隨著電商行業的快速發展,用戶行為分析成為企業優化營銷策略、提升用戶體驗的重要手段。通過分析用戶的購物行為數據,企業可以挖掘出用戶群體的消費特征和行為模式,從而制定更加精準的營銷策略。本文將詳細介紹一個基于Python實現的電商用戶購物行為分析系統,涵蓋數據預處理、K-Means聚類、分類驗證和結果可視化等模塊。
系統架構與模塊設計
該系統由四個主要模塊組成:
-
數據預處理模塊:負責加載、清洗和特征提取。
-
K-Means聚類模塊:用于用戶行為數據的聚類分析。
-
分類驗證模塊:驗證聚類結果的質量。
-
結果可視化模塊:將分析結果以圖表形式展示。
以下將詳細描述每個模塊的設計與實現。
數據預處理模塊
功能與實現
數據預處理是整個分析流程的基礎,其主要功能包括:
-
數據加載:從CSV文件中加載用戶行為數據。
-
數據清洗:處理缺失值、異常值和重復值。
-
特征提取:提取用戶行為的關鍵特征,如瀏覽次數、購買頻率等。
-
特征標準化:對特征進行歸一化或標準化處理。
-
特征降維:通過PCA等方法降低特征維度(可選)。
class DataPreprocessor:
def __init__(self, data_file):
self.data_file = data_file
self.data = Nonedef load_data(self):
try:
self.data = pd.read_csv(self.data_file)
print(f"數據加載成功,數據維度: {self.data.shape}")
return self.data
except Exception as e:
print(f"數據加載失敗: {e}")
return Nonedef clean_data(self):
# 處理缺失值
self.data = self.data.dropna()
# 處理重復值
self.data = self.data.drop_duplicates()
print(f"數據清洗完成,清洗后數據維度: {self.data.shape}")
return self.datadef extract_features(self):
# 提取用戶行為特征
user_features = self.data.groupby('user_id').agg({
'page_views': 'sum',
'purchase_amount': 'sum',
'visit_duration': 'mean',
'purchase_frequency': 'count'
}).reset_index()
print("特征提取完成")
return user_featuresdef normalize_features(self, method='z-score'):
# 特征標準化
scaler = StandardScaler()
normalized_features = pd.DataFrame(scaler.fit_transform(user_features),
columns=user_features.columns)
normalized_features['user_id'] = user_features['user_id']
print("特征標準化完成")
return normalized_features
K-Means聚類模塊
功能與實現
K-Means聚類模塊用于將用戶劃分為不同的群體,主要功能包括:
-
最優K值選擇:通過肘部法則和輪廓系數確定最優聚類數。
-
聚類執行:使用K-Means算法對用戶行為數據進行聚類。
-
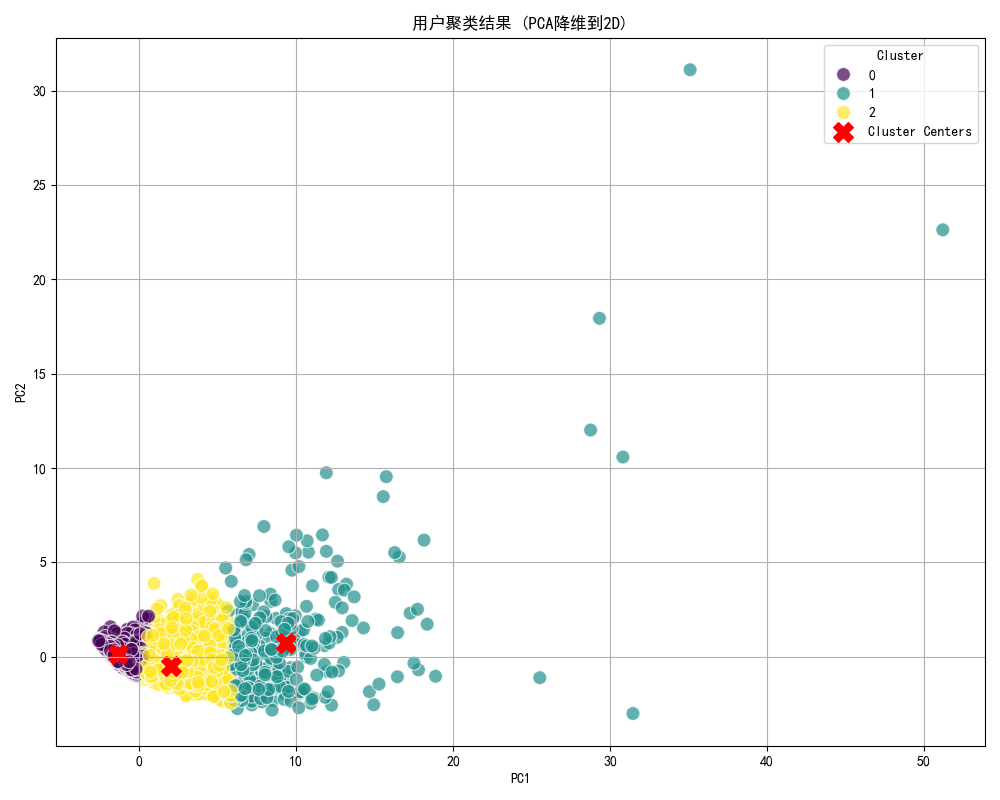
聚類結果可視化:通過2D/3D散點圖展示聚類結果。
-
聚類結果分析:計算每個簇的特征統計量。
代碼實現
class KMeansClusterer:
def __init__(self, features_data):
self.features_data = features_data
self.kmeans_model = None
self.cluster_labels = None
self.optimal_k = Nonedef find_optimal_k(self, k_range=(2, 10)):
# 使用肘部法則和輪廓系數確定最優K值

詳解:從零開始掌握(3))

)
)











深度教程)

:技術革新與行業發展脈絡梳理)
、CGAL(幾何計算)的安裝與使用指南)