- 查看環境
- 確定安裝版本
- 安裝CUDA12.8
- 安裝Anaconda
- 安裝Visual Studio C++桌面開發環境(編譯llama.cpp需要)
- 安裝cmake(編譯llama.cpp需要)
- 安裝llama.cpp(用于量化)
- 安裝huggingface-cli
- 安裝llama-factory
- 安裝PyTorch2.7.0
- 安裝bitsandbytes
- 安裝flash-attention加速(減少內存的)
- 安裝unsloth加速(減少顯存的)
- 安裝deepspeed加速(分布式訓練)
- 測試環境
- 準備數據集
- 修改配置以適配多顯卡
- 訓練
參考鏈接
查看環境
CPU:R7 9800X3D
RAM:96GB(5600)
GPU:5060Ti 16GB * 2
nvidia-smi

我的顯卡是5060Ti,CUDA版本為12.9,理論上有11.8、12.6、12.8三個版本可以以使用,但是在實際中,11.8、12.6是不支持50系顯卡的,所以需要使用12.8
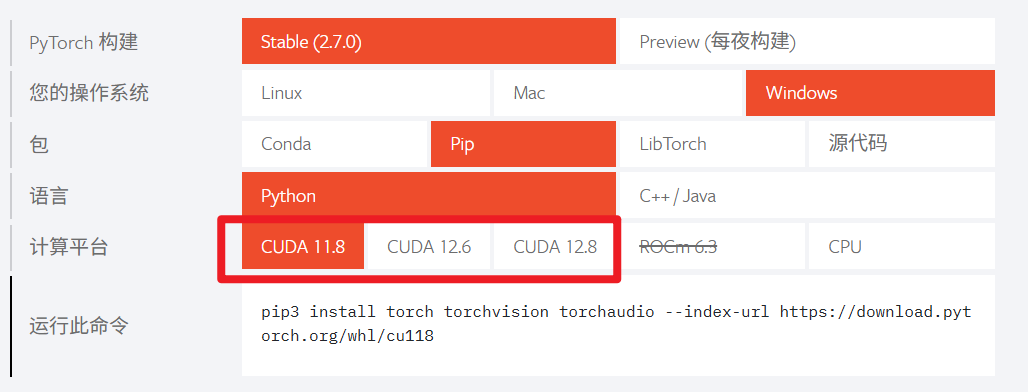
安裝環境
根據硬件環境確定了軟件環境
選擇環境為Python3.12.10+CUDA12.8+PyTorch2.7.0
在安裝之前需要先安裝Anaconda、python和Visual Studio的C++桌面開發環境
安裝llama.cpp
下載(需要先安裝 CUDA 和 python ):
安裝 curl(使用聯網下載模型,可選)
git clone https://github.com/microsoft/vcpkg.git
cd vcpkg
.\bootstrap-vcpkg.bat
.\vcpkg install curl:x64-windows
需手動新建模型下載目錄C:\Users\Administrator\AppData\Local\llama.cpp
git clone https://github.com/ggerganov/llama.cpp.gitcd llama.cpp
cmake -B build -DGGML_CUDA=ON -DLLAMA_CURL=OFF
cmake --build build --config Release
-B build:指定構建目錄為 ./build。
-DGGML_CUDA=ON:啟用 CUDA 支持(需已安裝 CUDA 工具包)。
-DLLAMA_CURL=ON:啟用 CURL 支持(需已安裝 curl)
安裝依賴:
# 也可以手動安裝 torch 之后,再安裝剩下的依賴
pip install -r requirements.txt
進入build\bin\Release目錄開始使用llama
安裝huggingface-cli
用于下載模型
pip install -U huggingface_hub
設置環境變量:

| 變量名 | 說明 |
|---|---|
| HF_HOME | 模型保存路徑 |
| HF_ENDPOINT | 從什么地方下載模型:使用國內鏡像站:https://hf-mirror.com |
下載指令如下:
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1 --local-dir e:/model --local-dir-use-symlinks False
--resume-download已棄用
--local-dir保存路徑
deepseek-ai/DeepSeek-R1為下載的模型
--local-dir-use-symlinks False 取消軟連接,Windows中沒有軟鏈接
可以簡化為:
huggingface-cli download deepseek-ai/DeepSeek-R1

下載LLaMa-factory:
git clone https://github.com/hiyouga/LLaMA-Factory.git
安裝LLaMa-factory:
如果出現環境沖突,請嘗試使用pip install --no-deps -e解決
conda create -n llama_factory python=3.12
conda activate llama_factory
cd LLaMA-Factory
pip install -e .[metrics]
這里指定metrics參數是安裝jieba分詞庫等,方面后續可能要訓練或者微調中文數據集。
可選的額外依賴項:torch、torch-npu、metrics、deepspeed、liger-kernel、bitsandbytes、hqq、eetq、gptq、aqlm、vllm、sglang、galore、apollo、badam、adam-mini、qwen、minicpm_v、modelscope、openmind、swanlab、quality
| 名稱 | 描述 |
|---|---|
| torch | 開源深度學習框架 PyTorch,廣泛用于機器學習和人工智能研究中。 |
| torch-npu | PyTorch 的昇騰設備兼容包。 |
| metrics | 用于評估和監控機器學習模型性能。 |
| deepspeed | 提供了分布式訓練所需的零冗余優化器。 |
| bitsandbytes | 用于大型語言模型量化。 |
| hqq | 用于大型語言模型量化。 |
| eetq | 用于大型語言模型量化。 |
| gptq | 用于加載 GPTQ 量化模型。 |
| awq | 用于加載 AWQ 量化模型。 |
| aqlm | 用于加載 AQLM 量化模型。 |
| vllm | 提供了高速并發的模型推理服務。 |
| galore | 提供了高效全參微調算法。 |
| badam | 提供了高效全參微調算法。 |
| qwen | 提供了加載 Qwen v1 模型所需的包。 |
| modelscope | 魔搭社區,提供了預訓練模型和數據集的下載途徑。 |
| swanlab | 開源訓練跟蹤工具 SwanLab,用于記錄與可視化訓練過程 |
| dev | 用于 LLaMA Factory 開發維護。 |
安裝好后就可以使用llamafactory-cli webui打開web頁面了
如果出現找不到llamafactory-cli,是沒有將該路徑加入環境變量,找到程序所在路徑,加入path環境變量即可
安裝CUDA12.8+PyTorch2.7.0
因為上述方式似乎默認安裝了一個CPU版本的pytorch,但是版本不是我們想要的,直接安裝覆蓋即可。具體方法根據PyTorch相應版本提供的安裝方式進行安裝
pip3 install torch==2.7.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
CUDA下載鏈接:https://developer.nvidia.com/cuda-toolkit-archive
選擇適合的版本進行安裝,安裝好后通過nvcc --version查看是否安裝成功,如果成功輸出版本號則安裝成功
nvcc --version
安裝bitsandbytes
如果要在 Windows 平臺上開啟量化 LoRA(QLoRA),需要安裝 bitsandbytes 庫
使用pip安裝
pip install bitsandbytes
也可以使用已經編譯好的,支持 CUDA 11.1 到 12.2, 根據 CUDA 版本情況選擇適合的發布版本。
https://github.com/jllllll/bitsandbytes-windows-webui/releases/tag/wheels
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
如果上面的方法都不行,就使用源碼安裝
git clone https://github.com/timdettmers/bitsandbytes.git
cd bitsandbytes
set CUDA_VERSION=128
make cuda12x
python setup.py install
windows中如果無法使用make可以使用cmake
cmake -B . -DCOMPUTE_BACKEND=cuda -S .
cmake --build .
pip install .
Windows的make下載地址:https://gnuwin32.sourceforge.net/packages/make.html
加速
LLaMA-Factory 支持多種加速技術,包括:FlashAttention 、 Unsloth 、 Liger Kernel 。
三種方法選擇其中一個就可以了,或者不安裝。
安裝flash-attention
FlashAttention 能夠加快注意力機制的運算速度,同時減少對內存的使用。
檢查環境:
pip debug --verbose

編譯好的下載鏈接:https://github.com/bdashore3/flash-attention/releases

由于沒有完全匹配的版本,所以選擇了最接近的一個版本
使用pip安裝
pip install E:\wheels\flash_attn-2.7.4.post1+cu124torch2.6.0cxx11abiFALSE-cp312-cp312-win_amd64.whl
如果無法使用可能需要源碼編譯安裝https://huggingface.co/lldacing/flash-attention-windows-wheel
Unsloth安裝
Unsloth 框架支持 Llama, Mistral, Phi-3, Gemma, Yi, DeepSeek, Qwen等大語言模型并且支持 4-bit 和 16-bit 的 QLoRA/LoRA 微調,該框架在提高運算速度的同時還減少了顯存占用。
需要先安裝xformers, torch, BitsandBytes 和triton,并且只支持NVIDIA顯卡
pip install unsloth
顯存和參數關系
| 模型參數 | QLoRA (4-bit) VRAM | LoRA (16-bit) VRAM |
|---|---|---|
| 3B | 3.5 GB | 8 GB |
| 7B | 5 GB | 19 GB |
| 8B | 6 GB | 22 GB |
| 9B | 6.5 GB | 24 GB |
| 11B | 7.5 GB | 29 GB |
| 14B | 8.5 GB | 33 GB |
| 27B | 22 GB | 64 GB |
| 32B | 26 GB | 76 GB |
| 40B | 30 GB | 96 GB |
| 70B | 41 GB | 164 GB |
| 81B | 48 GB | 192 GB |
| 90B | 53 GB | 212 GB |
| 405B | 237 GB | 950 GB |
Liger Kernel安裝
Liger Kernel是一個大語言模型訓練的性能優化框架, 可有效地提高吞吐量并減少內存占用。
測試
測試PyTorch和CUDA
編寫一個測試程序
import os
import torchos.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
print("PyTorch Version:", torch.__version__)
print("CUDA Available:", torch.cuda.is_available())if torch.cuda.is_available():print("CUDA Version:", torch.version.cuda)print("Current CUDA Device Index:", torch.cuda.current_device())print("Current CUDA Device Name:", torch.cuda.get_device_name(0))
else:print("CUDA is not available on this system.")
運行:

測試依賴庫
對基礎安裝的環境做一下校驗,輸入以下命令獲取訓練相關的參數指導, 否則說明庫還沒有安裝成功
llamafactory-cli train -h

Windows中如果報libuv的錯,則使用以下命令
set USE_LIBUV=0 && llamafactory-cli train -h

雙顯卡在Windows平臺會報錯,需要禁用一張顯卡,或者使用以下環境變量試試
set CUDA_VISIBLE_DEVICES=0,1

測試環境是否正常
windows似乎不支持CUDA_VISIBLE_DEVICES=0指定顯卡,并且也不支持”\“換行console,分別對應修改:
對于第一個問題,一種方式是修改環境變量,在用戶變量或者系統變量加一行就可以。CUDA_VISIBLE_DEVICES 0
llamafactory-cli webchat --model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct --template llama3
llamafactory-cli webchat E:hf\hub\LLaMA-Factory\examples\inference\llama3.yaml
訓練
pip install deepspeed
Windows平臺下在模型訓練的過程中出現 “RuntimeError: CUDA Setup failed despite GPU being available” 的錯誤,導致訓練中斷。
處理方法1:
pip uninstall bitsandbytes
pip install bitsandbytes-windows
執行上述的命令如果沒有解決問題,試一下一下方法:
pip uninstall bitsandbytes
pip install bitsandbytes-cuda128
pip uninstall bitsandbytes-cuda128
pip install bitsandbytes
在運行過程中所有的錯誤無非兩種情況造成的。
- 情況1:安裝環境出現沖突(包的依賴出現沖突或者CUDA的版本沒有安裝對);
- 情況2:權限不夠(sudo運行或者管理員下運行即可解決,一般報錯信息中會出現permission字樣)
webui微調
參考鏈接1
參考鏈接2
參考鏈接3
代碼微調
'''
需要的依賴torchtransformersdatasetspeftbitsandbytes
'''# 測試模型是否可用
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
# 加載模型 Hugging face提前下載
model_name = r'E:\hf\DeepSeekR1DistillQwen1.5B'
tokenizer = AutoTokenizer.from_pretrained(model_name)# 模型加載成功之后注釋model代碼,否則每次都占用內存 (如果內存不夠,可以使用device_map='auto')
model = AutoModelForCausalLM.from_pretrained(model_name,device_map='auto',trust_remote_code=True)for name, param in model.named_parameters():if param.is_meta:raise ValueError(f"Parameter {name} is in meta device.")print('---------------模型加載成功-------------')# 制作數據集
from data_prepare import samples
import json
with open('datasets.jsonl','w',encoding='utf-8') as f:for s in samples:json_line = json.dumps(s,ensure_ascii=False)f.write(json_line + '\n')else:print('-------數據集制作完成------')# 準備訓練集和測集
from datasets import load_dataset
dataset = load_dataset('json',data_files={'train':'datasets.jsonl'},split='train')
print('數據的數量',len(dataset))train_test_split = dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split['train']
eval_dataset = train_test_split['test']
print('訓練集的數量',len(train_dataset))
print('測試集的數量',len(eval_dataset))print('--------完成訓練數據的準備工作--------')# 編寫tokenizer處理工具
def tokenize_function(examples):texts = [f"{prompt}\n{completion}" for prompt , completion in zip(examples['prompt'],examples['completion'])]tokens = tokenizer(texts,truncation=True,max_length=512,padding="max_length")tokens["labels"] = tokens["input_ids"].copy()return tokenstokenized_train_dataset = train_dataset.map(tokenize_function,batched=True)
tokenized_eval_dataset = eval_dataset.map(tokenize_function,batched=True)print('---------完成tokenizer-------------')
# print(tokenized_eval_dataset[0])# 量化設置import torch
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.bfloat16,device_map="auto"
)
print('-----------完成量化模型的加載-----------------')# lora設置
from peft import LoraConfig,get_peft_model,TaskType
lora_config = LoraConfig(r=8,lora_alpha=16,target_modules=["q_proj","v_proj"],lora_dropout=0.05,bias="none",task_type=TaskType.CAUSAL_LM
)
model = get_peft_model(model,lora_config)
model.print_trainable_parameters()
print('-----------完成lora模型的加載-----------------')# 設置訓練參數
training_args = TrainingArguments(output_dir="./results",num_train_epochs=3,per_device_train_batch_size=8,per_device_eval_batch_size=8,gradient_accumulation_steps=4,fp16=True,evaluation_strategy="steps",save_steps=100,eval_steps=10,learning_rate=3e-5,logging_dir="./logs",run_name='deepseek1.5b',# 后期增加的內容label_names=["labels"], # 必須顯式指定remove_unused_columns=False, # 確保不自動刪除標簽字段
)
print('--------訓練參數設置完畢----------')# 定義訓練器
from transformers import Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_train_dataset,eval_dataset=tokenized_eval_dataset
)print('--------訓練器定義完畢----------')
print('----------開始訓練-------------')
trainer.train()
print('----------訓練完成-------------')
微調原理
數據處理
dataset_info.json包含了所有經過預處理的 本地數據集 以及 在線數據集。如果使用自定義數據集,在 dataset_info.json文件中添加對數據集及其內容的定義。
目前 LLaMA Factory支持 Alpaca格式和 ShareGPT格式的數據集。
Alpaca
針對不同任務,數據集格式要求如下:
- 指令監督微調
- 預訓練
- 偏好訓練
- KTO
- 多模態
指令監督微調數據集
樣例數據集: 指令監督微調樣例數據集
指令監督微調(Instruct Tuning)通過讓模型學習詳細的指令以及對應的回答來優化模型在特定指令下的表現。
instruction 列對應的內容為人類指令, input 列對應的內容為人類輸入, output 列對應的內容為模型回答。下面是一個例子
{"instruction": "計算這些物品的總費用。 ","input": "輸入:汽車 - $3000,衣服 - $100,書 - $20。","output": "汽車、衣服和書的總費用為 $3000 + $100 + $20 = $3120。"
},
在進行指令監督微調時, instruction 列對應的內容會與 input 列對應的內容拼接后作為最終的人類輸入,即人類輸入為 instruction\input。而 output 列對應的內容為模型回答。 在上面的例子中,人類的最終輸入是:
計算這些物品的總費用。
輸入:汽車 - $3000,衣服 - $100,書 - $20。
模型的回答是:
汽車、衣服和書的總費用為 $3000 + $100 + $20 = $3120。
如果指定, system 列對應的內容將被作為系統提示詞。
history 列是由多個字符串二元組構成的列表,分別代表歷史消息中每輪對話的指令和回答。注意在指令監督微調時,歷史消息中的回答內容也會被用于模型學習。
指令監督微調數據集 格式要求 如下:
[{"instruction": "人類指令(必填)","input": "人類輸入(選填)","output": "模型回答(必填)","system": "系統提示詞(選填)","history": [["第一輪指令(選填)", "第一輪回答(選填)"],["第二輪指令(選填)", "第二輪回答(選填)"]]}
]
下面提供一個 alpaca 格式 多輪 對話的例子,對于單輪對話只需省略 history 列即可。
[{"instruction": "今天的天氣怎么樣?","input": "","output": "今天的天氣不錯,是晴天。","history": [["今天會下雨嗎?","今天不會下雨,是個好天氣。"],["今天適合出去玩嗎?","非常適合,空氣質量很好。"]]}
]
對于上述格式的數據, dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"}
}
預訓練數據集
樣例數據集: 預訓練樣例數據集
大語言模型通過學習未被標記的文本進行預訓練,從而學習語言的表征。通常,預訓練數據集從互聯網上獲得,因為互聯網上提供了大量的不同領域的文本信息,有助于提升模型的泛化能力。 預訓練數據集文本描述格式如下:
[{"text": "document"},{"text": "document"}
]
在預訓練時,只有 text 列中的 內容 (即document)會用于模型學習。
對于上述格式的數據, dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","columns": {"prompt": "text"}
}
偏好數據集
偏好數據集用于獎勵模型訓練、DPO 訓練和 ORPO 訓練。對于系統指令和人類輸入,偏好數據集給出了一個更優的回答和一個更差的回答。
一些研究 表明通過讓模型學習“什么更好”可以使得模型更加迎合人類的需求。 甚至可以使得參數相對較少的模型的表現優于參數更多的模型。
偏好數據集需要在 chosen 列中提供更優的回答,并在 rejected 列中提供更差的回答,在一輪問答中其格式如下:
[{"instruction": "人類指令(必填)","input": "人類輸入(選填)","chosen": "優質回答(必填)","rejected": "劣質回答(必填)"}
]
對于上述格式的數據,dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","ranking": true,"columns": {"prompt": "instruction","query": "input","chosen": "chosen","rejected": "rejected"}
}
KTO 數據集
KTO數據集與偏好數據集類似,但不同于給出一個更優的回答和一個更差的回答,KTO數據集對每一輪問答只給出一個 true/false 的 label。 除了 instruction 以及 input 組成的人類最終輸入和模型回答 output ,KTO 數據集還需要額外添加一個 kto_tag 列(true/false)來表示人類的反饋。
在一輪問答中其格式如下:
[{"instruction": "人類指令(必填)","input": "人類輸入(選填)","output": "模型回答(必填)","kto_tag": "人類反饋 [true/false](必填)"}
]
對于上述格式的數據, dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","kto_tag": "kto_tag"}
}
多模態數據集
LLaMA Factory 目前支持多模態圖像數據集、 視頻數據集 以及 音頻數據集 的輸入。
圖像數據集
多模態圖像數據集需要額外添加一個 images 列,包含輸入圖像的路徑。 注意圖片的數量必須與文本中所有 <image> 標記的數量嚴格一致。
[{"instruction": "人類指令(必填)","input": "人類輸入(選填)","output": "模型回答(必填)","images": ["圖像路徑(必填)"]}
]
對于上述格式的數據, dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","images": "images"}
}
視頻數據集
多模態視頻數據集需要額外添加一個 videos 列,包含輸入視頻的路徑。 注意視頻的數量必須與文本中所有 <video> 標記的數量嚴格一致。
[{"instruction": "人類指令(必填)","input": "人類輸入(選填)","output": "模型回答(必填)","videos": ["視頻路徑(必填)"]}
]
對于上述格式的數據, dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","videos": "videos"}
}
音頻數據集
多模態音頻數據集需要額外添加一個 audio 列,包含輸入圖像的路徑。 注意音頻的數量必須與文本中所有 <audio> 標記的數量嚴格一致。
[{"instruction": "人類指令(必填)","input": "人類輸入(選填)","output": "模型回答(必填)","audios": ["音頻路徑(必填)"]}
]
對于上述格式的數據, dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","audios": "audios"}
}
ShareGPT
針對不同任務,數據集格式要求如下:
指令監督微調偏好訓練OpenAI格式
ShareGPT格式中的 KTO數據集(樣例)和多模態數據集(樣例) 與Alpaca格式的類似。
預訓練數據集不支持ShareGPT格式。
指令監督微調數據集
樣例數據集: 指令監督微調樣例數據集
相比 alpaca 格式的數據集, sharegpt 格式支持 更多 的角色種類,例如 human、gpt、observation、function 等等。它們構成一個對象列表呈現在 conversations 列中。 下面是 sharegpt 格式的一個例子:
{"conversations": [{"from": "human","value": "你好,我出生于1990年5月15日。你能告訴我我今天幾歲了嗎?"},{"from": "function_call","value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}"},{"from": "observation","value": "{\"age\": 31}"},{"from": "gpt","value": "根據我的計算,你今天31歲了。"}],"tools": "[{\"name\": \"calculate_age\", \"description\": \"根據出生日期計算年齡\", \"parameters\": {\"type\": \"object\", \"properties\": {\"birthdate\": {\"type\": \"string\", \"description\": \"出生日期以YYYY-MM-DD格式表示\"}}, \"required\": [\"birthdate\"]}}]"
}
注意其中 human 和 observation 必須出現在奇數位置,gpt 和 function 必須出現在偶數位置。
[{"conversations": [{"from": "human","value": "人類指令"},{"from": "function_call","value": "工具參數"},{"from": "observation","value": "工具結果"},{"from": "gpt","value": "模型回答"}],"system": "系統提示詞(選填)","tools": "工具描述(選填)"}
]
對于上述格式的數據, dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "conversations","system": "system","tools": "tools"}
}
偏好數據集
樣例數據集: 偏好數據樣例數據集
Sharegpt 格式的偏好數據集同樣需要在 chosen 列中提供更優的消息,并在 rejected 列中提供更差的消息。 下面是一個例子:
{"conversations": [{"from": "human","value": "老虎會吃哪一個,草還是樹葉?"}],"chosen": {"from": "gpt","value": "我很高興能幫助你解答問題!不過,我必須指出,這個問題本身可能沒有意義。老虎是食肉動物,通常不吃草或樹葉。它們的飲食主要包括大型有蹄動物、小型哺乳動物和鳥類。\n\n如果你提出這個問題是出于好奇或有特定原因,我很樂意幫助你找到更多關于老虎飲食習慣的信息,或者建議資源讓你更多了解這些壯麗的生物。請告訴我如何進一步協助你!"},"rejected": {"from": "gpt","value": "一只老虎是食肉動物,這意味著它的飲食主要是肉類。老虎主要獵捕和吃其他動物,如鹿和野豬。它們不會選擇吃草或樹葉,因為這些不是它們自然飲食的一部分。"}
}
其格式為:
[{"conversations": [{"from": "human","value": "人類指令"},{"from": "gpt","value": "模型回答"},{"from": "human","value": "人類指令"}],"chosen": {"from": "gpt","value": "優質回答"},"rejected": {"from": "gpt","value": "劣質回答"}}
]
對于上述格式的數據,dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","formatting": "sharegpt","ranking": true,"columns": {"messages": "conversations","chosen": "chosen","rejected": "rejected"}
}
OpenAI格式
OpenAI 格式僅僅是 sharegpt 格式的一種特殊情況,其中第一條消息可能是系統提示詞。
[{"messages": [{"role": "system","content": "系統提示詞(選填)"},{"role": "user","content": "人類指令"},{"role": "assistant","content": "模型回答"}]}
]
對于上述格式的數據, dataset_info.json 中的 數據集描述 應為:
"數據集名稱": {"file_name": "data.json","formatting": "sharegpt","columns": {"messages": "messages"},"tags": {"role_tag": "role","content_tag": "content","user_tag": "user","assistant_tag": "assistant","system_tag": "system"}
}
加速
如果使用 FlashAttention,在啟動訓練時在訓練配置文件中添加以下參數:
flash_attn: fa2
如果使用 Unsloth, 在啟動訓練時在訓練配置文件中添加以下參數:
use_unsloth: True
如果使用 Liger Kernel,在啟動訓練時在訓練配置文件中添加以下參數:
enable_liger_kernel: True
分布訓練
LLaMA-Factory 支持單機多卡和多機多卡分布式訓練。同時也支持 DDP , DeepSpeed 和 FSDP 三種分布式引擎。
DDP (DistributedDataParallel) 通過實現模型并行和數據并行實現訓練加速。 使用 DDP 的程序需要生成多個進程并且為每個進程創建一個 DDP 實例,他們之間通過 torch.distributed 庫同步。
DeepSpeed 是微軟開發的分布式訓練引擎,并提供ZeRO(Zero Redundancy Optimizer)、offload、Sparse Attention、1 bit Adam、流水線并行等優化技術。 您可以根據任務需求與設備選擇使用。
FSDP 通過全切片數據并行技術(Fully Sharded Data Parallel)來處理更多更大的模型。在 DDP 中,每張 GPU 都各自保留了一份完整的模型參數和優化器參數。而 FSDP 切分了模型參數、梯度與優化器參數,使得每張 GPU 只保留這些參數的一部分。 除了并行技術之外,FSDP 還支持將模型參數卸載至CPU,從而進一步降低顯存需求。
| 引擎 | 數據切分 | 模型切分 | 優化器切分 | 參數卸載 |
|---|---|---|---|---|
| DDP | 支持 | 不支持 | 不支持 | 不支持 |
| DeepSpeed | 支持 | 支持 | 支持 | 支持 |
| FSDP | 支持 | 支持 | 支持 | 支持 |
NativeDDP
NativeDDP 是 PyTorch 提供的一種分布式訓練方式,您可以通過以下命令啟動訓練:
單機多卡
llamafactory-cli
使用 llamafactory-cli 啟動 NativeDDP 引擎。
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml
如果 CUDA_VISIBLE_DEVICES 沒有指定,則默認使用所有GPU。如果需要指定GPU,例如第0、1個GPU,可以使用:
FORCE_TORCHRUN=1 CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli train config/config1.yaml
torchrun
使用 torchrun 指令啟動 NativeDDP 引擎進行單機多卡訓練。下面提供一個示例:
torchrun --standalone --nnodes=1 --nproc-per-node=8 src/train.py \
--stage sft \
--model_name_or_path meta-llama/Meta-Llama-3-8B-Instruct \
--do_train \
--dataset alpaca_en_demo \
--template llama3 \
--finetuning_type lora \
--output_dir saves/llama3-8b/lora/ \
--overwrite_cache \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 100 \
--save_steps 500 \
--learning_rate 1e-4 \
--num_train_epochs 2.0 \
--plot_loss \
--bf16
accelerate
使用 accelerate 指令啟動進行單機多卡訓練。
首先運行以下命令,根據需求回答一系列問題后生成配置文件:
accelerate config
下面提供一個示例配置文件:
# accelerate_singleNode_config.yaml
compute_environment: LOCAL_MACHINE
debug: true
distributed_type: MULTI_GPU
downcast_bf16: 'no'
enable_cpu_affinity: false
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
通過運行以下指令開始訓練:
accelerate launch \
--config_file accelerate_singleNode_config.yaml \
src/train.py training_config.yaml
多機多卡
llamafactory-cli
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yamlFORCE_TORCHRUN=1 NNODES=2 NODE_RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 \
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
| 變量名 | 介紹 |
|---|---|
| FORCE_TORCHRUN | 是否強制使用torchrun |
| NNODES | 節點數量 |
| NODE_RANK | 各個節點的rank。 |
| MASTER_ADDR | 主節點的地址。 |
| MASTER_PORT | 主節點的端口。 |
torchrun
使用 torchrun 指令啟動 NativeDDP 引擎進行多機多卡訓練。
torchrun --master_port 29500 --nproc_per_node=8 --nnodes=2 --node_rank=0 \
--master_addr=192.168.0.1 train.py
torchrun --master_port 29500 --nproc_per_node=8 --nnodes=2 --node_rank=1 \
--master_addr=192.168.0.1 train.py
accelerate
使用 accelerate 指令啟動進行多機多卡訓練。
首先運行以下命令,根據需求回答一系列問題后生成配置文件:
accelerate config
下面提供一個示例配置文件:
# accelerate_multiNode_config.yaml
compute_environment: LOCAL_MACHINE
debug: true
distributed_type: MULTI_GPU
downcast_bf16: 'no'
enable_cpu_affinity: false
gpu_ids: all
machine_rank: 0
main_process_ip: '192.168.0.1'
main_process_port: 29500
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 16
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
您可以通過運行以下指令開始訓練:
accelerate launch \
--config_file accelerate_multiNode_config.yaml \
train.py llm_config.yaml
DeepSpeed
DeepSpeed 是由微軟開發的一個開源深度學習優化庫,旨在提高大模型訓練的效率和速度。在使用 DeepSpeed 之前,需要先估計訓練任務的顯存大小,再根據任務需求與資源情況選擇合適的 ZeRO 階段。
ZeRO-1: 僅劃分優化器參數,每個GPU各有一份完整的模型參數與梯度。ZeRO-2: 劃分優化器參數與梯度,每個GPU各有一份完整的模型參數。ZeRO-3: 劃分優化器參數、梯度與模型參數。
簡單來說:從 ZeRO-1 到 ZeRO-3,階段數越高,顯存需求越小,但是訓練速度也依次變慢。此外,設置 offload_param=cpu 參數會大幅減小顯存需求,但會極大地使訓練速度減慢。因此,如果有足夠的顯存, 應當使用 ZeRO-1,并且確保 offload_param=none。
LLaMA-Factory 提供了使用不同階段的 DeepSpeed 配置文件的示例。包括:
- ZeRO-0 (不開啟)
- ZeRO-2
- ZeRO-2+offload
- ZeRO-3
- ZeRO-3+offload
備注: https://huggingface.co/docs/transformers/deepspeed 提供了更為詳細的介紹。
單機多卡
llamafactory-cli
使用 llamafactory-cli 啟動 DeepSpeed 引擎進行單機多卡訓練。
FORCE_TORCHRUN=1 llamafactory-cli train examples/train_full/llama3_full_sft_ds3.yaml
為了啟動 DeepSpeed 引擎,配置文件中 deepspeed 參數指定了 DeepSpeed 配置文件的路徑:
deepspeed: examples/deepspeed/ds_z3_config.json
deepspeed
使用 deepspeed 指令啟動 DeepSpeed 引擎進行單機多卡訓練。
deepspeed --include localhost:1 your_program.py <normal cl args> --deepspeed ds_config.json
下面是一個例子:
deepspeed --num_gpus 8 src/train.py \
--deepspeed examples/deepspeed/ds_z3_config.json \
--stage sft \
--model_name_or_path meta-llama/Meta-Llama-3-8B-Instruct \
--do_train \
--dataset alpaca_en \
--template llama3 \
--finetuning_type full \
--output_dir saves/llama3-8b/lora/full \
--overwrite_cache \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 500 \
--learning_rate 1e-4 \
--num_train_epochs 2.0 \
--plot_loss \
--bf16
備注:
使用 deepspeed 指令啟動 DeepSpeed 引擎時無法使用 CUDA_VISIBLE_DEVICES 指定GPU。而需要:
deepspeed --include localhost:1 your_program.py <normal cl args> --deepspeed ds_config.json
--include localhost:1 表示只是用本節點的gpu1。
多機多卡
LLaMA-Factory 支持使用 DeepSpeed 的多機多卡訓練,通過以下命令啟動:
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=0 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
FORCE_TORCHRUN=1 NNODES=2 NODE_RANK=1 MASTER_ADDR=192.168.0.1 MASTER_PORT=29500 llamafactory-cli train examples/train_lora/llama3_lora_sft_ds3.yaml
deepspeed
使用 deepspeed 指令來啟動多機多卡訓練。
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
your_program.py <normal cl args> --deepspeed ds_config.json
備注
關于hostfile:
hostfile的每一行指定一個節點,每行的格式為<hostname> slots=<num_slots>, 其中 <hostname> 是節點的主機名, <num_slots> 是該節點上的GPU數量。下面是一個例子: … code-block:
worker-1 slots=4
worker-2 slots=4
在 https://www.deepspeed.ai/getting-started/ 了解更多。
如果沒有指定 hostfile 變量, DeepSpeed 會搜索 /job/hostfile 文件。如果仍未找到,那么 DeepSpeed 會使用本機上所有可用的GPU。
accelerate
使用 accelerate 指令啟動 DeepSpeed 引擎。 首先通過以下命令生成 DeepSpeed 配置文件:
accelerate config
下面提供一個配置文件示例:
# deepspeed_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:deepspeed_multinode_launcher: standardgradient_accumulation_steps: 8offload_optimizer_device: noneoffload_param_device: nonezero3_init_flag: falsezero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
enable_cpu_affinity: false
machine_rank: 0
main_process_ip: '192.168.0.1'
main_process_port: 29500
main_training_function: main
mixed_precision: fp16
num_machines: 2
num_processes: 16
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
隨后,您可以使用以下命令啟動訓練:
accelerate launch \
--config_file deepspeed_config.yaml \
train.py llm_config.yaml
DeepSpeed 配置文件
ZeRO-0
### ds_z0_config.json
{"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","gradient_accumulation_steps": "auto","gradient_clipping": "auto","zero_allow_untested_optimizer": true,"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"bf16": {"enabled": "auto"},"zero_optimization": {"stage": 0,"allgather_partitions": true,"allgather_bucket_size": 5e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 5e8,"contiguous_gradients": true,"round_robin_gradients": true}
}
ZeRO-2
只需在 ZeRO-0 的基礎上修改 zero_optimization 中的 stage 參數即可。
### ds_z2_config.json
{..."zero_optimization": {"stage": 2,...}
}
ZeRO-2+offload
只需在 ZeRO-0 的基礎上在 zero_optimization 中添加 offload_optimizer 參數即可。
### ds_z2_offload_config.json
{..."zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu","pin_memory": true},...}
}
ZeRO-3
只需在 ZeRO-0 的基礎上修改 zero_optimization 中的參數。
### ds_z3_config.json
{..."zero_optimization": {"stage": 3,"overlap_comm": true,"contiguous_gradients": true,"sub_group_size": 1e9,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","stage3_max_live_parameters": 1e9,"stage3_max_reuse_distance": 1e9,"stage3_gather_16bit_weights_on_model_save": true}
}
ZeRO-3+offload
只需在 ZeRO-3 的基礎上添加 zero_optimization 中的 offload_optimizer 和 offload_param 參數即可。
### ds_z3_offload_config.json
{..."zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},...}
}
備注
https://www.deepspeed.ai/docs/config-json/ 提供了關于deepspeed配置文件的更詳細的介紹。
FSDP
PyTorch 的全切片數據并行技術 FSDP (Fully Sharded Data Parallel)能處理更多更大的模型。LLaMA-Factory支持使用 FSDP 引擎進行分布式訓練。
FSDP 的參數 ShardingStrategy 的不同取值決定了模型的劃分方式:
FULL_SHARD: 將模型參數、梯度和優化器狀態都切分到不同的GPU上,類似ZeRO-3。SHARD_GRAD_OP: 將梯度、優化器狀態切分到不同的GPU上,每個GPU仍各自保留一份完整的模型參數。類似ZeRO-2。NO_SHARD: 不切分任何參數。類似ZeRO-0。
llamafactory-cli
只需根據需要修改 examples/accelerate/fsdp_config.yaml 以及 examples/extras/fsdp_qlora/llama3_lora_sft.yaml ,文件然后運行以下命令即可啟動 FSDP+QLoRA 微調:
bash examples/extras/fsdp_qlora/train.sh
accelerate
此外,也可以使用 accelerate啟動 FSDP引擎, 節點數與 GPU數可以通過 num_machines 和 num_processes 指定。對此,Huggingface 提供了便捷的配置功能。 只需運行:
accelerate config
根據提示回答一系列問題后,我們就可以生成 FSDP 所需的配置文件。
當然也可以根據需求自行配置 fsdp_config.yaml 。
### /examples/accelerate/fsdp_config.yaml
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAPfsdp_backward_prefetch: BACKWARD_PREfsdp_forward_prefetch: falsefsdp_cpu_ram_efficient_loading: truefsdp_offload_params: true # offload may affect training speedfsdp_sharding_strategy: FULL_SHARDfsdp_state_dict_type: FULL_STATE_DICTfsdp_sync_module_states: truefsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: fp16 # or bf16
num_machines: 1 # the number of nodes
num_processes: 2 # the number of GPUs in all nodes
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
備注
請確保 num_processes 和實際使用的總GPU數量一致
隨后,可以使用以下命令啟動訓練:
accelerate launch \
--config_file fsdp_config.yaml \
src/train.py llm_config.yaml
警告
不要在 FSDP+QLoRA 中使用 GPTQ/AWQ 模型
量化
PTQ
后訓練量化(PTQ, Post-Training Quantization)一般是指在模型預訓練完成后,基于校準數據集 (calibration dataset)確定量化參數進而對模型進行量化。
GPTQ
GPTQ(Group-wise Precision Tuning Quantization)是一種靜態的后訓練量化技術。”靜態”指的是預訓練模型一旦確定,經過量化后量化參數不再更改。GPTQ 量化技術將 fp16 精度的模型量化為 4-bit ,在節省了約 75% 的顯存的同時大幅提高了推理速度。 為了使用GPTQ量化模型,您需要指定量化模型名稱或路徑,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-GPTQ
QAT
在訓練感知量化(QAT, Quantization-Aware Training)中,模型一般在預訓練過程中被量化,然后又在訓練數據上再次微調,得到最后的量化模型。
AWQ
AWQ(Activation-Aware Layer Quantization)是一種靜態的后訓練量化技術。其思想基于:有很小一部分的權重十分重要,為了保持性能這些權重不會被量化。 AWQ 的優勢在于其需要的校準數據集更小,且在指令微調和多模態模型上表現良好。 為了使用 AWQ 量化模型,您需要指定量化模型名稱或路徑,例如 model_name_or_path: TechxGenus/Meta-Llama-3-8B-Instruct-AWQ
AQLM
AQLM(Additive Quantization of Language Models)作為一種只對模型權重進行量化的PTQ方法,在 2-bit 量化下達到了當時的最佳表現,并且在 3-bit 和 4-bit 量化下也展示了性能的提升。 盡管 AQLM 在模型推理速度方面的提升并不是最顯著的,但其在 2-bit 量化下的優異表現意味著您可以以極低的顯存占用來部署大模型。
OFTQ
OFTQ(On-the-fly Quantization)指的是模型無需校準數據集,直接在推理階段進行量化。OFTQ是一種動態的后訓練量化技術。 在使用OFTQ量化方法時,需要指定預訓練模型、指定量化方法 quantization_method 和指定量化位數 quantization_bit 下面提供了一個使用bitsandbytes量化方法的配置示例:
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
quantization_bit: 4
quantization_method: bitsandbytes # choices: [bitsandbytes (4/8), hqq (2/3/4/5/6/8), eetq (8)]
bitsandbytes
區別于 GPTQ, bitsandbytes 是一種動態的后訓練量化技術。bitsandbytes 使得大于 1B 的語言模型也能在 8-bit 量化后不過多地損失性能。 經過bitsandbytes 8-bit 量化的模型能夠在保持性能的情況下節省約50%的顯存。
HQQ
依賴校準數據集的方法往往準確度較高,不依賴校準數據集的方法往往速度較快。HQQ(Half-Quadratic Quantization)希望能在準確度和速度之間取得較好的平衡。作為一種動態的后訓練量化方法,HQQ無需校準階段, 但能夠取得與需要校準數據集的方法相當的準確度,并且有著極快的推理速度。
EETQ
EETQ(Easy and Efficient Quantization for Transformers)是一種只對模型權重進行量化的PTQ方法。具有較快的速度和簡單易用的特性。
配置修改
// TODO
)



智能體在測試時的計算量)

)







--Linux安裝RabbitMQ)




