文章目錄
- 前言
- R-CNN
- Fast R-CNN
- 興趣區域匯聚層 (RoI Pooling)
- 代碼示例:興趣區域匯聚層 (RoI Pooling) 的計算方法
- Faster R-CNN
- Mask R-CNN
- 雙線性插值 (Bilinear Interpolation) 與興趣區域對齊 (RoI Align)
- 興趣區域對齊層的輸入輸出
- 全卷積網絡 (FCN) 的作用
- 掩碼輸出形狀
- 總結
前言
歡迎來到“從代碼學習深度學習”系列博客!在計算機視覺領域,目標檢測是一個核心任務,它不僅要求我們識別圖像中的物體,還需要定位它們的位置。區域卷積神經網絡(Region-based Convolutional Neural Networks, R-CNN)及其后續改進版本(Fast R-CNN, Faster R-CNN, Mask R-CNN)是解決這一問題的里程碑式工作。它們逐步提高了目標檢測的準確性和效率,并擴展到實例分割等更復雜的任務。
本篇博客將帶你回顧 R-CNN 系列模型的發展歷程,并通過 PyTorch 代碼示例(重點在興趣區域匯聚層)來理解其核心組件的工作原理。我們將從最初的 R-CNN 開始,逐步探索其改進版本,理解它們是如何解決前代模型的瓶頸,并引入新的創新思想的。
完整代碼:下載鏈接
R-CNN
R-CNN (Regions with CNN features) 是將深度學習應用于目標檢測領域的開創性工作之一。它的核心思想是利用卷積神經網絡(CNN)提取區域特征,從而進行目標分類和定位。
R-CNN 的第一步是從整張圖像中挑選出可能包含物體的小區域,稱為“候選區域”或“提議區域”(region proposals)。這些區域是由 Selective Search 這類算法選出來的,不是通過滑動窗口或CNN直接得到的。數量大約為2000個。(注:錨框是Faster R-CNN等后續方法的技術,R-CNN并不使用錨框。)R-CNN通過先選出可能含目標的圖像區域,對這些區域單獨用CNN提取特征,再用這些特征去判斷目標種類和更精準的位置。
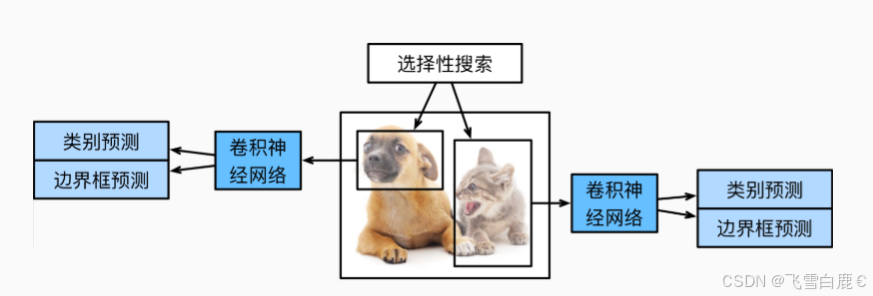
上圖展示了R-CNN模型。具體來說,R-CNN包括以下四個步驟:
- 對輸入圖像使用_選擇性搜索_(Selective Search)來選取多個高質量的提議區域。這些提議區域通常是在多個尺度下選取的,并具有不同的形狀和大小。每個提議區域都將被標注類別和真實邊界框。
- 選擇一個預訓練的卷積神經網絡,并將其在輸出層之前截斷。將每個提議區域變形為網絡需要的輸入尺寸,并通過前向傳播輸出抽取的提議區域特征。
- 將每個提議區域的特征連同其標注的類別作為一個樣本。訓練多個支持向量機(SVM)對目標分類,其中每個支持向量機用來判斷樣本是否屬于某一個類別。
- 將每個提議區域的特征連同其標注的邊界框作為一個樣本,訓練線性回歸模型來預測真實邊界框。
盡管R-CNN模型通過預訓練的卷積神經網絡有效地抽取了圖像特征,但它的速度很慢。因為可能從一張圖像中選出上千個提議區域,這需要上千次的卷積神經網絡的前向傳播來執行目標檢測。這種龐大的計算量使得R-CNN在現實世界中難以被廣泛應用。
Fast R-CNN
針對 R-CNN 的速度瓶頸,Fast R-CNN 提出了關鍵改進。R-CNN的主要性能瓶頸在于,對每個提議區域,卷積神經網絡的前向傳播是獨立的,而沒有共享計算。由于這些區域通常有重疊,獨立的特征抽取會導致重復的計算。Fast R-CNN 對R-CNN的主要改進之一,是僅在整張圖象上執行卷積神經網絡的前向傳播。
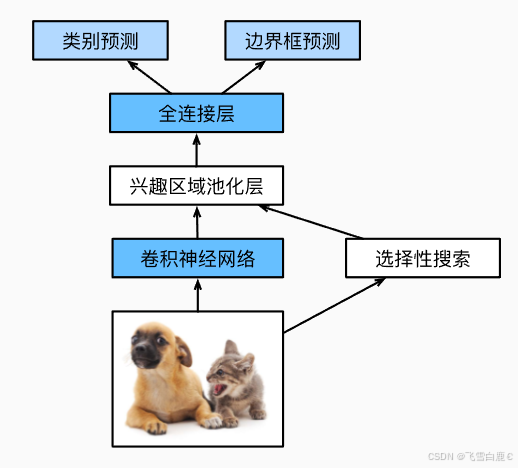
上圖中描述了Fast R-CNN模型。它的主要計算如下:
- 與R-CNN相比,Fast R-CNN用來提取特征的卷積神經網絡的輸入是整個圖像,而不是各個提議區域。此外,這個網絡通常會參與訓練。設輸入為一張圖像,將卷積神經網絡的輸出的形狀記為1×c×h1×w1。
- 假設選擇性搜索生成了n個提議區域。這些形狀各異的提議區域在卷積神經網絡的輸出上分別標出了形狀各異的興趣區域。然后,這些感興趣的區域需要進一步抽取出形狀相同的特征(比如指定高度h2和寬度w2),以便于連結后輸出。為了實現這一目標,Fast R-CNN引入了_興趣區域匯聚層_(RoI pooling):將卷積神經網絡的輸出和提議區域作為輸入,輸出連結后的各個提議區域抽取的特征,形狀為n×c×h2×w2。
- 通過全連接層將輸出形狀變換為n×d,其中超參數d取決于模型設計。
- 預測n個提議區域中每個區域的類別和邊界框。更具體地說,在預測類別和邊界框時,將全連接層的輸出分別轉換為形狀為n×q(q是類別的數量)的輸出和形狀為n×4的輸出。其中預測類別時使用softmax回歸。
興趣區域匯聚層 (RoI Pooling)
在匯聚層中,我們通過設置匯聚窗口、填充和步幅的大小來間接控制輸出形狀。而興趣區域匯聚層對每個區域的輸出形狀是可以直接指定的。
例如,指定每個區域輸出的高和寬分別為h2和w2。對于任何形狀為h×w的興趣區域窗口,該窗口將被劃分為h2×w2子窗口網格,其中每個子窗口的大小約為(h/h2)×(w/w2)。在實踐中,任何子窗口的高度和寬度都應向上取整,其中的最大元素作為該子窗口的輸出。因此,興趣區域匯聚層可從形狀各異的興趣區域中均抽取出形狀相同的特征。
代碼示例:興趣區域匯聚層 (RoI Pooling) 的計算方法
下面我們通過一段 PyTorch 代碼來演示興趣區域匯聚層 (RoI Pooling) 的計算方法。
# 演示興趣區域匯聚層(ROI Pooling)的計算方法
import torch # 導入PyTorch庫
import torchvision # 導入PyTorch視覺庫# 創建一個4×4的特征圖張量作為CNN抽取的特征
# torch.arange(16.) 創建一個包含0到15的一維浮點數張量,維度為[16]
# reshape(1, 1, 4, 4) 將張量重塑為4維張量,維度為[1, 1, 4, 4]
# 第一個維度: 批次大小(batch size) = 1
# 第二個維度: 通道數(channels) = 1
# 第三個維度: 高度(height) = 4
# 第四個維度: 寬度(width) = 4
X = torch.arange(16.).reshape(1, 1, 4, 4)
X[:


)








使用教程第六講)
算法)



: 安裝 repo 命令)

