大家好,我是java1234_小鋒老師,最近寫了一套【NLP輿情分析】基于python微博輿情分析可視化系統(flask+pandas+echarts)視頻教程,持續更新中,計劃月底更新完,感謝支持。今天講解數據持久化到Mysql
視頻在線地址:
2026版【NLP輿情分析】基于python微博輿情分析可視化系統(flask+pandas+echarts+爬蟲) 視頻教程 (火爆連載更新中..)_嗶哩嗶哩_bilibili
課程簡介:
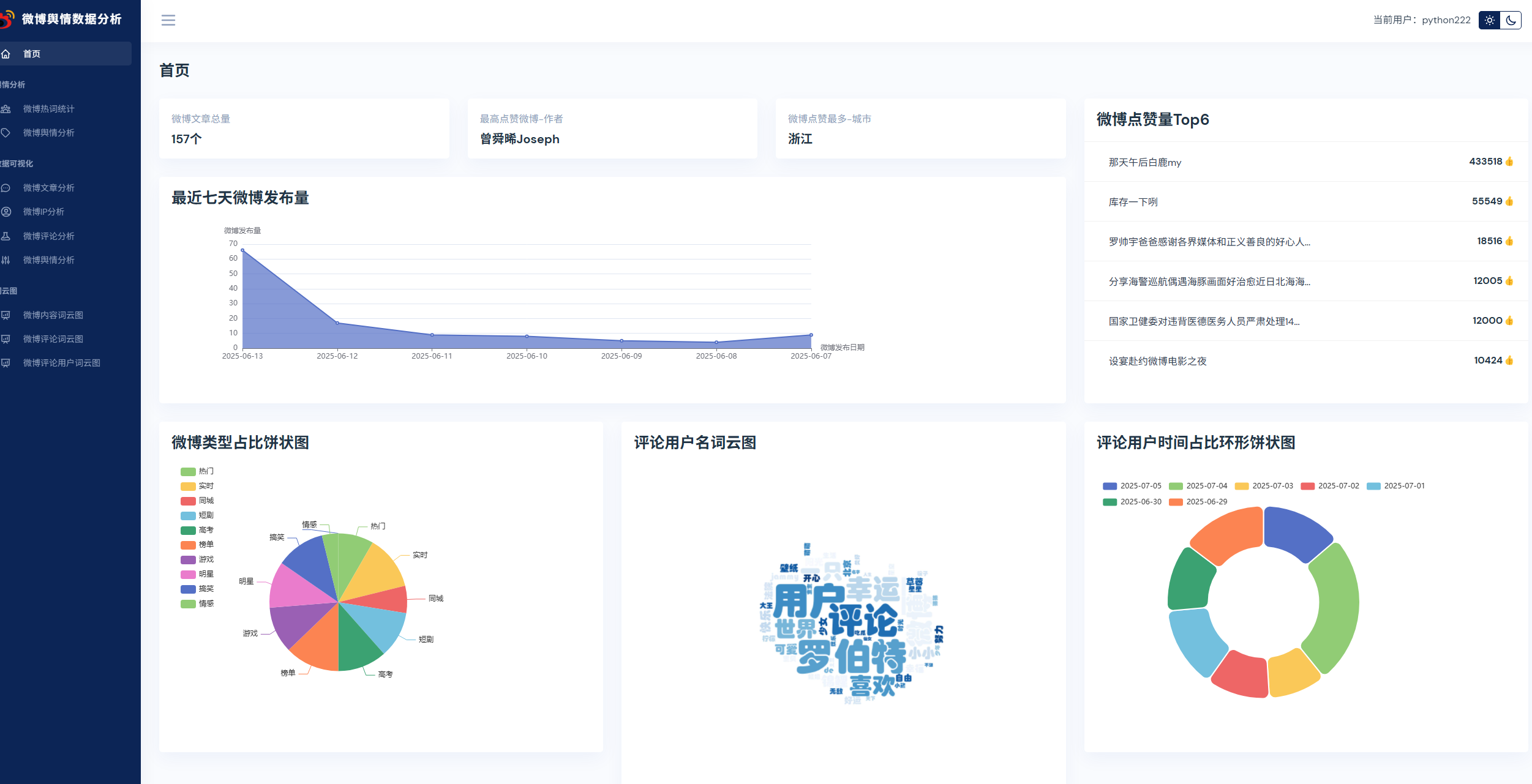
本課程采用主流的Python技術棧實現,Mysql8數據庫,Flask后端,Pandas數據分析,前端可視化圖表采用echarts,以及requests庫,snowNLP進行情感分析,詞頻統計,包括大量的數據統計及分析技巧。
實現了,用戶登錄,注冊,爬取微博帖子和評論信息,進行了熱詞統計以及輿情分析,以及基于echarts實現了數據可視化,包括微博文章分析,微博IP分析,微博評論分析,微博輿情分析。最后也基于wordcloud庫實現了詞云圖,包括微博內容詞云圖,微博評論詞云圖,微博評論用戶詞云圖等功能。
數據持久化到Mysql
前面我們抓取了微博類別,微博以及微博評論信息,存到了csv文件,但是有個問題,csv文件可能丟失,以及數據庫被覆蓋等問題。所以還是得持久化到數據庫。
一般處理流程有 1,爬數據 2,數據清洗 3,持久化到數據庫
持久化到數據庫的流程有細分下:先合并數據庫和csv文件到數據庫,再去重,然后存數據庫,最后再把兩個csv文件刪除。
新建main.py,下面是實現代碼:
"""爬數據,持久化到數據庫 主函數
"""
import os
import traceback
?
import pandas as pd
from sqlalchemy import create_engine
?
from article_spider import start as articleSpiderStart
from arcType_spider import start as arcTypeSpiderStart
?
engine = create_engine('mysql+pymysql://root:123456@localhost:3308/db_weibo2?charset=utf8mb4')
?
?
def dataClean():"""數據清洗 對csv文件數據處理 pandas庫處理:return:"""pass
?
?
def saveToDb():"""持久化到數據庫,先合并數據庫和csv數據庫,再去重,最后存數據庫:return:"""try:oldArticleDb = pd.read_sql('select * from t_article', engine)newArticleCsv = pd.read_csv('article_data.csv')concatArticlePd = pd.concat([newArticleCsv, oldArticleDb])resultArticlePd = concatArticlePd.drop_duplicates(subset='id', keep='last')resultArticlePd.to_sql('t_article', con=engine, if_exists='replace', index=False)
?oldCommentDb = pd.read_sql('select * from t_comment', engine)newCommentCsv = pd.read_csv('comment_data.csv')concatCommentPd = pd.concat([newCommentCsv, oldCommentDb])resultCommentPd = concatCommentPd.drop_duplicates(subset='id', keep='last')resultCommentPd.to_sql('t_comment', con=engine, if_exists='replace', index=False)except Exception as e:print('異常:', e)traceback.print_exc()newArticleCsv = pd.read_csv('article_data.csv')newCommentCsv = pd.read_csv('comment_data.csv')newArticleCsv.to_sql('t_article', con=engine, if_exists='replace', index=False)newCommentCsv.to_sql('t_comment', con=engine, if_exists='replace', index=False)
?os.remove('article_data.csv')os.remove('comment_data.csv')
?
?
if __name__ == '__main__':print("微博內容爬取開始...")articleSpiderStart()print("微博內容爬取結束...")
?print("微博評論爬取開始...")arcTypeSpiderStart()print("微博評論爬取結束...")
?print("數據清洗開始...")dataClean()print("數據清洗結束...")
?print("微博內容和評論信息持久化到數據庫開始...")saveToDb()print("微博內容和評論信息持久化到數據庫結束...")
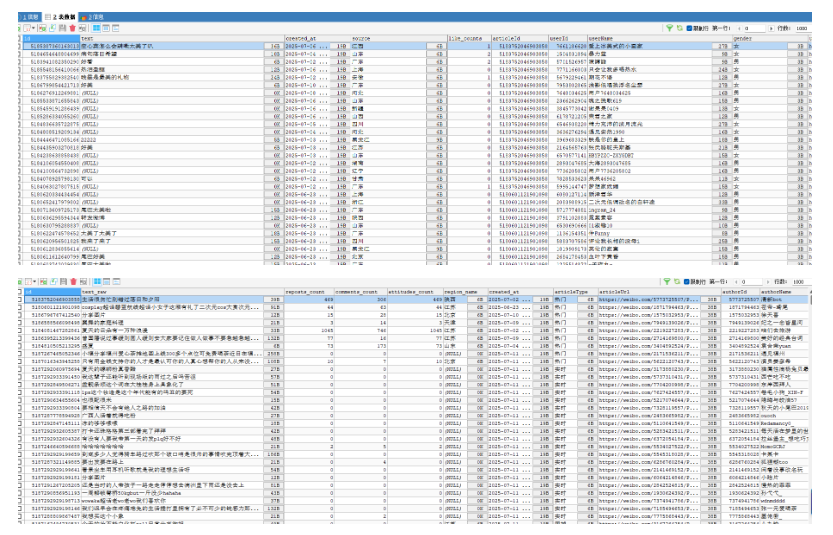
運行后,sqlalchemy自動創建兩個表。

)











)





