一、Demo概述
代碼已附在文末
1.1 代碼功能
- ? 實現VGG16網絡結構
- ? 在CIFAR10數據集上訓練分類模型
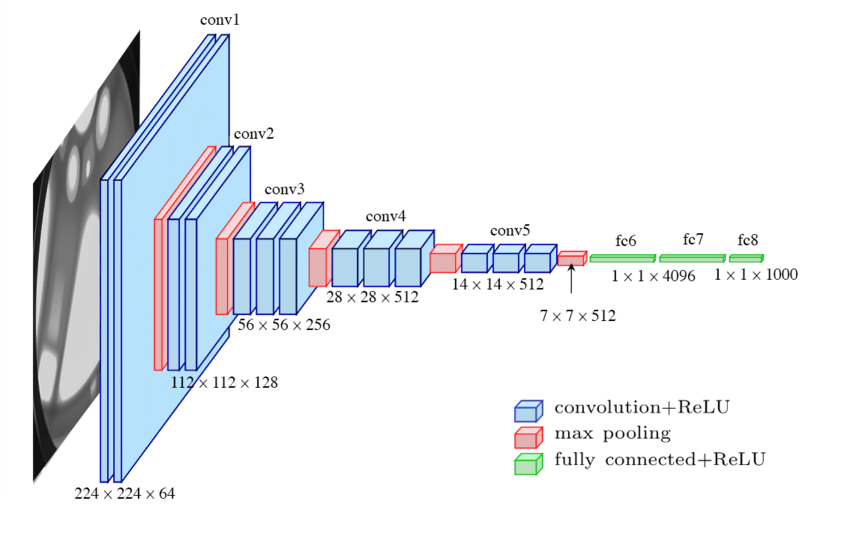
1.2 環境配置
詳見【深度學習】Windows系統Anaconda + CUDA + cuDNN + Pytorch環境配置
二、各網絡層概念
2.1 卷積層(nn.Conv2d)
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1)
| 參數 | 含義 | 作用說明 |
|---|---|---|
in_channels | 輸入通道數(如RGB圖為3) | 接收輸入的維度 |
out_channels | 輸出通道數(卷積核數量) | 提取不同特征類型的數量 |
kernel_size | 卷積核尺寸(如3x3) | 決定感知的局部區域大小 |
padding | 邊緣填充像素數 | 保持輸出尺寸與輸入一致 |
作用:通過滑動窗口提取局部特征(如邊緣、顏色分布)
示例: 輸入3通道224x224圖片 → 通過64個3x3卷積核 → 輸出64通道224x224特征圖
1)卷積后的輸出尺寸:
卷積后的輸出尺寸由以下公式決定:
輸出尺寸 = 輸入尺寸 ? 卷積核尺寸 + 2 × 填充 步長 + 1 \text{輸出尺寸} = \frac{\text{輸入尺寸} - \text{卷積核尺寸} + 2 \times \text{填充}}{\text{步長}} + 1 輸出尺寸=步長輸入尺寸?卷積核尺寸+2×填充?+1
在代碼中:
- 輸入尺寸:224x224
- 卷積核尺寸:3x3 → (k=3)
- 填充 (padding):1 → (p=1)
- 步長 (stride):1 → (s=1)(默認值)
代入公式:
輸出尺寸 = 224 ? 3 + 2 × 1 1 + 1 = 224 \text{輸出尺寸} = \frac{224 - 3 + 2 \times 1}{1} + 1 = 224 輸出尺寸=1224?3+2×1?+1=224
因此,寬度和高度保持不變(仍為224x224)。
2)64個卷積核的輸出不同
- 參數初始化差異
- 初始權重隨機:每個卷積核的權重矩陣在訓練前通過隨機初始化生成(如正態分布)
- 示例:
- 卷積核1初始權重可能偏向檢測水平邊緣
- 卷積核2初始權重可能隨機偏向檢測紅色區域
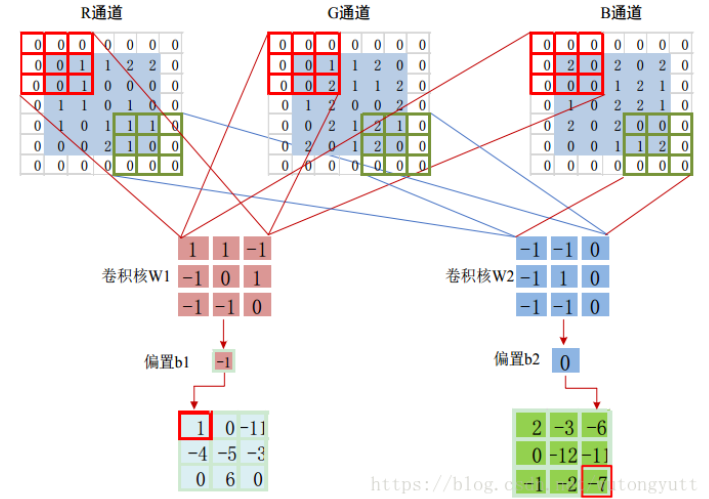
- 反向傳播差異:每個卷積核根據其當前權重計算出的梯度不同
數學表達:
Δ W k = ? η ? L ? W k \Delta W_k = -\eta \frac{\partial \mathcal{L}}{\partial W_k} ΔWk?=?η?Wk??L?- W k W_k Wk?:第k個卷積核的權重
- η \eta η:學習率
- 不同位置的梯度導致權重更新方向不同
3)卷積核參數的「通道敏感度」
卷積操作的完整計算式為:
輸出 = ∑ c = 1 C in ( 輸入通道 c ? 卷積核權重 c ) + 偏置 \text{輸出} = \sum_{c=1}^{C_{\text{in}}} (\text{輸入通道}_c \ast \text{卷積核權重}_c) + \text{偏置} 輸出=c=1∑Cin??(輸入通道c??卷積核權重c?)+偏置
其中:
- C in C_{\text{in}} Cin?:輸入通道數(例如RGB圖為3)
- ? \ast ? 表示卷積運算
- 偏置的意義在于允許激活非零特征
- 不同的卷積核權重決定了通道敏感度,比如RGB三個通道,R通道權重放大即偏好紅色特征,紅色通道的輸入會被加強
4)卷積核參數的「空間敏感度」?
- 卷積核矩陣決定空間關注模式,每個卷積核的權重矩陣就像一張「特征檢測模板」,決定了在圖像中的哪些空間位置組合能激活該核的輸出。
[ [ ? 1 , 0 , 1 ] , [ ? 2 , 0 , 2 ] , [ ? 1 , 0 , 1 ] ] [[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]] [[?1,0,1],[?2,0,2],[?1,0,1]] - 這是一個經典的Sobel水平邊緣檢測核,當輸入圖像在水平方向有明暗變化時(如水平邊緣),左右兩側的權重差異會放大響應值
5)參數協同工作
例. 綜合檢測紅色水平邊緣
假設一個卷積核的參數如下:
- 空間權重(與之前Sobel核相同):
[[-1, 0, 1],[-2, 0, 2],[-1, 0, 1]] - 通道權重:
- 紅色:0.9, 綠色:0.1, 藍色:-0.2
- 在紅色通道中檢測水平邊緣 → 高響應
- 在綠色/藍色通道的同類邊緣 → 響應被抑制
- 最終輸出:紅色物體的水平邊緣被突出顯示
2.2 激活函數(nn.ReLU)
沒有激活函數的神經網絡等效于單層線性模型
nn.ReLU(inplace=True)
激活函數有很多種,這里是最簡單的一種ReLU

1)ReLU 的數學原理
ReLU(Rectified Linear Unit)的數學定義非常簡單:
f ( x ) = max ? ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
-
正向傳播:
- 當輸入 x > 0 x > 0 x>0 時,輸出 f ( x ) = x f(x) = x f(x)=x(直接傳遞信號)。
- 當輸入 x < = 0 x <= 0 x<=0 時,輸出 f ( x ) = 0 f(x) = 0 f(x)=0(完全抑制信號)。
-
反向傳播:
- 在 x > 0 x > 0 x>0 時,梯度為 ? f ? x = 1 \frac{\partial f}{\partial x} = 1 ?x?f?=1(梯度無衰減)。
- 在 x < = 0 x <= 0 x<=0 時,梯度為 ? f ? x = 0 \frac{\partial f}{\partial x} = 0 ?x?f?=0(梯度歸零)。
2)引入非線性
如果神經網絡只使用線性激活函數(如 ( f(x) = x )),無論堆疊多少層,最終等效于單層線性變換(( W_{\text{total}} = W_1 W_2 \cdots W_n )),無法建模復雜函數。
- ReLU 的非線性:通過分段處理(保留正信號、抑制負信號),打破線性組合,使網絡能夠學習非線性決策邊界。
- 實際意義:ReLU 允許網絡在不同區域使用不同的線性函數(正區間為線性,負區間為常數),從而組合出復雜的非線性函數。
3)緩解梯度消失
梯度消失問題通常發生在深層網絡中,當反向傳播時梯度逐層衰減,導致淺層參數無法更新。
ReLU 的緩解機制如下:
-
導數值恒為 1(正區間): 相比于 Sigmoid(導數最大 0.25)、Tanh(導數最大 1),ReLU 在正區間的梯度恒為 1,避免梯度隨網絡深度指數級衰減。
-
稀疏激活性: ReLU 會抑制負值信號(輸出 0),導致部分神經元“死亡”,但活躍的神經元梯度保持完整,使有效路徑的梯度穩定傳遞。
-
對比其他激活函數: Sigmoid:導數 ( f’(x) = f(x)(1-f(x)) ),當 ( |x| ) 較大時,導數趨近 0。 ReLU:僅需判斷 ( x > 0 ),計算高效且梯度穩定。
4)輸入與輸出
我們輸入張量尺寸為 [Channels=64, Height=224, Width=224]:
- 維度不變性:
- ReLU 是逐元素操作(element-wise),不會改變輸入輸出的形狀,輸出尺寸仍為 64×224×224。
- 數值變化:
- 正區間:保留原始值,維持特征強度。
- 負區間:置零,可能造成特征稀疏性(部分像素/通道信息丟失)。
- 實際影響:
- 如果輸入中存在大量負值(如未規范化的數據),ReLU 會過濾掉這些信息,可能影響模型性能。
- 通常需配合批歸一化(BatchNorm) 使用,將輸入調整到以 0 為中心,減少負值抑制。
5)局限性與拓展
- 神經元死亡(Dead ReLU):
- 當輸入恒為負時,梯度為 0,導致神經元永久失效。
- 解決方案:
- 使用 Leaky ReLU:允許負區間有微小梯度(如 ( f(x) = \max(0.01x, x) ))。
- Parametric ReLU (PReLU):將負區間的斜率作為可學習參數。
2.3 池化層(nn.MaxPool2d)
nn.MaxPool2d(kernel_size=2, stride=2)
1)數學原理
最大池化(Max Pooling)是一種非線性下采樣操作,其核心是對輸入張量的局部區域取最大值。以參數 kernel_size=2, stride=2 為例:
- 窗口劃分:在輸入張量的每個通道上,以
2×2的窗口(無重疊)滑動。 - 步長操作:每次滑動
2個像素(橫向和縱向均移動 2 步),確保窗口不重疊。 - 計算規則:每個窗口內的最大值作為輸出。
示例:
輸入矩陣(2×2 窗口,步長 2):
輸入 (4×4):
[[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]]輸出 (2×2):
[[6, 8],[14, 16]]
- 第一個窗口(左上角)的值為
[1,2;5,6]→ 最大值 6 - 第二個窗口(右上角)的值為
[3,4;7,8]→ 最大值 8 - 依此類推。
2)核心作用
-
降維(下采樣):
- 降低特征圖的空間分辨率(高度和寬度),減少后續層的計算量和內存消耗。
- 例如,輸入尺寸
64×224×224→ 輸出64×112×112(通道數不變)。
-
特征不變性增強:
- 平移不變性:即使目標在輸入中有輕微平移,最大池化仍能捕捉到其主要特征。
- 旋轉/縮放魯棒性:通過保留局部最顯著特征,降低對細節變化的敏感度。
-
防止過擬合:
- 減少參數量的同時,抑制噪聲對模型的影響。
-
擴大感受野:
- 通過逐步下采樣,后續層的神經元能覆蓋輸入圖像中更大的區域。
3)對輸入輸出的影響
以 PyTorch 的 nn.MaxPool2d(kernel_size=2, stride=2) 為例:
-
輸入尺寸:
[Batch, Channels, Height, Width](如64×3×224×224)。 -
輸出尺寸:
輸出高度 = ? 輸入高度 ? kernel_size stride ? + 1 \text{輸出高度} = \left\lfloor \frac{\text{輸入高度} - \text{kernel\_size}}{\text{stride}} \right\rfloor + 1 輸出高度=?stride輸入高度?kernel_size??+1
同理計算寬度。- 若輸入為
224×224→ 輸出為112×112((224-2)/2 +1 = 112)。
- 若輸入為
-
通道數不變:池化操作獨立作用于每個通道,不改變通道數。
-
數值變化:
- 每個窗口僅保留最大值,其余數值被丟棄。
- 輸出張量的值域與輸入一致,但稀疏性可能增加(大量低值被過濾)。
4)與卷積層的區別
| 特性 | 卷積層 (nn.Conv2d) | 最大池化層 (nn.MaxPool2d) |
|---|---|---|
| 可學習參數 | 是(權重和偏置) | 否(固定操作) |
| 作用 | 提取局部特征并組合 | 下采樣,保留顯著特征 |
| 輸出通道數 | 可自定義(通過 out_channels) | 與輸入通道數相同 |
| 非線性 | 需配合激活函數(如 ReLU) | 自帶非線性(取最大值) |
2.4 全連接層(nn.Linear)
nn.Linear(512*7*7, 4096)
1)數學原理
全連接層(Fully Connected Layer)的數學本質是線性變換 + 偏置,其公式為:
y = W x + b y = Wx + b y=Wx+b
-
輸入向量 x ∈ R n x \in \mathbb{R}^{n} x∈Rn:將輸入張量展平為一維向量(例如
512×7×7→ 512 × 7 × 7 = 25088 512 \times 7 \times 7 = 25088 512×7×7=25088維)。 -
權重矩陣 W ∈ R m × n W \in \mathbb{R}^{m \times n} W∈Rm×n:維度為
[輸出維度, 輸入維度],即 4096 × 25088 4096 \times 25088 4096×25088。 -
偏置向量 b ∈ R m b \in \mathbb{R}^{m} b∈Rm:維度為
4096。 -
輸出向量 y ∈ R m y \in \mathbb{R}^{m} y∈Rm:維度為
4096。 -
假設輸入向量 x ∈ R 25088 x \in \mathbb{R}^{25088} x∈R25088,權重矩陣 W ∈ R 4096 × 25088 W \in \mathbb{R}^{4096 \times 25088} W∈R4096×25088,偏置 b ∈ R 4096 b \in \mathbb{R}^{4096} b∈R4096,則輸出向量的第 i i i 個元素為:
y i = ∑ j = 1 25088 W i , j ? x j + b i y_i = \sum_{j=1}^{25088} W_{i,j} \cdot x_j + b_i yi?=j=1∑25088?Wi,j??xj?+bi?
每個輸出元素是輸入向量的加權和,權重矩陣的每一行定義了一個“特征選擇器”。
2)核心作用
-
全局特征整合:
- 將卷積層提取的局部特征(如邊緣、紋理)通過矩陣乘法整合為全局語義信息(如物體類別)。
- 例如:將
512×7×7的特征圖(對應圖像不同區域的特征)映射到更高維度的抽象語義空間(如“貓”“狗”的分類特征)。
-
非線性建模能力:
- 通常配合激活函數(如 ReLU)使用,增強網絡的非線性表達能力。
-
維度壓縮/擴展:
- 通過調整輸出維度(如
4096),實現特征壓縮(降維)或擴展(升維)。
- 通過調整輸出維度(如
3)對輸入輸出的影響
以 nn.Linear(512*7*7, 4096) 為例:
-
輸入尺寸:
- 假設輸入為
[Batch=64, Channels=512, Height=7, Width=7],需先展平為[64, 512×7×7=25088]。
- 假設輸入為
-
輸出尺寸:
- 輸出為
[Batch=64, 4096],即每個樣本被映射到4096維的特征空間。
- 輸出為
-
參數數量:
- 權重矩陣參數: 25088 × 4096 = 102 , 760 , 448 25088 \times 4096 = 102,760,448 25088×4096=102,760,448
- 偏置參數: 4096 4096 4096
- 總計:102,764,544 個可訓練參數。
4)適用場景與局限性
-
適用場景:
- 傳統卷積網絡(如 AlexNet、VGG)的分類頭部。
- 需要全局特征交互的任務(如語義分割中的上下文建模)。
-
局限性:
- 參數量過大:例如本例中超過 1 億參數,易導致過擬合和計算成本高。
- 空間信息丟失:展平操作破壞特征圖的空間結構,不適合需要保留位置信息的任務(如目標檢測)。
-
替代方案:
- 全局平均池化(GAP):將
512×7×7壓縮為512×1×1,再輸入全連接層,大幅減少參數(例如 ResNet)。 - 1×1 卷積:保留空間維度,實現局部特征交互。
- 全局平均池化(GAP):將
三、VGG16網絡結構實現
3.1 特征提取層
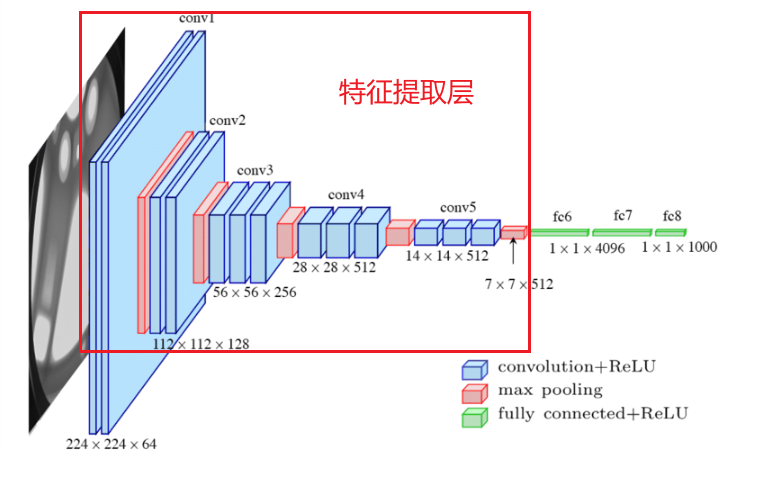
self.features = nn.Sequential(# Block 1 (2 conv layers)nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2), # 輸出尺寸112x112# 后續Block結構類似,此處省略...
)
3.1.1 特征提取的作用
- 特征提取的本質:通過卷積核的局部計算、ReLU的非線性激活、池化的降維,將原始像素逐步抽象為高層語義特征。
- 數學公式的遞進:
像素 → 卷積+ReLU 邊緣 → 卷積+ReLU 紋理 → 池化 物體部件 → ... 語義特征 \text{像素} \xrightarrow{\text{卷積+ReLU}} \text{邊緣} \xrightarrow{\text{卷積+ReLU}} \text{紋理} \xrightarrow{\text{池化}} \text{物體部件} \xrightarrow{\text{...}} \text{語義特征} 像素卷積+ReLU?邊緣卷積+ReLU?紋理池化?物體部件...?語義特征 - 對輸入的影響:空間分辨率降低,通道數增加,特征語義逐步抽象化。
3.1.2 數學原理
-
卷積層(核心操作):
每個卷積核(如3×3)在輸入特征圖上滑動,計算局部區域的加權和:
輸出 ( x , y ) = ∑ i = ? 1 1 ∑ j = ? 1 1 輸入 ( x + i , y + j ) ? 權重 ( i , j ) + 偏置 \text{輸出}(x,y) = \sum_{i=-1}^{1}\sum_{j=-1}^{1} \text{輸入}(x+i, y+j) \cdot \text{權重}(i,j) + \text{偏置} 輸出(x,y)=i=?1∑1?j=?1∑1?輸入(x+i,y+j)?權重(i,j)+偏置- 權重共享:同一卷積核在不同位置使用相同權重,捕捉空間不變性特征。
- 多通道:每個卷積核輸出一個通道,多個卷積核組合可提取多維度特征。
-
ReLU 激活函數:
ReLU ( x ) = max ? ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)- 作用:引入非線性,增強模型對復雜特征的表達能力。
-
最大池化層:
輸出 ( x , y ) = max ? i , j ∈ 窗口 輸入 ( x + i , y + j ) \text{輸出}(x,y) = \max_{i,j \in \text{窗口}} \text{輸入}(x+i, y+j) 輸出(x,y)=i,j∈窗口max?輸入(x+i,y+j)- 作用:降維并保留最顯著特征,提升模型對位置變化的魯棒性。
以輸入圖像 [Batch, 3, 224, 224] 為例,逐層分析變化:
| 層類型 | 輸入尺寸 | 輸出尺寸 | 數學影響 |
|---|---|---|---|
| Conv2d(3→64) | [B,3,224,224] | [B,64,224,224] | 提取 64 種基礎特征(邊緣/顏色) |
| ReLU | [B,64,224,224] | [B,64,224,224] | 非線性激活,抑制負響應 |
| Conv2d(64→64) | [B,64,224,224] | [B,64,224,224] | 細化特征,增強局部模式組合 |
| MaxPool2d | [B,64,224,224] | [B,64,112,112] | 下采樣,保留最顯著特征 |
| 重復塊(128→256→512) | … | … | 逐層增加通道數,提取更復雜特征 |
| 最終輸出 | [B,512,7,7] | [B,512,7,7] | 高層語義特征,輸入分類器或檢測頭 |
- 通道數變化:
3 → 64 → 128 → 256 → 512,表示特征復雜度遞增。 - 空間分辨率下降:
224x224 → 7x7,通過池化逐步聚焦全局語義。
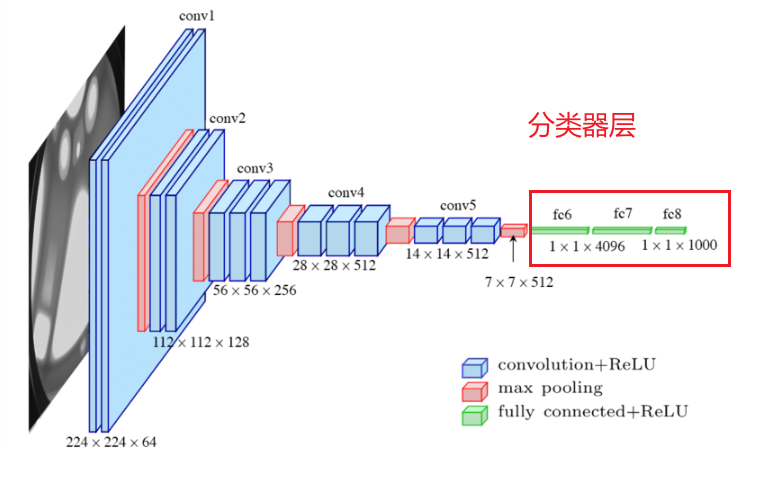
3.2 分類器層
self.classifier = nn.Sequential(nn.Dropout(p=0.5), # 防止過擬合nn.Linear(512*7*7, 4096), # 特征圖維度計算nn.ReLU(inplace=True),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes)
)
3.2.1 分類器層作用
分類器層(Classifier)是網絡的最后階段,負責將卷積層提取的高級語義特征映射到類別概率空間。其核心功能包括:
- 特征整合:將全局特征轉化為與任務相關的判別性表示。
- 分類決策:通過全連接層(Linear)和激活函數(ReLU)生成類別得分。
- 正則化:通過Dropout減少過擬合,提升模型泛化能力。
3.2.2 數學原理
假設輸入特征為 x ∈ R 512 × 7 × 7 x \in \mathbb{R}^{512 \times 7 \times 7} x∈R512×7×7(展平后為25088維),分類器層的計算流程如下:
-
Dropout層(訓練階段):
x drop = Dropout ( x , p = 0.5 ) x_{\text{drop}} = \text{Dropout}(x, p=0.5) xdrop?=Dropout(x,p=0.5)- 隨機將50%的神經元輸出置零,防止過擬合。
-
全連接層1(降維):
y 1 = W 1 x drop + b 1 ( W 1 ∈ R 4096 × 25088 , b 1 ∈ R 4096 ) y_1 = W_1 x_{\text{drop}} + b_1 \quad (W_1 \in \mathbb{R}^{4096 \times 25088}, \, b_1 \in \mathbb{R}^{4096}) y1?=W1?xdrop?+b1?(W1?∈R4096×25088,b1?∈R4096)- 將25088維特征壓縮到4096維。
-
ReLU激活:
a 1 = max ? ( 0 , y 1 ) a_1 = \max(0, y_1) a1?=max(0,y1?) -
重復Dropout和全連接層:
y 2 = W 2 ( Dropout ( a 1 ) ) + b 2 ( W 2 ∈ R 4096 × 4096 ) y_2 = W_2 (\text{Dropout}(a_1)) + b_2 \quad (W_2 \in \mathbb{R}^{4096 \times 4096}) y2?=W2?(Dropout(a1?))+b2?(W2?∈R4096×4096)
a 2 = max ? ( 0 , y 2 ) a_2 = \max(0, y_2) a2?=max(0,y2?) -
最終分類層:
y logits = W 3 a 2 + b 3 ( W 3 ∈ R 10 × 4096 ) y_{\text{logits}} = W_3 a_2 + b_3 \quad (W_3 \in \mathbb{R}^{10 \times 4096}) ylogits?=W3?a2?+b3?(W3?∈R10×4096)- 輸出10維向量(CIFAR-10的類別數)。
3.2.3 與特征提取層的對比
| 特性 | 特征提取層(卷積層) | 分類器層(全連接層) |
|---|---|---|
| 輸入類型 | 原始像素或低級特征 | 高級語義特征(如512×7×7) |
| 操作類型 | 局部卷積、池化 | 全局線性變換、非線性激活 |
| 參數分布 | 權重共享(卷積核) | 全連接權重(無共享) |
| 主要功能 | 提取空間局部特征(邊緣→紋理→語義部件) | 整合全局特征,輸出類別概率 |
| 維度變化 | 通道數增加,空間分辨率降低 | 特征維度壓縮,最終輸出類別數 |
三,完整代碼
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import time# 數據預處理
# 將CIFAR-10的32x32圖像縮放至224x224(VGG16的標準輸入尺寸)。
# 使用ImageNet的均值和標準差進行歸一化。
# 缺少數據增強(如隨機裁剪、翻轉等)。
transform = transforms.Compose([transforms.Resize(224), # VGG16 需要 224x224 的輸入transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 加載 CIFAR-10 數據集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=4)# 定義 VGG16 模型
# 自定義VGG16模型,包含13個卷積層和3個全連接層。
# 輸入尺寸為224x224,經過5次最大池化后特征圖尺寸為7x7,全連接層輸入維度為512 * 7 * 7=25088,符合原版VGG16設計。
# ?特征提取層:13個卷積層(含ReLU激活)+ 5個最大池化層
# ?分類層:3個全連接層(含Dropout)
# ?輸出維度:num_classes(CIFAR-10為10)
class VGG16(nn.Module):def __init__(self, num_classes=10):super(VGG16, self).__init__()# VGG16 的卷積層部分self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2))# VGG16 的全連接層部分self.classifier = nn.Sequential(nn.Dropout(),nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes))def forward(self, x):x = self.features(x) # 通過卷積層x = torch.flatten(x, 1) # 展平x = self.classifier(x) # 通過全連接層return x# 實例化模型
model = VGG16(num_classes=10)# 使用 GPU 如果可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 損失函數和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 訓練函數
def train(model, train_loader, criterion, optimizer, num_epochs=10):model.train() # 切換到訓練模式epoch_times = []for epoch in range(num_epochs):start_time = time.time()running_loss = 0.0correct = 0total = 0for i, (inputs, labels) in enumerate(train_loader):inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad() # 清空梯度outputs = model(inputs)loss = criterion(outputs, labels)loss.backward() # 反向傳播optimizer.step() # 參數更新running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()epoch_loss = running_loss / len(train_loader)epoch_acc = 100. * correct / totalepoch_end_time = time.time()epoch_duration = epoch_end_time - start_timeepoch_times.append(epoch_duration)print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_acc:.2f}%, Time: {epoch_duration:.2f}s')avg_epoch_time = sum(epoch_times) / num_epochsprint(f'\nAverage Epoch Time: {avg_epoch_time:.2f}s')# 測試函數
def test(model, test_loader):model.eval() # 切換到評估模式correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()accuracy = 100. * correct / totalprint(f'Test Accuracy: {accuracy:.2f}%')# 訓練和測試模型
train(model, train_loader, criterion, optimizer, num_epochs=10)
test(model, test_loader)




)




——3.4指令類型)




)



