線程概念與控制(上)![]() https://blog.csdn.net/Small_entreprene/article/details/146464905?sharetype=blogdetail&sharerId=146464905&sharerefer=PC&sharesource=Small_entreprene&sharefrom=mp_from_link我們經過上一篇的學習,接下來,先來好好整理一下:
https://blog.csdn.net/Small_entreprene/article/details/146464905?sharetype=blogdetail&sharerId=146464905&sharerefer=PC&sharesource=Small_entreprene&sharefrom=mp_from_link我們經過上一篇的學習,接下來,先來好好整理一下:
對上篇的整理
線程的優點
線程在Linux當中就是根據進程模擬實現的,兩者在Linux當中都被稱為是輕量級進程,每個進程在自己的用戶空間當中,每個進程當中的線程只要有自己的獨立的地址空間,那么線程就有了對應的自己的資源了。
那么,線程的優點是哪些呢?
創建一個新線程的代價要比創建一個新進程小得多:
因為創建一個線程之前,一定是進程已經存在了,就是資源已經分配了,而線程只需要創建PCB和資源劃分就可以,所以代價當然就小了。
與進程之間的切換相比,線程之間的切換需要操作系統做的工作要少很多。(進程內的線程切換)
- 最主要的區別是線程的切換虛擬內存空間依然是相同的,但是進程切換是不同的。這兩種上下文切換的處理都是通過操作系統內核來完成的。內核的這種切換過程伴隨的最顯著的性能損耗是將寄存器中的內容切換出。(不需要將CR3寄存器的內容進行保存,頁表不用切換)
- 另外一個隱藏的損耗是上下文的切換會擾亂處理器的緩存機制。(最主要的影響原因)簡單的說,一旦去切換上下文,處理器中所有已經緩存的內存地址一瞬間都作廢了。還有一個顯著的區別是當你改變虛擬內存空間的時候,處理的頁表緩沖TLB(快表)會被全部刷新,這將導致內存的訪問在一段時間內相當的低效。但是在線程的切換中,不會出現這個問題,當然還有硬件cache。(進程切換會導致TLB和Cache失效,下次運行,需要重新緩存!)
線程占用的資源要比進程少很多:因為線程拿到的資源本身就是進程資源的一部分!
能充分利用多處理器的可并行數量:因為線程本質就是CPU進行調度的基本單位,當我們有多個CPU的時候,我們可以創建多線程,使用多線程,讓整個系統多CPU并行起來了!
在等待慢速I/O操作結束的同時,程序可執行其他的計算任務。(這個多進程也是可以實現的)
計算密集型(加密,解密,壓縮...使用CPU的)應用,為了能在多處理器系統(多CPU)上運行,將計算分解到多個線程中實現。
I/O密集型應用,為了提高性能,將I/O操作重疊。線程可以同時等待不同的I/O操作。
那是不是線程越多越好呢?
不是的,因為如果是一計算密集型的應用場景,CPU只有兩個的話,最合理的創建線程的個數就是兩個,有幾個CPU就創建幾個線程,只有2CPU,非要創建10個線程,那么在實際計算的時候,每一個CPU均攤的是5個,除了在做計算,還在做切換,切換的算力本來可以用在計算上,還創建那么多線程,反而將效率減慢了。(一個人可以帶兩份飯,沒必要兩個人一起排隊買),但是IO的話,就可以多創建一些,因為IO需要等待。
線程的缺點
性能損失:一個很少被外部事件阻塞的計算密集型線程往往無法與其他線程共享同一個處理器。如果計算密集型線程的數量比可用的處理器多,那么可能會有較大的性能損失,這里的性能損失指的是增加了額外的同步和調度開銷,而可用的資源不變。(是創建太多線程導致的缺點,當讓也是多進程的缺點)
健壯性降低:編寫多線程需要更全面更深入的考慮,在一個多線程程序里,因時間分配上的細微偏差或者因共享了不該共享的變量而造成不良影響的可能性是很大的,換句話說線程之間是缺乏保護的。
缺乏訪問控制:進程是訪問控制的基本粒度,在一個線程中調用某些OS函數會對整個進程造成影響。
編程難度提高:編寫與調試一個多線程程序比單線程程序困難得多。
只要我們代碼寫得好,這些問題就不是問題了😊
線程異常
- 單個線程如果出現除零,野指針問題導致線程崩潰,進程也會隨著崩潰:因為線程是進程的執行分支,線程出異常,就是進程出異常,所以就會觸發系統給進程發信號,殺掉該進程,而線程賴以生存的資源,空間,頁表...都是屬于進行申請的資源,進程都沒了,線程也早就沒了。
- 線程是進程的執行分支,線程出異常,就類似進程出異常,進而觸發信號機制,終止進程,進程終止,該進程內的所有線程也就隨即退出。
線程用途
- 合理的使用多線程,能提高CPU密集型程序的執行效率。
- 合理的使用多線程,能提高IO密集型程序的用戶體驗(如生活中我們一邊寫代碼一邊下載開發工具,就是多線程運行的一種表現)。
Linux進程VS線程
進程和線程
在Linux系統中,進程和線程是兩個核心概念,它們在操作系統中扮演著不同的角色。
-
進程是資源分配的基本單位。每個進程都有自己的地址空間和系統資源,如內存、文件描述符等。
-
線程是調度的基本單位。線程是進程中的一個執行流,是CPU調度和分派的基本單位。
線程共享進程數據,但也擁有自己的部分數據:
-
線程ID:每個線程都有一個唯一的標識符。
-
一組寄存器(大部分的)(線程的上下文數據:證明線程是被獨立調度的!!!):線程有自己的寄存器集合,用于存儲臨時數據和狀態信息。
-
棧(棧不就一個嗎?線程是一個動態的概念,需要入棧出棧進行臨時數據的保存,后面具體說):每個線程都有自己的棧,用于存儲函數調用時的局部變量和返回地址。
-
errno:線程有自己的錯誤號,用于記錄最近一次系統調用的錯誤。
-
信號屏蔽字:線程可以設置自己的信號屏蔽字,決定哪些信號可以被處理。
-
調度優先級:線程有自己的調度優先級,影響其在CPU上的調度順序。
進程的多個線程共享
同一地址空間,因此Text Segment、Data Segment都是共享的。如果定義一個函數,在各線程中都可以調用。如果定義一個全局變量,在各線程中都可以訪問。除此之外,各線程還共享以下進程資源和環境:
-
文件描述符表:所有線程共享相同的文件描述符表,可以訪問相同的文件。
-
每種信號的處理方式(SIG_IGN、SIG_DFL或者自定義的信號處理函數):所有線程共享相同的信號處理方式。
-
當前工作目錄:所有線程共享相同的當前工作目錄。
-
用戶id和組id:所有線程共享相同的用戶id和組id。
進程和線程的關系如下圖:

關于進程線程的問題
如何看待之前學習的單進程?具有一個線程執行流的進程:在單進程模型中,進程只有一個執行流,即只有一個線程。這種模型簡單,但缺乏并發能力。在多線程模型中,一個進程可以有多個線程,每個線程可以獨立執行,從而實現并發處理。
Linux線程控制
驗證之前的理論
在Linux當中,如果我們想要創建多線程,就需要使用一個庫來實現創建多線程
這個庫就是:pthread_create
在Linux系統中,創建多線程通常使用POSIX線程(Pthreads)庫。Pthreads是一個廣泛使用的線程庫,它提供了一組API來支持多線程編程。pthread_create函數是Pthreads庫中用于創建新線程的關鍵函數。
以下是pthread_create函數的基本用法:(并不是系統調用哦)
#include <pthread.h>int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);-
pthread_t *thread:指向線程標識符的指針,用于存儲新創建線程的ID。 -
const pthread_attr_t *attr:指向線程屬性對象的指針,用于設置線程屬性。如果不需要設置特定屬性,可以傳遞NULL。 -
void *(*start_routine) (void *):線程開始執行的函數,即線程的入口函數。(返回值為void*,參數位void*的函數指針) -
void *arg:傳遞給線程入口函數(start_routine)的參數。
注意:線程入口函數start_routine必須符合以下原型:
void *start_routine(void *arg);其中,arg是傳遞給線程的參數,start_routine函數的返回值將被存儲在void *類型的指針中,可以通過pthread_join函數獲取。
我們下面來寫一個簡單的創建新線程的代碼:
#include <iostream>
#include <string>
#include <unistd.h>
#include <pthread.h>void *threadrun(void *args)
{std::string name = (const char *)args;while (true){sleep(1);std::cout << "我是新線程: name: " << name << std::endl;}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, threadrun, (void *)"thread-1");while (true){std::cout << "我是主線程..." << std::endl;sleep(1);}return 0;
}我們驗證之前的結論:threadrun不就是編譯后新的一組虛擬地址!!!(根本就不用我們自己去劃分虛擬地址)
 接下來,我們來編譯一下代碼:有時候會鏈接時報錯,這是因為pthread_create不是系統調用,但是它不是第三方庫,只是在默認情況下,編譯器只會鏈接一些核心標準庫(libc),需要在g++編譯后添加" -l+庫的名稱?".(我這里是不需要)(其實還有歷史的原因,在早期的Unix中,多線程編程并不是默認支持的,是被設計成一個可選的擴展)(下面會說其不是系統調用,是庫,是系統調用的)
接下來,我們來編譯一下代碼:有時候會鏈接時報錯,這是因為pthread_create不是系統調用,但是它不是第三方庫,只是在默認情況下,編譯器只會鏈接一些核心標準庫(libc),需要在g++編譯后添加" -l+庫的名稱?".(我這里是不需要)(其實還有歷史的原因,在早期的Unix中,多線程編程并不是默認支持的,是被設計成一個可選的擴展)(下面會說其不是系統調用,是庫,是系統調用的)
我們可以看到:

不過我們的代碼并沒有fork,沒有多進程,那么有沒有可能單進程的情況下,兩個死循環一起跑的,在我們之前的代碼中是不可能的,但是今天,我們main函數和threadrun函數是同時被調用的的!(這就可以說明是兩線程了,那么怎么看到是兩線程呢?)

我們可以看到,只有一個進程,而且為其發送9號信號,殺死進程,可以看出信號是兩個線程共享的。
我們使用:ps -aL(使用a:展示所有,L:查看線程)可以查看線程狀態

所以同一個進程當中可以存在兩個執行流。程序名都是test_thread,因為一個執行的是代碼中的main,一個是threadrun;
那LWP呢?在計算機操作系統中,LWP(Light Weight Process)即輕量級進程,是一種實現多任務的方法。(也就是兩個線程的輕量級進程號,LWP也是不同的,證明我們的進程內部可以存在兩個輕量級進程,那么誰是主線程呢?看LWP,LWP和PID相同的是主線程,因為我們執行的時候,還沒有創建一個線程的時候,就一個線程)
那么CPU調度的時候,是看PID還是LWP呢?
其實是看LWP,因為Linix當中只有輕量級進程,調度的時候是看LWD。只不過只有一個線程的時候,LWP和PID相等。

我們先來說一個比較無關的:關于調度的時間片問題:
?當我們創建新線程的時候,在系統層面上多了一個輕量級進程,一般我們的時間片在創建的時候,時間片基本是要等分,也就是進程本來有10毫秒的時間片,實現了兩線程,那么這兩線程各自5毫秒,是等分的,不能說創建一個線程,就再給10毫秒,因為時間片也是共享的!所以創建線程并不影響進程切換,因為時間片是共享的。
第二個問題:我們現在創建的輕量級進程,可能會出異常,我們下面來驗證一下異常:
void *threadrun(void *args)
{std::string name = (const char *)args;while (true){sleep(1);std::cout << "我是新線程: name: " << name << " ,pid: " << getpid() << std::endl;int a = 10;a /= 0; // 除0錯誤,觸發中斷}return nullptr;
}我們編譯運行一下代碼:

我們發現,任何一個線程崩潰,都會導致整個進程崩潰。從底層原理來講,一個進程崩潰(除0錯誤,野指針錯誤...)系統就會轉化成中斷處理的方式,由操作系統為目標進程發送信號,目標進程中,信號是共享的,所有線程都會接收到。所以說多線程的健壯性是比較低的,因為一個崩掉了,進程中的全部就會崩掉,但是多進程的話,一個崩掉了并不會影響其他進程,因為進程間具有獨立性。
最后一個問題:我們執行我們上面正常代碼的時候,發現消息打印時混著的,這是為什么?
當多個線程各自被調度,各自每隔1秒都是往顯示器上打印的,顯示器的本質是文件,兩個線程訪問的都是同一個文件,所以兩個線程向顯示器打印就是向顯示器文件寫入,所以顯示器文件本質就是一種共享資源,沒有加保護的時候,我們在進行IO時會出現錯誤,后面我們會用鎖來進行共享資源的保護。
引入pthread線程庫
為什么會有一個庫?這個庫是什么東西?
Linux系統,不存在真正意義上的線程,它所謂的概念,就是使用輕量級進程模擬的,但是,OS中,只有輕量級進程,我們不把他叫做線程,所謂模擬線程,只是我們的說法!所以操作系統(Linux)只會為我們提供輕量級進程的系統調用。比如:

所以線程真正來說,是用輕量級進程模擬的。
Linux系統中,線程的實現實際上是通過輕量級進程(Lightweight Process,LWP)來模擬的。在Linux內核中,并沒有真正意義上的線程概念,而是通過輕量級進程來實現類似線程的功能。輕量級進程是操作系統中的一種進程類型,它與傳統的重量級進程(Heavyweight Process)相比,具有更低的資源開銷和更快的創建、切換速度。在Linux系統中,線程的創建和管理實際上是通過輕量級進程的系統調用來實現的,這些系統調用允許程序創建多個共享同一地址空間的輕量級進程,從而模擬出線程的行為。盡管在操作系統的語境中,我們通常將這些輕量級進程稱為線程,但在Linux系統內部,它們本質上仍然是輕量級進程。

其實輕量級進程封裝模擬的線程,使用的是pthread庫,其底層實現其實是通過clone實現的。(Windowd就有具體的線程的系統調用)?
注意:因為POSIX線程庫(pthread)是操作系統提供的標準庫的一部分,而不是由獨立的第三方開發者或組織提供的。盡管在編譯時需要顯式地鏈接pthread庫(使用-lpthread),但這并不意味著它是一個第三方庫。(是系統調用的封裝)
所以:在C++11中,多線程編程得到了官方的支持,其在Linux系統下的實現本質上是對pthread庫的封裝。在Windoes下,封裝了Windows對應的系統調用接口,這種封裝使得C++11的多線程編程接口更加符合C++的語言特性,同時簡化了線程管理、同步等操作。
在C++11中,引入了<thread>頭文件,其中定義了std::thread類,用于表示和管理線程。std::thread的實現本質上是封裝了pthread庫的相關函數。例如:
-
當創建一個
std::thread對象并傳入線程函數時,底層會調用pthread_create來創建一個線程。 -
當調用
std::thread的join成員函數時,底層會調用pthread_join來等待線程結束。
此外,C++11還提供了其他多線程相關的功能,如std::mutex用于線程同步,std::condition_variable用于條件變量等,這些功能的底層實現也都是基于pthread庫的對應功能。
#include <iostream>
#include <thread>// 線程函數
void printHello() {std::cout << "Hello from thread!" << std::endl;
}int main() {// 創建一個線程,執行printHello函數std::thread t(printHello);// 等待線程結束t.join();std::cout << "Hello from main!" << std::endl;return 0;
}在Linux下,使用g++編譯器編譯時需要加上-pthread選項:
g++ -std=c++11 -pthread hello_thread.cpp -o hello_thread所以所有后端語言多線程的底層實現,有且只有一種方案:封裝 !!!
Linux線程控制的接口
在Linux系統中,創建和管理線程是一個常見的需求。本文將詳細介紹如何在Linux中使用POSIX線程庫(pthread)來創建和管理線程。
1. POSIX線程庫
POSIX線程庫(pthread)是一個廣泛使用的線程庫,它提供了一套API來支持多線程編程。pthread_create函數是pthread庫中用于創建新線程的關鍵函數。
pthread_create函數
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);-
thread: 返回線程ID。(是線程ID,輸出型參數,線程創建成功會返回出來,我們待會兒來看看,是不是LWP呢?) -
attr: 設置線程屬性,是輸入型參數,attr為NULL表示使用默認屬性。 -
start_routine: 是一個函數地址,線程啟動后要執行的函數。(一個函數指針,是種回調機制,代表創建出來的新線程要執行的函數入口) -
arg: 傳給線程啟動函數的參數。 -
返回值創建成功返回0,失敗返回錯誤碼。
-
傳統的一些函數是,成功返回1,失敗返回-1,并且對全局變量errno賦值以指示錯誤。
這個庫函數我們上面已經有詳細說過了,這里簡單回顧一下。
2. 線程等待
如果我們創建線程之后,線程就在內核當中以輕量級進程的形式運行,那么未來線程一旦創建了,主線程要對自己曾經創建的新線程進行等待,如果不等待,就會造成類似僵尸進程的問題!!!也就是內存泄漏!!!?
線程等待是必要的,因為已經退出的線程,其空間沒有被釋放,仍然在進程的地址空間內。
pthread_join函數
int pthread_join(pthread_t thread, void **value_ptr);-
value_ptr: 它指向一個指針,后者指向線程的返回值。這是一個輸出型參數!
在目標線程運行結束之前,調用 join 的線程會被阻塞,無法繼續執行后續代碼。
現在,我們就可以來寫一個偏整合代碼:
#include <iostream>
#include <string>
#include <unistd.h>
#include <pthread.h>
#include <cstdio>void showtid(pthread_t &tid)
{printf("tid: %ld\n", tid);
}void *routine(void *args)
{std::string name = static_cast<const char *>(args);int cnt = 5;while (cnt){std::cout << "我是一個新線程: 我的名字是: " << name << std::endl;sleep(1);cnt--;}return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, routine, (void *)"thread-1");(void)n;showtid(tid);pthread_join(tid, nullptr);return 0;
}
線程id是圖中的體現嗎?好像不是吧,這也太奇怪了,這也太大了吧,它竟然不是我們剛剛說的底層的LWP,其實他也就不應該是LWP,因為線程庫本身就是對線程做的封裝,LWP是輕量級進程的概念,是輕量級進程的id,我們要的是線程的id,既然封裝了,就應該要封裝得徹底,這個值有點大,我們可以將其轉化為16進制:
void showtid(pthread_t &tid)
{printf("tid: 0x%lx\n", tid);
}這個tid是什么鬼,暫時不說,反正我們知道它很大。
我們怎么知道我們獲得的tid就是對應線程的tid呢?就是對的呢?
我們就要來學習一個POSIX接口:
phread_self函數
pthread_self 是 POSIX 線程庫中的一個函數,用于獲取當前線程的線程標識符tid(pthread_t 類型)。它返回調用線程的標識符,可以用于標識和管理當前線程。線程標識符被視為一個不透明的對象,常規情況下無需了解其具體值。
以下是 pthread_self 函數的詳細介紹:
pthread_t pthread_self(void);函數說明:
-
pthread_self函數返回當前線程的線程標識符(pthread_t 類型)。 -
返回的線程標識符用于在其他線程或線程管理函數中標識當前線程。
我們的代碼就可以更新為:
void showtid(pthread_t &tid)
{printf("tid: 0x%lx\n", tid);
}std::string FormatId(const pthread_t &tid)
{char id[64];snprintf(id, sizeof(id), "0x%lx", tid);return id;
}void *routine(void *args)
{std::string name = static_cast<const char *>(args);pthread_t tid = pthread_self();int cnt = 5;while (cnt){std::cout << "我是一個新線程: 我的名字是: " << name << " 我的Id是: " << FormatId(tid) << std::endl;sleep(1);cnt--;}return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, routine, (void *)"thread-1");(void)n;showtid(tid);pthread_join(tid, nullptr);return 0;
}我們編譯運行發現:
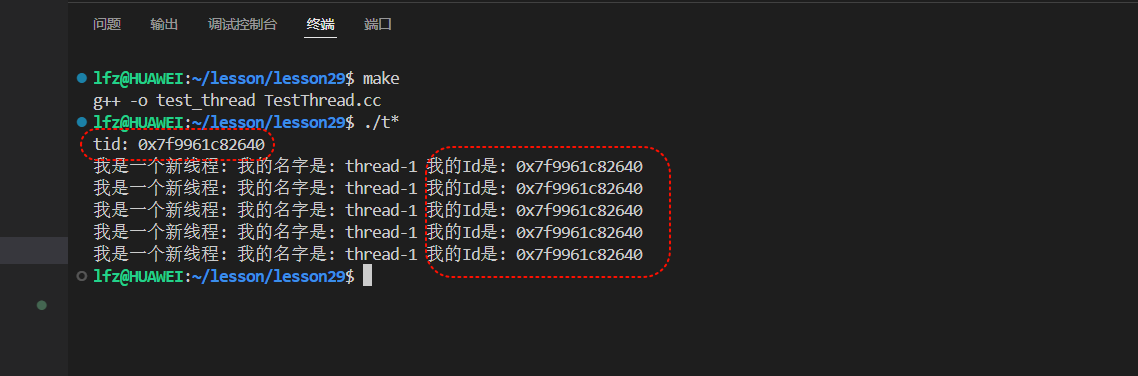
我們果然證明了,main執行流返回的tid就是當前線程的線程id!!!所以主線程join等待的tid就是新線程。
main函數也是一個線程,也有自己的tid,我想讓兩個線程都跑,我們可以更新代碼:
int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, routine, (void *)"thread-1");(void)n;showtid(tid);int cnt = 5;while (cnt){std::cout << "我是main線程: 我的名字是: main thread" << " 我的Id是: "<< FormatId(pthread_self()) << std::endl;sleep(1);cnt--;}pthread_join(tid, nullptr);return 0;
} 我們可以發現,不管是主線程還是新線程,都有自己的線程id。?
我們可以發現,不管是主線程還是新線程,都有自己的線程id。?
我現在先將結論說出來:
打印出來的 tid 是通過 pthread 庫中的函數 pthread_self 得到的,它返回一個 pthread_t 類型的變量,指代的是調用 pthread_self 函數的線程的 “ID”。
怎么理解這個 “ID” 這個 “ID” 是 pthread 庫給每個線程定義的進程內唯一標識,是 pthread 庫維持的。由于每個進程有自己的獨立內存空間,故此 “ID” 的作用域是進程級而非系統級(內核不認識)。其實 pthread 庫也是通過內核提供的系統調用(例如 clone)來創建線程的,而內核會為每個線程創建系統全局唯一的 “ID” 來唯一標識這個線程。

LWP 是什么呢?LWP 得到的是真正的線程ID。之前使? pthread_self 得到的這個數實際上是?個地址,在虛擬地址空間上的?個地址,通過這個地址,可以找到關于這個線程的基本信息,包括線程ID,線程棧,寄存器等屬性。在 ps -aL 得到的線程ID,有?個線程ID和進程ID相同,這個線程就是主線程,主線程的棧在虛擬地址空間的棧上,?其他線程的棧在是在共享區(堆棧之間),因為pthread系列函數都是pthread庫提供給我們的。?pthread庫是在共享區的。所以除了主線程之外的其他線程的棧都在共享區。
多線程中,代碼是共享的,雖然主線程執行一部分,新線程執行另一部分,但是都可以訪問公共的方法FormatId,因為地址空間是共享的,我們可以修改我們的代碼,定義一個全局的flag,讓新線程++,主線程打印:
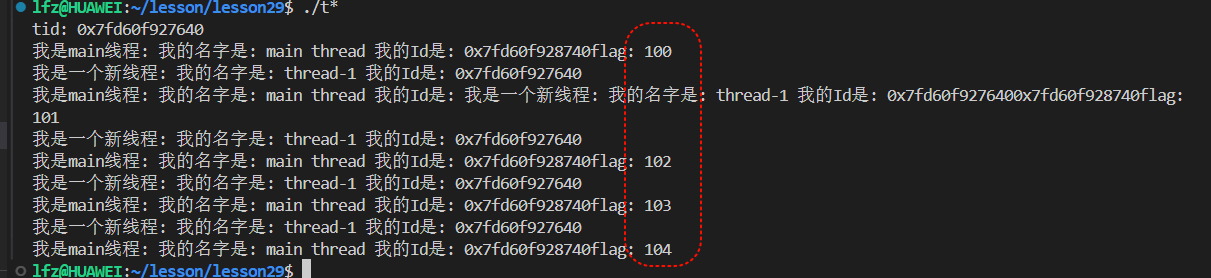
所以在線程領域,全局變量或者是函數,是在線程之間是可以共享的,這是因為地址空間是共享的!
對于FormatId函數同時被兩個執行流調用,也就是被重入了!

我們重入之后,使用的char id[64]緩沖區是局部,臨時的,不是全局的,所以該函數被稱為可重入函數!?
接下來,我們來談談線程傳參還有返回值:?
我們線程傳參其實就是一個回調,我們也就只知道這個,那么對于routine的返回值來說,該返回值是要被join接收的,而且返回值是void*類型的,什么意思呢?就好比返回值不是nullptr:
return (void*)123;//暫時表示線程退出的時候的退出碼void不占空間,但是void*要占用4/8字節,(void*)100就相當于一個地址了,是主線程將新線程創建出來的,主線程將其創建出來就是要求新線程去辦事的,要給主線程拿回點東西。所以pthread_join的第二個參數void** retval,雙指針是因為要傳址返回,而不是傳值返回,所以是void**,也就是看成是(&void*),要求是二級指針。
我們來更新一下我們的代碼:
#include <iostream>
#include <string>
#include <unistd.h>
#include <pthread.h>
#include <cstdio>int flag = 100;void showtid(pthread_t &tid)
{printf("tid: 0x%lx\n", tid);
}std::string FormatId(const pthread_t &tid)
{char id[64];snprintf(id, sizeof(id), "0x%lx", tid);return id;
}void *routine(void *args)
{std::string name = static_cast<const char *>(args);pthread_t tid = pthread_self();int cnt = 5;while (cnt){std::cout << "我是一個新線程: 我的名字是: " << name << " 我的Id是: " << FormatId(tid) << std::endl;sleep(1);cnt--;flag++;}return (void *)123; // 暫時表示線程退出的時候的退出碼
}int main()
{pthread_t tid;int n = pthread_create(&tid, nullptr, routine, (void *)"thread-1");(void)n;showtid(tid);int cnt = 5;while (cnt){std::cout << "我是main線程: 我的名字是: main thread" << " 我的Id是: " << FormatId(pthread_self()) << "flag: " << flag << std::endl;sleep(1);cnt--;}void *ret = nullptr; // ret也是一個變量,也是有空間的!!!// 等待的目標線程,如果異常了,整個進程都退出了,包括main線程,所以,join異常,沒有意義,看也看不到!// jion都是基于:線程健康跑完的情況,不需要處理異常信號,異常信號,是進程要處理的話題!!!pthread_join(tid, &ret); // 為什么在join的時候,沒有見到異常相關的字段呢??std::cout << "ret is: " << (long long int)ret << std::endl; // 要使用的就是ret的空間,因為ret是一個指針,所以打印要轉成long long intreturn 0;
}
這里有一個問題:為什么在join的時候,沒有見到異常相關的字段呢??
今天我們通過rontine返回值拿到的數字是線程結束的退出碼,怎么只有退出碼,我們進程等待時,好歹父進程還能拿到子進程的退出信號(信號為0,表示沒有收到,正常退出,信號非0,代表子進程出錯時的退出碼),join為什么沒有拿到異常退出的信號呢?
這是因為:等待的目標線程,如果異常了,整個進程都退出了,包括main線程,所以,join異常,沒有意義,看也看不到!jion都是基于:線程健康跑完的情況,不需要處理異常信號,異常信號,是進程要處理的話題!!!
還有,我們傳參是可以字符串,整型,甚至是對象,返回也是對象,只要可以傳對象,那么我們就可以寫一個類,這個類可以是某種任務,再定義一個類,用于返回結果等等...?
因為join的第二個參數其實是輸出型參數:
void* ret=nullptr;pthread_join(tid, &ret);routine的返回值就可以拿給ret,讓ret帶出來,但是這之間是有中轉的,等我們將接口認識清楚了,我們待會兒重談pthread庫的時候再來深刻談談。
- main函數結束,代表主線程結束,一般也代表進程結束,也就是說讓main線程先退出,可能會影響其他線程;
- 新線程對應的入口函數(routine),運行結束,代表當前線程運行結束;
- 給線程傳遞的參數和返回值,可以是任意類型。
所以,我們就可以創建一個線程,指定一個任務,讓新線程處理完后,返回結果:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <cstring>// 定義一個任務類,用于封裝兩個整數的加法操作
class Task
{
public:// 構造函數,初始化兩個整數Task(int a, int b) : _a(a), _b(b) {}// 執行任務,返回兩個整數的和int Execute(){return _a + _b;}// 析構函數~Task() {}private:int _a; // 第一個整數int _b; // 第二個整數
};// 定義一個結果類,用于封裝任務的執行結果
class Result
{
public:// 構造函數,初始化結果Result(int result) : _result(result) {}// 獲取結果int GetResult() { return _result; }// 析構函數~Result() {}private:int _result; // 任務的執行結果
};// 線程入口函數
void *routine(void *args)
{// 將傳入的參數強制轉換為Task類型Task *t = static_cast<Task *>(args);// 模擬線程工作,讓線程休眠1秒sleep(1);// 創建一個Result對象,存儲任務的執行結果Result *res = new Result(t->Execute());// 模擬線程工作,讓線程休眠1秒sleep(1);// 返回Result對象的指針return res;
}int main()
{pthread_t tid; // 定義線程IDTask *t = new Task(10, 20); // 創建一個Task對象// 創建線程,傳入Task對象的指針作為參數if (pthread_create(&tid, nullptr, routine, t) != 0){std::cerr << "Failed to create thread." << std::endl;delete t; // 如果線程創建失敗,釋放Task對象return -1;}// 定義一個Result指針,用于接收線程的返回值Result *ret = nullptr;// 等待線程結束,并獲取線程的返回值if (pthread_join(tid, reinterpret_cast<void **>(&ret)) != 0){std::cerr << "Failed to join thread." << std::endl;delete t; // 如果線程等待失敗,釋放Task對象return -1;}// 獲取任務的執行結果并輸出int n = ret->GetResult();std::cout << "新線程結束, 運行結果: " << n << std::endl;// 釋放Task和Result對象delete t;delete ret;return 0;
}?3. 線程終止
如果需要終止某個線程而不終止整個進程,可以采用以下三種方法:
-
從線程的入口函數中進行return就是線程終止。
-
線程調用pthread_exit終止自己。(一定不可以使用exit,exit是進行進程終止的,不是線程終止的,除非故意而為之,調用exit會導致所有線程退出,即進程退出)
-
一個線程可以調用pthread_cancel終止同一進程中的另一個線程。
pthread_exit函數
void pthread_exit(void *value_ptr);-
value_ptr: 不要指向一個局部變量。(等價于return void*)
pthread_cancel函數
int pthread_cancel(pthread_t thread);-
thread: 線程ID。(取消對應ID的線程,做法是主線程去取消新線程的,因為一般都是主線程最后退出的,除非一些特殊情況)(取消的時候,一定要保證,新線程已經啟動!這樣才是合法合理的)線程如果被取消,退出結果是-1【PTHREAD_CANCELED】

其實我們最多使用的還是return!!!
4. 線程分離
默認情況下,新創建的線程是joinable的,也就是線程默認是需要被等待的,線程退出后,需要對其進行pthread_join操作,否則無法釋放資源,從而造成系統泄漏。
不過:
我們學習信號之后,我們發現當一個子進程在結束時,我們可以給父進程設置對子進程的SIG_IGN,父進程就可以不需要wait了,那么如果我們有個需求:讓主線程不再關心新線程,當新線程結束的時候,讓該新線程自己釋放,不要再讓主線程阻塞式的join了,我們該怎么辦?
join 方法本身是阻塞的,沒有直接提供非阻塞選項。我們可以設置線程為分離狀態,來實現主線程不關心新線程,讓主線程不等待新線程,而是想讓新線程自己結束之后,自己退出,釋放資源,我們就需要將線程設置為分離狀態,即非joinable,或detach狀態:?
pthread_detach函數
int pthread_detach(pthread_t thread);-
可以是線程組內其他線程對目標線程進行分離,也可以是線程自己分離。(主線程分離新線程,或者新線程把自己分離了)
但是,分離的線程,依舊在進程的地址空間中,進程的所有資源,被分離的線程,依舊可以訪問,可以操作,只不過主線程不需要等待新線程!
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>void *thread_run(void * arg ) {pthread_detach(pthread_self());printf("%s\n", (char*)arg);return NULL;
}int main( void ) {pthread_t tid;if ( pthread_create(&tid, NULL, thread_run, "thread1 run...") != 0 ) {printf("Create thread error\n");return 1;}//也可以讓主線程分離新線程pthread_detach(tid);int ret = 0;sleep(1); // 很重要,要讓線程先分離,再等待if ( pthread_join(tid, NULL ) == 0 )printf("pthread wait success\n");elseprintf("pthread wait failed\n");ret = 1;return ret;
}所以我們如果進行線程分離之后,就不再需要join,因為join會失敗。
到目前,我們只是知道了下面的操作:(真正的原理還是不清楚的!)
- 線程ID;
- 線程傳參和返回值;
- 線程分離。
具體的原理我們還不清楚,我們會在下一篇談論。
接下來,因為上面我們只是多創建一個線程,接下來,我們來創建多線程來試試看:實現一個簡單的Demo:
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <cstring>
#include <vector>const int num = 10;void *routine(void *args) // 是所有線程的入口函數
{std::string name = static_cast<const char *>(args);int cnt = 5;while (cnt--){std::cout << "新線程名字: " << name << std::endl;sleep(1);}return nullptr;
}int main()
{std::vector<pthread_t> tids; // 所有的線程"ID"// 創建多線程for (int i = 0; i < num; i++){pthread_t tid;// bug??char id[64];snprintf(id, sizeof(id), "thread-%d", i);int n = pthread_create(&tid, nullptr, routine, id);if (n == 0){// 新線程創建成功tids.push_back(tid);}else{continue;}sleep(1); // 觀察線程一個一個被創建}// 對所有的新線程進行等待for (int i = 0; i < num; i++){// 要等就是要一個一個的等待:即便2號線程退出了,可是1號線程還沒處理,那么2號線程就還要等// 不行等的話就按照分離的操作啦int n = pthread_join(tids[i], nullptr);if (n == 0){std::cout << "等待新線程成功!" << std::endl;}}return 0;
}
我們打開監控腳本:

我們創建的多線程就同時跑起來了。
接下來,我們讓創建出來的新線程進入自己的執行函數之后,先休眠1秒,先不著急執行,同時讓創建新線程的for循環飛速執行,我們來觀察一下現象:

我們觀察到:被創建出來的所有的新線程的name都是thread-9,這是什么原因呢?
因為我們傳遞的char id[64]是屬于for循環當中的臨時數組,而且創建線程的時候,傳遞的id[64]屬于該數組的起始地址,routine函數拿進來后,sleep(1)之后才更改的這個值(std::string name = static_cast<const char *>(args);),那么就有可能:新線程被創建出來,指針id[64]是拿著的,但是指針指向的數組內的內容,可能在下一次循環的時候,id被清空,因為id出一次循環,作為局部變量,重新被釋放了(在回調的時候會有對args的拷貝,所以不用擔心釋放了就真沒了),釋放之后,又會寫入線程2,3,4......的id值,所以指針指向沒變,但是指針指向的內容一直在變化,所以當前看到的線程名就不是我們所期望的線程名。
即:
id 是一個局部變量,它在每次循環迭代時都會被重新初始化和覆蓋。在 pthread_create 調用時,雖然傳遞的是 id 的地址作為參數,但由于 id 是局部變量,它的生命周期僅限于當前循環迭代的范圍內。當線程開始執行時,它通過參數 args 訪問到的 id 地址指向的內存已經被覆蓋為最后一次循環迭代時的內容。換句話說,所有線程在運行時訪問到的都是同一個地址,而這個地址的內容在循環結束時已經被設置為 "thread-9",因此所有線程打印的 name 都是 "thread-9"。這種行為導致了線程之間共享了同一個變量的地址,而不是每個線程擁有獨立的變量內容。(多執行流訪問一個公共資源,該公共資源沒有加保護,這就引發了數據不一致問題)
我們這里就導致了一個比較簡單的線程安全的問題。
所以,我們的解決方法是不讓多個線程盯著單一的資源,我們可以在堆上開辟屬于一個線程的空間來使用,來保證互不干擾:(堆空間在原則上也是所有線程共享,但是只有當線程明確地訪問分配給自己的那部分堆空間時,才不會受到其他線程的干擾)。這樣,每個線程都有自己獨立的內存區域,不會因為共享局部變量而導致數據被覆蓋或混淆。
char *id = new char[64];std::string name = static_cast<const char *>(args);
delete (char*)args;//要釋放為什么?
delete[]?要在?routine?中1.?線程參數的生命周期
在
main函數中,為每個線程動態分配了一個字符串id,并將其傳遞給線程函數routine。這個字符串是動態分配的,因此需要在適當的時候釋放它,以避免內存泄漏。2.?線程的異步性
線程的執行是異步的,這意味著線程可能在
main函數的循環結束之前或之后開始運行。如果在main函數中釋放id的內存,可能會導致以下問題:
如果線程在
main函數釋放內存之前開始運行,那么它訪問的內存是有效的。如果線程在
main函數釋放內存之后開始運行,那么它訪問的內存已經被釋放,這會導致未定義行為(如訪問非法內存,可能導致程序崩潰)。為了避免這種問題,必須確保線程在訪問完參數后才釋放內存。因此,釋放內存的邏輯應該放在線程函數
routine中。3.?線程函數的責任
線程函數
routine是線程的入口點,它負責處理傳遞給線程的參數。因此,線程函數有責任管理它接收到的參數的生命周期。一旦線程函數完成對參數的處理,就應該釋放參數占用的內存。
std::string name = static_cast<const char *>(args);:將args指向的字符串內容復制到std::string對象name中。
delete[] (char *)args;:釋放args指向的動態分配的內存。這個操作必須在routine中進行,因為線程函數負責管理傳遞給它的參數。4. 為什么?
main?函數不需要釋放內存在
main函數中,雖然動態分配了內存,但這些內存是傳遞給線程的。線程函數routine負責管理這些內存的生命周期。如果在main函數中釋放這些內存,可能會導致線程訪問非法內存,從而引發未定義行為。因此,
main函數不需要釋放這些內存,而是將內存管理的責任委托給線程函數routine。


)


,源碼可白嫖!)

我的、消息(顯示與隱藏交互))
-安卓9.0-開啟ADB和ROOT-支持IPTV6-支持外置游戲系統-支持多種無線芯片-支持救磚-完美通刷線刷固件包)



之添加行拖拽排序功能示例9,TableView16_09 嵌套表格拖拽排序)






