本專欄通過檢索增強生成(RAG)應用的視角來學習大語言模型(LLM)。
本系列文章
- 簡介
- 數據準備(本文)
- 句子轉換器
- 向量數據庫
- 搜索與檢索
- 大語言模型
- 開源檢索增強生成
- 評估
- 大語言模型服務
- 高級檢索增強生成 RAG

如上圖所示,是檢索增強生成(RAG)的數據準備流程
在上一篇文章中,我們深入探討了檢索增強生成(RAG)流程,全面了解了它的各個組成部分。
任何機器學習應用的初始階段都需要進行數據準備。這包括建立數據攝取流程以及對數據進行預處理,使其與推理流程兼容。
在本文中,我們將把注意力轉向檢索增強生成(RAG)的數據準備方面。目標是有效地組織和構建數據結構,確保在我們的應用程序中能夠以最佳性能找到答案。
下面讓我們深入了解細節。
1. 步驟一:數據攝取
構建一個用戶友好的聊天機器人,始于明智的數據選擇。這篇博客將探討如何為成功的語言模型(LLM)應用有效地收集、管理和清理數據。
- 明智選擇:確定數據源,從門戶網站到應用程序編程接口(API),并設置一個推送機制,以便為你的大語言模型應用持續更新數據。
- 數據治理至關重要:預先實施數據治理政策。對文檔來源進行審核和編目,編輯掉敏感數據,并為上下文訓練奠定基礎。
- 質量檢查:評估數據的多樣性、規模和噪聲水平。質量較低的數據集會使回復質量下降,因此需要一個早期分類機制。
- 保持領先:即使在快節奏的大語言模型開發中,也要堅持數據治理。這可以降低風險,并確保可擴展、穩健的數據提取。
- 實時清理:從諸如Slack這樣的平臺獲取數據?實時過濾掉噪聲、拼寫錯誤和敏感內容,以打造一個干凈、有效的大語言模型應用。
2. 步驟二:數據清洗
我們文件的每一頁都會轉換為一個文檔對象,并且有兩個基本組成部分:頁面內容(page_content)和元數據(metadata)。
頁面內容展示了直接從文檔頁面提取的文本內容。
元數據是一組至關重要的附加詳細信息,比如文檔的來源(它所源自的文件)、頁碼、文件類型以及其他信息要點。元數據在發揮其作用并生成有深刻見解的答案時,會記錄它所利用的特定來源。

更多內容:Data Loading
為了實現這一點,我們利用強大的工具,如數據加載器(Data Loaders),這些工具由像LangChain和Llamaindex這樣的開源庫提供。這些庫支持各種格式,從PDF和CSV到HTML、Markdown,甚至是數據庫。
!pip install pypdf
!pip install langchain
# 對于PDF文件,我們需要從langchain框架中導入PyPDFLoader
from langchain_community.document_loaders import PyPDFLoader# 對于CSV文件,我們需要導入csv_loader
# 對于Doc文件,我們需要導入UnstructuredWordDocumentLoader
# 對于文本文檔,我們需要導入TextLoaderfilePath = "/content/A_miniature_version_of_the_course_can_be_found_here__1701743458.pdf"
loader = PyPDFLoader(filePath)
# 加載文檔
pages = loader.load_and_split()
print(pages[0].page_content)
這種方法的一個優點是可以通過頁碼來檢索文檔。
3. 步驟三:分塊

3.1. 為什么要分塊?
在應用程序領域中,關鍵在于你如何處理數據——無論是Markdown文件、PDF文件還是其他文本文件。想象一下:你有一個龐大的PDF文件,并且你渴望就其內容提出問題。問題在于,傳統的將整個文檔和你的問題一股腦拋給模型的方法并不管用。為什么呢?嗯,讓我們來談談模型上下文窗口的局限性。
以GPT-3.5 及其類似模型為例。可以把上下文窗口想象成窺視文檔的一個窗口,通常只限于一頁或幾頁的內容。那么,一次性共享整個文檔呢?不太現實。但是別擔心!
訣竅在于對數據進行分塊。將其分解為易于處理的部分,只將最相關的分塊發送給模型。這樣,你就不會讓模型不堪重負,并且能夠獲得你渴望的精確見解。
通過將我們的結構化文檔分解為可管理的分塊,我們使大語言模型能夠以無與倫比的效率處理信息。不再受頁面限制的約束,這種方法確保關鍵細節不會在處理過程中丟失。
3.2. 分塊前的考慮因素
- 文檔的結構和長度:
- 長文檔:書籍、學術文章等。
- 短文檔:社交媒體帖子、客戶評論等。
- 嵌入模型:分塊大小決定了應該使用哪種嵌入模型。
- 預期查詢:應用場景是什么?
3.3. 分塊大小
- 小塊大小:例如:單個句子 → 生成時的上下文信息較少。
- 大塊大小:例如:整頁、多個段落、整個文檔。在這種情況下,分塊涵蓋更多信息,這可以通過更多的上下文來提高生成的有效性。
3.3.1. 選擇分塊大小
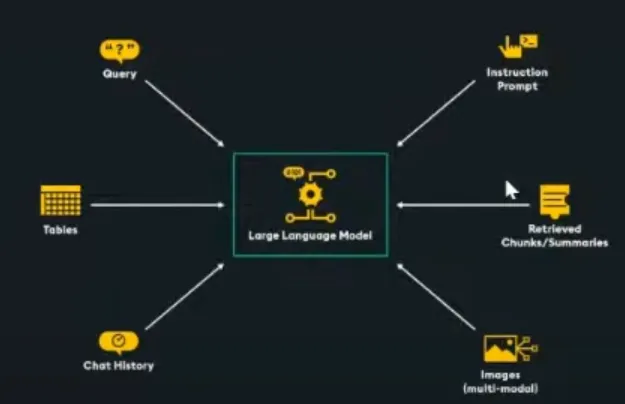
- 大語言模型上下文窗口:對可以輸入到大語言模型的數據量有限制。
- 前K個檢索到的分塊:假設大語言模型有一個10,000個Token的上下文窗口大小,我們為給定的用戶查詢預留大約1000個Token,為指令提示和聊天記錄預留2000個Token,那么只剩下7000個Token用于其他任何信息。假設我們打算將K = 10,即前10個分塊傳遞給大語言模型,這意味著我們將剩余的7000個Token除以總共10個分塊,那么每個分塊的最大大小約為700個Token。
- 分塊大小范圍:下一步是選擇一系列可能的分塊大小進行測試。如前所述,選擇應考慮內容的性質(例如,短消息或長篇文檔)、你將使用的嵌入模型及其能力(例如,標記限制)。目標是在保留上下文和保持準確性之間找到平衡。首先探索各種分塊大小,包括較小的分塊(例如,128或256個Token)以捕獲更精細的語義信息,以及較大的分塊(例如,512或1024個Token)以保留更多上下文。
- 評估每個分塊大小的性能:要測試各種分塊大小,你可以使用多個索引,或者使用具有多個命名空間的單個索引。使用具有代表性的數據集,為你想要測試的分塊大小創建嵌入,并將它們保存在你的索引(或多個索引)中。然后,你可以運行一系列查詢,通過這些查詢評估質量,并比較各種分塊大小的性能。這很可能是一個迭代過程,你針對不同的查詢測試不同的分塊大小,直到你能夠確定適合你的內容和預期查詢的性能最佳的分塊大小。
高上下文長度的限制:由于Transformer模型的自注意力機制,高上下文長度可能會導致時間和內存呈二次方增加。
在LlamaIndex發布的這個例子中,你可以從下面的表格中看到,隨著分塊大小的增加,平均響應時間會有小幅上升。有趣的是,平均忠實度似乎在分塊大小為1024時達到峰值,而平均相關性隨著分塊大小的增加持續提高,也在分塊大小為1024時達到峰值。這表明分塊大小為1024可能在響應時間和回復質量(以忠實度和相關性衡量)之間達到最佳平衡。

3.4. 分塊方法
有不同的分塊方法,并且每種方法可能適用于不同的情況。通過研究每種方法的優缺點,我們的目標是確定應用它們的合適場景。
3.4.1. 固定大小分塊
我們決定每個分塊中的標記數量,并可選擇添加重疊部分以確保效果。為什么要重疊呢?是為了確保語義上下文的豐富性在各個分塊之間保持完整。
為什么選擇固定大小呢?在大多數情況下,這是最佳選擇。它不僅計算成本低,節省處理能力,而且使用起來也很方便。無需復雜的自然語言處理庫,只需用固定大小的分塊優雅地分解你的數據即可。
以下是使用LangChain進行固定大小分塊的示例:
text = "..." # 你的文本
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(separator = "\n\n",chunk_size = 256,chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
3.4.2. “上下文感知”分塊
這些是一組利用我們正在分塊的內容的特性,并對其應用更復雜分塊的方法。以下是一些示例:
3.4.2.1. 句子分割
正如我們之前提到的,許多模型針對嵌入句子級別的內容進行了優化。自然地,我們會使用句子分塊,并且有幾種方法和工具可用于實現這一點,包括:
- 簡單分割:最直接的方法是按句號(“.”)和換行符分割句子。雖然這可能快速且簡單,但這種方法不會考慮所有可能的邊界情況。這是一個非常簡單的示例:
text = "..." # 你的文本
docs = text.split(".")
- NLTK:自然語言工具包(NLTK)是一個流行的用于處理人類語言數據的Python庫。它提供了一個句子標記器,可以將文本分割成句子,有助于創建更有意義的分塊。例如,要將NLTK與LangChain一起使用,可以執行以下操作:
text = "..." # 你的文本
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
docs = text_splitter.split_text(text)
- spaCy:spaCy是另一個用于自然語言處理任務的強大Python庫。它提供了一種復雜的句子分割功能,可以有效地將文本分割成單獨的句子,從而在生成的分塊中更好地保留上下文。例如,要將spaCy與LangChain一起使用,可以執行以下操作:
text = "..." # 你的文本
from langchain.text_splitter import SpacyTextSplitter
text_splitter = SpaCyTextSplitter()
docs = text_splitter.split_text(text)
3.4.2.2. 遞歸分塊
來認識一下我們的秘密武器:LangChain的RecursiveCharacterTextSplitter。這個多功能工具可以根據選定的字符優雅地分割文本,同時保留語義上下文。想想雙換行符、單換行符和空格——它就像把信息雕琢成易于理解的、有意義的部分。
它是如何工作的呢?很簡單。只需傳入文檔并指定所需的分塊長度(假設為1000個單詞)。你甚至可以微調分塊之間的重疊部分。
以下是如何使用LangChain進行遞歸分塊的示例:
text = "..." # 你的文本
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(# 設置一個非常小的分塊大小,僅用于演示。chunk_size = 256,chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
3.4.2.3. 特殊分塊
Markdown和LaTeX是你可能會遇到的兩種結構化和格式化內容的示例。在這些情況下,你可以使用特殊的分塊方法,在分塊過程中保留內容的原始結構。
- Markdown:Markdown是一種常用于格式化文本的輕量級標記語言。通過識別Markdown語法(例如,標題、列表和代碼塊),你可以根據其結構和層次結構智能地分割內容,從而得到語義更連貫的分塊。例如:
from langchain.text_splitter import MarkdownTextSplitter
markdown_text = "..."
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])
- LaTeX:LaTeX是一種常用于學術論文和技術文檔的文檔準備系統和標記語言。通過解析LaTeX命令和環境,你可以創建尊重內容邏輯組織(例如,章節、子章節和方程式)的分塊,從而得到更準確和上下文相關的結果。例如:
from langchain.text_splitter import LatexTextSplitter
latex_text = "..."
latex_splitter = LatexTextSplitter(chunk_size=100, chunk_overlap=0)
docs = latex_splitter.create_documents([latex_text])
3.5. 多模態分塊

- 從文檔中提取表格和圖像:使用LayoutPDFReader、Unstructured等工具。提取的表格和圖像可以用標題、描述和摘要等元數據進行標記。
- 多模態方法:
- 文本嵌入:總結圖像和表格。
- 多模態嵌入:使用可以處理原始圖像的嵌入模型。
4. 步驟四:Tokenization 標記化

最常用標記化方法總結
標記化包括將短語、句子、段落或整個文本文檔分割成更小的單元,例如單個單詞或術語。在本文中,我們將了解主要的標記化方法以及它們目前的應用場景。我建議你也查看一下Hugging Face制作的這個標記器總結,以獲取更深入的指南。
4.1. 詞級標記化 Word-Level Tokenization
詞級標記化包括將文本分割成單詞單元。為了正確地進行標記化,需要考慮一些注意事項。
- 空格和標點符號標記化:
將文本分割成較小的塊比看起來要難,并且有多種方法可以做到這一點。例如,讓我們看一下下面的句子:
“Don't you like science? We sure do.”
對這段文本進行標記化的一種簡單方法是按空格分割,這將得到:
["Don't", "you", "like", "science?", "We", "sure", "do."]
如果我們看一下標記“science?”和“do.”,我們會注意到標點符號與單詞“science”和“do”連在一起,這并不理想。我們應該考慮標點符號,這樣模型就不必學習一個單詞及其后面可能出現的每個標點符號的不同表示形式,否則模型必須學習的表示形式數量會激增。
考慮標點符號后,對我們的文本進行標記化將得到:
["Don", "'", "t", "you", "like", "science", "?", "We", "sure", "do", "."]
- 基于規則的標記化:
前面的標記化方法比單純基于空格的標記化要好一些。然而,我們可以進一步改進標記化處理“Don't”這個單詞的方式。“Don't”代表“do not”,所以用類似于["Do", "n't"]這樣的方式進行標記化會更好。其他一些特定規則可以進一步改進標記化效果。
然而,根據我們應用于文本標記化的規則不同,對于相同的文本會生成不同的標記化輸出。因此,只有當你向預訓練模型輸入的內容是使用與訓練數據標記化相同的規則進行標記化時,預訓練模型才能正常運行。
- 詞級標記化的問題:
詞級標記化對于大規模文本語料庫可能會導致問題,因為它會生成非常大的詞匯表。例如,Transformer XL語言模型使用空格和標點符號標記化,導致詞匯表大小達到267,000。
由于詞匯表如此之大,模型的輸入和輸出層有一個巨大的嵌入矩陣,這增加了內存和時間復雜度。作為參考,Transformer模型的詞匯表大小很少會超過50,000。
4.2. 字符級標記化 Character-Level Tokenization
那么,如果詞級標記化不可行,為什么不直接對字符進行標記化呢?
盡管字符級標記化會極大地降低內存和時間復雜度,但它會使模型更難學習到有意義的輸入表示。例如,學習字母“t”的一個有意義且與上下文無關的表示,要比學習單詞“today”的與上下文無關的表示難得多。
因此,字符級標記化往往會導致性能下降。為了兼顧兩者的優點,Transformer模型通常會使用一種介于詞級和字符級標記化之間的混合方法,稱為子詞標記化。
4.3. 子詞標記化 Subword Tokenization
子詞標記化算法基于這樣一個原則:常用詞不應被分割成更小的子詞,而罕見詞則應被分解為有意義的子詞。
例如,“annoyingly”可能被認為是一個罕見詞,可以分解為“annoying”和“ly”。“annoying”和“ly”作為獨立的子詞出現的頻率會更高,同時,“annoyingly”的意思通過“annoying”和“ly”的組合含義得以保留。
除了使模型的詞匯表大小合理之外,子詞標記化還能讓模型學習到有意義的、與上下文無關的表示。此外,子詞標記化可用于處理模型從未見過的單詞,方法是將它們分解為已知的子詞。
現在讓我們來看看幾種不同的子詞標記化方法。
字節對編碼(Byte-Pair Encoding: BPE)
字節對編碼(BPE)依賴于一個預標記器,該預標記器將訓練數據分割成單詞(例如像GPT-2和RoBERTa中使用的基于空格的標記化方法)。
在預標記化之后,BPE創建一個基礎詞匯表,該詞匯表由語料庫中唯一單詞集合中出現的所有符號組成,并學習合并規則,以便從基礎詞匯表中的兩個符號形成一個新符號。這個過程會不斷迭代,直到詞匯表達到所需的大小。
詞塊(WordPiece)
用于BERT、DistilBERT和ELECTRA的詞塊方法與BPE非常相似。WordPiece首先將詞匯表初始化為包含訓練數據中出現的每個字符,然后逐步學習一定數量的合并規則。與BPE不同的是,WordPiece不會選擇最頻繁出現的符號對,而是選擇一旦添加到詞匯表中就能使訓練數據出現概率最大化的那個符號對。
直觀地說,WordPiece與BPE略有不同,因為它會評估合并兩個符號所帶來的損失,以確保這樣做是值得的。
一元語法(Unigram)
與BPE或WordPiece不同,一元語法(Unigram)將其基礎詞匯表初始化為大量的符號,然后逐步削減每個符號,以獲得一個較小的詞匯表。例如,基礎詞匯表可以對應于所有預標記化的單詞和最常見的子字符串。Unigram通常與SentencePiece一起使用。
句子片段(SentencePiece)
到目前為止描述的所有標記化算法都有一個相同的問題:它們都假定輸入文本使用空格來分隔單詞。然而,并非所有語言都使用空格來分隔單詞。
為了從根本上解決這個問題,SentencePiece將輸入視為一個原始輸入流,因此將空格也包含在要使用的字符集合中。然后,它使用BPE或Unigram算法來構建合適的詞匯表。
使用SentencePiece的模型示例包括ALBERT、XLNet、MarianMT和T5。
OpenAI標記化可視化:https://platform.openai.com/tokenizer
結論
在這篇博客中,我們探討了檢索增強生成(RAG)應用程序的數據準備過程,強調了為實現最佳性能進行高效的數據結構化。它涵蓋了將原始數據轉換為結構化文檔、創建相關的數據塊,以及子詞標記化等標記化方法。我們強調了選擇合適數據塊大小的重要性,以及對每種標記化方法的考量因素。這篇文章為根據特定應用需求定制數據準備工作提供了深刻見解。
鳴謝
在這篇博客文章中,我們匯集了來自各種來源的信息,包括研究論文、技術博客、官方文檔等。每個來源都在相應的圖片下方進行了適當的標注,并提供了來源鏈接。
以下是參考列表:
- https://dataroots.io/blog/aiden-data-ingestion
- https://www.pinecone.io/learn/chunking-strategies/
- https://www.youtube.com/watch?v=uhVMFZjUOJI&t=1209s
- https://medium.com/nlplanet/two-minutes-nlp-a-taxonomy-of-tokenization-methods-60e330aacad3
- https://medium.com/@vipra_singh/building-llm-applications-data-preparation-part-2-b7306d224245




】安全審計與日志管理:為電商平臺筑牢安全防線)


PHP入門學習)

)

)



)



