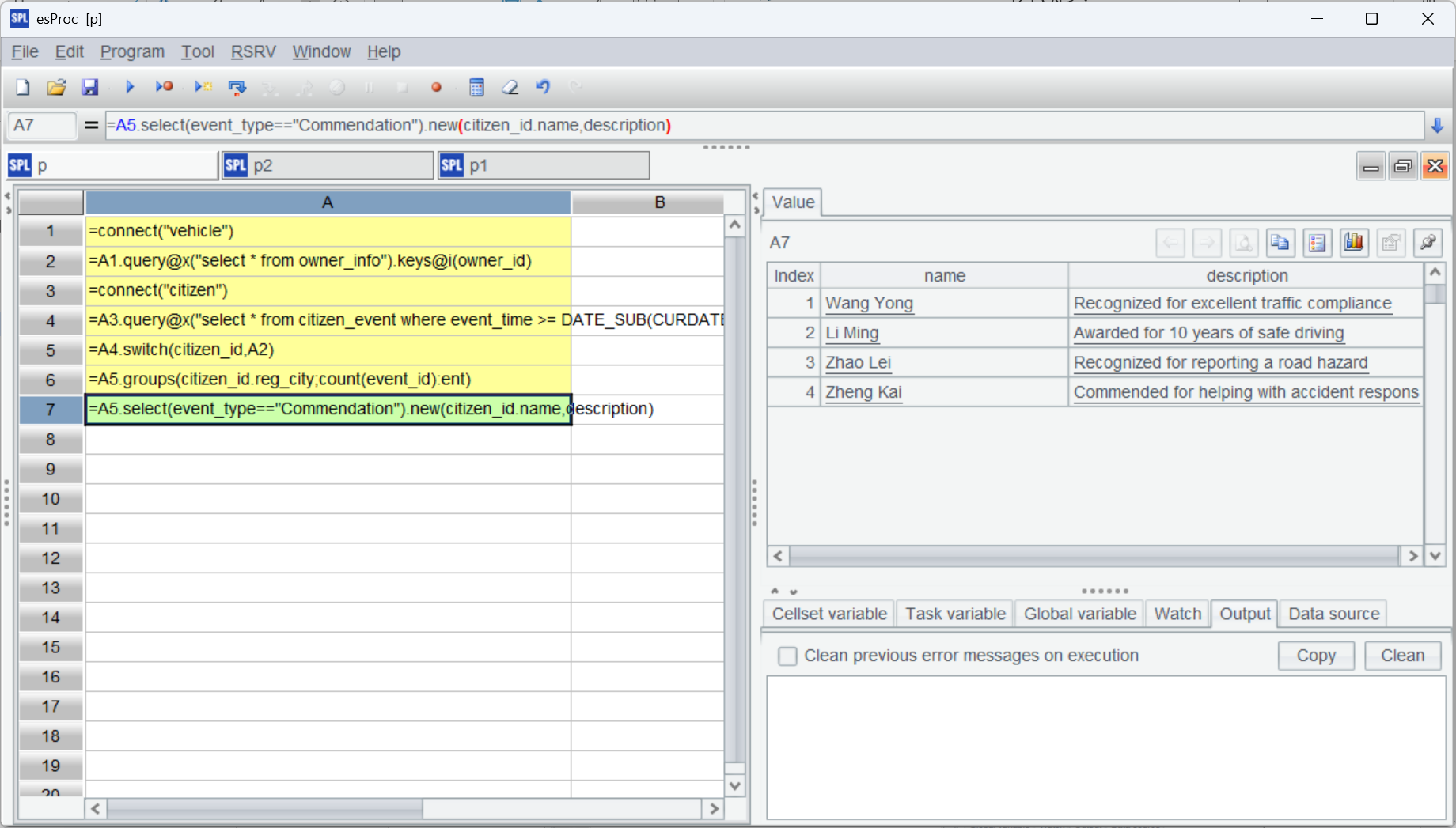
| 7 | =A5.select(event_type=="Commendation").new(citizen_id.name,description) |
還是基于 A5 的關聯結果進行計算,實現了復用。
這里我們再解釋一下,跨庫關聯很多數據庫本身就做不了,尤其是異構的情況。esProc 的這種關聯能力是與數據源無關的,什么庫都可以,甚至其他五花八門的數據源也都沒問題,這是其一。其二是,即使與單庫 JOIN 相比,esProc 顯著區分外鍵關系也有很大的好處。
書寫和理解上,通過點(.)操作符(類似對象. 屬性)就能引用外鍵表的所有字段,有多少層都可以(維表還可能有維表),也很容易表達自關聯 / 循環關聯的情況。
當 citizen_event 表的數據量很大時,用 esProc 仍然可以處理。不過,當數據量大到無法全部放進內存時,內存地址化方法就不再有效了,因為在外存無法保存事先算好的地址,這時就只能邊讀入邊地址化。
按城市統計所有車公民的事件數量:
| A | |
| 1 | =connect("vehicle") |
| 2 | =A1.query@x("select * from owner_info").keys@i(owner_id) |
| 3 | =connect("citizen") |
| 4 | =A3.cursor@x("select * from citizen_event") |
| 5 | =A4.switch(citizen_id,A2) |
| 6 | =A5.groups(citizen_id.reg_city;count(event_id):ent) |
與全內存的寫法大部分一樣,區別在 A4 使用 cursor 創建游標分批讀取數據。esProc 的游標是延遲游標,附加在游標上的計算等到最后取數時才會真正計算。
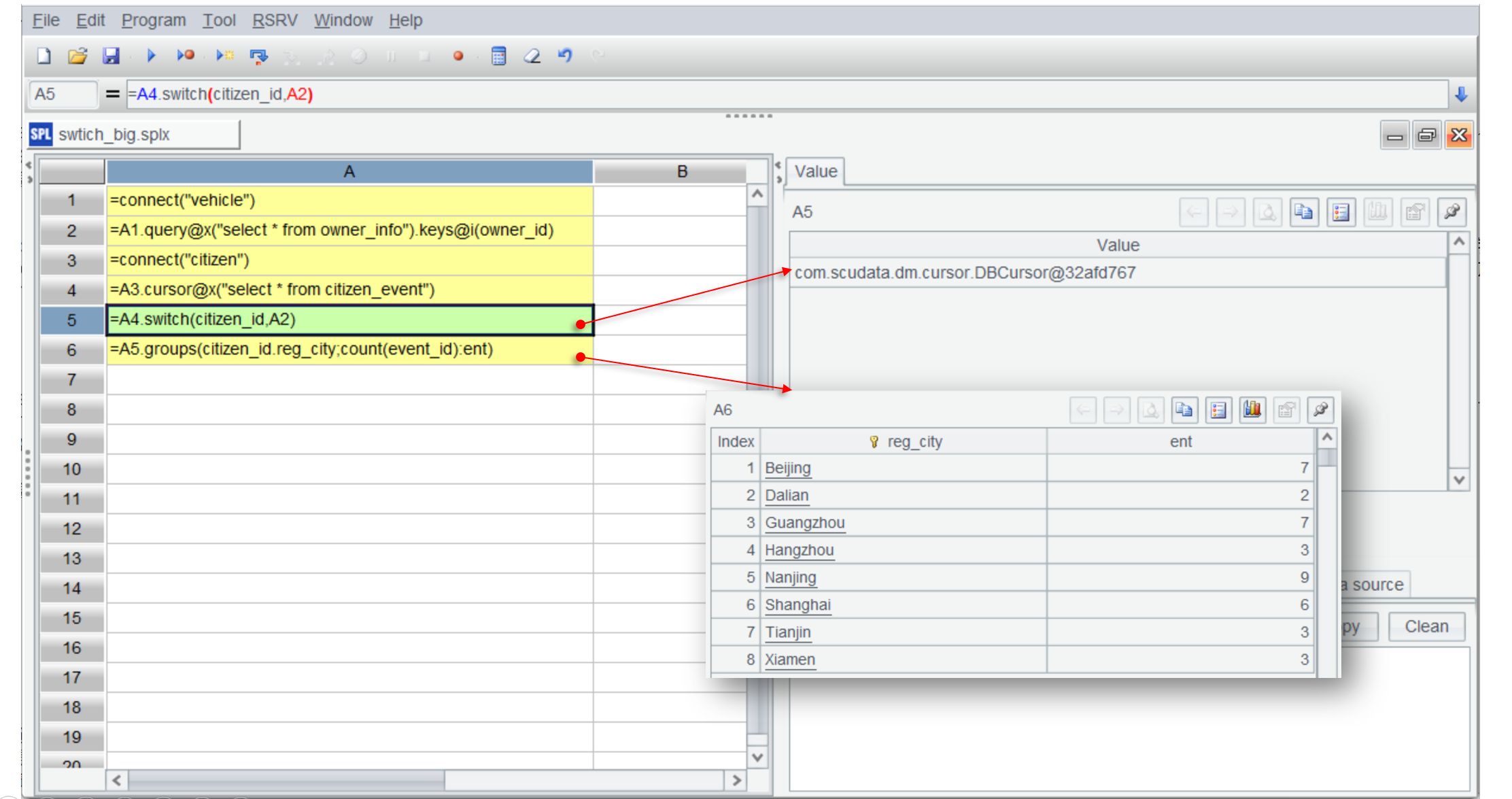
但游標是一次性的,如果想再進行其他計算,比如還要獲得表彰的車主。再基于 A5 計算是得不到結果的(注意 A7 的計算結果):
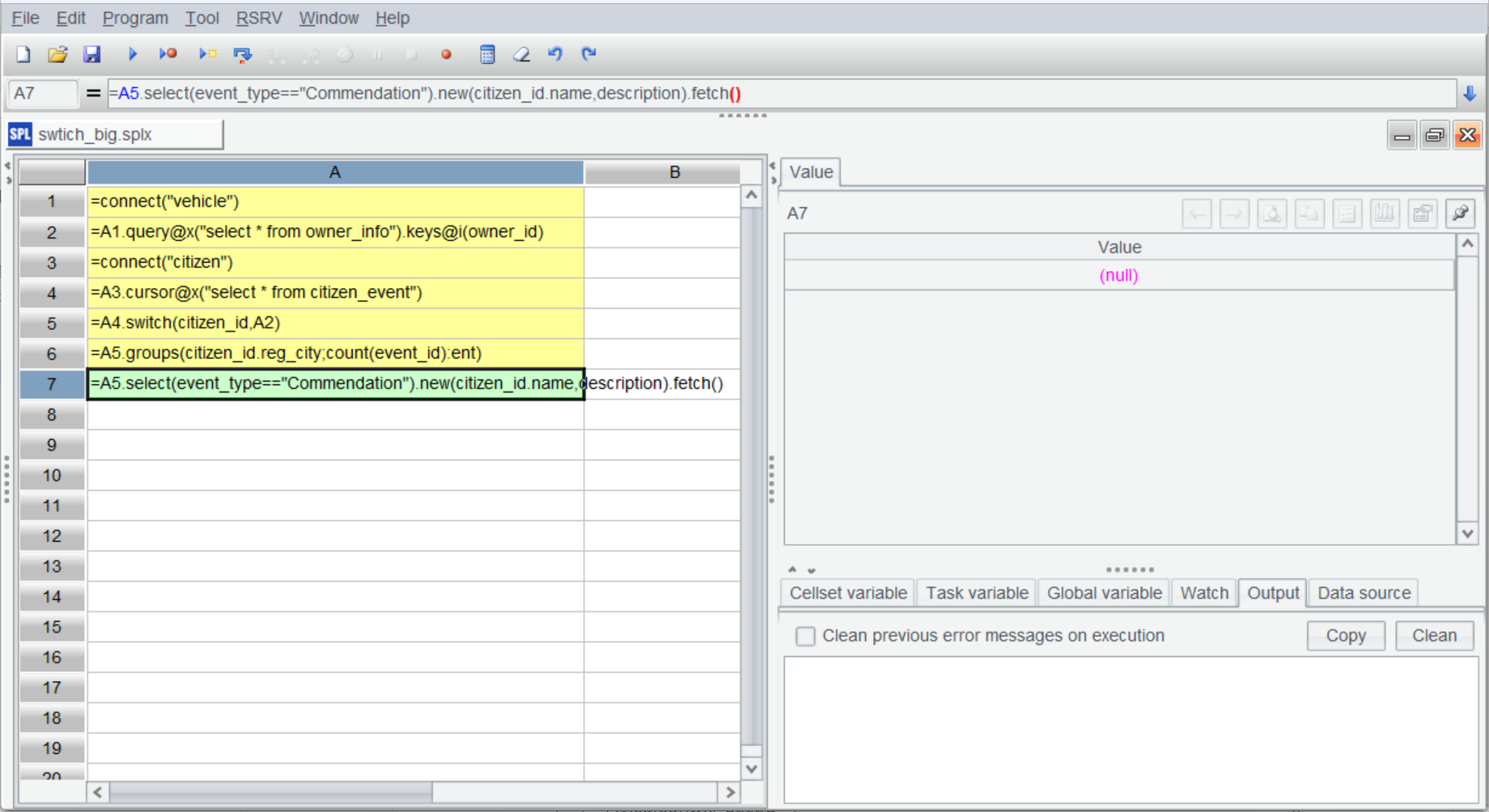
這時可以使用 esProc 提供的管道機制:
| A | B | |
| 1 | =connect("dba") | |
| 2 | =A1.cursor@x("SELECT * FROM orders WHERE EXTRACT(YEAR FROM order_date) = EXTRACT(YEAR FROM CURRENT_DATE) ORDER BY customer_id") | |
| 3 | =connect("dbc") | |
| 4 | =A3.query@x("SELECT * FROM customer").keys@i(customer_id) | |
| 5 | =A2.switch(customer_id,A4) | |
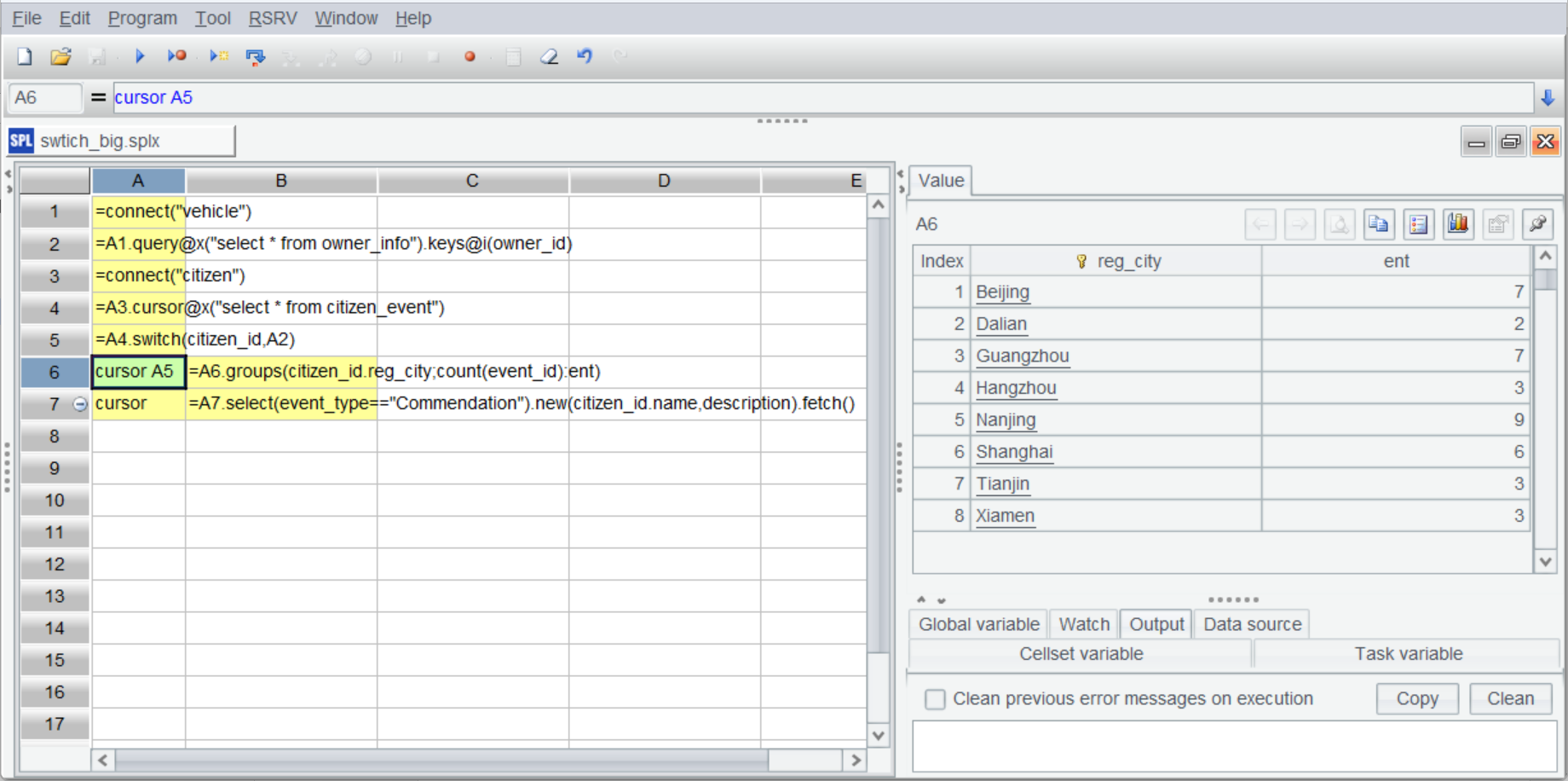
| 6 | cursor A5 | =A6.groups(customer_id.customer_level;count(1):order_count) |
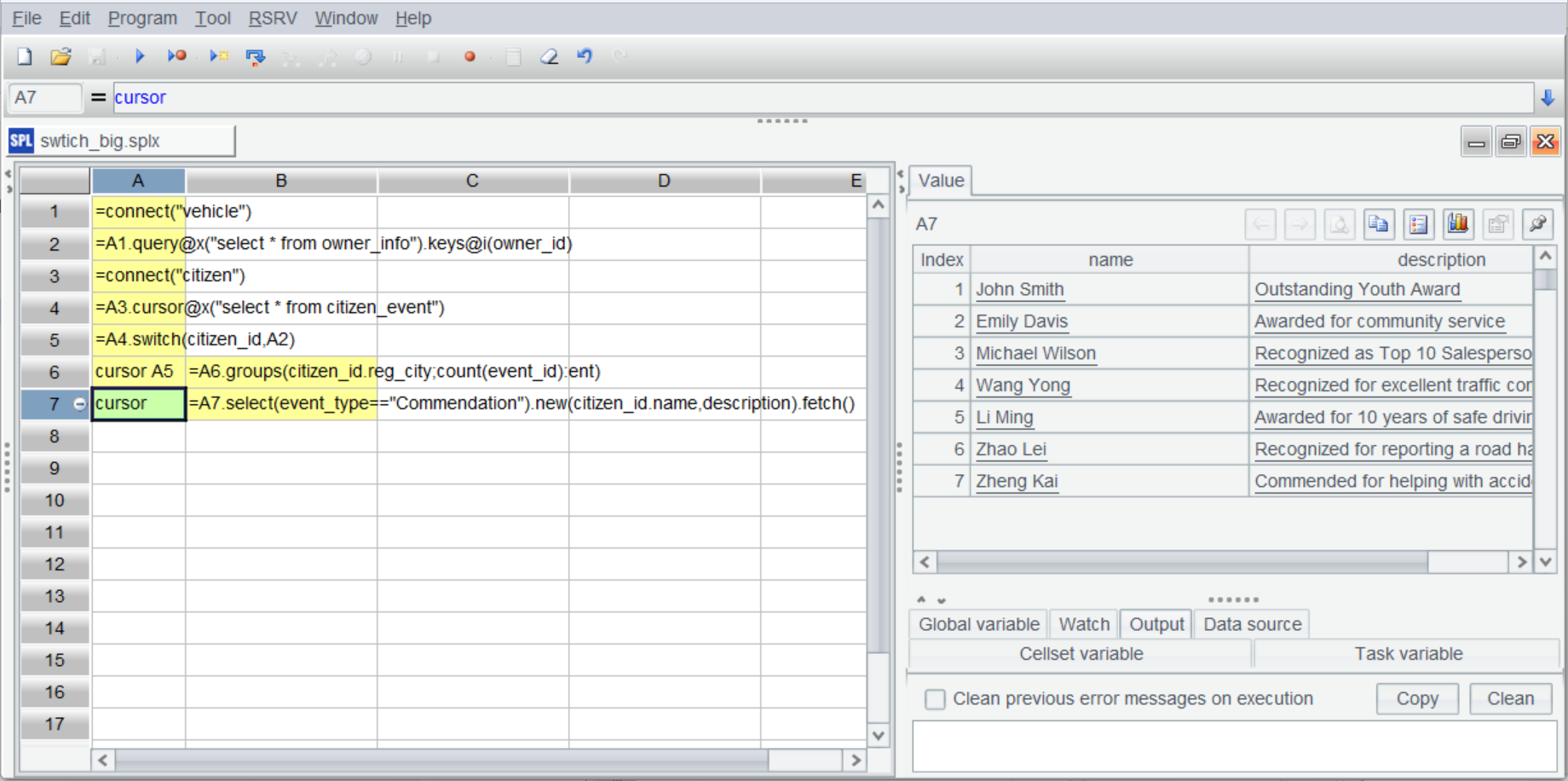
| 7 | cursor | =A7.group(customer_id).select(~.len()>1).conj().id(customer_id.customer_name) |
A6 和 A7 基于 A5 創建管道(A7 是簡化寫法),B6 基于管道進行分組匯總,結果返回給 A6:
B7 則根據另一個管道篩選獲得表彰的數據,A7 的結果:
主子表的關聯
按年份和品牌統計車輛違章次數。
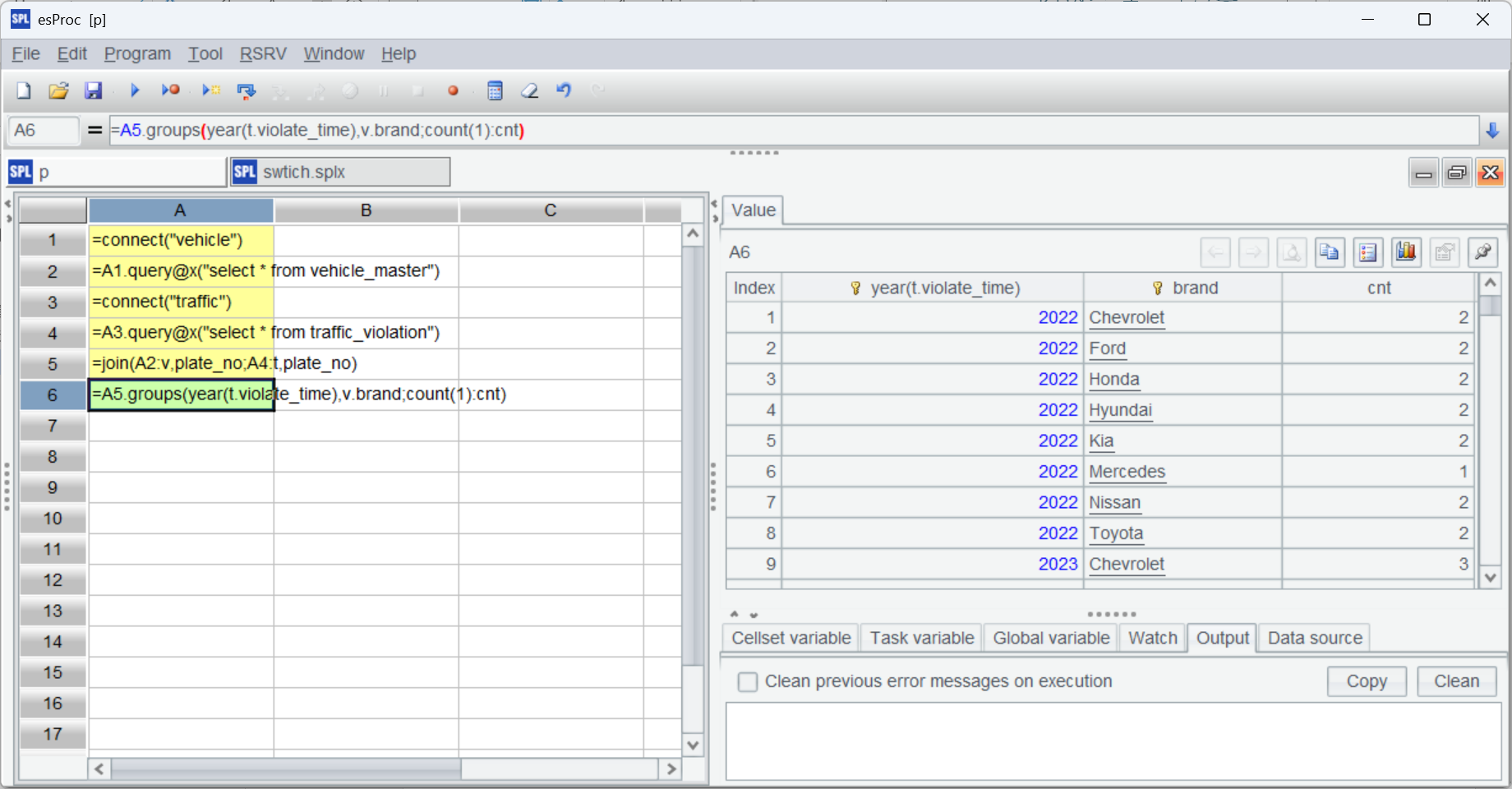
| A | |
| 1 | =connect("vehicle") |
| 2 | =A1.query@x("select * from vehicle_master") |
| 3 | =connect("traffic") |
| 4 | =A3.query@x("select * from traffic_violation") |
| 5 | =join(A2:v,plate_no;A4:t,plate_no) |
| 6 | =A5.groups(year(t.violate_time),v.brand;count(1):cnt) |
A5 使用 join 函數根據 plate_no 關聯了兩個表,其關聯結果是這樣的:
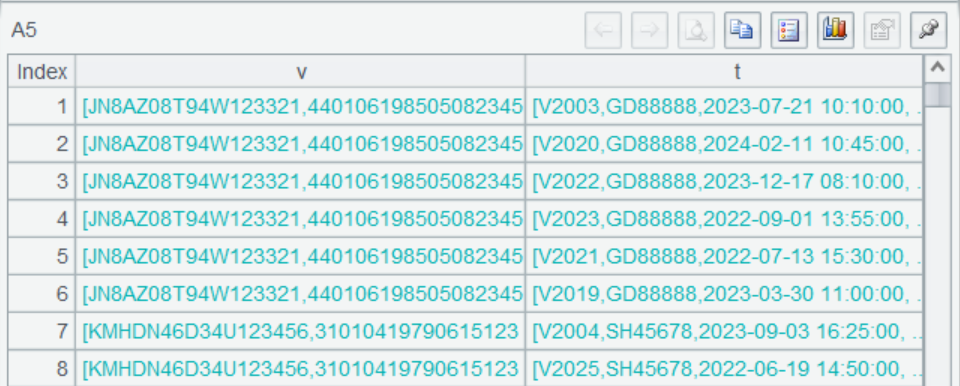
保留了兩邊完整記錄的多層集合,點開可以看到
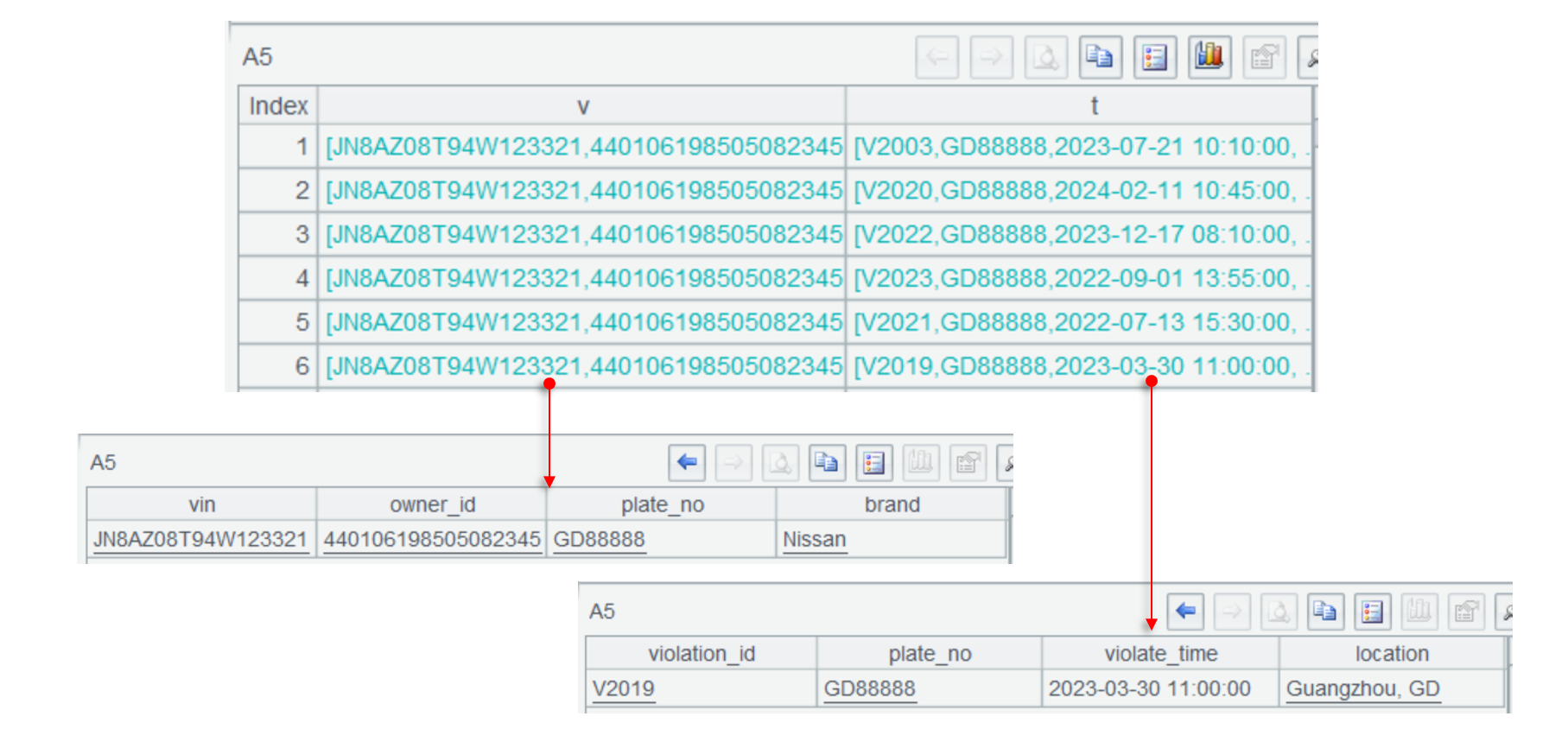
關聯完成后,A6 就能通過多層引用進行分組匯總。
處理主子表關聯時,我們使用了與外鍵關聯 switch 不同的 join 函數,join 函數提供了一些選項,@1 表示左連接,@f 表示全連接,@d 做差集等,用來滿足不同的連接需求。事實上,外鍵關聯也可以使用 join 函數來完成。
那為什么不統一用 join 呢?
這里我們看到的都是兩個表關聯,如果存在多個維表(大部分情況),使用 switch 可以將維表(維表可能還有維表)都附加到事實表上,但用 join 就很難表達這種層次關系,書寫也不方便。
主子表關聯時的兩個表可能都很大,利用表的關聯字段都是主鍵(或部分主鍵)的特性,可以采用有序歸并的算法一次遍歷就完成關聯。
按年份和品牌統計車輛違章次數:
| A | |
| 1 | =connect("vehicle") |
| 2 | =A1.cursor@x("select * from vehicle_master order by plate_no") |
| 3 | =connect("traffic") |
| 4 | =A3.cursor@x("select * from traffic_violation order by plate_no") |
| 5 | =joinx(A2:v,plate_no;A4:t,plate_no) |
| 6 | =A5.groups(year(t.violate_time),v.brand;count(1):cnt) |
A2 和 A4 使用 cursor 創建游標,里面的 SQL 都對 plate_no 排序。
A5 使用 joinx 做有序歸并,返回的仍是游標。剩下的代碼就跟全內存時一樣了。
有序遍歷利用了關聯鍵有序的特性,只適用于主子表的關聯(可對主鍵有序),但不適用于前面那種維表的外鍵關聯。因為同一個表上可能有多個要參與關聯的外鍵字段,不可能讓同一個表同時針對多個字段都有序。這也是區分 JOIN 后采用了不同函數(算法)的原因。
總體來看,esProc 不僅能輕松實現跨庫關聯,還提供了不同關聯場景的實現算法,簡單區分后就能獲得明顯的編碼效率和運算效率的提升。














![[論文閱讀]MCP Guardian: A Security-First Layer for Safeguarding MCP-Based AI System](http://pic.xiahunao.cn/[論文閱讀]MCP Guardian: A Security-First Layer for Safeguarding MCP-Based AI System)




