Linux 是如何決定何時進行上下文切換的?
在Linux中,CPU 上下文切換是指當操作系統將 CPU 從一個進程切換到另一個進程時,保存當前進程的執行狀態,并加載新進程的執行狀態的過程就稱為上下文切換。
但在 Linux 內核中,是否切換進程通常由一個關鍵標志位 TIF_NEED_RESCHED 來決定。
當該標志被設置時,內核會在合適的時機(例如從中斷返回或系統調用結束時)調用schedule(),從而觸發上下文切換。
TIF_NEED_RESCHED標志的設置過程
剛才我們提到切換進程或任務是由TIF_NEED_RESCHED標志位來判斷,那這個標志位是如何設置的呢
接下來,我們將從 scheduler_tick() 函數開始,逐步揭示這個標志位是如何被設置,并最終觸發上下文切換的。
1. scheduler_tick():調度的“心跳”
讓我們先從**scheduler_tick()**函數開始 說起
scheduler_tick() 是由定時器中斷(以 HZ 頻率)觸發的調度驅動函數。它會獲取當前 CPU 上正在運行的進程,并調用該進程所屬調度器的 task_tick() 方法,然后根據具體對應的調度策略判斷是否需要重新調度。
// kernel/sched/core.c
void scheduler_tick(void)
{int cpu = smp_processor_id();struct rq *rq = cpu_rq(cpu);struct task_struct *curr = rq->curr;struct rq_flags rf;// ...rq_lock(rq, &rf); // 加鎖以保護運行隊列// ... 省略 ...// 這是核心調用:根據任務類型調用其對應的 task_tick 方法curr->sched_class->task_tick(rq, curr, 0);// ... 其他邏輯 ...rq_unlock(rq, &rf); // 解鎖// ...
}
在上述代碼中,最關鍵的一行是 curr->sched_class->task_tick(rq, curr, 0);
這行代碼是調度器邏輯的入口,它根據當前運行任務 (curr) 所屬的調度類 (sched_class),動態地調用其特有的 task_tick 方法。對于 CFS(完全公平調度器)任務,就會調用 task_tick_fair(),從而進入具體的調度決策流程。
2. task_tick_fair():CFS 的任務周期調度
剛才提到過每種調度策略都會通過一個sched_class結構體定義其行為,完全公平調度器(CFS)的調度類定義在**kernel/sched/fair.c** 文件中,它通過 DEFINE_SCHED_CLASS(fair) 結構體被綁定到 task_tick 接口上。
/* kernel/sched/fair.c */
DEFINE_SCHED_CLASS(fair) = {.enqueue_task = enqueue_task_fair,.dequeue_task = dequeue_task_fair,.yield_task = yield_task_fair,....task_tick = task_tick_fair, // 👈 心跳函數綁定在這里....update_curr = update_curr_fair,
};
那我們接著就看一下task_tick_fair函數
/** scheduler tick hitting a task of our scheduling class.** NOTE: This function can be called remotely by the tick offload that* goes along full dynticks. Therefore no local assumption can be made* and everything must be accessed through the @rq and @curr passed in* parameters.*/
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{struct cfs_rq *cfs_rq;struct sched_entity *se = &curr->se;for_each_sched_entity(se) {cfs_rq = cfs_rq_of(se);entity_tick(cfs_rq, se, queued);}if (static_branch_unlikely(&sched_numa_balancing))task_tick_numa(rq, curr);update_misfit_status(curr, rq);update_overutilized_status(task_rq(curr));task_tick_core(rq, curr);
}
首先CFS 把調度的最小單位抽象成 sched_entity,它即可以是線程也可以是進程組。每個sched_entity都會對應一個 運行隊列
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
接著**for_each_sched_entity循環會一直向上遍歷到最頂層的調度實體**(例如:線程 → 進程組 → 父組),并在每一層都調用 entity_tick() 函數。
for_each_sched_entity(se) {cfs_rq = cfs_rq_of(se);entity_tick(cfs_rq, se, queued);
}
3. entity_tick() 與 update_deadline():判斷是否“超時”
在 entity_tick() 函數中會調用 update_curr(),該函數會負責更新當前任務的運行時間統計信息,并在此過程中判斷任務是否已超出其分配的時間片。
update_curr() 隨后會調用 update_deadline(),這里便是我們尋找的觸發點。該函數會更新當前任務的運行時間,并判斷是否需要觸發調度。我們先看一下update_deadline的具體代碼
/** XXX: strictly: vd_i += N*r_i/w_i such that: vd_i > ve_i* this is probably good enough.*/
static void update_deadline(struct cfs_rq *cfs_rq, struct sched_entity *se)
{if ((s64)(se->vruntime - se->deadline) < 0)return;/** For EEVDF the virtual time slope is determined by w_i (iow.* nice) while the request time r_i is determined by* sysctl_sched_base_slice.*/se->slice = sysctl_sched_base_slice;/** EEVDF: vd_i = ve_i + r_i / w_i*/se->deadline = se->vruntime + calc_delta_fair(se->slice, se);/** The task has consumed its request, reschedule.*/if (cfs_rq->nr_running > 1) {resched_curr(rq_of(cfs_rq));clear_buddies(cfs_rq, se);}
}
當Linux中任務的虛擬運行時間超過其截止時間,并且運行隊列 (cfs_rq) 中有其他可運行的任務時,就會認為當前任務的時間片已用完。此時就會調用 resched_curr() 從而設置TIF_NEED_RESCHED 標志位了
if (cfs_rq->nr_running > 1) {resched_curr(rq_of(cfs_rq));clear_buddies(cfs_rq, se);
}
4. resched_curr():設置 TIF_NEED_RESCHED 標志
最后再看一下**resched_curr**的代碼,代碼在kernel/sched/core.c中
/** resched_curr - mark rq's current task 'to be rescheduled now'.** On UP this means the setting of the need_resched flag, on SMP it* might also involve a cross-CPU call to trigger the scheduler on* the target CPU.*/
void resched_curr(struct rq *rq)
{struct task_struct *curr = rq->curr;int cpu;lockdep_assert_rq_held(rq);if (test_tsk_need_resched(curr))return;cpu = cpu_of(rq);if (cpu == smp_processor_id()) {set_tsk_need_resched(curr); // 標記當前任務需要被調度set_preempt_need_resched(); // 觸發搶占檢查return;}if (set_nr_and_not_polling(curr))smp_send_reschedule(cpu);elsetrace_sched_wake_idle_without_ipi(cpu);
}
檢查是否已標記 resched_curr函數首先會檢查當前任務 (curr) 的 need_resched 標志是否已經被設置。如果已經被設置,說明任務已經被標記為需要調度就直接返回避免重復操作。
if (test_tsk_need_resched(curr))return;
處理當前對應CPU核心上的調度
這段代碼檢查 resched_curr 是否在當前 CPU 上被調用。如果是,它會執行兩個關鍵步驟:
set_tsk_need_resched(curr): 顯式地設置當前任務的TIF_NEED_RESCHED標志。set_preempt_need_resched(): 告訴搶占機制,在下一個安全點(例如從中斷返回或系統調用結束時),應該檢查該標志并立即進行一次上下文切換。
if (cpu == smp_processor_id()) {set_tsk_need_resched(curr); // 標記當前任務需要被調度set_preempt_need_resched(); // 觸發搶占檢查return;
}
總結:need_resched 的調用鏈
現在,我們可以清晰地梳理出 TIF_NEED_RESCHED 標志的完整設置流程:
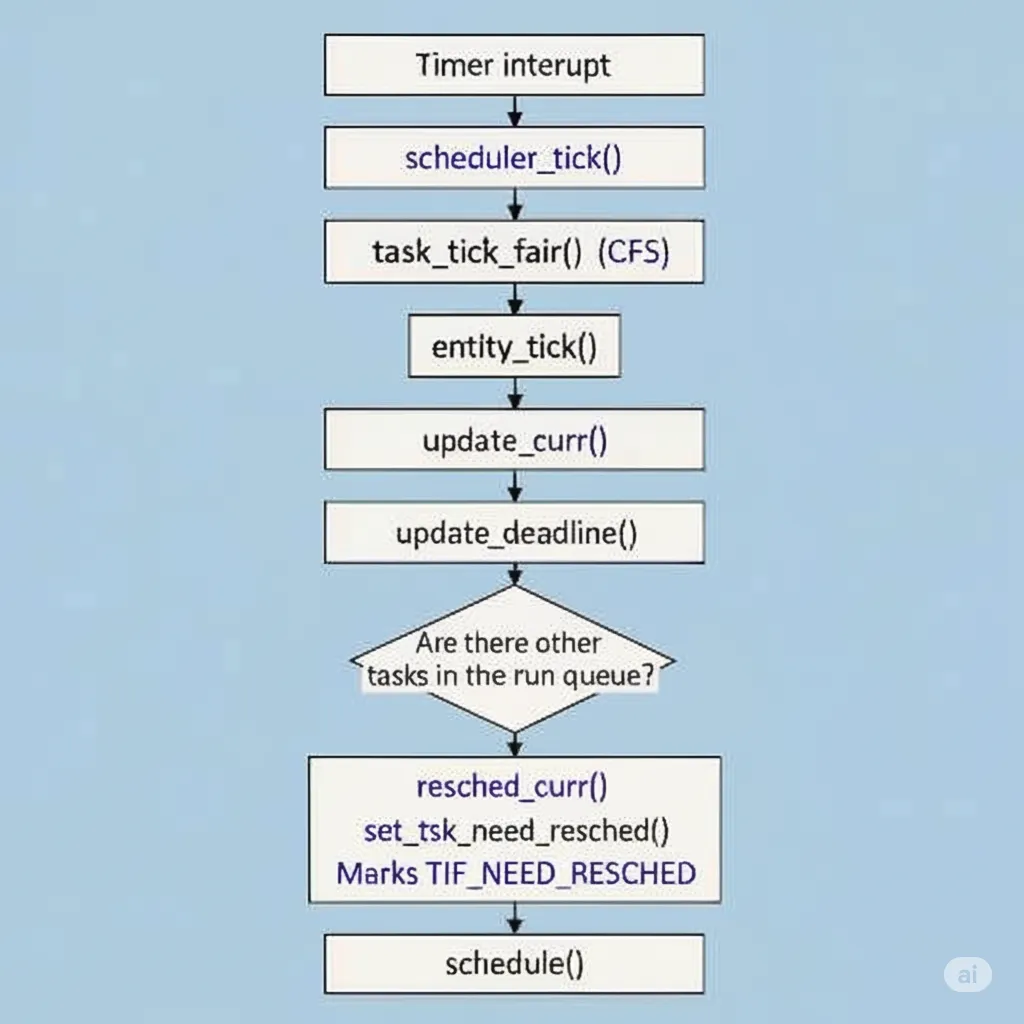
這個調用鏈展示了 Linux 內核如何利用一個周期性的定時器中斷,結合 CFS 調度器的公平性原則,最終實現了搶占式多任務的調度核心。
完整代碼參考: 完整的源碼可以在 Linux 內核源碼的 kernel/sched/fair.c 和 kernel/sched/core.c 文件中找到這些函數的完整實現。
linux/kernel/sched/fair.c at master · torvalds/linux · GitHublinux/kernel/sched/core.c at master · torvalds/linux · GitHub





)

與Unity的交互-有線串流調試篇)





)



——筆鋒(單 Path))
——取地址運算符重載、類型轉換、static成員和友元)
)