在web應用中,當數據量非常大時,即使MySQL的存儲能夠滿足,但性能一般也會比較差。此時,可以考慮使用ClickHouse存儲歷史數據,在Mysql存儲最近熱點數據的方式,來優化和提升查詢性能。ClickHouse的設計初衷就是為了解決大規模數據分析場景下的性能問題,特別是在處理OLAP(聯機分析處理)任務時表現優異。
但是,通常不推薦直接使用Clickhouse作為數據庫使用,雖然Clickhouse查詢大數量時表現優秀,但其本身不支持事務,不具備Innodb鎖等機制。Clickhouse其主要作用是優化海量數據的查詢問題,所以結合Mysql做冷熱數據分離的方式更推薦。海量的冷數據存儲在Clickhouse中,最近的熱點數據存儲在Mysql中。
1、ClickHouse vs MySQL在大數據量場景下的對比
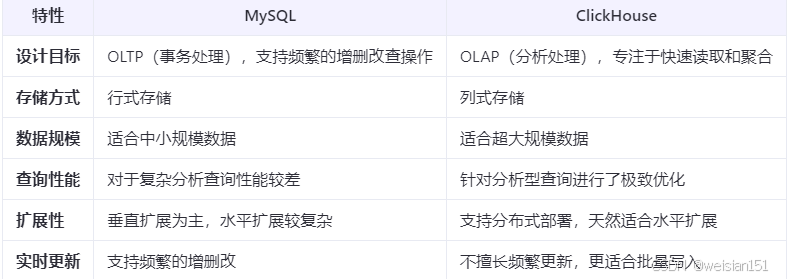
ClickHouse更適合處理海量數據的分析查詢,而MySQL更擅長事務處理和頻繁的數據修改。
2、具體思路
(1)、數據遷移
- 如果你的業務已經運行在MySQL上,但發現查詢性能瓶頸,可以將部分數據遷移到ClickHouse中。
- 通常的做法是將需要頻繁分析的歷史數據或日志數據導入到ClickHouse,而MySQL繼續負責事務處理。
- 遷移工具:
- 可以通過ETL工具(如Apache NiFi、DataX等)將數據從MySQL導出并導入到ClickHouse。
- 或者直接使用ClickHouse的INSERT INTO … SELECT …語句從MySQL中抽取數據。
(2)、數據分層架構
- MySQL作為主數據庫:用于存儲在線交易數據,支持高頻的增刪改操作。
- ClickHouse作為分析引擎:定期從MySQL同步數據,或者通過日志(如Binlog)實時訂閱MySQL的變化數據,加載到ClickHouse中進行分析。
- 這種架構既能保證事務處理的靈活性,又能充分發揮ClickHouse在分析查詢上的優勢。
(3)、查詢分離
- 將復雜的分析查詢從MySQL轉移到ClickHouse。例如:
- 如果你需要統計過去一年的用戶行為數據,并按月進行匯總分析,這種查詢可能會讓MySQL不堪重負。
- 而在ClickHouse中,這類查詢可以在秒級甚至毫秒級完成。
(4)、數據壓縮與列式存儲
- ClickHouse的列式存儲和高效壓縮算法能夠顯著減少存儲空間占用,同時提高查詢性能。
- 對于大規模數據集,存儲成本和I/O開銷往往是性能瓶頸的重要因素,ClickHouse在這方面具有明顯優勢。
3、具體案例
- 場景:電商網站的日志分析
- 問題:電商平臺每天產生大量的用戶訪問日志和訂單數據,存儲在MySQL中。隨著時間推移,數據量達到TB級別,查詢變得越來越慢。
- 解決方案:
(1)、將歷史日志數據從MySQL導出到ClickHouse。
(2)、在ClickHouse中創建表,并使用MergeTree引擎進行存儲。
(3)、定期將MySQL中的增量數據同步到ClickHouse。
(4)、使用ClickHouse執行復雜的分析查詢,例如:
sql示例:
SELECT toDate(event_time) AS event_date, COUNT(*) AS event_countFROM user_logsWHERE event_date BETWEEN '2025-01-01' AND '2025-01-31'GROUP BY event_date;
這類查詢在ClickHouse中通常只需幾秒鐘即可完成。
4、性能對比
場景:5000萬條日志數據查詢
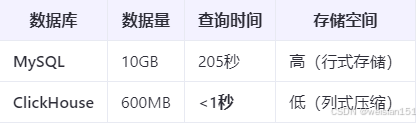
優化效果:
- 查詢速度提升:200倍以上(從分鐘級到秒級)。
- 存儲成本降低:壓縮率高達 17倍(10GB → 600MB)。
可以看到,相同的數據放到Mysql和ClickHouse中,占用的內存節省了90%多,查詢的速度也是非常高效的。
5、注意事項
盡管ClickHouse在處理大數據量方面表現出色,但也需要注意以下幾點:
(1)、不適合頻繁更新:
- ClickHouse不擅長頻繁的單行更新或刪除操作。如果你的業務需要頻繁修改數據,可能需要結合其他工具(如Kafka)來實現增量更新。
(2)、學習曲線:
- ClickHouse的功能和優化方式與傳統的關系型數據庫有很大不同,團隊可能需要時間熟悉其特性和最佳實踐。
(3)、數據一致性:
- ClickHouse本身不提供強一致性保證,因此在需要高一致性的場景下,仍需依賴MySQL或其他事務型數據庫。
(4)、硬件需求:
- ClickHouse對硬件資源(尤其是內存和CPU)要求較高,尤其是在分布式部署時。
6、數據遷移步驟
(1)、數據遷移
步驟 1:定義歷史數據范圍
- 時間字段:確保 MySQL 表中存在時間字段(如 create_time 或 update_time),用于劃分歷史數據和近期數據。
- 遷移條件:例如,將三個月之前 create_time < ‘2025-01-12’ 的數據遷移到 ClickHouse。
步驟 2:遷移歷史數據
-
工具選擇:
- 全量遷移:使用 mysqldump或mydumper導出歷史數據,通過clickhouse-client導入。
- 增量遷移(可選):使用 Canal、Debezium 或 TapData 實時捕獲 MySQL 的 Binlog,過濾歷史數據并同步到 ClickHouse。
-
遷移示例:
– 在 MySQL 中導出歷史數據(示例)
mysqldump -u user -p --where="create_time < '2025-01-12'" dbname table_name > history_data.sql
– 轉換為 CSV 格式(如通過腳本或工具)
– 導入到 ClickHouse
clickhouse-client --query="INSERT INTO clickhouse_table FORMAT CSV" < history_data.csv
步驟 3:清理MySQL中的歷史數據
- 分區表優化:在 MySQL 中按時間分區,刪除舊分區以釋放空間(參考知識庫[9])。
– 創建分區表(示例)
ALTER TABLE mysql_table PARTITION BY RANGE (TO_DAYS(create_time)) (PARTITION p2024 VALUES LESS THAN (TO_DAYS('2025-01-01')),PARTITION p2025 VALUES LESS THAN (TO_DAYS('2026-01-01')));
– 刪除舊分區
ALTER TABLE mysql_table DROP PARTITION p2024;
(2)、查詢路由實現
方案 1:應用層路由
- 邏輯判斷:在應用代碼中根據時間條件決定查詢 MySQL 或 ClickHouse。
python示例:
def query_data(start_time, end_time):if end_time < '2025-01-12': // 三個月之前查詢 ClickHousereturn clickhouse_query(...)elif start_time > '2025-01-12': // 三個月之內查詢 MySQLreturn mysql_query(...)else:合并查詢(如需跨時間范圍)return merge(mysql_query(...), clickhouse_query(...))
方案 2:中間件路由
- 使用代理工具:如 ProxySQL 或自定義 SQL 路由服務,根據查詢條件動態轉發請求。
- 示例規則:
- 若查詢條件中 create_time < ‘2025-01-12’,則路由到 ClickHouse。
- 否則路由到 MySQL。
7、總結建議
當MySQL在大數據量場景下性能不足時,ClickHouse是一個非常優秀的解決方案,特別是在需要高性能分析查詢的場景中。通過合理的數據分層架構和查詢分離策略,可以充分利用ClickHouse的優勢,同時保留MySQL在事務處理上的靈活性。
不過,ClickHouse并非萬能藥。它最適合的是只讀或批量寫入的大數據分析場景。在引入ClickHouse之前,建議充分評估業務需求,并制定清晰的數據遷移和查詢優化策略。
逆風翻盤,Dare To Be!!!
)

工具)




 工具)







)



)