
論文地址:https://arxiv.org/pdf/2503.06671
代碼地址:https://github.com/dslisleedh/ESC
關注UP CV縫合怪,分享最計算機視覺新即插即用模塊,并提供配套的論文資料與代碼。
https://space.bilibili.com/473764881
摘要
本研究解決了Transformer在高效圖像超分辨率(SR)任務中的高計算開銷問題。基于對自注意力層間重復性的觀察,本研究引入了一個名為卷積注意力(ConvAttn)的卷積化自注意力模塊,它利用單個共享的大卷積核和動態卷積核來模擬自注意力的遠程建模能力和實例依賴加權。通過利用ConvAttn模塊,本研究顯著減少了對自注意力及其相關內存密集型操作的依賴,同時保持了Transformer的表示能力。此外,本研究克服了將Flash Attention集成到輕量級SR領域的挑戰,有效地緩解了自注意力固有的內存瓶頸。本研究使用Flash Attention將窗口大小擴展到32×32,而不是提出復雜的自注意力模塊,在Urban100 ×2上PSNR顯著提高了0.31dB,同時延遲和內存使用量分別降低了16倍和12.2倍。基于這些方法,本研究提出的網絡名為“用卷積模擬自注意力(ESC)”,與HiT-SRF相比,在Urban100 ×4上PSNR顯著提高了0.27dB,延遲和內存使用量分別降低了3.7倍和6.2倍。大量實驗表明,盡管大部分自注意力被ConvAttn模塊取代,ESC仍保持了Transformer的遠程建模能力、數據可擴展性和表示能力。
引言
Transformer在高效圖像超分辨率中的應用:用卷積模擬自注意力
本研究致力于解決Transformer在高效圖像超分辨率(SR)任務中的高計算開銷問題。當前,隨著多媒體內容和生成模型需求的顯著增長,SR技術的重要性日益凸顯,因為它能夠使用戶在資源受限的條件下享受高質量內容。因此,實際部署已成為SR任務中的一個關鍵考慮因素,促使許多SR研究在提高性能的同時降低計算復雜度和參數規模。Transformer在SR任務中取得了比卷積神經網絡(CNN)更優越的性能,同時具有更低的計算量和更少的參數,因此受到了廣泛關注。通過自注意力機制捕獲長距離依賴關系和執行依賴于輸入的加權,Transformer展現出強大的表征能力和增強的性能,尤其是在訓練數據量增加時。然而,許多研究忽略了自注意力機制造成的過度內存訪問,這是由于需要實例化分數矩陣以及利用內存密集型操作(如張量重塑和窗口掩碼)所導致的。在SR架構中,由于需要處理大特征圖而沒有patchify stem或下采樣階段,內存訪問問題更加嚴重。例如,即使SwinIR-light的計算量和參數規模分別比重建×2比例高清圖像的CNN少14.5倍和17倍,但其延遲卻高4.7倍,內存使用量也高2倍。因此,盡管Transformer的性能很有前景,但在資源受限的設備(如消費級GPU)上部署它們仍然具有挑戰性。
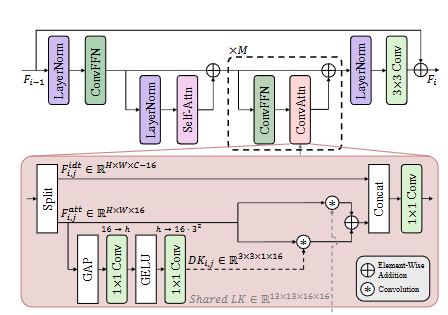
本研究的初步分析表明,自注意力機制執行的相似性建模和提取的特征在多層之間保持高度一致。這一發現表明自注意力機制可能會提取重疊的特征,這意味著可以通過使用高效的替代方案來降低計算開銷而不損害表征能力。基于此發現,本研究提出了一種設計策略,僅在每個塊的第一層保留自注意力機制,而用本研究提出的高效替代方案——卷積注意力(ConvAttn)模塊——替換其余層。為了有效地模擬自注意力的長距離建模和依賴于實例的加權,ConvAttn模塊采用雙重機制運作。首先,它通過在整個網絡中應用具有共享的13×13大核的卷積來簡化自注意力的長距離交互,僅針對一部分通道進行操作。其次,生成動態核以捕獲依賴于輸入的加權,模仿自注意力的自適應特性。通過結合這些組件,ConvAttn模塊顯著減少了對內存密集型自注意力的依賴,同時保持了Transformer的表征能力。
通過用ConvAttn替換大部分自注意力層,本研究利用這種效率進一步增強了剩余的自注意力層。具體而言,本研究擴大了自注意力的窗口大小,在僅略微增加計算量的情況下顯著提高了性能。然而,增加窗口大小會導致分數矩陣擴大,從而大幅增加峰值內存使用量。為了解決這個問題,本研究將Flash Attention引入到輕量級SR任務中,以避免實例化分數矩陣。本研究的優化實現允許將窗口大小擴展到32×32,同時將延遲和內存使用量分別減少16倍和12.2倍。基于這些方法,本研究介紹了一種名為“用卷積模擬自注意力(ESC)”的輕量級SR網絡。與ATD-light相比,所提出的ESC在Urban100 ×4上PSNR提高了0.1dB,同時速度提高了8.9倍。此外,ESC-light在Urban100 ×2上PSNR超過ELAN-light 0.29dB,同時延遲降低了22%。本研究通過引入ESC-FP進一步驗證了ESC在降低計算量和參數規模至關重要的場景下的有效性,ESC-FP在Manga109 ×4上的性能優于MambaIRV2-light,同時計算量和參數規模分別減少了20%和32%。通過廣泛的實驗,本研究證明了即使大部分自注意力被ConvAttn模塊取代,ESC仍然充分利用了Transformer的優勢,包括其大的感受野、表征能力以及關于數據量的可擴展性。本研究通過深入的實驗支持了這些結果,表明所提出的ConvAttn模塊提取的特征與自注意力機制相似。
論文創新點
本研究提出了一個名為ESC的高效圖像超分辨率網絡,旨在降低Transformer在計算和內存方面的開銷。本研究的創新點主要體現在以下幾個方面:
-
? 基于卷積的注意力模塊(ConvAttn): ?
- 本研究觀察到Transformer中自注意力機制的層間特征存在高度相似性,這表明自注意力機制在不同層提取的特征存在冗余。
- 基于此,本研究設計了ConvAttn模塊,它結合了共享的大核卷積和動態生成的深度卷積核,以模擬自注意力機制的長距離建模能力和實例依賴的加權能力。
- ConvAttn模塊有效地替代了Transformer中除了每個塊的第一層以外的其他自注意力層,從而顯著降低了對內存密集型自注意力操作的依賴,同時保持了Transformer的表示能力。
-
🚀 共享大核卷積: 🚀
- ConvAttn 模塊中的共享大核卷積(LK)貫穿整個網絡,負責捕獲全局上下文信息和長距離依賴關系。
- LK 的參數在所有層之間共享,從而減少了模型的整體參數量和計算開銷,并有助于穩定訓練。
-
?? 動態深度卷積核: ??
- 為了模擬自注意力機制的實例依賴加權,ConvAttn 模塊引入了動態深度卷積核(DK)。
- DK 根據輸入特征動態生成,能夠捕獲特定實例的局部特征。
- DK與 LK 協同工作,在降低內存開銷的同時,實現了對全局和局部特征的有效建模。
-
?? Flash Attention的集成: ??
- 為了進一步降低自注意力機制的內存開銷,本研究將Flash Attention集成到輕量級SR任務中。
- Flash Attention 通過避免顯式計算和存儲注意力矩陣,顯著減少了自注意力操作的內存占用和延遲。
- 本研究優化了 Flash Attention 的實現,使其能夠支持更大的窗口大小(32x32),從而在輕量級SR任務中實現了性能的顯著提升。
-
🌐 多尺度特征融合: 🌐
- ESC 網絡巧妙地融合了局部和全局特征。ConvFFN 模塊提取局部特征,而 ConvAttn 模塊捕獲全局上下文信息。
- 通過將這兩個模塊的輸出進行融合,ESC 網絡能夠有效地利用多尺度信息,從而提高了圖像超分辨率的性能。
通過這些創新,本研究提出的ESC網絡在多個圖像超分辨率基準數據集上取得了顯著的性能提升,同時顯著降低了計算和內存開銷。此外,本研究還證明了 ESC 網絡在數據擴展性和任意尺度超分辨率任務上的有效性,進一步驗證了其優越的泛化能力和實用價值。
論文實驗
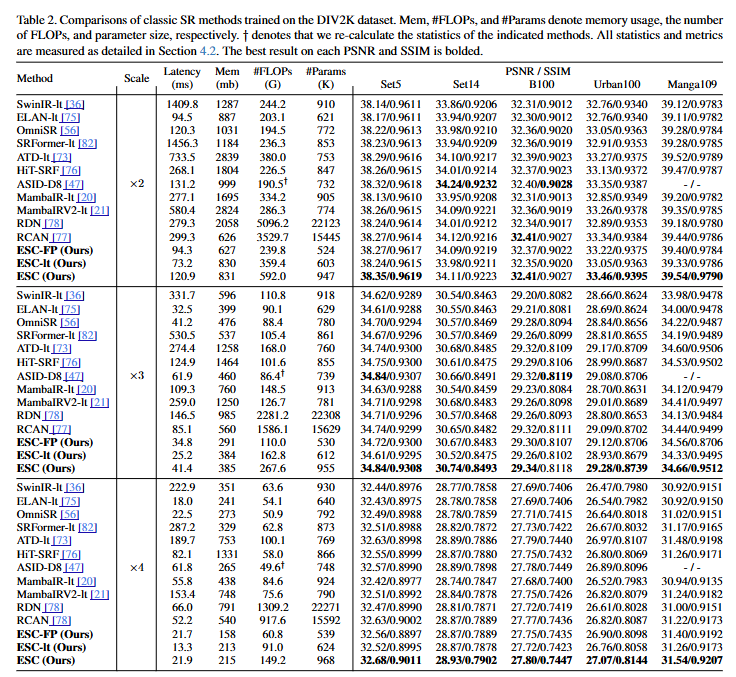
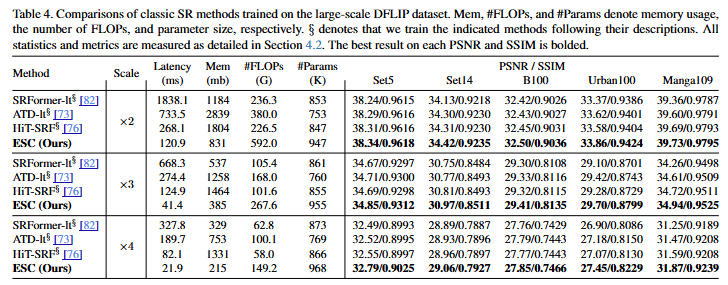



)
![[修訂版]Xenomai/IPIPE源代碼情景解析](http://pic.xiahunao.cn/[修訂版]Xenomai/IPIPE源代碼情景解析)
-> QCheckBox)





)
)
:構建自動化AI客服系統)





