1??為什么要進行案例研究?
????????過去,計算機視覺中的大量研究都集中在如何將卷積層、池化層以及全連接層這些基本組件組合起來,形成有效的卷積神經網絡。
????????找感覺的最好方法之一就是去看一些示例,就像很多人通過看別人的代碼來學習編程一樣。我認為一個很好的方法去了解關于如何構建卷積神經網絡,就是去看別人構建的高效卷積神經網絡。事實證明,一個神經網絡結構,如果在一個計算機視覺問題中表現的很好,通常也會在別的問題中表現很好。
????????在接下來,我們將會,學習一些計算機視覺領域的研究論文。
2??經典網絡
? ? ? ? ?LeNet-5的網絡架構是:
????????從一幅32×32×1的圖像開始,而LeNet-5的任務是識別手寫數字,LeNet-5是針對灰度圖像訓練的,這就是為什么他是32×32×1。
????????LeNet-5的第一層使用六個5×5的過濾器,步長為1,padding為0,輸出結果是28×28×6,圖像尺寸從32×32縮小到28×28,然后進行池化操作。在這篇論文發表的那個年代,人們更喜歡用平均池化;而現在,我們可能用最大池化更多一點。但是在這個例子中,我們進行平均池化,過濾器的寬度為二,步長為二,圖像的高度和寬度都縮小兩倍,輸出結果是一個14×14×6的圖像。
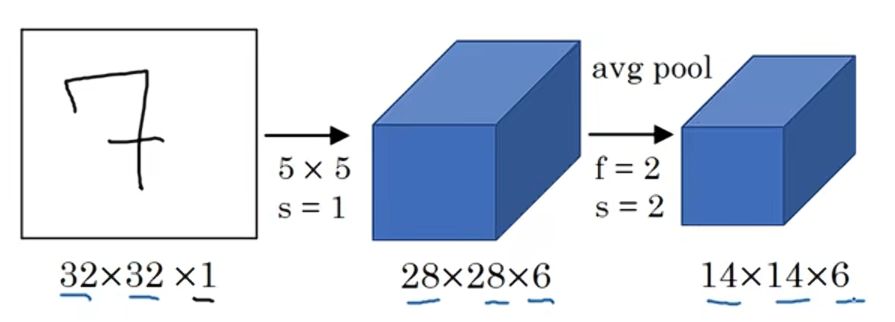
?????????在LeNet-5論文發表的年代,當時人們并不使用padding或者valid卷積,這就是為什么每進行一次卷積,圖像的高度和寬度都會縮小一半。
????????接下來繼續用16個5×5,步長為1的過濾器進行卷積,新的輸出結果是10×10×16,再進行平池化,輸出5×5×16。
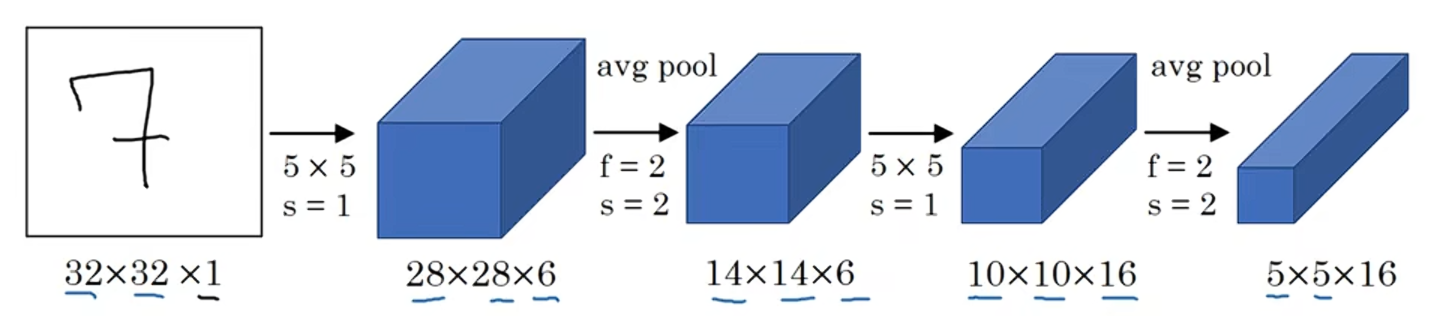
? ? ? ? 把5×5×16展平成400個神經單元,建立全連接層,120個神經元每個都全連接這400個單元;再建立一層全連接層,用84維特征生成一個最終結果,
可能有10個可能值,對應識別的0-9這10個數字。現在,用Softmax函數輸出十種分類結果
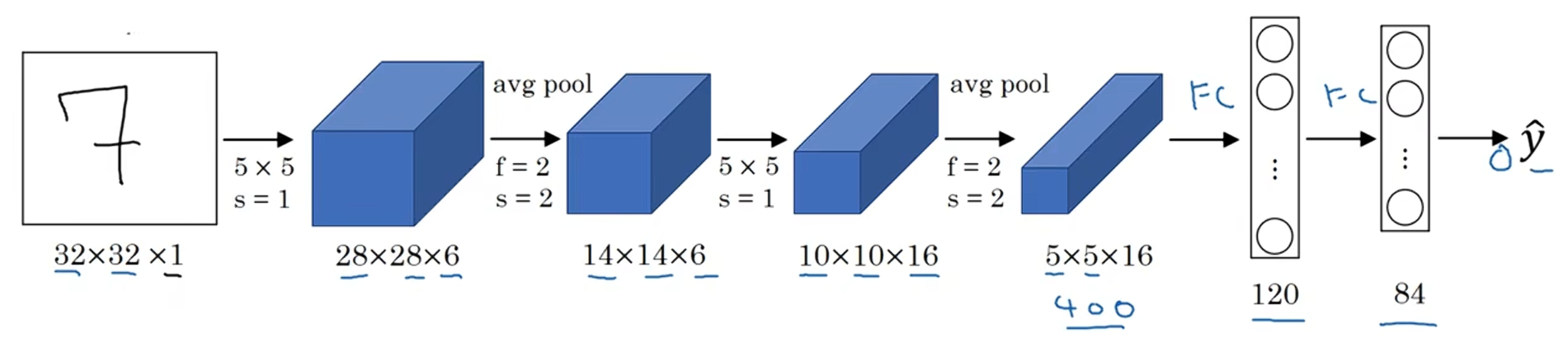
?????????盡管LeNet-5原先是用別的分類器做輸出層,而這個分類器現在已經不用了。用現在的標準來看,這是個小型神經網絡,大概有6萬個參數;而如今你經常會見到千萬到億量級參數的神經網絡。不管怎樣,如果我們從左往右看這個神經網絡,會發現隨著網絡越來越深,圖像的高度和寬度都在縮小,從最初的32×32縮小到28×28,再到14×14,10×10,最后只有5×5;與此同時,隨著網絡層次的加深,通道數量一直在增加,從1個增加到6個,再到16個。這個神經網絡中還有一個模式,至今仍然經常用到,那就是先使用一個或者多個卷積層,后面跟著一個池化層,然后又是若干個卷積層,再接一個池化層,然后是全連接層,最后是輸出,這種排列方式很常見。
? ? ? ? AlexNet的網絡架構是:
????????AlexNet首先用一張227×227×3的圖片作為輸入,如果你讀了這篇論文,論文提及的是224×224×3的圖像,但如果你檢查數字,你會發現227×227才合理。
? ? ? ? 第一層使用96個11×11,步長為4的過濾器,圖像尺寸縮小到55×55×96,隨后的最大池化層用了3×3的過濾器,尺寸縮小為27×27×96,然后用256個5×5的過濾器進行Same卷積,得到27×27×256,再來一次做最大池化,尺寸縮小到13×13×256。
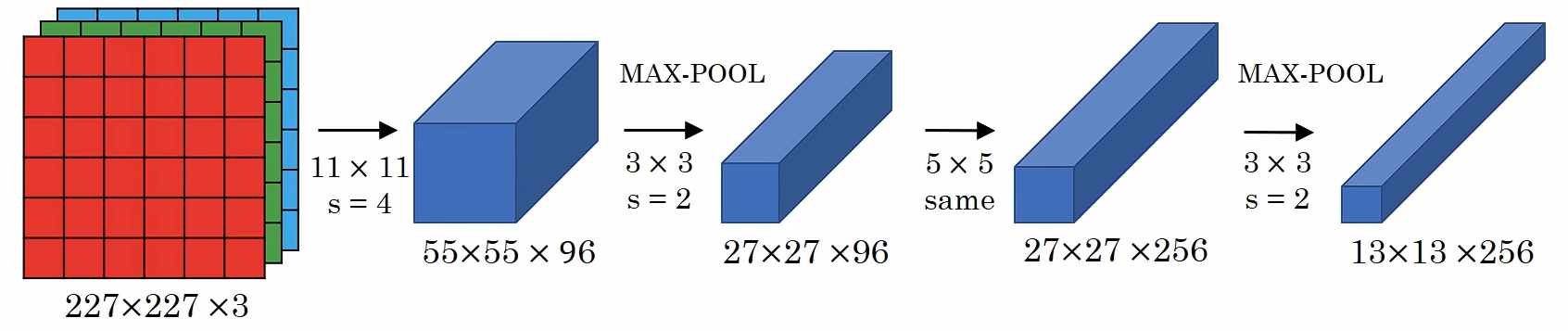

?????????使用384個3×3的過濾器進行兩次Same卷積,得到13×13×384;用256個3×3的過濾器進行卷積,得到13×13×256,進行最大池化,尺寸縮小到6×6×256,把他展平成9216個單元,然后進行一些全連接層,使用Softmax函數輸出,看他是1000個可能對象中的哪一個?
????????Alexnet神經網絡結構與LeNet有很多相似之處,不過Alexnet要大很多,AlexNet包含約6000萬個參數,AlexNet采用與LeNet相似的構造版塊,擁有更多隱藏神經元、在更多數據上訓練。Alexnet在ImageNet數據庫上訓練,使它有優秀的性能。
?????????Alexnet神經網絡比LeNet更好地原因是:Relu函數的使用。
? ? ? ? VGG-16的網絡架構是:
????????按作者所說,關于VGG-16非常值得注意的一點是:VGG-16沒有那么多超參數,結構更簡單,更能關注卷積層,使用3×3、步長為1的Same過濾器;最大池化的過濾器都是2×2、步長為2。
????????假設你要識別224×224×3的圖像,在最開始的兩層,用64個3×3的過濾器對輸入的圖像進行Same卷積,得到224×224×64的結果,使用最大池化縮小到112×12×64;接著又是使用2層Same卷積層,結果是112×112×128,經過池化層后,維度是56×56×128;再使用三層Same卷積層,使得維度變成56×56×256,接著使用池化層后維度變成28×28×256;再經過三層Same卷積層變成28×28×512,經過最大池化變成14×14×512。再經過卷積、池化,直到最后維度變成7×7×512,把得到的神經單元展平拉直,通過全連接層,經過Softmax函數輸出1000類結果。
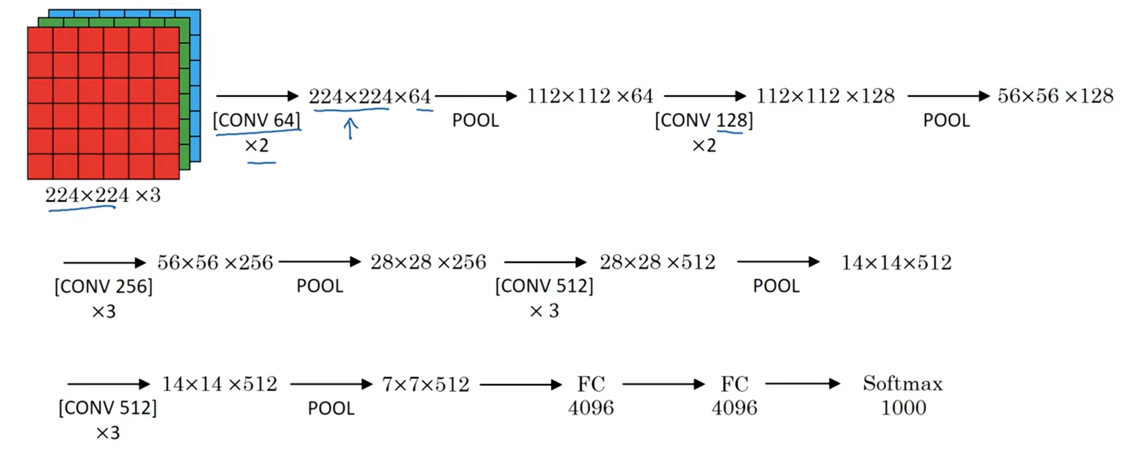
????????VGG-16中的16指該網絡有16層帶權重的層,這是一個相當大的網絡,它總共有一億三千八百萬個參數。即使以現在的衡量標準,也是很大的 。VGG-16結構的簡潔性也非常吸引人,看得出這個結構相當統一,先是幾層卷積層,再是池化層。另一方面,如果你看卷積層中過濾器數,從64到128到256再到512,每次粗略的雙倍增加過濾器的方式是設計神經網絡時用的另一個簡單原則。
3??ResNets
????????太深的神經網絡訓練起來很難,因為有梯度消失和梯度爆炸問題,我們將學習跳躍連接,它可以允許從某一網絡層得到激活值,并迅速傳遞給下一層甚至是更深的神經網絡層,利用它你就可以訓練網絡層很深的殘差網絡。殘差網絡是使用了殘差結構的網絡。
????????這里有兩層神經網絡,代表第L層的激活函數,然后是
,兩層后得到
。
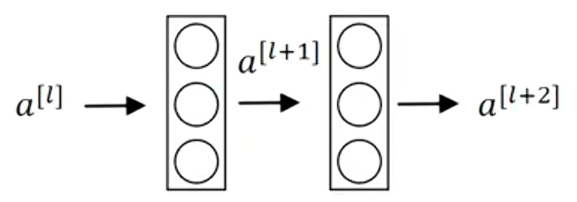
? ? ? ? 在這個例子的激活函數,作為輸入,計算出
,之后應用非線性激活函數Relu得到
;然后在下一層經過線性計算
,再使用一次Relu函數得到
。換句話說,從
流向
的信息需要經過上面的所有步驟,我把這稱做這組層的主路徑。
????????在殘差網絡中,我們需要做個改變,把直接向后連接到深層神經網絡的位置。
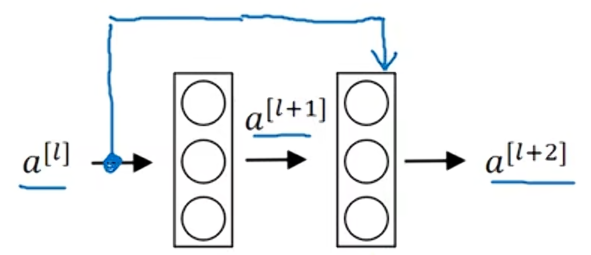
? ? ? ? 這條路徑是在進行Relu非線性激活函數之前加上的。也就是,
。
? ? ? ? 我們來看看下面這個網絡,它并不是一個殘差網絡,而是一個普通網絡:

? ? ? ? 把它變成ResNet的方法是加上所有的跳躍連接,就像這樣:?

????????事實證明,如果你使用標準的優化算法(如梯度下降法)來訓練普通網絡,從經驗上來說,你會發現當你增加層數時,訓練誤差會在下降一段時間后回升;
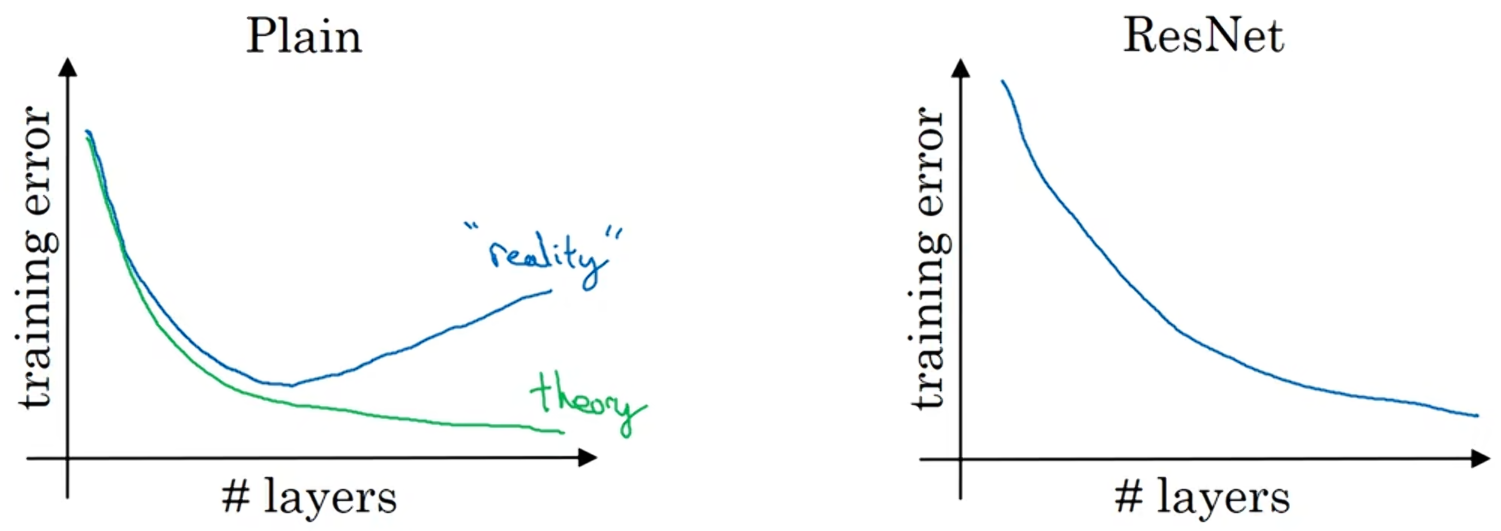
????????而理論上,隨著網絡深度的加深,應該訓練的越來越好。如果沒有殘差網絡,對于一個普通網絡來說,網絡越深意味著用優化算法越難訓練,訓練錯誤會越來越多;但是有了ResNet就不一樣了,即使網絡再深,訓練表現也不錯,訓練錯誤會減少。
4??ResNets 為何有效?
? ? ? ? 為什么ResNets這么好用吶?
????????一個網絡深度越深,它會使得你用訓練集訓練神經網絡的能力下降,這也是有時候我們不希望加深網絡的原因,但當你訓練ResNet的時候就不一樣了,我們來看一個例子。
????????如果你有一個大型神經網絡,它的輸入是x,輸出激活值。

?????????如果你想調整神經網絡,使其深度更深一點:
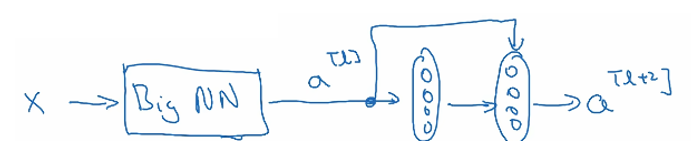
????????把這兩層看作是具有跳躍連接的殘差塊。為了方便說明,假設我們在整個網絡中使用Relu激活函數,所有激活值都大于等于零。
? ? ? ? 我們看一下的值,也就是
,展開這個表達式,也就是:
。注意一點,如果使用L2正則化或者權重衰減,它會壓縮
的值,如果對b使用權重衰減也會達到同樣的效果。這里的w是關鍵項,假設
,如果
,那么
,
。因為我們假設使用Relu激活函數,并且所有激活值都是非負的,
是非負的,所以結果是
,這意味著殘差塊比較容易學習恒等函數,由于這個跳躍連接也很容易得到
,將這兩層加入到你的神經網絡,與上面這個沒有這兩層的網絡相比,并不會非常影響神經網絡的能力,因為對于它來說學習恒等函數非常容易。所以這就是為什么添加兩層,不論是把殘差塊添加到神經網絡的中間還是尾部都不會影響神經網絡的表現。
????????當然,我們的目標并不只是維持原有的表現,而是幫助獲得更好的表現。你可以想象,如果這些隱藏單元學習到一些有用信息,那么它可能比學習恒等函數表現的更好;而這些不含殘差塊或跳躍連接的普通神經網絡,情況就不一樣了。當網絡不斷加深時,就算是選擇用來學習恒等函數的參數也很困難,所以很多層最后的表現,不但沒有更好,反而更糟。
????????我認為殘差網絡起作用的主要原因是:這些額外層學習恒等函數非常容易,幾乎總能保證它不會影響總體的表現,很多時候甚至可以提高效率,或者說至少不會降低網絡效率。
????????除此之外,關于殘差網絡另一個值得討論的細節是:對于,我們是假定
和
具有相同的維度。所以你會看到在ResNet中許多Same卷積的使用。如果輸入和輸出有不同的維度,假如
是128維,而
和
的結果是256維的,我們可以讓
與一個256×128維的
矩陣相乘,也就是
。
????????
????????


![[C語言]猜數字游戲](http://pic.xiahunao.cn/[C語言]猜數字游戲)









)






