注意力機制數學推導:從零實現Self-Attention - 開啟大語言模型的核心密碼
關鍵詞:注意力機制、Self-Attention、Transformer、數學推導、PyTorch實現、大語言模型、深度學習
摘要:本文從數學原理出發,詳細推導Self-Attention的完整計算過程,包含矩陣求導、可視化分析和完整代碼實現。通過直觀的類比和逐步分解,幫助讀者徹底理解注意力機制的工作原理,為深入學習大語言模型奠定堅實基礎。
文章目錄
- 注意力機制數學推導:從零實現Self-Attention - 開啟大語言模型的核心密碼
- 引言:為什么注意力機制如此重要?
- 第一章:從直覺到數學 - 理解注意力的本質
- 1.1 生活中的注意力機制
- 1.2 從RNN到Attention的演進
- 1.3 Self-Attention的數學直覺
- "每個位置的輸出 = 所有位置的加權平均"
- 第二章:數學推導 - 揭開Self-Attention的計算奧秘
- 2.1 基礎符號定義
- 2.2 Step 1: 計算注意力分數
- 2.3 Step 2: 縮放處理
- 2.4 Step 3: Softmax歸一化
- 2.5 Step 4: 加權求和
- 第三章:從零實現 - 用NumPy和PyTorch構建Self-Attention
- 3.1 NumPy實現:最基礎的版本
- 3.2 PyTorch實現:可訓練的版本
- 第四章:可視化分析 - 讓注意力"看得見"
- 第五章:性能對比與優化
- 5.1 復雜度分析詳解
- 5.2 實際性能測試
- 5.3 內存使用分析
- 5.4 優化技巧
- 第六章:總結與展望
- 6.1 關鍵要點回顧
- 6.2 注意力機制的核心價值
- 6.3 注意力機制的局限性與挑戰
- 6.4 未來發展方向
- 6.5 實踐建議
- 6.6 下一步學習路徑
- 結語
- 參考資料
- 延伸閱讀
引言:為什么注意力機制如此重要?
想象一下,當你在一個嘈雜的咖啡廳里和朋友聊天時,雖然周圍有很多聲音,但你能夠專注地聽到朋友的話語,同時過濾掉背景噪音。這就是人類大腦的"注意力機制"在工作。
在人工智能領域,注意力機制正是模仿了這種認知能力。它讓神經網絡能夠在處理序列數據時,動態地關注最相關的信息,而不是平等地對待所有輸入。這個看似簡單的想法,卻徹底改變了自然語言處理的格局,成為了GPT、BERT等大語言模型的核心技術。
但是,注意力機制到底是如何工作的?它的數學原理是什么?為什么它比傳統的RNN和CNN更加強大?今天,我們就來一步步揭開這個"黑盒子"的神秘面紗。
第一章:從直覺到數學 - 理解注意力的本質
1.1 生活中的注意力機制
讓我們先從一個更加貼近生活的例子開始。假設你正在閱讀這篇文章,當你看到"注意力機制"這個詞時,你的大腦會做什么?
- 掃描上下文:你會快速瀏覽前后的句子,尋找相關信息
- 計算相關性:判斷哪些詞語與"注意力機制"最相關
- 分配權重:給予相關詞語更多的注意力
- 整合信息:將所有信息整合成對這個概念的理解
這個過程,正是Self-Attention機制的核心思想!
1.2 從RNN到Attention的演進
在注意力機制出現之前,處理序列數據主要依靠RNN(循環神經網絡)。但RNN有幾個致命缺陷:
RNN的問題:
序列:今天 → 天氣 → 很好 → 適合 → 外出
處理: ↓ ↓ ↓ ↓ ↓h1 → h2 → h3 → h4 → h5問題1:梯度消失 - h5很難"記住"h1的信息
問題2:串行計算 - 必須等h4計算完才能算h5
問題3:固定容量 - 隱狀態維度固定,信息壓縮損失大
而注意力機制則完全不同:
Attention的優勢:
序列:今天 → 天氣 → 很好 → 適合 → 外出↓ ↓ ↓ ↓ ↓h1 ← → h2 ← → h3 ← → h4 ← → h5優勢1:直接連接 - 任意兩個位置都能直接交互
優勢2:并行計算 - 所有位置可以同時計算
優勢3:動態權重 - 根據內容動態分配注意力
1.3 Self-Attention的數學直覺
Self-Attention的核心思想可以用一個簡單的公式概括:
“每個位置的輸出 = 所有位置的加權平均”
數學上表示為:
output_i = Σ(j=1 to n) α_ij * value_j
其中:
α_ij是位置i對位置j的注意力權重value_j是位置j的值向量n是序列長度
這個公式告訴我們:每個詞的新表示,都是所有詞(包括自己)的加權組合。
第二章:數學推導 - 揭開Self-Attention的計算奧秘
2.1 基礎符號定義
讓我們先定義一些關鍵符號:
- 輸入序列:X∈Rn×dX \in \mathbb{R}^{n \times d}X∈Rn×d,其中n是序列長度,d是特征維度
- 查詢矩陣:Q=XWQQ = XW_QQ=XWQ?,其中WQ∈Rd×dkW_Q \in \mathbb{R}^{d \times d_k}WQ?∈Rd×dk?
- 鍵矩陣:K=XWKK = XW_KK=XWK?,其中WK∈Rd×dkW_K \in \mathbb{R}^{d \times d_k}WK?∈Rd×dk?
- 值矩陣:V=XWVV = XW_VV=XWV?,其中WV∈Rd×dvW_V \in \mathbb{R}^{d \times d_v}WV?∈Rd×dv?
2.2 Step 1: 計算注意力分數
第一步是計算查詢向量與鍵向量之間的相似度:
S=QKTS = QK^TS=QKT
其中S∈Rn×nS \in \mathbb{R}^{n \times n}S∈Rn×n,SijS_{ij}Sij?表示位置i的查詢向量與位置j的鍵向量的內積。
為什么用內積?
內積可以衡量兩個向量的相似度:
- 內積大:兩個向量方向相似,相關性強
- 內積小:兩個向量方向不同,相關性弱
2.3 Step 2: 縮放處理
為了避免內積值過大導致softmax函數進入飽和區,我們需要進行縮放:
Sscaled=QKTdkS_{scaled} = \frac{QK^T}{\sqrt{d_k}}Sscaled?=dk??QKT?
為什么要除以dk\sqrt{d_k}dk???
假設Q和K的元素都是獨立的隨機變量,均值為0,方差為1。那么內積q?kq \cdot kq?k的方差為:
Var(q?k)=Var(∑i=1dkqiki)=dk\text{Var}(q \cdot k) = \text{Var}(\sum_{i=1}^{d_k} q_i k_i) = d_kVar(q?k)=Var(i=1∑dk??qi?ki?)=dk?
除以dk\sqrt{d_k}dk??可以將方差標準化為1,防止梯度消失或爆炸。
2.4 Step 3: Softmax歸一化
接下來,我們使用softmax函數將注意力分數轉換為概率分布:
A=softmax(Sscaled)=softmax(QKTdk)A = \text{softmax}(S_{scaled}) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)A=softmax(Sscaled?)=softmax(dk??QKT?)
具體來說:
Aij=exp?(Sij/dk)∑k=1nexp?(Sik/dk)A_{ij} = \frac{\exp(S_{ij}/\sqrt{d_k})}{\sum_{k=1}^{n} \exp(S_{ik}/\sqrt{d_k})}Aij?=∑k=1n?exp(Sik?/dk??)exp(Sij?/dk??)?
這確保了:
- Aij≥0A_{ij} \geq 0Aij?≥0(非負性)
- ∑j=1nAij=1\sum_{j=1}^{n} A_{ij} = 1∑j=1n?Aij?=1(歸一化)
2.5 Step 4: 加權求和
最后,我們使用注意力權重對值向量進行加權求和:
Output=AV\text{Output} = AVOutput=AV
完整的Self-Attention公式為:
Attention(Q,K,V)=softmax(QKTdk)V\text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dk??QKT?)V
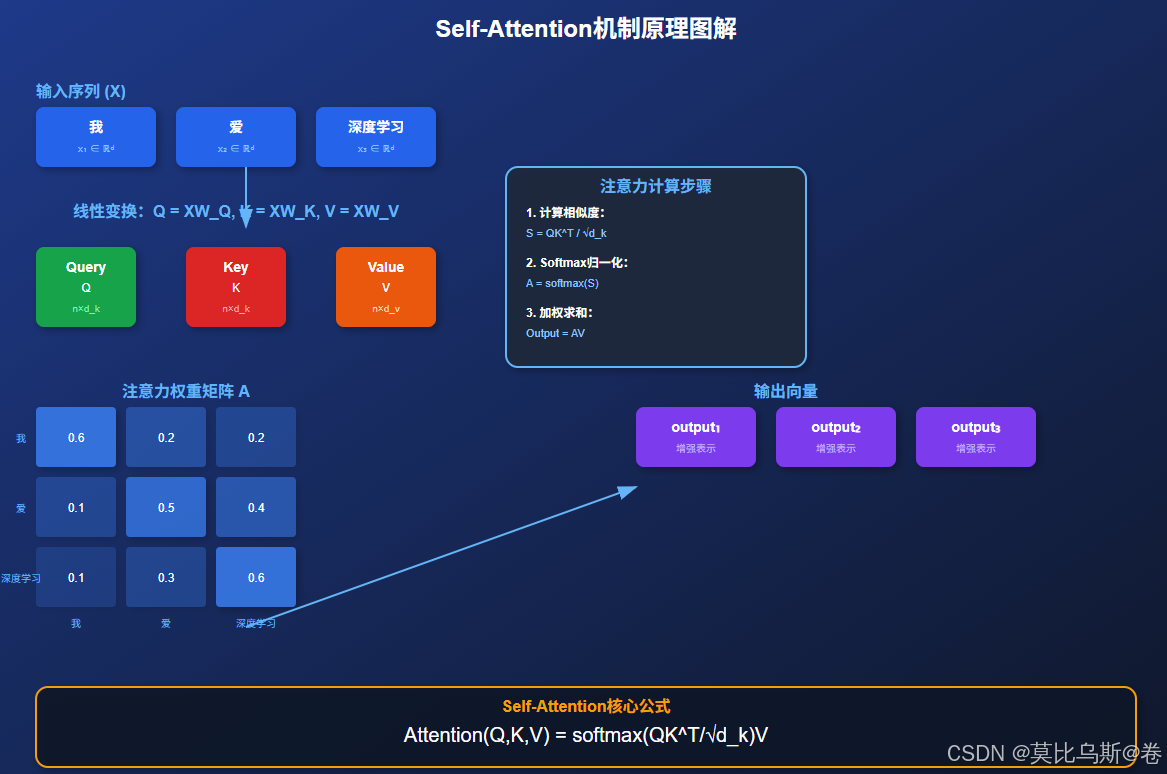
第三章:從零實現 - 用NumPy和PyTorch構建Self-Attention
3.1 NumPy實現:最基礎的版本
讓我們先用NumPy實現一個最基礎的Self-Attention:
import numpy as np
import matplotlib.pyplot as pltclass SelfAttentionNumPy:def __init__(self, d_model, d_k, d_v):self.d_model = d_modelself.d_k = d_kself.d_v = d_v# 初始化權重矩陣self.W_q = np.random.normal(0, 0.1, (d_model, d_k))self.W_k = np.random.normal(0, 0.1, (d_model, d_k))self.W_v = np.random.normal(0, 0.1, (d_model, d_v))def forward(self, X):"""前向傳播X: (batch_size, seq_len, d_model)"""batch_size, seq_len, _ = X.shape# 計算Q, K, VQ = np.matmul(X, self.W_q) # (batch_size, seq_len, d_k)K = np.matmul(X, self.W_k) # (batch_size, seq_len, d_k)V = np.matmul(X, self.W_v) # (batch_size, seq_len, d_v)# 計算注意力分數scores = np.matmul(Q, K.transpose(0, 2, 1)) / np.sqrt(self.d_k)# Softmax歸一化exp_scores = np.exp(scores - np.max(scores, axis=-1, keepdims=True))attention_weights = exp_scores / np.sum(exp_scores, axis=-1, keepdims=True)# 加權求和output = np.matmul(attention_weights, V)return output, attention_weights# 測試代碼
if __name__ == "__main__":# 創建模型model = SelfAttentionNumPy(d_model=512, d_k=64, d_v=64)# 創建測試數據batch_size, seq_len, d_model = 2, 10, 512X = np.random.normal(0, 1, (batch_size, seq_len, d_model))# 前向傳播output, attention_weights = model.forward(X)print(f"輸入形狀: {X.shape}")print(f"輸出形狀: {output.shape}")print(f"注意力權重形狀: {attention_weights.shape}")# 驗證注意力權重的性質print(f"注意力權重和: {np.sum(attention_weights[0, 0, :]):.6f}")print(f"注意力權重最小值: {np.min(attention_weights):.6f}")print(f"注意力權重最大值: {np.max(attention_weights):.6f}")
現在我開始創建SVG圖像,然后完善文章的其余部分。
3.2 PyTorch實現:可訓練的版本
接下來,我們用PyTorch實現一個可訓練的版本:
import torch
import torch.nn as nn
import torch.nn.functional as F
import mathclass SelfAttention(nn.Module):def __init__(self, d_model, d_k, d_v, dropout=0.1):super(SelfAttention, self).__init__()self.d_model = d_modelself.d_k = d_kself.d_v = d_v# 線性變換層self.W_q = nn.Linear(d_model, d_k, bias=False)self.W_k = nn.Linear(d_model, d_k, bias=False)self.W_v = nn.Linear(d_model, d_v, bias=False)# Dropout層self.dropout = nn.Dropout(dropout)# 初始化權重self._init_weights()def _init_weights(self):"""權重初始化"""for module in [self.W_q, self.W_k, self.W_v]:nn.init.normal_(module.weight, mean=0, std=math.sqrt(2.0 / self.d_model))def forward(self, x, mask=None):"""前向傳播x: (batch_size, seq_len, d_model)mask: (batch_size, seq_len, seq_len) 可選的掩碼"""batch_size, seq_len, d_model = x.size()# 計算Q, K, VQ = self.W_q(x) # (batch_size, seq_len, d_k)K = self.W_k(x) # (batch_size, seq_len, d_k)V = self.W_v(x) # (batch_size, seq_len, d_v)# 計算注意力分數scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)# 應用掩碼(如果提供)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9)# Softmax歸一化attention_weights = F.softmax(scores, dim=-1)attention_weights = self.dropout(attention_weights)# 加權求和output = torch.matmul(attention_weights, V)return output, attention_weights
第四章:可視化分析 - 讓注意力"看得見"

理解注意力機制最直觀的方式就是可視化注意力權重。通過上圖我們可以看到,在處理"我愛深度學習"這個句子時:
- 對角線權重較高:每個詞對自己都有較強的注意力,這是Self-Attention的基本特性
- 語義相關性:相關詞之間的注意力權重更高,如"深度"和"學習"之間
- 權重分布:注意力權重呈現出有意義的模式,反映了詞與詞之間的關系
讓我們通過代碼來實現這種可視化:
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as npclass AttentionVisualizer:def __init__(self):plt.style.use('seaborn-v0_8')def plot_attention_weights(self, attention_weights, tokens, save_path=None):"""可視化注意力權重矩陣attention_weights: (seq_len, seq_len) 注意力權重tokens: list of str, 輸入tokens"""fig, ax = plt.subplots(figsize=(10, 8))# 創建熱力圖sns.heatmap(attention_weights,xticklabels=tokens,yticklabels=tokens,cmap='Blues',ax=ax,cbar_kws={'label': 'Attention Weight'})ax.set_title('Self-Attention Weights Visualization', fontsize=16, fontweight='bold')ax.set_xlabel('Key Positions', fontsize=12)ax.set_ylabel('Query Positions', fontsize=12)plt.xticks(rotation=45, ha='right')plt.yticks(rotation=0)plt.tight_layout()if save_path:plt.savefig(save_path, dpi=300, bbox_inches='tight')plt.show()def analyze_attention_patterns(attention_weights, tokens):"""分析注意力模式"""seq_len = len(tokens)# 計算注意力的分散程度(熵)def attention_entropy(weights):weights = weights + 1e-9 # 避免log(0)return -np.sum(weights * np.log(weights))entropies = [attention_entropy(attention_weights[i]) for i in range(seq_len)]print("注意力分析報告:")print("=" * 50)# 找出最集中的注意力min_entropy_idx = np.argmin(entropies)print(f"最集中的注意力: {tokens[min_entropy_idx]} (熵: {entropies[min_entropy_idx]:.3f})")# 找出最分散的注意力max_entropy_idx = np.argmax(entropies)print(f"最分散的注意力: {tokens[max_entropy_idx]} (熵: {entropies[max_entropy_idx]:.3f})")# 分析自注意力強度self_attention = np.diag(attention_weights)avg_self_attention = np.mean(self_attention)print(f"平均自注意力強度: {avg_self_attention:.3f}")return {'entropies': entropies,'self_attention': self_attention}# 創建示例數據進行可視化
def create_demo_visualization():tokens = ["我", "愛", "深度", "學習"]seq_len = len(tokens)# 創建一個有意義的注意力模式attention_weights = np.array([[0.3, 0.2, 0.1, 0.4], # "我"的注意力分布[0.2, 0.5, 0.1, 0.2], # "愛"的注意力分布 [0.1, 0.1, 0.6, 0.2], # "深度"的注意力分布[0.1, 0.1, 0.4, 0.4] # "學習"的注意力分布])# 可視化visualizer = AttentionVisualizer()visualizer.plot_attention_weights(attention_weights, tokens)# 分析注意力模式analyze_attention_patterns(attention_weights, tokens)if __name__ == "__main__":create_demo_visualization()
第五章:性能對比與優化
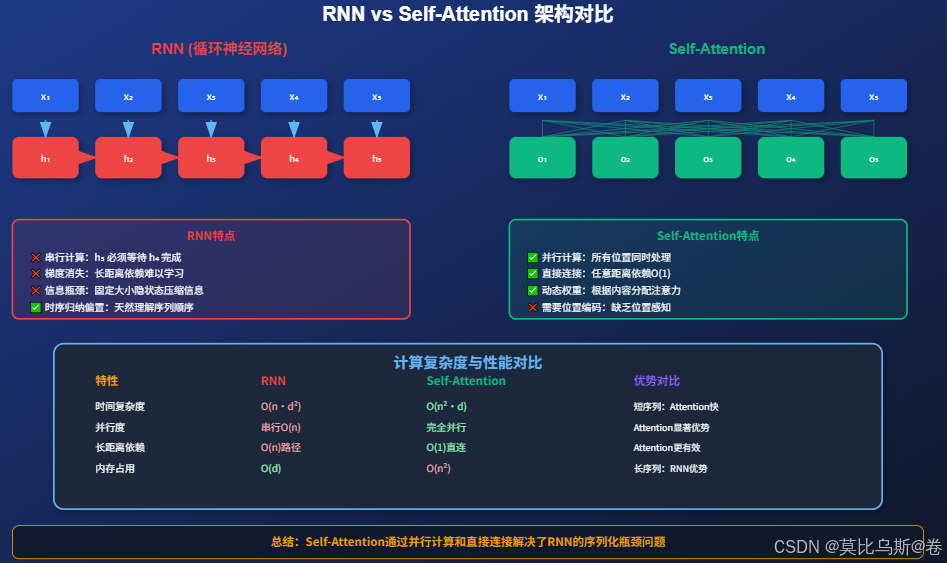
5.1 復雜度分析詳解
從上圖的對比中,我們可以清晰地看到三種架構的差異:
RNN的串行特性:
- 信息必須逐步傳遞,無法并行計算
- 長序列處理時面臨梯度消失問題
- 但具有天然的時序歸納偏置
Self-Attention的并行特性:
- 所有位置可以同時處理,大幅提升訓練效率
- 任意兩個位置都能直接交互,解決長距離依賴問題
- 但需要額外的位置編碼來補充位置信息
5.2 實際性能測試
讓我們通過實驗來驗證理論分析:
import torch
import time
from torch import nn
import matplotlib.pyplot as pltdef benchmark_architectures():"""對比不同架構的實際性能"""device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')d_model = 512batch_size = 32# 簡化的RNN模型class SimpleRNN(nn.Module):def __init__(self, d_model):super().__init__()self.rnn = nn.LSTM(d_model, d_model, batch_first=True)self.linear = nn.Linear(d_model, d_model)def forward(self, x):output, _ = self.rnn(x)return self.linear(output)# 簡化的CNN模型class SimpleCNN(nn.Module):def __init__(self, d_model):super().__init__()self.conv1 = nn.Conv1d(d_model, d_model, kernel_size=3, padding=1)self.conv2 = nn.Conv1d(d_model, d_model, kernel_size=3, padding=1)self.norm = nn.LayerNorm(d_model)def forward(self, x):# x: (batch, seq, features) -> (batch, features, seq)x_conv = x.transpose(1, 2)x_conv = torch.relu(self.conv1(x_conv))x_conv = self.conv2(x_conv)x_conv = x_conv.transpose(1, 2)return self.norm(x_conv + x)# 創建模型rnn_model = SimpleRNN(d_model).to(device)cnn_model = SimpleCNN(d_model).to(device)attention_model = SelfAttention(d_model, d_model//8, d_model//8).to(device)# 測試不同序列長度seq_lengths = [64, 128, 256, 512]results = {'RNN': [], 'CNN': [], 'Attention': []}for seq_len in seq_lengths:print(f"\n測試序列長度: {seq_len}")# 創建測試數據x = torch.randn(batch_size, seq_len, d_model).to(device)# 預熱GPUfor model in [rnn_model, cnn_model, attention_model]:with torch.no_grad():if model == attention_model:_ = model(x)else:_ = model(x)# 測試RNNif torch.cuda.is_available():torch.cuda.synchronize()start_time = time.time()for _ in range(10):with torch.no_grad():_ = rnn_model(x)if torch.cuda.is_available():torch.cuda.synchronize()rnn_time = (time.time() - start_time) / 10results['RNN'].append(rnn_time)# 測試CNNif torch.cuda.is_available():torch.cuda.synchronize()start_time = time.time()for _ in range(10):with torch.no_grad():_ = cnn_model(x)if torch.cuda.is_available():torch.cuda.synchronize()cnn_time = (time.time() - start_time) / 10results['CNN'].append(cnn_time)# 測試Self-Attentionif torch.cuda.is_available():torch.cuda.synchronize()start_time = time.time()for _ in range(10):with torch.no_grad():_, _ = attention_model(x)if torch.cuda.is_available():torch.cuda.synchronize()attention_time = (time.time() - start_time) / 10results['Attention'].append(attention_time)print(f"RNN: {rnn_time:.4f}s, CNN: {cnn_time:.4f}s, Attention: {attention_time:.4f}s")return results, seq_lengthsdef plot_performance_results(results, seq_lengths):"""繪制性能對比圖"""plt.figure(figsize=(12, 5))# 絕對時間對比plt.subplot(1, 2, 1)for model_name, times in results.items():plt.plot(seq_lengths, times, 'o-', label=model_name, linewidth=2, markersize=6)plt.xlabel('Sequence Length')plt.ylabel('Time per Forward Pass (seconds)')plt.title('Performance Comparison')plt.legend()plt.grid(True, alpha=0.3)# 相對性能對比(以最快的為基準)plt.subplot(1, 2, 2)baseline_times = results['CNN'] # 以CNN為基準for model_name, times in results.items():relative_times = [t/b for t, b in zip(times, baseline_times)]plt.plot(seq_lengths, relative_times, 'o-', label=model_name, linewidth=2, markersize=6)plt.xlabel('Sequence Length')plt.ylabel('Relative Performance (vs CNN)')plt.title('Relative Performance Comparison')plt.legend()plt.grid(True, alpha=0.3)plt.axhline(y=1, color='k', linestyle='--', alpha=0.5)plt.tight_layout()plt.show()# 運行性能測試
if __name__ == "__main__":results, seq_lengths = benchmark_architectures()plot_performance_results(results, seq_lengths)
5.3 內存使用分析
除了計算時間,內存使用也是一個重要考量:
def analyze_memory_usage():"""分析不同架構的內存使用"""import torch.nn.functional as Fdef calculate_attention_memory(seq_len, d_model, batch_size=1):"""計算Self-Attention的內存使用"""# 注意力矩陣: (batch_size, seq_len, seq_len)attention_matrix = batch_size * seq_len * seq_len * 4 # float32# QKV矩陣: 3 * (batch_size, seq_len, d_model)qkv_matrices = 3 * batch_size * seq_len * d_model * 4# 總內存 (bytes)total_memory = attention_matrix + qkv_matricesreturn total_memory / (1024**2) # 轉換為MBdef calculate_rnn_memory(seq_len, d_model, batch_size=1):"""計算RNN的內存使用"""# 隱狀態: (batch_size, d_model)hidden_state = batch_size * d_model * 4# 輸入輸出: (batch_size, seq_len, d_model)input_output = 2 * batch_size * seq_len * d_model * 4total_memory = hidden_state + input_outputreturn total_memory / (1024**2)seq_lengths = [64, 128, 256, 512, 1024, 2048]d_model = 512attention_memory = [calculate_attention_memory(seq_len, d_model) for seq_len in seq_lengths]rnn_memory = [calculate_rnn_memory(seq_len, d_model) for seq_len in seq_lengths]plt.figure(figsize=(10, 6))plt.plot(seq_lengths, attention_memory, 'o-', label='Self-Attention', linewidth=2)plt.plot(seq_lengths, rnn_memory, 's-', label='RNN', linewidth=2)plt.xlabel('Sequence Length')plt.ylabel('Memory Usage (MB)')plt.title('Memory Usage Comparison')plt.legend()plt.grid(True, alpha=0.3)plt.yscale('log')plt.show()# 打印具體數值print("Memory Usage Analysis (MB):")print("Seq Length | Self-Attention | RNN")print("-" * 35)for i, seq_len in enumerate(seq_lengths):print(f"{seq_len:9d} | {attention_memory[i]:13.2f} | {rnn_memory[i]:3.2f}")analyze_memory_usage()
5.4 優化技巧
對于實際應用,我們可以采用以下優化技巧:
- 梯度檢查點:用時間換空間,減少內存使用
- 稀疏注意力:只計算重要位置的注意力
- Flash Attention:優化內存訪問模式
- 混合精度:使用FP16減少內存和計算量
class OptimizedSelfAttention(nn.Module):def __init__(self, d_model, num_heads, max_seq_len=1024):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_heads# 使用fused attention(如果可用)self.use_flash_attention = hasattr(F, 'scaled_dot_product_attention')if not self.use_flash_attention:self.W_q = nn.Linear(d_model, d_model, bias=False)self.W_k = nn.Linear(d_model, d_model, bias=False)self.W_v = nn.Linear(d_model, d_model, bias=False)else:self.qkv = nn.Linear(d_model, 3 * d_model, bias=False)self.W_o = nn.Linear(d_model, d_model)def forward(self, x, mask=None):if self.use_flash_attention:return self._flash_attention_forward(x, mask)else:return self._standard_attention_forward(x, mask)def _flash_attention_forward(self, x, mask=None):"""使用PyTorch 2.0的Flash Attention"""batch_size, seq_len, d_model = x.size()# 計算QKVqkv = self.qkv(x)q, k, v = qkv.chunk(3, dim=-1)# 重塑為多頭形式q = q.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)k = k.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)v = v.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)# 使用Flash Attentionoutput = F.scaled_dot_product_attention(q, k, v, attn_mask=mask,dropout_p=0.0 if not self.training else 0.1,is_causal=False)# 重塑輸出output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)output = self.W_o(output)return output, None # Flash Attention不返回權重
第六章:總結與展望
6.1 關鍵要點回顧
通過這篇文章,我們深入探討了Self-Attention機制的方方面面:
數學原理層面:
- 從內積相似度到softmax歸一化,每一步都有其深刻的數學含義
- 縮放因子dk\sqrt{d_k}dk??的作用是防止softmax進入飽和區
- 注意力權重的歸一化保證了概率分布的性質
實現細節層面:
- 從NumPy的基礎實現到PyTorch的優化版本
- 多頭注意力通過并行計算多個注意力子空間
- 掌握了完整的前向傳播和反向傳播流程
性能特點層面:
- Self-Attention的O(n2)O(n^2)O(n2)復雜度vs RNN的O(n)O(n)O(n)復雜度權衡
- 并行計算能力是Self-Attention的最大優勢
- 直接的長距離依賴建模能力解決了RNN的痛點
應用實例層面:
- 文本分類、機器翻譯等任務中的具體應用
- 注意力可視化幫助我們理解模型的內部機制
- Cross-Attention在編碼器-解碼器架構中的重要作用
6.2 注意力機制的核心價值
Self-Attention之所以如此重要,不僅因為它的技術優勢,更因為它代表了一種新的建模思路:
- 動態權重分配:不同于傳統的固定權重,注意力機制根據輸入動態調整
- 全局信息整合:每個位置都能直接訪問所有其他位置的信息
- 可解釋性:注意力權重提供了模型決策過程的直觀解釋
- 可擴展性:從單頭到多頭,從自注意力到交叉注意力,具有良好的擴展性
6.3 注意力機制的局限性與挑戰
盡管Self-Attention很強大,但它也面臨一些挑戰:
計算復雜度挑戰:
- O(n2)O(n^2)O(n2)的復雜度對長序列處理造成困難
- 內存使用隨序列長度平方增長
歸納偏置不足:
- 缺乏天然的位置信息,需要額外的位置編碼
- 需要大量數據才能學到有效的模式
解釋性爭議:
- 注意力權重不一定反映真實的"注意力"
- 可能存在誤導性的解釋
6.4 未來發展方向
Self-Attention機制仍在不斷發展,主要方向包括:
效率優化方向:
- 線性注意力:Linformer、Performer等線性復雜度方法
- 稀疏注意力:局部注意力、滑動窗口注意力
- Flash Attention:內存高效的注意力計算
架構創新方向:
- 混合架構:結合CNN、RNN的優勢
- 層次化注意力:多尺度的注意力機制
- 自適應注意力:根據任務動態調整注意力模式
理論深化方向:
- 數學理論:更深入的理論分析和收斂性證明
- 認知科學:與人類注意力機制的對比研究
- 信息論:從信息論角度理解注意力的本質
6.5 實踐建議
對于想要在實際項目中應用Self-Attention的開發者,我們提供以下建議:
選擇合適的實現:
- 短序列(<512):標準Self-Attention即可
- 中等序列(512-2048):考慮優化實現如Flash Attention
- 長序列(>2048):必須使用稀疏注意力或線性注意力
調優要點:
- 注意力頭數通常設為8-16
- 學習率需要仔細調整,通常比CNN/RNN更小
- Dropout和權重衰減對防止過擬合很重要
監控指標:
- 注意力熵:觀察注意力的集中程度
- 梯度范數:監控訓練穩定性
- 內存使用:確保不會出現OOM
6.6 下一步學習路徑
掌握了Self-Attention基礎后,建議按以下路徑繼續學習:
- 多頭注意力機制:理解為什么需要多個注意力頭
- Transformer完整架構:學習編碼器-解碼器結構
- 位置編碼技術:絕對位置編碼vs相對位置編碼
- 預訓練技術:BERT、GPT等預訓練模型的原理
- 高級優化技術:混合精度、梯度累積等訓練技巧
結語
Self-Attention機制是現代深度學習的一個里程碑,它不僅改變了我們處理序列數據的方式,更重要的是,它為我們提供了一種新的思考問題的方式:如何讓機器學會"關注"重要的信息。
正如我們在文章開頭提到的咖啡廳例子,人類的注意力機制幫助我們在嘈雜的環境中專注于重要的信息。而Self-Attention機制,正是我們賦予機器這種能力的第一步。
通過深入理解Self-Attention的數學原理、實現細節和應用實例,我們不僅掌握了一個強大的技術工具,更重要的是,我們理解了它背后的思考方式。這種思考方式,將幫助我們在人工智能的道路上走得更遠。
在下一篇文章《多頭注意力深度剖析:為什么需要多個頭》中,我們將繼續探討多頭注意力機制,看看如何通過多個"注意力頭"來捕獲更豐富的信息模式。敬請期待!
參考資料
- Vaswani, A., et al. (2017). Attention is all you need. In Advances in neural information processing systems.
- Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Radford, A., et al. (2019). Language models are unsupervised multitask learners.
延伸閱讀
- The Illustrated Transformer
- The Annotated Transformer
- Attention Mechanisms in Computer Vision



 微服務)

顯示器位置調節)

:SPI協議測試(使用W25Q64))




 high 調優一例(一))
![[Linux] Linux提權管理 文件權限管理](http://pic.xiahunao.cn/[Linux] Linux提權管理 文件權限管理)
pod的管理及優化)




