目錄
應用層
1. 應用層的作用
2. 自定義應用層協議?
3. 應用層的 "通用協議格式"
3.1 xml
3.2 json?
3.3 protobuffer (pd)
傳輸層?
1. UDP?
1.1 無連接
1.2 不可靠傳輸?
1.3 面向數據報?
1.4 全雙工?
1.5 緩沖區
1.6 UDP 數據報
2. TCP
2.1 有連接?
2.2 可靠傳輸
2.2.1 確認應答
2.2.2 超時重傳?
2.2.3 連接管理
2.2.4 滑動窗口
2.2.5 流量控制?
2.2.6 擁塞控制?
2.2.7 延遲應答?
2.2.8 捎帶應答?
2.2.9 面向字節流
2.2.10?TCP 異常情況的處理
2.3 TCP 十個核心特性簡要總結
2.4 TCP / UDP 對比
網絡層
1. IP 協議
1.1 基本概念
1.2 協議頭格式
1.3 IPv4 (IP 地址不夠用了怎么辦?)
1.4 IPv6 (從根本上解決了 IP 地址不夠用的問題)?
2. 地址管理
2.1 網段劃分
2.2 特殊的 IP 地址
3. 路由選擇
數據鏈路層
1. 認識以太網
1.1 以太網幀格式
1.2 認識 MAC 地址
1.3 認識 MTU
1.4 DNS (域名解析系統)
應用層
1. 應用層的作用
// 滿?我們?常需求的?絡程序,都是在應?層
2. 自定義應用層協議?
// 我們可以根據自己具體的需求, 來設定應用層協議
// 自定義的協議格式, 是可以任意的
3. 應用層的 "通用協議格式"
// 為了避免一些過于 "個性化" 的設計, 圈內大佬就搞出來了 "通用的協議格式"
// 參考一些 "通用的協議格式", 可以對我們的協議設計產生重要的指導作用
// "通用協議格式" 有很多種體現形式
3.1 xml
// 以成對的標簽, 來表示 "鍵值對" 信息, 同時標簽支持嵌套, 就可以構成一些更復雜的樹形結構數據
// <request> (開始標簽)
//? ? ? ? <useId>...</useId> (內容: 鍵值對 結構)
// </request> (結束標簽)
// 優點: 可以非常清晰的把結構化數據表示出來
// 缺點: 表示數據需要引入大量的標簽, 看起來繁瑣, 還會占用不少的網絡帶寬
3.2 json?
// 當前最流行的一種數據組織形式
// 本質上也是鍵值對, 但看起來比 xml 要干凈不少
// {
//? ? ? ?useId: ... ,
// }
// json 中, 使用 { } 表示 鍵值對, 使用 [ ] 表示數組, 數組里的每個元素, 可以是字符串, 還可以是其他的 { } 或 [ ]
// json 對于換行并不敏感, 所有內容放在同一行也是合法的
// 一般網絡傳輸的時候, 會對 json 進行壓縮 (去掉不必要的換行和空格), 同時將所以數據放到一行中去, 整體占用的帶寬就會降低 (影響到可讀性)
// 我們格式化 json 時也有很多 json 格式化工具, 可以直接使用
// 優勢: 相比于 xml , 表示的數據簡潔很多, 可讀性非常好, 方便我們觀察中間結果, 方便調試問題
// 劣勢: 終究需要花費一定的帶寬來傳輸 key 的名字的
3.3 protobuffer (pd)
// 谷歌提出的一套, 二進制的數據序列化方式
// 使用二進制的方式, 約定某幾個字節, 表示哪個屬性
// 優點: 節省帶寬, 最大化效率
// 最大程度的節省空間 (不必傳輸 key, 是根據位置和長度, 區分每個屬性的)
// 缺點: 二進制數據, 無法肉眼直接觀察, 不方便調試
// 使用起來比較復雜, 需要專門編寫一個 proto 文件, 描述數據的格式 (需要先學習它的語法規則), 再進一步通過人家提供的工具, 把 proto 文件轉換成一些代碼, 再嵌入到程序中使用
// 相當于是 犧牲了開發效率, 換來了運行效率
傳輸層?
1. UDP?
// 基本特點: 無連接 不可靠傳輸 面向數據報 全雙工
// UDP 傳輸過程類似于寄信
1.1 無連接
// 指導對象端的 IP 和端口號就可以直接進行傳輸, 不需要建立連接
1.2 不可靠傳輸?
// 沒有任何安全機制, 發送端發送數據報之后, 如果因為網絡故障該段無法發給對方, UDP 協議層也不會給應用層返回任何的錯誤信息
1.3 面向數據報?
// 應用層交給 UDP 多長的報文, UDP 照原樣發送, 既不會拆分,也不會合并
1.4 全雙工?
// 既可以發送數據, 也可以接收數據, 這兩個操作也可以同時進行 (既能讀也能寫)
1.5 緩沖區
// UDP 只有接收緩沖區, 沒有發送緩沖區
1.6 UDP 數據報
// UDP 數據報由: UDP 報頭 + 載荷
?// UDP 報頭由: 源端口 (2 字節) + 目的端口 (2 字節) + UDP 報文長度 (2 字節) + 校驗和 (2 字節)
2. TCP
// 基本特點: 有連接 可靠傳輸 面向字節流 全雙工
// TCP 的報頭是 "變長" 的, 最大長度是 60 字節
2.1 有連接?
// 在進行數據傳輸之前, 需要先進行連接
2.2 可靠傳輸
// 靠內核實現的可靠傳輸 (校驗和)
// 可靠傳輸實現的最重要 (核心) 的機制: 確認應答
// 我們可以通過編號的方式來確保數據傳輸的可靠性 (對每個字節進行編號)
// TCP 報頭 中的 ACK 若為 0, 表示 這是一個普通報文, 此時只有 32 位序號是有效的, ACK 若為 1, 表示這是一個應答報文, 這個報文的 序號 和 確認序號, 都是有效的 (確認報文的序號和正常報文的序號之間沒有關聯關系, 各自論各自的)?
2.2.1 確認應答
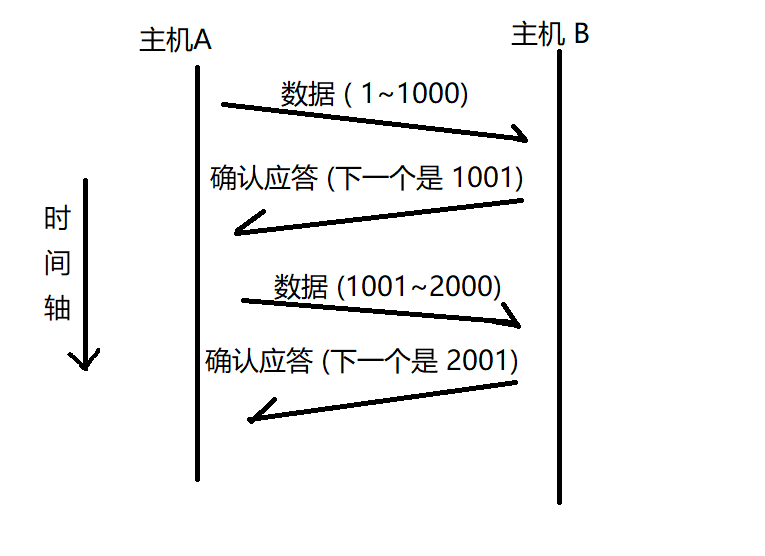
// 每一個 ACK 都帶有對應的確認序列號, 意思是告訴發送者, 我已經收到了哪些數據, 下一次你從哪里發?
2.2.2 超時重傳?
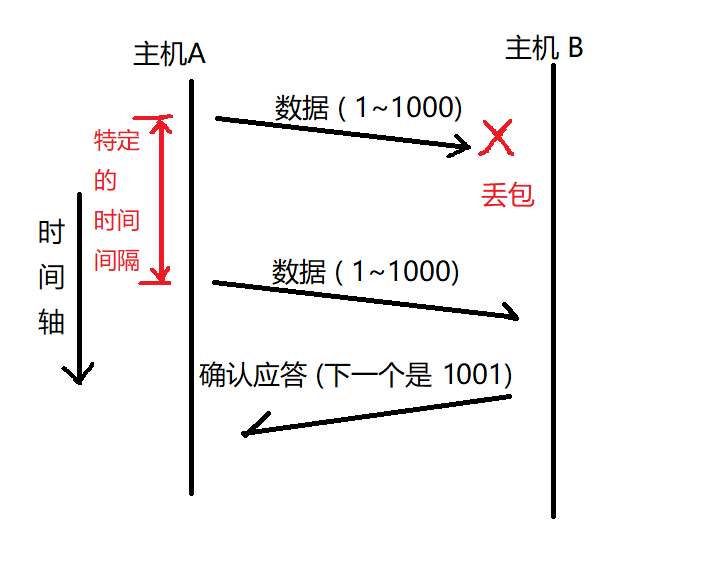
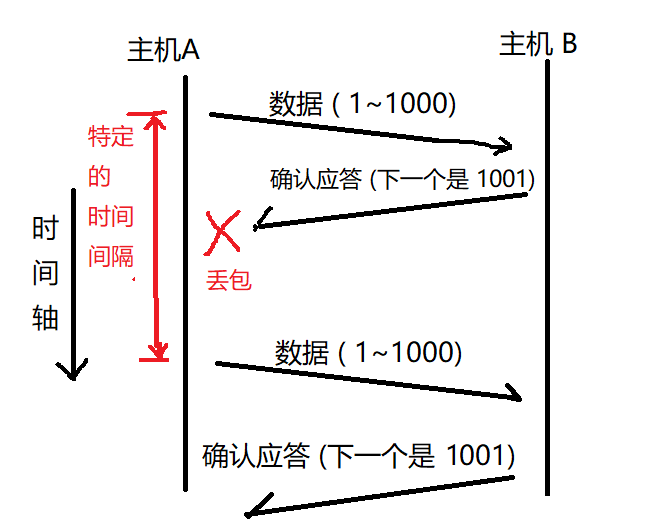
// 主機 A 發送數據給 B 之后, 可能因為網絡擁堵等一些原因導致數據無法到達 B
// 如果主機 A 在一個特定時間間隔內沒有收到 B 發來的確認應答, 就會進行重發; 但是, 主機 A 未收到 B 發來的確認應答, 可能是因為 ACK 丟失了, 因此主機 B 會收到很多重復數據, 那么 TCP 協議 需要能夠識別出哪些包是重復的包, 并且把重復的丟棄掉
// 這時我們可以利用前面提到的序列號, 達到去重的效果
// 接收方, 也會在接收緩沖區中, 對收到的數據進行排序, 也能處理后發先至的問題
2.2.3 連接管理
// 正常情況下, TCP 要建立連接: 需要三次握手, 斷開連接: 需要四次揮手
2.2.3.1 建立連接:?三次握手
// 三次握手 (其實是四次交互,但中間兩次進行了合并), 這樣可以減少封裝和分用的次數, 得到更高的傳輸效率
? ? ? ? ? ? ? ? ? ? ? ? ? ? ??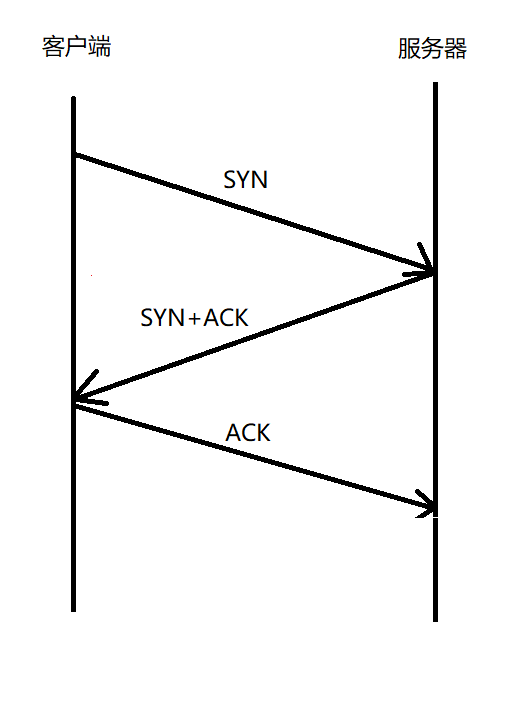
// 三次握手, 第一次 SYN 一定是客戶端發起的 (客戶端是主動的一方)?
// 三次握手的意義: 1) 是一種保證可靠性的機制 (投石問路); 2) 是協商必要的參數, 使客戶端和服務器使用相同的參數進行消息傳輸
// TCP 三次握手, 就是要驗證網絡通信是否通暢, 以及驗證每個主機的發送能力和接收能力是否正常
// 三次握手, 還能起到 "消息協商" 的效果,使通信雙?共同確認?些通信中的必備參數數值
2.2.3.2 斷開連接: 四次揮手
// 連接: 通信雙方, 各自在內存中保存了對端的相關信息
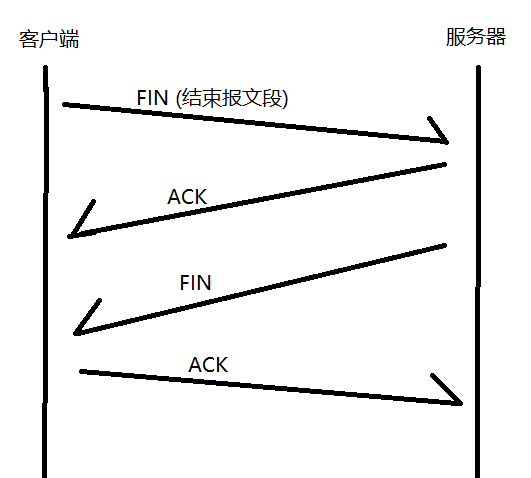
// 經過上述四個步驟之后, 連接就徹底不再使用了, 雙方就可以把各自保存對端消息的空間釋放了?
// 四次揮手中間這兩步不一定能合并, 有時候可以, 有時候不行
// FIN 的觸發, 是應用程序代碼來控制的, 調用 socket.close() 或者進程結束, 就會觸發 FIN, 相比之下, ACK 則是由內核控制的, 收到 FIN 就會立馬返回 ACK , 所以關鍵還是要看代碼是怎么編寫的
// 為了確保最后一次客戶端向服務器發送的 ACK 服務器確認收到了, 而沒有出現中途丟包導致超時重傳, 客戶端需要在發送完成 ACK 之后, 等待一定時間后再釋放連接, 但是也不用一直等下去, 只要超過應該等待的時間 [MSL] (網絡上任意兩點之間傳輸數據所需最大時間的兩倍), 服務器還沒有重傳 FIN, 大概率就是服務器成功接收到了 ACK, 這時候就可以自行釋放連接了, 若發生了網絡傳輸問題導致服務器沒有成接收到 ACK, 則客戶端重傳一次即可
// TCP 是如何實現可靠傳輸的: 1) 確認應答 (起決定性作用)? 2) 超時重傳 3) 連接管理 (三次握手, 四次揮手)
2.2.4 滑動窗口
// 用來提高傳輸效率 (更準確的說, 是讓 TCP 在可靠傳輸的前提下, 效率不要太拉胯)
// 使用滑動窗口, 不能使 TCP 變得比 UDP 快, 但是可以縮小差距
// 使用滑動窗口, 一次性發出一組數據, 發這一組數據的過程中, 不需要等待 ACK 就直接往前發, 此時就相當于使用 "一份等待時間" 等四個 ACK
// 把一次發多少數據, 不用等 ACK 這樣的大小, 稱為窗口
2.2.5 流量控制?
//?TCP?持根據接收端的處理能?,來決定發送端的發送速度.這個機制就叫做流量控制 (Flow Control)
// 接收端將自己可以接受的緩沖區大小放入 TCP 首部中的 "窗口大小" 字段, 通過 ACK 端通知發送端
// 窗口大小字段越大, 說明網絡的吞吐量越高
// 接收端一旦發現自己的緩沖區快滿了, 就會將窗口大小設置成一個更小的值通知給發送端
// 發送端接受到這個窗口之后, 就會減慢自己的發送速度
// 如果接收端緩沖區滿了, 就會將窗口置為 0, 這時發送方不再發送數據, 但是需要定期發送一個窗口探測數據段, 使接收端把窗口大小告訴發送端
2.2.6 擁塞控制?
// 總的傳輸效率, 是一個 木桶效應, 取決于最短板
// TCP 中, 擁塞控制是這樣展開的: 1) 慢啟動: 剛開始進行通信的時候, 會使用一個非常小的窗口, 先試試水; 2) 指數增長: 在傳輸通常的過程中, 擁塞窗口就會指數增長 (*2) (指數增長的速度是極快的, 必須加以限制,否則會出現非常大的值) 3) 線性增長: 指數增長到擁塞窗口達到一個閾值之后, 就會從指數增長轉換成 線性增長(+n) (線性增長也會使得發送速度越來越快, 當快到一定程度, 接近網絡傳輸的極限, 就可能會出現丟包了) 4) 擁塞窗口回歸一個小窗口: 當窗口大小增長過程中, 如果傳輸出現丟包, 就認為事當前網絡出現擁堵了, 此時就會把窗口大小調整成最初的小窗口, 繼續回到之前 指數增長 + 線性增長 的過程, 另外此處也會根據當前出現丟包的窗口大小, 調整閾值 (指數增長 -> 線性增長), 新的閾值是: 出現丟包的窗口大小/2?
// 擁塞窗口, 就是在這個過程中不斷發生變化, 不斷重新調整的過程
// 這樣的調整就可以非常好的適應多變的網絡環境
// 當然, 也是有不少的性能損失
// 實際發送方的窗口 = min (擁塞窗口, 流量控制窗口)
// 擁塞控制和流量控制, 共同限制了滑動窗口機制, 可以使滑動窗口能夠在可靠性的前提下, 提高傳輸速率
2.2.7 延遲應答?
// 是一種提高傳輸效率的機制, 還是圍繞滑動窗口琢磨的, 在條件允許的基礎山, 盡可能的提高窗口大小
// 在返回 ACK 的時候, 拖延一點時間, 利用這個拖延時間, 就可以給應用程序藤出來更多的消費數據的時間, 這樣接收緩沖區的剩余空間就更大了
2.2.8 捎帶應答?
// 在延遲應答基礎上, 引入的一個進一步提高效率的方式
// 延遲應答: 讓 ACK 傳輸的時機更慢
// 捎帶應答: 基于延遲應答, 讓數據進行合并
// 四次揮手有時也可以是三次的主要原因就是延遲應答和捎帶應答的功勞, 可以將兩個數據包合成一個, 效率會有明顯的提升
2.2.9 面向字節流
// 粘包問題: 這里 "粘" 的是 "應用層數據包"
// 在 TCP 協議頭中, 沒有如同 UDP 一樣的 "報文長度" 這樣的字段, 但是有一個序號字段
// 站在傳輸層的角度, TCP 是一個一個報文過來的, 按照序號排好序放在緩沖區中
// 站在應用層的角度, 看到的只是一串連續的字節數據
// 那么應用程序看到了這么一連串的字節數據, 就不知道從哪個部分開始到哪個部分是一個完整的應用層數據包
// 解決粘包問題的核心就是明確來那個包之間的邊界
// 粘包問題不僅僅是 TCP 才有的, 只要是面向字節流的機制 (文件) 也有同樣的問題, 解決方案也都是一樣的, 要么使用分隔符, 要么在數據前固定幾個字節來表示數據長度
2.2.10?TCP 異常情況的處理
// 網絡本身存在一些變數, 導致 TCP 連續不能繼續正常工作了
// 進程崩潰: 進程沒了, 相當于調用了 socket.close(), 崩潰的這一方就會發出 FIN, 進一步的觸發 四次揮手, 此時連接就正常釋放了, 這種情況下 TCP 的處理和進程正常退出沒啥區別
// 主機關機 (正常步驟關機): 關機前會先去強制終止所有的進程, 和之前的崩潰處理是一樣的
// 主機掉電 (拔電源, 不留反應空間): 此時就沒有任何可以操作的空間了, 接收端認為連接還在, 一旦接收端有寫入操作, 接收端發現連接已經不在了, 就會進行 reset . 即使沒有寫入操作, TCP 自己也內置了一個保活定時器 (心跳包), 會定期詢問對方是否還在, 如果對方不在, 也會把連接釋放
// 網線斷開: 相當于主機掉電的升級版本
2.3 TCP 十個核心特性簡要總結
// 確認應答 -> 可靠性
// 超時重傳 -> 可靠性
// 連接管理 -> 可靠性
// 滑動窗口 -> 效率
// 流量控制 -> 可靠性
// 擁塞控制 -> 可靠性
// 延時應答 -> 效率
// 捎帶應答 -> 效率
// 面向字節流 => 粘包問題 -> 編程注意事項
// 異常情況處理 => 心跳包 -> 異常情況
2.4 TCP / UDP 對比
// TCP 優勢在于可靠性: 適用于絕大部分場景, 應用于文件傳輸, 重要狀態更新等場景
// UDP 優勢在于效率: 適合于機房內部的主機之間通信, 用于對高速傳輸和實時性要求較高的通信領域
2.4.1 用 UDP 實現可靠傳輸
// 本質還是要到 TCP 上去, 使用?TCP 中的一些保證可靠性的方法實現可靠性傳輸
網絡層
1. IP 協議
1.1 基本概念
// 主機: 配有 IP 地址, 但是不進行路由控制的設備
// 路由器: 既配有 IP 地址, 又能進行路由控制
// 節點: 主機和路由器的統稱
1.2 協議頭格式
// 4 位版本號, 用來表示 IP 協議的版本, 現有的 IP 協議只有 IPv4 和 IPv6
// 4位首部長度, 設定和 TCP 一樣, IP 報頭可變長的, IP 報頭又是帶有選項的, 此處單位也是 4 字節
// 8 位服務類型 (其中真正只有 4 位才有效果), 類似于 模式/形態 切換
// 16 位總長度: IP 報頭 + 載荷 的長度
// 16 位標識, 3 位標志位, 13位片偏移, 描述了整個 IP 數據報拆包組包的過程
// 8 位生存時間 (TTL), 單位是 次, 初始情況下, TTL 會有個數值, 每次經過一個路由器轉發, TTL 就會 -1, 減到 0 了就會被丟棄; 正常來說 TTL 足以支持數據報到達網絡的任一位置, 如果確實出現 0 了, 基本可以認為目標 IP 不可達
// 16 位首部校驗和: 校驗數據是否正確的機制, 只需要校驗首部即可
// 32 位源地址, 32 位目的地址: IP 協議中最為重要的部分, 說明了 數據報 從哪來, 到哪去
1.3 IPv4 (IP 地址不夠用了怎么辦?)
// IPv4, 是 4 個字節, 32 位表示 IP 地址
// 動態分配 IP (DHCP) : 這杯需要上網了才分配 IP, 不需要就先不分配, 這種方法只能緩解, 但不能根治
// NAT 機制 (網絡地址轉換): 把 IP 地址分為內網 IP (不同的局域網內的設備, 內網 IP 可以重復, 同一個局域網內的設備, 內網 IP 不能重復)?和外網 IP (不能重復), 它也只是提高了 IP 地址的 "利用率", 并沒有從根本上解決 IP 不夠用的問題, 缺點也很明顯: 1) 效率不高; 2) 非常繁瑣; 3) 不方便直接訪問局域網內的設備; 但是它有一個很大的優點: NAT 是一個 "純軟件實現" 的方案
1.4 IPv6 (從根本上解決了 IP 地址不夠用的問題)?
// IPv6, 是 16 個字節, 128 位, 表示 IP 地址
2. 地址管理
2.1 網段劃分
// IP 地址分為兩個部分, 網絡號和主機號 (192.168.22.25)
// 網絡號: 標識網段, 保證相互連接的兩個網段具有不同的標識
// 主機號: 標識主機, 同一網段內, 主機之間具有相同的網絡號, 但是必須有不同的主機號
// 子網掩碼是現代用來劃分網絡號的方案 (255.255.255.0)
// 過去是用 A B C D E 將 IP地址劃分為五類
2.2 特殊的 IP 地址
// 將 IP 地址中的主機地址全部設為 0, 就成為了網絡號, 代表這個局域網
// 將 IP 地址中的主機地址全部設為 1 , 就成為了廣播地址, 用于給同一個鏈路中相互連接的所有主機發送數據包; 此處廣播, 在傳輸層只能使用 UDP, 而不能使用 TCP (TCP 無法針對廣播地址進行三次握手, 建立連接的操作)
// 127.* 的 IP 地址用于本機環回 (loop back) 測試, 通常是 127.0.0.1
// 本機環回主要用于本機到本機的網絡通信 (系統內部為了性能, 不會走網絡的方式傳輸), 對于開發網絡通信的程序 (即網絡編程) 而言, 常見的開發方式都是本機到本機的網絡通信
3. 路由選擇
// 路由選擇的過程, 是一跳一跳 (Hop by Hop) "問路" 的過程, 這里給出的路徑, 不一定是最優解, 只能說是 "較優解"
數據鏈路層
// 代表協議: 以太網
1. 認識以太網
1.1 以太網幀格式
// 以太網幀格式: 目的地址 (6個字節) + 源地址 (6個字節) + 類型?(2個字節) + 數據 + CRC?(4個字節)
// 源地址和目的地址是指: 物理地址 (MAC 地址), 長度是 48 位, 是在網卡出廠時固化的
// 幀協議類型字段有 3 種值, 分別對應 IP, ARP, RARP
// 一個以太網數據幀, body 部分, 最大長度 1500, 受限于硬件
// 幀末尾是 CRC 校驗碼
1.2 認識 MAC 地址
// MAC 地址用來失敗數據鏈路層中相連的節點
// 長度為 48 位, 即 6個字節, 一般用 16 進制數字加上冒號的形式來表示?(例如:08:00:27:03:fb:19)
// 在網卡出廠時就確定了, 不能修改. MAC 地址通常是唯一的?
1.3 認識 MTU
// MTU 相當于發快遞時對包裹尺寸的限制, 這個限制是不同的數據鏈路對應的物理層, 產生的限制
// 以太網幀中的數據長度規定最小 46 字節, 最大 1500 字節, ARP 數據包的長度不夠 46 字節, 要在后面補填充位
// 最大值 1500 稱為以太網的最大傳輸單元 (MTU), 不同的網絡類型有不同的 MTU;
// 如果一個數據包從以太網路由到撥號鏈路上, 數據包長度大于撥號鏈路的 MTU 了, 則需要對數據包進行分片 (fragmentation)
// 不同的數據鏈路層標準的 MTU 是不同的
1.4 DNS (域名解析系統)
// 上網要訪問服務器, 知道服務器的 IP 地址, IP 地址是一串數字, 雖然這個數字使用點分十進制已經清晰不少了, 但是任然不方便人們記憶和傳播, 我們可以通過單詞 (域名) 來代替 IP 地址
// 域名往往是分級的, 例如: www.sougou.com 中 com (一級域名); sougou (二級域名); www (三級域名)
// DNS 服務器如何能夠承載高并發量 (開源, 節流): 1) 在每個電腦上, 在進行域名解析的時候, 都會有緩存, 訪問很多次, 只有第一次真的訪問 DNS, 后面幾次不一定訪問; 2) 全世界會搭建出很多的 "DNS 鏡像服務器", 從最初的 DNS 服務器這里同步數據?

![[OS_7] 訪問操作系統對象 | offset | FHS | Handle](http://pic.xiahunao.cn/[OS_7] 訪問操作系統對象 | offset | FHS | Handle)




學習筆記(二)--k8s 集群安裝)

森林中的兔子)



)



詳解)


