一、復現代碼
然后去找相關的2d的聲吶圖像分類的算法
融合可以搞的,雖然有文獻但是不多,感覺也是可以的
"""
Author: Benny
Date: Nov 2019
"""import os
import sys
import torch
import numpy as npimport datetime
import logging
import provider
import importlib
import shutil
import argparsefrom pathlib import Path
from tqdm import tqdm
from data_utils.ModelNetDataLoader import ModelNetDataLoaderBASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = BASE_DIR
sys.path.append(os.path.join(ROOT_DIR, 'models'))
#隨機種子 seed
#測試驗證的時候,只跑一次結果,還是【投票跑3次取平均】
#點云分類有兩個指標,一個是總體的分類準確率,另一個是類平均準確率
#是選擇最好的作為結果還是【用自己的保存的最好的模型的函數(沒聽懂)】
def parse_args():'''PARAMETERS'''parser = argparse.ArgumentParser('training')parser.add_argument('--use_cpu', action='store_true', default=False, help='use cpu mode')parser.add_argument('--gpu', type=str, default='0', help='specify gpu device')parser.add_argument('--batch_size', type=int, default=24, help='batch size in training')parser.add_argument('--model', default='pointnet_cls', help='model name [default: pointnet_cls]')parser.add_argument('--num_category', default=40, type=int, choices=[10, 40], help='training on ModelNet10/40')parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training')parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training')parser.add_argument('--num_point', type=int, default=1024, help='Point Number')parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training')parser.add_argument('--log_dir', type=str, default=None, help='experiment root')parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate')parser.add_argument('--use_normals', action='store_true', default=False, help='use normals')parser.add_argument('--process_data', action='store_true', default=False, help='save data offline')parser.add_argument('--use_uniform_sample', action='store_true', default=False, help='use uniform sampiling')return parser.parse_args()def inplace_relu(m):classname = m.__class__.__name__if classname.find('ReLU') != -1:m.inplace=Truedef test(model, loader, num_class=40):mean_correct = []class_acc = np.zeros((num_class, 3))classifier = model.eval()for j, (points, target) in tqdm(enumerate(loader), total=len(loader)):if not args.use_cpu:points, target = points.cuda(), target.cuda()points = points.transpose(2, 1)pred, _ = classifier(points)pred_choice = pred.data.max(1)[1]for cat in np.unique(target.cpu()):classacc = pred_choice[target == cat].eq(target[target == cat].long().data).cpu().sum()class_acc[cat, 0] += classacc.item() / float(points[target == cat].size()[0])class_acc[cat, 1] += 1correct = pred_choice.eq(target.long().data).cpu().sum()mean_correct.append(correct.item() / float(points.size()[0]))class_acc[:, 2] = class_acc[:, 0] / class_acc[:, 1]class_acc = np.mean(class_acc[:, 2])instance_acc = np.mean(mean_correct)return instance_acc, class_accdef main(args):def log_string(str):logger.info(str)print(str)'''HYPER PARAMETER'''os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu'''CREATE DIR'''timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))exp_dir = Path('./log/')exp_dir.mkdir(exist_ok=True)exp_dir = exp_dir.joinpath('classification')exp_dir.mkdir(exist_ok=True)if args.log_dir is None:exp_dir = exp_dir.joinpath(timestr)else:exp_dir = exp_dir.joinpath(args.log_dir)exp_dir.mkdir(exist_ok=True)checkpoints_dir = exp_dir.joinpath('checkpoints/')checkpoints_dir.mkdir(exist_ok=True)log_dir = exp_dir.joinpath('logs/')log_dir.mkdir(exist_ok=True)'''LOG'''args = parse_args()logger = logging.getLogger("Model")logger.setLevel(logging.INFO)formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model))file_handler.setLevel(logging.INFO)file_handler.setFormatter(formatter)logger.addHandler(file_handler)log_string('PARAMETER ...')log_string(args)'''DATA LOADING'''log_string('Load dataset ...')data_path = 'data/modelnet40_normal_resampled/'train_dataset = ModelNetDataLoader(root=data_path, args=args, split='train', process_data=args.process_data)test_dataset = ModelNetDataLoader(root=data_path, args=args, split='test', process_data=args.process_data)trainDataLoader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=10, drop_last=True)testDataLoader = torch.utils.data.DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, num_workers=10)'''MODEL LOADING'''num_class = args.num_categorymodel = importlib.import_module(args.model)shutil.copy('./models/%s.py' % args.model, str(exp_dir))shutil.copy('models/pointnet2_utils.py', str(exp_dir))shutil.copy('./train_classification.py', str(exp_dir))classifier = model.get_model(num_class, normal_channel=args.use_normals)criterion = model.get_loss()classifier.apply(inplace_relu)if not args.use_cpu:classifier = classifier.cuda()criterion = criterion.cuda()try:checkpoint = torch.load(str(exp_dir) + '/checkpoints/best_model.pth')start_epoch = checkpoint['epoch']classifier.load_state_dict(checkpoint['model_state_dict'])log_string('Use pretrain model')except:log_string('No existing model, starting training from scratch...')start_epoch = 0if args.optimizer == 'Adam':optimizer = torch.optim.Adam(classifier.parameters(),lr=args.learning_rate,betas=(0.9, 0.999),eps=1e-08,weight_decay=args.decay_rate)else:optimizer = torch.optim.SGD(classifier.parameters(), lr=0.01, momentum=0.9)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.7)global_epoch = 0global_step = 0best_instance_acc = 0.0best_class_acc = 0.0'''TRANING'''logger.info('Start training...')for epoch in range(start_epoch, args.epoch):log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))mean_correct = []classifier = classifier.train()scheduler.step()for batch_id, (points, target) in tqdm(enumerate(trainDataLoader, 0), total=len(trainDataLoader), smoothing=0.9):optimizer.zero_grad()points = points.data.numpy()points = provider.random_point_dropout(points)points[:, :, 0:3] = provider.random_scale_point_cloud(points[:, :, 0:3])points[:, :, 0:3] = provider.shift_point_cloud(points[:, :, 0:3])points = torch.Tensor(points)points = points.transpose(2, 1)if not args.use_cpu:points, target = points.cuda(), target.cuda()pred, trans_feat = classifier(points)loss = criterion(pred, target.long(), trans_feat)pred_choice = pred.data.max(1)[1]correct = pred_choice.eq(target.long().data).cpu().sum()mean_correct.append(correct.item() / float(points.size()[0]))loss.backward()optimizer.step()global_step += 1train_instance_acc = np.mean(mean_correct)log_string('Train Instance Accuracy: %f' % train_instance_acc)with torch.no_grad():instance_acc, class_acc = test(classifier.eval(), testDataLoader, num_class=num_class)if (instance_acc >= best_instance_acc):best_instance_acc = instance_accbest_epoch = epoch + 1if (class_acc >= best_class_acc):best_class_acc = class_acclog_string('Test Instance Accuracy: %f, Class Accuracy: %f' % (instance_acc, class_acc))log_string('Best Instance Accuracy: %f, Class Accuracy: %f' % (best_instance_acc, best_class_acc))if (instance_acc >= best_instance_acc):logger.info('Save model...')savepath = str(checkpoints_dir) + '/best_model.pth'log_string('Saving at %s' % savepath)state = {'epoch': best_epoch,'instance_acc': instance_acc,'class_acc': class_acc,'model_state_dict': classifier.state_dict(),'optimizer_state_dict': optimizer.state_dict(),}torch.save(state, savepath)global_epoch += 1logger.info('End of training...')if __name__ == '__main__':args = parse_args()main(args)
?具體進程:
1、虛擬環境
anaconda prompt :
---conda create -n pointnet python=3.7
---conda install pytorch==1.6.0 cudatoolkit=10.1 -c pytorch
2、pycharm
設置環境
3、數據
在pointnet文件夾下新建data文件,將40數據放到data文件夾下
4、代碼
修改代碼參數運行
5、運行結果
訓練
C:\Users\229\anaconda3\envs\pointnet\python.exe D:\pycharm\Pointnet_Pointnet2_pytorch-master\train_classification.py
PARAMETER ...
Namespace(batch_size=8, decay_rate=0.0001, epoch=1, gpu='0', learning_rate=0.001, log_dir='pointnet2_cls_ssg', model='pointnet2_cls_ssg', num_category=40, num_point=1024, optimizer='Adam', process_data=False, use_cpu=False, use_normals=False, use_uniform_sample=False)
Load dataset ...
The size of train data is 9843
The size of test data is 2468
No existing model, starting training from scratch...
Epoch 1 (1/1):
100%|██████████| 1230/1230 [09:21<00:00, 2.19it/s]
Train Instance Accuracy: 0.448069
100%|██████████| 309/309 [02:12<00:00, 2.34it/s]
Test Instance Accuracy: 0.652508, Class Accuracy: 0.532580
Best Instance Accuracy: 0.652508, Class Accuracy: 0.532580
Saving at log\classification\pointnet2_cls_ssg\checkpoints/best_model.pth測試
PARAMETER ...
Namespace(batch_size=24, gpu='0', log_dir='pointnet2_cls_ssg', num_category=40, num_point=1024, num_votes=3, use_cpu=False, use_normals=False, use_uniform_sample=False)
Load dataset ...
The size of test data is 2468
100%|██████████| 103/103 [02:39<00:00, 1.55s/it]
Test Instance Accuracy: 0.650485, Class Accuracy: 0.527661?
二、論文
基于深度學習的點云配準的最新進展改進了泛化,但大多數方法仍然需要針對每個新環境進行重新訓練或手動參數調整。
在實踐中,大多數現有方法仍然要求用戶在未知數據集環境的情況下提供最佳參數->所以要針對不同的場景(室內和室外)進行泛化
限制泛化的三個關鍵因素:
(a) 依賴于特定于環境的體素大小和搜索半徑
(b)基于學習的關鍵點檢測器在域外情況的魯棒性較差
(c) 原始坐標使用
目標:估計兩個無序的三維點云 P 和 Q 之間的相對三維旋轉矩陣 R和平移向量 t
BUFFER-X方法
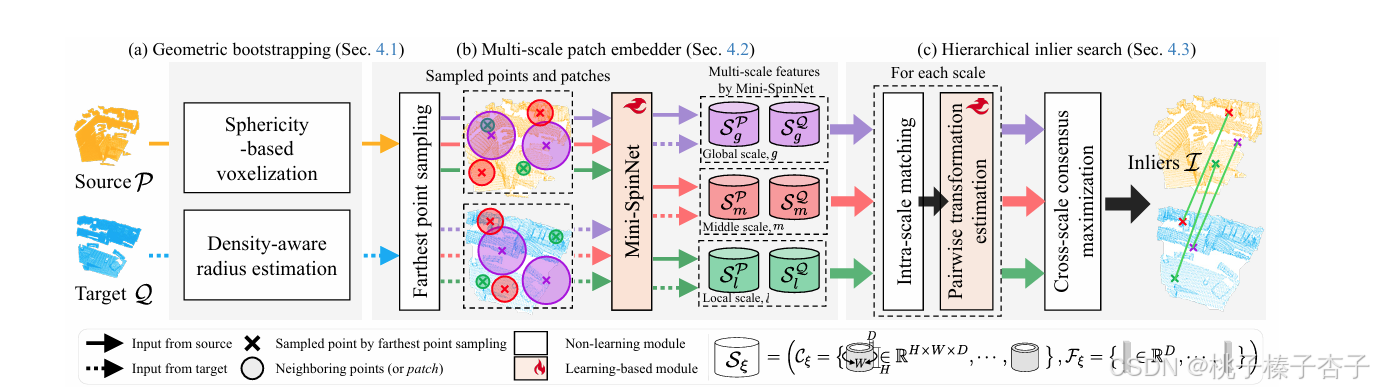
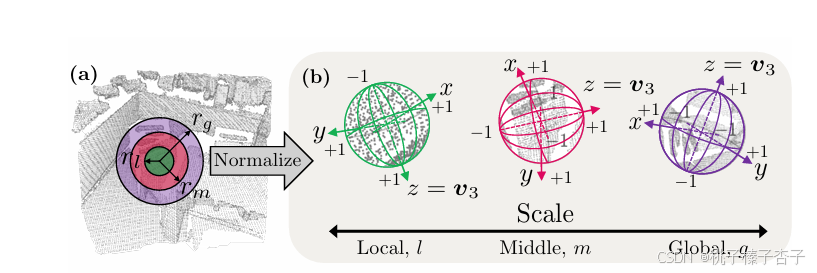
(a) 自適應地確定體素大小和搜索半徑
1)基于球形度的體素化——v
h(P,Q)根據點的數量選擇較大點云
g(P,δ) 是一個從點云 P 中隨機采樣 δ% 點的函數
C是 g(h(P,Q),δv) 的協方差矩陣,δv是定義的采樣率
然后使用PCA計算三個特征值和對應的特征向量:Cva?=λa?va?
假設λ1?≥λ2?≥λ3,則球形度為λ3/λ1
通常來講雷達的球形度低于rgb-d相機的
所以有:
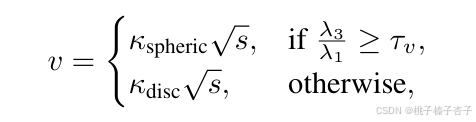
其中s 表示點云沿最小特征值 v3? 對應的特征向量方向的分布范圍
2)基于密度感知的半徑估計
搜索半徑在local、中間和全局三個尺度上分別進行估計,以捕捉不同尺度下的特征信息
設 N(pq?,P,r) 為點 pq? 在點云 P 中,以 r 為半徑的鄰域內的點集,定義為:
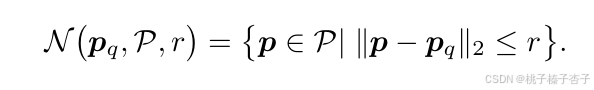
半徑的計算,τξ? 是用戶定義的閾值,表示期望的鄰域密度(即鄰域點相對于總點數的平均比例)
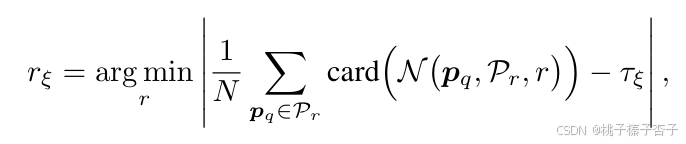
 ?
?
?
τl? ≤ τm ?≤ τg?,相應地,rl? ≤ rm ?≤ rg?(半徑和期望密度的關系
(b) 多尺度
1)最遠點采樣
我們在每個尺度上使用最遠點采樣(FPS)從 P 中采樣 Pξ?(分別從 Q 中采樣 Qξ?),以避免使用基于學習的關鍵點檢測器。需要注意的是,我們為每個尺度獨立采樣不同的點,這是因為不同區域可能需要不同的尺度來進行最佳特征提取。
2)基于Mini-SpinNet的描述符生成
我們通過除以 rξ 將每個塊中的點的尺度歸一化到有界范圍 [?1,1]來確保尺度的一致性,然后
將塊的大小固定為 Npatch?,將這些歸一化的塊作為輸入,Mini-SpinNet輸出一個超集 SPξ??,包含 D 維特征向量 FPξ?? 和圓柱形特征圖 CPξ??,對應于 Pξ?(分別地,SQξ?? 包含 FQξ?? 和 CQξ?? 來自 Qξ?)
BUFFER使用學習到的參考軸來提取圓柱坐標,我們的方法通過將PCA應用于塊內點的協方差來定義每個塊的參考軸,將 z 方向設置為 v3?(協方差對應的特征向量)
(c) 分層內點搜索
1)在 FPξ?? 和 FQξ?? 之間進行基于最近鄰的雙向匹配,得到每個尺度上的匹配對應關系 Aξ?
2)成對變換估計
計算R和t
3)使用所有尺度上的每對 (R,t) 估計值,選擇具有最大基數的3D點對,確保跨尺度一致性,通過共識最大化問題來選擇最終的內點對應關系
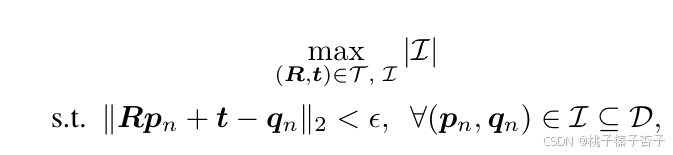
4)最終,將 I 作為輸入,使用求解器(如 RANSAC)估計最終的相對旋轉 R^ 和平移 t^?
三、
正則化層——加快神經網絡的訓練速度
線性層——
torch.reshape是什么東西捏,感覺只能理解一個大概
神經網絡搭建:
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linearclass Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.conv1 = Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2)self.maxpool1 = MaxPool2d(kernel_size=2)self.conv2 = Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2)self.maxpool2 = MaxPool2d(kernel_size=2)self.conv3 = Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)self.maxpool3 = MaxPool2d(kernel_size=2)self.flatten = Flatten()self.linear1 = Linear(in_features=1024, out_features=64)self.linear2 = Linear(in_features=64, out_features=10)def forward(self, x):x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)return xtudui = Tudui()
print(tudui)損失函數loss function
現有網絡模型的使用與修改:
要多看官方文檔)
import torchvision
from torch import nn# train_data = torchvision.datasets.ImageNet("./data_image_net",spilt='train', download=Ture, transform=trocvision.transforms.ToTensor())
vgg16_false = torchvision.models.vgg16(pretrained=False)vgg16_true = torchvision.models.vgg16(pretrained=True)print(vgg16_true)train_data = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor())
#數據集是CIFAR10,然后通過vgg16的模型
#但是vgg16的輸出是1000層,所以還要進一步搞成10層的才符合原數據集的分類要求
vgg16_true.add_module('add_linear',nn.Linear(1000,10))print(vgg16_true)輸出結果:
VGG(
? (features): Sequential(
? ? (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (1): ReLU(inplace=True)
? ? (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (3): ReLU(inplace=True)
? ? (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
? ? (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (6): ReLU(inplace=True)
? ? (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (8): ReLU(inplace=True)
? ? (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
? ? (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (11): ReLU(inplace=True)
? ? (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (13): ReLU(inplace=True)
? ? (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (15): ReLU(inplace=True)
? ? (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
? ? (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (18): ReLU(inplace=True)
? ? (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (20): ReLU(inplace=True)
? ? (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (22): ReLU(inplace=True)
? ? (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
? ? (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (25): ReLU(inplace=True)
? ? (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (27): ReLU(inplace=True)
? ? (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
? ? (29): ReLU(inplace=True)
? ? (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
? )
? (avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
? (classifier): Sequential(
? ? (0): Linear(in_features=25088, out_features=4096, bias=True)
? ? (1): ReLU(inplace=True)
? ? (2): Dropout(p=0.5, inplace=False)
? ? (3): Linear(in_features=4096, out_features=4096, bias=True)
? ? (4): ReLU(inplace=True)
? ? (5): Dropout(p=0.5, inplace=False)
? ? (6): Linear(in_features=4096, out_features=1000, bias=True)
? )
? (add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
vgg16_true.classifier.add_module('add_linear',nn.Linear(1000,10))通過這個classifier的操作可以把這一步添加到classifier層中而不是單獨放出來
直接修改最后一個線性層:
vgg16_false.classifier[6] = nn.Linear(1000,10)
print(vgg16_false)結果:
? (classifier): Sequential(
? ? (0): Linear(in_features=25088, out_features=4096, bias=True)
? ? (1): ReLU(inplace=True)
? ? (2): Dropout(p=0.5, inplace=False)
? ? (3): Linear(in_features=4096, out_features=4096, bias=True)
? ? (4): ReLU(inplace=True)
? ? (5): Dropout(p=0.5, inplace=False)
? ? (6): Linear(in_features=1000, out_features=10, bias=True)
? )
)
模型的保存
模型的加載
準確率:

import torchoutputs = torch.tensor([[0.1,0.2],[0.3,0.4]])#argmax(1)是橫向比較一行,argmax(0)是縱向比較一列
print(outputs.argmax(1))
preds = outputs.argmax(1)
targets = torch.tensor([0, 1])
print(preds == targets)
print((preds == targets).sum())
GPU訓練
完整的模型驗證套路-》利用已經訓練好的模型,然后給他提供輸入
注意這里可能的報錯,如果記錄的是用gpu訓練過的,那么在運行的時候要加入cuda的相關內容,
import torch
import torchvision
from PIL import Image
from torch import nnimage_path= "images/dog.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),nn.MaxPool2d(2),nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(in_features=64*4*4, out_features=64),nn.Linear(in_features=64, out_features=10))def forward(self, x):x = self.model(x)return xmodel = torch.load("tudui_9.pth",weights_only=False)
print(model)image = torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():output = model(image)
print(output)
也算是學完了,最后開源代碼的部分也看一下把



)








)


將輸入的彩色圖像轉換為兩種風格的鉛筆素描效果函數pencilSketch())



