Generative AI with Diffusion Models,加載時間在20分鐘左右,耐心等待。

6.2TODO
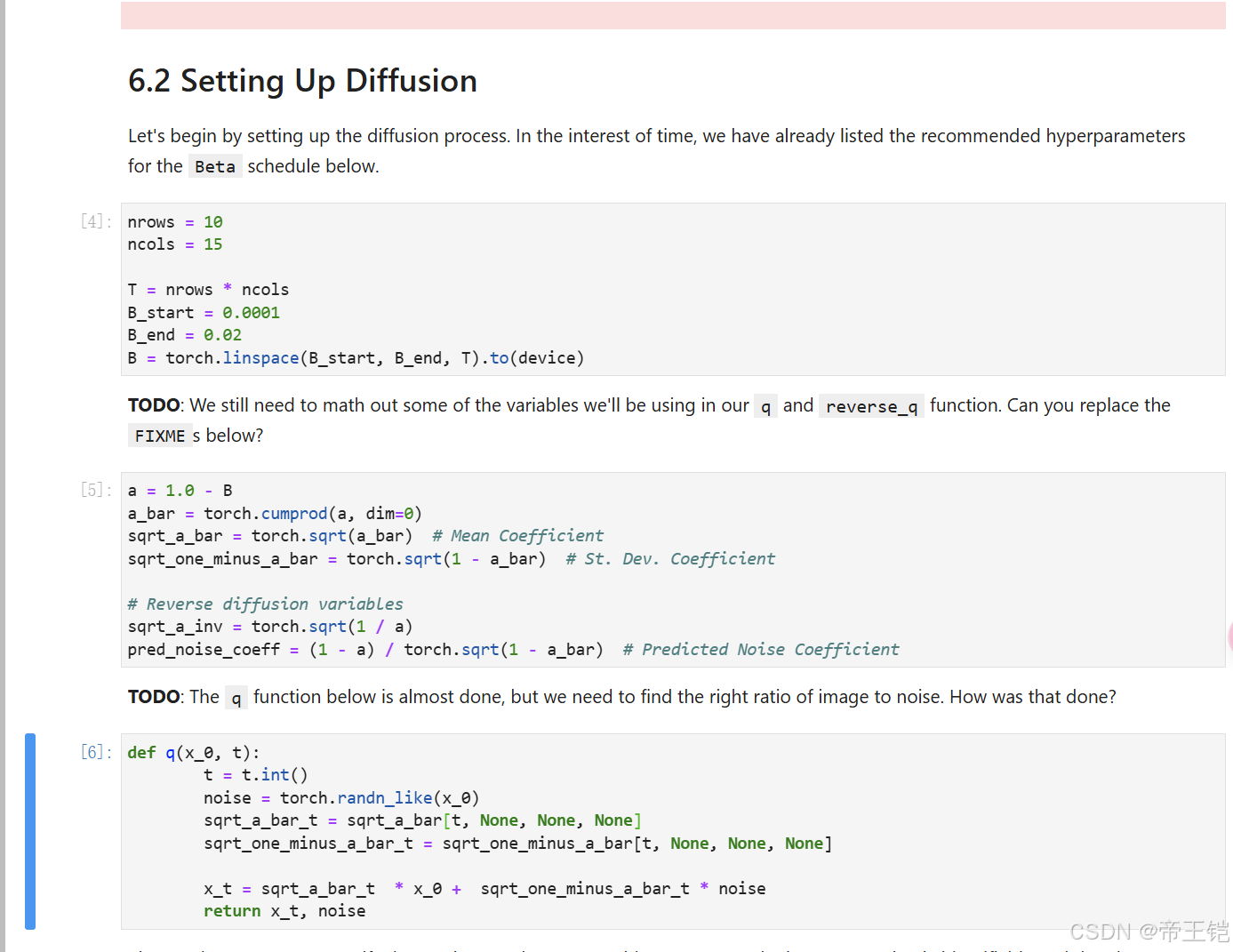
這里是在設置擴散模型的參數,代碼里的FIXME部分需要根據上下文進行替換。以下是各個FIXME的替換說明:
1.a_bar 是 a 的累積乘積,在 PyTorch 里可以用 torch.cumprod 實現。
2.sqrt_a_bar、sqrt_one_minus_a_bar 和 sqrt_a_inv 都是對輸入張量求平方根,可使用 torch.sqrt 實現。
3.pred_noise_coeff 中的 FIXME(1 - a_bar) 同樣是求平方根,用 torch.sqrt 即可。
以下是替換后的代碼:
nrows = 10
ncols = 15T = nrows * ncols
B_start = 0.0001
B_end = 0.02
B = torch.linspace(B_start, B_end, T).to(device)a = 1.0 - B
a_bar = torch.cumprod(a, dim=0)
sqrt_a_bar = torch.sqrt(a_bar) # Mean Coefficient
sqrt_one_minus_a_bar = torch.sqrt(1 - a_bar) # St. Dev. Coefficient# Reverse diffusion variables
sqrt_a_inv = torch.sqrt(1 / a)
pred_noise_coeff = (1 - a) / torch.sqrt(1 - a_bar) # Predicted Noise Coefficient
在擴散模型里,正向擴散過程 q 函數是按照如下公式把原始圖像 x_0 逐步添加噪聲變成 x_t 的
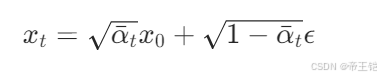
FIXME 部分應該分別用 sqrt_a_bar_t 和 sqrt_one_minus_a_bar_t 來替換。
在這個 q 函數中,按照擴散模型的正向過程公式,把原始圖像 x_0 和隨機噪聲 noise 按一定比例組合,從而得到加噪后的圖像 x_t。
def q(x_0, t):t = t.int()noise = torch.randn_like(x_0)sqrt_a_bar_t = sqrt_a_bar[t, None, None, None]sqrt_one_minus_a_bar_t = sqrt_one_minus_a_bar[t, None, None, None]x_t = sqrt_a_bar_t * x_0 + sqrt_one_minus_a_bar_t * noisereturn x_t, noise
在反向擴散過程中,我們要根據當前的潛在圖像,當前時間步 , 以及預測的噪聲 來恢復上一個時間步的圖像。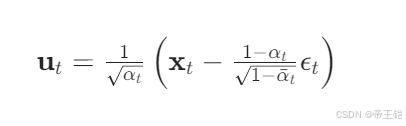
在這個 reverse_q 函數中,我們根據反向擴散過程的公式,從當前的潛在圖像和預測的噪聲中恢復上一個時間步的圖像。如果當前時間步為 0,則表示反向擴散過程完成。否則,我們會添加一些噪聲以模擬擴散過程。下面是對代碼中 FIXME 部分的分析與替換:
@torch.no_grad()
def reverse_q(x_t, t, e_t):t = t.int()pred_noise_coeff_t = pred_noise_coeff[t]sqrt_a_inv_t = sqrt_a_inv[t]u_t = sqrt_a_inv_t * (x_t - pred_noise_coeff_t * e_t)if t[0] == 0: # All t values should be the samereturn u_t # Reverse diffusion complete!else:B_t = B[t - 1] # Apply noise from the previous timestepnew_noise = torch.randn_like(x_t)return u_t + torch.sqrt(B_t) * new_noise

6.3TODO
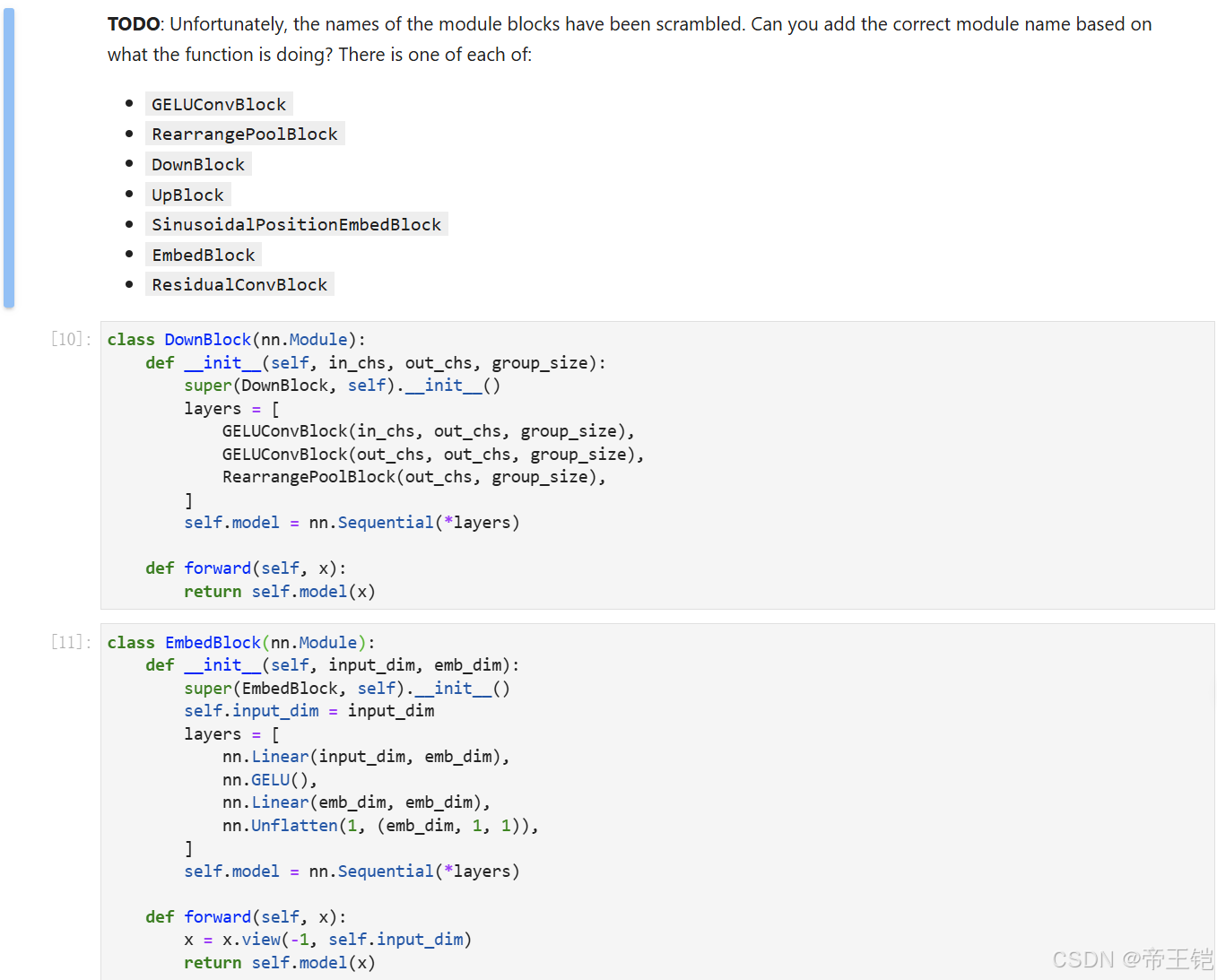
每個類的功能來添加正確模塊名 依次改寫FIXME 即可:
DownBlock進行下采樣操作,包含卷積和池化相關的塊
EmbedBlock將輸入進行線性變換和激活
GELUConvBlock使用了卷積、組歸一化和 GELU 激活函數,通常是一個卷積塊
RearrangePoolBlock使用了 Rearrange 進行張量重排和卷積操作
ResidualConvBlock使用了兩個卷積塊并進行了殘差連接
SinusoidalPositionEmbedBlock實現了正弦位置嵌入的功能
UpBlock上采樣操作,包含轉置卷積和卷積塊
6.4TODO
在這個 get_context_mask 函數里,其目的是隨機丟棄上下文信息。要實現隨機丟棄,通常會使用 torch.bernoulli 函數。torch.bernoulli 函數會依據給定的概率來生成一個二進制掩碼張量,其中每個元素為 1 的概率就是傳入的概率值。
在這個函數中,我們希望以 drop_prob 的概率丟棄上下文,所以每個元素保留的概率是 1 - drop_prob。因此,FIXME 處應該填入 bernoulli。
def get_context_mask(c, drop_prob):c_hot = F.one_hot(c.to(torch.int64), num_classes=N_CLASSES).to(device)c_mask = torch.bernoulli(torch.ones_like(c_hot).float() * (1 - drop_prob)).to(device)return c_hot, c_mask
代碼解釋:
c_hot = F.one_hot(c.to(torch.int64), num_classes=N_CLASSES).to(device):將輸入的 c 轉換為獨熱編碼向量,并且移動到指定的設備(如 GPU)上。
c_mask = torch.bernoulli(torch.ones_like(c_hot).float() * (1 - drop_prob)).to(device):生成一個與 c_hot 形狀相同的二進制掩碼張量,每個元素以 1 - drop_prob 的概率為 1,以 drop_prob 的概率為 0。
return c_hot, c_mask:返回獨熱編碼向量和二進制掩碼張量。
這樣,你就可以使用這個函數來隨機丟棄上下文信息了。

在擴散模型里,通常采用均方誤差損失(Mean Squared Error Loss,MSE)來衡量預測噪聲 noise_pred 和實際添加的噪聲 noise 之間的差異。因為均方誤差能夠很好地衡量兩個向量之間的平均平方誤差,這對于擴散模型中預測噪聲的準確性評估是很合適的。
在 PyTorch 中,nn.functional.mse_loss 函數可用于計算均方誤差損失。所以 FIXME 處應填入 mse_loss。
def get_loss(model, x_0, t, *model_args):x_noisy, noise = q(x_0, t)noise_pred = model(x_noisy, t/T, *model_args)return F.mse_loss(noise, noise_pred)
代碼解釋
x_noisy, noise = q(x_0, t):調用 q 函數給原始圖像 x_0 添加噪聲,得到加噪后的圖像 x_noisy 以及實際添加的噪聲 noise。
noise_pred = model(x_noisy, t/T, *model_args):把加噪后的圖像 x_noisy 和歸一化后的時間步 t/T 輸入到模型 model 中,得到模型預測的噪聲 noise_pred。
return F.mse_loss(noise, noise_pred):使用 F.mse_loss 函數計算實際噪聲 noise 和預測噪聲 noise_pred 之間的均方誤差損失并返回。
通過使用均方誤差損失,模型能夠學習到如何更準確地預測添加到圖像中的噪聲,從而在反向擴散過程中更好地恢復原始圖像。
下一個 TODO
- c_drop_prob 的設置
c_drop_prob 是上下文丟棄概率,一般在訓練過程中會采用線性衰減策略,也就是在訓練初期以較高概率丟棄上下文,隨著訓練的推進逐漸降低丟棄概率。在代碼中,我們可以簡單地將其設置為一個隨著訓練輪數逐漸降低的值。 - get_context_mask 函數的輸入
get_context_mask 函數需要一個上下文標簽作為輸入,在代碼里這個標簽應該從 batch 中獲取。通常假設 batch 的第二個元素為上下文標簽。
optimizer = Adam(model.parameters(), lr=0.001)
epochs = 5
preview_c = 0model.train()
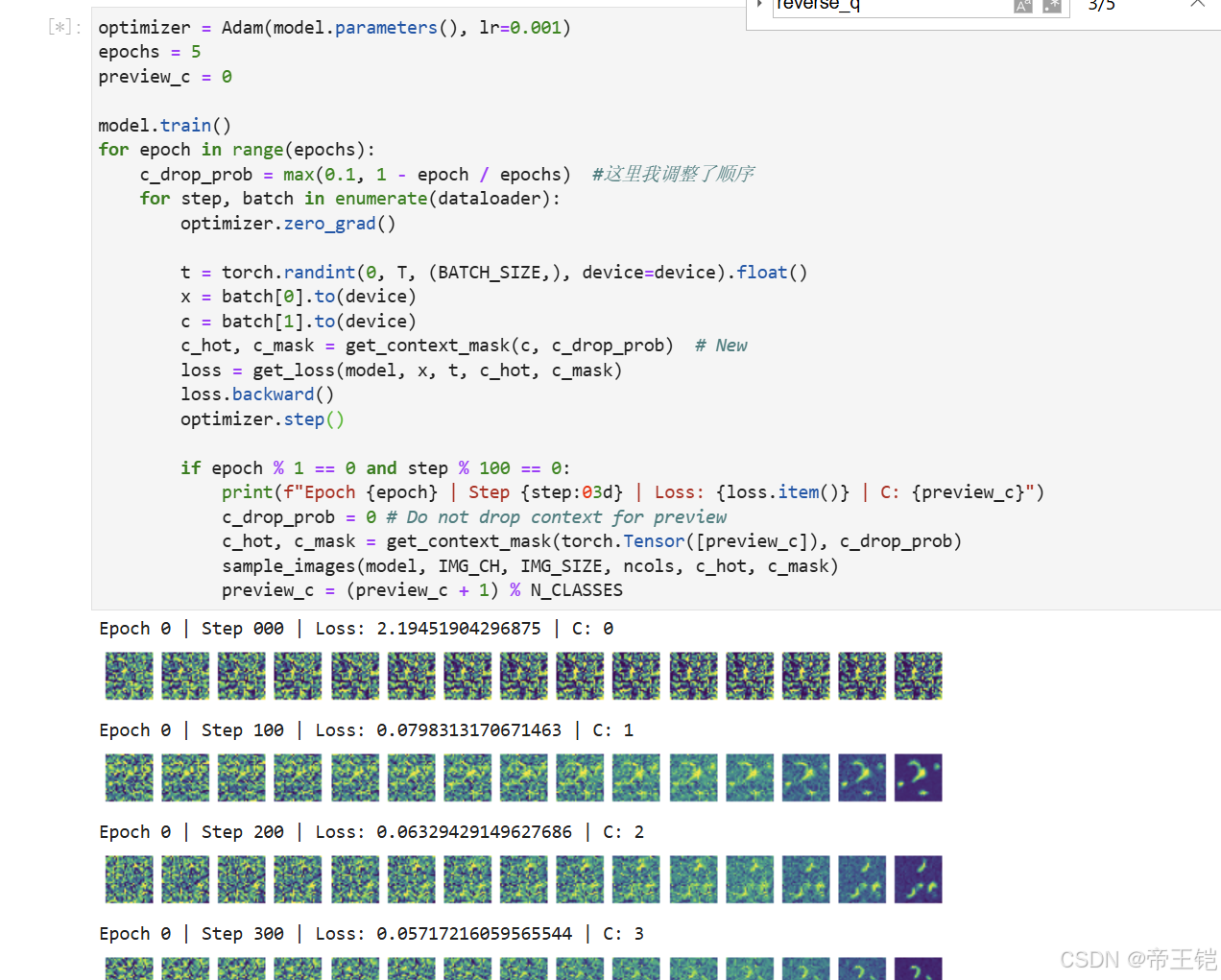
for epoch in range(epochs):# 線性衰減上下文丟棄概率c_drop_prob = max(0.1, 1 - epoch / epochs) #這里我調整了順序for step, batch in enumerate(dataloader):optimizer.zero_grad()t = torch.randint(0, T, (BATCH_SIZE,), device=device).float()x = batch[0].to(device)# 假設 batch 的第二個元素是上下文標簽c = batch[1].to(device)c_hot, c_mask = get_context_mask(c, c_drop_prob)loss = get_loss(model, x, t, c_hot, c_mask)loss.backward()optimizer.step()if epoch % 1 == 0 and step % 100 == 0:print(f"Epoch {epoch} | Step {step:03d} | Loss: {loss.item()} | C: {preview_c}")c_drop_prob = 0 # Do not drop context for previewc_hot, c_mask = get_context_mask(torch.Tensor([preview_c]).to(device), c_drop_prob)sample_images(model, IMG_CH, IMG_SIZE, ncols, c_hot, c_mask)preview_c = (preview_c + 1) % N_CLASSES
代碼解釋
c_drop_prob 的設置:運用線性衰減策略,在訓練初期 c_drop_prob 為 0.9,隨著訓練的推進逐漸降低到 0.1。
get_context_mask 函數的輸入:假設 batch 的第二個元素是上下文標簽,將其傳入 get_context_mask 函數。
訓練過程:在每個訓練步驟中,先將梯度清零,接著計算損失,再進行反向傳播和參數更新。每訓練 100 個步驟,就打印一次損失信息并進行一次樣本生成。
通過這些修改,代碼就能正常運行,從而開始訓練模型。
6.5TODO
在擴散模型的采樣過程中,為了給擴散過程添加權重,一般會根據給定的權重 w 對保留上下文的預測噪聲 e_t_keep_c 和丟棄上下文的預測噪聲 e_t_drop_c 進行加權組合。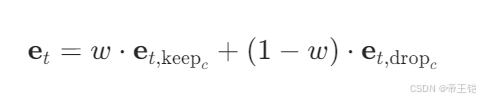
在代碼中,FIXME 處應該根據上述公式進行計算,將 e_t_keep_c 和 e_t_drop_c 按照權重 w 進行組合。具體的代碼如下:
def sample_w(model, c, w):input_size = (IMG_CH, IMG_SIZE, IMG_SIZE)n_samples = len(c)w = torch.tensor([w]).float()w = w[:, None, None, None].to(device) # Make w broadcastablex_t = torch.randn(n_samples, *input_size).to(device)# One c for each wc = c.repeat(len(w), 1)# Double the batchc = c.repeat(2, 1)# Don't drop context at test timec_mask = torch.ones_like(c).to(device)c_mask[n_samples:] = 0.0x_t_store = []for i in range(0, T)[::-1]:# Duplicate t for each samplet = torch.tensor([i]).to(device)t = t.repeat(n_samples, 1, 1, 1)# Double the batchx_t = x_t.repeat(2, 1, 1, 1)t = t.repeat(2, 1, 1, 1)# Find weighted noisee_t = model(x_t, t, c, c_mask)e_t_keep_c = e_t[:n_samples]e_t_drop_c = e_t[n_samples:]e_t = w * e_t_keep_c + (1 - w) * e_t_drop_c# Deduplicate batch for reverse diffusionx_t = x_t[:n_samples]t = t[:n_samples]x_t = reverse_q(x_t, t, e_t)return x_t
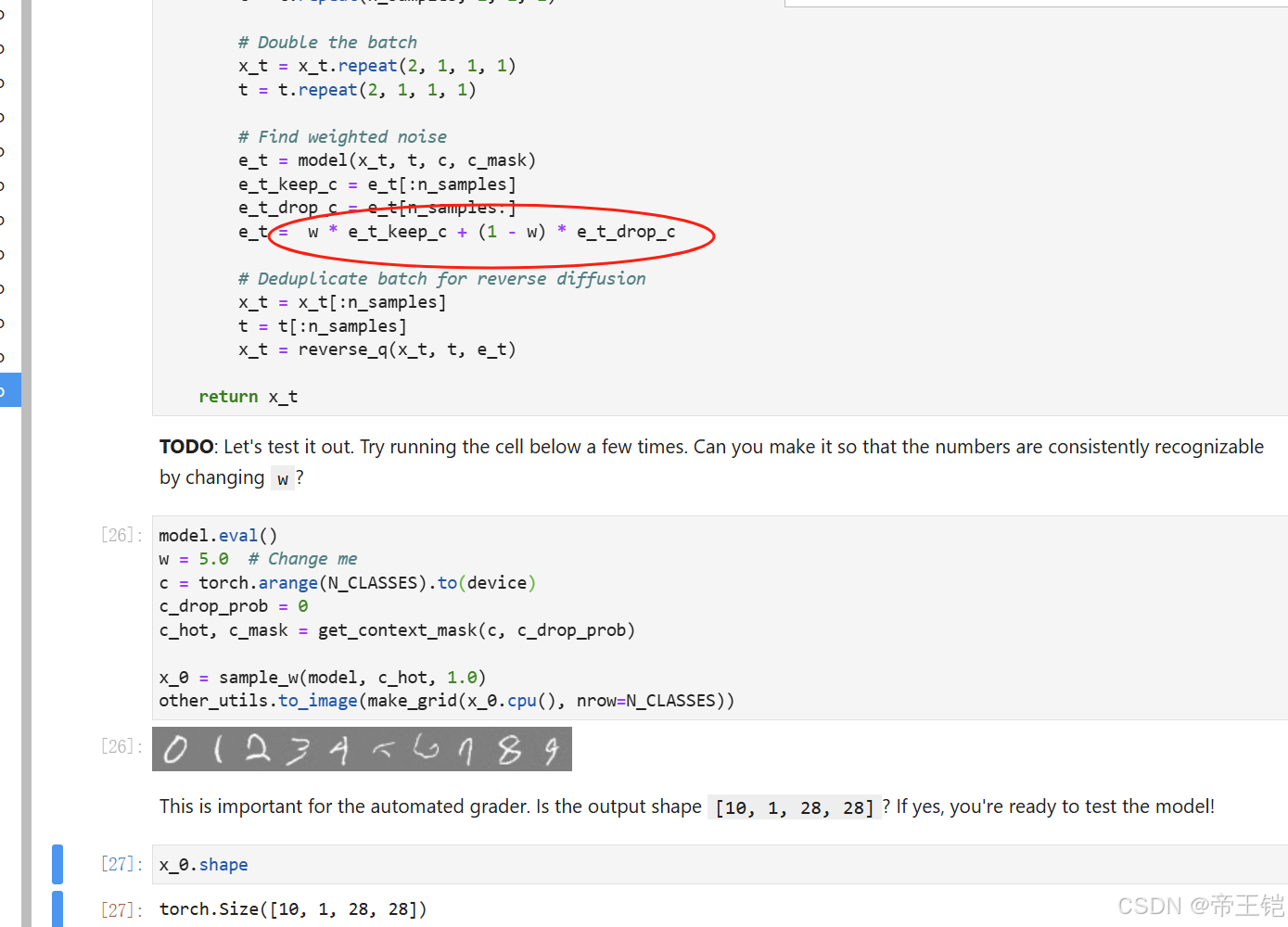
在擴散模型里,權重 w 可用于控制上下文信息在生成過程中的影響程度。w 值越接近 1,生成結果就越依賴上下文信息;w 值越接近 0,生成結果受上下文信息的影響就越小。若要讓生成的數字能夠被持續識別,你可以試著增大 w 的值,以此增強上下文信息對生成過程的影響。
下面是修改后的代碼,你可以調整 w 的值來觀察生成結果:
model.eval()
w = 5.0 # 可以嘗試不同的值,通常大于 1 能增強上下文的影響
c = torch.arange(N_CLASSES).to(device)
c_drop_prob = 0
c_hot, c_mask = get_context_mask(c, c_drop_prob)x_0 = sample_w(model, c_hot, w)
other_utils.to_image(make_grid(x_0.cpu(), nrow=N_CLASSES))
代碼解釋
w = 5.0:把 w 的值設為 5.0,你可以根據實際情況調整這個值。通常,當 w 大于 1 時,上下文信息的影響會得到增強,這樣生成的數字可能會更易于識別。
x_0 = sample_w(model, c_hot, w):調用 sample_w 函數生成圖像,將 w 作為參數傳入。
other_utils.to_image(make_grid(x_0.cpu(), nrow=N_CLASSES)):把生成的圖像轉換為可視化的形式。
你可以多次運行這段代碼,并且調整 w 的值,直到生成的數字能夠被穩定識別。
至此結束。
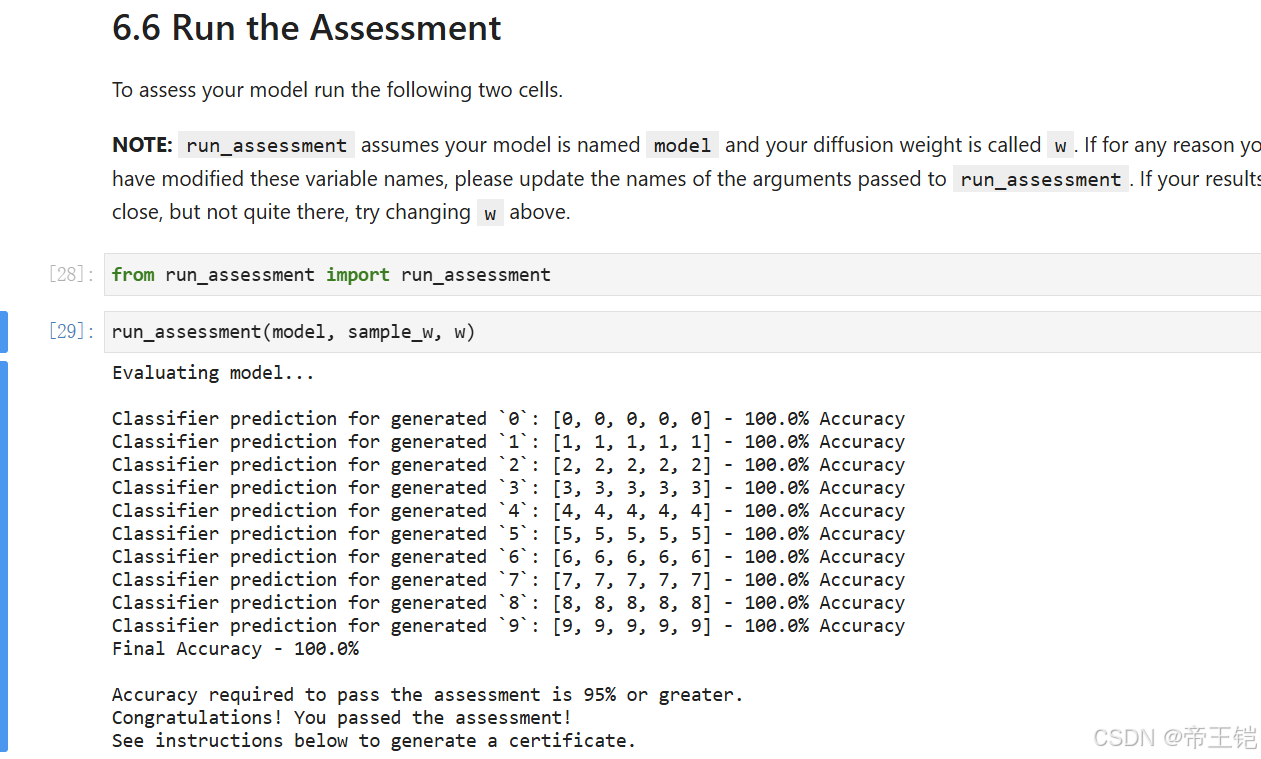
完整代碼都在圖片里




)

)






)
 Socket入門 TCP同步連接 與 簡單封裝練習)
)



