上篇:人工智能通識速覽一(機器學習)
人工智能通識速覽一(機器學習)(編輯中)-CSDN博客![]() https://blog.csdn.net/siper12138/article/details/146512068?sharetype=blogdetail&sharerId=146512068&sharerefer=PC&sharesource=siper12138&spm=1011.2480.3001.8118
https://blog.csdn.net/siper12138/article/details/146512068?sharetype=blogdetail&sharerId=146512068&sharerefer=PC&sharesource=siper12138&spm=1011.2480.3001.8118
目錄
二、神經網絡
1.參數優化
1.1.梯度下降及其變體
1.1.1 隨機梯度下降(SGD):
1.1.2 帶動量的隨機梯度下降(Momentum SGD):
1.1.3 Adagrad:
1.1.4 Adadelta:
1.1.5 RMSProp:
1.1.6 Adam:
1.2 學習率調整策略
固定學習率:
學習率衰減:
自適應學習率調整:
1.3 正則化技術
1.4 二階優化方法
2.經典的神經網絡
2.1. 感知機(Perceptron)
2.2 多層感知機(Multilayer Perceptron, MLP)
二、神經網絡
- 定義2:神經網絡通常指人工神經網絡(Artificial Neural Networks,ANNs),是一種模仿動物神經網絡行為特征,進行分布式并行信息處理的算法數學模型。它是受到人類大腦結構啟發而誕生的一種算法,通過調整內部大量節點之間相互連接的關系來處理信息。
- 基本結構3:神經網絡由輸入層、一個或多個隱藏層和輸出層組成。輸入層接收外部數據,隱藏層對數據進行處理和特征提取,輸出層給出最終的處理結果。數據從輸入層進入,經過隱藏層的層層處理,最終從輸出層輸出。每個層由多個神經元組成,神經元之間通過帶有權重的連接相互傳遞信息。
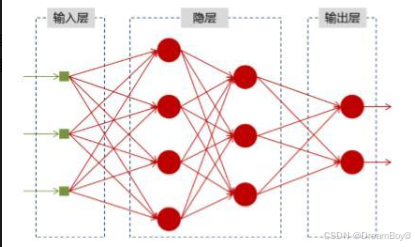
- 工作原理1:每個神經元接收來自其他神經元的輸入,并將這些輸入進行加權求和,再通過一個激活函數進行處理。如果輸出值超過給定閾值,神經元將被激活,并將數據傳遞到下一層。神經網絡通過調整神經元之間連接的權重來學習數據中的模式和規律,這個過程通常使用反向傳播算法來實現。在訓練過程中,根據預測結果與真實標簽之間的差異,反向傳播算法會計算出每個權重的梯度,并更新權重,使得網絡的預測結果逐漸接近真實值。
- 類型1:包括前饋神經網絡,數據僅沿一個方向從輸入流向輸出,是最常見的類型;卷積神經網絡,常用于圖像識別、模式識別和計算機視覺等領域,利用卷積操作提取圖像特征;循環神經網絡,具有反饋循環,適用于處理時間序列數據,如股票市場預測、自然語言處理中的文本生成等。
- 應用4:在計算機視覺領域,可用于圖像識別、目標檢測、圖像分割等,如自動駕駛汽車中的視覺識別、面部識別系統等;在語音識別領域,能將語音信號轉化為文字,用于虛擬助手、自動轉錄軟件等;在自然語言處理領域,可實現文本分類、情感分析、機器翻譯、問答系統等功能;還可用于推薦系統,根據用戶的行為和偏好進行個性化推薦。
1.參數優化
神經網絡的參數優化技術旨在調整神經網絡中的參數,以最小化損失函數,提高模型的性能和泛化能力。以下是一些常見的參數優化技術:
1.1.梯度下降及其變體
1.1.1 隨機梯度下降(SGD):
每次迭代使用一個小批量的數據來計算梯度并更新參數。它的計算速度快,但梯度估計可能存在噪聲,導致收斂過程有波動。通過調整學習率等超參數,可以在一定程度上控制收斂速度和穩定性。
1.1.2 帶動量的隨機梯度下降(Momentum SGD):
引入動量概念,將過去的梯度信息進行累積,以加速收斂并減少振蕩。可以理解為在參數更新時,不僅考慮當前的梯度,還考慮之前的梯度方向,使參數更新具有一定的慣性,能夠更快地朝著最優方向移動。
1.1.3 Adagrad:
自適應地調整每個參數的學習率,根據參數的歷史梯度信息來調整學習率的大小。對于頻繁更新的參數,學習率會逐漸變小;對于不常更新的參數,學習率會相對較大。這樣可以在訓練過程中自動調整不同參數的學習速度,適用于不同特征具有不同尺度的數據集。
1.1.4 Adadelta:
是 Adagrad 的改進版本,它通過使用一個移動窗口來計算梯度的平方和,而不是像 Adagrad 那樣累積所有歷史梯度的平方和,從而避免了學習率過度衰減的問題。同時,Adadelta 不需要手動設置學習率,具有更好的自適應能力。
1.1.5 RMSProp:
與 Adadelta 類似,也是通過對梯度的平方進行指數加權平均來調整學習率。它能夠有效緩解 Adagrad 中學習率急劇下降的問題,在處理非平穩目標函數時表現較好,常用于循環神經網絡(RNN)等模型的訓練。
1.1.6 Adam:
結合了 Momentum 和 RMSProp 的優點,不僅能夠自適應地調整學習率,還利用了動量來加速收斂。它對不同的參數分別進行自適應更新,同時能夠處理非平穩目標函數和稀疏梯度問題,是目前應用較為廣泛的一種優化算法。、
1.2 學習率調整策略
學習率(Learning Rate)是機器學習和深度學習中一個至關重要的超參數,它在模型訓練過程中起著控制模型參數更新步長的關鍵作用
固定學習率:
在整個訓練過程中使用固定的學習率。這種方法簡單,但可能無法在不同的訓練階段都達到最佳的收斂效果。通常需要通過多次試驗來選擇合適的固定學習率。
學習率衰減:
隨著訓練的進行,逐漸降低學習率。常見的衰減方式有線性衰減、指數衰減、余弦退火衰減等。例如,指數衰減按照一定的指數規律降低學習率,能夠在訓練前期快速收斂,后期逐漸減小學習率以避免錯過最優解。

自適應學習率調整:
根據模型的訓練情況自動調整學習率。例如,當損失函數在一定步數內沒有明顯下降時,降低學習率;或者根據驗證集上的性能指標來調整學習率。這種方法能夠更靈活地適應不同的訓練情況,但也需要更多的計算資源和時間來監控和調整學習率。
1.3 正則化技術
L1 和 L2 正則化:
在損失函數中添加正則化項,用于懲罰模型的復雜度。
L1 正則化會使模型的參數變得稀疏,即一些參數的值會變為 0,從而實現特征選擇的效果;

L2 正則化通過懲罰參數的平方和,使參數的值盡量小,能夠防止模型過擬合,提高模型的泛化能力。

Dropout:在訓練過程中隨機丟棄一部分神經元及其連接,以減少神經元之間的協同適應,防止模型過擬合。Dropout 可以看作是一種數據增強技術,每次訓練時都相當于從原始數據中采樣出不同的子網絡進行訓練,從而提高模型的魯棒性和泛化能力。


1.4 二階優化方法
牛頓法:
利用目標函數的二階導數(海森矩陣)來確定參數的更新方向,能夠更快地收斂到最優解。然而,計算海森矩陣及其逆矩陣的計算成本較高,并且在高維空間中可能存在數值穩定性問題,因此在大規模神經網絡訓練中較少直接使用。
擬牛頓法:
如 BFGS、L - BFGS 等算法,通過近似海森矩陣或其逆矩陣來避免直接計算二階導數,降低了計算復雜度。這些方法在一些小規模問題或特定場景下可能表現較好,但在處理大規模神經網絡時,由于內存需求和計算量仍然較大,也不是主流的優化方法。
2.經典的神經網絡
2.1. 感知機(Perceptron)
簡介:是最簡單的神經網絡形式,由美國學者弗蘭克?羅森布拉特在 1957 年提出。它是一種二分類的線性模型,可看作是一個具有單層神經元的前饋神經網絡。
結構:包含輸入層和輸出層,輸入層接收外界信息,輸出層根據輸入信息進行加權求和并通過激活函數(如階躍函數)進行處理,最終輸出分類結果。

學習策略



應用:早期用于圖像識別、字符識別等簡單的模式識別任務,雖然其功能有限,但為后續神經網絡的發展奠定了基礎。
2.2 多層感知機(Multilayer Perceptron, MLP)
簡介:在感知機的基礎上增加了隱藏層,形成了多層結構,能夠處理更復雜的非線性問題,是一種前饋神經網絡。
結構:由輸入層、一個或多個隱藏層和輸出層組成,層與層之間通過全連接的方式連接,即前一層的每個神經元與后一層的每個神經元都有連接,信息從輸入層依次向前傳播到輸出層,在傳播過程中通過激活函數對神經元的輸出進行非線性變換。
工作原理:


應用:廣泛應用于各種領域,如數據分類、回歸分析、語音識別、圖像識別等,是許多其他復雜神經網絡模型的基礎。
2.3 #激活函數#
激活函數:引入非線性因素,使多層感知機能夠學習復雜的非線性關系。常見的激活函數有:
Sigmoid 函數

特點:其函數圖像是一條 S 形曲線,能將任意實數映射到(0,1)區間,輸出值可看作概率,常用于二分類問題的輸出層。它具有平滑、可導的優點,但存在梯度消失問題,當輸入值過大或過小時,梯度趨近于 0,導致訓練速度慢,且輸出不以 0 為中心,會影響權重更新。
ReLU 函數(Rectified Linear Unit)

特點:計算簡單,收斂速度快,能有效緩解梯度消失問題。在輸入大于 0 時,梯度恒為 1,使神經元更容易被激活。但它也有缺點,如訓練時可能出現神經元死亡的情況,即某些神經元在訓練過程中一直輸出 0,不再更新權重。
Leaky ReLU 函數

特點:是 ReLU 函數的改進版,解決了 ReLU 函數在負半軸神經元死亡的問題。當x為負數時,Leaky ReLU 函數有一個較小的斜率α,使神經元在負半軸也能有一定的激活程度,從而避免神經元完全死亡。
Tanh 函數(Hyperbolic Tangent)

特點:函數圖像關于原點對稱,輸出值范圍在(?1,1)之間,與 Sigmoid 函數形狀相似,但克服了 Sigmoid 函數輸出不以 0 為中心的問題。不過,它同樣存在梯度消失問題,在深層網絡訓練中可能導致收斂困難。
Softmax 函數

特點:常用于多分類問題的輸出層,能將輸入向量轉換為表示各個類別的概率分布的輸出向量,輸出向量的每個元素都在(0,1)之間,且所有元素之和為 1。通過 Softmax 函數,可以得到每個類別被預測為正例的概率,從而進行分類決策。
ELU(Exponential Linear Unit)函數

特點:ELU 函數結合了 ReLU 函數和 Leaky ReLU 函數的優點,既能夠在正半軸保持線性,又在負半軸具有指數形式的平滑過渡。它可以使神經元的輸出均值更接近0,有助于加快訓練速度,并且在一定程度上緩解了梯度消失問題。同時,由于其在負半軸的取值范圍是[?α,0),可以避免神經元在訓練過程中出現死亡的情況。
SELU(Scaled Exponential Linear Unit)函數

特點:SELU 函數是在 ELU 函數的基礎上進行了縮放,具有自歸一化的特性。在使用 SELU 函數的神經網絡中,如果滿足一定的條件,網絡在訓練過程中能夠自動保持輸入數據的均值為0,方差為1,這有助于減少梯度消失和梯度爆炸的問題,使得深層神經網絡的訓練更加穩定和高效。
Swish 函數

特點:Swish 函數是一種平滑的、非單調的激活函數,它結合了 Sigmoid 函數的非線性特性和線性函數的一些優點。具有無上界有下界、平滑、非單調等性質,在一些深度學習任務中表現出了較好的性能,能夠提高模型的泛化能力和訓練速度。與 ReLU 函數相比,Swish 函數在負半軸也有一定的取值,不會像 ReLU 那樣直接將負半軸的值置為0,從而能夠更好地利用輸入信息。
Mish 函數
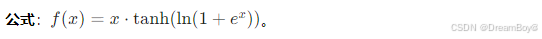
特點:Mish 函數是一種新型的激活函數,它具有連續可微、非單調等特性。Mish 函數在深層神經網絡中表現出了較好的性能,能夠提高模型的準確率和泛化能力。與 ReLU 函數和 Swish 函數相比,Mish 函數在不同的數據集和模型結構上可能具有更好的適應性,尤其在處理復雜的圖像和語音等數據時,能夠更好地提取特征,減少模型的過擬合現象。
GELU(Gaussian Error Linear Unit)函數

特點:GELU 函數是一種基于正態分布的激活函數,它根據輸入值的概率分布來調整神經元的輸出。與 ReLU 等激活函數相比,GELU 函數能夠更好地對輸入信息進行建模,尤其在處理具有不確定性的輸入數據時表現出更好的性能。它具有平滑、連續可微的特點,能夠使神經網絡的訓練更加穩定,在自然語言處理等領域的一些大型模型中得到了廣泛應用。
SiLU(Sigmoid - weighted Linear Unit)函數
 。
。
特點:SiLU 函數結合了線性函數和 Sigmoid 函數的特性,具有平滑的非線性變換能力。它在不同的深度學習任務中都表現出了較好的性能,能夠自適應地調整神經元的輸出,根據輸入的大小來決定是更接近線性變換還是更強烈的非線性變換,有助于模型更好地學習數據的內在特征,提高模型的表達能力。
Hard - Sigmoid 函數
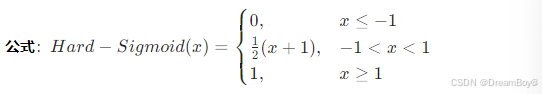
特點:Hard - Sigmoid 函數是 Sigmoid 函數的一種近似形式,它通過分段線性函數來逼近 Sigmoid 函數。與 Sigmoid 函數相比,Hard - Sigmoid 函數的計算更加簡單高效,不需要進行指數運算,因此在一些對計算資源和速度要求較高的場景中具有優勢,如在嵌入式設備或移動設備上的深度學習模型中可能會被采用。不過,由于它是分段線性的,其平滑性不如 Sigmoid 函數,可能會在一定程度上影響模型的性能,但在某些情況下可以通過適當的模型調整來彌補。
Hard - Swish 函數

特點:Hard - Swish 函數是 Swish 函數的一種近似形式,類似于 Hard - Sigmoid 函數與 Sigmoid 函數的關系。它通過簡單的線性運算和取最大值操作來近似 Swish 函數,計算復雜度較低,適合在資源受限的環境中使用。同時,它也保留了 Swish 函數的一些優點,如在一定程度上能夠自適應地調整神經元的激活程度,對模型的性能有一定的提升作用,在一些輕量級的深度學習模型中表現出了較好的效果。
2.4 卷積神經網絡(Convolutional Neural Network, CNN)
簡介:專門為處理具有網格結構數據(如圖像、音頻)而設計的神經網絡,由福島邦彥在 20 世紀 80 年代提出,在 2012 年 AlexNet 取得巨大成功后得到了廣泛關注和應用。
結構:包含卷積層、池化層和全連接層等。卷積層通過卷積核在數據上滑動進行卷積操作,提取數據的局部特征;池化層對卷積層的輸出進行下采樣,減少數據維度,同時保留重要特征;全連接層則將池化層的輸出進行分類或回歸等操作。
應用:在圖像識別、目標檢測、語義分割等計算機視覺領域取得了巨大的成功,也在自然語言處理等其他領域有一定的應用。
AlexNet
簡介:2012 年由 Alex Krizhevsky 等人提出,在當年的 ImageNet 大規模視覺識別挑戰賽(ILSVRC)中取得了顯著勝利,其 top - 5 錯誤率比第二名低了 10.8 個百分點,推動了深度學習在計算機視覺領域的復興。
模型結構:它是一個 8 層的卷積神經網絡,包含 5 個卷積層和 3 個全連接層,使用了 ReLU 激活函數,首次引入了數據增強、Dropout 等技術來防止過擬合,還使用了局部響應歸一化(LRN)層來提高模型的泛化能力。
影響和應用:證明了深度卷積神經網絡在大規模圖像分類任務上的強大能力,為后續的深度學習模型發展奠定了基礎,啟發了一系列更深層次、更復雜的神經網絡架構的出現,推動了計算機視覺領域的快速發展。
VGGNet
簡介:2014 年由牛津大學的 Visual Geometry Group 提出,在 ILSVRC 競賽中取得了優異成績,其網絡結構簡潔且具有很強的擴展性,加深網絡層數后性能有顯著提升。
模型結構:主要特點是使用了多個較小卷積核(如 3×3)的卷積層來代替較大卷積核的卷積層,通過不斷堆疊這些小卷積核的卷積層來增加網絡的深度,同時使用了多個全連接層進行特征分類,網絡結構規整,易于實現和理解。
影響和應用:VGGNet 的結構簡單且高效,為后來的深度學習模型設計提供了一種有效的范式,即通過增加網絡深度來提高模型性能。其預訓練模型在許多計算機視覺任務中被廣泛用作特征提取器,具有很好的通用性和遷移學習能力。
GoogLeNet(Inception - v1)
簡介:2014 年由谷歌公司的 Christian Szegedy 等人提出,在 ILSVRC 競賽中獲得冠軍,其創新的 Inception 模塊大大提高了網絡的性能,同時減少了模型的參數數量。
模型結構:引入了 Inception 模塊,該模塊通過并行使用不同大小的卷積核和池化操作,能夠捕捉不同尺度的圖像特征,有效地提高了網絡對圖像特征的提取能力。此外,網絡中還使用了全局平均池化層來代替全連接層,進一步減少了模型的參數數量,降低了過擬合的風險。
影響和應用:開創了使用多尺度卷積核并行提取特征的先河,為后續的模型設計提供了新的思路。其 Inception 模塊被廣泛應用于各種計算機視覺模型中,推動了計算機視覺領域對網絡結構設計的創新和發展。
ResNet
簡介:2015 年由何愷明等人提出,解決了隨著神經網絡層數增加而出現的梯度消失和退化問題,使得訓練極深的神經網絡成為可能,在 ILSVRC 競賽中取得了重大突破。
模型結構:引入了殘差連接(Residual Connection),通過將輸入直接跳過一些層連接到后面的層,使得網絡可以學習殘差函數,有效地緩解了梯度消失問題,同時也使得網絡能夠更好地訓練和優化。
影響和應用:ResNet 的提出極大地推動了深度學習在計算機視覺以及其他領域的發展,使得訓練非常深的神經網絡成為常態,為后續各種高性能模型的發展提供了基礎,許多先進的模型都借鑒了殘差連接的思想。
YOLO(You Only Look Once)
簡介:2015 年由 Joseph Redmon 等人提出的一種目標檢測算法,它將目標檢測任務看作是一個回歸問題,直接從圖像中預測出目標的類別和位置,大大提高了目標檢測的速度。
模型結構:將輸入圖像劃分為 S×S 的網格,每個網格負責預測 B 個邊界框和這些邊界框的置信度,以及 C 個類別概率。網絡結構簡單,由卷積層和全連接層組成,能夠快速地對圖像進行處理,實現實時的目標檢測。
影響和應用:YOLO 開創了基于深度學習的單階段目標檢測算法的先河,為實時目標檢測提供了一種有效的解決方案。在安防監控、自動駕駛、機器人視覺等需要快速檢測目標的領域有廣泛應用,并且啟發了一系列后續的單階段目標檢測算法的發展。
循環神經網絡(Recurrent Neural Network, RNN)
簡介:具有記憶功能的神經網絡,能夠處理序列數據,如文本、語音等。它的神經元之間存在反饋連接,使得網絡能夠對之前的信息進行記憶和利用,從而更好地處理序列中的長期依賴關系。
結構:由輸入層、隱藏層和輸出層組成,隱藏層的神經元在每個時間步都會接收當前的輸入和上一個時間步的隱藏狀態,并根據這些信息更新當前的隱藏狀態,然后輸出結果。常見的 RNN 變體有長短期記憶網絡(LSTM)和門控循環單元(GRU)。
應用:在自然語言處理領域的語言建模、機器翻譯、文本生成等任務,以及語音識別、時間序列預測等領域有廣泛應用。
長短期記憶網絡(Long - Short Term Memory, LSTM)
簡介:是一種特殊的循環神經網絡(RNN),由 Sepp Hochreiter 和 Jürgen Schmidhuber 于 1997 年提出,能夠有效地處理序列數據中的長期依賴問題。
模型結構:LSTM 的核心是記憶單元,它可以選擇性地記住和遺忘信息。通過輸入門、遺忘門和輸出門來控制信息的流動,能夠更好地捕捉序列中的長期依賴關系,避免了傳統 RNN 中梯度消失和爆炸的問題。
應用:在自然語言處理中,廣泛應用于語言建模、機器翻譯、文本生成等任務;在語音識別中,用于對語音序列進行建模,提高識別準確率;在時間序列預測中,能夠根據歷史數據預測未來趨勢。
門控循環單元(Gated Recurrent Unit, GRU)
簡介:也是一種循環神經網絡,由 Kyunghyun Cho 等人于 2014 年提出,是 LSTM 的一種變體,具有更簡單的結構,同時也能有效地處理序列數據中的長期依賴問題。
模型結構:GRU 主要包含更新門和重置門,更新門用于控制前一時刻的狀態信息有多少被保留到當前時刻,重置門用于控制對過去信息的遺忘程度。通過這兩個門來調節信息的流動,從而實現對長期依賴關系的建模。
應用:與 LSTM 類似,在自然語言處理、語音識別、時間序列預測等領域有廣泛應用,由于其結構相對簡單,計算效率較高,在一些對實時性要求較高的任務中表現出色。
Transformer
簡介:2017 年由 Ashish Vaswani 等人提出,最初用于機器翻譯任務,它摒棄了傳統的循環神經網絡(RNN)和卷積神經網絡(CNN),完全基于注意力機制,能夠并行計算,大大提高了訓練效率,并且在處理長序列數據時表現出了強大的能力。
模型結構:由編碼器和解碼器兩部分組成,編碼器負責將輸入序列編碼成一個固定長度的向量表示,解碼器則根據編碼器的輸出和之前生成的輸出序列來生成下一個輸出。其中,注意力機制是 Transformer 的核心,通過計算輸入序列中每個位置與其他位置之間的關聯程度,自適應地分配權重,從而更好地捕捉文本中的長程依賴關系。
應用:在自然語言處理領域引發了重大變革,不僅在機器翻譯中取得了顯著的成果,還廣泛應用于文本生成、問答系統、文本分類等各種自然語言處理任務中。此外,在計算機視覺等其他領域也開始得到應用和推廣,如視覺 Transformer(ViT)將 Transformer 應用于圖像分類任務,取得了很好的效果。
高效注意力機制改進版
FlashAttention:通過優化 GPU 內存的使用來減少內存讀寫次數,使 Transformer 在處理長文本序列時更快且更節省內存,訓練速度更快且能處理更長文本序列,提升了模型性能。
顯式稀疏 Transformer(Explicit Sparse Transformer):旨在解決自注意力機制提取不相關信息的問題,通過顯式選擇最相關片段,提高對全局上下文的注意力集中度,在自然語言處理和計算機視覺任務上具有性能優勢。
多查詢注意力(Multi - Query Attention):通過在所有不同的注意力 “頭” 之間共享鍵和值,大幅減小張量大小,降低了增量解碼的內存帶寬需求,能更快解碼且與基線相比質量下降輕微。
結構增強型 Transformer
Convolutional Transformers(Convs):在每一層之間嵌入一維卷積操作,結合了卷積神經網絡的局部特征提取能力和 Transformer 的全局建模能力,有助于提高模型對局部信息的處理能力,增強模型的特征提取效果。
Gated Linear Units(GLUs):利用門控線性單元控制信息流路徑,能夠自適應地調節信息在模型中的流動,有助于提高模型的表達能力和訓練效率。
Recurrent Neural Networks Integration:將 RNN 融入 Transformer 中,能夠更好地捕捉時間依賴關系,適用于處理具有長期時間序列特征的數據,如語音和視頻等。
基于 Transformer 架構的特定任務模型
ERNIE - Doc:一種基于遞歸 Transformer 的文檔級語言預訓練模型,通過回顧性饋送機制和增強的遞歸機制,能夠捕獲完整文檔的上下文信息,具有更長的有效上下文長度,適用于文檔級別的自然語言處理任務,如文檔分類、文檔摘要等。
CogView:一個具有 40 億參數的 Transformer 模型,結合了 VQ - VAE 標記器,用于解決通用領域中的文本到圖像生成問題,將自然語言處理與計算機視覺任務相結合,展示了 Transformer 在多模態任務中的應用潛力。
僅編碼器架構(Encoder - only)
BERT(Bidirectional Encoder Representations from Transformers):通過使用掩碼語言模型(MLM)和下一句預測(NSP)兩種預訓練任務,學習到雙向的上下文信息,在多種自然語言處理任務上取得突破性成果,如文本分類、問答系統、命名實體識別等。
RoBERTa(Robustly Optimized BERT Pretraining Approach):是對 BERT 的改進,通過調整訓練數據、訓練策略等,進一步提高了模型的性能和泛化能力,在多個自然語言處理任務上取得了更好的效果。
僅解碼器架構(Decoder - only)
GPT(Generative Pre - trained Transformer):通過預訓練大量文本數據,學習到豐富的語言知識和生成模式,采用單向語言模型的預訓練方式,根據已知前文預測下一個詞,具有強大的文本生成能力,可生成新聞報道、故事創作、代碼生成等高質量文本。
LLama(Large Language Model Meta):由 Meta 開發的大型語言模型,同樣基于 Decoder - only 架構,在大規模預訓練數據上進行訓練,具有出色的文本生成能力和語言理解能力,可用于多種自然語言處理任務,如對話系統、文本生成、知識問答等。
生成對抗網絡(Generative Adversarial Network, GAN)
簡介:由伊恩?古德費洛等人在 2014 年提出,是一種生成式模型,通過對抗訓練的方式學習數據的分布,從而生成新的數據樣本。
結構:包含生成器和判別器兩個部分。生成器的目標是生成與真實數據相似的樣本,判別器的目標是區分生成的樣本和真實樣本,兩者通過不斷地對抗訓練來提高各自的能力,最終達到一種平衡狀態,使得生成器能夠生成高質量的樣本。
應用:在圖像生成、圖像編輯、數據增強、半監督學習等領域有廣泛的應用,能夠生成逼真的圖像、視頻等內容,也可以用于數據擴充和模型訓練的輔助等。

:MPTS+Lconv+注意力集成機制的Transformer時間序列模型)


)






)




(A-D))


)