
- 作者:Junming FAN 1 ^{1} 1, Yue YIN 1 ^{1} 1, Tian WANG 1 ^{1} 1, Wenhang DONG 1 ^{1} 1, Pai ZHENG 1 ^{1} 1, Lihui WANG 2 ^{2} 2
- 單位: 1 ^{1} 1香港理工大學工業及系統工程系, 2 ^{2} 2瑞典皇家理工學院
- 論文標題: Vision-language model-based human-robot collaboration for smart manufacturing: A state-of-the-art survey
- 論文鏈接:https://link.springer.com/content/pdf/10.1007/s42524-025-4136-9.pdf
- 出版信息:Frontiers of Engineering Management 2025, 12(1): 177–200
主要貢獻
- 論文系統總結了VLMs在智能制造中人機協作領域的最新進展和應用。通過對VLMs的基本架構、預訓練方法和應用案例的詳細分析,填補了現有研究中缺乏全面視角的空白。
- 詳細探討了VLMs在機器人任務規劃、導航和操作中的應用。通過結合視覺和語言信息,VLMs顯著增強了機器人的任務執行能力和人機交互的靈活性。
- 強調了VLMs在人機技能轉移中的作用,展示了如何通過多模態數據整合來簡化機器人技能的獲取過程,來提高機器人適應未來靈活制造環境的能力。
- 討論了當前VLMs應用的局限性,并提出了未來研究的方向,包括提高實時處理能力、增強動態環境適應性和提升操作精度等。
介紹
-
人機協作的潛力:
- 人機協作(human–robot collaboration,HRC)被視為制造業變革的重要途徑,通過結合人類的靈活性和機器人的精確性來提高生產力、適應性和效率。
- 這種協同工作模式標志著智能制造的重大轉變。
- 最近在人工智能領域的突破,特別是計算機視覺和自然語言處理,展示了推動這一轉型的巨大潛力。
- 通過賦予機器人多模態感知和理解能力,機器人可以在更復雜和無縫的環境中與人類協作。
-
VLMs的應用:
- 由于標準的大模型(LLMs)僅能處理文本信息,限制了其在需要視覺上下文的場景中的應用。
- VLMs通過整合視覺和文本數據,增強了機器人解釋和互動環境的能力。
- VLMs在圖像描述、視覺問答和多模態推理等任務中表現出色。
-
研究現狀與不足:
- 盡管VLMs在HRC場景中有初步應用,但現有研究較為分散,缺乏對VLMs潛力的全面探索。
- 本文旨在填補這一空白,提供VLMs在HRC中的最新進展和應用的綜合綜述。
-
研究目標:
- 本文的目標是通過系統回顧VLMs在HRC中的應用,展示其潛力并指出當前的限制。
- 強調未來研究方向,以實現VLMs在智能制造中的全部潛力。
文獻綜述過程
-
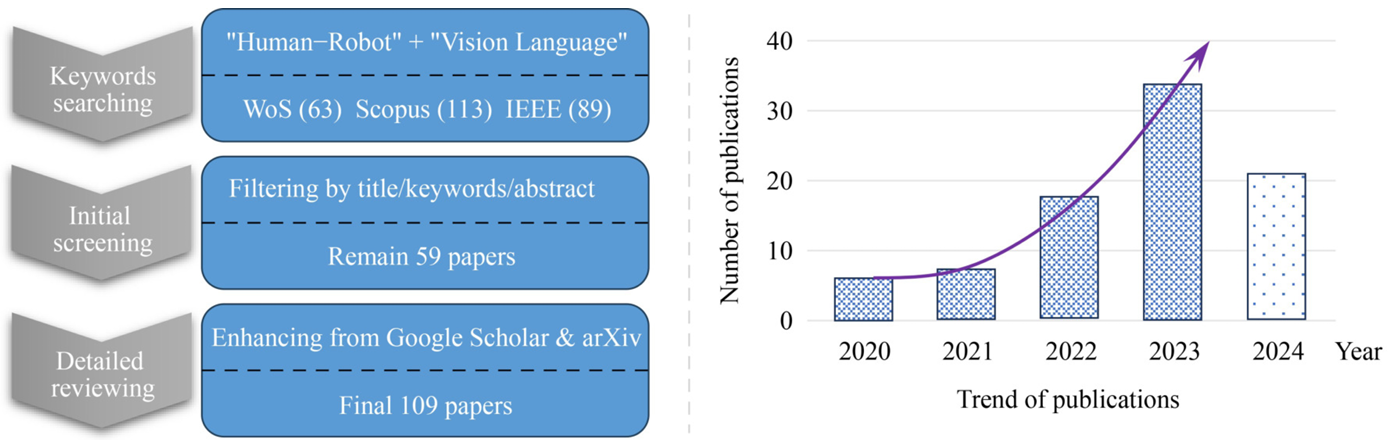
系統性搜索:
- 使用Web of Science、Scopus和IEEE Xplore等學術數據庫進行初始搜索,關鍵詞包括“human-robot”和“vision language”。
- 搜索時間跨度為2020年至2024年,共檢索到63項來自Web of Science、113項來自Scopus和89項來自IEEE Xplore的相關文獻。
-
文獻篩選:
- 初步篩選階段,僅包括英文的期刊和會議論文。
- 根據標題、關鍵詞和摘要排除明顯不符合范圍的文獻,最終篩選出59篇論文。
-
深入審查:
- 實施深入審查過程,進一步識別不合適的文獻并進行分類。
- 由于初步數據庫的文獻有限,從Google Scholar和arXiv等較寬松的搜索引擎中補充相關文獻。
-
文獻選擇:
- 最終選擇了109篇文獻作為綜述的基礎。
- 這些文獻將在后續章節中詳細描述,以展示VLMs在HRC中的最新應用和進展。
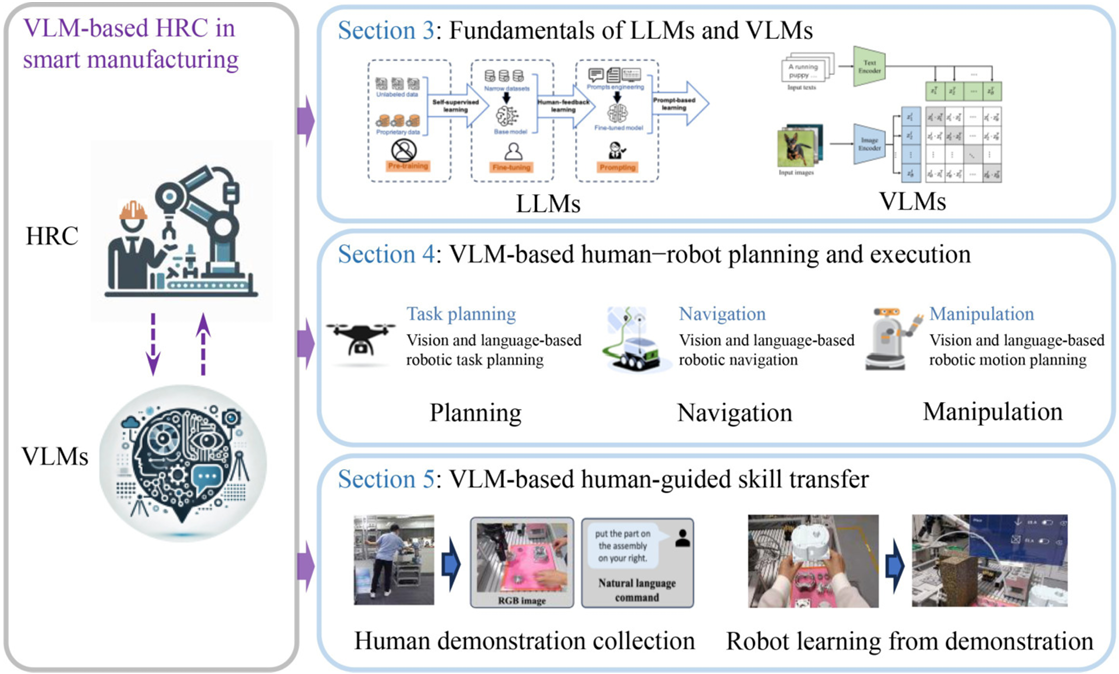
LLMs與VLMs回顧
大模型基礎
架構
-
LLMs通常基于Transformer架構構建,這是一種用于自然語言處理的深度學習模型。
-
Transformer通過使用多頭注意力機制來捕捉文本中的長距離依賴關系。
-
Transformer的核心是自注意力機制,其計算公式為:
Attention ? ( Q , K , V ) = softmax ? ( Q K T d k ) V , \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V, Attention(Q,K,V)=softmax(dk??QKT?)V, -
Transformer還包括編碼器和解碼器結構,用于處理輸入和生成輸出。
-
編碼器通過自注意力機制提取輸入文本的相關信息,而解碼器則使用編碼器的輸出來生成翻譯后的文本。
模型類型
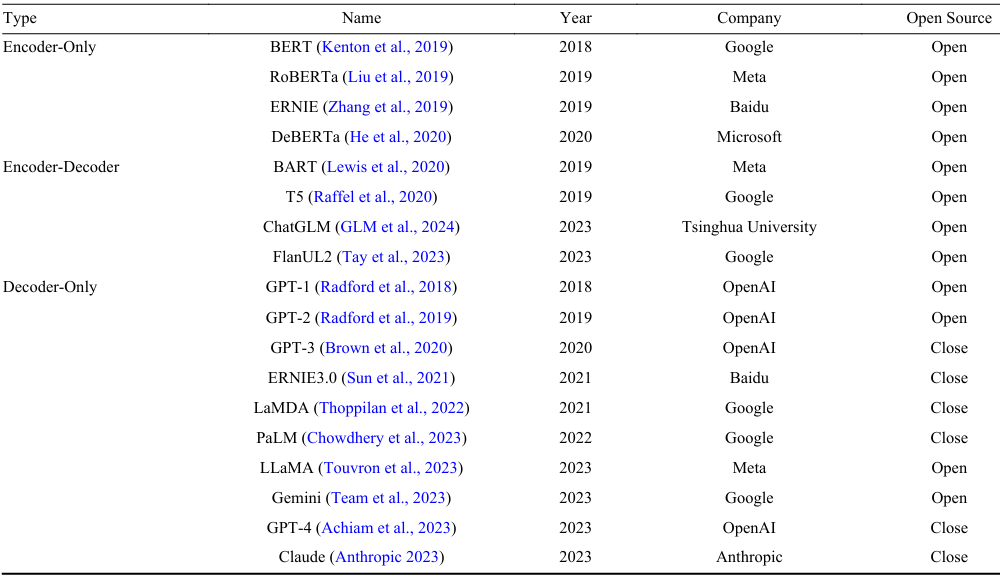
根據編碼器-解碼器結構的變體,LLMs可以分為三類:
-
僅編碼器模型:這些模型僅包含編碼器,適用于需要特征提取的任務,如文本分類。典型的例子包括BERT(Kenton and Toutanova, 2019)。
-
編碼器-解碼器模型:這類模型結合了編碼器和解碼器,適用于需要序列生成的任務,如翻譯和文本總結。典型的例子包括BART(Lewis et al., 2020)和T5(Raffel et al., 2020)。
-
僅解碼器模型:這些模型僅包含解碼器,專注于生成任務,如問答和文本生成。典型的例子包括GPT系列(Radford et al., 2018, 2019, 2020)。
預訓練
- 預訓練是LLMs的初始階段,通過在大量無監督的文本數據上進行訓練來發展基本的語言能力。
- 這一階段的目標是讓模型學會語言的基本結構和模式。
- 預訓練后,模型可以通過微調來適應特定任務。
微調和對齊
-
微調:在特定任務的數據集上進行訓練,以調整預訓練模型以適應新任務。微調通常使用監督學習技術。
-
對齊:
- 為了確保模型生成的內容符合人類價值觀和意圖,進行對齊訓練。
- 對齊通常涉及使用人類反饋來調整模型輸出,以避免生成不準確或有害的內容。
- 常用的技術包括強化學習與人類反饋(RLHF)。
Prompt技術
在模型經過充分訓練和微調后,Prompt技術用于引導模型生成所需的響應。常見的Prompt方法包括:
-
零樣本Prompt:模型在沒有示例的情況下被給予任務,依賴于其預訓練知識來生成響應。
-
上下文學習:也稱為少樣本學習,提供少量示例來指導模型的響應。
-
鏈式推理:一種Prompt技術,引導模型生成逐步推理或解釋,以提高其在復雜推理任務上的表現。
視覺語言模型基礎
目標
- VLMs旨在通過結合視覺和語言信息來增強模型的理解和推理能力。
- VLMs特別適用于需要跨模態理解的場景,如圖像描述、視覺問答和人機協作。
架構
- VLMs通常包括兩個并行編碼器:一個用于處理視覺數據(如圖像),另一個用于處理文本數據。
- 這些編碼器將輸入轉換為高維嵌入,然后在共享的特征空間中對齊或融合,使模型能夠聯合解釋和推理視覺和語言輸入。
視覺和語言編碼
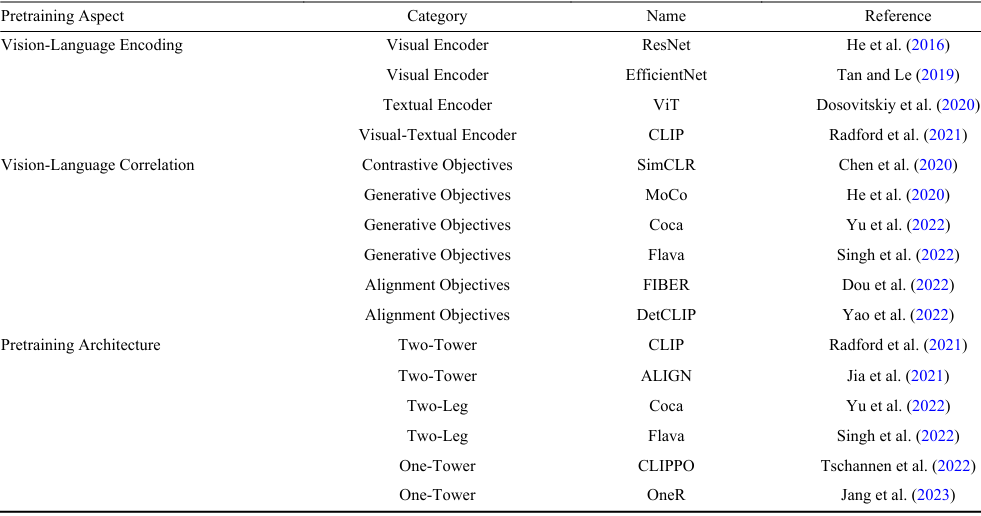
VLMs使用深度神經網絡從圖像-文本對中提取特征。典型的網絡架構包括:
-
視覺編碼器:
- 用于從圖像中提取特征。常見的架構包括卷積神經網絡(CNNs),如ResNet(He et al., 2016)和EfficientNet(Tan and Le, 2019)。
- 最近的研究還探索了Transformer架構,如ViT(Dosovitskiy et al., 2020),它在圖像特征學習中表現出色。
-
文本編碼器:
- 用于從文本中提取特征。Transformer架構及其變體是文本特征編碼的標準選擇。
- 例如,CLIP(Radford et al., 2021)使用標準Transformer架構進行文本編碼。
視覺-語言相關性
VLMs的核心在于理解視覺和語言數據之間的相關性。為此,設計了多種預訓練目標來增強視覺-語言特征的學習:
-
對比性目標:通過吸引成對樣本并推開不成對樣本來獲取判別性表示。這種方法通常通過最小化對稱的圖像-文本infoNCE損失來實現(Chen et al., 2020)。
-
生成性目標:通過訓練網絡生成圖像/文本數據來學習視覺-語言相關性特征。這包括圖像生成、語言生成或跨模態生成(He et al., 2021; Yu et al., 2022; Singh et al., 2022)。
-
對齊目標:通過全局圖像-文本匹配或區域-詞匹配來對齊圖像-文本特征(Dou et al., 2022; Yao et al., 2022)。
預訓練架構
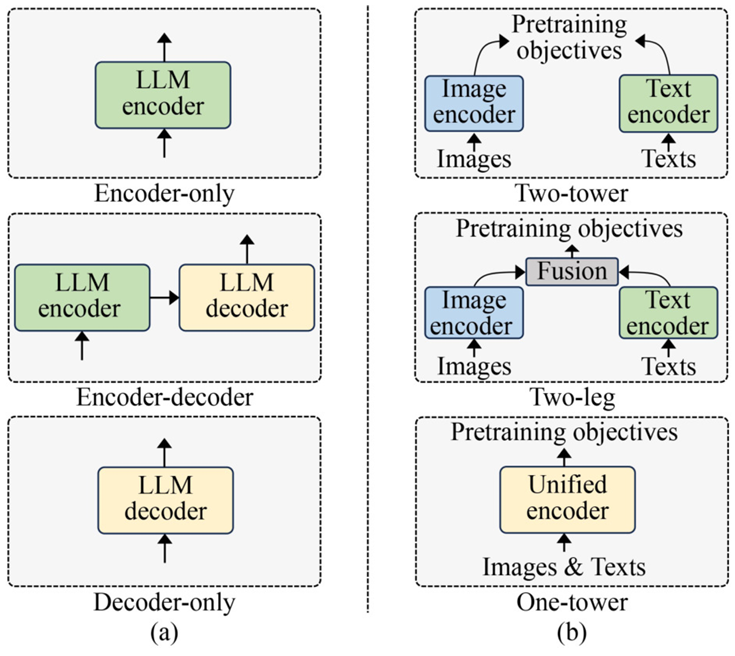
VLM預訓練的架構主要涉及視覺和語言處理分支及其嵌入的互連和通信方式。常見的框架包括:
-
雙塔架構:使用獨立的編碼器處理輸入圖像和文本。這種架構在VLMs中廣泛使用,如CLIP(Radford et al., 2021)和ALIGN(Jia et al., 2021)。
-
兩腿架構:包括額外的多模態融合層,促進圖像和文本特征之間的交互。這種架構在Yu et al.(2022)和Singh et al.(2022)的工作中被采用。
-
單塔架構:將視覺和語言處理集成到一個編碼器中,促進不同數據模態之間的更高效通信。這種架構在Tschannen et al.(2022)和Jang et al.(2023)的工作中被提出。
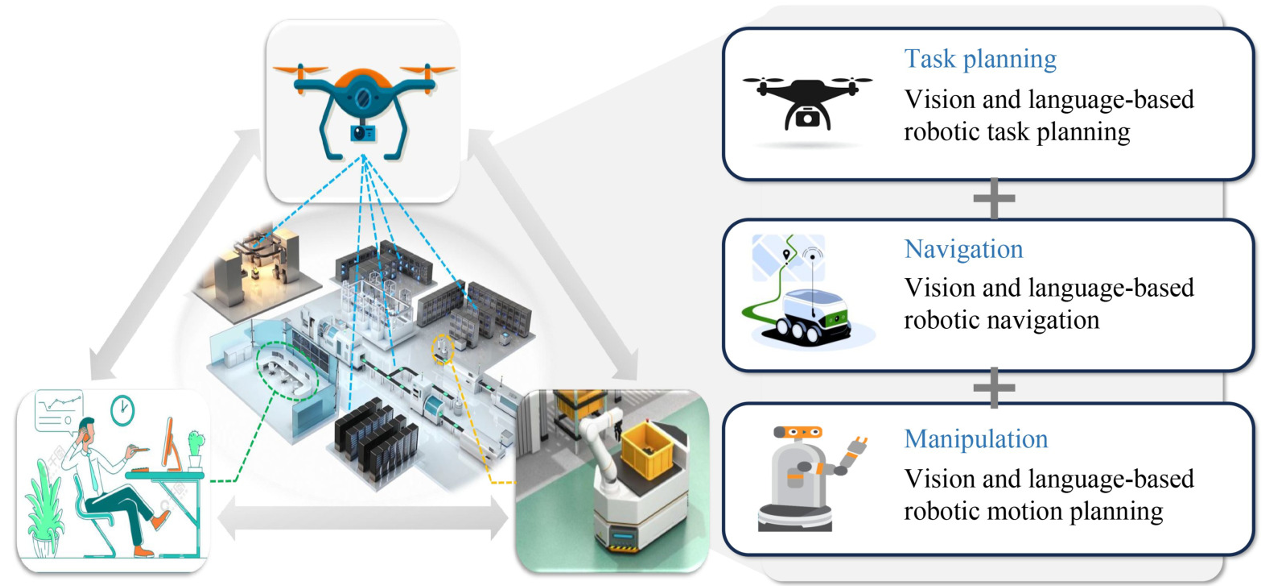
基于大模型的人機交互任務規劃與執行
視覺語言任務規劃
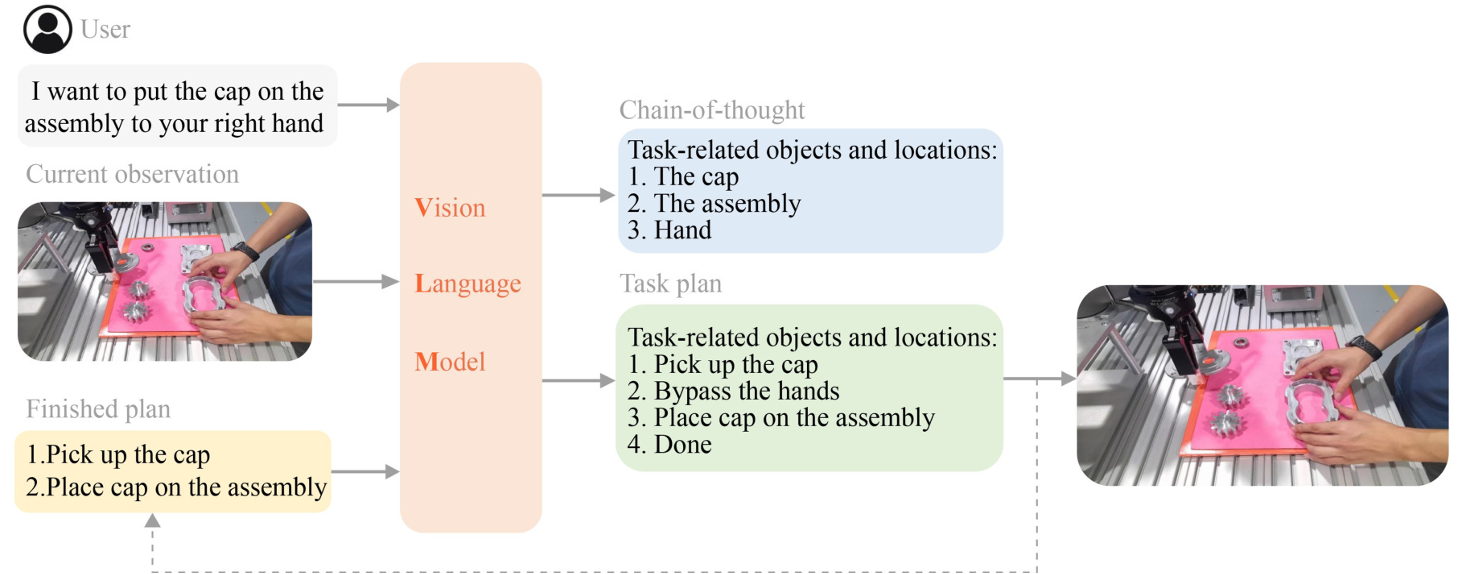
任務理解和分解
-
任務理解和分解是任務規劃的首要步驟,涉及從自然語言描述中提取任務目標,并將復雜任務分解為一系列可管理的子任務。
-
這一過程的關鍵在于VLMs能夠從文本和圖像中提取豐富的語義信息,從而實現更準確的任務理解。
- 任務理解:VLMs通過分析自然語言指令,理解任務的具體要求和目標。
- 任務分解:將復雜任務分解為多個子任務,便于機器人逐步執行。
-
VLMs在這一過程中發揮著重要作用,例如,Zheng et al.(2024)使用BERT和ResNet來解析真實場景,并通過PromptLLM來分解整體任務。
多模態任務信息融合
- 多模態任務信息的融合和比對是VLM成功理解和分解人機交互任務的關鍵。
- 核心在于如何在統一的表示空間中捕獲不同模態之間的關聯,并利用互補信息提供更全面的語義理解。
- 信息融合:通過結合視覺和語言信息,VLMs能夠更好地理解任務場景和人類指令。
- 語義理解:VLMs通過多模態信息融合,實現對任務場景的全面理解。
- Fan and Zheng(2024)通過結合CLIP模型解析視覺信息和LLM理解語言指令,生成可行的機器人動作序列。
動作序列生成
- 在任務分解和多模態信息融合之后,生成相應的動作序列來完成指定任務是關鍵步驟。
- VLMs可以直接從視覺和語言輸入生成合理的動作序列。
- 動作序列生成:VLMs通過端到端的方式生成動作序列,確保任務的順利執行。
- 實時適應性:生成的序列能夠適應動態變化的環境,提高任務執行的靈活性。
- Hu et al.(2023)和Zhang et al.(2024)展示了如何通過VLMs生成動作序列。
長期任務規劃
- 長期任務規劃涉及在較長時間跨度內進行任務規劃,需要考慮任務的長期目標和中間步驟的協調。
- 這一過程需要處理更多的不確定性和復雜性。
- 長期目標:VLMs需要具備處理長期任務目標的能力。
- 中間步驟協調:確保任務的不同階段能夠有效銜接。
- Wu et al.(2023)和Mei et al.(2024)展示了如何通過VLMs進行長期任務規劃,處理更復雜和不確定的任務。
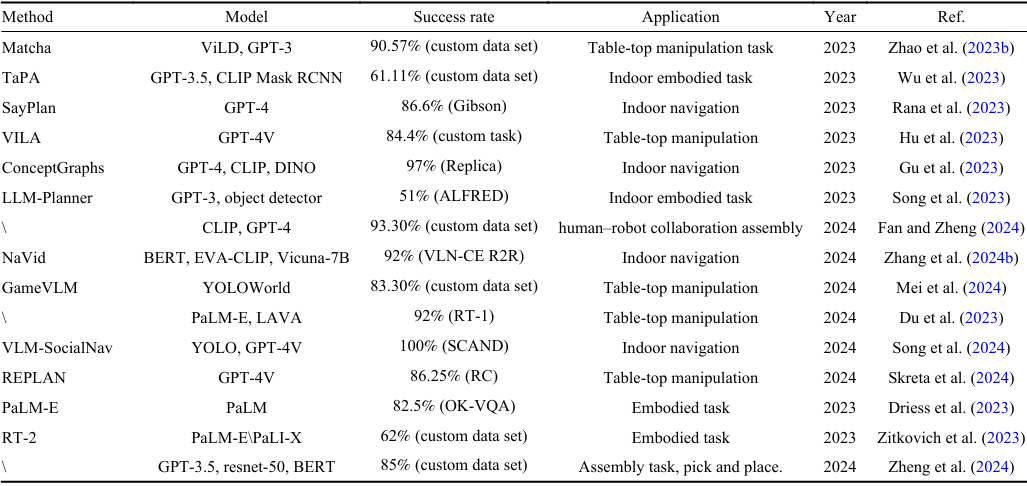
視覺語言導航
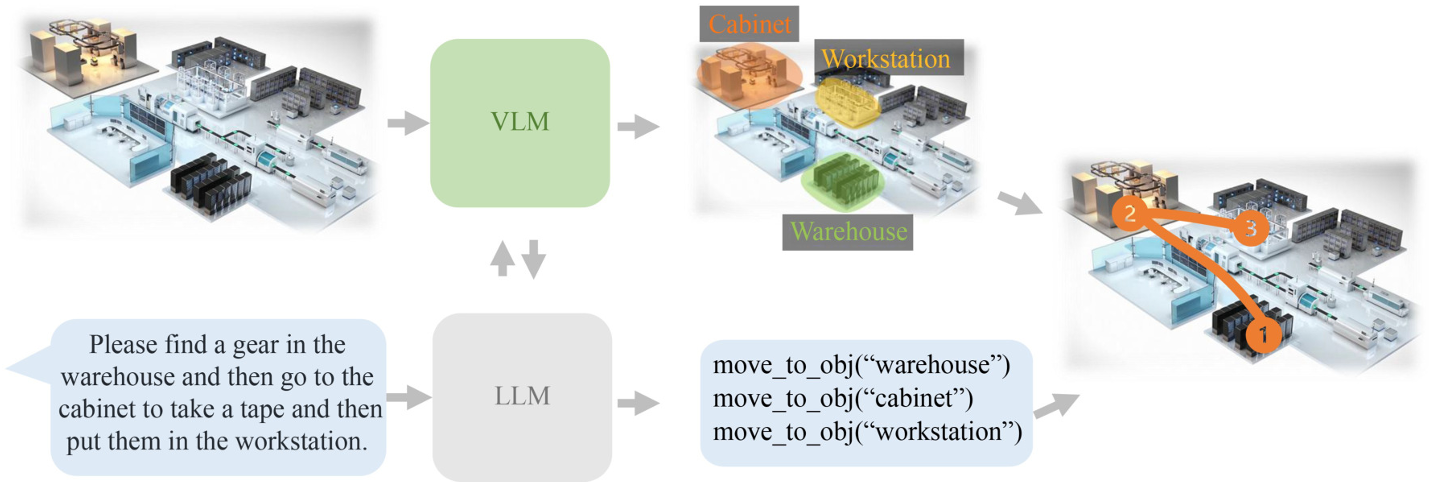
室內導航
-
室內導航是VLMs在機器人技術中最常見的應用之一,主要用于家庭服務機器人和工業協作機器人。
-
其主要目標是使機器人能夠在室內環境中根據人類的自然語言指令完成導航任務。
-
任務類型:
- 包括簡單的指令跟隨任務和遠程指代表達任務。
- 在簡單指令跟隨任務中,機器人接收詳細的步驟指令,并根據這些指令導航到目標位置。
- 遠程指代表達任務則需要機器人在不明確指令的情況下,通過與人類互動來確定目標位置。
-
關鍵技術:
- VLMs通常作為視覺編碼器來捕獲語義信息,而LLMs用于理解人類語言指令。
- CLIP模型因其強大的特征表示能力而被廣泛應用。
-
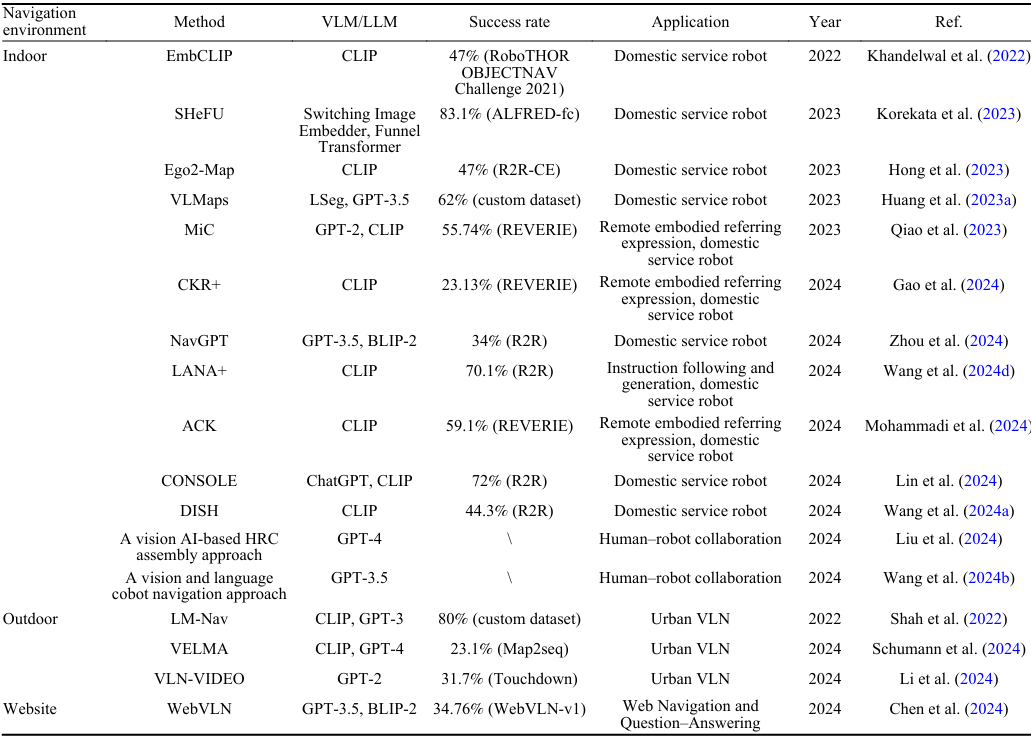
應用實例:
- Khandelwal et al.(2022)提出的EmbCLIP模型在RoboTHOR OBJECTNAV挑戰中取得了47%的成功率。
- Korekata et al.(2023)的SheFU模型在ALFRED-fc數據集中達到了83%的成功率。
戶外導航
-
戶外導航環境相對開放且復雜,涉及多種地形、天氣條件和動態元素(如車輛和行人)。
-
VLMs在戶外導航中的應用包括自動駕駛、機器人配送和智慧城市管理。
-
任務類型:
- 包括長距離導航和復雜環境中的路徑規劃。
- 這些任務需要機器人具備更高的自主性和適應性。
-
關鍵技術:
- VLMs結合SLAM(同時定位與地圖構建)技術,以提供實時的環境更新。
- CLIP和GPT-4的組合被用于處理復雜的導航任務。
-
應用實例:
- Shah et al.(2022)的LM-Nav系統在自定義數據集中取得了80%的成功率。
- Schumann et al.(2024)的VELMA模型在Map2seq數據集中達到了23.1%的成功率。
網絡環境導航
網絡環境導航是一個新興的應用領域,涉及機器人根據網絡內容進行導航和問答任務。
-
任務類型:
- 包括基于網頁內容的導航和問答。
- 這種任務需要機器人能夠理解網絡信息并據此做出決策。
-
關鍵技術:
- VLMs結合網絡爬蟲和自然語言處理技術,以實現基于網絡內容的導航。
-
應用實例:
- Chen et al.(2024)提出的WebVLN模型在WebVLN-v1數據集中實現了34.7%的任務完成率。
視覺語言操作
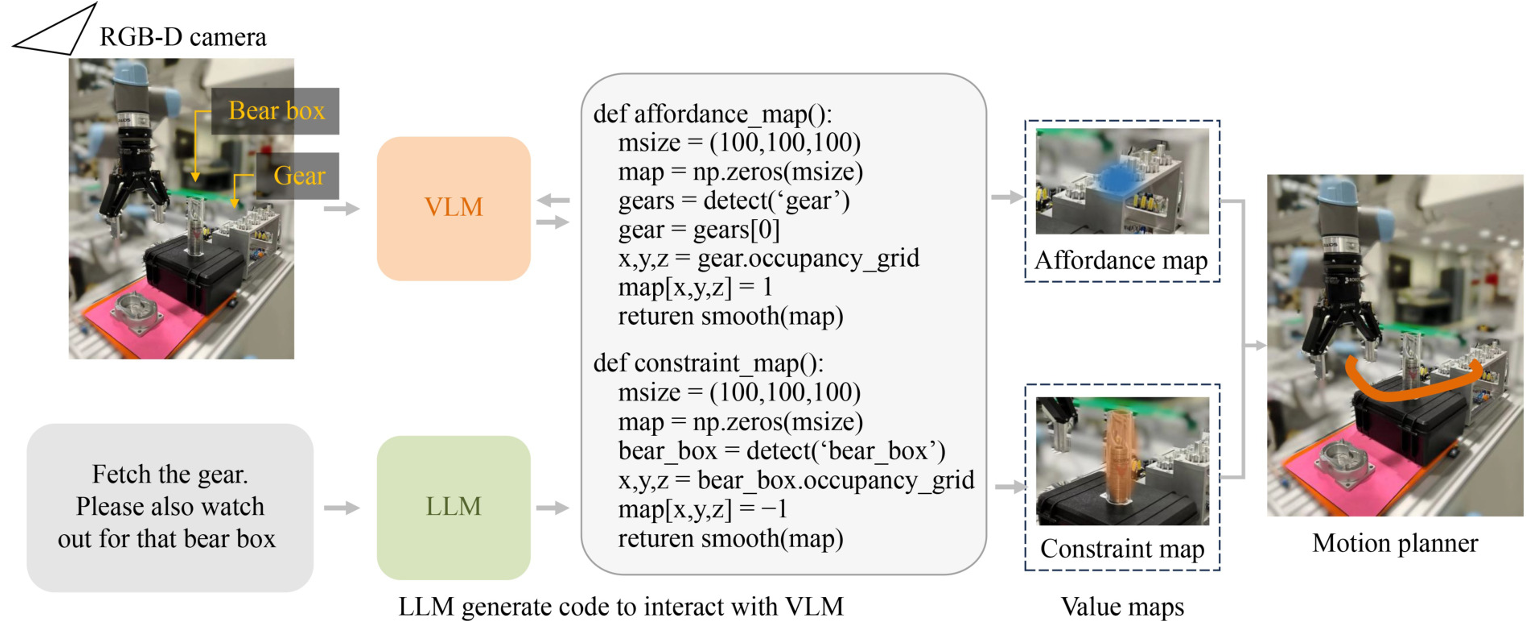
基于規劃的視覺語言操作
-
基于規劃的視覺和語言操作方法通過設計復雜的自然語言Prompt來指導機器人生成精確的運動軌跡。
-
這種方法側重于直接生成動作序列,以實現特定的操作任務。
-
方法概述:VLMs和LLMs結合使用,通過自然語言指令生成詳細的運動路徑。這種方法通常涉及設計復雜的Prompt來引導模型生成所需的動作序列。
-
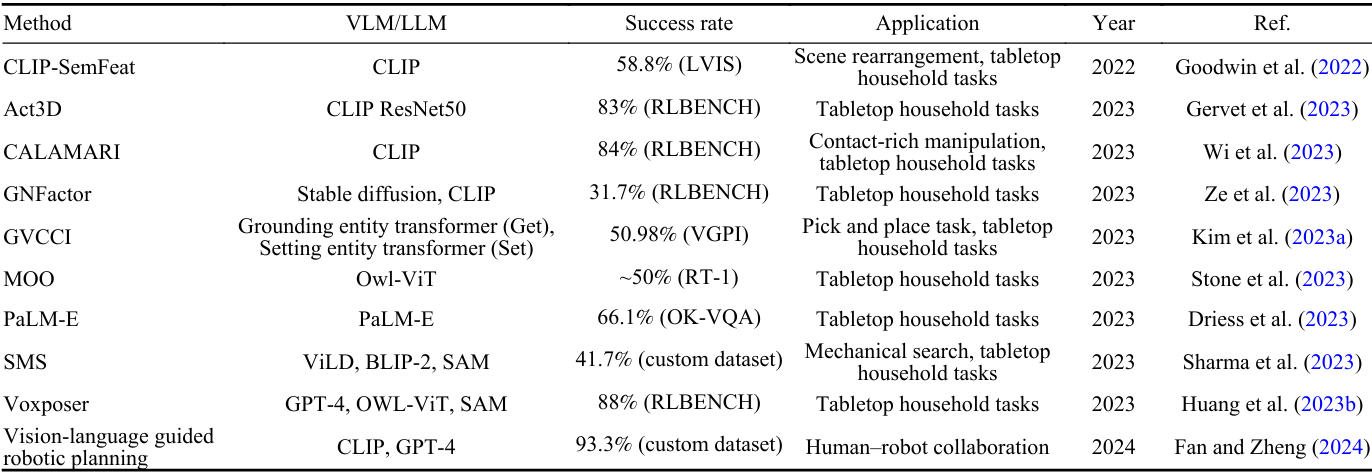
應用實例:Goodwin et al.(2022)提出的CLIP-SemFeat方法在場景重排任務中取得了58.8%的成功率。Driess et al.(2023)的PaLM-E模型在OK-VQA數據集中實現了66.1%的成功率。
-
挑戰:盡管這些方法在家庭環境中表現出色,但在工業應用中仍需提高精度和魯棒性。
基于學習的視覺語言操作
基于學習的視覺語言操作方法側重于通過機器人學習生成策略來完成操作任務,而不是直接生成軌跡。這種方法通過機器人與環境的交互來學習任務。
-
方法概述:VLMs和LLMs輔助生成策略,使機器人能夠通過經驗學習執行操作任務。這種方法通常涉及強化學習和模仿學習。
-
應用實例:Gervet et al.(2023)的Act3D方法在RLBENCH任務中取得了83%的成功率。Wi et al.(2023)的CALAMARI方法在擦拭桌面任務中達到了90%的成功率。
-
挑戰:這種方法在任務成功率和適應性方面表現出色,但在復雜任務中仍需進一步優化。
工業任務的操作
盡管大多數研究集中在家庭任務上,VLMs在工業任務中的應用也顯示出潛力。工業操作任務通常需要更高的精度和魯棒性。
-
應用實例:Fan and Zheng(2024)提出的視覺-語言引導的機器人規劃方法在工業裝配任務中取得了93.3%的成功率。
-
挑戰:工業任務的操作需要更高的精度和魯棒性,這對VLMs的規劃和執行能力提出了更高要求。
基于VLM的人類引導技能遷移與機器人學習
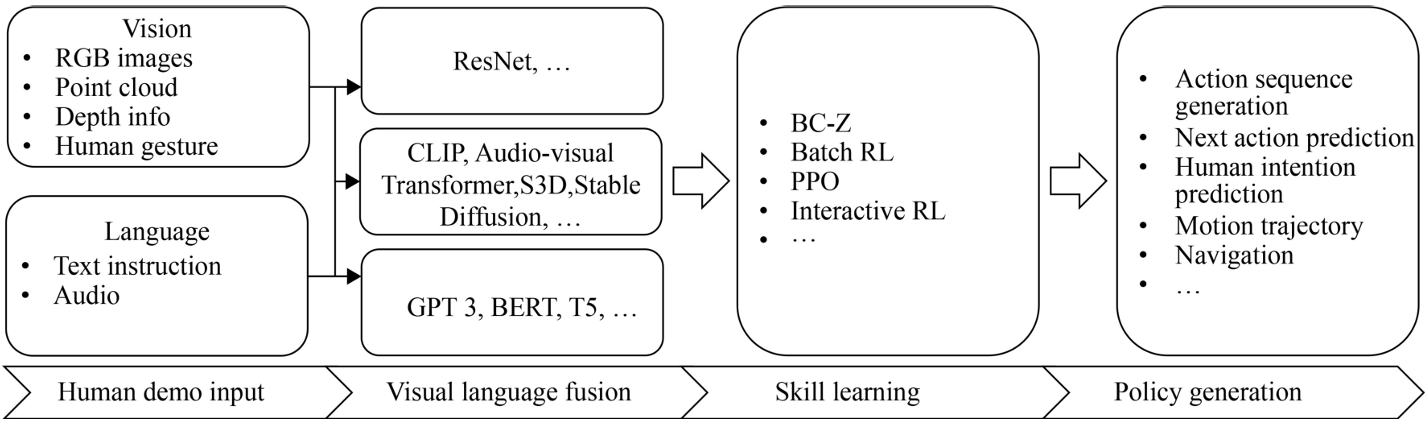
基于視覺語言模型的人類示范收集

與人類認知的對齊
-
人類通常通過觀察示范動作并結合聽到的口頭解釋來學習新技能。
-
因此,整合視頻和語言信息可以幫助機器人更緊密地模仿人類的學習過程。
-
方法:通過自然用戶交互(如指向、展示和口頭描述),機器人使用RGB攝像頭捕捉圖像數據,并結合骨架檢測和語音識別技術來逐步學習和更新對象模型。
-
應用:Azagra et al.(2020)通過這種方法使機器人能夠在動態和多樣化的交互環境中逐漸學習和理解不同的對象。
提高泛化能力
-
純粹的視頻觀察可能使機器人在理解動作的意圖和語義方面遇到困難。
-
語言信息可以提供關鍵的上下文細節,幫助機器人更好地理解示范的目的和邏輯。
-
方法:通過結合關鍵幀提取和強化學習,機器人可以提高命令生成的準確性。
-
應用:Yin和Zhang(2023)通過這種方法提高了機器人在任務執行中的準確性和泛化能力。
提取隱含規則
-
機器人可以從人類演示中學習隱含的規則和習慣,這些規則和習慣難以通過傳統方法明確抽象出來。
-
方法:通過行為驅動的狀態抽象,機器人可以捕獲人類任務相關的偏好。
-
應用:Peng et al.(2024)通過這種方法使機器人能夠學習有效的人類導航技能。
增強人機交互
-
相比被動視頻觀察,利用機器人遙控來收集演示數據是一種更準確和高效的方法。
-
這種方法結合了動作示范和語言解釋,提供了更直觀和有效的人機交互。
-
方法:通過多模態交互,機器人可以更好地理解和執行任務。
-
應用:Halim et al.(2022)通過這種方法引入了一種無代碼的機器人編程系統,適用于初學者。
支持更復雜的操作技能學習
-
獲取復雜的操作技能通常需要多模態信息。人類不僅掌握所需的動作,還理解與任務相關的各種狀態、狀態轉換和約束。
-
方法:通過多模態框架,機器人可以從多種感官數據中收集豐富的演示數據。
-
應用:Shukla et al.(2023)通過這種方法支持機器人學習復雜的工具操作技能。
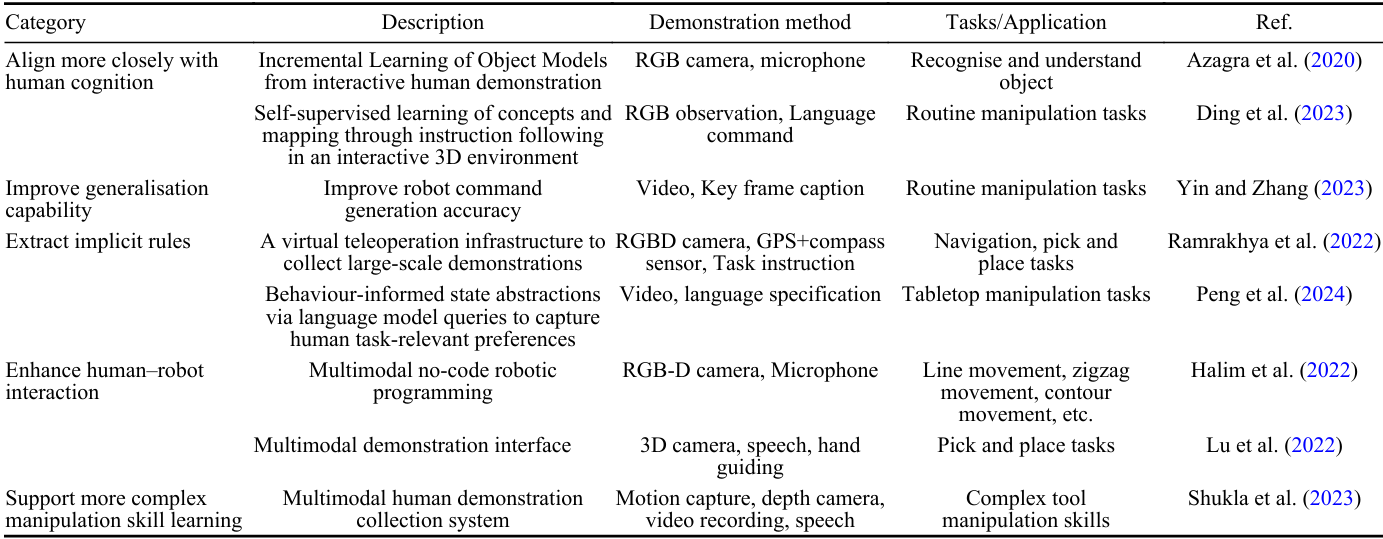
基于視覺語言模型的機器人學習
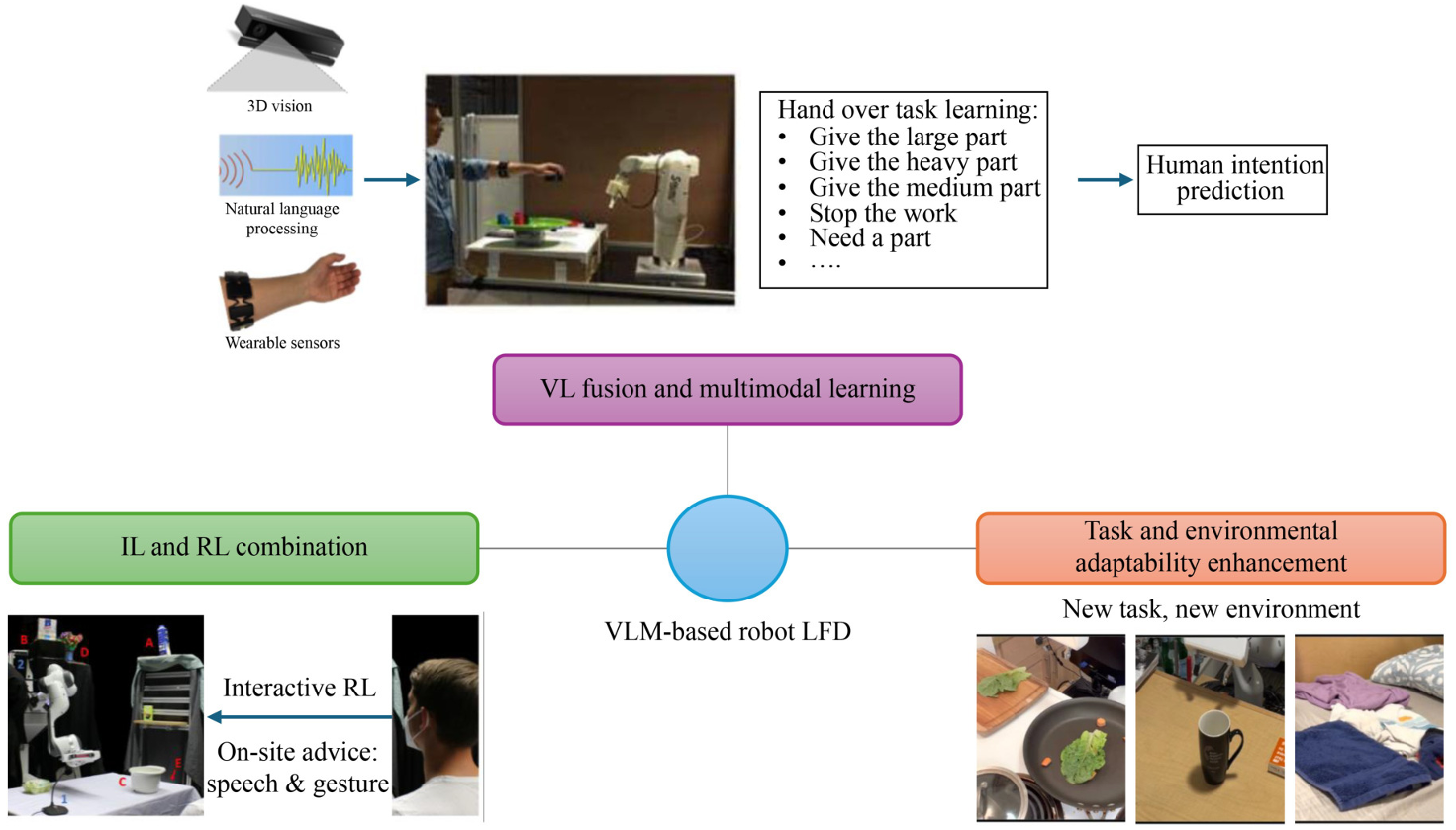
視覺語言融合與多模態學習
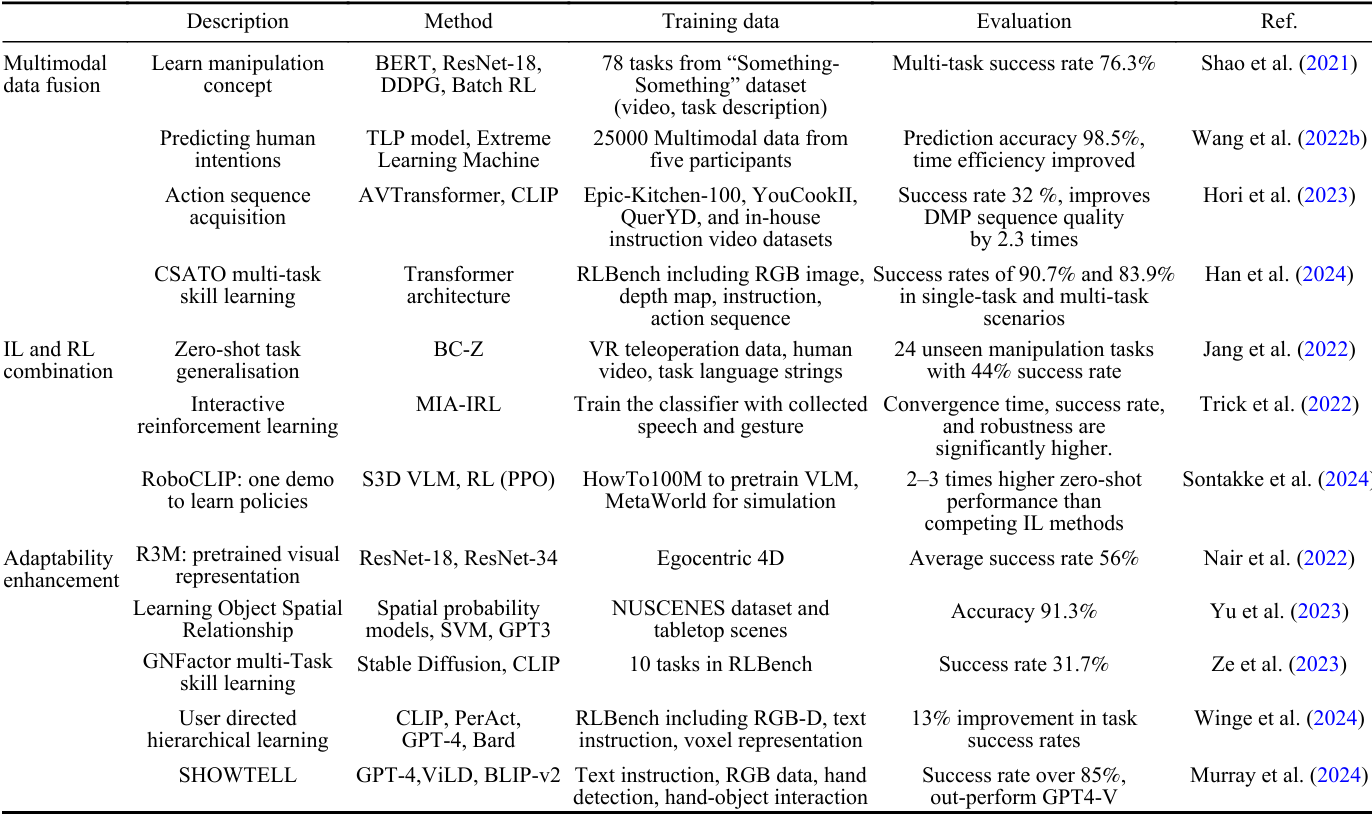
視覺-語言融合和多模態學習通過整合視覺和語言信息,增強了機器人在復雜任務中的理解和執行能力。
- 方法:通過結合視覺和語言輸入,機器人能夠更好地理解任務場景和人類指令。這種方法通常涉及使用深度神經網絡來提取特征,并在共享的特征空間中對齊這些特征。
- 應用:Shao et al.(2021)通過結合自然語言指令和視覺輸入,提高了機器人在復雜操作任務中的泛化能力和學習效率。Wang et al.(2022b)通過多模態數據融合,提高了機器人在手遞任務中預測人類意圖的準確性。
模仿學習(IL)與強化學習(RL)的結合
模仿學習和強化學習的結合通過利用人類演示和強化學習算法,顯著提升了機器人的任務泛化能力和零樣本學習能力。
- 方法:模仿學習使機器人能夠快速從人類演示中學習復雜行為,而強化學習則通過試錯來優化這些行為。通過結合這兩種方法,機器人能夠在多種場景中表現出色。
- 應用:Jang et al.(2022)通過結合多語言句子編碼器和強化學習,實現了在未見任務中的零樣本任務泛化。Trick et al.(2022)通過結合多模態建議的貝葉斯融合,提高了機器人在任務中的收斂速度和魯棒性。
任務和環境適應性的增強
通過視覺-語言模型,機器人可以在學習和執行任務時更好地適應不同的環境和任務需求。
- 方法:通過學習空間關系和概率模型,機器人能夠更準確地執行任務。這種方法通常涉及使用深度學習模型來提取和理解空間信息。
- 應用:Nair et al.(2022)通過預訓練的視覺表示模型,提高了機器人在未見環境中的任務成功率。Yu et al.(2023)通過學習對象的空間關系,提高了機器人在復雜環境中的任務執行能力。
面臨挑戰與未來研究方向
數據和計算高效的訓練及部署
VLMs在實際制造場景中的預訓練和部署面臨顯著的挑戰,主要是由于其高計算需求和廣泛的數據需求。
- 計算需求:VLMs的訓練和推理需要大量的計算資源,限制了其在實時應用中的可行性。
- 數據需求:高質量、標注的數據集在多樣化制造環境中難以獲取,增加了訓練成本和時間。
- 實時處理:VLMs在實時處理中常面臨延遲問題,影響其在動態環境中的應用。
- 魯棒性和可靠性:VLMs需要在實際生產中具備魯棒性和可靠性,以應對變化和模糊性。
未來研究方向包括開發高效的訓練策略、模型優化技術和魯棒數據收集方法,以提高VLMs在實際應用中的可行性和有效性。
動態環境中的視覺語言任務規劃
VLMs在任務規劃中的一個重要挑戰是其對靜態場景的關注,限制了其在動態環境中的應用。
- 實時任務規劃:在動態環境中進行實時任務規劃仍然是一個未解決的問題。
- SLAM技術:未來的研究可以探索結合同時定位與地圖構建(SLAM)技術,以提供實時環境更新,增強VLMs的動態適應能力。
- 計算效率:提高VLMs的計算效率,以處理實時數據和開發更復雜的動態任務規劃算法,是未來的關鍵研究方向。
實時3D場景重建和分割
盡管VLMs和LLMs在視覺-語言導航(VLN)方面取得了顯著進展,但其工業應用仍然受到限制。
- 實時更新:當前的導航規劃依賴于預建立的靜態地圖,無法滿足動態環境的需求。
- 低延遲重建:實現快速、低延遲的實時3D重建和分割是未來的研究方向。
- 輕量級網絡:結合大模型與輕量級網絡,通過動態跟蹤和人工操作員的輔助,實現高效的3D場景更新和適應性。
高精度的運動規劃
VLM和LLM在機器人操作中的應用主要集中在家庭任務上,工業應用較少。
- 精度不足:現有的VLM/LLM在工業應用中的運動規劃精度不足以滿足復雜任務的需求。
- 傳感器技術:通過集成先進的傳感器技術和反饋控制系統,可以提升運動規劃的精度。
- 平衡靈活性和精度:未來的研究應致力于在靈活性、泛化和精度之間找到平衡。
額外的模態和復雜指令理解
在VLM指導下的人機技能轉移中,整合額外的模態可以增強機器人的上下文理解和技能獲取能力。
- 多模態信息:結合觸覺反饋和其他感官信息,可以提升機器人在復雜任務中的表現。
- 復雜指令:現有的VLM在處理復雜或上下文依賴的指令方面存在局限,未來的研究應提升其理解能力。
動態任務適應和無監督評估
為了實現技能在仿真和現實應用之間的有效轉移,學習算法需要具備對現實世界變化的魯棒性。
- 動態適應:機器人需要具備在動態環境中自主適應的能力,結合域隨機化和增強現實進行訓練。
- 無監督評估:實施無監督評估機制,建立自我評估框架,減少對人類監督的依賴。
- 持續學習:通過持續學習機制,機器人可以基于新經驗和環境反饋自主改進性能。
總結
- 論文系統地回顧了VLMs在智能制造中人機協作中的最新進展和應用,展示了其在任務規劃、導航、操作和技能轉移中的潛力。
- 盡管VLMs在多個應用場景中表現出顯著的優勢,但仍面臨實時處理、計算需求和動態環境處理等挑戰。
- 未來的研究方向包括提高VLMs的可擴展性、開發更自然和直觀的人機交互機制,以及減少VLMs的數據和計算需求,以便在工業環境中大規模部署。
- 通過解決這些挑戰,VLMs有望在智能制造中發揮更大的作用,推動制造業的智能化和自動化。







)


)


)

——通過FFmpeg命令使用RTP發送TS流)
窗口表面)


)