1. 前言
我們知道,大模型現在很火爆,尤其是 deepseek 風靡全球后,大模型毫無疑問成為為中國新質生產力的代表。百度創始人李彥宏也說:“2025 年可能會成為 AI 智能體爆發的元年”。
隨著科技的飛速發展,大模型的影響力日益凸顯。它不僅在數據處理和分析方面展現出了強大的能力,還為各個領域帶來了前所未有的創新機遇。在眾多應用場景中,智能駕駛無疑是備受矚目的一個領域。
智能駕駛作為未來交通的重要發展方向,具有巨大的潛力和市場需求。大模型的出現,為智能駕駛的發展注入了強大的動力。它可以通過對大量駕駛數據的學習和分析,實現更加精準的環境感知、路徑規劃和決策控制。例如,大模型可以實時識別道路上的障礙物、交通標志和其他車輛,預測潛在的危險情況,并及時做出相應的駕駛決策,從而提高駕駛的安全性和舒適性。
在這樣的一種大趨勢下,筆者將針對智能駕駛場景,講一講大模型的應用前景以及存在的瓶頸!!!
2.自動駕駛中的大模型
自動駕駛領域的大模型主要涵蓋 感知(Perception)、決策(Decision-making)和控制(Control) 等多個方面,那么可以應用于自動駕駛中的大模型可以分為;
2.1 感知層(Perception)
感知層主要依賴 計算機視覺**(CV)和多模態大模型(MMML)**,處理攝像頭、雷達、激光雷達等傳感器數據。
2.1.1 計算機視覺模型
1.Tesla Vision(特斯拉)
Tesla Vision 是 特斯拉(Tesla) 開發的一套基于純視覺(Camera-only)的自動駕駛感知系統,完全放棄了激光雷達(LiDAR)和毫米波雷達(Radar),僅依靠攝像頭和 AI 算法進行環境感知。該系統用于 Tesla Autopilot 和 FSD**(Full Self-Driving)**,目前在 FSD V12 版本中已經實現端到端 Transformer 訓練。
Tesla Vision 具有以下核心特點:
- 純視覺(Camera-only)感知:自 2021 年起,特斯拉宣布移除毫米波雷達,完全依靠攝像頭。8 個攝像頭覆蓋 360° 視角,包括前、后、側方攝像頭。
- 基于 Transformer 的端到端 AI**:Tesla Vision 早期使用卷積神經網絡(CNN)**進行目標檢測、分割和軌跡預測。 FSD V12 采用 端到端 Transformer 模型,用 BEV(Bird’s Eye View)+ 視頻 Transformer 進行感知。利用神經網絡自動標注駕駛數據,大規模訓練 AI 駕駛模型。BEVFormer / Occupancy Network 將 2D 視覺數據轉化為 3D 環境模型,提高自動駕駛感知能力。
- **端到端學習(End-to-End Learning):**早期 FSD 采用模塊化架構(Perception → Planning → Control),FSD V12 采用端到端神經網絡,直接學習駕駛行為,無需手工編寫規則。
Tesla Vision 的工作原理:
- 感知(Perception):通過 8 個攝像頭輸入視頻流。采用 Transformer 處理時序數據,形成 BEV(俯視圖)Occupancy Network 預測周圍動態環境(車輛、行人、紅綠燈等)。
- 規劃(Planning):FSD V12 直接通過 Transformer 計算駕駛路徑,無需手工編碼。AI 學習人類駕駛行為,進行轉向、加速、剎車等決策。
- 控制(Control):車輛根據 AI 計算的軌跡執行駕駛動作。特斯拉自研 AI 芯片 Dojo 提供超大規模計算能力。
2.多模態大模型
在自動駕駛領域,多模態大模型(Multimodal Large Models, MML)能夠融合多個傳感器數據(如攝像頭、激光雷達、毫米波雷達、IMU 等)來提升感知、決策和控制能力。以下是當前主流的多模態大模型:
BEVFusion
BEVFusion 融合激光雷達 + 攝像頭數據,提升 3D 目標檢測能力。嚴格來說,BEVFusion 本身并不算一個典型的大模型(LLM 級別的超大參數模型),但它可以被視為自動駕駛中的大模型趨勢之一,特別是在感知層的多模態融合方向。目前主流的 BEVFusion 主要用于 3D 目標檢測,并非大語言模型(LLM)那樣的百億、千億級參數模型。例如,Waymo、Tesla 的 BEV 模型參數量遠低于 GPT-4 級別的 AI 大模型。而且任務范圍局限于感知,主要用于將 2D 視覺(RGB 圖像)和 3D 激光雷達(LiDAR 點云)融合,輸出鳥瞰圖(BEV)用于目標檢測、占用網絡等。不直接涉及自動駕駛的決策和控制,不像 Tesla FSD V12 那樣實現端到端駕駛。
雖然 BEVFusion 不是超大參數模型,但它具備大模型的一些核心特征:
- 多模態(Multimodal)融合:融合 RGB 視覺 + LiDAR + Radar,類似 GPT-4V(圖像+文本)這種多模態 AI 方向。
- Transformer 結構:新一代 BEVFusion 開始采用 BEVFormer(Transformer 結構),可擴展成更大規模的計算模型。
- 大規模數據驅動:需要超大規模的數據集(如 Waymo Open Dataset、Tesla 數據庫)進行訓練,符合大模型訓練模式。
Segment Anything Model (SAM)(Meta)+ DINO(自監督學習)
SAM 是由 Meta AI 發布的一種通用圖像分割模型,可以對任何圖像中的任何物體進行分割,而無需特定的數據集進行微調。DINO(基于 Vision Transformer 的自監督學習方法) 由 Facebook AI(現 Meta AI)提出,能夠在無監督情況下學習圖像表示,廣泛用于物體檢測、跟蹤和語義分割。SAM 和 DINO 結合后,可以極大提升自動駕駛中的 感知精度、泛化能力和數據效率。其結合方式可以總結為:
- DINO 作為自監督學習特征提取器,提供高質量的視覺表示。
- SAM 作為通用分割工具,利用 DINO 提供的特征進行高精度分割。
- 結合 BEVFusion、Occupancy Network,增強 3D 語義感知。
其在自動駕駛中的應用可以是:
- 無監督 3D 語義分割:DINO 預訓練提取高質量視覺特征,SAM 進行目標分割,提高語義理解能力。
- BEV 視角感知(鳥瞰圖增強):DINO 適應跨尺度檢測,SAM 用于 BEV 視角的動態目標分割。
- 動態物體跟蹤:結合 SAM 的強大分割能力,可更精準跟蹤行人、騎行者等。
2.2 規劃與決策(Decision-making & Planning)
這一層面涉及強化學習、端到端 Transformer 以及大語言模型(LLM)用于自動駕駛策略決策
2.2.1 強化學習與決策模型
自動駕駛的決策層需要處理復雜的動態環境,包括車輛行駛策略、避障、變道、紅綠燈響應等。強化學習(RL, Reinforcement Learning)和決策大模型(LLM, Large Decision Models)已成為關鍵技術,能夠學習人類駕駛員的策略并在不同交通場景下進行智能決策。其基本框架為馬爾可夫決策過程(MDP),主要的強化學習方法有:
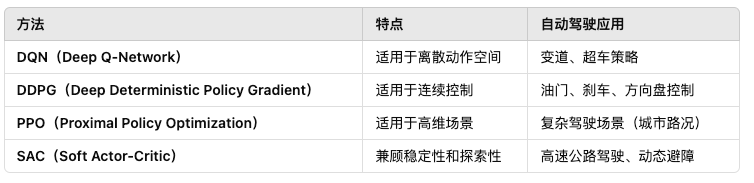
其應用實例有:
- Waymo & Tesla:采用 DDPG/PPO 進行端到端駕駛策略優化。
- Uber ATG:使用 DQN 進行交通信號識別和決策。
2.2.2 端到端 Transformer
端到端(End-to-End, E2E)Transformer 在自動駕駛中融合感知、預測、規劃,實現端到端學習,擺脫傳統模塊化架構的局限。Tesla FSD V12 采用 Vision Transformer(ViT)+ GPT 進行端到端自動駕駛,而 GriT(Grid Transformer) 則專注于端到端路徑規劃,提供更高效的軌跡優化。
1.Vision Transformer (ViT) + GPT
Tesla FSD V12 采用 Vision Transformer (ViT) + GPT 結構,實現端到端駕駛控制,直接從攝像頭輸入生成方向盤轉角、油門、剎車等控制信號。詳細見前文。
2.GriT( Grid Transformer)
GriT(Grid Transformer) 是一種基于 Transformer 的路徑規劃模型,能夠在復雜環境下進行高效軌跡規劃。其核心思想為**:**
- 采用 柵格(Grid-based)方法 進行端到端軌跡預測。
- 適用于 動態環境,如城市道路、高速公路、交叉路口等。
- 結合 Transformer 結構進行全局路徑優化,避免局部最優問題。
GriT 主要結構為:
輸入(多模態信息)
-
攝像頭(前視 & 側視)、LiDAR 點云(可選)、HD 地圖信息。
-
目標檢測(行人、車輛、紅綠燈)。
-
車輛當前狀態(速度、加速度、方向等)。
Transformer 編碼(Grid-based Representation)
-
采用 柵格化(Grid-based Representation),將環境信息編碼為網格結構。
-
使用 Self-Attention 計算,學習全局路徑規劃策略。
軌跡預測 & 規劃
-
通過 Transformer 計算最優駕駛軌跡。
-
適應不同交通狀況(紅綠燈、變道、避障等)。
GriT 在自動駕駛中的應用
復雜路口決策
-
GriT 能夠預測多個可能路徑,并選擇最優軌跡,避免碰撞。
動態避障
-
在高速公路、城市駕駛場景下,實時避讓前方障礙物或慢速車輛。
路徑全局優化
-
傳統路徑規劃方法(如 A*、Dijkstra)易陷入局部最優,而 GriT 通過 Transformer 提高全局規劃能力。
發展趨勢
ViT + GPT 端到端感知 & 規劃進一步優化
-
結合更多傳感器數據(如雷達)提升安全性。
-
提高自監督學習能力,減少數據標注需求。
GriT 結合 BEV,提升軌跡規劃能力
未來 GriT 可能與 BEV 結合,提高 3D 規劃能力。
提高對動態環境的適應性,優化駕駛策略。
多智能體 Transformer 強化學習
- 未來可訓練多車輛協同駕駛,提高車隊自動駕駛能力。
結合 RL(強化學習)優化自動駕駛策略。
2.3 控制層(Control)
控制層是自動駕駛的核心模塊之一,負責將感知和規劃結果轉換為具體的車輛控制指令(方向盤、油門、剎車)。近年來,大模型(如 Transformer、RL-based Policy Network)正在革新自動駕駛控制層,使其更智能、更平滑、更適應復雜環境。
- DeepMind MuZero:無模型強化學習框架,可用于動態駕駛控制優化。
- Nvidia Drive Orin / Thor:專用 AI 芯片結合 Transformer 網絡,用于高精度自動駕駛控制。
2.4 端到端自動駕駛大模型
部分大模型實現了從感知到控制的端到端學習:
- OpenPilot(Comma.ai):開源自動駕駛系統,基于 Transformer 訓練的行為克隆模型。
- DriveGPT(類似 AutoGPT 的自動駕駛 LLM):將 LLM 應用于駕駛策略。
2.4 端到端自動駕駛大模型*
部分大模型實現了從感知到控制的端到端學習:
- OpenPilot(Comma.ai):開源自動駕駛系統,基于 Transformer 訓練的行為克隆模型。
- DriveGPT(類似 AutoGPT 的自動駕駛 LLM):將 LLM 應用于駕駛策略。
目前,特斯拉 FSD V12 是最先進的端到端 Transformer 自動駕駛大模型。











回調函數(4)Python)



)



