檢索增強生成(RAG):提升大型語言模型能力的全新思路
隨著人工智能應用的不斷深入發展,如何讓大型語言模型(LLM)具備更強的上下文理解和實時響應能力成為了關鍵問題。檢索增強生成(Retrieval-Augmented Generation,RAG)正是在這一背景下應運而生的技術,它巧妙地結合了外部知識檢索和生成模型的優點,極大地拓展了 LLM 的應用邊界。
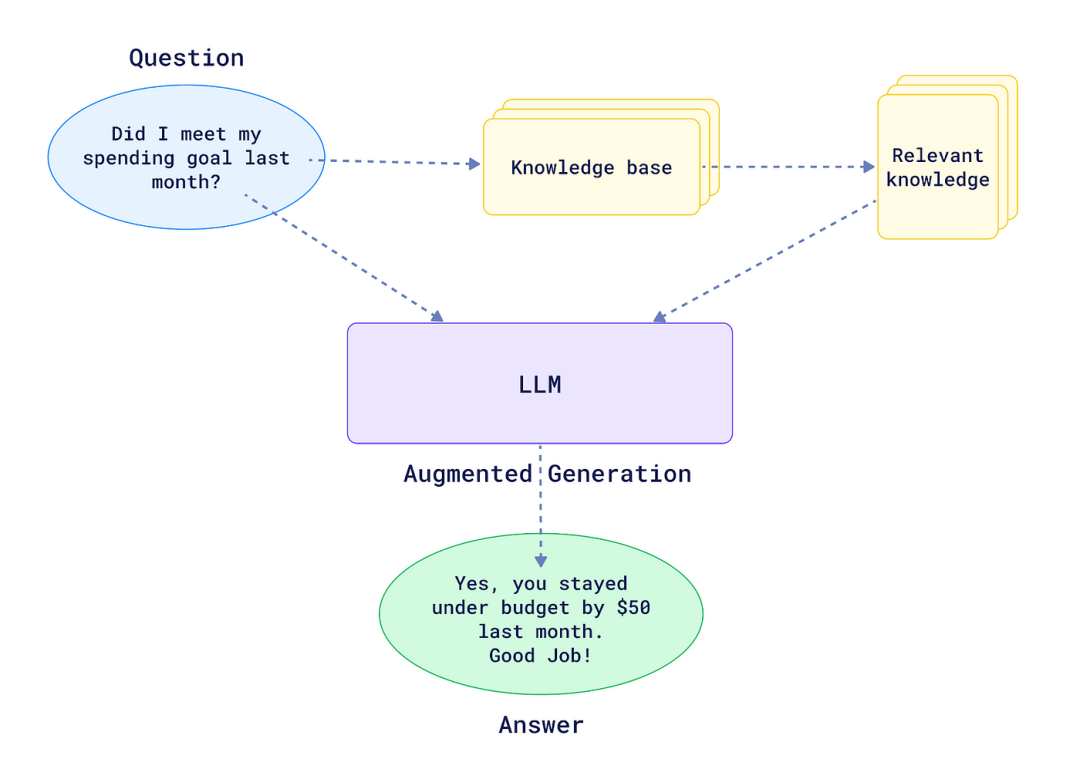
RAG 工作原理概覽
RAG 框架的核心思路是:先從龐大的知識庫中抽取與當前任務密切相關的信息,再將這些信息融入到生成模型的輸入中,最終輸出更為準確且富有上下文感知的答案。這樣一來,模型不僅能突破自身訓練數據的時間限制,還能有效降低生成內容出現“幻覺”現象的風險。
為什么不直接使用 LangChain?
雖然 LangChain 是搭建 LLM 應用的極佳工具,但它并不能完全替代 RAG。實際上,LangChain 常常被用來構建 RAG 系統。與單純依賴 LangChain 不同,RAG 能帶來如下幾大優勢:
- 外部知識接入:通過實時檢索領域內最新或特定的信息,RAG 能補充模型知識盲區。
- 準確性提升:利用檢索結果作為生成依據,有效減少模型輸出錯誤信息的幾率。
- 定制化能力:針對不同數據集和領域,RAG 能提供更為精準的定制響應。
- 信息溯源:借助檢索過程,生成結果的依據更加透明,便于審計和追蹤。
因此,LangChain 更多的是作為實現 RAG 的工具箱,而 RAG 則代表了提升模型輸出質量的一種更系統的技術策略。
GitHub 上的十大 RAG 框架
接下來,我們將探討 GitHub 上目前最受關注的十大 RAG 框架。每個框架都有其獨到之處,適合不同場景下的人工智能應用構建需求。
1. Haystack
GitHub星級:20.1k

Haystack 是一個高度模塊


)

![[leetcode]2685. 統計完全連通分量的數量](http://pic.xiahunao.cn/[leetcode]2685. 統計完全連通分量的數量)
——使用Langchain agents構建Gradio UI)

)



及其應用場景)





![Muduo網絡庫實現 [三] - Socket模塊](http://pic.xiahunao.cn/Muduo網絡庫實現 [三] - Socket模塊)

(java)合并區間)