樸素貝葉斯分類器
樸素貝葉斯是一種基于密度估計的分類算法,它利用貝葉斯定理進行預測。該算法的核心假設是在給定類別的情況下,各個特征之間是條件獨立的,盡管這一假設在現實中通常不成立,但樸素貝葉斯分類器依然能夠生成對有偏類密度估計具有較強魯棒性的后驗分布,尤其是在后驗概率接近決策邊界(0.5)時。
樸素貝葉斯分類器通過最大后驗概率決策規則將觀測值分配到最有可能的類別。
具體步驟如下:
- 密度估計:計算每個類別中各特征的密度分布。
- 后驗概率建模:根據貝葉斯公式計算后驗概率。對于所有類別 k = 1 , … , K k = 1, \ldots, K k=1,…,K,
P ^ ( Y = k ∣ X 1 , … , X d ) = P ( Y = k ) ∏ j = 1 d P ( X j ∣ Y = k ) ∑ k = 1 K P ( Y = k ) ∏ j = 1 d P ( X j ∣ Y = k ) , \widehat{P}(Y = k | X_1, \ldots, X_d) = \frac{P(Y = k) \prod\limits_{j=1}^{d} P(X_j | Y = k)}{\sum_{k=1}^{K} P(Y = k) \prod\limits_{j=1}^{d} P(X_j | Y = k)}, P (Y=k∣X1?,…,Xd?)=∑k=1K?P(Y=k)j=1∏d?P(Xj?∣Y=k)P(Y=k)j=1∏d?P(Xj?∣Y=k)?,
其中:
- Y Y Y表示觀測值所屬類別的隨機變量。
- X 1 , … , X d X_1, \ldots, X_d X1?,…,Xd?是觀測值的特征變量。
- P ( Y = k ) P(Y = k) P(Y=k)是類別 k k k的先驗概率。
- 分類決策:通過比較不同類別的后驗概率,將觀測值歸類到后驗概率最大的類別中。
兩類密度估計方法
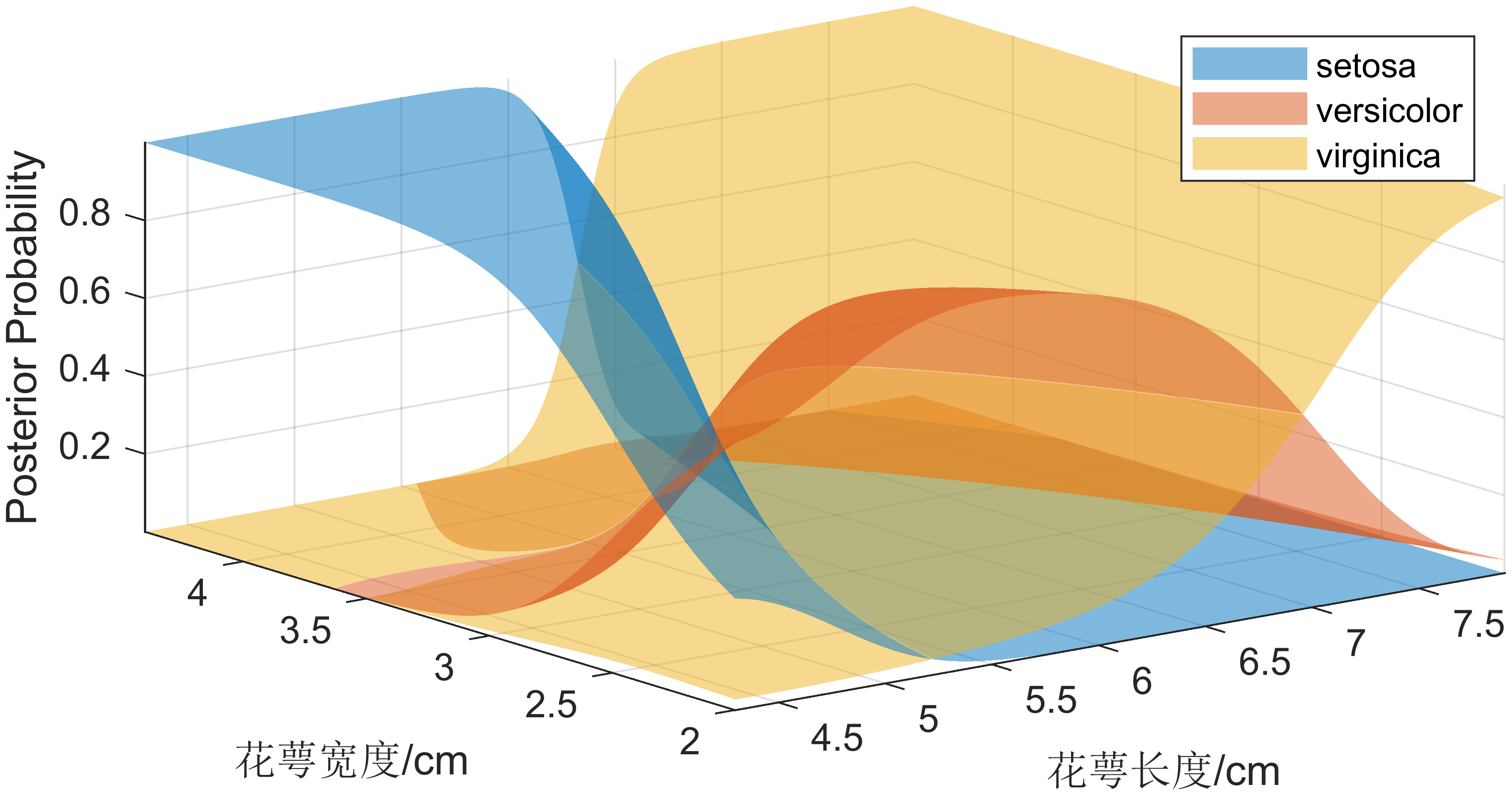
Normal (Gaussian) Distribution
The ‘normal’ distribution (specify using ‘normal’) is appropriate for predictors that have normal distributions in each class. For each predictor you model with a normal distribution, the naive Bayes classifier estimates a separate normal distribution for each class by computing the mean and standard deviation of the training data in that class.
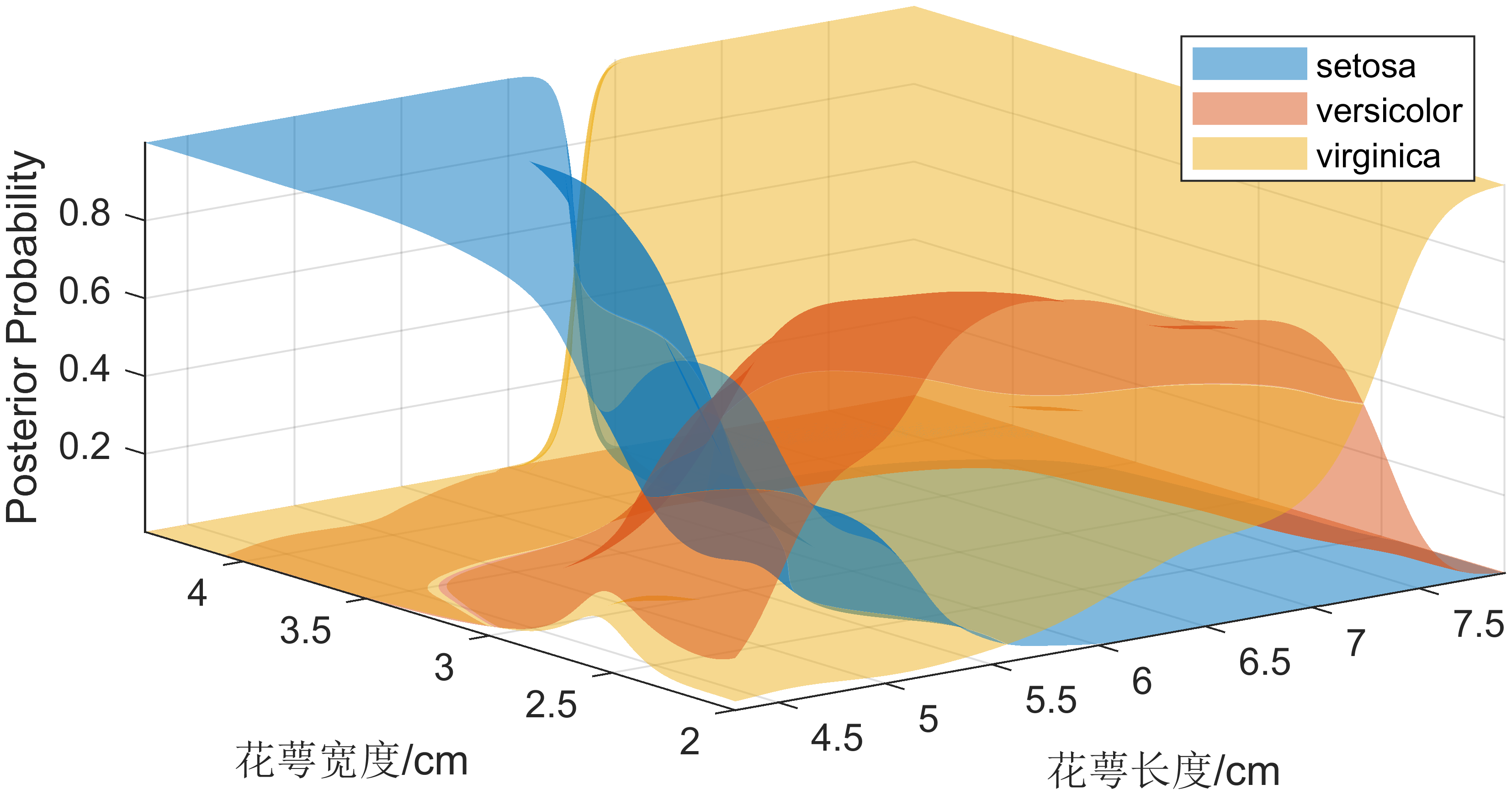
Kernel Distribution
The ‘kernel’ distribution (specify using ‘kernel’) is appropriate for predictors that have a continuous distribution. It does not require a strong assumption such as a normal distribution and you can use it in cases where the distribution of a predictor may be skewed or have multiple peaks or modes. It requires more computing time and more memory than the normal distribution. For each predictor you model with a kernel distribution, the naive Bayes classifier computes a separate kernel density estimate for each class based on the training data for that class. By default the kernel is the normal kernel, and the classifier selects a width automatically for each class and predictor. The software supports specifying different kernels for each predictor, and different widths for each predictor or class.
定理 設 ( X 1 , X 2 , ? , X n ) (X_1, X_2, \cdots, X_n) (X1?,X2?,?,Xn?)是 n n n維連續型隨機變量, f ( x 1 , x 2 , ? , x n ) f(x_1, x_2, \cdots, x_n) f(x1?,x2?,?,xn?)是其聯合概率密度函數, f X i ( x i ) f_{X_i}(x_i) fXi??(xi?)是關于 X i ( i = 1 , 2 , ? , n ) X_i (i=1,2,\cdots,n) Xi?(i=1,2,?,n)的邊緣概率密度函數,則隨機變量 X 1 , X 2 , ? , X n X_1, X_2, \cdots, X_n X1?,X2?,?,Xn?相互獨立等價于
f ( x 1 , x 2 , ? , x n ) = ∏ i = 1 n f X i ( x i ) , f(x_1, x_2, \cdots, x_n) = \prod_{i=1}^{n} f_{X_i}(x_i), f(x1?,x2?,?,xn?)=i=1∏n?fXi??(xi?),
其中 ( x 1 , x 2 , ? , x n ) (x_1, x_2, \cdots, x_n) (x1?,x2?,?,xn?)為任意的實數組。


優化器nestloop參數化路徑評估不準問題分析)



)

![[藍橋杯真題題目及解析]2025年C++b組](http://pic.xiahunao.cn/[藍橋杯真題題目及解析]2025年C++b組)

)








