從零開始構建微博爬蟲與數據分析系統
引言
社交媒體平臺蘊含著海量的信息和數據,通過對這些數據的收集和分析,我們可以挖掘出有價值的見解。本文將詳細介紹如何構建一個完整的微博爬蟲和數據分析系統,從數據爬取、清洗、到多維度分析與可視化。
系統架構
整個系統分為兩個主要模塊:
- 微博爬蟲模塊:負責通過API獲取微博數據并保存
- 數據分析模塊:對獲取的數據進行清洗和多維度分析
一、微博爬蟲實現
1.1 爬蟲設計思路
微博的數據爬取主要基于其Ajax接口,通過模擬瀏覽器請求獲取JSON格式數據。主要挑戰在于:
- 需要登錄憑證(Cookie)才能訪問完整內容
- 接口限制和反爬措施
- 數據格式的解析與清洗
1.2 核心代碼實現
WeiboCrawler類是爬蟲的核心,主要包含以下功能:
class WeiboCrawler:def __init__(self, cookie=None):# 初始化請求頭和會話self.headers = {...}if cookie:self.headers['Cookie'] = cookieself.session = requests.Session()self.session.headers.update(self.headers)def get_user_info(self, user_id):# 獲取用戶基本信息url = f'https://weibo.com/ajax/profile/info?uid={user_id}'# 實現...def get_user_weibos(self, user_id, page=1, count=20):# 獲取用戶微博列表url = f'https://weibo.com/ajax/statuses/mymblog?uid={user_id}&page={page}&feature=0'# 實現...def crawl_user_weibos(self, user_id, max_pages=None):# 爬取所有微博并返回結果# 實現...
1.3 數據清洗與存儲
爬取的原始數據需要進行清洗,主要包括:
- 去除HTML標簽和特殊字符
- 提取時間、內容、圖片鏈接等信息
- 識別轉發內容并單獨處理
清洗后的數據以結構化文本形式存儲,便于后續分析:
def format_weibo(self, weibo):# 格式化微博內容為易讀格式created_at = datetime.strptime(weibo['created_at'], '%a %b %d %H:%M:%S %z %Y')text = self.clean_text(weibo.get('text', ''))formatted = f"[{created_at.strftime('%Y-%m-%d %H:%M:%S')}]\n{text}\n"# 處理轉發內容、圖片鏈接等# ...return formatted
二、數據分析模塊
2.1 數據加載與預處理
WeiboAnalyzer類負責從文本文件加載微博數據,并轉換為結構化形式:
def load_data(self):# 從文件加載微博數據with open(self.file_path, 'r', encoding='utf-8') as f:lines = f.readlines()# 提取用戶信息和微博內容# ...print(f"成功加載 {len(self.weibos)} 條微博")
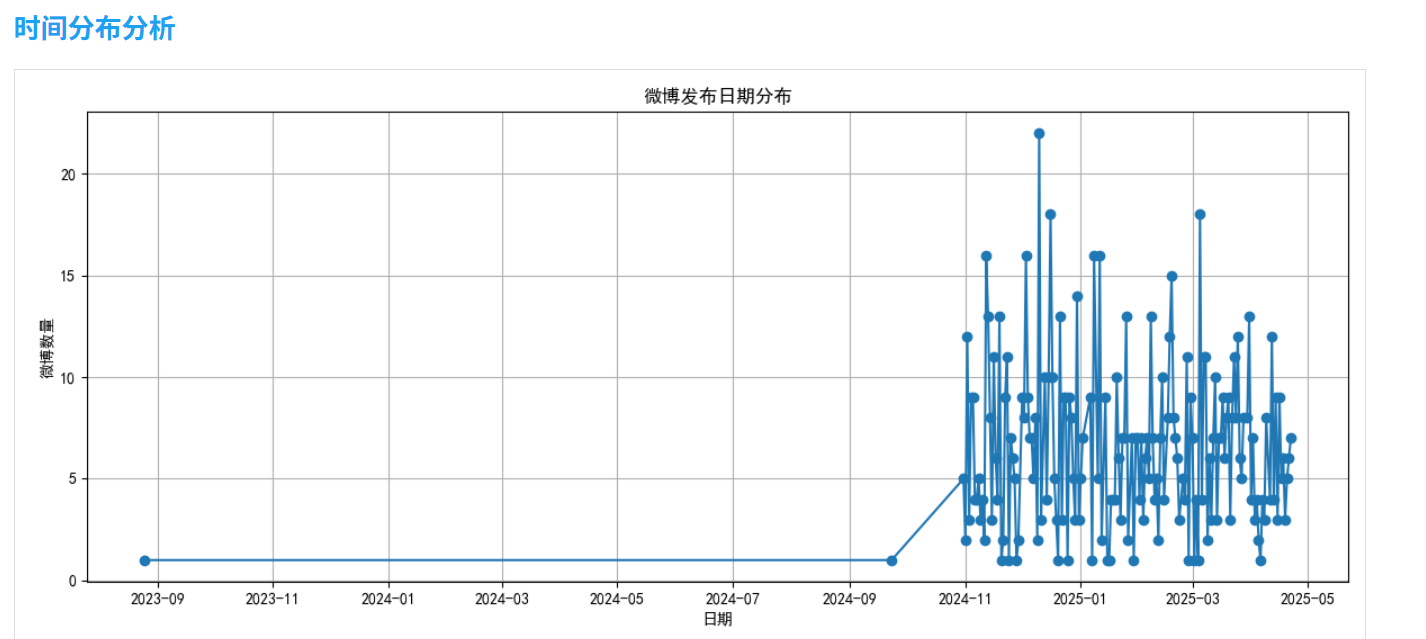
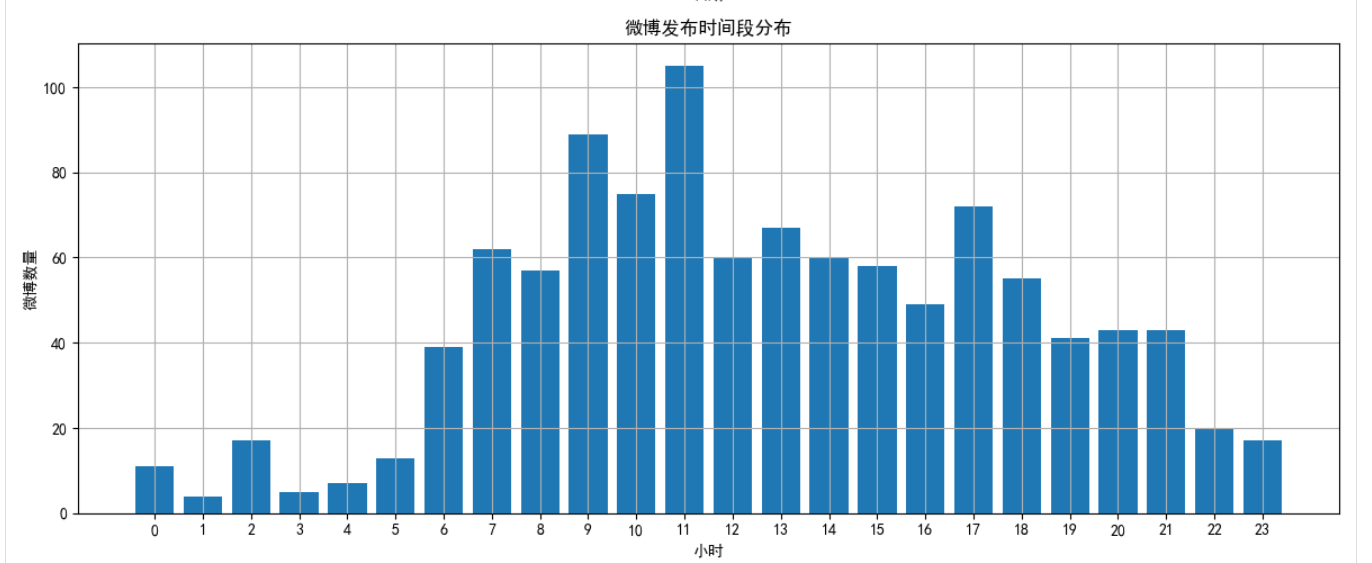
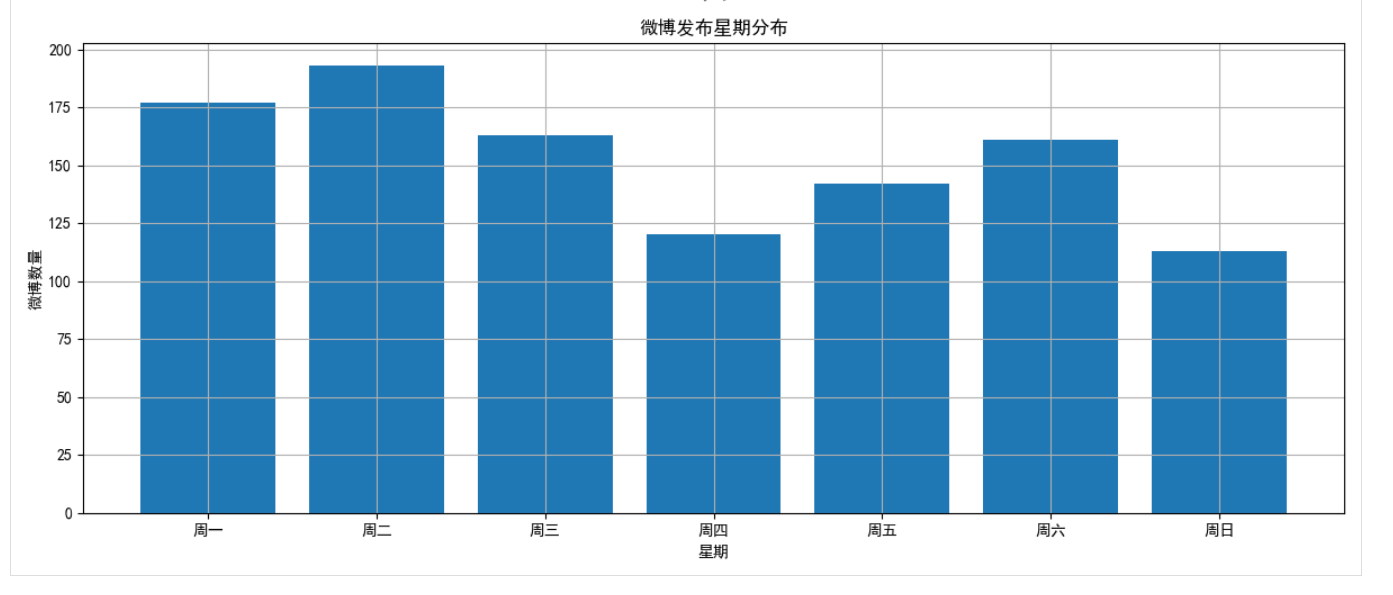
2.2 時間分布分析
分析微博發布的時間規律,包括日期、小時和星期分布:
def time_distribution_analysis(self):# 提取日期和時間dates = [weibo['date'].date() for weibo in self.weibos]hours = [weibo['date'].hour for weibo in self.weibos]weekdays = [weibo['date'].weekday() for weibo in self.weibos]# 使用pandas和matplotlib進行統計和可視化# ...
通過這一分析,我們可以了解用戶在什么時間段最活躍,是否有固定的發布模式。
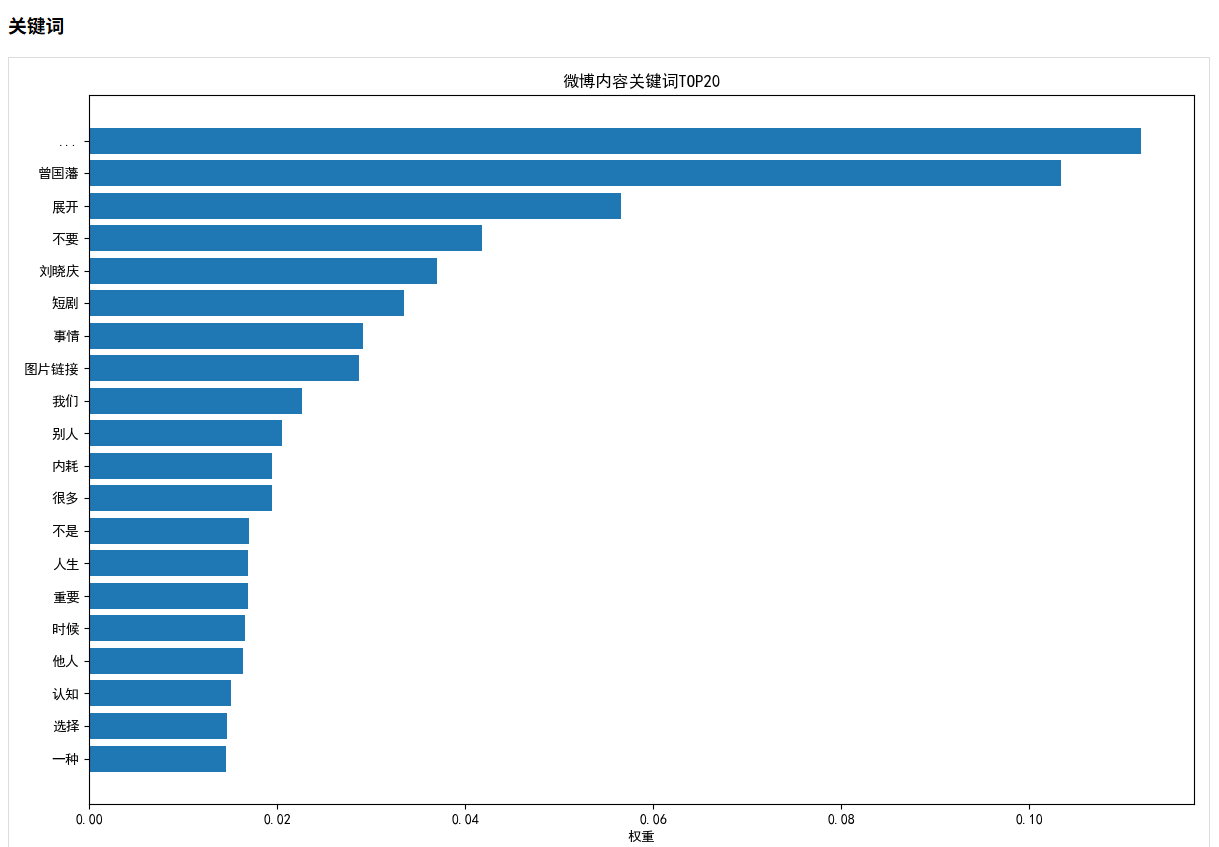
2.3 內容分析與關鍵詞提取
使用jieba分詞和TF-IDF算法提取微博內容的關鍵詞:
def content_analysis(self):# 合并所有微博內容all_content = ' '.join([weibo['content'] for weibo in self.weibos])# 使用jieba進行分詞jieba.analyse.set_stop_words('stopwords.txt')words = jieba.cut(all_content)# 過濾單個字符和數字filtered_words = [word for word in words if len(word) > 1 and not word.isdigit()]# 統計詞頻word_counts = Counter(filtered_words)# 提取關鍵詞keywords = jieba.analyse.extract_tags(all_content, topK=50, withWeight=True)# 生成詞云和關鍵詞圖表# ...
詞云能直觀地展示內容主題,關鍵詞分析則揭示了用戶最關注的話題。
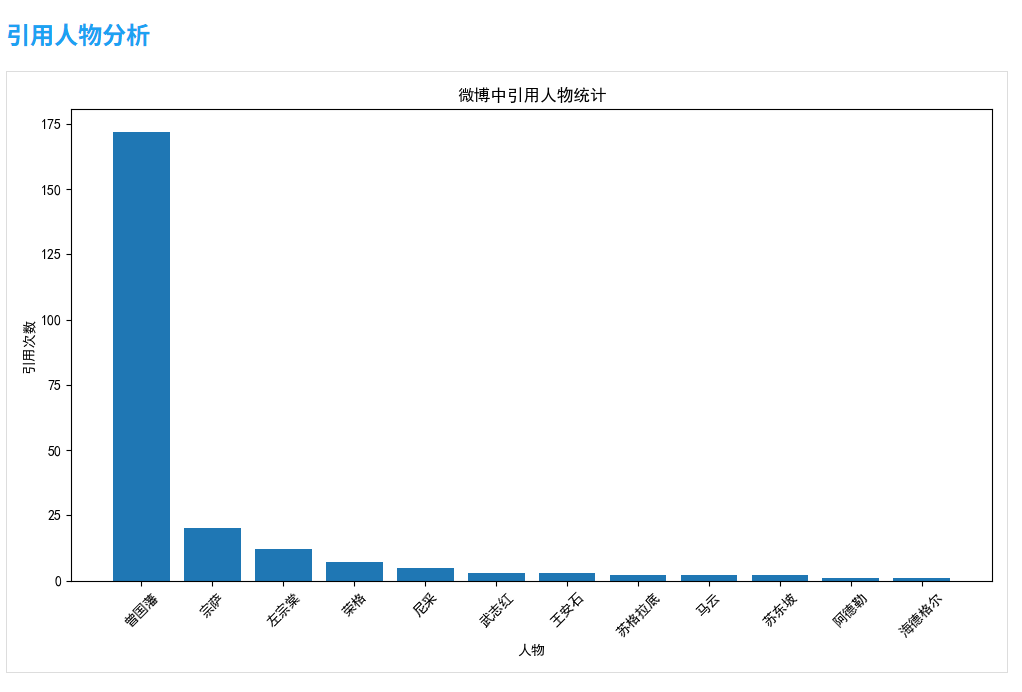
2.4 引用人物分析
分析微博中引用的名人或專家:
def quote_analysis(self):# 定義可能被引用的人物列表famous_people = ['曾國藩', '尼采', '榮格', '蘇格拉底', '馬云', '武志紅', '阿德勒', '王安石', '蘇東坡', '海德格爾', '左宗棠', '宗薩']# 統計每個人物被引用的次數quotes = {person: 0 for person in famous_people}for weibo in self.weibos:content = weibo['content']for person in famous_people:if person in content:quotes[person] += 1# 繪制引用人物條形圖# ...
這一分析可以揭示用戶的思想傾向和崇拜的對象。
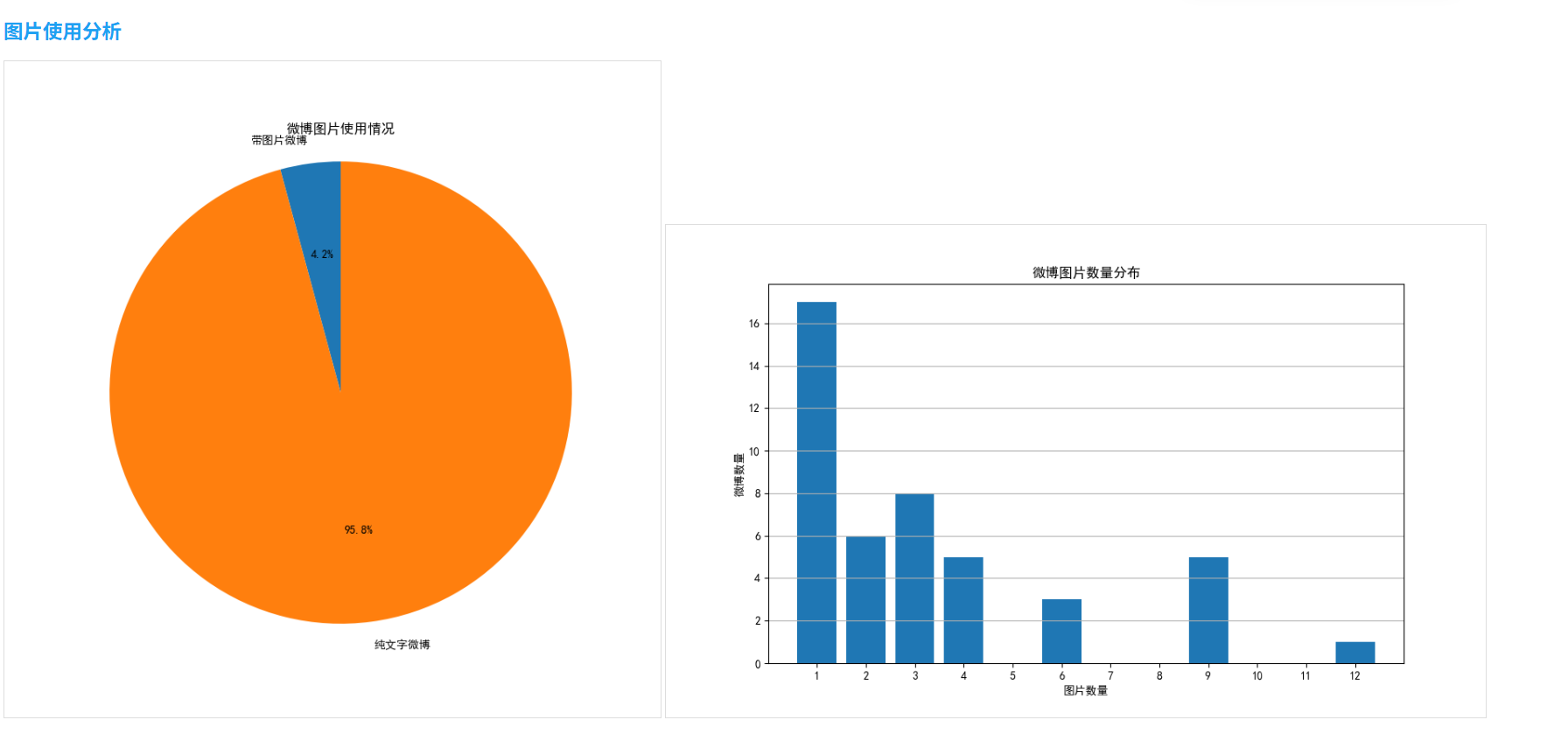
2.5 圖片使用分析
分析微博中的圖片使用情況:
def image_analysis(self):# 統計帶圖片的微博數量weibos_with_images = [weibo for weibo in self.weibos if weibo['images']]image_counts = [len(weibo['images']) for weibo in weibos_with_images]# 計算統計數據total_weibos = len(self.weibos)weibos_with_images_count = len(weibos_with_images)percentage = weibos_with_images_count / total_weibos * 100 if total_weibos > 0 else 0# 繪制餅圖和分布圖# ...
三、可視化報告生成
最終,將所有分析結果整合為一個HTML報告:
def generate_report(self):# 執行所有分析self.time_distribution_analysis()self.content_analysis()self.quote_analysis()self.image_analysis()# 生成HTML報告html_content = f"""<!DOCTYPE html><html><head><meta charset="UTF-8"><title>微博數據分析報告</title><style>body {{ font-family: Arial, sans-serif; margin: 20px; }}h1, h2 {{ color: #1DA1F2; }}.section {{ margin-bottom: 30px; }}img {{ max-width: 100%; border: 1px solid #ddd; }}</style></head><body><h1>微博數據分析報告</h1><!-- 各部分分析結果 --><!-- ... --></body></html>"""with open('weibo_analysis_report.html', 'w', encoding='utf-8') as f:f.write(html_content)
四、實際應用案例
以用戶"侯小強"(ID: 1004524612)為例,我爬取了其全部1069條微博并進行分析。以下是一些關鍵發現:
- 時間分布:該用戶主要在晚上8點至10點發布微博,周六和周日活躍度明顯高于工作日
- 關鍵詞分析:心理、生活、思考是最常出現的關鍵詞,表明用戶關注心理學和個人成長話題
- 引用分析:尼采、榮格、蘇格拉底是被最多引用的人物,表明用戶對西方哲學有較深興趣
- 圖片使用:約37%的微博包含圖片,其中以單圖發布為主
網頁展示效果如下:


五、技術難點與解決方案
- 反爬蟲機制:微博有嚴格的請求頻率限制,我通過設置合理的請求間隔(1秒)和會話保持來解決
- 中文分詞挑戰:中文分詞準確度對內容分析至關重要,使用jieba庫并自定義停用詞表提高分析質量
- 數據清洗:微博內容中包含大量HTML標簽和特殊字符,需要精心設計正則表達式進行清洗
- 可視化定制:調整matplotlib的中文字體和樣式設置,確保圖表美觀且信息豐富
六、總結與展望
本項目實現了一個完整的微博數據爬取和分析系統,可以幫助我們從用戶的微博內容中挖掘出有價值的信息。未來的改進方向包括:
- 支持多用戶批量爬取和對比分析
- 加入情感分析功能,評估微博的情感傾向
- 增加互動數據(點贊、評論、轉發)的分析
- 開發時間序列分析,檢測用戶興趣變化趨勢
通過這個項目,我們不僅可以了解特定用戶的發布規律和內容偏好,還能窺探社交媒體用戶的思想動態和關注重點,為社會學和心理學研究提供數據支持。
完整代碼:爬取數據代碼-weibo_crawler.py
import requests
import json
import time
import os
import re
import argparse
from datetime import datetimeclass WeiboCrawler:def __init__(self, cookie=None):"""初始化微博爬蟲:param cookie: 用戶登錄的cookie字符串"""self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Accept': 'application/json, text/plain, */*','Accept-Language': 'zh-CN,zh;q=0.9','Referer': 'https://weibo.com/','Origin': 'https://weibo.com',}if cookie:self.headers['Cookie'] = cookieself.session = requests.Session()self.session.headers.update(self.headers)def get_user_info(self, user_id):"""獲取用戶基本信息:param user_id: 用戶ID:return: 用戶信息字典"""url = f'https://weibo.com/ajax/profile/info?uid={user_id}'try:response = self.session.get(url)if response.status_code == 200:data = response.json()if data.get('ok') == 1 and 'data' in data:return data['data']['user']return Noneexcept Exception as e:print(f"獲取用戶信息失敗: {e}")return Nonedef get_user_weibos(self, user_id, page=1, count=20):"""獲取用戶的微博列表:param user_id: 用戶ID:param page: 頁碼:param count: 每頁微博數量:return: 微博列表"""url = f'https://weibo.com/ajax/statuses/mymblog?uid={user_id}&page={page}&feature=0'try:response = self.session.get(url)if response.status_code == 200:data = response.json()if data.get('ok') == 1 and 'data' in data:return data['data']['list'], data['data']['total']return [], 0except Exception as e:print(f"獲取微博列表失敗: {e}")return [], 0def clean_text(self, text):"""清理文本內容,去除HTML標簽等:param text: 原始文本:return: 清理后的文本"""if not text:return ""# 去除HTML標簽text = re.sub(r'<[^>]+>', '', text)# 替換特殊字符text = text.replace(' ', ' ')text = text.replace('<', '<')text = text.replace('>', '>')text = text.replace('&', '&')# 去除多余空格和換行text = re.sub(r'\s+', ' ', text).strip()return textdef format_weibo(self, weibo):"""格式化微博內容:param weibo: 微博數據:return: 格式化后的微博文本"""created_at = datetime.strptime(weibo['created_at'], '%a %b %d %H:%M:%S %z %Y').strftime('%Y-%m-%d %H:%M:%S')text = self.clean_text(weibo.get('text', ''))formatted = f"[{created_at}]\n"formatted += f"{text}\n"# 添加轉發內容if 'retweeted_status' in weibo and weibo['retweeted_status']:retweeted = weibo['retweeted_status']retweeted_user = retweeted.get('user', {}).get('screen_name', '未知用戶')retweeted_text = self.clean_text(retweeted.get('text', ''))formatted += f"\n轉發 @{retweeted_user}: {retweeted_text}\n"# 添加圖片鏈接if 'pic_ids' in weibo and weibo['pic_ids']:formatted += "\n圖片鏈接:\n"for pic_id in weibo['pic_ids']:pic_url = f"https://wx1.sinaimg.cn/large/{pic_id}.jpg"formatted += f"{pic_url}\n"formatted += "-" * 50 + "\n"return formatteddef crawl_user_weibos(self, user_id, max_pages=None):"""爬取用戶的所有微博:param user_id: 用戶ID:param max_pages: 最大爬取頁數,None表示爬取全部:return: 所有微博內容的列表"""user_info = self.get_user_info(user_id)if not user_info:print(f"未找到用戶 {user_id} 的信息")return []screen_name = user_info.get('screen_name', user_id)print(f"開始爬取用戶 {screen_name} 的微博")all_weibos = []page = 1total_pages = float('inf')while (max_pages is None or page <= max_pages) and page <= total_pages:print(f"正在爬取第 {page} 頁...")weibos, total = self.get_user_weibos(user_id, page)if not weibos:breakall_weibos.extend(weibos)# 計算總頁數if total > 0:total_pages = (total + 19) // 20 # 每頁20條,向上取整page += 1# 防止請求過快time.sleep(1)print(f"共爬取到 {len(all_weibos)} 條微博")return all_weibos, screen_namedef save_weibos_to_file(self, user_id, max_pages=None):"""爬取用戶微博并保存到文件:param user_id: 用戶ID:param max_pages: 最大爬取頁數:return: 保存的文件路徑"""weibos, screen_name = self.crawl_user_weibos(user_id, max_pages)if not weibos:return None# 創建文件名filename = f"{user_id}_weibos.txt"# 寫入文件with open(filename, 'w', encoding='utf-8') as f:f.write(f"用戶: {screen_name} (ID: {user_id})\n")f.write(f"爬取時間: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n")f.write(f"微博數量: {len(weibos)}\n")f.write("=" * 50 + "\n\n")for weibo in weibos:formatted = self.format_weibo(weibo)f.write(formatted)print(f"微博內容已保存到文件: {filename}")return filenamedef main():parser = argparse.ArgumentParser(description='微博爬蟲 - 爬取指定用戶的微博')parser.add_argument('user_id', help='微博用戶ID')parser.add_argument('--cookie', help='登錄cookie字符串', default=None)parser.add_argument('--max-pages', type=int, help='最大爬取頁數', default=None)parser.add_argument('--cookie-file', help='包含cookie的文件路徑', default=None)args = parser.parse_args()cookie = args.cookie# 如果提供了cookie文件,從文件讀取cookieif args.cookie_file and not cookie:try:with open(args.cookie_file, 'r', encoding='utf-8') as f:cookie = f.read().strip()except Exception as e:print(f"讀取cookie文件失敗: {e}")crawler = WeiboCrawler(cookie=cookie)crawler.save_weibos_to_file(args.user_id, args.max_pages)if __name__ == "__main__":main()
數據分析代碼:weibo_analsis.py
import re
import os
import matplotlib.pyplot as plt
from datetime import datetime
import jieba
import jieba.analyse
from collections import Counter
import numpy as np
from wordcloud import WordCloud
import matplotlib.font_manager as fm
from matplotlib.font_manager import FontProperties
import pandas as pd
from matplotlib.dates import DateFormatter
import seaborn as sns# 設置中文字體
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號class WeiboAnalyzer:def __init__(self, file_path):"""初始化微博分析器:param file_path: 微博數據文件路徑"""self.file_path = file_pathself.weibos = []self.user_info = {}self.load_data()def load_data(self):"""加載微博數據"""with open(self.file_path, 'r', encoding='utf-8') as f:lines = f.readlines()# 提取用戶信息if lines and "用戶:" in lines[0]:user_info_match = re.match(r'用戶: (.*) \(ID: (.*)\)', lines[0])if user_info_match:self.user_info['name'] = user_info_match.group(1)self.user_info['id'] = user_info_match.group(2)if len(lines) > 2 and "微博數量:" in lines[2]:count_match = re.match(r'微博數量: (\d+)', lines[2])if count_match:self.user_info['count'] = int(count_match.group(1))# 提取微博內容current_weibo = Nonefor line in lines:# 新微博的開始if re.match(r'\[\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\]', line):if current_weibo:self.weibos.append(current_weibo)date_match = re.match(r'\[(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})\]', line)if date_match:date_str = date_match.group(1)content = line[len(date_str) + 3:].strip()current_weibo = {'date': datetime.strptime(date_str, '%Y-%m-%d %H:%M:%S'),'content': content,'images': [],'is_retweet': False,'retweet_content': '','retweet_user': ''}# 圖片鏈接elif line.strip().startswith('https://wx1.sinaimg.cn/'):if current_weibo:current_weibo['images'].append(line.strip())# 轉發內容elif current_weibo and line.strip().startswith('轉發 @'):current_weibo['is_retweet'] = Trueretweet_match = re.match(r'轉發 @(.*): (.*)', line.strip())if retweet_match:current_weibo['retweet_user'] = retweet_match.group(1)current_weibo['retweet_content'] = retweet_match.group(2)# 繼續添加內容elif current_weibo and not line.strip() == '-' * 50 and not line.strip() == '=' * 50:current_weibo['content'] += ' ' + line.strip()# 添加最后一條微博if current_weibo:self.weibos.append(current_weibo)print(f"成功加載 {len(self.weibos)} 條微博")def time_distribution_analysis(self):"""分析微博發布時間分布"""if not self.weibos:print("沒有微博數據可分析")return# 提取日期和時間dates = [weibo['date'].date() for weibo in self.weibos]hours = [weibo['date'].hour for weibo in self.weibos]weekdays = [weibo['date'].weekday() for weibo in self.weibos]# 創建日期DataFramedf = pd.DataFrame({'date': dates,'hour': hours,'weekday': weekdays})# 按日期統計date_counts = df['date'].value_counts().sort_index()# 按小時統計hour_counts = df['hour'].value_counts().sort_index()# 按星期幾統計weekday_counts = df['weekday'].value_counts().sort_index()weekday_names = ['周一', '周二', '周三', '周四', '周五', '周六', '周日']# 創建圖表fig, axes = plt.subplots(3, 1, figsize=(12, 15))# 日期分布圖axes[0].plot(date_counts.index, date_counts.values, marker='o')axes[0].set_title('微博發布日期分布')axes[0].set_xlabel('日期')axes[0].set_ylabel('微博數量')axes[0].grid(True)# 小時分布圖axes[1].bar(hour_counts.index, hour_counts.values)axes[1].set_title('微博發布時間段分布')axes[1].set_xlabel('小時')axes[1].set_ylabel('微博數量')axes[1].set_xticks(range(0, 24))axes[1].grid(True)# 星期幾分布圖axes[2].bar([weekday_names[i] for i in weekday_counts.index], weekday_counts.values)axes[2].set_title('微博發布星期分布')axes[2].set_xlabel('星期')axes[2].set_ylabel('微博數量')axes[2].grid(True)plt.tight_layout()plt.savefig('time_distribution.png')plt.close()print("時間分布分析完成,結果已保存為 time_distribution.png")def content_analysis(self):"""分析微博內容"""if not self.weibos:print("沒有微博數據可分析")return# 合并所有微博內容all_content = ' '.join([weibo['content'] for weibo in self.weibos])# 使用jieba進行分詞jieba.analyse.set_stop_words('stopwords.txt') # 如果有停用詞表words = jieba.cut(all_content)# 過濾掉單個字符和數字filtered_words = [word for word in words if len(word) > 1 and not word.isdigit()]# 統計詞頻word_counts = Counter(filtered_words)# 提取關鍵詞keywords = jieba.analyse.extract_tags(all_content, topK=50, withWeight=True)# 創建詞云wordcloud = WordCloud(font_path='simhei.ttf', # 設置中文字體width=800,height=400,background_color='white').generate_from_frequencies(dict(word_counts))# 繪制詞云圖plt.figure(figsize=(10, 6))plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')plt.title('微博內容詞云')plt.savefig('wordcloud.png')plt.close()# 繪制關鍵詞條形圖plt.figure(figsize=(12, 8))keywords_dict = dict(keywords[:20])plt.barh(list(reversed(list(keywords_dict.keys()))), list(reversed(list(keywords_dict.values()))))plt.title('微博內容關鍵詞TOP20')plt.xlabel('權重')plt.tight_layout()plt.savefig('keywords.png')plt.close()print("內容分析完成,結果已保存為 wordcloud.png 和 keywords.png")def quote_analysis(self):"""分析微博中引用的人物"""if not self.weibos:print("沒有微博數據可分析")return# 定義可能被引用的人物列表famous_people = ['曾國藩', '尼采', '榮格', '蘇格拉底', '馬云', '武志紅', '阿德勒', '王安石', '蘇東坡', '海德格爾', '左宗棠', '宗薩']# 統計每個人物被引用的次數quotes = {person: 0 for person in famous_people}for weibo in self.weibos:content = weibo['content']for person in famous_people:if person in content:quotes[person] += 1# 過濾掉未被引用的人物quotes = {k: v for k, v in quotes.items() if v > 0}# 按引用次數排序sorted_quotes = dict(sorted(quotes.items(), key=lambda item: item[1], reverse=True))# 繪制引用人物條形圖plt.figure(figsize=(10, 6))plt.bar(sorted_quotes.keys(), sorted_quotes.values())plt.title('微博中引用人物統計')plt.xlabel('人物')plt.ylabel('引用次數')plt.xticks(rotation=45)plt.tight_layout()plt.savefig('quotes.png')plt.close()print("引用人物分析完成,結果已保存為 quotes.png")def image_analysis(self):"""分析微博中的圖片使用情況"""if not self.weibos:print("沒有微博數據可分析")return# 統計帶圖片的微博數量weibos_with_images = [weibo for weibo in self.weibos if weibo['images']]image_counts = [len(weibo['images']) for weibo in weibos_with_images]# 計算統計數據total_weibos = len(self.weibos)weibos_with_images_count = len(weibos_with_images)percentage = weibos_with_images_count / total_weibos * 100 if total_weibos > 0 else 0# 繪制餅圖plt.figure(figsize=(8, 8))plt.pie([weibos_with_images_count, total_weibos - weibos_with_images_count], labels=['帶圖片微博', '純文字微博'], autopct='%1.1f%%',startangle=90)plt.title('微博圖片使用情況')plt.axis('equal')plt.savefig('image_usage.png')plt.close()# 繪制圖片數量分布if image_counts:plt.figure(figsize=(10, 6))counter = Counter(image_counts)plt.bar(counter.keys(), counter.values())plt.title('微博圖片數量分布')plt.xlabel('圖片數量')plt.ylabel('微博數量')plt.xticks(range(1, max(image_counts) + 1))plt.grid(axis='y')plt.savefig('image_count.png')plt.close()print("圖片使用分析完成,結果已保存為 image_usage.png 和 image_count.png")def generate_report(self):"""生成分析報告"""# 執行所有分析self.time_distribution_analysis()self.content_analysis()self.quote_analysis()self.image_analysis()# 生成HTML報告html_content = f"""<!DOCTYPE html><html><head><meta charset="UTF-8"><title>微博數據分析報告</title><style>body {{ font-family: Arial, sans-serif; margin: 20px; }}h1, h2 {{ color: #1DA1F2; }}.section {{ margin-bottom: 30px; }}img {{ max-width: 100%; border: 1px solid #ddd; }}</style></head><body><h1>微博數據分析報告</h1><div class="section"><h2>用戶信息</h2><p>用戶名: {self.user_info.get('name', '未知')}</p><p>用戶ID: {self.user_info.get('id', '未知')}</p><p>微博總數: {self.user_info.get('count', len(self.weibos))}</p><p>分析微博數: {len(self.weibos)}</p></div><div class="section"><h2>時間分布分析</h2><img src="time_distribution.png" alt="時間分布分析"></div><div class="section"><h2>內容分析</h2><h3>詞云</h3><img src="wordcloud.png" alt="詞云"><h3>關鍵詞</h3><img src="keywords.png" alt="關鍵詞"></div><div class="section"><h2>引用人物分析</h2><img src="quotes.png" alt="引用人物分析"></div><div class="section"><h2>圖片使用分析</h2><img src="image_usage.png" alt="圖片使用情況"><img src="image_count.png" alt="圖片數量分布"></div></body></html>"""with open('weibo_analysis_report.html', 'w', encoding='utf-8') as f:f.write(html_content)print("分析報告已生成: weibo_analysis_report.html")def main():# 創建停用詞文件(如果需要)stopwords = ['的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一個', '上', '也', '很', '到', '說', '要', '去', '你', '會', '著', '沒有', '看', '好', '自己', '這', '那', '啊', '吧', '把', '給', '但是', '但', '還', '可以', '這個', '這樣', '這些', '因為', '所以', '如果', '就是', '么', '什么', '只是', '只有', '這種', '那個', '他們']with open('stopwords.txt', 'w', encoding='utf-8') as f:f.write('\n'.join(stopwords))# 分析微博數據analyzer = WeiboAnalyzer('1004524612_weibos.txt')analyzer.generate_report()if __name__ == "__main__":main()
所有數據以及代碼也放在下面的倉庫里了:源碼鏈接
參考資料
- Python爬蟲實戰指南
- 《數據可視化之美》
- 自然語言處理與文本挖掘技術
- jieba中文分詞官方文檔




)





)



)




