原文地址:https://mp.weixin.qq.com/s/0VlIjbeEdPZUbLD389disA
當生產環境中的容器CPU出現異常時,可能會引發上層業務出現一系列問題,比如業務請求緩慢、網頁卡頓甚至崩潰等,如果沒有一個有效的故障定位方法,運維人員很難從海量的告警信息中快速找到根本原因并解決問題。
1 故障場景
某個時刻,幾十個電商服務同時出現大量告警,如下所示。
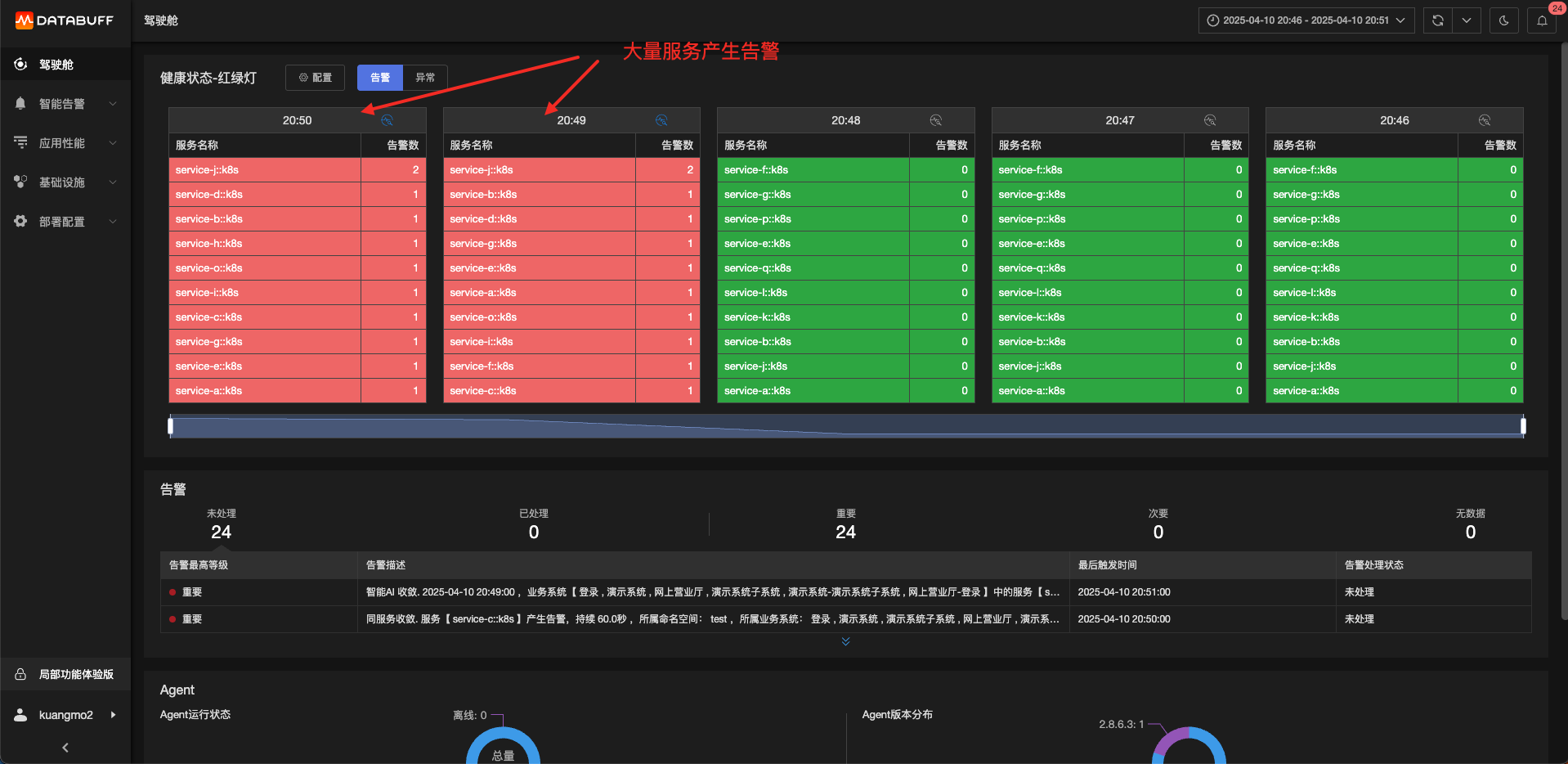
通常的方法是,從海量的告警信息中搜索有效信息,經過幾十分鐘時間的排查,可以拿到如下故障結論:
-
**定界(確定故障服務節點):**服務J是根因服務,影響了上游一系列的服務
-
**定位(確定服務上的具體問題):**服務J的CPU使用率非常高
但是,對于生產環境中出現的問題,幾十分鐘的排查時間無疑是太久了。因此,我們需要一個效率更高、更準確的方案,能夠在幾分鐘內就能找到問題根因。
2 故障定位思路分析
下面從定界和定位兩個方面進行展開,討論如何才能更高效的實現故障定位。
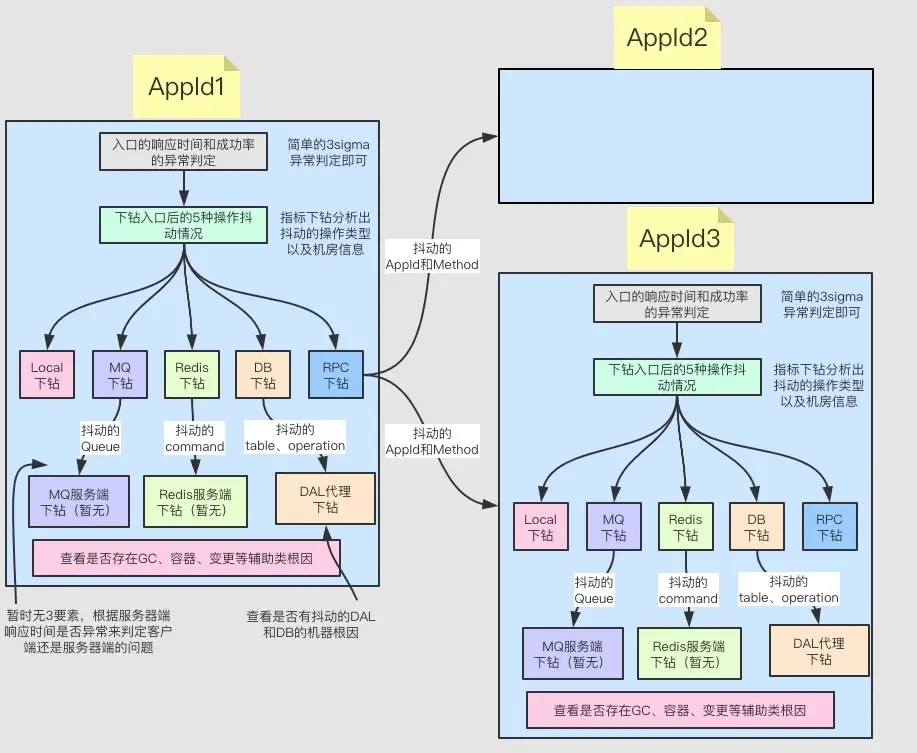
2.1 定界
對該故障的定界主要有如下2個難點
-
如何確定是自身、訪問組件、訪問下游服務的問題?
-
如何確定是自身還是下游服務的問題?
構建實時關系拓撲
首先需要拓撲依賴,構建出實時的關系拓撲
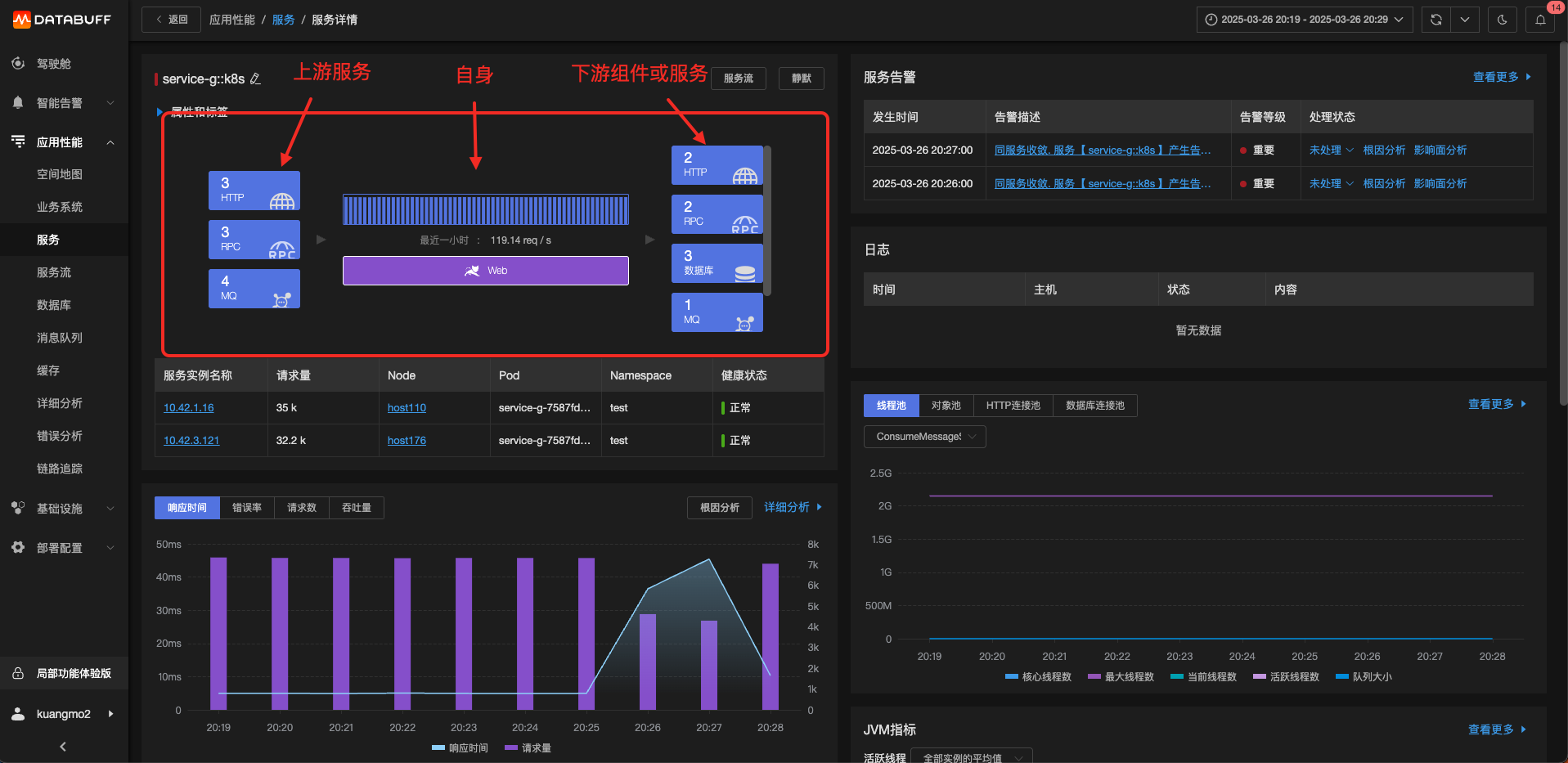
通過異常檢測確定下游故障點
其次,對訪問下游組件或者訪問下游服務的異常或者錯誤進行異常檢測,判斷是否符合當前服務的故障范圍。
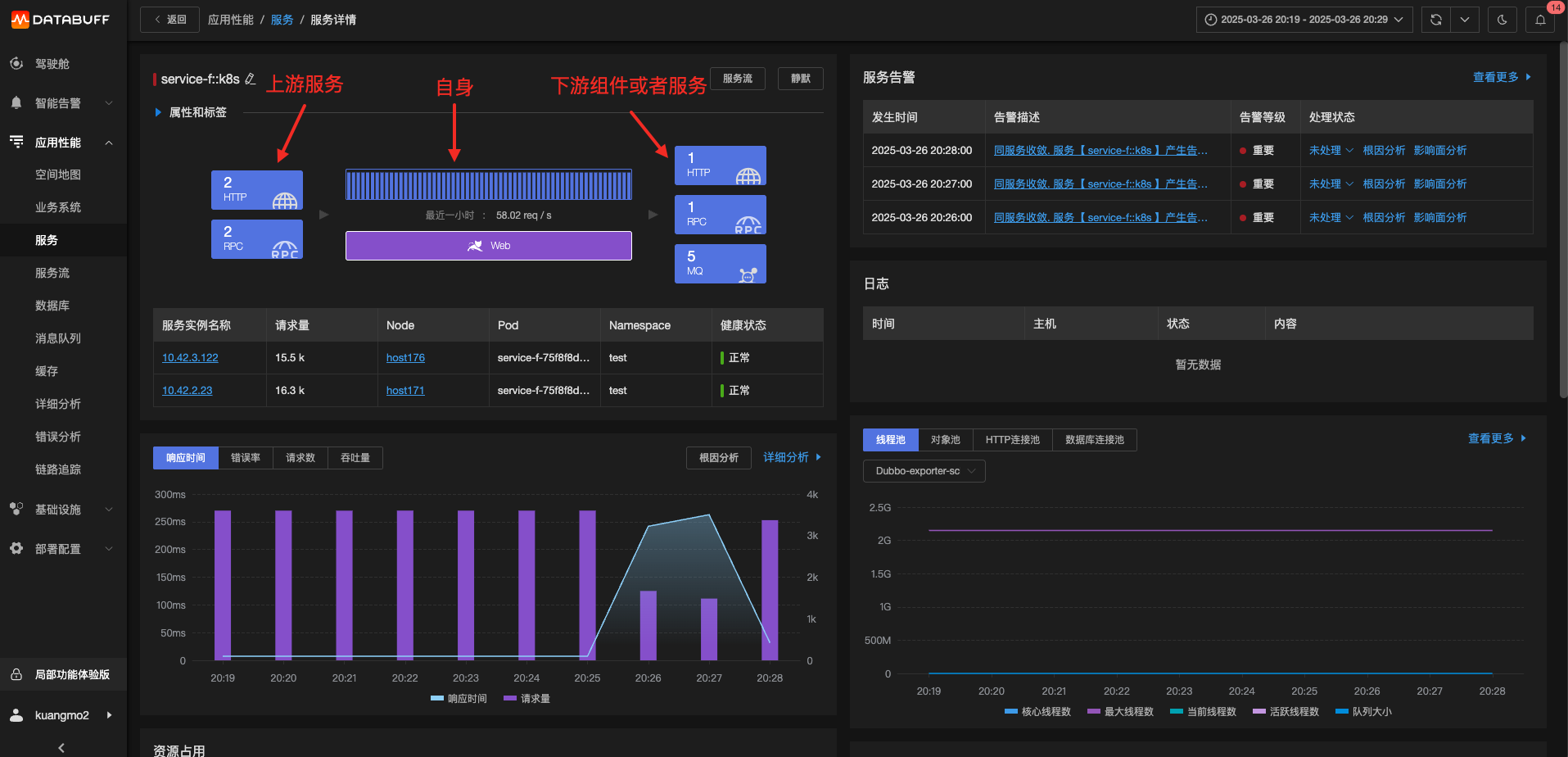
進一步定界
一旦確定是訪問下游服務導致之后,有如下3種可能:
-
下游服務問題
-
網絡問題
-
自身問題
判斷方法是:客戶端響應時間和服務端響應時間的基準對比。
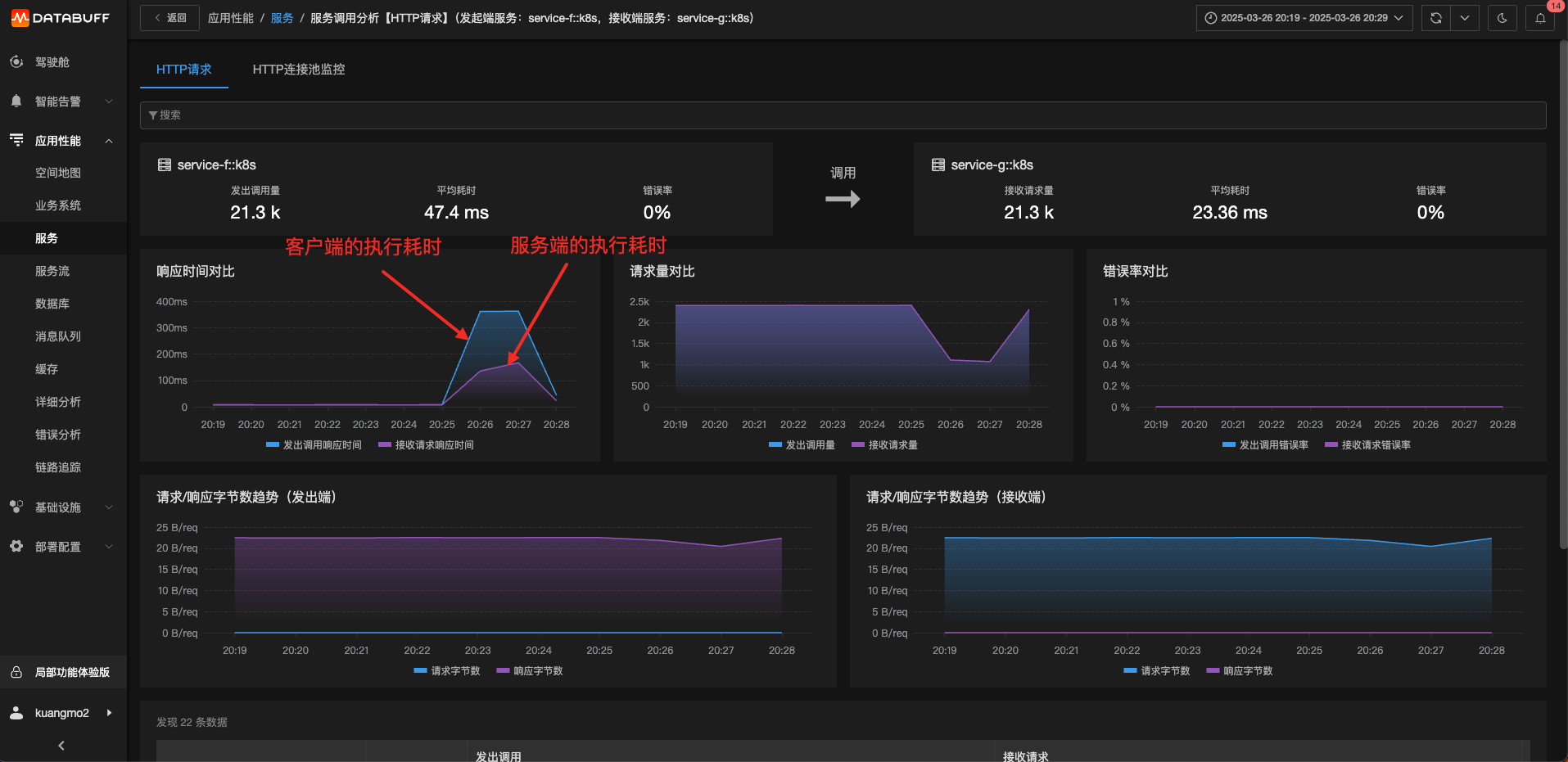
-
如果服務端的耗時也波動了,大概率就是服務端的問題;
-
如果服務端的耗時沒有波動,大概率是網絡問題或者客戶端的問題:
-
通過網絡丟包、重傳來確定是否有網絡問題;
-
如果GC嚴重則大概率是客戶端問題。
-
2.2 定位(確定服務節點上的具體問題)
當確定了當前服務是根因服務時(即下游服務并未發現問題),我們就需要分析當前服務自身的問題。
當前服務自身的問題包含如下幾種類型:
-
GC問題
-
資源問題
-
變更問題
-
等等
對這幾種類型的問題,我們只能一一檢測,并且上述只能作為輔助因素,因為沒有嚴謹的數據能證明GC超過XXXms跟當前故障是否一定強相關。
當我們要查看該服務或者實例的資源指標時,就涉及到非常重要的數據關聯操作。
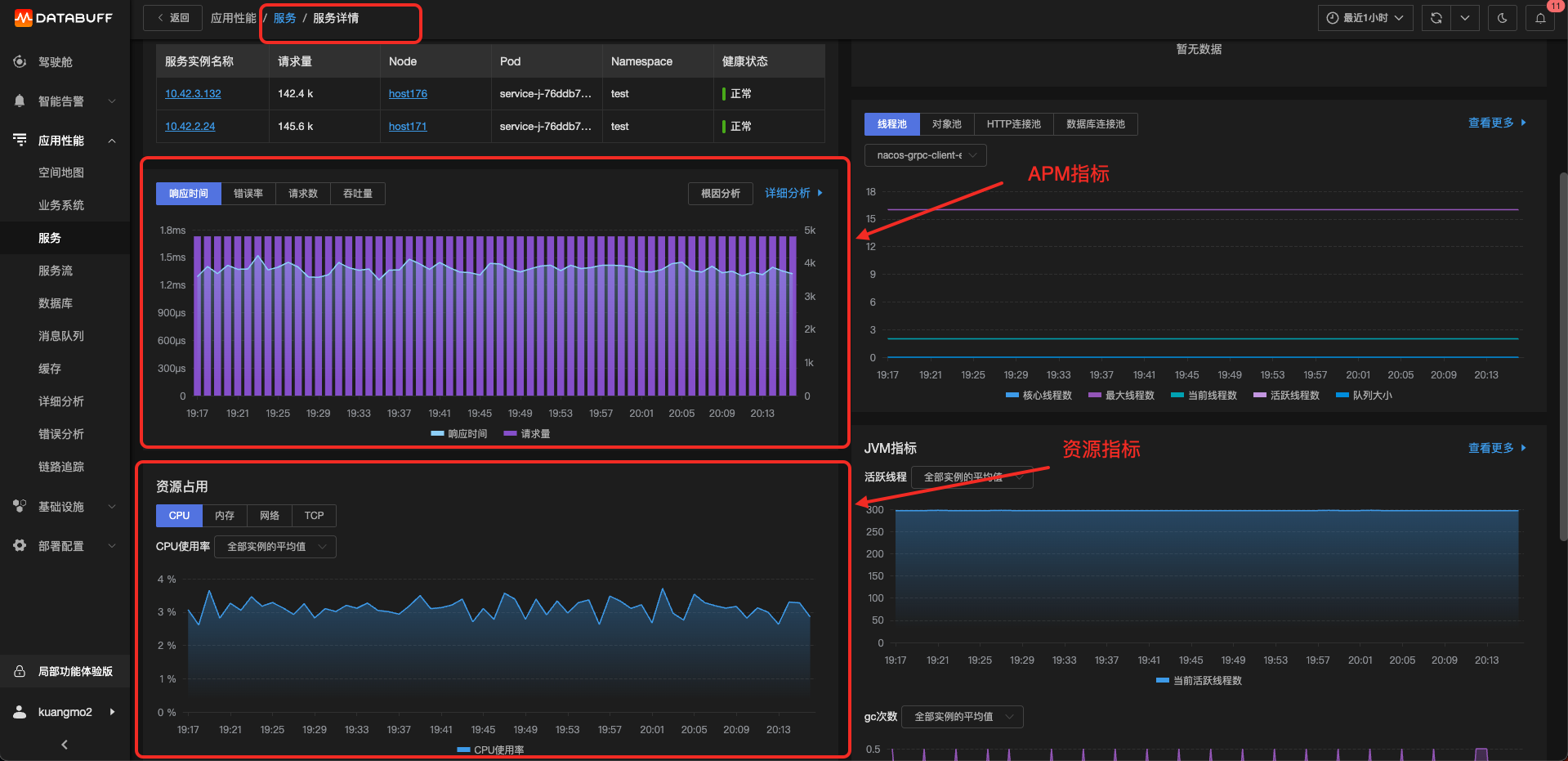
不同環境下的數據如何跟APM的服務和服務實例建立關聯呢?
| 不同環境下的數據來源 | APM數據(包含serviceName、ip、pid、containerId、podName、主機host、k8s clusterId) |
|---|---|
| 主機采集的進程數據(包含主機host、pid等) | 和APM關聯方案:主機host+pid |
| docker采集的容器數據 (包含主機host、containerId等) | 關聯方案:主機host+containerId |
| k8s采集的container數據(包含k8s clusterId、containerId、podName等) | 關聯方案:k8s clusterId+containerId |
本質上就是定義一套資源標準,將不同環境下的數據指標映射到這套標準上
- APM數據要采集足夠多的關聯字段,才能跟其他各種環境的資源數據進行關聯
做到了上述幾點,就建立起了服務實例跟各種資源指標的關聯,然后就進行異常檢測
CPU異常檢測的難點:
異常檢測為了適應各種服務的波動,通常是突變檢測,即產生突變即會認為是異常,對于CPU來說,很容易被突變檢測認為是異常,因此還需要一些其他的一些抗干擾的檢測能力。
-
最低的CPU閾值:低于此則不認是異常;
-
波動率:比如至少波動30%才可能認為造成響應時間的波動。
同時對CPU波動度進行打分,波動度越高得分高,根因排序的優先級就高,因此同一個服務內的各個根因都要有打分機制,通過打分機制來決定到底哪個更適合作為根因
3 實戰案例
接下來,我們采用故障演練的方式來驗證。
我們到RootTalk Sandbox上進行上述故障場景的復現。
:::
RootTalk Sandbox是一個故障演練和定位的系統,可以進行多種故障場景的復現,目前開放注冊。
地址:https://sandbox.databuff.com/
:::
3.1 故障注入
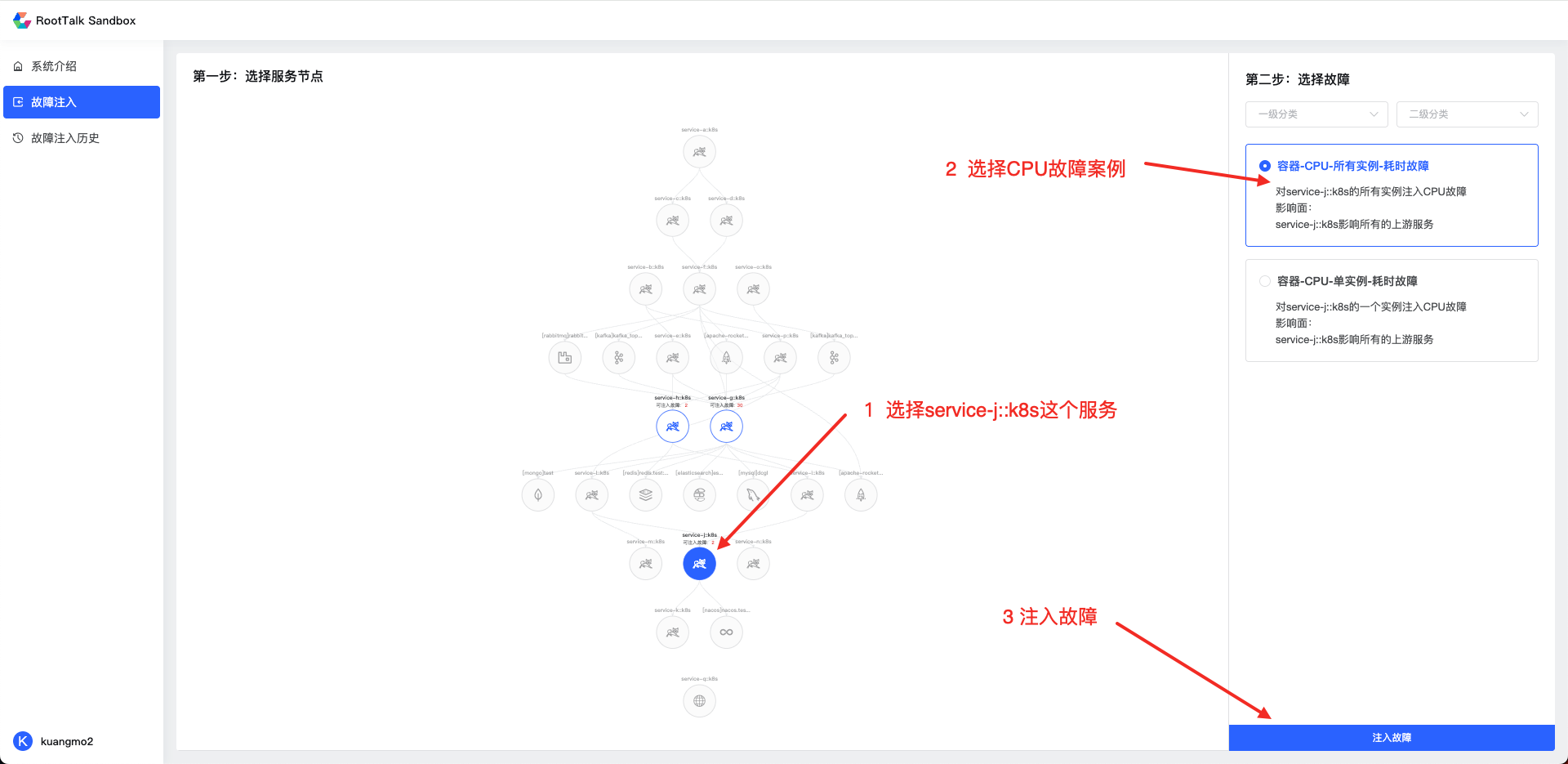
如上圖所示進行操作,對拓撲圖中的service-j::k8s這個服務的所有實例容器CPU滿載的故障。
注入后等待2~3分鐘,可直接點擊跳轉到Databuff的故障定位平臺。
3.2 故障定位
登錄Databuff后可以看到完整故障樹,如下圖。
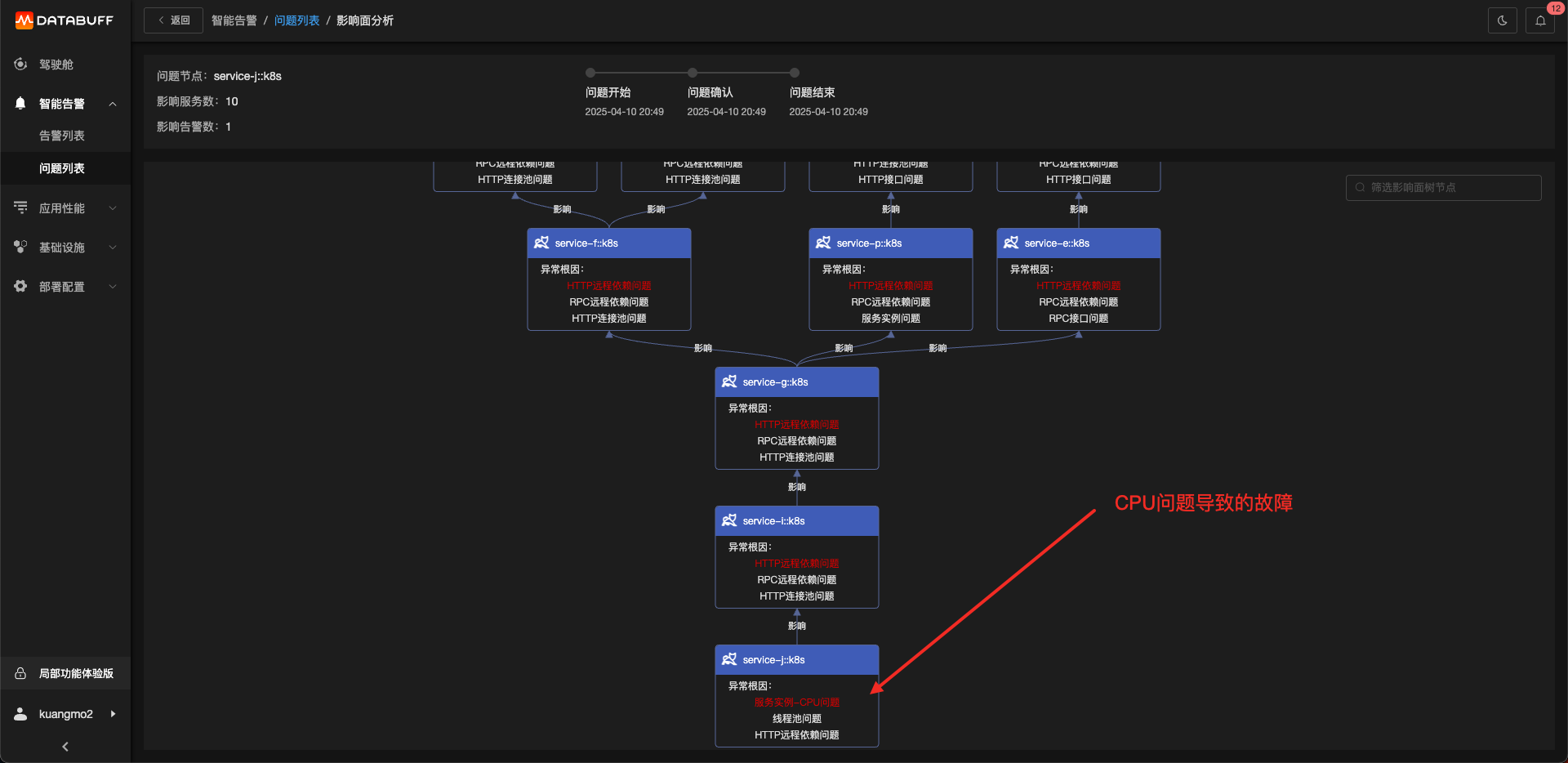
點擊根因節點
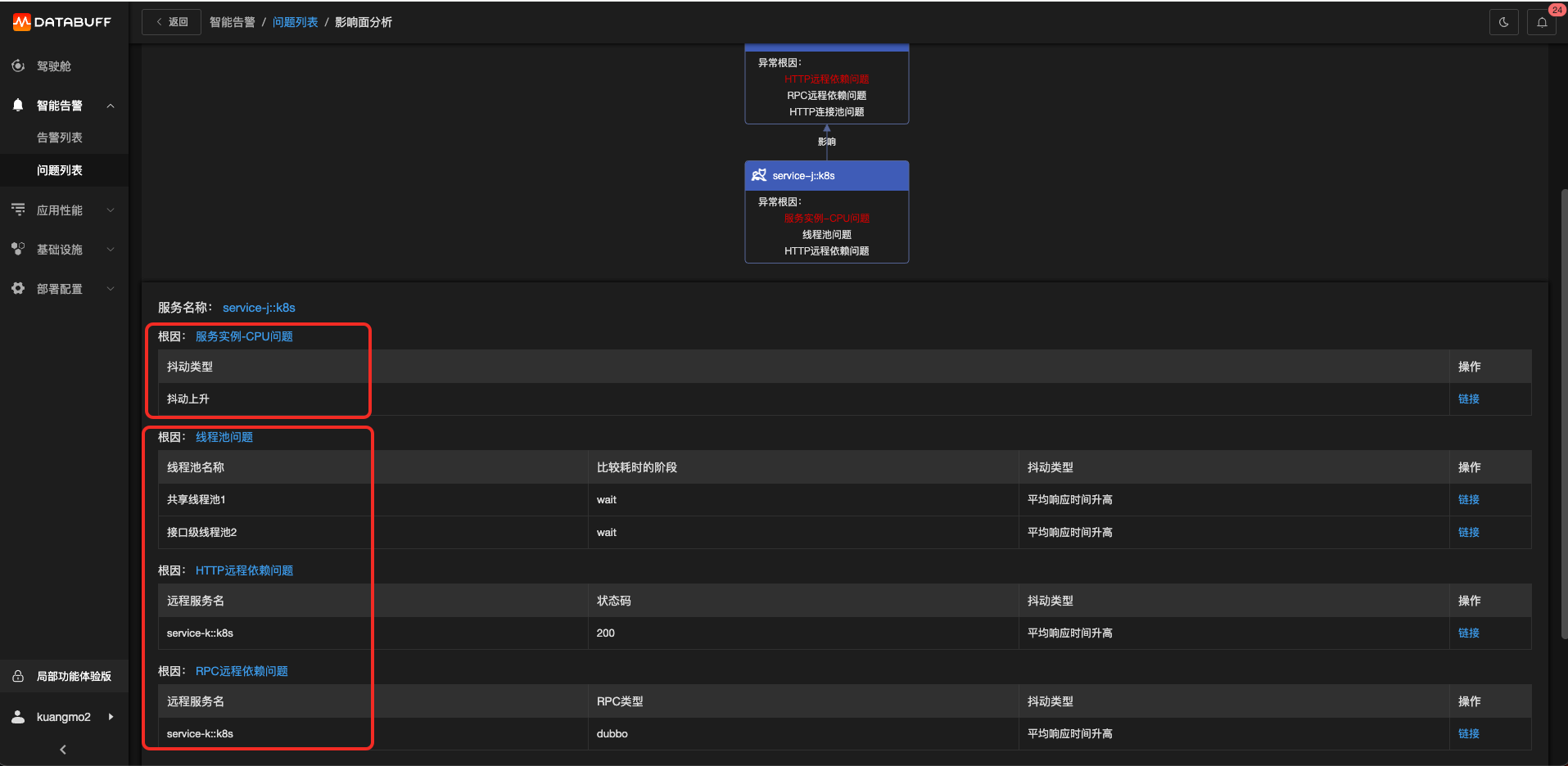
由于CPU問題會導致許多的組件訪問都會出現問題,所以CPU的優先級會更高一些。
點擊服務實例-CPU問題的地址鏈接,可以直接驗證是否真的是CPU抖動上升了。
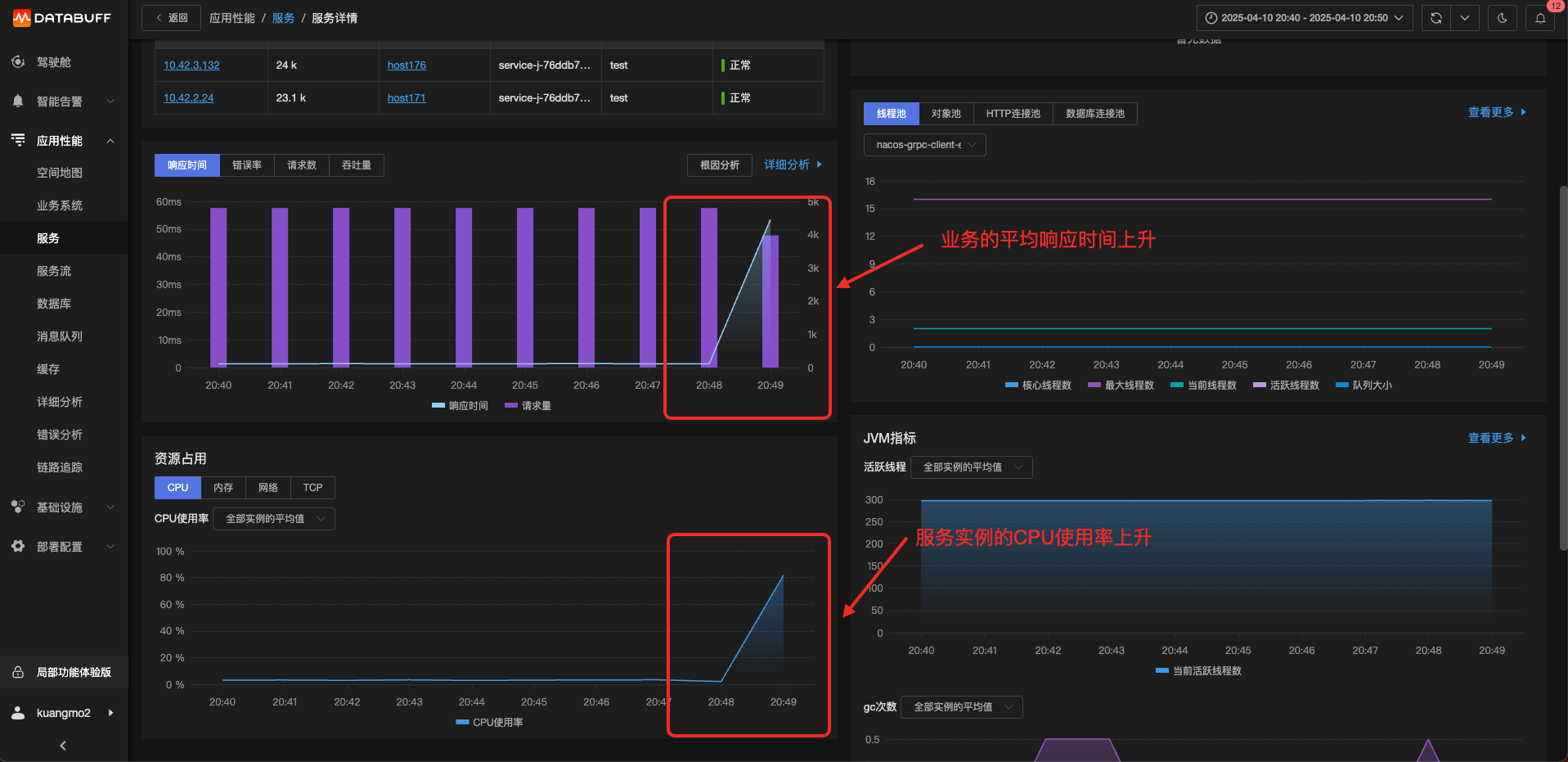
這個排查過程只需要幾分鐘就可完成。

的解析)
)



 — 探針和鉤子)


)
)


)


)
圖像與通道拼接函數-----仿射變換函數warpAffine())

