三級緩存是指什么
我們常說的三級緩存如下:
- CPU三級緩存
- Spring三級緩存
- 應用架構(JVM、分布式緩存、db)三級緩存
CPU
基本概念
CPU 的訪問速度每 18 個月就會翻 倍,相當于每年增? 60% 左右,內存的速度當然也會不斷增?,但是增?的速度遠小于 CPU,平均每年 只增? 7% 左右。于是,CPU 與內存的訪問性能的差距不斷拉大。
為了彌補 CPU 與內存兩者之間的性能差異,就在 CPU 內部引入了 CPU Cache,也稱高速緩存。
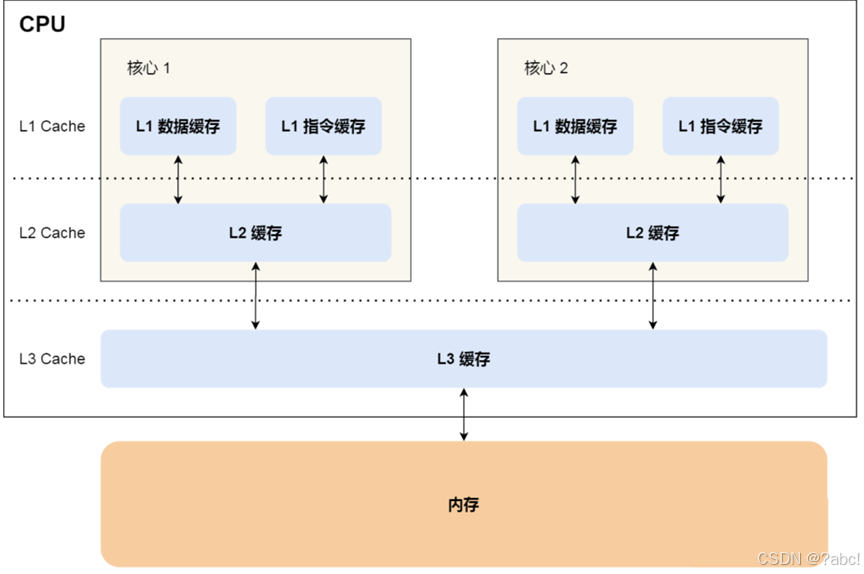
CPU Cache 通常分為大小不等的三級緩存,分別是 L1 Cache、L2 Cache 和 L3 Cache。其中L3是多個核心共享的。
離 CPU 核心越近,緩存的讀寫速度就越快
但 CPU 的空間很狹小,離 CPU 越近緩存大小受到的限制也越大。
所以,綜合硬件布局、性能等因素,CPU 緩存通常分為大小不等的三級緩存。
三級緩存要比一、二級緩存大許多倍,這是因為當下的 CPU 都是多核心的,
每個核心都有自己的一、二級緩存,- 但
三級緩存卻是一顆 CPU 上所有核心共享的 緩存一致性:在多核CPU時代,CPU有“緩存一致性”原則,也就是說每個處理器(核)都會通過嗅探在總線上傳播的數據來檢查自己的緩存值是不是過期了。如果過期了,則失效。- 比如聲明volitate,當變量被修改,則會立即要求寫入系統內存。
程序執行數據流向
順序如下
- 先將內存中的數據加載到共享的 L3 Cache 中,
- 再加載到每個核心獨有的 L2 Cache,
- 最后 進入到最快的 L1 Cache,之后才會被 CPU 讀取。
- 之間的層級關系,如下圖。
Spring三級緩存
概述
三級緩存就是在Bean生成流程中保存Bean對象三種形態的三個Map集合
]
這個三級緩存就是為了解決循環依賴
當創建相互依賴的對象時,會形成死循環,例如下圖無緩存中的情況。
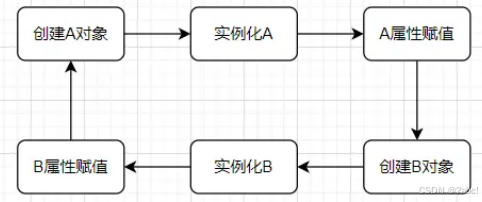
- 而Spring通過增加緩存,
將未完全創建好的A提前暴露在緩存中,當相互依賴的對象B對屬性A賦值時,可以直接從緩存中獲取A,而不需要再創建A。如下所示
哪三個緩存
Spring三級緩存機制包括以下三個緩存:
singletonObjects:一級緩存,緩存中的bean是已經創建完成的,該bean經歷過實例化->屬性填充->初始化以及各種的后置處理。因此,一旦需要獲取bean時,會優先尋找一級緩存earlySingletonObjects:二級緩存,該緩存跟一級緩存的區別在于,該緩存所獲取到的bean是提前曝光出來的,是還沒創建完成的。也就是說獲取到的bean只能確保已經進行了實例化,但是屬性填充跟初始化還沒有做完,因此該bean還沒創建完成,時半成品,僅僅能作為指針提前曝光,被其他bean所引用singletonFactories:三級緩存,在bean實例化完之后,屬性填充以及初始化之前,如果允許提前曝光,spring會將實例化后的bean提前曝光,也就是把該bean轉換成beanFactory并加入到三級緩存。在需要引用提前曝光對象時再通過singletonFactory.getObject()獲取。
// 一級緩存Map 存放完整的Bean(流程跑完的)
private final Map<String, Object> singletonObjects = new ConcurrentHashMap(256);// 二級緩存Map 存放不完整的Bean(只實例化完,還沒屬性賦值、初始化)
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap(16);// 三級緩存Map 存放一個Bean的lambda表達式(也是剛實例化完)
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
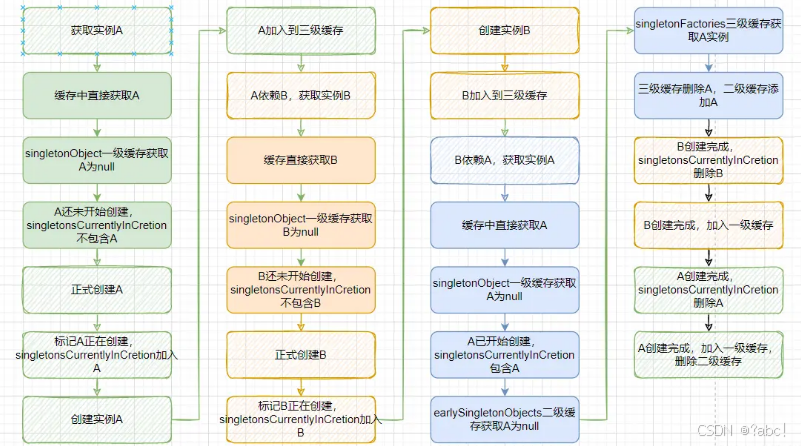
發現兩個Bean循環依賴時
當Spring發現兩個或更多個bean之間存在循環依賴關系時
- 它會
先將其中一個beanA創建的過程中尚未完成的實例放入earlySingletonObjects緩存中, - 然后
將創建該beanA的工廠對象放入singletonFactories緩存中。 - 接著,
Spring會暫停當前bean的創建過程,去創建它所依賴的bean。 - 當
依賴的bean創建完成后,Spring會將其放入singletonObjects緩存中,并使用它來完成當前bean的創建過程。 - 在創建當前bean的過程中,如果發現它還依賴其他的bean,Spring會重復上述過程,直到所有bean的創建過程都完成為止。
注意:當使用構造函數注入方式時,循環依賴是無法解決的。- 因為在創建bean時,必須先創建它所依賴的bean實例,而構造函數注入方式需要在創建bean實例時就將依賴的bean實例傳入構造函數中。
- 如果依賴的bean實例尚未創建完成,就無法將其傳入構造函數中,從而導致循環依賴無法解決。
- 此時,
可以考慮使用setter注入方式來解決循環依賴問題。
當A和B相互依賴時,若先創建實例A,則整個調用過程如下:
簡化圖如下
應用架構三級緩存
概述
應用架構三級緩存的時候,一般說JVM級別的、分布式緩存級別的、數據庫級別的
JVM級別:一般常見本地緩存框架有Guava Cache和Caffeine Cache分布式緩存級別:一般用的Redis。數據庫級別:mysql等數據庫
眾所周知 MySQL 數據庫會將數據存儲在硬盤以防止掉電丟失,但是受制于硬盤的物理設計,即便是目前性能最好的企業級 SSD 硬盤,也比內存的這種高速設備 IO 層面差一個數量級
典型的 “讀多寫少” 的場景,需要在設計上進行數據的讀寫分離,數據寫入時直接落盤處理,
而占比超過 90% 的數據讀取操作時則從以 Redis 為代表的內存 NoSQL 數據庫提取數據,利用內存的高吞吐瞬間完成數據提取,這里 Redis 的作用就是我們常說的緩存。
二級緩存架構
二級緩存架構
1級為本地緩存,或者進程內的緩存(如 Ehcache) ——速度快,進程內可用2級為集中式緩存(如 Redis)——可同時為多節點提供服務
Java 的應用端多級緩存
在 Java 的應用端也要設計多級緩存,我們將進程內緩存與分布式緩存服務結合,有效分攤應用壓力。
- 在
Java 應用層面,只有 本地緩存(EhCache、Caffeine Cache) 的緩存不存在時,再去 Redis 分布式緩存獲取, - 如果 Redis 也沒有此數據再去數據庫查詢,
數據查詢成功后對 Redis 與 本地緩存 同時進行雙寫更新。 - 這樣 Java 應用下一次再查詢相同數據時便直接從本地緩存提取,不再產生新的網絡通信,應用查詢性能得到顯著提高。
為了保證緩存一致性,利用 通知(MQ、發布訂閱模式等) 向其他服務實例以及 Redis 緩存服務發起變更通知。
源碼分析)
)
論文筆記)












)



