文章目錄
- Pre
- 引言
- 案例
- 何謂查詢分離?
- 何種場景下使用查詢分離?
- 查詢分離實現思路
- 1. 如何觸發查詢分離?
- 方式一: 修改業務代碼:在寫入常規數據后,同步建立查詢數據。
- 方式二:修改業務代碼:在寫入常規數據后,異步建立查詢數據。
- 方式三: 監控數據庫日志:如有數據變更,更新查詢數據。
- 方案對比
- 適用場景
- 2. 如何實現查詢分離?
- 3. 查詢數據如何存儲?
- 4. 查詢數據如何使用?
- 整體方案
- 歷史數據遷移
- 查詢分離解決方案的不足

Pre
MySQL索引原理與優化指南:深入解析B+Tree與高效查詢策略
MySQL - 事務隔離級別和鎖的機制
MySQL - 讀多寫少場景下的優化數據查詢方案
MySQL - 寫多讀少的場景下如何優化數據存儲方案
MySQL - 冷熱分離:表數據量大讀寫緩慢的優化方案
引言
MySQL - 冷熱分離:表數據量大讀寫緩慢的優化方案中提到了冷熱分離解決方案的性價比高,但它并不是一個最優的方案,仍然存在諸多不足,比如:查詢冷數據慢、業務無法再修改冷數據、冷數據多到一定程度系統依舊扛不住,我們如果想把這些問題一一解決掉,可以用另外一種解決方案——查詢分離。

注意:查詢分離與讀寫分離還是有區別的
案例
某系統工單表中存放了幾千萬條數據,且查詢工單表數據時需要關聯十幾個子表,每個子表的數據也是超億條。
如此龐大的數據量,跟前面的冷熱分離一樣,每次查詢數據時幾十秒才能返回結果,即便使用了索引、SQL 等數據庫優化技巧,效果依然不明顯。
加上工單表中有些數據是幾年前的,因業務原因,需要繼續保持更新,因此無法將這些舊數據封存到別的地方,也就沒法通過前面的冷熱分離方案來解決。
最終采用了查詢分離的解決方案,才得以將這個問題順利解決:將更新的數據放在一個數據庫里,而查詢的數據放在另外一個系統里。因為數據的更新都是單表更新,不需要關聯也沒有外鍵,所以更新速度立馬得到提升,數據的查詢則通過一個專門處理大數據量的查詢引擎來解決,也快速地滿足了需求。
通過這種解決方案處理后,每次查詢數據時,500ms 內就可得到返回結果。
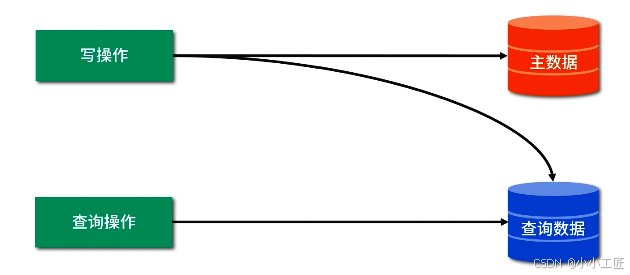
何謂查詢分離?
每次寫數據時保存一份數據到另外的存儲系統里,用戶查詢數據時直接從另外的存儲系統里獲取數據,示意圖如下:
何種場景下使用查詢分離?
當在實際業務中遇到以下情形,則可以考慮使用查詢分離解決方案。
-
數據量大;
-
所有寫數據的請求效率尚可;
-
查詢數據的請求效率很低;
-
所有的數據任何時候都可能被修改;
-
業務希望我們優化查詢數據的功能。
查詢分離實現思路
查詢分離解決方案的實現思路如下:
-
如何觸發查詢分離?
-
如何實現查詢分離?
-
查詢數據如何存儲?
-
查詢數據如何使用?
1. 如何觸發查詢分離?
這個問題說明的是我們應該在什么時候保存一份數據到查詢數據中,即什么時候觸發查詢分離這個動作。
一般來說,查詢分離的觸發邏輯分為 3 種。
方式一: 修改業務代碼:在寫入常規數據后,同步建立查詢數據。

方式二:修改業務代碼:在寫入常規數據后,異步建立查詢數據。
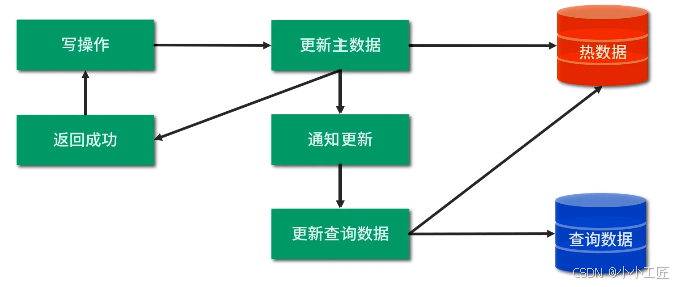
方式三: 監控數據庫日志:如有數據變更,更新查詢數據。
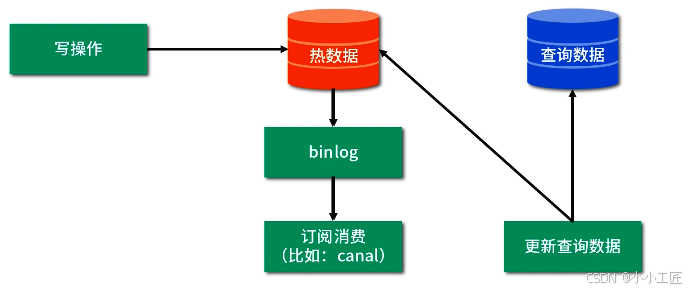
方案對比

適用場景

2. 如何實現查詢分離?
以上共3 種觸發邏輯,第 1 種是同步建立查詢數據的過程比較簡單,這里就不展開說明,接下來我們主要圍繞第 2 種來展開。
關于第 2 種觸發方案:修改業務代碼異步建立查詢數據,最基本的實現方式是單獨起一個線程建立查詢數據,不過這種做法會出現如下情況:
-
寫操作較多且線程太多,最終撐爆 JVM;
-
建查詢數據的線程出錯了,如何自動重試;
-
多線程并發時,很多并發場景需要解決。
面對以上三種情況,我們該如何處理?此時使用 MQ 管理這些線程即可解決。
MQ 的具體操作思路為每次主數據寫操作請求處理時,都會發一個通知給 MQ,MQ 收到通知后喚醒一個線程更新查詢數據
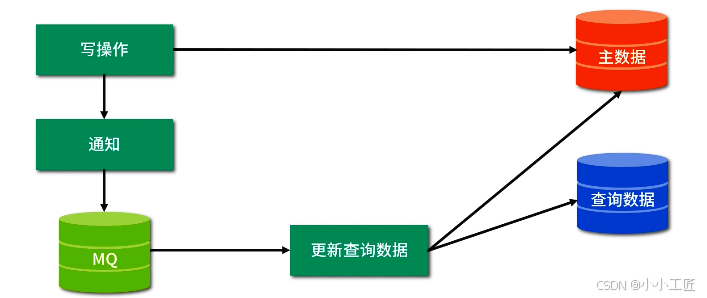
了解了 MQ 的具體操作思路后,還應該考慮以下 5 大問題。
問題一:MQ 如何選型?
從易用性和代碼工作量角度考量即可。
問題二:MQ 宕機了怎么辦?
如果 MQ 宕機了,我們只需要保證主流程正常進行,且 MQ 恢復后數據正常處理即可,具體方案分為三大步驟。
-
每次寫操作時,在主數據中加個標識:
NeedUpdateQueryData=true,這樣發到 MQ 的消息就很簡單,只是一個簡單的信號告知更新數據,并不包含更新的數據 id。 -
MQ 的消費者獲取信號后,先批量查詢待更新的主數據,然后批量更新查詢數據,更新完后查詢數據的主數據標識
NeedUpdateQueryData就更新成 false 了。 -
當然還存在多個消費者同時搬運動作的情況,這就涉及并發性的問題,因此問題冷熱分離中的并發性處理邏輯類似。
問題三:更新查詢數據的線程失敗了怎么辦?
如果更新的線程失敗了,NeedUpdateQueryData 的標識就不會更新,后面的消費者會再次將有 NeedUpdateQueryData 標識的數據拿出來處理。但如果一直失敗,我們可以在主數據中多添加一個嘗試搬運次數,比如每次嘗試搬運時 +1,成功后就清零,以此監控那些嘗試搬運次數過多的數據。
問題四:消息的冪等消費
在編程中,一個冪等操作的特點是多次執行某個操作均與執行一次操作的影響相同。
舉個例子,比如主數據的訂單 A 更新后,我們在查詢數據中插入了 A,可是此時系統出問題了,系統誤以為查詢數據沒更新,又把訂單 A 插入更新了一次。
所謂冪等,就是不管更新查詢數據的邏輯執行幾次,結果都是我們想要的結果。因此,考慮消費端并發性的問題時,我們需要保證更新查詢數據冪等。
問題五:消息的時序性問題
比如某個訂單 A 更新了 1 次數據變成 A1,線程甲將 A1 的數據搬到查詢數據中。不一會兒,后臺訂單 A 又更新了 1 次數據變成 A2,線程乙也啟動工作,將 A2 的數據搬到查詢數據中。
所謂的時序性就是如果線程甲啟動比乙早,但搬運數據動作比線程乙還晚完成,就有可能出現查詢數據最終變成過期的 A1。如下圖(動作前面的序號代表實際動作的先后順序):
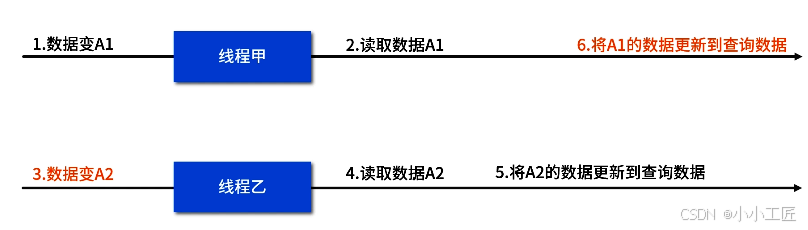
此時解決方案為主數據每次更新時,都更新上次更新時間 last_update_time,然后每個線程更新查詢數據后,檢查當前訂單 A 的 last_update_time 是否跟線程剛開始獲得的時間一樣,且 NeedUpdateQueryData 是否等于 false,如果都滿足的話,我們就將 NeedUpdateQueryData 改為 true,然后再做一次搬運。
MQ 在這里的作用只是一個觸發信號的工具,如果不用 MQ 好像也沒啥問題啊,但是MQ的作用不僅體現在這里,還有以下:
-
服務的解耦: 這樣主業務邏輯就不會依賴更新查詢數據這個服務了。
-
控制更新查詢數據服務的并發量: 如果我們直接調用更新查詢數據服務,因寫操作速度快,更新查詢數據速度慢,寫操作一旦并發量高,會給更新查詢數據服務造成超負荷壓力。如果通過消息觸發更新查詢數據服務,我們就可以通過控制消息消費者的線程數來控制負載。
3. 查詢數據如何存儲?
我們應該使用什么技術存儲查詢數據呢?目前,市面上主要使用 Elasticsearch 實現大數據量的搜索查詢,當然還可能會使用到 MongoDB、HBase 這些技術,這就需要我們對各種技術的特性了如指掌,再進行技術選型。
關于技術選型這個問題,很多時候我們不能單單只考慮業務功能的需求,還需要考慮組織結構。比如當初設計架構方案時,為什么選擇用 Elasticsearch,除 ES 對查詢的擴展性支持外,最關鍵的一點是團隊對 Elasticsearch 很熟悉。
4. 查詢數據如何使用?
因 ES 自帶 API,所以使用查詢數據時,我們在查詢業務代碼中直接調用 ES 的 API 就行。
不過,這個辦法會出現一個問題:數據查詢更新完前,查詢數據不一致怎么辦?
2 種解決思路。
-
在查詢數據更新到最新前,不允許用戶查詢。(我們沒用過這種設計,但我確實見過市面上有這樣的設計。)
-
給用戶提示:您目前查詢到的數據可能是 1 秒前的數據,如果發現數據不準確,可以嘗試刷新一下,這種提示用戶一般比較容易接受。
整體方案
以上,我們已經把四個問題都討論完了,我們再一起看下查詢分離的整體方案,如下圖所示:
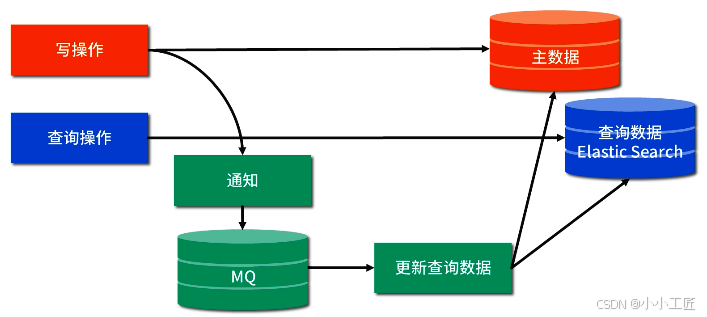
歷史數據遷移
新的架構方案上線后,舊的數據如何適用新的架構方案?這是實際業務中需要我們考慮的問題。
在這個方案里,我們只需要把所有的歷史數據加上這個標識:NeedUpdateQueryData=true,程序就會自動處理了。
查詢分離解決方案的不足
查詢分離這個解決方案雖然能解決一些問題,但我們也要清醒地認識到它的不足。
不足一: 使用 Elasticsearch 存儲查詢數據時,注意事項是什么 ?
不足二: 主數據量越來越大后,寫操作還是慢,到時還是會出問題。
不足三: 主數據和查詢數據不一致時,假設業務邏輯需要查詢數據保持一致性呢?









)







:過擬合與正則化)


