MySQL的安裝就不講述了, 本篇文章著重講解sql優化
本篇是對B站顏群老師視頻講解的筆記梳理, 感興趣的可以去看下老師的原視頻: SQL優化
MySQL原理
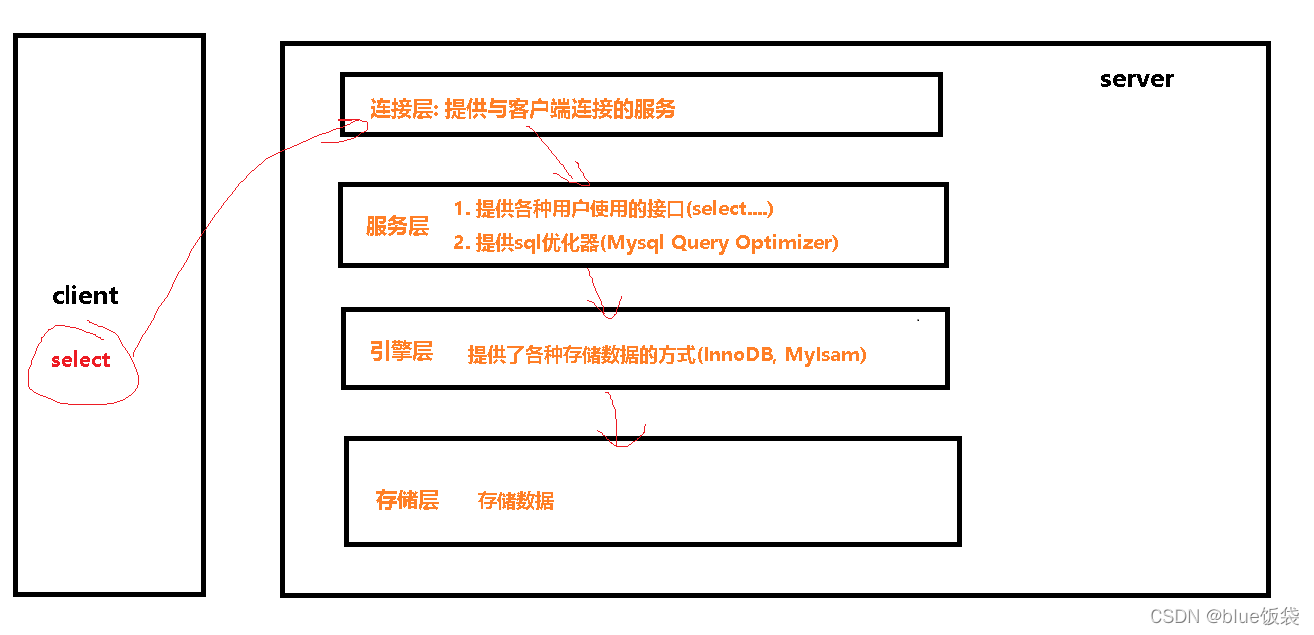
1. MySQL邏輯分層: 連接層->服務層->引擎層->存儲層(如圖)
- 連接層:提供與客戶端連接的服務
- 服務層:提供各種用戶使用的接口(select…)/提供各種sql優化器(mysql query optimizer)
- 引擎層:提供了各種存儲數據的方式(InnoDB和MyIsam)
- 存儲層:存儲數據
- InnoDB引擎(默認使用): 事務優先, 適合高并發操作, 采用的是行鎖
- MyISAM: 性能優先, 采用的是表鎖
2. 查看數據庫引擎
支持哪些引擎的命令
show engines;
查看當前使用的引擎
show variables like '%storage_engine%';
指定數據庫對象的引擎
create table tb(....)
ENGINE=MYISAM AUTO_INCREMENT=1
DEFAULT CHARSET=UTF8MB4;
3.SQL優化
3.1 原因: 性能低, 執行時間太長, 等待時間太久, SQL語句欠佳(連接查詢), 索引失效, 服務器參數設置不合理(緩沖, 線程數…)
- SQL的編寫過程:
select distinct...from...join...on...where...group by...having...order by...limit...
- SQL的解析過程
from...on...join...where...group by...having...select distinct...order by...limit...
- SQL優化,主要是優化索引
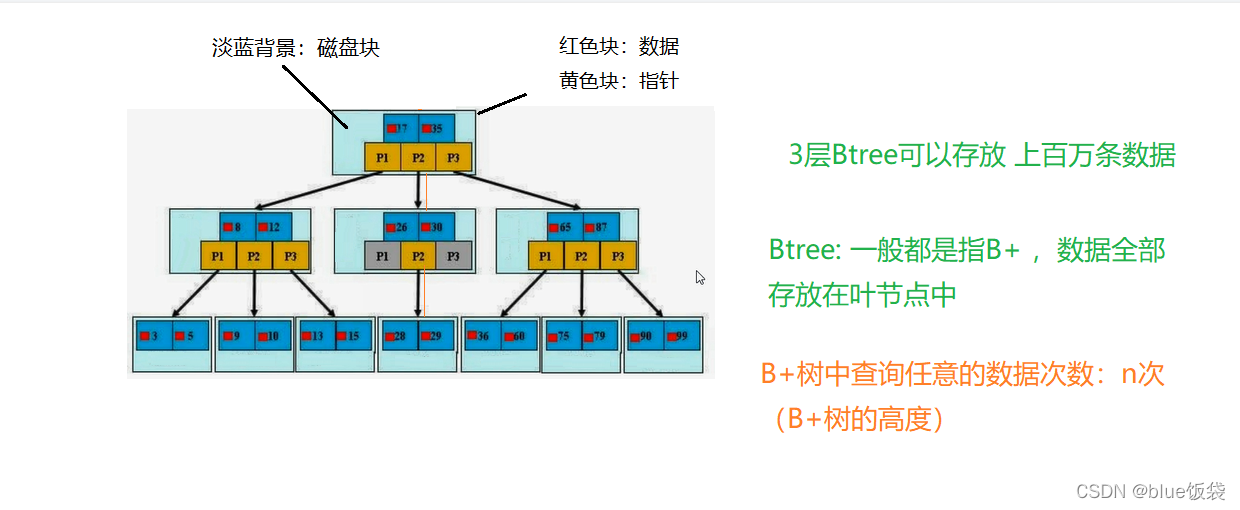
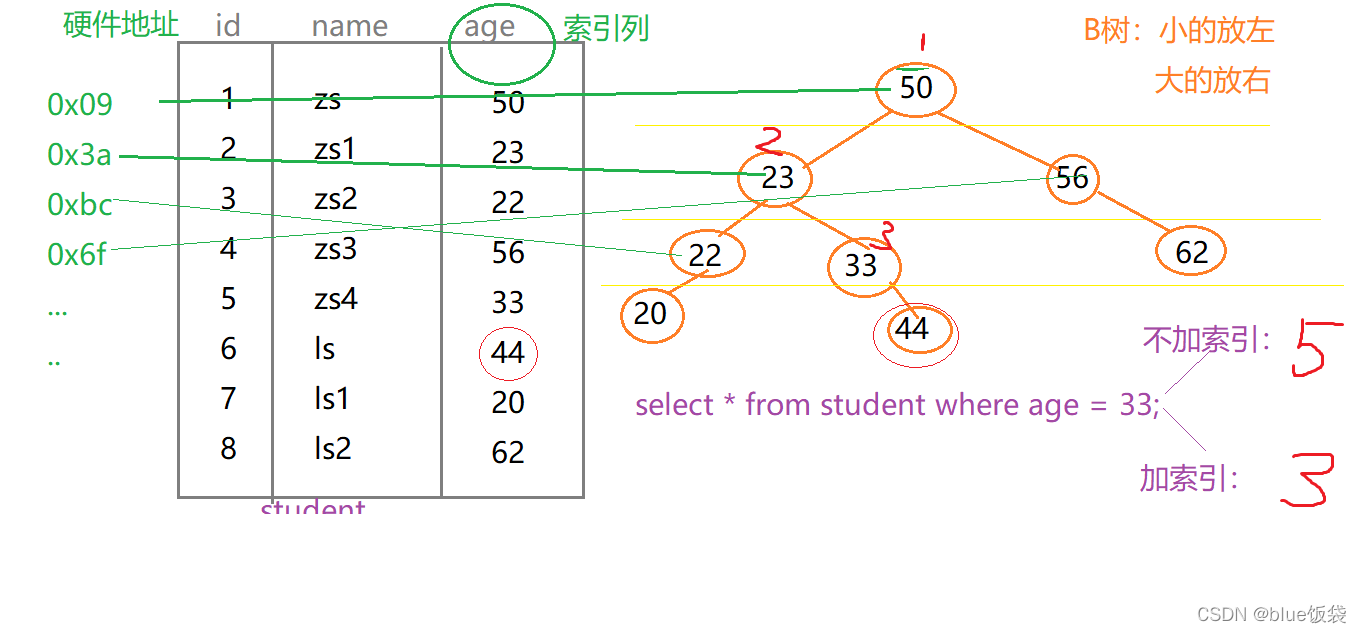
索引相當于書的目錄, 是幫助mysql高效獲取數據的數據結構(樹: B樹, Hash樹)
- 索引的弊端
- 索引本身很大, 可以存放在內存/硬盤(一般為硬盤)
- 索引不是所有情況都適用(少量數據/頻繁更新的字段/很少使用的字段并不適合索引)
- 索引會降低增刪改的效率
- 索引的優勢
- 提高查詢效率, 降低IO使用率
- 降低CPU使用率(…order by age desc, 因為B樹索引本身就是一個好排序的結構, 因此可以在排序時直接使用)
4. 索引
4.1 索引分類
- 主鍵索引: 不能重復, 不能是null, 是一種約束, 例如id
- 唯一索引: 不能重復, 可以是null, 是一種索引
- 單值索引: 單列, 一個表可以有多個單值索引
- 復合索引: 多個列構成的索引, 相當于二級目錄
附: 主鍵索引和唯一索引的區別
- 主鍵是一種約束, 而唯一索引是一種索引, 二者在本質上市不同的
- 主鍵可以被其他表作為外鍵引用, 而唯一索引不能
- 主鍵列不允許空值, 唯一索引列允許空值
- 一張表里可以多個唯一索引, 但是只有一個主鍵
- 主鍵創建后一定包含一個唯一索引, 而唯一索引不一定是主鍵
4.2 創建索引
- 方式一: create 索引類型 索引名 on 表(字段)
單值索引 : create index dept_index on tb(dept);
唯一索引: create unique index name_index on tb(name);
復合索引: create index dept_name_index on tb(dept,name);
- 方式二: alter table 表名 索引類型 索引名(字段)
單值索引: alter table tb add index dept_index(dept);
唯一索引: alter table tb add unique index name_index(name);
復合索引: alter table tb add index dept_name_index(dept,name);
4.3 刪除索引
drop index 索引名 on 表名;
drop index name_index on tb;
4.4 查詢索引
show index from 表名;
show index from 表名 \G
5. SQL性能問題
- 分析SQL的執行計劃: explain, 可以模擬sql優化器執行SQL語句, 從而讓開發人員知道自己編寫的SQL狀況
- MySQL查詢優化器會干擾我們的優化
- 優化方法, 官網https://dev.mysql.com/doc/refman/8.0/en/optimize-overview.html
- 查詢執行計劃: explain + SQL語句, 如圖:

- 字段詳解
id: 編號
select_type: 查詢類型
table: 表名
partitions: 分區
type: 類型
possible_keys: 預測使用到的索引
key: 實際使用到的索引
key_len: 實際使用到的索引長度
ref: 表之間的引用
rows: 通過索引查詢到的數據量
filtered: 返回結果的行數占讀取行數的百分比
Extra: 額外的信息
5.1 準備數據
課程表
create table course(cid int(3),cname varchar(20),tid int(3)
);
教師表
create table teacher(tid int(3),tname varchar(20),tcid int(3)
);
教師信息表
create table teacher_card(tcid int(3),tcdesc varchar(200)
);
插入數據
insert into course values(1,'java',1);
insert into course values(2,'html',1);
insert into course values(3,'sql',2);
insert into course values(4,'web',3);insert into teacher values(1,'tz',1);
insert into teacher values(2,'tw',2);
insert into teacher values(3,'tl',3);insert into teacher_card values(1,'tzdesc') ;
insert into teacher_card values(2,'twdesc') ;
insert into teacher_card values(3,'tldesc') ;
5.2 執行過程分析
5.2.1 id
select tc.tcdesc from course c join teacher t on c.tid = t.tid join teacher_card tc on t.tcid = tc.tcid where c.cid = 2 or tc.tcid = 3

id值相同, 從上往下順序執行, t - c -tc
表的執行順序, 因數量的個數改變而改變的原因: 笛卡爾積
a b c
4 3 2 = 2*3*4 = 6*4 = 24= 3*4*2 = 12*2 = 24
查詢原則: 數據小的表, 優先查詢
id值不同: id值越大, 越優先查詢(本質: 在嵌套時, 先查內層, 再查外層)
子查詢 + 多表: 查詢教授SQL課程的老師的描述
-- 查詢教授sql的老師tid
select tid from course where cname = 'sql';
-- 查詢該老師的tcid
select tcid from teacher where tid = (select tid from course where cname = 'sql');
-- 查詢該tcid對應老師的描述
select tcdesc from teacher_card where tcid = (select tcid from teacher where tid = (select tid from course where cname = 'sql'));

id值有相同, 又有不同; id值越大越優先, id值相同, 從上往下順序執行
5.2.2 select_type: 查詢類型
PRIMARY: 包含子查詢SQL中的主查詢(最外層)
SUBQUERY:包含子查詢SQL中的子查詢(非最外層)
SIMPLE:簡單查詢(不包含子查詢, union)
DERIVED: 衍生查詢(使用到了臨時表)
UNION:
- 在from子查詢中只有一張表
explain select cr.cname from(select * from course where tid in (1,2)) cr;
- 在from子查詢中, 如果有table1 union table2, 則table1就是derived, table2就是union
explain select cr.cname from (select * from course where tid = 1 union select * from course where tid = 2) cr;

UNION RESULT:告知開發人員, 哪些表之間存在union查詢
5.2.3 type: 索引類型, 類型
級別對比: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
其中, system,const只是理想情況, 實際能達到ref > range
5.2.3.1 system(忽略): 只有一條數據的系統表, 或衍生表只有一條數據的主查詢
5.2.3.2 const: 僅僅能查到一條數據的sql, 用于primary key 或 unique 索引(類型與索引類型有關)
-- 建表插入數據
create table test01(tid int(3),tname varchar(20)
);insert into test01 values(1,'a');
commit;
-- 增加索引并解析
alter table test01 add constraint tid_pk primary key(tid) ;
explain select * from (select * from test01) t where tid = 1;

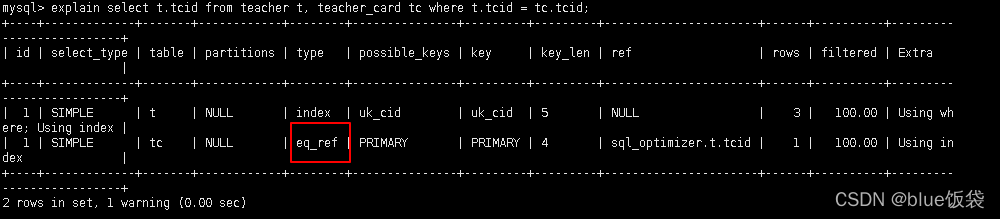
5.2.3.3 eq_ref: 唯一性索引, 對于每個索引鍵的查詢, 返回匹配唯一行數據(有且只有1個, 不能多, 不能0), 常見于唯一索引和主鍵索引
lalter table teacher_card add constraint pk_tcid primary key(tcid);
alter table teacher add constraint uk_tcid unique index(tcid);
explain select t.tcid from teacher t, teacher_card tc where t.tcid = tc.tcid;
以上SQL, 用到的索引是t.tcid, 即teacher表中的tcid字段;
除非teacher表的數據個數與連接查詢的數據個數一致, 則有可能滿足eq_ref級別, 否則無法滿足
5.2.3.4 ref: 非唯一性索引, 對于每個索引鍵的查詢, 返回匹配的所有行(0條或多條)
準備數據:
insert into teacher values(4,'tz',4);
insert into teacher_card values(4,'tz222');
測試:
alter table teacher add index index_name(tname);
explain select * from teacher where tname = 'tz';

5.2.3.5 range: 檢索指定范圍的行, where后面是一個范圍查詢(between, >, <, >=, <=)
alter table teacher add index tid_index(tid);
explain select * from teacher t where t.tid in (1,2);
explain select * from teacher t where t.tid < 3;
特殊: in有時候會失效, 從而轉為無索引 all


5.2.3.6 index: 查詢全部索引中數據
explain select tid from teacher;
tid是索引, 只需要掃描索引表,不需要所有表中的數據

5.2.3.7 all: 查詢全部表中的數據
explain select cid from course;
cid 不是索引, 需要全表掃描

5.2.4 possible_keys: 可能用到的索引, 是一種預測, 不準
alter table course add index index_cname_index(cname);
如果possible_keys/key是null, 則說明沒用索引
explain select tc.tcdesc from teacher_card tc, course c, teacher t where c.tid = t.tid and t.tcid = tc.tcid and c.cname = 'sql';

5.2.5 key: 實際使用到的索引(具體可參考上面的)
5.2.6 key_len: 索引的長度
作用: 用于判斷復合索引是否被完全使用(a,b,c)
create table test_kl(name char(20) not null default ''
);
alter table test_kl add index index_name(name);
explain select * from test_kl where name = '';

在utf8mb4編碼中, 一個字符占4個字節
alter table test_kl add column name1 char(20); -- name1可以為null
-- 如果索引字段可以為null, 則會使用1個字節用于標識
explain select * from test_kl where name1 = ''; -- null
-- 增加一個符合索引
alter table test_kl add index name_name1_index(name,name1);
explain select * from test_kl where name1 = ''; -- null
explain select * from test_kl where name = ''; -- 80
-- 可以為null
alter table test_kl add column name2 varchar(20);
alter table test_kl add index name2_index(name2);
-- 83 = 20 * 4 = 80 + 1(null) + 2(2個字節標識可變長度)
explain select * from test_kl where name2 = '';
5.2.7 ref: 注意與type中的ref值區分
作用: 指明當前所參照的字段
select ...where a.c = b.x;(其中b.x可以是常量, const)
alter table course add index tid_index(tid);
explain select * from course c, teacher t where c.tid = t.tid and t.tname = 'tw';

5.2.8 rows: 被索引優化查詢的數據條數(實際通過索引而查詢到的數據條數)
explain select * from course c, teacher t where c.tid = t.tid and t.tname = 'tz';

5.2.9 Extra: 額外的
5.2.9.1 using filesort: 性能消耗大, 需要額外的一次排序(查詢), 常見于order by語句中
排序:先查詢
單值索引
create table test02(a1 char(3),a2 char(3),a3 char(3),index idx_a1(a1),index idx_a2(a2),index idx_a3(a3)
);explain select * from test02 where a1 = '' order by a1;

explain select * from test02 where a1 = '' order by a2; -- using filesort
小結: 避免using filesort 的出現, where哪些字段, 就order by哪些字段
復合索引
drop index idx_a1 on test02;
drop index idx_a2 on test02;
drop index idx_a3 on test02;
alter table test02 add index idx_a1_a2_a3(a1,a2,a3);
explain select * from test02 where a1 = '' order by a3; -- 跨列使用
explain select * from test02 where a2 = '' order by a3; -- 跨列使用
explain select * from test02 where a1 = '' order by a2; -- 有序使用
explain select * from test02 where a2 = '' order by a1; -- 無序使用
小結: 避免using filesort的方法, where和order by 按照復合索引的順序使用, 不要跨列或者無序使用
5.2.9.2 using temporary: 性能損耗大, 用到了臨時表, 一般出現在group by語句中
explain select a1 from test02 where a1 in ('1','2','3') group by a1;
explain select a1 from test02 where a1 in ('1','2','3') group by a2; -- using temporary

規避原則: 查詢哪些列, 就根據哪些列group by
5.2.9.3 using index: 性能提升, 索引覆蓋
原因: 不讀取源文件, 只從索引文件中獲取數據(不需要回表查詢), 只要使用到的列全部在索引中, 就是索引覆蓋
例如: test02表中有一個復合索引(a1, a2, a3)
explain select a1,a2 from test02 where a1 = '' or a2 = ''; -- using index
drop index idx_a1_a2_a3 on test02;
alter table test02 add index idx_a1_a2(a1,a2);
explain select a1,a3 from test02 where a1 = '' or a3 = '';
-- 如果用到了索引覆蓋(using index), 會對possible_keys 和key造成影響:
-- a. 如果沒有where, 則索引只出現在key中;
-- b. 如果有where, 則索引出現在key和possible_keys中
explain select a1,a2 from test02 where a1 = '' or a2 = '';
explain select a1,a2 from test02;
5.2.9.4 using where(需要回表查詢)
假設age是索引列, 但查詢語句select age, name from …where age = … 此語句中必須回原表查Name, 因此會顯示using where
explain select a1,a3 from test02 where a3 = ''; -- a3需要回表查詢
5.2.9.5 impossible where : where 子句永遠為false
explain select * from test02 where a1 = 'x' and a1 = 'y';
6. 優化案例(單表優化, 雙表優化, 三表優化)
6.1 單表優化
create table book(bid int(4) primary key,name varchar(20) not null,authorid int(4) not null,publicid int(4) not null,typeid int(4) not null
);insert into book values(1,'tjava',1,1,2);
insert into book values(2,'tc',2,1,2);
insert into book values(3,'wx',3,2,1);
insert into book values(4,'math',4,2,3);
6.1.1 查詢authorid 為1并且 typeid 為2或3的bid
explain select bid from book where authorid = 1 and (typeid in (2,3)) order by typeid desc;
-- 優化,加索引
alter table book add index idx_bta(bid,authorid,typeid);
-- 雖然是using index, 但是也有回表查詢的情況

-- 索引一旦進行升級優化, 需要將之前廢棄的索引刪掉,防止干擾
drop index idx_bta on book;
-- 根據sql實際解析的順序, 調整索引的順序
alter table book add index idx_atb(authorid,typeid,bid);
-- 再次優化(之前是index級別): 因為范圍查詢in有時候會失效, 因此交換索引的順序,將typeid in(2,3)放在最后

6.1.2 小結
- 最佳左前綴, 保證索引定義與使用的順序一致性
- 索引需要逐步優化
- 將含in的范圍查詢放在where條件的最后, 防止索引失效
6.1.3 本例中同時出現了using where(需要回原表); using index(不需要回原表);
原因:
where authorid = 1 and typeid in (2, 3)中, authorid 在索引(authorid,typeid,bid)中, 因此不需要回原表(直接在索引表中就能查到); 而typeid雖然也在索引(authorid,typeid,bid)中, 但是含in的范圍查詢以及or的條件連接查詢已經使該typeid索引失效, 因此相當于沒有typeid這個索引, 所以需要回原表(using where)
例如以下沒有了in, 則不會出現using where
explain select bid from book where authorid = 1 and typeid = 2 order by typeid desc;

還可以通過key_len屬性證明in可以使索引失效
6.2 雙表優化
create table teacher2(tid int(4) primary key,cid int(4) not null
);insert into teacher2 values(1,2);
insert into teacher2 values(2,1);
insert into teacher2 values(3,3);create table course2(cid int(4),cname varchar(20)
);insert into course2 values(1,'java');
insert into course2 values(2,'python');
insert into course2 values(3,'kotlin');
6.2.1 左連接
explain select * from teacher2 t left join course2 c on t.cid = c.cid where c.cname = 'java';
Q: 索引往哪張表加?
A: 小表驅動大表, 索引建立在經常使用的字段上(本題t.cid = c.cid可知, cid字段使用頻繁, 因此給該字段加上索引), 一般情況下, 對于左外連接, 給左表加索引, 右外連接, 給右表加索引
小表: 10條數據
大表: 300條數據
where 小表 x10 = 大表y300 ; – 循環了10次
? 大表y 300 = 小表x 10; – 循環了300次
select ...where 小表.x10=大表.x300 ;for(int i=0;i<小表.length10;i++){for(int j=0;j<大表.length300;j++){...}}select ...where 大表.x300=小表.x10 ;for(int i=0;i<大表.length300;i++){for(int j=0;j<小表.length10;j++){...}}-- 以上2個for循環, 最終都會循環3000次;但是對于雙層循環來說, 一般建議將數據量小的循環放外層, 數據量大的循環放內層
-- 當編寫...on t.cid = c.cid時, 將數據量小的表放左邊(假設此時t表數據量小)
alter table teacher2 add index index_teacher2_cid(cid) ;
alter table course2 add index index_course2_cname(cname);Using join buffer:extra中的一個選項,作用:Mysql引擎使用了 連接緩存。
6.3 三張表優化A B C
a. 小表驅動大表
b. 索引建立在經常查詢的字段上
create table test03(a1 int(4) not null,a2 int(4) not null,a3 int(4) not null,a4 int(4) not null
);alter table test03 add index idx_a1_a2_a3_4(a1,a2,a3,a4) ;
-- 推薦寫法,因為索引的使用順序(where后面的順序), 和復合索引的順序保持一致
explain select a1,a2,a3,a4 from test03 where a1 = 1 and a2 = 2 and a3 = 3 and a4 = 4;
-- 雖然編寫順序和索引順序不一致, 但是sql在真正執行前, 經過了sql優化器的調整,結果與上條是一致的
explain select a1,a2,a3,a4 from test03 where a4 = 1 and a2 = 2 and a3 = 3 and a1 = 4;
-- 以上兩個sql, 使用了全部的復合索引explain select a1,a2,a3,a4 from test03 where a1 = 1 and a2 = 2 and a4 = 4 order by a3;
-- 以上sql用到了a1,a2兩個索引,該兩個字段不需要回表查詢using index; 而a4因為跨列使用,造成該索引失效,需要回表查詢, 因此是where;以上可以通過key_len驗證explain select a1,a2,a3,a4 from test03 where a1 = 1 and a4 = 4 order by a3;
-- 以上sql出現了using filesort(文件排序, "多了一次額外的查找排序";) 不要跨列使用(where和order by拼起來, 不要跨列使用)explain select a1,a2,a3,a4 from test03 where a1 = 1 and a4 = 4 order by a2, a3;
-- 以上sql不會出現using filesort
c. 總結
- 如果(a,b,c,d)復合索引和使用的順序全部一致, 且不跨列使用, 則復合索引全部使用, 如果部分一致(且不跨列使用), 則使用的部分索引. 例如:
select a,c where a =... and b = ... and c = ... where 和order by拼起來, 不需要跨列使用usring temporary: 需要額外多使用一張表, 一般出現在group by語句中, 已經有表了, 但是不適用, 必須再來一張表
explain select * from test03 where a2 = 2 and a4 = 4 group by a2,a4; -- 沒有using temporary
explain select * from test03 where a2 = 2 and a4 = 4 group by a3;
- 解析過程:
from...on...join...where...group by...having...select...distinct...order by...limit...
7.避免索引失效的一些原則
7.1 復合索引
- 不要跨列使用或者無序使用
- 盡量使用全索引匹配
7.2 不要在索引上進行任何操作(計算, 函數, 類型轉換), 否則索引失效
select ... where A.x = ...; -- 假設A.x是索引
-- 不要進行對索引進行操作, 如下
select .. where A.x * 3 = ...;
explain select * from book where authorid = 3 and typeid = 2;
-- 以上sql用到了'a','t'2個索引
explain select * from book where authorid = 3 and typeid * 2 = 2;
-- 以上sql用到了'a'1個索引
explain select * from book where authorid * 2 = 3 and typeid = 2;
-- 以上sql用到了0個索引, 對于復合索引,如果左邊失效,右側全部失效-- 單索引(不適用最佳左前綴)
drop index idx_atb on book;
alter table book add index idx_authorid(authorid);
alter table book add index idx_typeid(typeid);
explain select * from book where authorid = 1 and typeid = 2;
7.3 復合索引不能使用"!=“, “is (not) null”, 否則自身以及右側索引全部失效, 如果復合索引中有”>", 則自身以及右側索引全部失效
explain select * from book where authorid = 1 and typeid = 2;
explain select * from book where authorid != 1 and typeid = 2;
explain select * from book where authorid != 1 and typeid != 2;
-- sql優化,是一種概率層面的優化. 至于是否實際使用了我們的優化, 需要通過explain進行推測
-- 體驗概率情況(>,<,=):原因是服務層中有sql優化器,可能會影響我們的優化
drop index idx_authorid on book;
drop index idx_typeid on book;
alter table book add index idx_book_at(authorid,typeid);
explain select * from book where authorid = 1 and typeid = 2; -- 復合索引at全部使用
explain select * from book where authorid > 1 and typeid = 2; -- 復合索引如果有>, 則自身和右側索引全部失效
explain select * from book where authorid = 1 and typeid > 2; -- 復合索引全部使用
-- 明顯的概率問題 --
explain select * from book where authorid < 1 and typeid = 2; -- 復合索引只用到了1個索引
explain select * from book where authorid < 10 and typeid = 2; -- 復合索引全部失效
7.4 補救: 盡量使用索引覆蓋(using index)
-- 假設表中有復合索引(a,b,c), 盡量以下面這種方式去寫
select a,b,c from ... where a = ... and b = ...and c = ...;
7.5 like盡量以"常量"開頭, 不要以"%"開頭, 否則索引失效
select * from ... where name like '%x%'; -- name索引失效
explain select * from teacher where tname like '%x%'; -- tname索引失效
explain select * from teacher where tname like 'x%';
explain select tname from teacher where tname like '%x%'; -- 如果必須要用like'%X%'進行模糊查詢, 可以使用索引覆蓋挽救一部分.
7.6 盡量不要使用類型轉換(顯示/隱式), 否則索引失效
explain select * from teacher where tname = 'abc';
explain select * from teacher where tname = 123; -- 程序底層將123 -> '123', 進行了類型轉換, 因此索引失效
7.7 盡量不要使用or, 否則會使索引失效
explain select * from teacher where tname = '' or tcid > 1; -- or左側的tname將失效
8. 一些其他的優化方法
8.1 exist和in
select ... from table where exists (子查詢);
select ... from table where column in (子查詢);
-- 如果主查詢的數據集大, 則使用in, 效率高
-- 如果子查詢的數據集大, 則使用exists, 效率高
-- exists語法: 將主查詢的結果, 放到子查詢結果中去校驗(看子查詢是否有數據,如果有數據, 則校驗成功), 如果符合校驗, 則保留數據
select tname from teacher where exists (select * from teacher);
-- 等價于 select tname from teacher
select tname from teacher where exists (select * from teacher where tid = 9999);-- in語法
select ... from table where id in (1,3,5);
8.2 order by 優化
using filesort 有兩種算法(根據io的次數, io消耗性能): 單路排序, 雙路排序
MySQL4.1 之前默認使用雙路排序,:
雙路排序: 掃描2次磁盤
- 從磁盤讀取排序字段, 對排序字段進行排序(在buffer中進行的排序)
- 掃描其他字段
MySQL4.1之后默認使用單路排序: 只讀一次(全部字段), 在buffer中進行排序, 但這種單路排序會有一定的隱患(不一定真的是單路1次io, 有可能多次io).
原因:`如果數據量特別大, 則無法將所有字段的數據一次性讀取完畢, 因此會進行單路排序; 單路排序在使用時, 如果數據量大, 可以考慮調整buffer的大小
set max_length_for_sort_data = 1024; -- 單位為byte
如果max_length_for_sort_data值太低, 則mysql會自動從單路切換到雙路(太低: 需要排序的字段的總大小超過了max_length_for_sort_data定義的字節數)
提高order by 查詢的策略:
- 選擇使用單路還是雙路, 調整buffer容量的大小
- 避免
select * ...... - 復合索引: 不要跨列使用, 避免using filesort
- 保證全部的排序字段, 排序的一致性(都是升序或者降序)



)







—享元模式)
)






)