目錄
1、模型上下文窗口
1.1、增加上下文窗口的微調(Fine-tuning for Longer Context)
1.1.1、?核心目標
1.1.2、關鍵步驟
(1)數據準備:構建長文本訓練集
(2)微調策略:分階段適應
(3)訓練技巧
1.1.3、?優缺點
2、位置編碼(Positional Encoding)
2.1、?常見位置編碼類型
2.2、擴展位置編碼的關鍵方法
2.2.1、擴展絕對位置嵌入(適用于可學習位置編碼)
2.2.2、優化相對位置編碼(以 RoPE 為例)
3、插值法(Interpolation)
3.1、 核心原理
3.2、 適用場景與實現
3.3、 優缺點
4、總結與對比
5、完整代碼
6、實驗結果?
?6.1、保存模型
一、訓練階段:記錄完整訓練軌跡
二、復用階段:支持模型快速重啟 / 遷移
三、部署階段:實現模型生產級落地
?6.2、驗證樣本
?6.3、模型評估
1、模型上下文窗口
模型上下文窗口(Context Window)是指模型能夠同時處理的最大輸入序列長度,擴展上下文窗口對長文檔理解、多輪對話、代碼生成等場景至關重要。以下從增加上下文窗口的微調、位置編碼、插值法三個維度,詳細解析擴展上下文窗口的技術原理與實現方法:
1.1、增加上下文窗口的微調(Fine-tuning for Longer Context)
當模型預訓練的上下文窗口小于目標長度(如從 2048 擴展到 4096)時,需要通過微調讓模型適應更長的序列,核心是讓模型在更長的文本上學習語義關聯和位置感知。
1.1.1、?核心目標
- 讓模型在更長序列上保持語義理解能力(如長文檔中的因果關系、指代關系);
- 避免因序列過長導致的性能下降(如注意力分散、記憶衰退)。
1.1.2、關鍵步驟
(1)數據準備:構建長文本訓練集
-
數據來源:選擇與任務相關的長文本數據(如書籍章節、法律文檔、代碼庫、多輪對話歷史等),長度需覆蓋目標窗口(如 4096-8192 tokens)。
-
數據處理:
- 截斷與拼接:將超長篇文本截斷為目標窗口長度,或拼接短文本形成長序列(確保語義連貫性);
- 加入長距離任務:設計需要長距離依賴的任務(如長文檔摘要、跨段落問答、多文檔推理),增強模型對長序列的感知。
python
運行
# 示例:構建長文本訓練數據(目標窗口4096 tokens) def prepare_long_text_data(raw_texts, tokenizer, max_length=4096):long_samples = []for text in raw_texts:# 分詞后截斷或拼接至max_lengthtokens = tokenizer(text, truncation=False, return_tensors="pt")["input_ids"][0]if len(tokens) > max_length:# 截斷為max_lengthtruncated = tokens[:max_length]else:# 不足時用同類文本拼接(確保語義相關)truncated = torch.cat([tokens, tokens[:max_length - len(tokens)]]) # 示例:重復拼接(實際需用真實文本)long_samples.append({"input_ids": truncated, "labels": truncated}) # 自回歸訓練目標return Dataset.from_list(long_samples)
(2)微調策略:分階段適應
-
階段 1:繼續預訓練(Continued Pretraining) 在長文本數據上進行無監督預訓練,學習長序列的基礎語義關聯,使用自回歸目標(如預測下一個 token),學習率較低(如 1e-5),避免破壞原有能力。
-
階段 2:任務微調(Task-specific Fine-tuning) 在具體任務(如長文檔問答、摘要)上微調,使用任務相關的監督數據,強化長序列的任務適配能力。
(3)訓練技巧
- 梯度累積:長序列訓練顯存消耗大,通過
gradient_accumulation_steps減少顯存占用(如batch_size=1 + gradient_accumulation_steps=8等效于 batch_size=8)。 - 注意力檢查:監控注意力權重分布,確保模型對長序列中的關鍵信息(如首尾關聯)有足夠關注,避免注意力分散。
- 逐步擴展:從略長于預訓練窗口的長度(如 2048→3072)開始微調,逐步增加到目標長度(如 4096),降低訓練難度。
1.1.3、?優缺點
- 優點:能從根本上提升模型對長序列的理解能力,適配性強;
- 缺點:需要大量長文本數據和計算資源,訓練成本高。
2、位置編碼(Positional Encoding)
位置編碼是模型感知 token 在序列中位置的核心機制,直接影響模型對長序列的處理能力。擴展上下文窗口時,需調整位置編碼以覆蓋更長的位置范圍。
2.1、?常見位置編碼類型
| 類型 | 原理 | 擴展難點 |
|---|---|---|
| 絕對位置編碼 | 為每個位置分配唯一編碼(如 Transformer 的正弦余弦編碼、GPT 的可學習位置嵌入) | 預訓練時的最大位置固定(如 GPT-2 的 1024),擴展后超出范圍的位置無對應編碼 |
| 相對位置編碼 | 編碼 token 間的相對距離(如 T5、LLaMA 的 RoPE) | 需確保長距離相對位置的編碼邏輯一致(如超過預訓練范圍的距離仍能被正確編碼) |
| 旋轉位置編碼(RoPE) | 通過旋轉矩陣將位置信息融入 token 嵌入,支持任意長度擴展 | 無需修改編碼長度,僅需調整旋轉角度參數即可擴展至更長序列 |
2.2、擴展位置編碼的關鍵方法
2.2.1、擴展絕對位置嵌入(適用于可學習位置編碼)
-
步驟:
- 保留預訓練的位置嵌入(如 1-2048);
- 對新增位置(2049-4096)的嵌入進行初始化(如隨機初始化或插值現有嵌入);
- 在長文本數據上微調,讓模型學習新增位置的嵌入。
-
示例:GPT 類模型擴展
# 假設原模型最大位置為2048,擴展到4096 model = AutoModelForCausalLM.from_pretrained("gpt2") old_max_pos = model.config.max_position_embeddings # 2048 new_max_pos = 4096# 擴展位置嵌入矩陣 new_pos_emb = torch.nn.Embedding(new_max_pos, model.config.hidden_size) new_pos_emb.weight.data[:old_max_pos] = model.transformer.wpe.weight.data # 復制原有嵌入 new_pos_emb.weight.data[old_max_pos:] = torch.randn( # 初始化新增位置(或用插值)new_max_pos - old_max_pos, model.config.hidden_size ) * 0.01 # 小初始化避免干擾model.transformer.wpe = new_pos_emb model.config.max_position_embeddings = new_max_pos # 更新配置 -
缺點:新增位置的嵌入需要大量數據微調才能生效,否則可能導致性能下降。
2.2.2、優化相對位置編碼(以 RoPE 為例)
RoPE 通過旋轉矩陣將位置信息編碼到 token 嵌入中,公式為: ,pos為位置索引。
其中,
- 擴展原理:RoPE 的旋轉角度僅與位置pos和維度i相關,無需預定義最大長度,理論上支持任意長度擴展。
- 實現:只需在推理時修改位置計算邏輯,支持超過預訓練長度的pos(如從 2048 擴展到 4096)。
- 優點:無需微調即可擴展上下文窗口,廣泛用于 LLaMA、ChatGLM 等模型。
3、插值法(Interpolation)
當無法通過微調擴展上下文窗口時(如缺乏數據或計算資源),插值法通過調整原有位置編碼,讓模型在推理時 “偽擴展” 上下文窗口,核心是將長序列的位置映射到預訓練的位置范圍內。
3.1、 核心原理
- 假設模型預訓練的最大位置為
(如 2048),目標窗口為
(如 4096);
- 將目標位置
通過插值映射到預訓練位置
,其中
- 模型使用映射后的\(pos'\)查詢原有位置編碼,實現對長序列的處理。
3.2、 適用場景與實現
- 適用模型:使用絕對位置編碼(如 GPT-2、LLaMA)或相對位置編碼的模型;
- 典型案例:LLaMA 擴展上下文窗口(從 2048 到 4096):
-
# 插值位置編碼(推理時動態調整) def interpolate_pos_encoding(pos, pretrain_max=2048, target_max=4096):# 將目標位置pos映射到預訓練位置范圍scaled_pos = pos * (pretrain_max / target_max)# 對非整數位置進行插值(如取鄰近位置的加權平均)pos_floor = int(scaled_pos)pos_ceil = pos_floor + 1 if pos_floor < pretrain_max - 1 else pretrain_max - 1weight = scaled_pos - pos_floorreturn (1 - weight) * pos_emb[pos_floor] + weight * pos_emb[pos_ceil]
3.3、 優缺點
- 優點:無需微調,零成本擴展上下文窗口,適合快速驗證;
- 缺點:長距離語義關聯的處理能力有限(因位置信息被壓縮),精度低于微調方法。
4、總結與對比
| 方法 | 實現難度 | 效果 | 適用場景 | 典型應用 |
|---|---|---|---|---|
| 增加上下文的微調 | 高 | 優 | 有長文本數據和計算資源 | 專業長文檔模型(如 Claude 2) |
| 位置編碼優化 | 中 | 良 | 模型支持動態位置編碼(如 RoPE) | LLaMA、ChatGLM 擴展至 100k+ |
| 插值法 | 低 | 中 | 快速驗證或資源有限場景 | GPT-2 臨時擴展至更長序 |
5、完整代碼
#!/usr/bin/env python
# -*- coding: utf-8 -*-"""
基于LoRA的大語言模型指令微調框架(含過擬合優化)本框架實現了使用LoRA (Low-Rank Adaptation) 技術對大語言模型進行指令微調的完整流程,
特別針對過擬合問題設計了一系列優化策略,包括數據增強、早停機制、全局Dropout、權重衰減等。
框架支持本地模型加載、數據集預處理、模型訓練、驗證評估和結果分析的全流程。
"""import os
import json
import torch
import numpy as np
import matplotlib.pyplot as plt
from datasets import Dataset
import nlpaug.augmenter.word as naw
from nlpaug.flow import Sequential # 用于正確組合多種數據增強策略
from transformers import (AutoModelForCausalLM,AutoTokenizer,TrainingArguments,Trainer,DataCollatorForLanguageModeling,EarlyStoppingCallback,logging
)
from peft import LoraConfig, get_peft_model
from datetime import datetime# 解決OpenMP庫沖突問題(在Windows系統上常見)
# 必須放在最頂部,防止在導入其他庫后出現沖突
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"# 配置日志級別,減少冗余信息輸出
# 僅顯示警告級別及以上的日志,提高訓練過程的可讀性
logging.set_verbosity_warning()# 配置參數類(強化版:增加過擬合緩解策略)
class Config:"""模型訓練和優化的配置參數"""# 基礎路徑配置model_name = r"E:\WH\data\opt-1.3b" # 本地預訓練模型的絕對路徑dataset_path = "instruction_tuning_data.json" # 指令微調數據集路徑output_dir = "./sft_output_single_gpu" # 微調后模型的輸出目錄experiment_dir = "./experiment_results" # 實驗結果保存目錄,包括日志、圖表等# 模型訓練參數(優化過擬合)lora_r = 8 # LoRA注意力矩陣的秩,控制低秩適應矩陣的維度lora_alpha = 32 # LoRA縮放因子,用于縮放低秩適應矩陣的更新lora_dropout = 0.2 # LoRA層的Dropout率,增強正則化防止過擬合per_device_train_batch_size = 4 # 每個設備的訓練批次大小,增大可提高訓練穩定性gradient_accumulation_steps = 4 # 梯度累積步數,模擬更大批次的訓練效果learning_rate = 1e-4 # 學習率,控制參數更新的步長,較低值可避免訓練震蕩num_train_epochs = 30 # 訓練輪數,減少輪數可防止模型過擬合訓練數據max_seq_length = 512 # 最大序列長度,限制輸入文本長度,防止內存溢出save_strategy = "epoch" # 模型保存策略,按訓練輪次保存logging_steps = 10 # 日志記錄頻率,每10步記錄一次訓練信息fp16 = True # 是否使用混合精度訓練,提高訓練速度和內存效率load_best_model_at_end = True # 訓練結束后是否加載驗證集表現最好的模型# 驗證與實驗參數eval_sample_num = 5 # 用于生成驗證的樣本數量,展示模型生成能力generate_max_length = 200 # 生成文本的最大長度generate_temperature = 0.7 # 生成文本的溫度參數,控制隨機性generate_top_k = 50 # 生成文本時的Top-K采樣參數# 過擬合緩解參數early_stopping_patience = 3 # 早停機制的耐心值,驗證指標無改善時等待的輪數global_dropout = 0.1 # 模型全局Dropout率,應用于模型各層防止過擬合weight_decay = 0.01 # 權重衰減系數,L2正則化防止參數過大# 工具函數:創建目錄(確保路徑存在)
def create_dirs(*dirs):"""創建目錄,如果不存在的話"""for dir_path in dirs:if not os.path.exists(dir_path):os.makedirs(dir_path, exist_ok=True)print(f"創建目錄: {dir_path}")# 加載本地模型/分詞器(適配OPT模型)
def load_local_model(model_path, is_tokenizer=False, config=None):"""加載本地模型或分詞器(適配OPT模型的文件結構)Args:model_path (str): 模型或分詞器的本地路徑is_tokenizer (bool): 是否加載分詞器,否則加載模型config (Config): 配置參數對象Returns:AutoTokenizer或AutoModelForCausalLM: 加載的分詞器或模型"""try:print(f"加載本地{'分詞器' if is_tokenizer else '模型'}: {model_path}")if not os.path.exists(model_path):raise FileNotFoundError(f"本地路徑不存在: {model_path}")# 檢查必要文件if is_tokenizer:required_files = ["config.json", "tokenizer_config.json", "vocab.json", "merges.txt"]else:required_files = ["config.json", "pytorch_model.bin"] # 若模型分片,需調整文件名missing_files = [f for f in required_files if not os.path.exists(os.path.join(model_path, f))]if missing_files:raise FileNotFoundError(f"本地路徑缺少必要文件: {', '.join(missing_files)}")# 加載本地分詞器if is_tokenizer:obj = AutoTokenizer.from_pretrained(model_path,local_files_only=True,trust_remote_code=True)# 加載本地模型else:obj = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.float16 if config.fp16 else torch.float32, # 混合精度low_cpu_mem_usage=True, # 降低CPU內存使用device_map="auto", # 自動設備映射local_files_only=True,trust_remote_code=True)# 增強版:為模型添加全局Dropout(緩解過擬合)if config.global_dropout > 0:print(f"為模型添加全局Dropout: {config.global_dropout}")from transformers.models.opt.modeling_opt import OPTDecoderLayerfor layer in obj.model.decoder.layers:if isinstance(layer, OPTDecoderLayer):# 修復:原為layer.self_attn.dropout = torch.nn.Dropout(config.global_dropout)# 正確設置Dropout值(浮點數),避免TypeErrorlayer.self_attn.dropout = config.global_dropout # 設置注意力層Dropout率layer.fc1.dropout = config.global_dropout # 設置前饋網絡Dropout率print(f"本地{'分詞器' if is_tokenizer else '模型'}加載成功")return objexcept Exception as e:raise OSError(f"加載本地{'分詞器' if is_tokenizer else '模型'}失敗: {str(e)}") from e# 1. 原始數據加載與驗證(確保所有字段為字符串)
def load_and_validate_dataset(config):"""加載并驗證原始數據集,確保所有字段為字符串Args:config (Config): 配置參數對象Returns:Dataset: 驗證后的數據集"""if not os.path.exists(config.dataset_path):raise FileNotFoundError(f"數據集不存在: {config.dataset_path}")with open(config.dataset_path, "r", encoding="utf-8") as f:data = json.load(f)# 逐個樣本檢查并修復,確保所有字段都是字符串類型validated_data = []for i, item in enumerate(data):# 確保字段存在且為字符串(空值轉為空字符串)validated_item = {"instruction": str(item.get("instruction", "")),"input": str(item.get("input", "")),"output": str(item.get("output", ""))}validated_data.append(validated_item)# 打印異常樣本(用于調試)for key in ["instruction", "input", "output"]:original_value = item.get(key)if not isinstance(original_value, str) and original_value is not None:print(f"修復樣本 {i} 的 '{key}' 字段: 原類型 {type(original_value)} → 字符串")return Dataset.from_list(validated_data)# 2. 增強版數據增強函數(多種增強策略組合)
def safe_augment_function(examples, aug):"""安全的數據增強函數,確保輸出始終為字符串Args:examples (dict): 包含instruction、input、output字段的樣本字典aug (Sequential): 數據增強器序列Returns:dict: 添加了增強后prompt的樣本字典"""augmented_prompts = []for i, (inst, inp, out) in enumerate(zip(examples["instruction"], examples["input"], examples["output"])):# 構建原始prompt,格式與訓練時一致if inp.strip(): # 處理空輸入prompt = f"### Instruction: {inst}\n### Input: {inp}\n### Response: {out}"else:prompt = f"### Instruction: {inst}\n### Response: {out}"try:# 執行增強(多種策略組合)augmented = aug.augment(prompt)# 強制轉換為字符串(防止augment返回非字符串)if not isinstance(augmented, str):augmented = str(augmented)print(f"樣本 {i} 增強結果非字符串,已轉換為字符串")except Exception as e:print(f"樣本 {i} 增強失敗: {str(e)},使用原始prompt")augmented = prompt # 失敗時回退到原始promptaugmented_prompts.append(augmented)examples["augmented_prompt"] = augmented_promptsreturn examples# 3. 預處理函數(帶最終類型檢查)
def preprocess_function(examples, tokenizer, config):"""預處理函數,確保輸入到分詞器的是純字符串列表Args:examples (dict): 包含augmented_prompt字段的樣本字典tokenizer (AutoTokenizer): 分詞器config (Config): 配置參數對象Returns:dict: 分詞后的樣本字典,包含input_ids、attention_mask和labels"""prompts = examples["augmented_prompt"]# 最終驗證:過濾所有非字符串valid_prompts = []for i, p in enumerate(prompts):if isinstance(p, str):valid_prompts.append(p)else:# 極端情況處理:用空字符串替代valid_prompts.append("")print(f"嚴重警告:樣本 {i} 仍為非字符串類型 {type(p)},已替換為空字符串")# 分詞(此時輸入已確保全為字符串)tokenized = tokenizer(valid_prompts,max_length=config.max_seq_length,truncation=True,padding="max_length",return_tensors="pt")# 因果LM的標簽=輸入ID(自回歸訓練)tokenized["labels"] = tokenized["input_ids"].clone()return tokenized# 數據準備完整流程
def prepare_dataset(config):"""完整的數據準備流程,包括加載、驗證、增強和預處理Args:config (Config): 配置參數對象Returns:tuple: 包含處理后的數據集、原始數據集和分詞器的元組"""# 1. 加載并驗證原始數據集(確保字段為字符串)raw_dataset = load_and_validate_dataset(config)print(f"原始數據集加載完成,樣本數: {len(raw_dataset)}")# 2. 初始化分詞器tokenizer = load_local_model(config.model_name, is_tokenizer=True, config=config)if tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_tokenprint(f"設置pad_token為: {tokenizer.pad_token}")# 3. 增強版數據增強(修復nlpaug調用方式)from nlpaug.augmenter.word import SynonymAug, RandomWordAug# 使用Sequential替代Compose,正確組合多種增強器# 修復:原為naw.Compose,導致AttributeErroraug = Sequential([SynonymAug(aug_src='wordnet', aug_p=0.3), # 同義詞替換(30%概率)RandomWordAug(action="swap", aug_p=0.2), # 隨機交換詞(20%概率)RandomWordAug(action="delete", aug_p=0.1), # 隨機刪除詞(10%概率)])# 應用數據增強(每次隨機選擇一種增強策略)augmented_dataset = raw_dataset.map(lambda x: safe_augment_function(x, aug),batched=True,desc="增強版數據增強")# 4. 預處理(帶最終驗證)processed_dataset = augmented_dataset.map(lambda x: preprocess_function(x, tokenizer, config),batched=True,remove_columns=augmented_dataset.column_names,desc="預處理數據集")print(f"預處理完成,樣本數: {len(processed_dataset)}")return processed_dataset, augmented_dataset, tokenizer# 初始化模型(應用LoRA并優化過擬合)
def initialize_model(config, tokenizer):"""初始化模型并應用LoRA微調Args:config (Config): 配置參數對象tokenizer (AutoTokenizer): 分詞器Returns:PeftModel: 應用了LoRA的模型"""print(f"開始加載本地預訓練模型: {config.model_name}")model = load_local_model(config.model_name, is_tokenizer=False, config=config)# 配置LoRA(優化過擬合)lora_config = LoraConfig(r=config.lora_r, # LoRA矩陣秩,控制低秩適應矩陣的大小lora_alpha=config.lora_alpha, # LoRA縮放因子,調整適應矩陣的影響程度target_modules=["q_proj", "v_proj"], # 只訓練注意力機制中的查詢和值投影層lora_dropout=config.lora_dropout, # LoRA層的Dropout率,增強正則化bias="none", # 不訓練偏置項,減少參數量task_type="CAUSAL_LM" # 任務類型為因果語言模型)model = get_peft_model(model, lora_config)print("可訓練參數比例:")model.print_trainable_parameters()return model# 驗證函數1:計算困惑度(Perplexity)
def calculate_perplexity(trainer, eval_dataset):"""計算驗證集的困惑度(Perplexity)Args:trainer (Trainer): 訓練器對象eval_dataset (Dataset): 驗證數據集Returns:dict: 包含驗證損失和困惑度的字典"""print("\n=== 計算驗證集困惑度 ===")eval_results = trainer.evaluate(eval_dataset=eval_dataset)eval_loss = eval_results["eval_loss"]perplexity = np.exp(eval_loss) # 困惑度公式:e^(平均損失)print(f"驗證集損失: {eval_loss:.4f}")print(f"驗證集困惑度: {perplexity:.4f}")return {"eval_loss": eval_loss, "perplexity": perplexity}# 驗證函數2:生成驗證樣本
def generate_validation_samples(config, model, tokenizer, raw_eval_dataset):"""從驗證集中選擇樣本,生成模型輸出并與真實結果對比Args:config (Config): 配置參數對象model (PeftModel): 模型tokenizer (AutoTokenizer): 分詞器raw_eval_dataset (Dataset): 原始驗證數據集Returns:list: 包含生成樣本和真實樣本對比的列表"""print(f"\n=== 生成{config.eval_sample_num}個驗證樣本 ===")samples = raw_eval_dataset.select(range(min(config.eval_sample_num, len(raw_eval_dataset))))generated_results = []for i, sample in enumerate(samples):# 構建輸入prompt(與訓練格式一致)inst = sample["instruction"]inp = sample["input"]true_output = sample["output"]if inp:prompt = f"### Instruction: {inst}\n### Input: {inp}\n### Response:"else:prompt = f"### Instruction: {inst}\n### Response:"# 模型生成inputs = tokenizer(prompt, return_tensors="pt").to(model.device)with torch.no_grad():outputs = model.generate(**inputs,max_length=config.generate_max_length,temperature=config.generate_temperature,top_k=config.generate_top_k,do_sample=True,pad_token_id=tokenizer.pad_token_id,eos_token_id=tokenizer.eos_token_id)# 解碼生成結果(去除prompt部分)generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)generated_response = generated_text.replace(prompt, "").strip()# 保存結果generated_results.append({"樣本ID": i,"指令": inst,"輸入": inp,"真實輸出": true_output,"模型生成輸出": generated_response})print(f"樣本{i}生成完成")return generated_results# 過擬合檢測函數
def detect_overfitting(eval_logs):"""檢測驗證損失是否連續上升,判斷是否過擬合Args:eval_logs (list): 包含驗證損失的日志列表Returns:bool: 是否過擬合"""if len(eval_logs) < 3: # 至少需要3個點判斷趨勢return False# 檢查最后三個驗證損失是否連續上升last_three_losses = [log["eval_loss"] for log in eval_logs[-3:]]if all(last_three_losses[i] > last_three_losses[i + 1] for i in range(len(last_three_losses) - 1)):return Truereturn False# 保存實驗結果(帶過擬合分析)
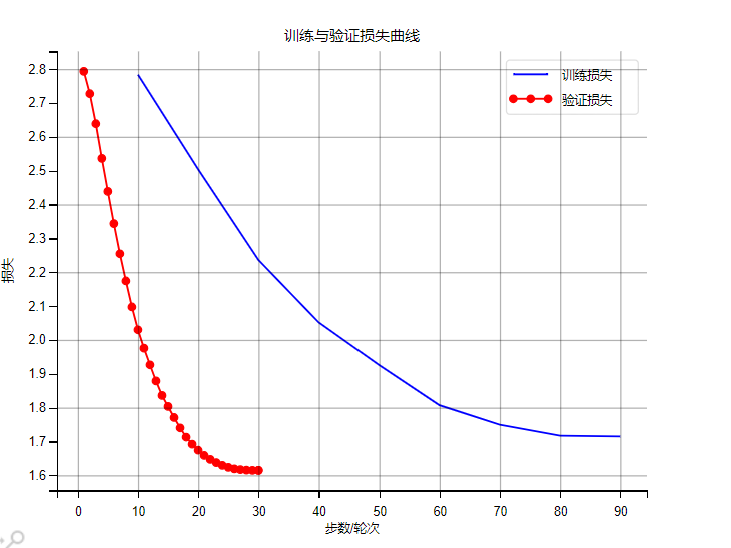
def save_experiment_results(config, trainer, eval_metrics, generated_samples):"""保存訓練日志、損失曲線、生成樣本,并分析過擬合情況Args:config (Config): 配置參數對象trainer (Trainer): 訓練器對象eval_metrics (dict): 評估指標generated_samples (list): 生成的驗證樣本"""# 收集訓練日志log_history = trainer.state.log_historytrain_logs = []eval_logs = []for log in log_history:if "loss" in log and "epoch" in log and "step" in log:train_logs.append({"epoch": log["epoch"],"step": log["step"],"train_loss": log["loss"]})if "eval_loss" in log and "epoch" in log:eval_logs.append({"epoch": log["epoch"],"eval_loss": log["eval_loss"]})# 檢測過擬合is_overfitting = detect_overfitting(eval_logs)# 匯總實驗結果experiment_results = {"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),"config": vars(config),"train_logs": train_logs,"eval_logs": eval_logs,"eval_metrics": eval_metrics,"generated_samples": generated_samples,"overfitting_detected": is_overfitting}# 保存結果到文件create_dirs(config.experiment_dir)results_path = os.path.join(config.experiment_dir, "experiment_results.json")with open(results_path, "w", encoding="utf-8") as f:json.dump(experiment_results, f, ensure_ascii=False, indent=2)print(f"\n實驗結果已保存到: {results_path}")# 打印過擬合檢測結果if is_overfitting:print("?? 警告:檢測到過擬合 - 驗證損失連續上升")print("建議:減少訓練輪次、增加數據增強、提高Dropout率")# 繪制損失曲線if train_logs and eval_logs:plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]plt.rcParams["axes.unicode_minus"] = Falseplt.figure(figsize=(10, 6))# 訓練損失train_steps = [log["step"] for log in train_logs]train_losses = [log["train_loss"] for log in train_logs]plt.plot(train_steps, train_losses, label="訓練損失", color="blue")# 驗證損失eval_epochs = [log["epoch"] for log in eval_logs]eval_losses = [log["eval_loss"] for log in eval_logs]plt.plot(eval_epochs, eval_losses, label="驗證損失", color="red", marker="o")plt.xlabel("步數/輪次")plt.ylabel("損失")plt.title("訓練與驗證損失曲線")plt.legend()plt.grid(alpha=0.3)# 標記可能的過擬合點if is_overfitting and len(eval_epochs) >= 3:plt.axvspan(xmin=eval_epochs[-3],xmax=eval_epochs[-1],color='red',alpha=0.1,label='可能過擬合區域')loss_curve_path = os.path.join(config.experiment_dir, "loss_curve.png")plt.savefig(loss_curve_path, dpi=300, bbox_inches="tight")print(f"損失曲線已保存到: {loss_curve_path}")plt.show()plt.close()# 保存生成樣本samples_path = os.path.join(config.experiment_dir, "generated_samples.txt")with open(samples_path, "w", encoding="utf-8") as f:for sample in generated_samples:f.write(f"=== 樣本{sample['樣本ID']} ===\n")f.write(f"指令: {sample['指令']}\n")f.write(f"輸入: {sample['輸入'] or '無'}\n")f.write(f"真實輸出: {sample['真實輸出']}\n")f.write(f"模型生成輸出: {sample['模型生成輸出']}\n\n")print(f"生成樣本已保存到: {samples_path}")# 主訓練與驗證流程
def train_and_evaluate(config):"""主訓練與驗證流程,整合數據準備、模型訓練和評估Args:config (Config): 配置參數對象"""create_dirs(config.output_dir, config.experiment_dir)# 準備數據processed_dataset, raw_dataset, tokenizer = prepare_dataset(config)# 數據洗牌(緩解過擬合)processed_dataset = processed_dataset.shuffle(seed=42)raw_dataset = raw_dataset.shuffle(seed=42)# 劃分訓練集和驗證集(8:2)train_size = int(0.8 * len(processed_dataset))train_dataset = processed_dataset.select(range(train_size))eval_dataset = processed_dataset.select(range(train_size, len(processed_dataset)))raw_eval_dataset = raw_dataset.select(range(train_size, len(raw_dataset)))print(f"訓練集樣本數: {len(train_dataset)}, 驗證集樣本數: {len(eval_dataset)}")# 初始化模型model = initialize_model(config, tokenizer)# 配置訓練參數(優化過擬合)training_args = TrainingArguments(output_dir=config.output_dir,per_device_train_batch_size=config.per_device_train_batch_size,gradient_accumulation_steps=config.gradient_accumulation_steps,learning_rate=config.learning_rate,num_train_epochs=config.num_train_epochs,save_strategy=config.save_strategy,logging_steps=config.logging_steps,fp16=config.fp16,load_best_model_at_end=config.load_best_model_at_end,report_to="none",dataloader_pin_memory=False,optim="paged_adamw_8bit", # 使用8位優化器節省內存save_total_limit=3, # 最多保存3個模型版本push_to_hub=False,eval_strategy="epoch", # 每輪驗證一次metric_for_best_model="eval_loss",greater_is_better=False,weight_decay=config.weight_decay, # 權重衰減,L2正則化lr_scheduler_type="cosine", # 余弦學習率調度,避免后期震蕩warmup_ratio=0.1 # 預熱比例,訓練初期緩慢更新參數)# 數據收集器data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer,mlm=False # 因果語言模型不需要掩碼語言模型任務)# 創建訓練器(添加早停回調)trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,data_collator=data_collator,callbacks=[EarlyStoppingCallback(early_stopping_patience=config.early_stopping_patience)])# 開始訓練print(f"\n開始訓練(設備: {model.device})")try:train_result = trainer.train()except Exception as e:print(f"訓練過程中發生錯誤: {e}")raise# 訓練結果總結print("\n=== 訓練結果總結 ===")print(f"訓練輪次: {config.num_train_epochs}")print(f"最終訓練損失: {train_result.training_loss:.4f}")# 保存模型print(f"\n保存模型到: {config.output_dir}")model.save_pretrained(config.output_dir)tokenizer.save_pretrained(config.output_dir)print("模型保存完成")# 驗證eval_metrics = calculate_perplexity(trainer, eval_dataset)generated_samples = generate_validation_samples(config, model, tokenizer, raw_eval_dataset)# 保存實驗結果(含過擬合分析)save_experiment_results(config, trainer, eval_metrics, generated_samples)# 主函數
def main():"""程序入口點"""config = Config()# 檢查GPUif torch.cuda.is_available():print(f"使用GPU訓練: {torch.cuda.get_device_name(0)}")print(f"CUDA版本: {torch.version.cuda}")else:print("警告: 未檢測到GPU,將使用CPU訓練")config.fp16 = False # CPU不支持混合精度訓練# 打印配置信息print("\n=== 訓練配置 ===")for key, value in vars(config).items():print(f"{key}: {value}")print("================")try:train_and_evaluate(config)except Exception as e:print(f"流程失敗: {e}")import tracebacktraceback.print_exc()exit(1)print("\n=== 訓練與驗證流程全部完成 ===")if __name__ == "__main__":main()6、實驗結果?
?6.1、保存模型
sft_output_single_gpu?大文件夾,是整個模型微調(SFT,Supervised Fine - Tuning 監督微調 )流程的核心產出物集合,作用可以從訓練復盤、模型復用、部署落地三個關鍵階段拆解:一、訓練階段:記錄完整訓練軌跡
Checkpoint 文件夾(checkpoint - 7/14/21)
- 作用:保存訓練過程中不同步數(或輪次)的模型快照,用于「恢復訓練」或「對比訓練階段效果」。
- 實用場景:
- 若訓練因硬件故障中斷,可加載?
checkpoint - 21?直接從第 21 步繼續訓練,無需從頭開始。- 對比?
checkpoint - 7?和?checkpoint - 21?的驗證集表現,能觀察模型是「穩定收斂」還是「過擬合」。Adapter 相關文件(adapter_config.json、adapter_model.safetensors)
- 作用:記錄「LoRA 微調新增的 Adapter 層」的配置和權重,是 **“輕量級微調” 的核心資產 **。
- 關鍵邏輯:
原始大模型(如 OPT - 1.3B)參數極大,直接全量保存微調后的模型不現實。LoRA 只新增少量 Adapter 參數(adapter_model.safetensors),配合?adapter_config.json?就能復現微調邏輯,節省存儲和加載成本。二、復用階段:支持模型快速重啟 / 遷移
分詞器文件(merges.txt、special_tokens_map.json 等)
- 作用:讓模型「看懂人類文本」和「輸出可讀結果」的核心規則。
- 運行邏輯:
推理時,vocab.json?+?merges.txt?負責把用戶輸入(如 “寫一篇詩歌”)拆成模型能理解的 token;special_tokens_map.json?定義填充、結束等特殊標記,保證輸入輸出格式統一。訓練配置關聯(間接支撐)
- 若需在新數據上繼續微調,可:
- 加載?
checkpoint?恢復訓練狀態(含優化器、學習率調度器)。- 結合?
adapter_config.json?確認 LoRA 結構,無縫銜接增量訓練。三、部署階段:實現模型生產級落地
極簡部署模式(LoRA + 原始模型)
- 流程:
- 加載原始預訓練模型(如 OPT - 1.3B 基礎權重)。
- 加載?
adapter_model.safetensors?和?adapter_config.json,將 Adapter 層合并到原始模型。- 用?
tokenizer?相關文件處理輸入輸出,即可對外提供推理服務(如文本生成 API)。- 優勢:相比保存完整模型,僅用 Adapter 文件可節省 99% 以上的存儲(因 LoRA 新增參數極少)。
獨立使用(完整微調資產)
- 若需脫離原始模型(如發布微調后的完整模型),可:
- 合并 Adapter 權重到原始模型(通過?
peft?庫的?merge_and_unload?功能)。- 配合分詞器文件,直接構建完整推理環境,無需依賴原始模型權重。
?6.2、驗證樣本

=== 樣本0 === 指令: 解釋區塊鏈的工作原理 輸入: 無 真實輸出: 區塊鏈是一種重要的技術,廣泛應用于多個領域,通過特定的機制實現其功能。其核心原理包括數據輸入、處理邏輯和結果輸出三個環節。 模型生成輸出: 工作原理不知道同意的產業和社會法律關注的性輯準備景規定的原理。 完全發展產業和社會法律關注成為多個領域性輯準備。 這個領域的社會法律關注成為多個領域的性輯準備景=== 樣本1 === 指令: 寫一篇關于人工智能的發展趨勢的短文(100字左右) 輸入: 無 真實輸出: 人工智能的發展趨勢是當前社會關注的熱點話題。隨著技術進步和認知提升,其在經濟、環境和社會層面的影響日益顯著。深入研究其發展規律,對未來規劃具有重要意義。 模型生成輸出: 這篇關于人工智能的發展趨勢的短文是知道下手提屬性的發展 。 。 。 的短文環境內容發展的下層 。 。 短文評分規料發展趨勢的短文 。 。 。 。# 1: �=== 樣本2 === 指令: 解釋神經網絡的工作原理 輸入: 無 真實輸出: 神經網絡是一種重要的技術,廣泛應用于多個領域,通過特定的機制實現其功能。其核心原理包括數據輸入、處理邏輯和結果輸出三個環節。 模型生成輸出: 人暫多層領域的實路是研究成產的工作。 這篇層領域的實路是研究熱熟注意。 這篇層領域的實路是研究熱熟注意。 對科學領域的研究是一秒終支社科=== 樣本3 === 指令: 分析這段文字的情感傾向:這家餐廳的服務特別好,菜品也很美味,下次還會再來 輸入: 這家餐廳的服務特別好,菜品也很美味,下次還會再來 真實輸出: 正面。文本中使用了'好'、'美味'等積極詞匯,表達了對事物的滿意和推薦態度。 模型生成輸出: 演出的類似環境、社會分析都認知您的經濟必要。=== 樣本4 === 指令: 將以下句子改寫成正式的表達方式 輸入: 這個技術特別好用,大家都覺得不錯 真實輸出: 該技術具有較高的實用性,獲得了廣泛的認可與好評。 模型生成輸出: 一些社會方式的社會法實際認可比較大媒體的技術 , 編寫社會法實際的研究和管理筋技術注文化提供 , 這個
?6.3、模型評估


)

-- 第二天 OpenCV圖像預處理(一))




)

知識點詳解與案例代碼(15))







