文章目錄
- 摘要
- abstract
- 1.ControlNet
- 1.1 原文摘要
- 1.2 模型架構
- 1.3 架構細節
- 1.4 訓練損失函數
- 1.5 實驗
- 1.6 結論
- 2.總結
- 參考文獻
摘要
本周學習的ControlNet 是一種用于文本到圖像擴散模型(如 Stable Diffusion)的條件控制方法。它通過凍結預訓練的擴散模型,并創建一個可訓練的副本,使其能夠學習額外的條件信息。關鍵技術包括零卷積(Zero Convolutions),用于確保模型訓練初期不影響原始網絡,同時逐步引入控制信息。ControlNet 可以接受多種條件輸入(如 Canny 邊緣檢測),并在保持高質量圖像生成的同時,實現精確的結構控制。實驗結果表明,該方法在不同條件約束下均能穩定工作,有效增強了擴散模型的可控性。
abstract
ControlNet is a conditional control method for text-to-image Diffusion models such as Stable Diffusion. It does this by freezing the pre-trained diffusion model and creating a trainable copy, enabling it to learn additional conditional information. Key techniques include Zero Convolutions, which ensure that the initial model training does not affect the original network, while gradually introducing control information. ControlNet can accept a variety of conditional inputs (such as Canny edge detection) and achieve precise structural control while maintaining high-quality image generation. Experimental results show that the proposed method can work stably under different conditions and effectively enhance the controllability of diffusion model.
1.ControlNet
1.1 原文摘要
上周學習的T2I-Adapter模型和ControlNet兩者都是基于Stable Diffusion模型的擴展,顯示的將條件(支持很多條件)注入到預訓練的網絡當中。

摘要的第一句話表明ControlNet可以想T2I擴散模型添加條件,以此來控制擴散模型的生成。通過凍結預訓練好的擴散模型,然后重復的使用它們學習各種條件的控制,并且使用Zero convolutions(權重和偏置分別初始化為0,卷積核大小為1*1的卷積層,這樣的卷積在模型中所充當的角色就是將ControlNet和SD做一個連接)來確保微調過程中不受到噪音的影響。
1.2 模型架構
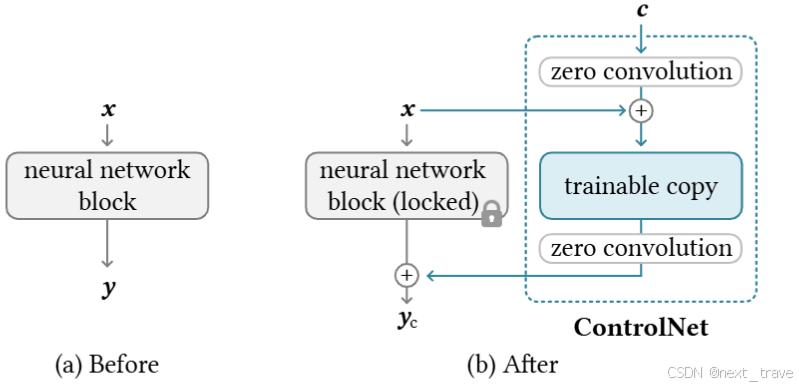
無論是ControlNet還是T2I-Adapter,它們都是對當前大規模預訓練好的文本到圖像的擴散模型提供可控的輸入條件,使得生成會變得更加可控。上圖中,右側ControlNet,它先將模型凍結,同時復制一個可訓練的網絡(和凍結的網絡結構參數是一樣的,就是一個更新一個不更新)。然后將條件c輸入到ControlNet中,從而得到這個條件網絡的輸出,這個輸入會加到當前的擴散模型中輸出結果。上述零卷積的作用就是連接了兩個網絡。
1.3 架構細節
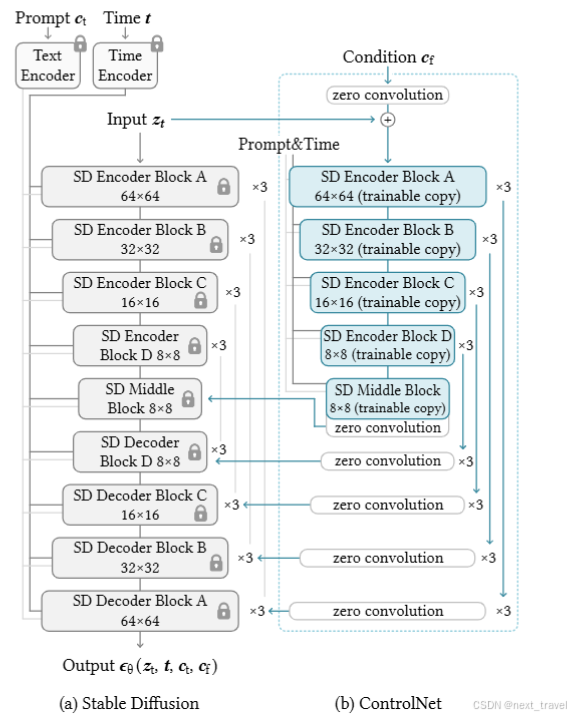
左側是凍結的SD模型,右側是ControlNet,主要是復制了SD的encoder Block和Middle Block這兩個部分。輸入的condition經過controlNet后,會經過零卷積(網絡沒有更新的第一次運算時,無論輸入什么,這個網絡的輸出都是0,就是在訓練開始時,不會對SD有任何的干擾)分別連接SD的每一層當中。
1.4 訓練損失函數
L = E z 0 , t , c t , c f , ? ~ N ( 0 , 1 ) [ ∥ ? ? ? θ ( z t , t , c t , c f ) ) ∥ 2 2 ] \mathcal{L}=\mathbb{E}_{\boldsymbol{z}_{0},\boldsymbol{t},\boldsymbol{c}_{t},\boldsymbol{c}_{\mathrm{f}},\epsilon\sim\mathcal{N}(0,1)}\left[\|\epsilon-\epsilon_{\theta}(\boldsymbol{z}_{t},\boldsymbol{t},\boldsymbol{c}_{t},\boldsymbol{c}_{\mathrm{f}}))\|_{2}^{2}\right] L=Ez0?,t,ct?,cf?,?~N(0,1)?[∥???θ?(zt?,t,ct?,cf?))∥22?]
它的優化目標和T2I-Adapter很像,就是在原始的時間步、文本、當前噪聲的條件下,再加入條件輸入,這樣整體的優化目標仍然是在當前時間步去估計當前加的噪聲,以及和真實噪聲做一個L2 loss.ControlNet從宏觀來說,就是利用一個網絡去對另外一個網絡注入條件,它所用的網絡實際上是一個小網絡(為一個大網絡提供條件,希望大網絡能夠得到一些性能)。
1.5 實驗

上述實驗中用高斯權重初始化的標準卷積層替換零卷積層。
實驗代碼
輸入提示詞 prompt: cute dog
apply_canny = CannyDetector()model = create_model('./models/cldm_v15.yaml').cpu()
model.load_state_dict(load_state_dict('./models/control_sd15_canny.pth', location='cuda'))
model = model.cuda()
ddim_sampler = DDIMSampler(model)def process(input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, guess_mode, strength, scale, seed, eta, low_threshold, high_threshold):with torch.no_grad():img = resize_image(HWC3(input_image), image_resolution)H, W, C = img.shapedetected_map = apply_canny(img, low_threshold, high_threshold)detected_map = HWC3(detected_map)control = torch.from_numpy(detected_map.copy()).float().cuda() / 255.0control = torch.stack([control for _ in range(num_samples)], dim=0)control = einops.rearrange(control, 'b h w c -> b c h w').clone()if seed == -1:seed = random.randint(0, 65535)seed_everything(seed)if config.save_memory:model.low_vram_shift(is_diffusing=False)cond = {"c_concat": [control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]}un_cond = {"c_concat": None if guess_mode else [control], "c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]}shape = (4, H // 8, W // 8)if config.save_memory:model.low_vram_shift(is_diffusing=True)model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13) # Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples,shape, cond, verbose=False, eta=eta,unconditional_guidance_scale=scale,unconditional_conditioning=un_cond)if config.save_memory:model.low_vram_shift(is_diffusing=False)x_samples = model.decode_first_stage(samples)x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8)results = [x_samples[i] for i in range(num_samples)]return [255 - detected_map] + resultsblock = gr.Blocks().queue()
with block:with gr.Row():gr.Markdown("## Control Stable Diffusion with Canny Edge Maps")with gr.Row():with gr.Column():input_image = gr.Image(source='upload', type="numpy")prompt = gr.Textbox(label="Prompt")run_button = gr.Button(label="Run")with gr.Accordion("Advanced options", open=False):num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)image_resolution = gr.Slider(label="Image Resolution", minimum=256, maximum=768, value=512, step=64)strength = gr.Slider(label="Control Strength", minimum=0.0, maximum=2.0, value=1.0, step=0.01)guess_mode = gr.Checkbox(label='Guess Mode', value=False)low_threshold = gr.Slider(label="Canny low threshold", minimum=1, maximum=255, value=100, step=1)high_threshold = gr.Slider(label="Canny high threshold", minimum=1, maximum=255, value=200, step=1)ddim_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=20, step=1)scale = gr.Slider(label="Guidance Scale", minimum=0.1, maximum=30.0, value=9.0, step=0.1)seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, randomize=True)eta = gr.Number(label="eta (DDIM)", value=0.0)a_prompt = gr.Textbox(label="Added Prompt", value='best quality, extremely detailed')n_prompt = gr.Textbox(label="Negative Prompt",value='longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality')with gr.Column():result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=2, height='auto')ips = [input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, guess_mode, strength, scale, seed, eta, low_threshold, high_threshold]run_button.click(fn=process, inputs=ips, outputs=[result_gallery])

1.6 結論
ControlNet是一種神經網絡架構,用于學習大型預訓練文本到圖像擴散模型的條件控制。原始模型和可訓練副本通過zero convolution層連接,從而消除訓練過程中的有害噪聲。文中大量實驗表明無論是否有提示詞,ControlNet可以有效地控制具有單個或多個條件的SD。
2.總結
ControlNet 通過在 Stable Diffusion 之上添加一個可訓練的控制網絡,實現了對圖像生成的精確調控。其核心優勢在于無需修改原始擴散模型,而是通過獨立的可訓練分支來學習條件映射,從而提高可控性。零卷積的引入確保了訓練的穩定性,避免了對擴散模型的過度干擾。實驗表明,ControlNet 可以在不同任務(如邊緣檢測、深度圖、姿態引導等)中有效發揮作用,使得文本到圖像的生成更加靈活、多樣,為擴散模型的實際應用提供了更廣泛的可能性。
參考文獻
https://arxiv.org/pdf/2302.05543.pdf
https://github.com/lllyasviel/ControlNet













)



)

