【Java高頻面試問題】高并發篇
- Kafka原理
- 核心組件
- 高吞吐核心機制
- 高可用設計
- Kafka 如何保證消息不丟失
- 如何解決Kafka重復消費
- 一、生產者端:根源防重
- 二、消費者端:精準控制
- 三、業務層:冪等性設計(核心方案)
- 如何解決Kafka消息積壓
- 一、緊急止血:快速降低積壓
- 二、消費端優化:提升吞吐能力
- 三、生產端控流:源頭限速
- 四、集群與架構改造
- 💎 決策樹:按場景選擇方案
Kafka原理
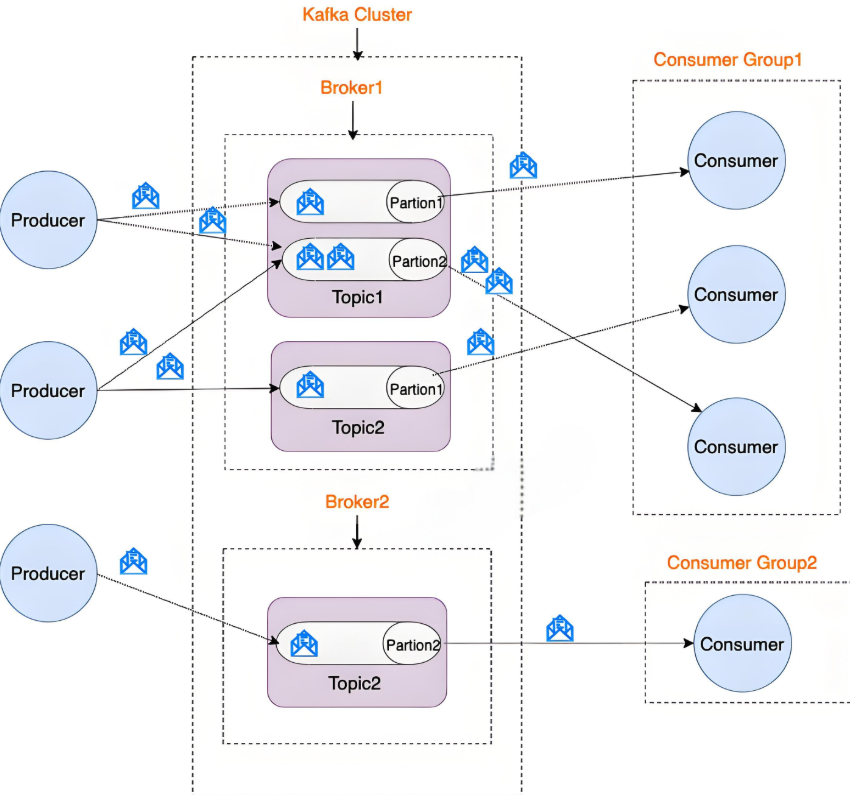
核心組件
| ?組件? | ?作用? |
|---|---|
| ?Producer? | 生產者,將消息發布到指定Topic(可指定分區策略) |
| ?Broker? | Kafka服務節點,組成集群存儲消息(默認端口9092) |
| ?Topic? | 邏輯消息分類(如訂單流、日志流) |
| ?Partition? | Topic的分區,每個分區是?有序不可變?的消息隊列(實現水平擴展與并行處理) |
| ?Consumer? | 消費者,通過Consumer Group訂閱Topic(組內消費者競爭分區消費權) |
| ?ZooKeeper? | 管理集群元數據、Broker注冊、Leader選舉(Kafka 2.8+開始支持KRaft模式替代ZK) |
高吞吐核心機制
-
分區與并行化?
- Topic劃分為多個Partition,分布在不同Broker,提升吞吐能力。
- Producer/Consumer可并行讀寫不同分區。
-
存儲優化?
- 順序寫入磁盤?:避免隨機I/O,速度提升百倍。
- **零拷貝(Zero-Copy)**?:
sendfile()減少內核態數據拷貝。 - 頁緩存?:利用OS緩存加速讀寫,而非直接寫盤。
-
?批量處理?
- Producer累積消息批量發送(
batch.size+linger.ms)。 - Consumer批量拉取消息(
max.poll.records)。
- Producer累積消息批量發送(
高可用設計
-
?副本機制(Replica)
- 每個分區配置N個副本(如
replication.factor=3)。 - Leader處理讀寫,Follower同步數據,Leader故障時自動選舉新Leader。
- 每個分區配置N個副本(如
-
?ISR(In-Sync Replicas) ?
- 動態維護與Leader數據同步的副本集合。
- 僅ISR中的副本可參與Leader選舉,確保數據一致性。
Kafka 如何保證消息不丟失
- 生產者設置
**acks=all**:所有ISR副本寫入成功才返回確認。 - 生產者(Producer) 調用
send方法發送消息之后,為其添加回調函數。
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);future.addCallback(result -> logger.info("生產者成功發送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),ex -> logger.error("生產者發送消失敗,原因:{}", ex.getMessage()));
- 消費者手動關閉自動提交 offset,每次在真正消費完消息之后再自己手動提交 offset (
enable.auto.commit=false+commitSync())。結合分布式鎖可以防止消費者重復消費
如何解決Kafka重復消費
一、生產者端:根源防重
-
?啟用冪等生產者?
- 設置
enable.idempotence=true,為每條消息附加唯一序列號(PID + Sequence Number),Broker 自動過濾重復提交的消息 。 - 適用場景:消息發送階段的網絡重試導致重復。
- 設置
-
?事務消息機制?
- 跨生產者與消費者的分布式事務(
transactional.id),確保消息發送與 Offset 提交原子性。
- 跨生產者與消費者的分布式事務(
producer.initTransactions(); // 初始化事務
producer.beginTransaction();
producer.send(record);
producer.commitTransaction(); // 提交事務
二、消費者端:精準控制
-
?手動提交 Offset?
- 關閉自動提交(
enable.auto.commit=false),在?業務邏輯完成后再提交 Offset? 。
- 關閉自動提交(
-
?避免 Rebalance 導致重復?
- 優化會話超時時間(
session.timeout.ms),防止誤判消費者下線觸發不必要的分區重分配 。
- 優化會話超時時間(
三、業務層:冪等性設計(核心方案)
-
?唯一標識去重?
- 生產者為消息注入全局唯一 ID(如 UUID),消費者通過 DB/Redis 判重 。
-
?數據庫唯一約束?
- 利用數據庫主鍵/唯一索引攔截重復數據插入(如訂單ID)。
-
?狀態機驅動?
- 基于業務狀態流轉(如訂單“已支付”狀態),拒絕重復操作 。
生產者防重復是?第一道防線?,消費者冪等設計是?終極保障?
如何解決Kafka消息積壓
一、緊急止血:快速降低積壓
-
?擴容消費者組?
- 增加消費者實例?:確保消費者數量 ≤ 分區數,避免資源閑置(例如:4 分區主題至少配 4 個消費者)。
# 查看積壓情況
kafka-consumer-groups.sh --bootstrap-server <broker> --group <group> --describe
-
?跳過非關鍵消息?
- 按時間戳跳過:
--to-datetime "2025-06-18T00:00:00.000"。 - 允許丟失部分數據時,重置 Offset 到最新位置:
- 按時間戳跳過:
kafka-consumer-groups.sh --bootstrap-server <broker> --group <group> --reset-offsets --to-latest --execute
二、消費端優化:提升吞吐能力
-
?提升單消費者效率?
- 多線程消費?:單分區內使用線程池并行處理消息(需確保消息無序或分區內有序)。
- 批量拉取?:增大
max.poll.records(默認 500)和fetch.max.bytes,減少網絡交互次數。
-
?異步化處理?
- 將耗時操作(如 DB 寫入、計算)移交線程池,消費者僅提交 Offset。
- 使用內存隊列解耦:消費者快速拉取 → 隊列緩沖 → 工作線程處理。
-
?避免阻塞操作?
- 優化慢 SQL、減少同步 RPC 調用,用緩存預加載數據。
三、生產端控流:源頭限速
-
?動態限流?
- 令牌桶算法?:控制生產者寫入速率,匹配消費能力。
- 降級策略?:業務高峰時關閉非核心消息生產者。
-
?優化生產者參數?
linger.ms=50 # 適當增大批量發送延遲
batch.size=16384 # 增大批次大小(默認 16KB)
compression.type=lz4 # 啟用壓縮減少網絡負載
四、集群與架構改造
-
?擴容分區與集群?
- 增加主題分區數(需重啟或新建主題),突破并行消費瓶頸。
- 擴展 Broker 節點和磁盤,提升集群整體吞吐。
-
?分流與降級?
- ?新建臨時 Topic?:將積壓消息轉發到更多分區的新 Topic,消費者并行處理。
- ?離線補償?:消費者直接消費最新消息,積壓數據由離線任務補處理。
-
?監控體系?
- 實時監控
Consumer Lag,設置閾值告警(如 Lag >10,000 觸發)。 - 跟蹤 CPU、磁盤 IO、網絡流量,定位集群瓶頸。
- 實時監控
💎 決策樹:按場景選擇方案
| ?積壓原因? | ?優先級方案? |
|---|---|
| 消費能力不足 | 增加消費者 + 消費端多線程優化 |
| 生產流量瞬時飆升 | 生產者限流 + 消息跳過 |
| 分區數不足 | 擴容分區 + Broker 節點 |
| 消費邏輯阻塞(如慢 SQL) | 異步化改造 + 查殺異常進程 |
| 持續產能失衡 | 架構拆分 + 離線補償 |
?關鍵原則?:
- 優先 ?擴容消費者? 和 ?消費并行化? 提升吞吐。
- 生產端限流是 ?預防性手段?,避免系統雪崩。
- 分區數決定 ?并行上限?,需提前規劃彈性。
持續更新中…
)



:基于RAG的法律助手項目(上):總體流程簡易實現)






)
Aerotech.A3200名空間)






