數據結構——哈希詳解
目錄
一、哈希的定義
二、六種哈希函數的構造方法
2.1 除留取余法
2.2 平方取中法
2.3 隨機數法
2.4 折疊法
2.5 數字分析法
2.6 直接定值法
三、四種解決哈希沖突的方法
3.1 開放地址法
3.1.1 線性探測法
3.1.2 二次探測法
3.2 鏈地址法
3.3 再散列函數法
3.4 公共區溢出法
四、用代碼解決鏈地址法
一、哈希的定義
順序表/鏈表有一個共同特征,數據值本身和其存儲位置之間是沒有關系的,所以我們要查找/搜索一個值,只能一個一個的去比較,時間復雜度是O(n),
我們想把時間復雜度降下來,提供一種技術讓我們數據值本身和存儲關系之前有映射關系,這時我們查找值是否存在則直接根據這種映射關系計算得出其存儲位置,這時只去要去計算得出的存儲位置查看即可——這種技術就是散列技術也就是哈希,映射關系就是哈希函數f???
f(關鍵字key)=存儲位置
哈希即是一種存儲方法也是一種查找方法
哈希沖突定義:倆個或多個關鍵碼Key1!=Key2但是通過哈希函數的計算得出的結果卻相等,這種現象就是發生了哈希沖突

二、六種哈希函數的構造方法
2.1 除留取余法
原理:
-
哈希函數 h(k)=k mod m,其中 k 是鍵值,m 是哈希表的大小。
-
通過取鍵值 k 除以 m 的余數來確定哈希值。
優點:
-
實現簡單,計算速度快。
缺點:
-
如果鍵值分布不均勻,容易導致沖突。例如,當鍵值都是偶數時,若 m 是偶數,那么所有哈希值也都是偶數,會浪費一半的哈希表空間。
-
對 m 的選擇敏感,通常 m 選擇為質數可以減少沖突。
應用場景:
-
適用于鍵值范圍較大且分布較為均勻的場景,如簡單的哈希表設計。
2.2 平方取中法
原理:
-
將鍵值 k 平方,然后從平方后的結果中取出中間幾位數字作為哈希值。
-
例如,鍵值 k=1234,平方后為 1522756,取中間幾位(如 2275)作為哈希值。
優點:
-
能夠較好地打亂鍵值的分布,減少沖突。
缺點:
-
如果鍵值較小,平方后的數字位數不夠,可能需要補零,導致哈希值不夠隨機。
-
計算平方操作相對耗時。
應用場景:
-
適用于對哈希值隨機性要求較高的場景,但計算資源允許的情況下。
2.3 隨機數法
原理:
-
使用偽隨機數生成器(PRNG)根據鍵值生成隨機數作為哈希值。
-
通常需要一個種子值,種子值可以根據鍵值計算得到。
優點:
-
哈希值的隨機性高,沖突概率低。
缺點:
-
隨機數生成器的實現復雜,且需要保證每次計算結果一致(即相同的鍵值產生相同的哈希值)。
-
如果隨機數生成器質量不高,可能會導致哈希值分布不均勻。
應用場景:
-
適用于對哈希值隨機性要求極高的場景,如密碼學中的哈希函數。
2.4 折疊法
原理:
-
將鍵值分成若干部分,然后將這些部分進行折疊(相加、相減或按位運算)以生成哈希值。
-
例如,鍵值 k=12345678,可以分成 1234 和 5678,然后相加得到 6912,再取模或者直接取后三位得到最終哈希值。
優點:
-
簡單易實現,能夠較好地處理較長的鍵值。
缺點:
-
如果鍵值的某些部分分布不均勻,可能會影響哈希值的分布。
-
對折疊操作的選擇敏感,不同的折疊方式可能導致不同的效果。
應用場景:
-
適用于鍵值較長且分布不均勻的場景,如字符串哈希。
2.5 數字分析法
原理:
-
分析鍵值的每一位數字(或字符),根據某種規則選擇部分數字組合成哈希值。
-
例如,鍵值 k=12345678,可以選擇第 2、4、6 位數字(2、4、6),然后組合成 246 作為哈希值。
優點:
-
能夠根據鍵值的分布特點進行優化,減少沖突。
缺點:
-
實現復雜,需要對鍵值的分布有先驗知識。
-
如果鍵值的分布變化較大,可能需要重新調整規則。
應用場景:
-
適用于對鍵值分布有明確了解的場景,如特定的數據庫索引設計。
2.6 直接定值法
原理:
-
取關鍵字的線性函數值作為散列地址 f(key)=axkey+b?
-
通常用于鍵值范圍較小且連續的情況。
優點:
-
實現極其簡單,沒有沖突。
缺點:
-
如果鍵值范圍較大,會浪費大量空間。
-
不適用于鍵值范圍較大的場景。
應用場景:
-
適用于鍵值范圍較小且連續的場景,如小型數據庫索引。
三、四種解決哈希沖突的方法
哈希沖突定義:倆個或多個關鍵碼Key1!=Key2但是通過哈希函數的計算得出的結果卻相等,這種現象就是發生了哈希沖突
3.1 開放地址法
3.1.1 線性探測法
原理:當發生哈希沖突時,從沖突位置開始,按照線性順序依次探測下一個位置,向右探測,直到找到空閑位置為止。即若哈希地址為?h(key)?的位置已被占用,則依次探測?h(key)+1、h(key)+2、h(key)+3…… 直到找到空閑位置。
優點:實現簡單,容易理解和編程實現。
缺點:容易出現 “聚集” 現象,即連續的多個空閑位置被占用,形成一個聚集區,導致后續元素查找和插入時需要探測更多的位置,效率降低。
公式:f(key)=(f(key)+d)mod m????? d=1,2,3,4,5…
3.1.2 二次探測法
使用線性探測法會發生堆積,我們想要探測的時候即向左也向右探測并且每次探測幅度盡可能變化,呈指數變化 eg:1,-1,4,-4,9,-9
增加平方運算是為了不讓關鍵字都聚集在某一個區域
優點:能有效減少聚集現象,提高哈希表的性能。
缺點:不能探測到哈希表中的所有位置,可能會出現無法找到空閑位置的情況,特別是當哈希表大小不是合適的數值時。
3.2 鏈地址法
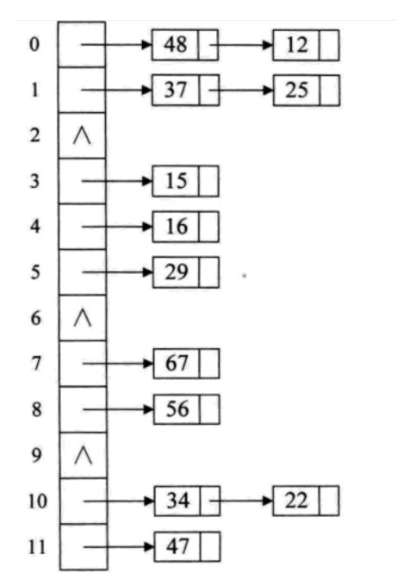
其核心思想是將所有哈希地址相同的元素都鏈接到同一個鏈表中。在哈希表中,每個位置對應一個鏈表,當發生哈希沖突(即不同的關鍵字通過哈希函數計算得到相同的哈希地址)時,將這些沖突的元素依次插入到對應的鏈表中
優點:
-
處理沖突簡單,不需要探測。
-
刪除元素容易,只需從鏈表中移除即可。
缺點:
-
需要額外的空間來存儲鏈表。
-
當一個槽位的鏈表很長時,搜索效率會降低。
3.3 再散列函數法
再散列函數法使用兩個不同的哈希函數。第一個哈希函數?h1(key)?用于計算元素的初始哈希地址。當該地址發生沖突時,使用第二個哈希函數?h2(key)?來確定下一個探測位置的步長,從而在哈希表中尋找下一個可用的位置。
通過這種方式,不斷嘗試新的位置,直到找到一個空槽來插入元素,或者確定該元素不存在于哈希表中。
3.4 公共區溢出法

不沖突放到基本表中,沖突就放到溢出表中,基本表中都沒有數據為空說明溢出表中肯定沒有,基本表由哈希函數構成,溢出表由順序存儲構成先來先到,
適用于哈希沖突相對較少的場景
四、用代碼解決鏈地址法
.cpp
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include "hash_List_address.h"
#include <stdlib.h>//0.哈希函數
int Hash(ELEM_TYPE val)
{return val % INITSIZE;
}//1.初始化
void Init_List_Address(List_address* pla)
{for (int i = 0; i < INITSIZE; i++){Init_List(&pla->arr[i]);}
}//2.插入值(頭插)
bool Insert(List_address* pla, ELEM_TYPE val)
{//assertint index = Hash(val);struct Node* pnewnode = (Node*)malloc(sizeof(Node));if (pnewnode == NULL){return false;}pnewnode->data = val;pnewnode->next = pla->arr[index].next;pla->arr[index].next = pnewnode;return true;
}//3.刪除值
bool Del(List_address* pla, ELEM_TYPE val)
{struct Node* q = Search(pla, val);if (q == NULL)return false;//此時,代碼執行到這里,證明val值節點存在在index下標里面的單鏈表上int index = Hash(val);struct Node* p = &pla->arr[index];for (; p->next != q; p = p->next);//此時,代碼執行到這里,證明p和q都就位p->next = q->next;free(q);q = NULL;return true;
}//4.查找值
struct Node* Search(List_address* pla, ELEM_TYPE val)
{//assertint index = Hash(val);struct Node* q = pla->arr[index].next;for (; q != NULL; q = q->next){if (q->data == val){break;}}return q;}//5.打印
void Show(List_address* pla)
{for (int i = 0; i < INITSIZE; i++){printf("第%d行:", i);struct Node* p = pla->arr[i].next;for (; p != NULL; p=p->next){printf("%d->", p->data);}printf("\n");}
}int main()
{List_address head;Init_List_Address(&head);Insert(&head, 12);Insert(&head, 67);Insert(&head, 56);Insert(&head, 16);Insert(&head, 25);Insert(&head, 37);Insert(&head, 22);Insert(&head, 29);Insert(&head, 15);Insert(&head, 47);Insert(&head, 48);Insert(&head, 34);Show(&head);Del(&head, 25);Del(&head, 12345);Show(&head);return 0;
}.h?
#pragma oncetypedef int ELEM_TYPE;
//鏈地址法有效節點結構體設計:
typedef struct List_Node
{ELEM_TYPE data;struct List_Node* next;
}List_Node;#include "list.h"//鏈地址法整個的輔助節點結構體設計:
#define INITSIZE 12
typedef struct List_address
{struct Node arr[INITSIZE];
}List_address;//0.哈希函數
int Hash(ELEM_TYPE val);//1.初始化
void Init_List_Address(List_address* pla);//2.插入值
bool Insert(List_address* pla, ELEM_TYPE val);//3.刪除值
bool Del(List_address* pla, ELEM_TYPE val);//4.查找值
struct Node* Search(List_address* pla, ELEM_TYPE val);//5.打印
void Show(List_address* pla);









之旅——方法的使用⑤)
)
![[Python基礎速成]2-模塊與包與OOP](http://pic.xiahunao.cn/[Python基礎速成]2-模塊與包與OOP)

)


六大技術支柱在醫療領域的應用)
)
