一、技術背景
隨著大語言模型(LLM)的飛速發展,如何更高效、更靈活地駕馭這些強大的模型生成我們期望的內容,成為了開發者們面臨的重要課題。傳統的通過拼接字符串、管理復雜的狀態和調用 API 的方式,在處理復雜任務時顯得力不從心。正是在這樣的背景下,SGlang (Structured Generation Language) 應運而生,它旨在成為連接用戶意圖與 LLM 生成能力之間的橋梁,提供一種更高效、更具控制力的 LLM 交互方式
二、SGlang 介紹
2.1 核心概念
SGLang 的核心概念圍繞著如何將復雜的 LLM 生成任務分解和控制:
-
SGLang 程序 (SGLang Program): 這是 SGLang 的基本執行單元。一個 SGLang 程序定義了一系列與 LLM 交互的指令和邏輯。
-
生成原語 (Generation Primitives): SGLang 提供了一系列內置的指令,用于控制 LLM 的文本生成。這些原語包括:
gen:用于生成文本。select:用于從多個選項中選擇一個。capture:用于捕獲 LLM 生成的特定部分內容。 -
控制流 (Control Flow): SGLang 支持類似傳統編程語言的控制流結構,如條件判斷(
if/else)、循環(for)等。這使得開發者可以根據 LLM 的中間生成結果動態地調整后續的生成策略。 -
并行執行 (Parallel Execution): SGLang 允許并行執行多個生成任務或生成分支,從而提高效率。
-
狀態管理 (State Management): SGLang 程序可以維護狀態,并在不同的生成步驟之間傳遞信息。
-
模板化 (Templating): 支持靈活的文本模板,方便構建動態的提示。
2.2 組成部分
一個典型的 SGLang 系統通常包含以下幾個關鍵組成部分:
-
SGLang 語言解釋器/編譯器 (SGLang Interpreter/Compiler): 負責解析和執行 SGLang 程序。它將 SGLang 代碼轉換為對底層 LLM 運行時的操作序列。
-
LLM 運行時 (LLM Runtime): 這是實際執行 LLM 推理的部分。SGLang 旨在與多種不同的 LLM 后端(如 vLLM、Hugging Face Transformers 等)集成。SGLang 的運行時優化是其核心優勢之一,它通過將控制流直接卸載到 KV 緩存中,實現了高效的執行。
-
SGLang API/SDK: 提供給開發者的接口,用于編寫、部署和管理 SGLang 程序。
2.3 關鍵技術
SGLang 的實現依賴于以下一些關鍵技術:
-
基于提示的執行 (Prompt-based Execution with Advanced Control): 雖然仍然以提示為基礎,但 SGLang 通過其語言結構提供了更高級別的控制。
-
KV 緩存優化 (KV Cache Optimization): 這是 SGLang 實現高性能的關鍵。傳統的 LLM 調用在每次生成時都需要重新計算和填充 KV 緩存(鍵值緩存,用于存儲注意力機制的中間結果)。SGLang 通過將控制邏輯(如
if/else,for循環,select)直接在 KV 緩存層面進行管理和復用,顯著減少了冗余計算和數據傳輸,從而大幅提升了執行速度,特別是在需要復雜控制流和多輪交互的場景下。 -
Radix Tree (基數樹) 和 Token Healing: 用于高效地管理和重用提示(prompts)以及修復因 tokenization 邊界問題導致的生成不連貫的情況。Radix Tree 允許多個并發請求共享和重用共同的前綴提示,從而節省了重復處理的時間和內存。Token Healing 則用于確保在
select或其他需要精確匹配的場景下,即使 LLM 的生成結果在 token 邊界上與預期不完全一致,也能進行有效的校正。 -
與后端 LLM 推理引擎的緊密集成: SGLang 不是一個獨立的 LLM,而是一個運行在現有 LLM 推理引擎之上的控制層。它通過與 vLLM 等高性能推理后端的深度集成,充分利用這些后端的優化能力。
-
聲明式與命令式編程的結合: SGLang 允許開發者以聲明式的方式定義生成目標(例如,生成一個 JSON 對象),同時也提供了命令式的控制流結構來指導生成過程。
2.4 優勢與價值
SGLang 為開發者和應用帶來了顯著的優勢和價值:
-
顯著的性能提升 (Significant Performance Improvement): 通過 KV 緩存優化、Radix Tree 和并行執行等技術,SGLang 可以大幅度提高 LLM 應用的吞吐量并降低延遲,尤其是在需要復雜交互和控制流的任務中(例如,多輪對話、結構化數據生成、Agent 模擬等)。有報告稱其速度比傳統方法快幾倍甚至幾十倍。
-
增強的可控性 (Enhanced Controllability): 開發者可以更精確地控制 LLM 的生成過程,包括強制輸出格式、實現條件邏輯、從多個選項中進行選擇等。這使得構建更可靠、更符合預期的 LLM 應用成為可能。
-
更高的開發效率和可維護性 (Improved Developer Productivity and Maintainability): SGLang 提供了更接近傳統編程的體驗,使得編寫、調試和維護復雜的 LLM 應用更加容易。將控制邏輯從冗長的提示中分離出來,使得代碼更清晰、更模塊化。
-
降低成本 (Reduced Cost): 通過提高推理效率,可以減少對計算資源的需求,從而降低運行 LLM 應用的成本。
-
促進復雜 LLM 應用的開發 (Facilitates Development of Complex LLM Applications): 使得構建需要精細控制和高效執行的復雜應用(如多步驟推理、模擬、內容生成流水線、以及各種 Agent 應用)變得更加可行。
-
后端無關性 (Backend Agnostic - to some extent): 雖然與特定后端(如 vLLM)集成可以獲得最佳性能,但其設計理念是希望能夠支持多種 LLM 推理后端。
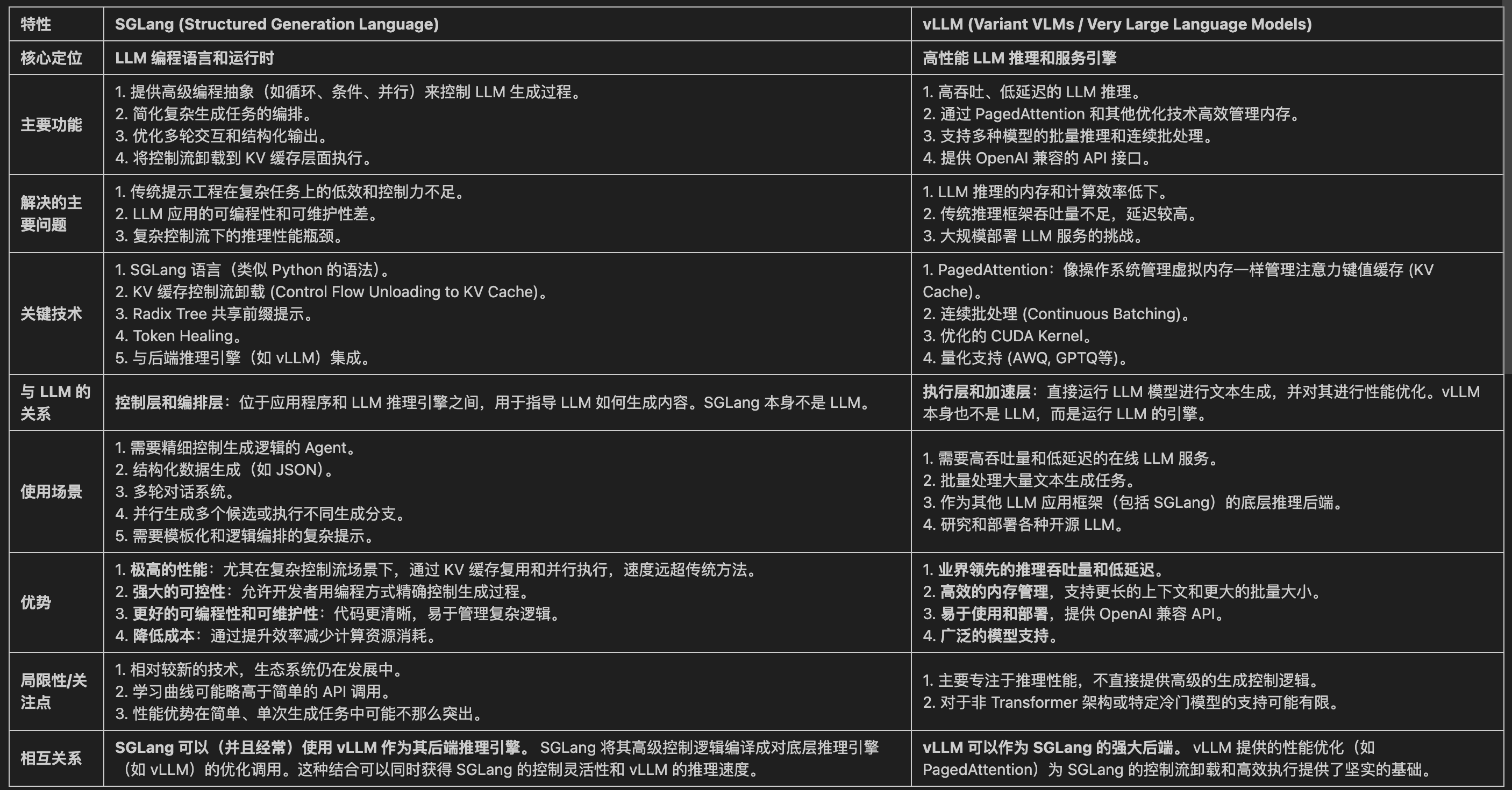
2.5 SGLang vs vLLM
三、SGlang 實戰
3.1 基礎環境配置
服務器資源申請請參考:
Qwen2.5 7B 極簡微調訓練_qwen-7b訓練-CSDN博客文章瀏覽閱讀310次,點贊4次,收藏6次。實現 qwen 2.5 7b 模型微調實驗,并打包好模型最后發布到 huggingface_qwen-7b訓練https://blog.csdn.net/weixin_39403185/article/details/147115232?spm=1001.2014.3001.5501
sudo apt update && upgrade -y
sudo apt install build-essential cmake -y# 安裝 conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /data/Miniconda3.sh
bash /data/Miniconda3.sh -b -p /data/miniconda3echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
source /data/miniconda3/bin/activate
source ~/.bashrc# 安裝 conda 訓練環境
conda create -n llm python=3.10 -y
conda activate llm
echo 'conda activate llm' >> ~/.bashrc
source ~/.bashrcpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install "sglang[all]"3.2?SGlang 單機部署測試
服務器申請: 一臺 A10 先顯卡的服務器即可
a) 基礎環境配置
參考 3.1
b) 模型準備
mkdir -p /data/models
huggingface-cli download Qwen/Qwen3-8B --resume-download --local-dir /data/models/qwen3-8b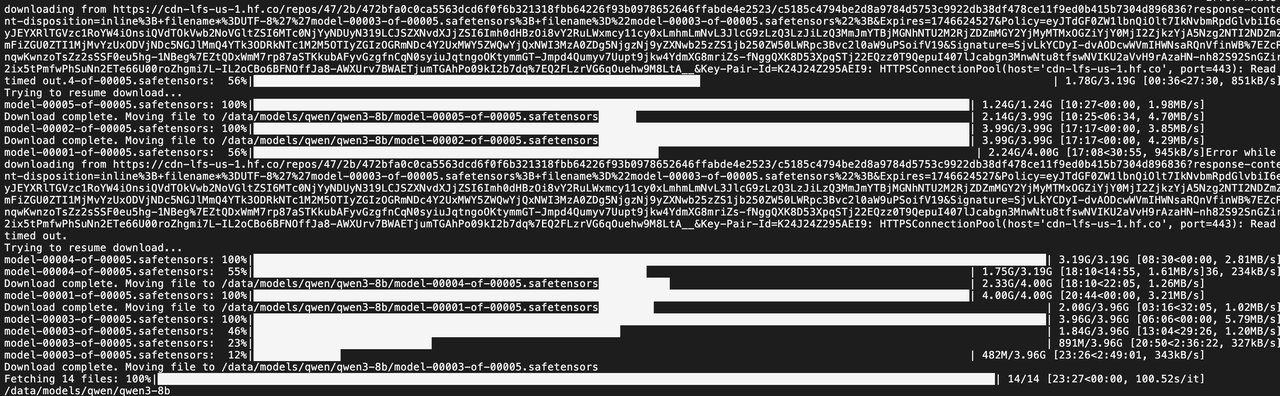
c) 單機部署
python -m sglang.launch_server \
--model-path /data/models/qwen3-8b \
--port 8000 --host 0.0.0.0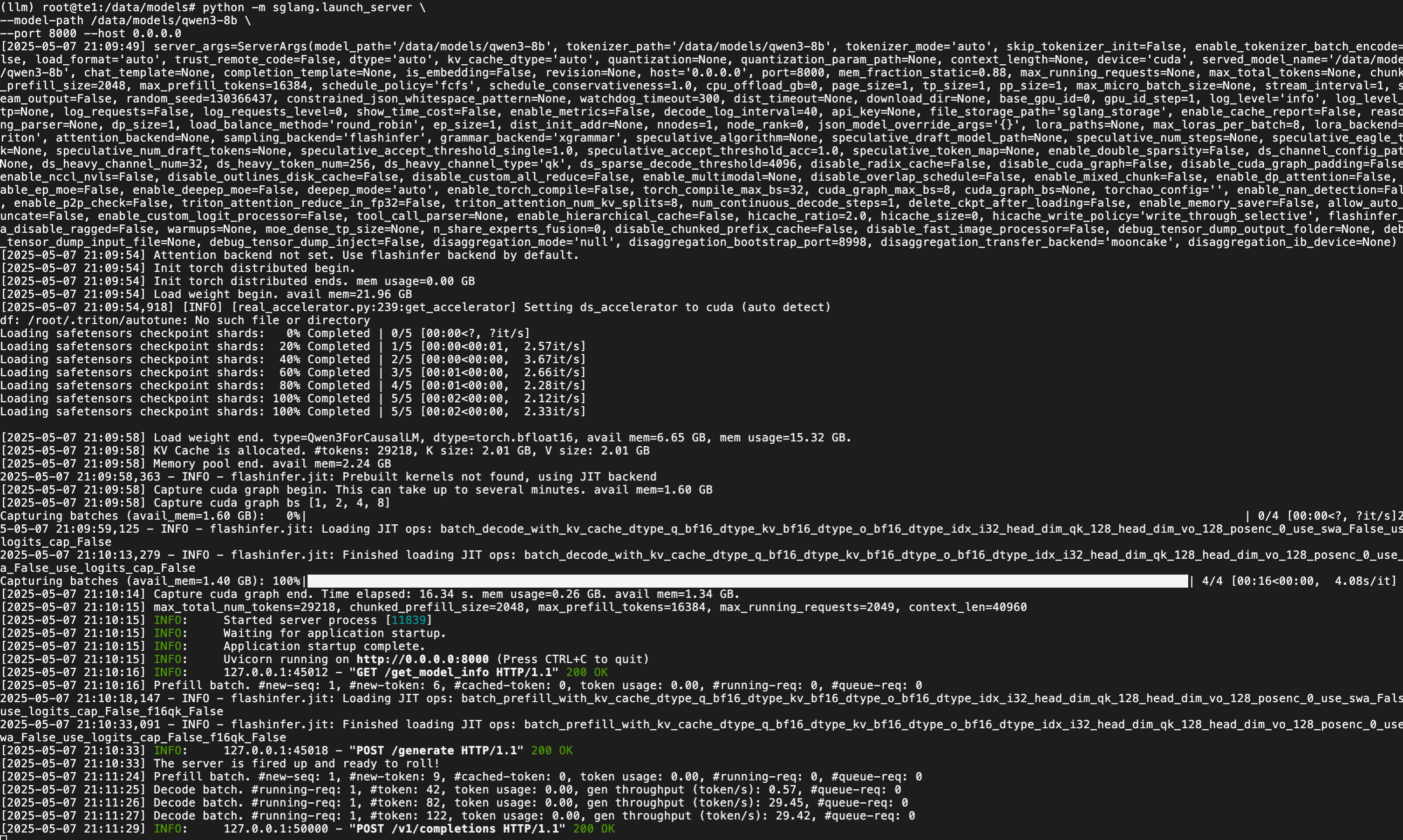
d) 測試推理模型
curl http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen/Qwen2-7B-Instruct","prompt": "你好,請介紹一下你自己以及 SGLang。","max_tokens": 150,"temperature": 0.7}' | jq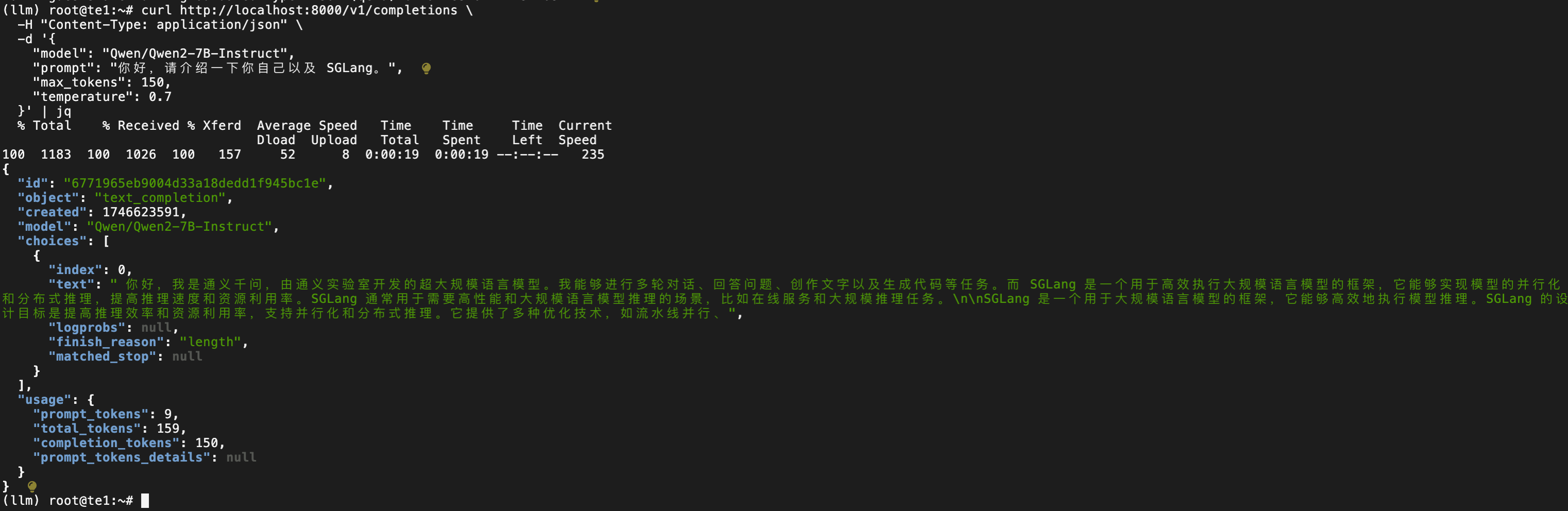
watch -n 0.5 nvidia-smi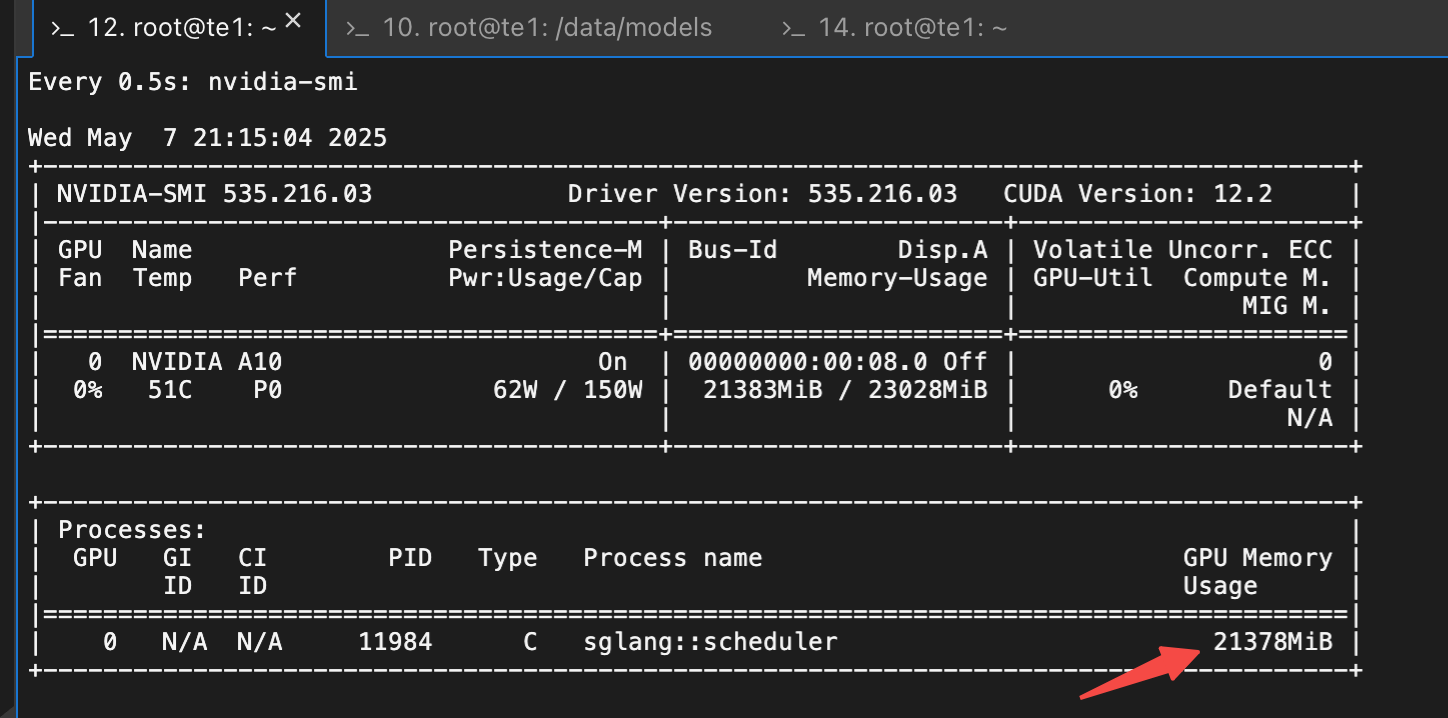
3.3?SGlang 推理模型張量并行
服務器申請: 2臺 A10 先顯卡的服務器即可
詳情可以參考:
a) 基礎環境配置
參考 3.1
b) 模型準備
參考 3.4 模型準備
c) 張量并行部署
# te1 節點執行
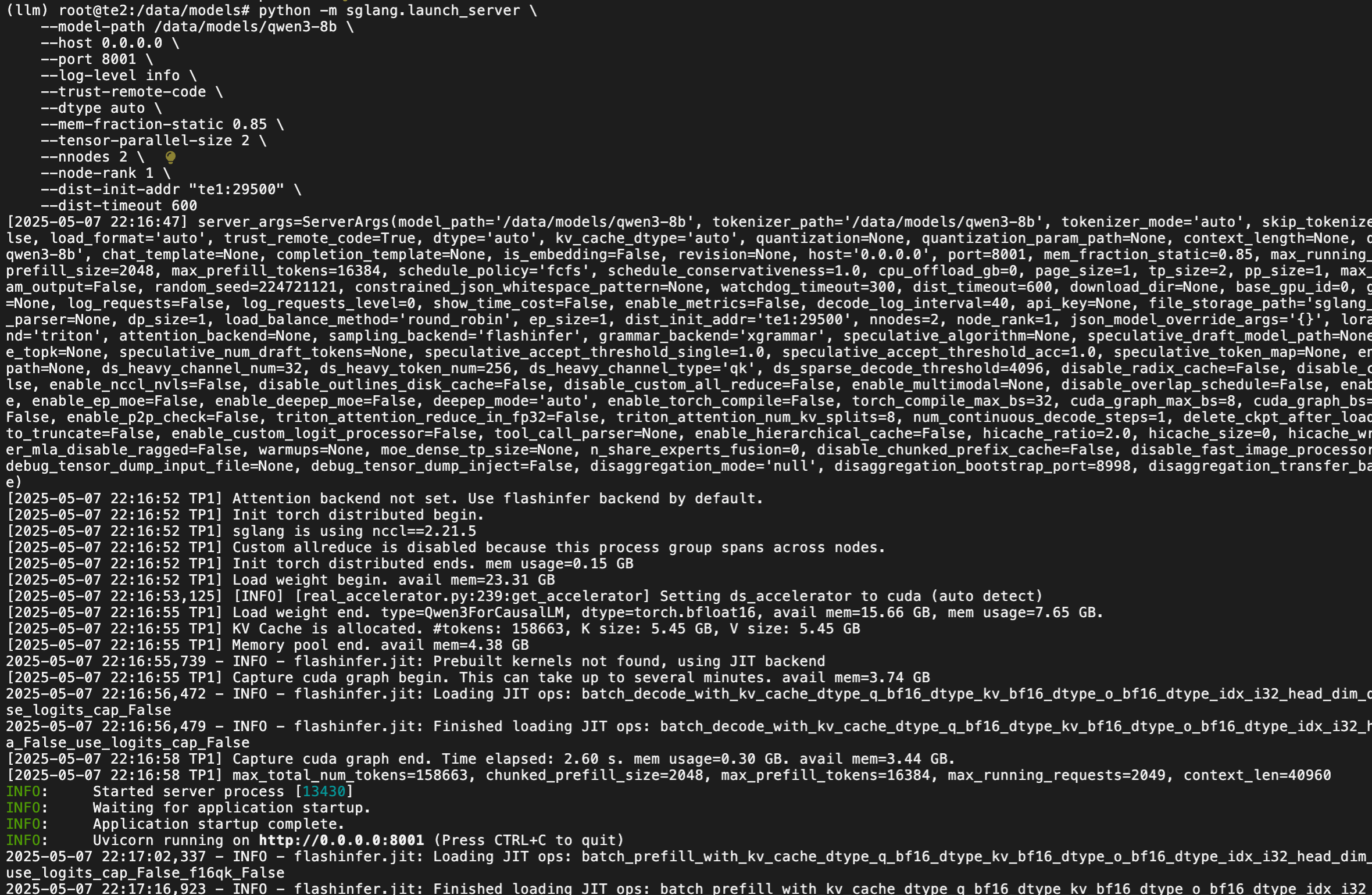
python -m sglang.launch_server \--model-path /data/models/qwen3-8b \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--tensor-parallel-size 2 \--nnodes 2 \--node-rank 0 \--dist-init-addr "te1:29500" \--dist-timeout 600# te2 節點執行
python -m sglang.launch_server \--model-path /data/models/qwen3-8b \--host 0.0.0.0 \--port 8001 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--tensor-parallel-size 2 \--nnodes 2 \--node-rank 1 \--dist-init-addr "te1:29500" \--dist-timeout 600te1 日志
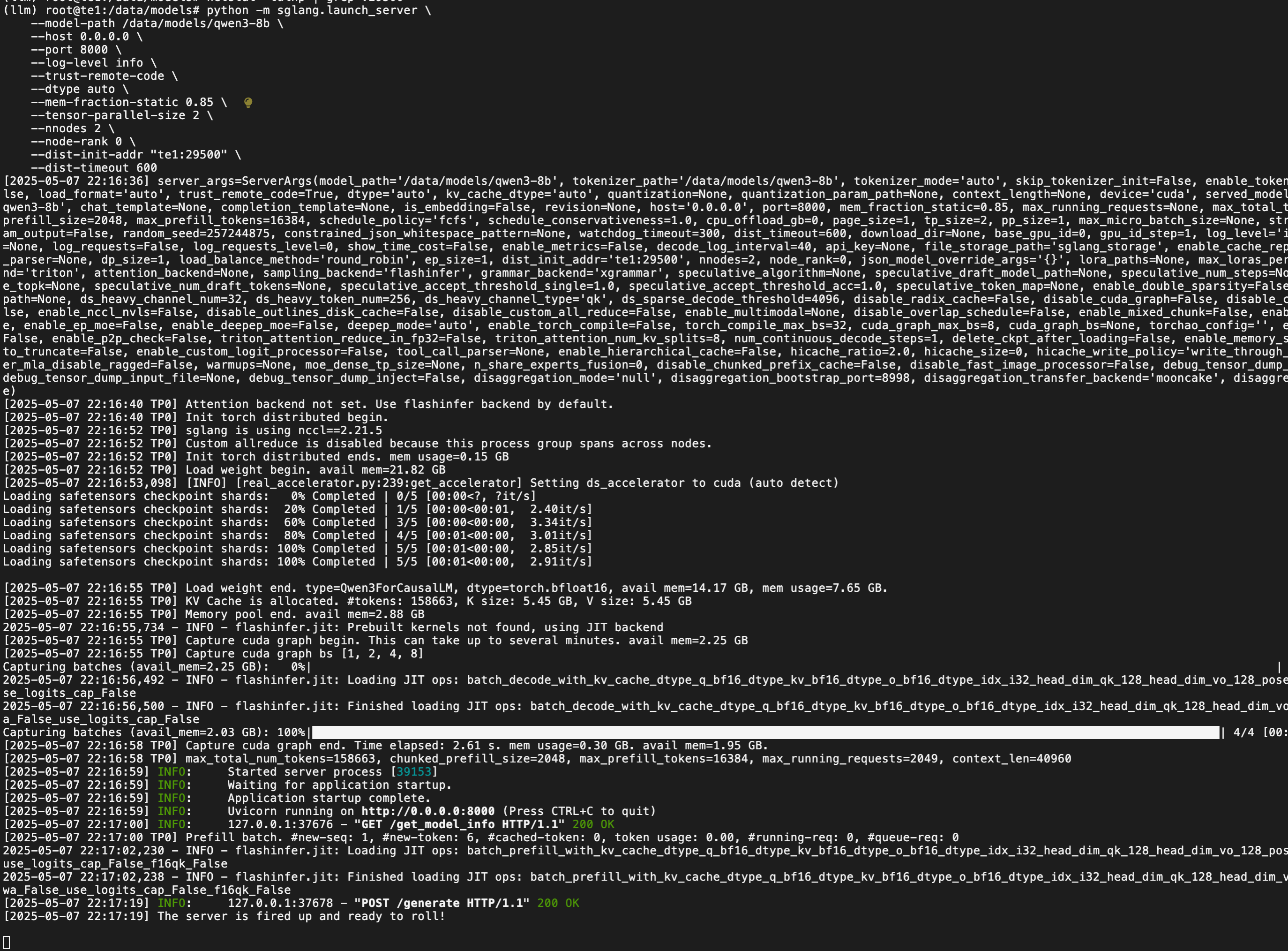
te2?日志
d) 測試推理模型
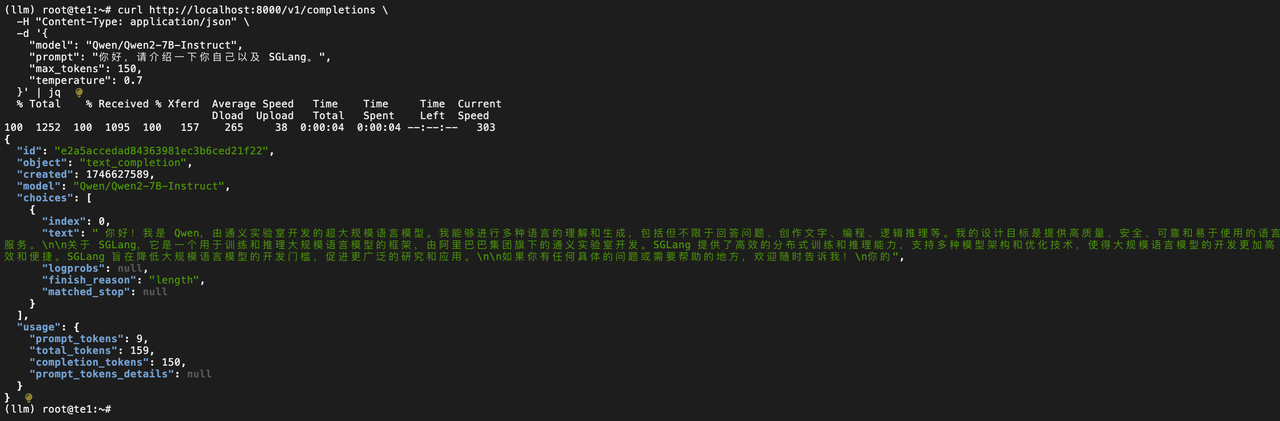
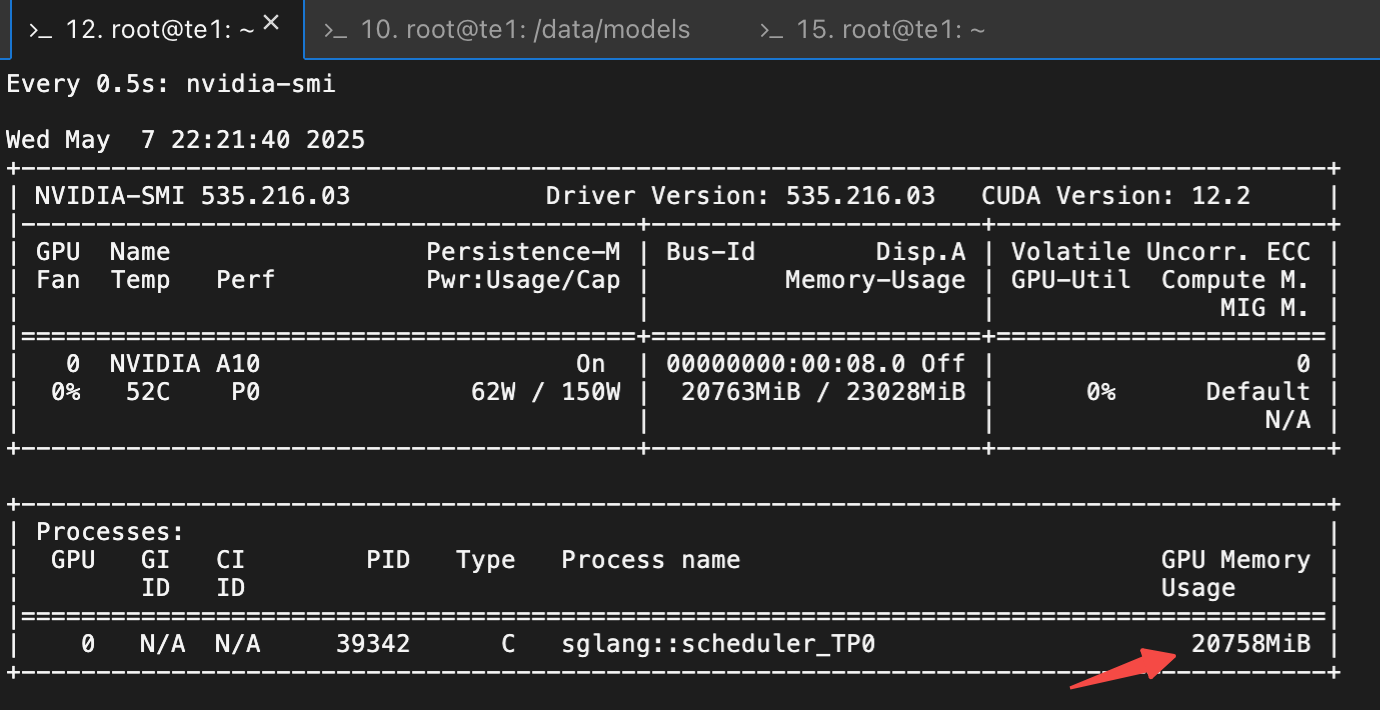
3.4?SGlang MoE 推理模型
服務器申請: 4臺 A10 先顯卡的服務器即可
a) 基礎環境準備
參考 3.1
b) 模型準備 (MoE 架構的 Qwen3 -30B)
Qwen/Qwen3-30B-A3B 模型準備:
模型很大約 60Gi 要下載很久很久。
mkdir -p /data/models
huggingface-cli download Qwen/Qwen3-30B-A3B --resume-download --local-dir /data/models/Qwen3-30B-A3B
c) SGLang 部署 MoE Qwen3 30B
# te1 節點執行
python -m sglang.launch_server \--model-path /data/models/Qwen3-30B-A3B \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--attention-backend flashinfer \--tensor-parallel-size 4 \--nnodes 4 \--node-rank 0 \--dist-init-addr "te1:29500" \--dist-timeout 600 \--enable-ep-moe \--ep-size 4# te2 節點執行
python -m sglang.launch_server \--model-path /data/models/Qwen3-30B-A3B \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--attention-backend flashinfer \--tensor-parallel-size 4 \--nnodes 4 \--node-rank 1 \--dist-init-addr "te1:29500" \--dist-timeout 600--enable-ep-moe \--ep-size 4# te3 節點執行
python -m sglang.launch_server \--model-path /data/models/Qwen3-30B-A3B \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--attention-backend flashinfer \--tensor-parallel-size 4 \--nnodes 4 \--node-rank 2 \--dist-init-addr "te1:29500" \--dist-timeout 600--enable-ep-moe \--ep-size 4# te4 節點執行
python -m sglang.launch_server \--model-path /data/models/Qwen3-30B-A3B \--host 0.0.0.0 \--port 8000 \--log-level info \--trust-remote-code \--dtype auto \--mem-fraction-static 0.85 \--attention-backend flashinfer \--tensor-parallel-size 4 \--nnodes 4 \--node-rank 3 \--dist-init-addr "te1:29500" \--dist-timeout 600--enable-ep-moe \--ep-size 4te1 節點上運行日志?
te2,te3,te4節點上日志都差不多 我就保留了 te2 的運行情況?
d) 測試推理模型
curl http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen/Qwen2-7B-Instruct","prompt": "請介紹一下自己","max_tokens": 150,"temperature": 0.7}' | jq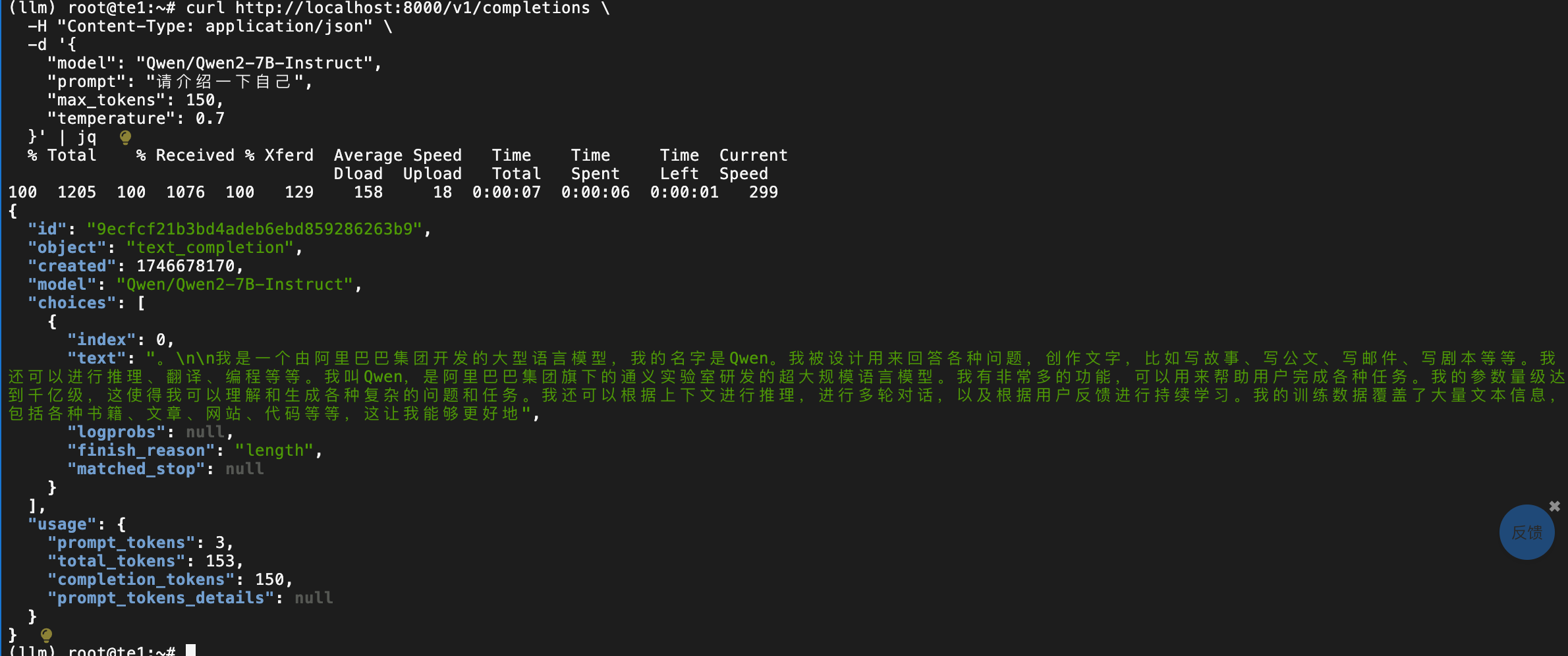
e) locust 性能測試
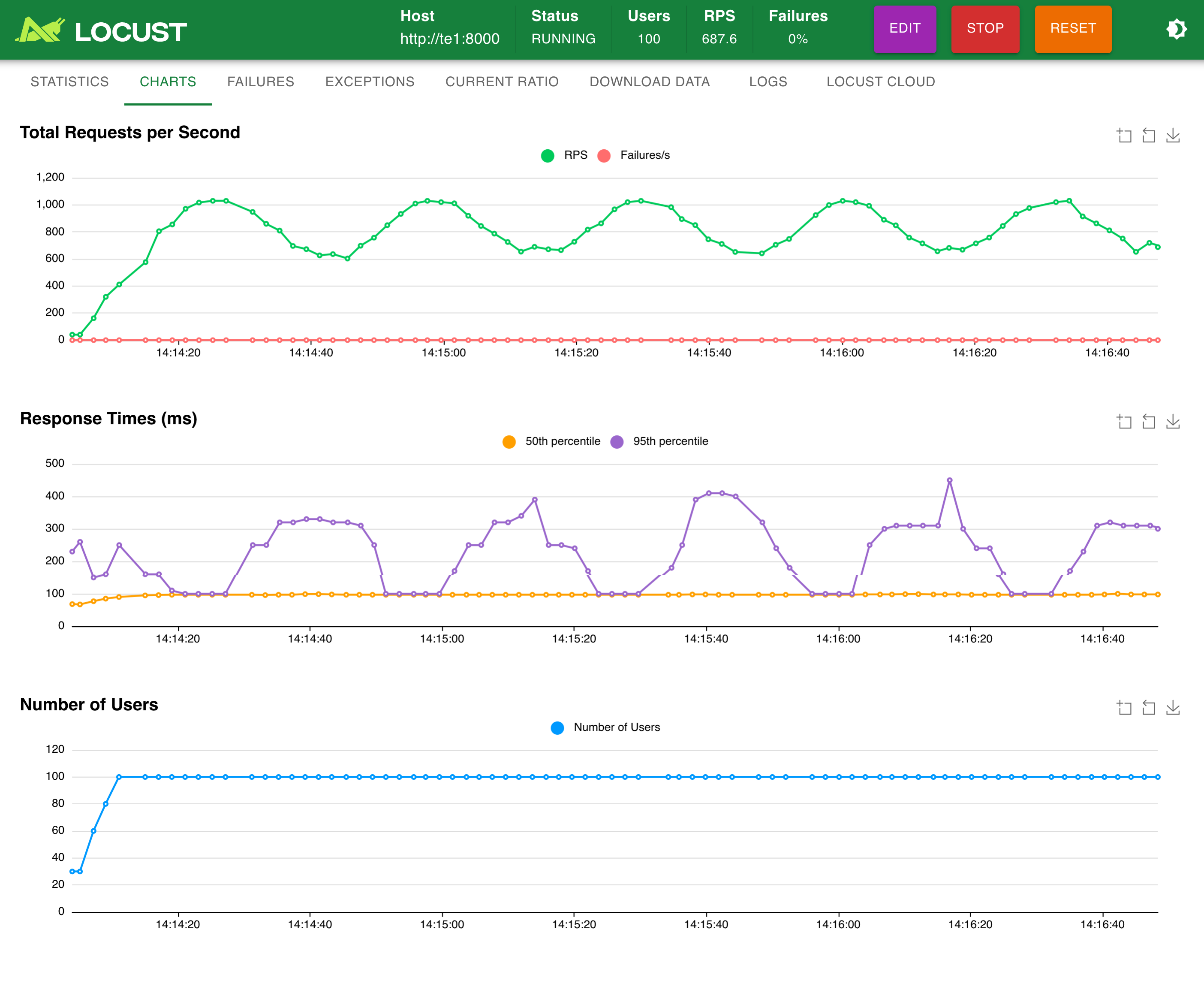
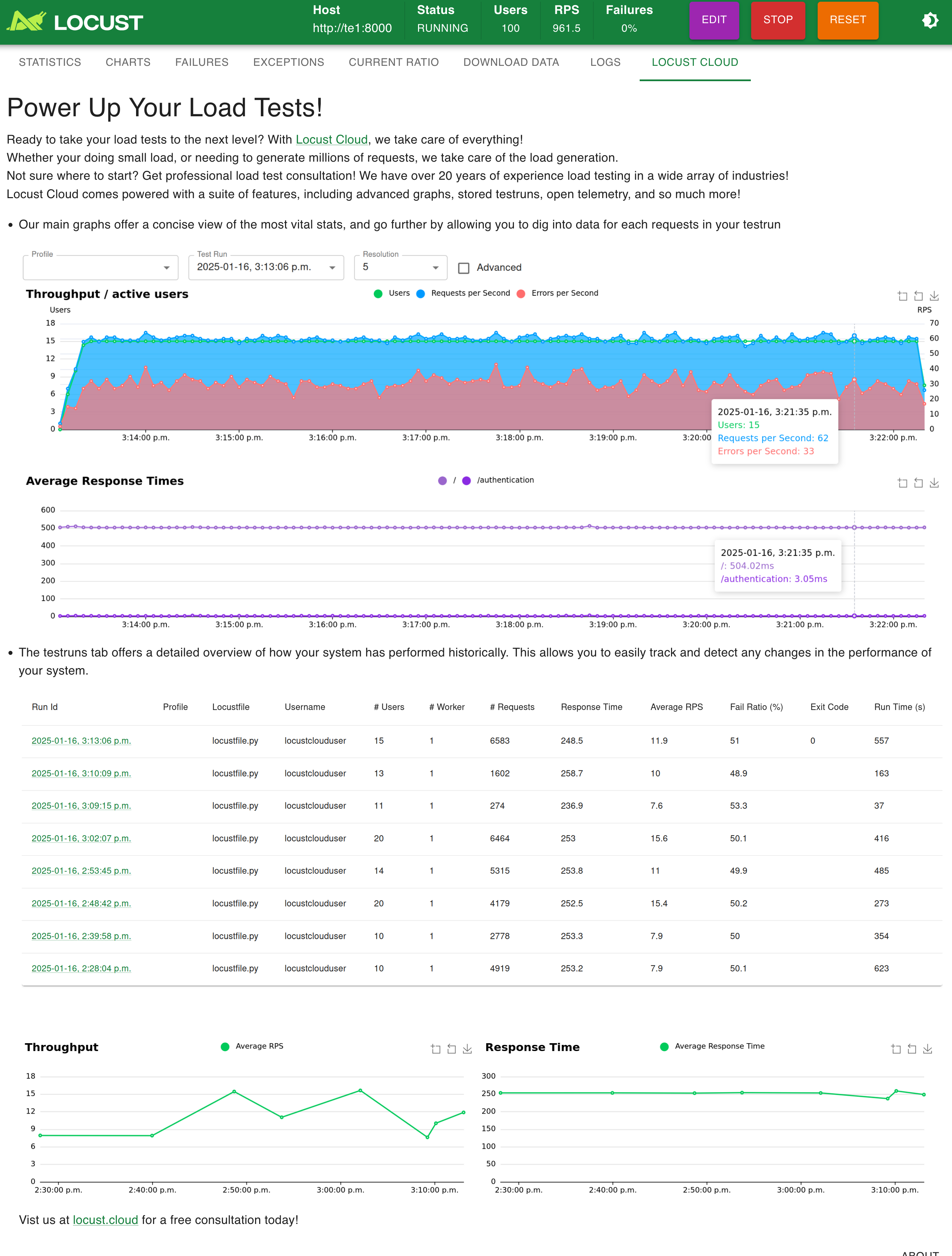
模擬 30 并發:
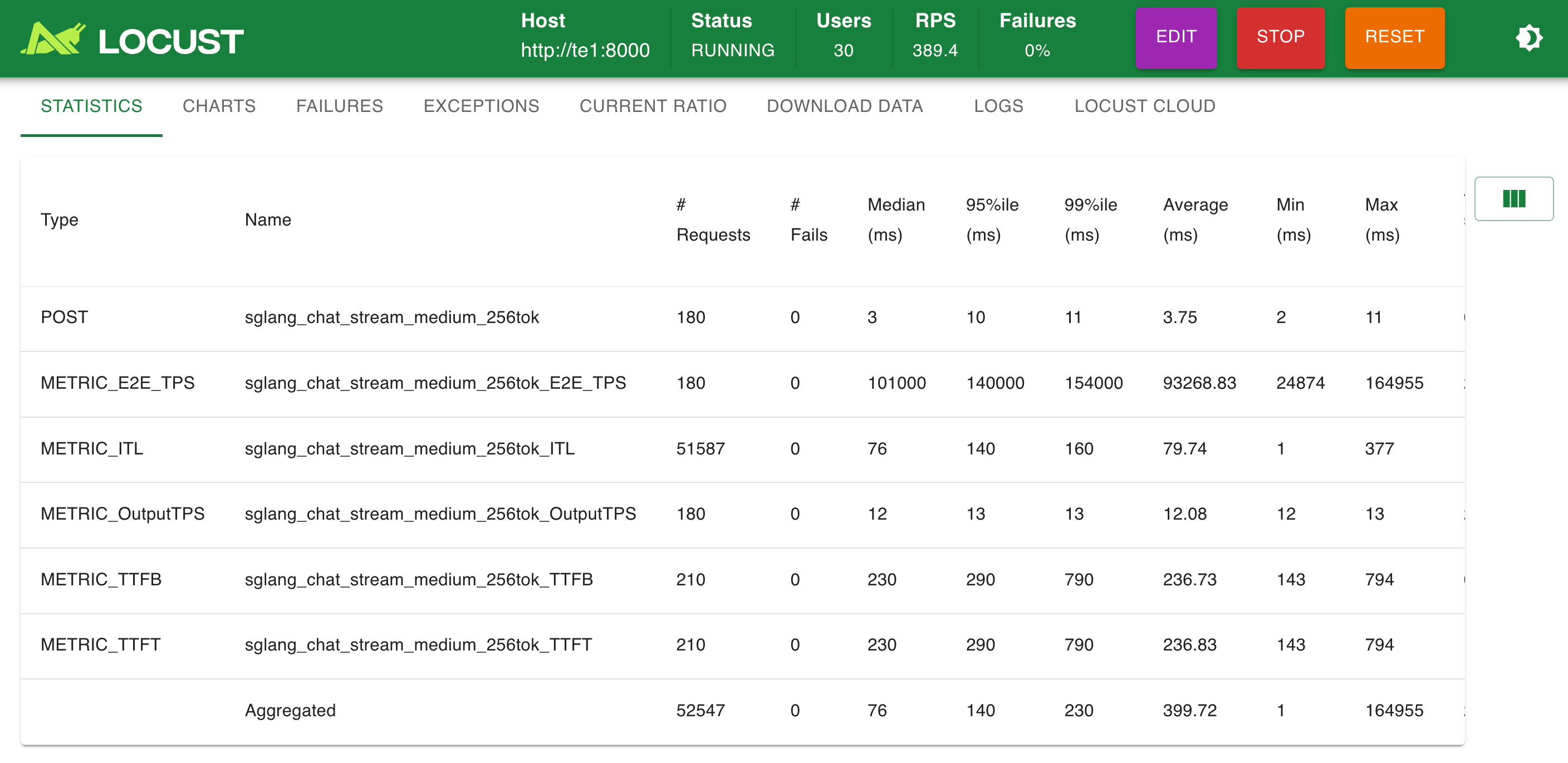
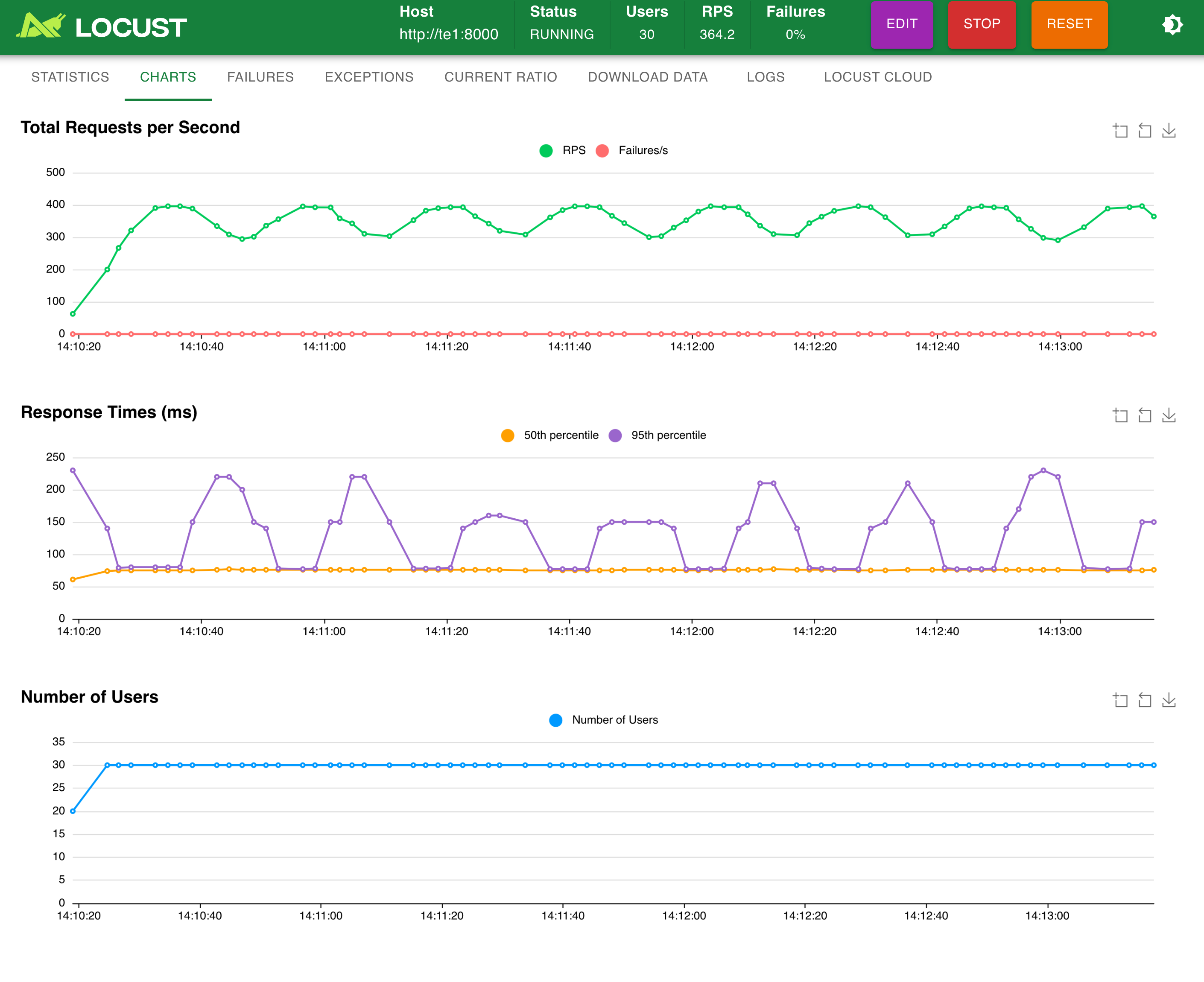
模擬 100 并發:
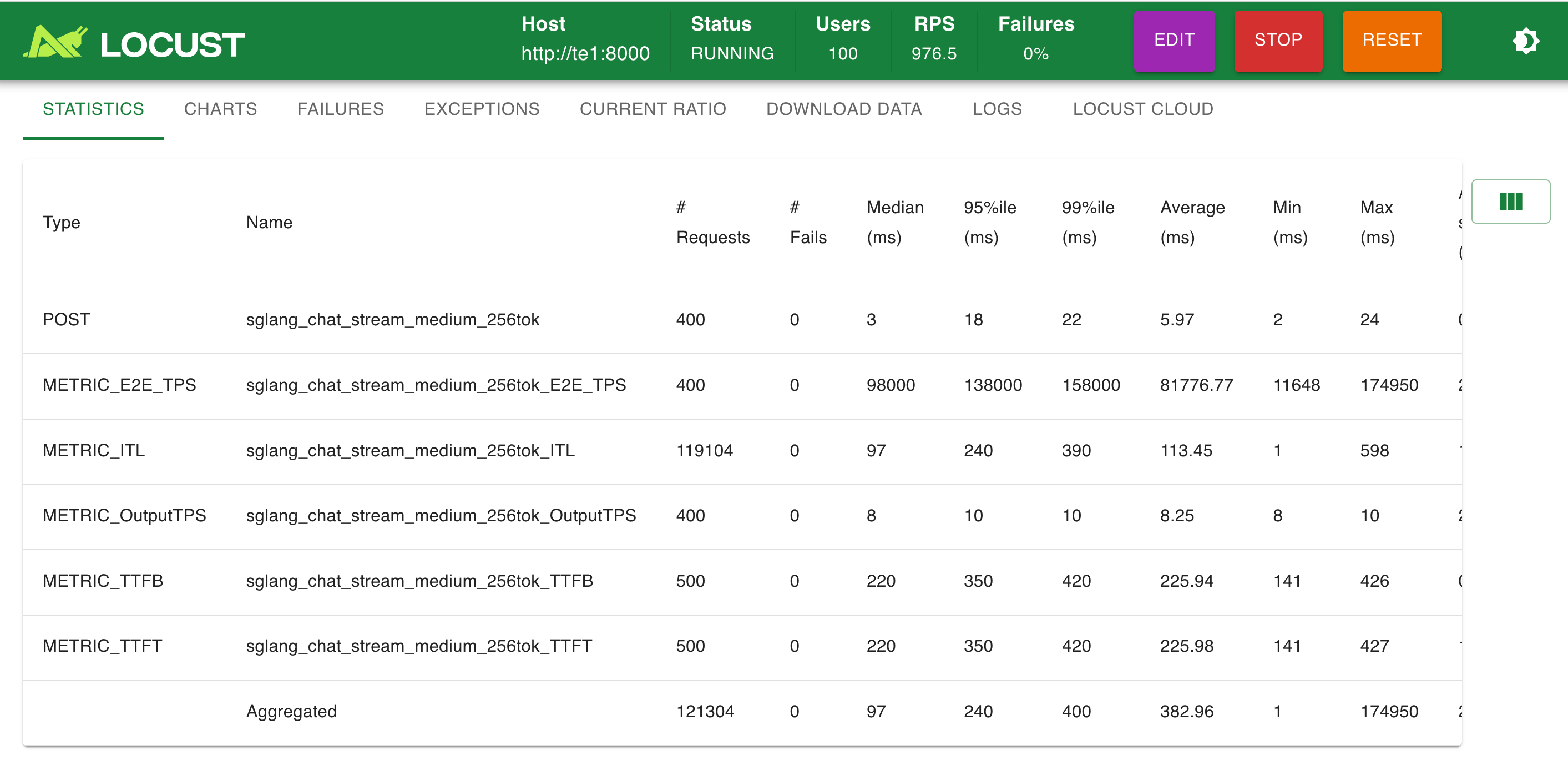
補充代碼:
## 調試專用
## te1
watch nvidia-smi
kill -9 pid
netstat -tulnp | grep :8000
netstat -tulnp | grep :29500## te2
nvidia-smi
kill -9 pid
netstat -tulnp | grep :8001四、小結
SGlang技術還是相當成熟的,使用下來基本上沒有什么 bug 或者莫名的報錯,顯存管理控制也是非常好。測試調試最順暢的一次。針對SGlang部署推理模型 單機版,張量并行和 MoE 形式的都提供了完整的示例。最后也提供了性能測試的相關內容。
參考:
Server Arguments — SGLang![]() https://docs.sglang.ai/backend/server_arguments.htmlGitHub - sgl-project/sglang: SGLang is a fast serving framework for large language models and vision language models.SGLang is a fast serving framework for large language models and vision language models. - sgl-project/sglang
https://docs.sglang.ai/backend/server_arguments.htmlGitHub - sgl-project/sglang: SGLang is a fast serving framework for large language models and vision language models.SGLang is a fast serving framework for large language models and vision language models. - sgl-project/sglang![]() https://github.com/sgl-project/sglangLarge Language Models — SGLang
https://github.com/sgl-project/sglangLarge Language Models — SGLang![]() https://docs.sglang.ai/supported_models/generative_models.htmlhttps://huggingface.co/Qwen/Qwen3-30B-A3B
https://docs.sglang.ai/supported_models/generative_models.htmlhttps://huggingface.co/Qwen/Qwen3-30B-A3B![]() https://huggingface.co/Qwen/Qwen3-30B-A3B大語言模型中的MoE - 哥不是小蘿莉 - 博客園1.概述 MoE代表“混合專家模型”(Mixture of Experts),這是一種架構設計,通過將不同的子模型(即專家)結合起來進行任務處理。與傳統的模型相比,MoE結構能夠動態地選擇并激活其中一部分專家,從而顯著提升模型的效率和性能。尤其在計算和參數規模上,MoE架構能夠在保持較低計算開銷的同
https://huggingface.co/Qwen/Qwen3-30B-A3B大語言模型中的MoE - 哥不是小蘿莉 - 博客園1.概述 MoE代表“混合專家模型”(Mixture of Experts),這是一種架構設計,通過將不同的子模型(即專家)結合起來進行任務處理。與傳統的模型相比,MoE結構能夠動態地選擇并激活其中一部分專家,從而顯著提升模型的效率和性能。尤其在計算和參數規模上,MoE架構能夠在保持較低計算開銷的同![]() https://www.cnblogs.com/smartloli/p/18577833
https://www.cnblogs.com/smartloli/p/18577833
https://huggingface.co/blog/zh/moe![]() https://huggingface.co/blog/zh/moe
https://huggingface.co/blog/zh/moe












![[python] 函數2-匿名函數](http://pic.xiahunao.cn/[python] 函數2-匿名函數)






