目錄
一.Dust3r
1.簡述
2.PointMap與ConfidenceMap
3.模型結構
4.損失函數
5.全局對齊
二.Mast3r
1.簡述
2.MASt3R matching
3.MASt3R sfm
匹配與標準點圖
BA優化?
三.Fast3r
1.簡述
2.模型結構
3.損失函數
三維重建是計算機視覺中的一個高層任務,包含了很多底層的計算機視覺技術。傳統的三維重建,如SFM(structure from motion),就像是一個系列的pipeline工程,包含了關鍵點提取、本質矩陣計算、三角化、相機位姿估計、稀疏重建、稠密重建等。
一.Dust3r
1.簡述
傳統的三維重建將任務拆解為了多個子問題,作者認為這樣的設定,存在幾個問題:
- 前一個子任務會把誤差累進到后一個子任務中,比如匹配的誤差就不可避免會給三角化帶來影響
- 后一個子任務的信息很難前饋到前一個子任務中,比如相機估計出來的位姿能夠用于重建,但重建后的結果卻很難前饋到估計位姿過程中去
而DUSt3R則完全不劃分任何子任務,輸入兩張圖像就直接通過網絡模型來端到端地計算3D點云。
DUSt3R(Dense Unconstrained Stereo 3D Reconstruction),在非標定、不含位姿信息的圖像上進行稠密三維重建。如下圖,相比傳統方法,DUSt3R從非約束的圖像集合中直接恢復出對應的相機坐標系下面的三維點位置信息。然后在三維點信息基礎上進行相機標定、深度估計、相機位姿估計、稠密三維重建等。DUSt3R利用數據驅動的方式,采用神經網絡的方法,直接從2D圖像對中估計3D點云信息,從而跳過了傳統三維重建方法中的提取特征點、特征點匹配、點云三角化等步驟。使得整個三維重建pipeline變得簡潔,僅僅包含了3D點云估計、全局對齊兩個步驟。

從2D圖像直接估計出3D點云信息,這讓重建技術有了新的角度。傳統的SFM,會先去構建圖像和圖像的2D對應關系,然后三角化獲得空間點云,然后利用其他圖像和已知圖像的2D-2D匹配關系,轉化為2D-3D匹配關系,使用PnP的方式進行求解。而現在,我們直接擁有了2D圖像對應的3D點云信息(相機坐標系下面),剩下的問題就是如何讓這些在各自相機坐標系下面的3D點云形成一個完整的場景表達。這就是Global Alignment需要完成的事情。
2.PointMap與ConfidenceMap
先來看一下DUSt3R的輸出格式,對于H*W*3的RGB圖像而言,最終會輸出一個H*W*3的PointMap和一個H*W的ConfidenceMap。其中ConfidenceMap非常好理解,就是每個像素對應的PointMap的置信度,一共有H*W個像素,所以ConfidenceMap的維度是H*W。
而PointMap則是每個RGB圖像的像素點對應的三維空間坐標,因為每個空間點是三維坐標,一共有H*W個像素,所以PointMap的維度是H*W*3。
PointMap的物理含義是,從光心與對應像素的組成的射線,遇到的最近的空間結構在相機坐標系中的坐標。但需要注意,這實際上隱含了所有被相機觀測的物體都是不透明物體這一假設。如下圖,在存在透明/半透明結構時,這時最近的3D點應該是半透玻璃,但實際上因為被半透玻璃遮蔽的物體有更顯著的特征,因為基于PointMap大概率無法很好的重建出這類結構。

3.模型結構

USt3R的功能是從2D圖像中恢復出相機坐標系下面的三維點。其輸入是兩張圖像,采用的是孿生網絡結構。首先,兩張圖像分別經過參數共享的ViT encoder,然后分別經過transformer decoder(利用cross attention來進行特征交互),隨后利用各自的head分別輸出點云和置信度。針對圖像1分支,輸出包括了圖像相同大小的置信度特征和圖像大小的點云![]() ,其坐標是在圖像1代表的camera的相機坐標系。而圖像2分支,輸出包括了圖像相同大小的置信度特征和圖像大小的點云?
,其坐標是在圖像1代表的camera的相機坐標系。而圖像2分支,輸出包括了圖像相同大小的置信度特征和圖像大小的點云?![]() ,其坐標同樣是圖像1代表的camera的相機坐標系。
,其坐標同樣是圖像1代表的camera的相機坐標系。
DUSt3R輸出的點云是從2D圖像中獲取的,因為單目相機的深度是不具有唯一性的,因此從兩張圖像中恢復出來的3D點云是不具備尺度信息的,也就是![]() 不具備實際的物理尺寸。
不具備實際的物理尺寸。
簡單來說,輸入的兩張圖像I1、I2會用同一個ViT模型進行編碼得到對應的F1、F2,然后基于transformer和cross-attention來融合兩幀的信息進行解碼,最后把所有解碼器的輸出用DPT head來融合并輸出最終每一幀圖像的PointMap與ConfidenceMap。(代碼里的head有linear和dpt兩種,先用linear進行低分辨率訓練,然后dpt在更高分辨率上訓練從而節省時間)

簡要模型概覽?
4.損失函數
損失函數由兩部分組成,第一部分是3D點空間距離,第二部分是置信度。
3D點距離損失
DUSt3R的損失函數包含兩個部分,一個是置信度得分,一個預測點云和真值點云在歐式空間的距離。這里值得一提的是真值點云的獲取。因為真值點云是在相機坐標下面,因此當我們有圖像對應的深度圖和相機的內參以后,我們可以采用公式![]() 獲取,其中?i,j?是圖像像素坐標值。而為了獲取到圖像2在camera1的像素坐標系下的點云真值,則需要借助camera1和camera2的位姿信息。也就是利用公式
獲取,其中?i,j?是圖像像素坐標值。而為了獲取到圖像2在camera1的像素坐標系下的點云真值,則需要借助camera1和camera2的位姿信息。也就是利用公式![]() 來獲取,其中?Pm,Pn?都是世界坐標系到相機坐標系的變換矩陣,?h?是普通坐標轉化為齊次坐標。因此,在構建訓練集的時候,我們就需要獲得圖像對應的相機內參、以及相機位姿信息,方便構建圖像對應的相機坐標系下的點云和在其他相機坐標系下的點云。
來獲取,其中?Pm,Pn?都是世界坐標系到相機坐標系的變換矩陣,?h?是普通坐標轉化為齊次坐標。因此,在構建訓練集的時候,我們就需要獲得圖像對應的相機內參、以及相機位姿信息,方便構建圖像對應的相機坐標系下的點云和在其他相機坐標系下的點云。
假設第j張圖像(只有兩張圖,所以j=1或2)的第i個像素在基準坐標系對應的真實空間點為![]() ,而預測出來的為
,而預測出來的為![]() ,那么計算3D回歸損失:
,那么計算3D回歸損失:

其中![]() ?是歸一化因子,表示3D點到原點的平均距離。上述loss只衡量了PointMap的3D點與真實3D點之間的誤差,但網絡還會輸出一個ConfidenceMap,還需要把置信度融合進loss里:
?是歸一化因子,表示3D點到原點的平均距離。上述loss只衡量了PointMap的3D點與真實3D點之間的誤差,但網絡還會輸出一個ConfidenceMap,還需要把置信度融合進loss里:

訓練損失函數
下圖是網絡的輸出結果,從左往右依次是原圖、深度圖、置信圖、重建結果。

網絡輸出結果
5.全局對齊
輸入了一個圖像集合,兩兩圖像能夠構建出很多圖像對,利用上面的DUSt3R網絡,能夠獲得對應的置信度和點云,通過置信度信息,能夠剔除那些兩張圖像重合度不夠的圖像對。
全局對齊的目標就是將所有的預測點云都統一到一個坐標系下面。因為網絡一次輸出的一對點云是在同一個相機坐標系下面,因此全局對齊部分需要去估計?N?個相機位姿和?N?個尺度因子,?N?表示圖像對的對數。通過優化公式可以看出,優化的目標是讓每個點云轉化到世界坐標系中的點云具有一致性,也就是歐式距離最小。
利用全局對齊獲得了世界坐標系下面的點云,進一步,通過公式![]() 可以估計出相機的位姿、內參、深度圖等信息。其中
可以估計出相機的位姿、內參、深度圖等信息。其中
![]() 表示第?n?張圖上的第?i,j?像素點對應的點云(世界坐標系下面)。以下是重建結果圖:從左往右依次是原圖、深度圖、置信圖、重建結果。
表示第?n?張圖上的第?i,j?像素點對應的點云(世界坐標系下面)。以下是重建結果圖:從左往右依次是原圖、深度圖、置信圖、重建結果。
作者指出,相比于傳統的BA(Bundle Adjustment)利用重投影,在2D圖像上進行誤差優化,本文的全局對齊是在3D空間中進行優化的,采用了標準的梯度下降法,能夠快速地收斂。
二.Mast3r
1.簡述
首先,提出了MASt3R,一種建立在最近發布的DUSt3R框架之上的3d感知匹配方法。通過附加一個新的頭部來增強 DUSt3R 網絡,輸出密集的局部特征,并使用額外的匹配損失進行訓練。進一步解決密集匹配的二次復雜度問題,其對于下游應用非常慢。引入一種快速相互匹配(reciprocal match)方案,它不僅可以將匹配速度提高幾個數量級,而且還具有理論保證,最后可以產生更好的結果,使其能夠處理高分辨率的圖像。第三,MASt3R在幾個絕對和相對的姿態定位基準上顯著優于最先進的性能。
MASt3R是對DUSt3R的改進,MASt3R其實分為了兩篇文章,一篇是MASt3R matching,基于DUSt3R的網絡主體結構,多了一些模塊用于兩幀之間的匹配;還有一篇是MASt3R sfm,這篇是基于MASt3R matching做的一個用于多圖sfm。因為MASt3R sfm是基于MASt3R matching的網絡結構并用到了里面一些NN算法,所以我們先來看MASt3R matching。
2.MASt3R matching
matching的網絡結構跟DUSt3R基本保持一致,藍色的部分是新增的模塊。比較明顯的是新增了一個head用來提取local feature,然后是多了兩個最鄰近匹配模塊用來構建匹配。

對于H*W*3的輸入圖像而言,最終除了會輸出一個H*W*3的PointMap和一個H*W的ConfidenceMap外,還會為每個像素生成一個長度為d的特征,也就是H*W*3的LocalFeature,也就是用神經網絡來提取特征。剩余的網絡部分與DUSt3R保持一致。
關于loss部分,MASt3R matching對DUStER的![]() 做了一點小改動,然后新增了匹配loss。
做了一點小改動,然后新增了匹配loss。
具體而言,MASt3R matching取消了不同的深度正則化項,直接用gt的平均深度![]()

?然后因為新增了一個用于匹配的head輸出,而希望每個像素點最多和另一張圖的一個像素點匹配,作者將這部分描述為infoNCE loss,假設gt的匹配點為![]() ,并記
,并記![]() 的輸出:
的輸出:

有了上述模型與Loss就可以訓練了,但是網絡的輸出還需要經過一些處理,才能得到需要的匹配關系。注意,網絡只輸出了PointMap和每個像素的LocalFeature,而期望得到的是兩個圖像之間的像素點級別的匹配,匹配相關的部分就是圖中新增的NN模塊。
作者在匹配時設計了一個新算法,先對兩個圖像對應的特征點進行降采樣,先得到圖像1的特征點對于圖像2的正向NN匹配,在從已經匹配上的圖像2特征點反向NN匹配到圖像1,能夠形成閉環的NN匹配關系便成為最終的匹配。一次迭代同時包含正向和反向NN匹配,通過這樣就能快速收斂。

到這matching還沒結束,還有一步優化,因為之前不是降采樣了嘛,降采樣之后的最鄰近不一定是真的最鄰近,所以還要回到原分辨率的圖像上去,重新分塊再來一遍匹配(無論是分塊還是降采樣肯定都比直接全局NN快得多)。這樣就得到了最終的匹配關系。

3.MASt3R sfm
看總覽下pipeline:

雖然看起來MASt3R sfm直接在pipeline里集成了多幀輸入,但是因為網絡從DUSt3R一脈相承仍然只能一次處理兩張圖像,只是MASt3R sfm確實在多幀輸入的處理方式上存在很多改進,效果也確實好很多。
MASt3R sfm是基于MASt3R matching的網絡結構來開展的,MASt3R sfm只用了MASt3R matching里encoder的輸出作為tokenFeature(注意不是head輸出的LocalFeature),而不需要像素級別的匹配關系。
MASt3R sfm也是像DUSt3R那樣,先基于重疊視角構建一個Graph,具體做法如下:
- 根據encoder輸出的tokenFeature,使用最遠點采樣算法(farthest point sampling, FPS)來選出N個關鍵幀(或控制幀,理解成聚類算法的中心點一樣東西),然后把這N個關鍵幀兩兩相連,構成
條邊
- 剩余的普通幀連接到最近的關鍵幀上,然后還會通過NN算法連接到最近的k個普通幀上去
在上述過程中計算特征的距離完全是基于tokenFeature,對tokenFeature白化(feature whitening)后計算二進制距離來實現的。而由于一個圖像不止一個特征,所以會采用ASMK算法計算相似度來描述兩張圖像重疊視野,也就是用ASMK相似度來描述兩張圖像是否接近。
這里使用encoder輸出而不是head的輸出作為feature的好處是顯而易見的:encoder的輸入只要一張圖像,所以每張圖像都過一遍encoder就行了,而encoder又是不可缺少的步驟,相當于提取特征沒有開銷。
也就是構建pair時用encoder輸出作為tokenFeature,而后續的匹配和優化則使用head輸出的LocalFeature。
匹配與標準點圖
通過上述共視圖計算兩兩pair的PointMap、ConfidenceMap和LocalFeature后,會首先使用MASt3R matching中提到NN算法來匹配一個pair中的2D-3D點(分別得到![]()
![]() ,其中
,其中![]() 表示一個pair中第i張到第j張圖的2D-3D匹配點對)。
表示一個pair中第i張到第j張圖的2D-3D匹配點對)。
但是從構建共視圖中就可以看出來,同一張圖像肯定不止參與一個pair的運算,這樣相當于一張圖像同時有好幾個PointMap,每個PointMap都可能有一定誤差,而且一對多這樣子也不方便后面計算,所以作者將一張圖像的所有PointMap合成為一個Canonical PointMap(姑且翻譯成標準點圖),其實就是PointMap對于置信度的加權平均(這里![]() 表示每個pair,
表示每個pair,![]() 是對應的置信度):
是對應的置信度):

BA優化?
回想一下,我們期望得到的輸出是3D點云,使用Canonical PointMap作為點云可以嗎?顯然不可以,首先多幀之間的Canonical PointMap不一定對齊,其次每幀估計出來的Canonical PointMap也不一定準確(比如不滿足針孔相機模型,所有2D-3D連線不一定能過光心)。
在DUSt3R里是僅對共視圖的連接關系進行多幀優化,相對而言確實比較粗糙。而在MASt3R里,首先會先固定Canonical PointMap來優化出一個盡可能滿足針孔相機模型約束的焦距,從而恢復出一個比較接近的相機內參矩陣,這個優化僅涉及自身的Canonical PointMap,所以跟pair什么的沒關系,如果圖片是不同相機拍的也可以為每個相機做單獨的優化:

然后來優化Canonical PointMap對于像素的重投影誤差,這會同時優化相機內參K和共視圖中pair連接的相對位姿(外參),這是使用3D點誤差來優化的。這里的
![]()
是把3D點投影到2D點映射,![]()

這里的c指的是pair中的匹配像素,qc是匹配置信度,可以由MASt3R對應的置信度加權得到。注意這個優化是把所有匹配作為內點來優化對應的Sim3變換,但是實際上不可能所有的匹配都是內點,所以作者又引入了一個用置信度加權的重投影誤差優化來盡量消除外點影響,這里的ρ(?)是一個魯棒核函數:
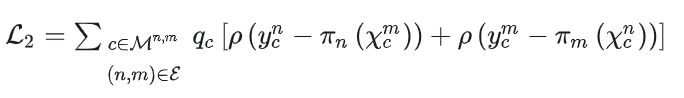

三.Fast3r
1.簡述
DUSt3R通過將成對重建問題轉化為點圖的回歸問題能夠直接從RGB圖像中預測三維結構。這代表了三維重建領域的一次根本性轉變,因為端到端可學習的解決方案不僅減少了流程中誤差的累積,還顯著簡化了操作。
然而,?DUSt3R的根本是重建兩幅圖像輸入的場景。為了處理多于兩幅圖像,DUSt3R需要計算O(N2)對點圖并執行全局對齊優化過程。這一過程計算成本高昂,隨著圖像數量的增加,其擴展性較差。?例如,在A100 GPU上僅處理48個視角就可能導致內存溢出(OOM)。另外,兩兩重建這一過程限制了模型的上下文信息,既影響了訓練期間的學習效果,也限制了推理階段的最終精度。從這個意義上說,DUSt3R與傳統SfM和MVS方法一樣,面臨著成對處理的瓶頸問題。
Fast3R是一種新型的多視圖重建框架,旨在克服上面提到的局限性。 FAST3R在Dust3R的基礎上,利用Transformer-based架構并行處理多個圖像,允許在單個前向傳遞中重建N個圖像。通過消除對順序或成對處理的需要,每個幀可以在重建期間同時關注輸入集中的所有其他幀,從而顯著減少錯誤累積 并且Fast3R推理的時間也大大減少。總的來說,Fast3R是一種基于Transformer的多視角點圖估計模型,無需全局后處理,在速度、計算開銷和可擴展性方面實現了顯著提升。模型性能隨著視角數量的增加而提升。
2.模型結構
如圖,輸入N個無序無pose的RGB圖像![]() ,Fast3R預測對應的pointmap
,Fast3R預測對應的pointmap![]() (
(![]() )以及confidence map?
)以及confidence map??
![]() ?來重建場景,不過這里的?
?來重建場景,不過這里的?![]() ?有兩類,一種是全局pointmap?
?有兩類,一種是全局pointmap?![]() ?,另一種是局部pointmap?
?,另一種是局部pointmap?![]() ?,confidence map也一樣,全局置信圖?
?,confidence map也一樣,全局置信圖?![]() ?,局部置信圖?
?,局部置信圖?![]() ?,比如,在MASt3R中,?
?,比如,在MASt3R中,?![]() ?是在視角1的坐標系下,?
?是在視角1的坐標系下,?![]() ?就是當前相機坐標系:
?就是當前相機坐標系:

Fast3R的結構設計來源于DUSt3R,包括三部分:image encoding, fusion transformer,
and pointmap decoding,并且處理圖片的方式是?并行?的。
(1)Image encoder
與DUST3R一樣,對于任意的圖片?![]() ?,encoder部分使用CroCo ViT里面的?
?,encoder部分使用CroCo ViT里面的?![]() ?,即分成patch提取特征,最后得到?
?,即分成patch提取特征,最后得到?![]() ?,其中?
?,其中?![]() ?,記作:
?,記作:
![]()
然后,在fusion transformer之前,往patch 特征H里面添加一維的索引嵌入(image index positional embeddings),索引嵌入幫助融合Transformer確定哪些補丁來自同一圖像,并且是識別?![]() ?的機制,而?
?的機制,而?![]() ?定義了全局坐標系。使模型能夠從原本排列不變的標記集中隱式地聯合推理所有圖像的相機pose。
?定義了全局坐標系。使模型能夠從原本排列不變的標記集中隱式地聯合推理所有圖像的相機pose。
(2)Fusion transformer
Fast3R 主要的計算在Fusion transformer過程中,我們使用的是與ViTB或 BERT類似的12層transformer,還可以按照比例放大,在此過程中,直接執行all-to-all的自注意力,這樣,Fast3R獲得了包含整個數據集的場景信息。
(3)pointmap decoding
Fast3R的位置編碼細節也很講究,這個細節大家感興趣可以仔細看看,可以達到訓練20張圖,推理1000張圖的效果。最后,使用DPT-Large的decoder得到點圖?![]() ?以及置信圖?
?以及置信圖?![]() ?,下面簡單介紹一下DPT-L。
?,下面簡單介紹一下DPT-L。
DPT探討了如何將視覺Transformer應用于密集預測任務(如語義分割、深度估計等)。通過引入層次化特征提取、多尺度特征融合以及專門的密集預測頭,改進了ViT架構,使其能夠有效處理高分辨率輸入并生成像素級預測。

3.損失函數
Fast3R的預測?![]() ?與GT的loss是DUST3R的一個廣義版本,即歸一化 3D 逐點回歸損失的置信加權:
?與GT的loss是DUST3R的一個廣義版本,即歸一化 3D 逐點回歸損失的置信加權:
![]()
首先,我們回顧DUST3R的點圖loss:

在此基礎上,使用confidence-ajusted loss:

我們的直覺是置信度加權有助于模型處理標簽噪聲。與DUST3R類似,我們在真實世界的掃描數據上進行訓練,這些數據通常包含底層點圖標簽中的系統性誤差。例如,在真實激光掃描中,玻璃或薄結構通常無法正確重建,而相機配準中的誤差會導致圖像與點圖標簽之間的錯位。
參考鏈接:
Dust3r:
https://zhuanlan.zhihu.com/p/686078541
https://zhuanlan.zhihu.com/p/28169401009
Mast3r:
MASt3R-CSDN博客
https://zhuanlan.zhihu.com/p/17982445115
Fast3r:
【論文筆記】Fast3R:前向并行muti-view重建方法-CSDN博客

)








)








