在大模型時代,單節點 GPU 資源往往難以滿足大模型(如 7B/13B 參數模型)的部署需求。借助 Ray 分布式框架,我們可以輕松實現跨節點 GPU 資源調度,讓大模型在多節點間高效運行。本文將以 DeepSeek-llm-7B-Chat 模型為例,詳細講解如何通過 Ray 搭建跨節點集群,結合 vLLM 實現分布式推理,并解決部署過程中的常見問題。
一、背景與目標
為什么需要跨節點 GPU 調用?
- 模型規模限制:7B 參數的 DeepSeek 模型單卡可加載,但更大的模型(如 33B)單卡顯存不足,需多卡并行。
- 資源利用率:跨節點調用可整合多臺服務器的 GPU 資源,避免單節點資源閑置。
- 分布式推理優勢:通過 Ray 的張量并行(Tensor Parallelism),模型層可拆分到不同節點的 GPU,提升推理效率。
本文目標
- 搭建包含 1 個主節點、2 個工作節點的 Ray 集群。
- 跨節點調用 2 張 GPU,用 vLLM 部署 DeepSeek-llm-7B-Chat 模型。
- 實現 OpenAI 兼容的 API 服務,支持客戶端調用。
二、環境準備
硬件要求
- 節點數量:3 臺服務器(1 主 2 從,支持 GPU)。
- 主節點(master):192.168.2.221,至少 1 張 GPU(本文用 Tesla V100-32GB)。
- 工作節點 1(worker1):192.168.2.226,至少 1 張 GPU。
- 工作節點 2(worker2):192.168.2.227,至少 1 張 GPU。
- 網絡:節點間內網互通(推薦 10Gbps 以上帶寬),支持 SSH 免密登錄。
軟件要求
| 工具 / 庫 | 版本 | 作用 |
|---|---|---|
| Python | 3.9 | 運行環境 |
| Ray | 2.9.0 | 分布式集群管理 |
| vLLM | 0.9.2 | 高效大模型推理引擎 |
| CUDA | 11.8 | GPU 加速 |
| DeepSeek-llm-7B-Chat | - | 目標部署模型 |
三、詳細部署步驟
步驟 1:全節點初始化環境(所有節點執行)
1.1 安裝系統依賴
解決后續可能出現的Python.h缺失問題(編譯 C 擴展時需要):
# 基于CentOS/RHEL的系統
dnf install -y python3-devel gcc gcc-c++# 基于Ubuntu的系統
# apt-get install -y python3-dev gcc g++
1.2 創建虛擬環境
統一環境避免依賴沖突:
# 安裝virtualenv
pip3 install virtualenv# 創建并激活虛擬環境
cd /opt
virtualenv vllm_env --python=python3.9
source vllm_env/bin/activate # 激活環境(后續所有操作均在此環境中執行)
1.3 安裝核心依賴
# 安裝Ray(包含集群管理和客戶端組件)
pip install "ray[default,client]" --upgrade# 安裝vLLM(支持分布式推理)
pip install vllm==0.9.2# 安裝其他工具(可選,用于測試)
pip install requests # 用于發送API請求
步驟 2:搭建 Ray 分布式集群
2.1 啟動主節點(master:192.168.2.221)
# 啟動Ray主節點,指定IP、端口和Dashboard
ray start --head \--node-ip-address 192.168.2.221 \ # 主節點IP--port 6379 \ # 端口(集群元數據存儲)--dashboard-host 0.0.0.0 \ # 允許外部訪問Dashboard--dashboard-port 8265 \ # Dashboard端口(用于監控集群)--include-dashboard=True \ # 啟用Dashboard啟動成功后,會顯示工作節點加入命令(需記錄):
To add another node to this Ray cluster, run:ray start --address='192.168.2.221:6379'
2.2 加入工作節點(worker1:192.168.2.226 和 worker2:192.168.2.227)
在兩個工作節點分別執行以下命令,加入主節點集群:
# 激活虛擬環境(同主節點路徑)
source /opt/vllm_env/bin/activate# 加入集群(使用主節點輸出的地址)
ray start \--address '192.168.2.221:6379' \ # 主節點地址--node-ip-address 192.168.2.226 # 當前工作節點IP(worker1填226,worker2填227)
2.3 驗證集群狀態(主節點執行)
# 查看集群節點信息
ray status
預期輸出(顯示 3 個節點,2 張 GPU 可用):
Node status
---------------------------------------------------------------
Healthy:1 node_abc... (192.168.2.221)1 node_def... (192.168.2.226)1 node_ghi... (192.168.2.227)
Resources
---------------------------------------------------------------
Total Usage: 0.0/192.0 CPU, 0.0/2.0 GPU # 2張GPU可用
步驟 3:部署 DeepSeek 模型(主節點執行)
3.1 準備模型
將 DeepSeek-llm-7B-Chat 模型下載到所有節點均可訪問的路徑(推薦用 NFS 共享,避免多節點重復下載):
# 示例:通過Hugging Face Hub下載(需提前登錄hf-cli)
huggingface-cli download deepseek-ai/deepseek-llm-7b-chat --local-dir /data/storage/data/VLLM_MODE/deepseek-llm-7b-chat
3.2 啟動 vLLM 服務(支持跨節點 GPU 調用)
# 激活虛擬環境
source /opt/vllm_env/bin/activate# 設置Ray集群地址
export RAY_ADDRESS="192.168.2.221:6379"# 啟動OpenAI兼容的API服務
python -m vllm.entrypoints.openai.api_server \--model /data/storage/data/VLLM_MODE/deepseek-llm-7b-chat \ # 模型路徑--port 9001 \ # API服務端口--host 0.0.0.0 \ # 允許外部訪問--tensor-parallel-size 2 \ # 張量并行數(=總GPU數)--distributed-executor-backend ray \ # 使用Ray作為分布式后端--gpu-memory-utilization 0.9 # GPU內存利用率(90%)
啟動成功的關鍵日志:
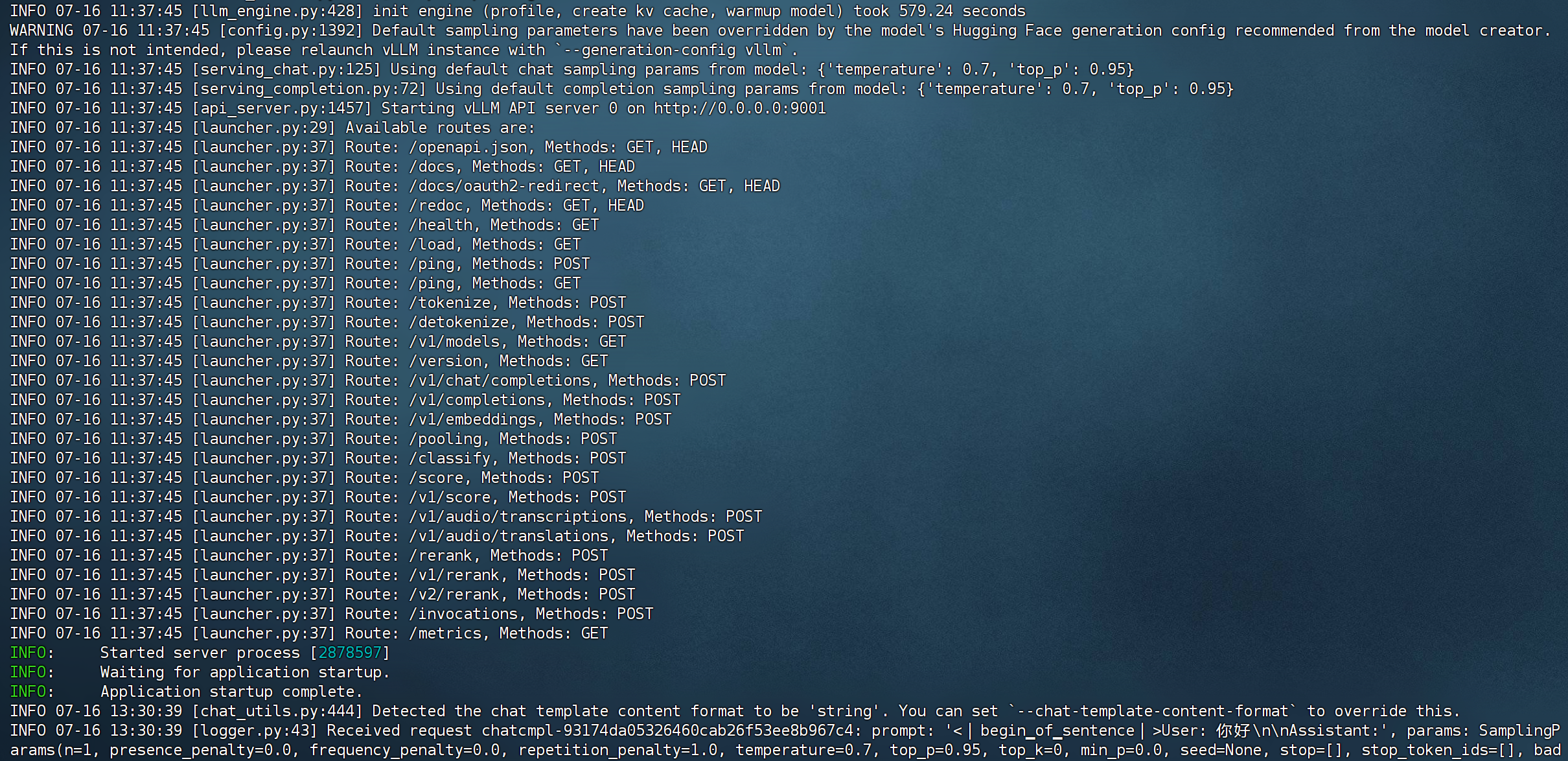
步驟 4:驗證跨節點 GPU 調用
4.1 檢查 GPU 使用情況(工作節點執行)
在 worker1(192.168.2.226)和 worker2(192.168.2.227)分別執行nvidia-smi,可看到 GPU 被 vLLM 進程占用:
nvidia-smi
預期輸出(關鍵信息):
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 872773 C ...vllm_env/bin/python 28511MiB | # vLLM進程占用
+-----------------------------------------------------------------------------+
說明兩個節點的 GPU 均被成功調用(每張卡負載約 28GB,符合 7B 模型 + 90% 內存利用率的預期)。
4.2 測試模型推理(客戶端執行)
通過 API 發送請求測試:
# 發送推理請求
curl http://192.168.2.221:9001/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "deepseek-llm-7b-chat","messages": [{"role": "user", "content": "介紹一下Ray和vLLM的關系"}]}'
成功響應示例(部分):
json
{"id": "chatcmpl-xxx","object": "chat.completion","created": 1689523456,"model": "deepseek-llm-7b-chat","choices": [{"message": {"role": "assistant","content": "Ray是一個分布式計算框架,可用于管理跨節點的GPU資源...vLLM是高效的大模型推理引擎,通過Ray實現分布式部署..."},"finish_reason": "stop","index": 0}]
}
步驟 5:Ray 集群的停止與清理
當需要更新配置或重啟集群時,需徹底停止 Ray 進程并清理殘留數據,避免舊會話信息干擾:
# 停止當前節點的 Ray 進程
ray stop# 若 ray stop 無效,直接 kill 殘留進程(謹慎使用,確保只 kill Ray 相關進程)
pkill -f ray# 清理 Ray 臨時目錄(包含Redis數據、會話信息等)
rm -rf /tmp/ray/*
注意:以上命令需在所有節點執行(主節點 + 工作節點),確保集群完全停止。清理完成后,可重新執行步驟 2 和步驟 3 啟動新集群。
四、常見問題與解決方案
問題 1:Python.h: No such file or directory

- 原因:缺少 Python 開發庫,編譯 C 擴展時失敗。
- 解決:安裝
python3-devel:dnf install python3-devel # CentOS/RHEL # 或 apt-get install python3-dev # Ubuntu
問題 2:ModuleNotFoundError: No module named 'vllm'
- 原因:工作節點未安裝 vLLM。
- 解決:在所有工作節點的虛擬環境中安裝 vLLM:
source /opt/vllm_env/bin/activate pip install vllm==0.9.2
問題 3:Ray Client 連接超時
- 原因:6379 端口未開放或 Ray Client 服務未啟動。
- 解決:
# 主節點開放端口 firewall-cmd --add-port=6379/tcp --permanent firewall-cmd --reload# 重啟Ray時顯式指定Client端口 ray start --head ... --ray-client-server-port 6379
問題 4:GPU 資源不足
- 原因:
tensor-parallel-size超過實際 GPU 數量。 - 解決:確保
--tensor-parallel-size等于集群總 GPU 數(本文為 2)。
關鍵代碼
pip install "ray[default]" --upgrade
ray start --head --node-ip-address 192.168.2.221 --port 6379 --dashboard-host 0.0.0.0 --dashboard-port 8265 --include-dashboard=True 創建master ray主節點
ray start --address '192.168.2.221:6379' --node-ip-address 192.168.2.226
ray start --address '192.168.2.221:6379' --node-ip-address 192.168.2.227cd /opt/
source vllm_env/bin/activateexport HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download deepseek-ai/deepseek-llm-7b-chat --local-dir /data/storage/data/VLLM_MODE/deepseek-llm-7b-chatRAY_ADDRESS="192.168.2.221:6379" python -m vllm.entrypoints.openai.api_server --model /data/storage/data/VLLM_MODE/deepseek-llm-7b-chat --port 9001 --host 0.0.0.0 --tensor-parallel-size 2 --distributed-executor-backend ray --gpu-memory-utilization 0.9


)

)





)



和SVN-VS2022插件(visualsvn)官網下載)




