最近在做用k-mer評估基因組規模的任務,其中一個局部程序,想偷懶,直接在jupyter中跑了下結果,想看看這一小步處理如何,結果沒想到內核崩潰了!
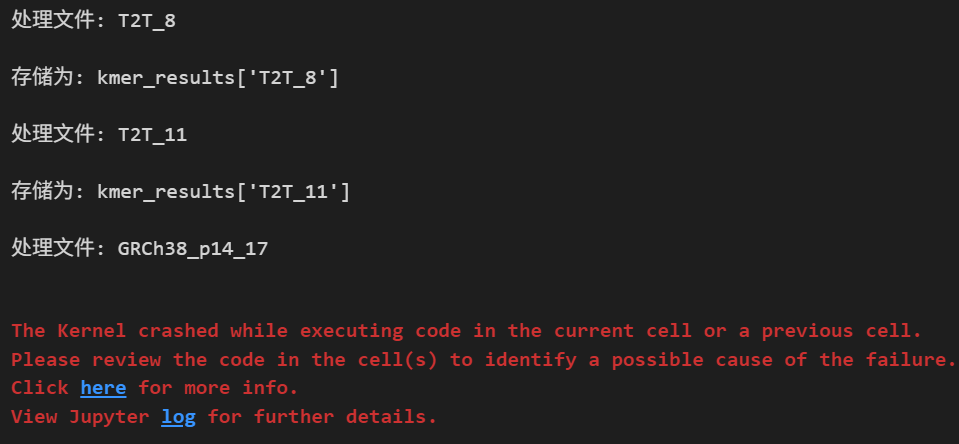
這一步我的草稿代碼如下:
import pandas as pd
import glob
from pathlib import Path
def kmer_dict(jf_txt_file,top_m):"""Args:jf_txt_file (str): 主要是dump命令的輸出文件路徑top_m(int):從k-mer文件中要提取的top幾個k-merFun:從輸入文件中返回該k-mer文件中top M的k-mer的字典,key為k-mer,value為該k-mer的計數,按照count的降序整理,返回該dict,同時輸出為tsv格式的文件后續如果要使用輸出文件,可以繼續使用pandas等進行處理;如果要使用返回的字典變量,可以直接使用該函數的返回值 """kmer = pd.read_csv(jf_txt_file,sep=" ",header=None,names=["mer","count"])# 按照降序排列,順便只看前top_m行kmer = kmer.sort_values(by="count",ascending=False).head(top_m)# 輸出為tsv格式文件kmer.to_csv(jf_txt_file.replace(".txt",f"_{top_m}.tsv"),sep="\t",header=True)# 同時返回每一個k-mer的字典kmer_dict = dict(zip(kmer["mer"],kmer["count"]))return kmer_dict# 對于兩個基因組的所有k-mer文件,使用前面定義的kmer_dict函數來提取top M的k-mer字典
Q1_dir = "/data1/project/omics_final/Q1"
kmer_files = glob.glob(f"{Q1_dir}/*.txt")kmer_results = {}
for each_kmer in kmer_files:each_kmer_name = Path(each_kmer).stem # 獲取文件名,不包含路徑和擴展名print(f"處理文件: {each_kmer_name}\n")# 此處對于每一個k-mer文件,提取其前10個對應的k-mer,并將結果輸出為對應的變量kmer_results[each_kmer_name] = kmer_dict(each_kmer,top_m=10)print(f"存儲為: kmer_results['{each_kmer_name}']\n")做的事情呢,其實很簡單,就是用jellyfish count,在自己的測試基因組組裝數據集上統計了一下k-mer,
然后用jellyfish dump命令,將統計結果,用python稍微處理一下整理成字典形式,存到一個字典中;
我測試的數據只有2個新組裝的人類基因組,各自大小也就在3G左右,k-mer文件將近30個,每個大小不一,k小的文件才幾M,k大的文件組合花樣多,一般都幾十G,
任務是在jupyter中跑的,結果爆了,推測是處理大量k-mer數據導致的內存或計算資源耗盡。
問題來了:
我放在后臺跑,比如python xxx.py,肯定能夠成功執行,比放在cell中穩妥多了;
但是我的變量已經return出來了,我肯定還是想之后能夠直接在python環境中訪問的,雖然我用pandas再將結果文件讀進去都一樣的內容,但是太麻煩了,我太懶了。
有沒有什么一般的策略,不僅僅局限于這個問題,就是可能會導致內核崩潰的稍微大型計算任務,
我又想像放在后臺穩定運行一樣能夠跑完這個任務,又希望就放在cell中跑,跑完之后直接訪問結果變量?
法1:使用批處理 + 保存中間結果
其實就是很簡單,分批嘛,batch,我一次處理30多個數據多麻煩,每次只處理一小部分,比如說5個,如果還是太大了,就3個文件一處理;
重要的是我要及時將結果文件保存,所以還是輸出到硬盤上了(其實理論上來講,那我還是可以全部都放在后臺運行,然后在代碼上添加每一步都保存的命令,這樣我還是可以保證結果變量能夠訪問);
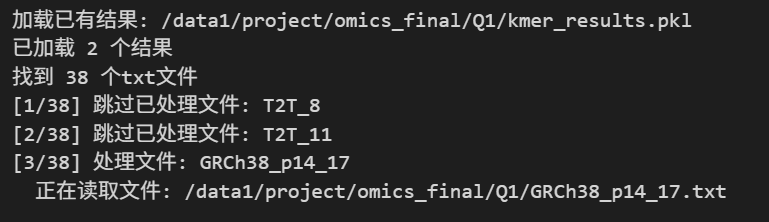
總之一小批一小批的運行并pickle輸出到硬盤中保存,然后下一次運行判斷哪些已經跑過了(這里比較重要,如果內核又崩潰了,我們就需要再次重啟內核在cell中跑,但是已經跑過的結果就不用再跑了)。
當然,有人會擔心如果我每次跑的時候,保存保存了一部分然后內核就崩潰了,那么文件系統檢查的時候如果重新加載了這個變量,然后它一看如果發現我加載的字典中已經有這個結果了,哪怕是一部分,會不會直接跳過,然后導致我其實這個應該被關注留意的結果其實并沒有得到重視?
比如說下面的這里?

其實這個問題我也考慮到了,所以我要確保每次保存結果的時候,都要完整保存或者說保存命令執行成功了,我才打印進程提醒:
比如說下面這里的進程——》
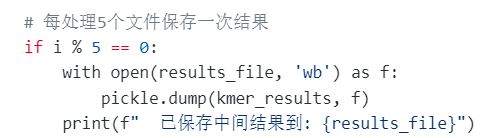
代碼整體邏輯如下:
import pandas as pd
import glob
import pickle
import os
from pathlib import Path
import gcdef kmer_dict(jf_txt_file, top_m):"""k-mer處理函數,添加錯誤處理"""try:print(f" 正在讀取文件: {jf_txt_file}")kmer = pd.read_csv(jf_txt_file, sep=" ", header=None, names=["mer", "count"])print(f" 數據形狀: {kmer.shape}")kmer = kmer.sort_values(by="count", ascending=False).head(top_m)# 輸出TSV文件output_file = jf_txt_file.replace(".txt", f"_{top_m}.tsv")kmer.to_csv(output_file, sep="\t", header=True, index=False)# 返回字典kmer_dict = dict(zip(kmer["mer"], kmer["count"]))# 清理內存del kmergc.collect()return kmer_dictexcept Exception as e:print(f" 處理文件 {jf_txt_file} 時出錯: {e}")return Nonedef process_kmer_files_safely():"""安全處理k-mer文件,支持斷點續傳"""Q1_dir = "/data1/project/omics_final/Q1"kmer_files = glob.glob(f"{Q1_dir}/*.txt")# 結果保存文件results_file = f"{Q1_dir}/kmer_results.pkl"# 如果已有結果文件,先加載if os.path.exists(results_file):print(f"加載已有結果: {results_file}")with open(results_file, 'rb') as f:kmer_results = pickle.load(f)print(f"已加載 {len(kmer_results)} 個結果")else:kmer_results = {}print(f"找到 {len(kmer_files)} 個txt文件")# 處理每個文件for i, each_kmer in enumerate(kmer_files, 1):each_kmer_name = Path(each_kmer).stem# 跳過已處理的文件if each_kmer_name in kmer_results:print(f"[{i}/{len(kmer_files)}] 跳過已處理文件: {each_kmer_name}")continueprint(f"[{i}/{len(kmer_files)}] 處理文件: {each_kmer_name}")try:result = kmer_dict(each_kmer, top_m=10)if result is not None:kmer_results[each_kmer_name] = resultprint(f" 成功處理,獲得 {len(result)} 個k-mer")# 每處理5個文件保存一次結果if i % 5 == 0:with open(results_file, 'wb') as f:pickle.dump(kmer_results, f)print(f" 已保存中間結果到: {results_file}")else:print(f" 處理失敗,跳過")except Exception as e:print(f" 發生異常: {e}")continue# 強制垃圾回收gc.collect()# 保存最終結果with open(results_file, 'wb') as f:pickle.dump(kmer_results, f)print(f"\n最終結果已保存到: {results_file}")print(f"總共處理了 {len(kmer_results)} 個文件")return kmer_results# 運行處理
try:kmer_results = process_kmer_files_safely()
except Exception as e:print(f"處理過程中發生錯誤: {e}")# 嘗試加載已保存的結果results_file = "/data1/project/omics_final/Q1/kmer_results.pkl"if os.path.exists(results_file):with open(results_file, 'rb') as f:kmer_results = pickle.load(f)print(f"加載了已保存的結果: {len(kmer_results)} 個文件")
真實運行情況:
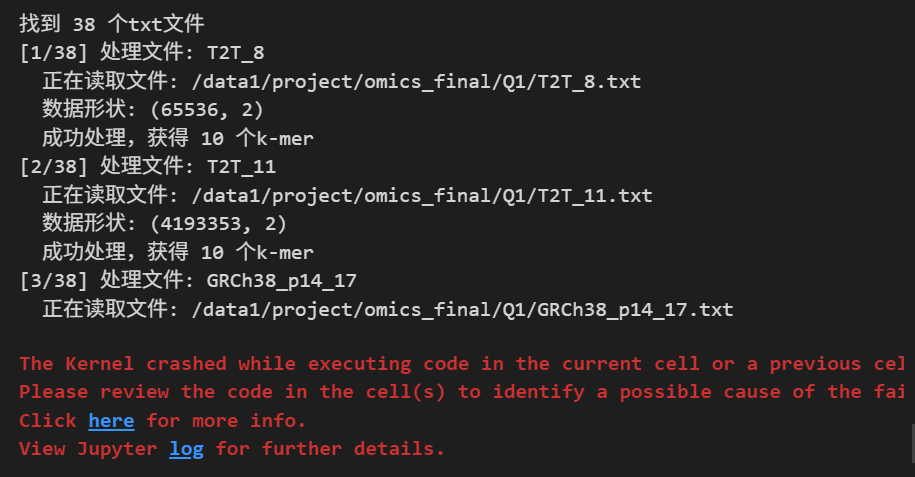
所以3個還是消耗太大了,對于我上面的執行邏輯,干脆就直接改為1,每運行1次就保存,當然我還是得蹲在前臺一直看著這個代碼的運行。
文件其實很多,我們先仔細看一下:
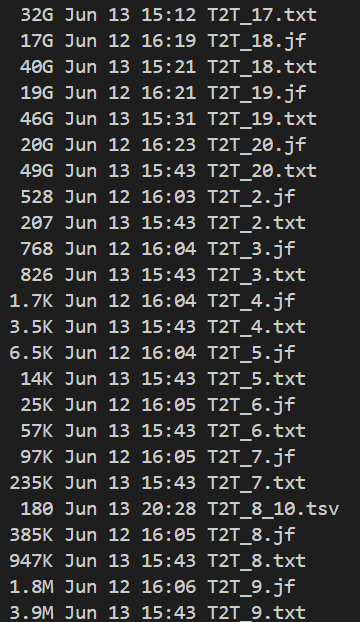
ls -lh | awk -F " " '{print $5}' | grep "G" | awk -F "G" '{print $1}' | sort | uniq
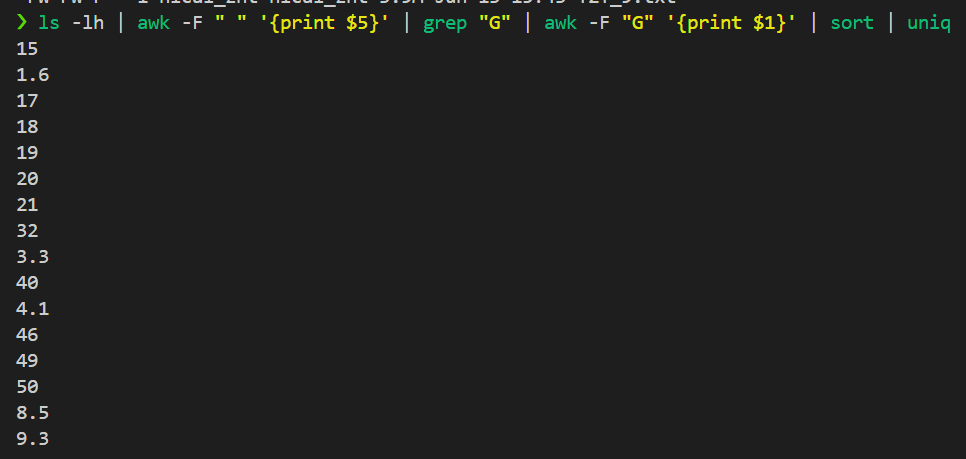
可以發現,其實最大的文件已經達到了50G了,比基因組規模3G大了十幾倍,
其實運行了好幾次了,都是17-mer這個文件就一直卡著,其實我們也可以另外直接在shell中awk處理好輸出top M的文件,也沒必要什么都在python中處理,不然吃不消。
法2:使用Jupyter的后臺執行
# 在新的cell中運行
import threading
import timedef background_process():"""后臺處理函數"""global kmer_results # 使用全局變量try:kmer_results = process_kmer_files_safely()print("后臺處理完成!")except Exception as e:print(f"后臺處理出錯: {e}")# 啟動后臺線程
processing_thread = threading.Thread(target=background_process)
processing_thread.daemon = True # 設置為守護線程
processing_thread.start()print("后臺處理已啟動,您可以繼續使用其他cell")
print("使用 processing_thread.is_alive() 檢查處理狀態")
其實就是多線程庫threading的使用,主要函數繼承前面的,主要改了點運行
法3:分批處理 + 內存優化
其實batch的想法還是和1一樣的,只不過是多了個內存的監控強制優化
import pandas as pd
import glob
import pickle
from pathlib import Path
import gc
import psutil
import osdef get_memory_usage():"""獲取當前內存使用情況"""process = psutil.Process(os.getpid())return process.memory_info().rss / 1024 / 1024 # MBdef process_kmer_batch(file_batch, batch_num):"""處理一批文件"""print(f"\n=== 處理批次 {batch_num} ===")print(f"內存使用: {get_memory_usage():.1f} MB")batch_results = {}for i, file_path in enumerate(file_batch, 1):filename = Path(file_path).stemprint(f" [{i}/{len(file_batch)}] 處理: {filename}")try:# 檢查內存使用memory_usage = get_memory_usage()if memory_usage > 4000: # 超過4GB則強制清理print(f" 內存使用過高 ({memory_usage:.1f} MB),執行垃圾回收")gc.collect()result = kmer_dict(file_path, top_m=10)if result is not None:batch_results[filename] = resultprint(f" 成功,獲得 {len(result)} 個k-mer")except Exception as e:print(f" 失敗: {e}")continuereturn batch_resultsdef process_all_files_in_batches(batch_size=5):"""分批處理所有文件"""Q1_dir = "/data1/project/omics_final/Q1"kmer_files = glob.glob(f"{Q1_dir}/*.txt")print(f"總共找到 {len(kmer_files)} 個文件")print(f"將分 {len(kmer_files)//batch_size + 1} 批處理,每批 {batch_size} 個文件")all_results = {}# 分批處理for i in range(0, len(kmer_files), batch_size):batch = kmer_files[i:i+batch_size]batch_num = i//batch_size + 1batch_results = process_kmer_batch(batch, batch_num)all_results.update(batch_results)# 每批處理完后保存結果results_file = f"{Q1_dir}/kmer_results_batch_{batch_num}.pkl"with open(results_file, 'wb') as f:pickle.dump(batch_results, f)print(f" 批次結果已保存: {results_file}")# 強制垃圾回收gc.collect()print(f" 當前總結果數: {len(all_results)}")# 保存最終合并結果final_results_file = f"{Q1_dir}/kmer_results_final.pkl"with open(final_results_file, 'wb') as f:pickle.dump(all_results, f)print(f"\n處理完成!最終結果已保存: {final_results_file}")return all_results# 執行分批處理
kmer_results = process_all_files_in_batches(batch_size=3)
法4:訪問已保存的結果
這個其實就是最原始的想法,全都放在后臺,只保留全部運行之后的結果變量,執行過程當然是用到什么變量就得保存什么變量,還是保存為pkl格式。
當然,實際運行的時候,其實發現真的很耗費計算資源的任務,你放在cell中內核會崩潰,其實放在后臺則是會被kill,其實都是同樣有極大可能性失敗的;
# 在任何時候都可以加載已保存的結果
import pickle
import osdef load_saved_results():"""加載已保存的結果"""Q1_dir = "/data1/project/omics_final/Q1"# 嘗試加載最終結果final_file = f"{Q1_dir}/kmer_results_final.pkl"if os.path.exists(final_file):with open(final_file, 'rb') as f:results = pickle.load(f)print(f"加載最終結果: {len(results)} 個文件")return results# 如果沒有最終結果,嘗試加載中間結果intermediate_file = f"{Q1_dir}/kmer_results.pkl"if os.path.exists(intermediate_file):with open(intermediate_file, 'rb') as f:results = pickle.load(f)print(f"加載中間結果: {len(results)} 個文件")return resultsprint("沒有找到已保存的結果")return {}# 加載結果
kmer_results = load_saved_results()# 查看結果概況
if kmer_results:print(f"加載了 {len(kmer_results)} 個文件的結果")print("文件列表:")for name in sorted(kmer_results.keys()):print(f" {name}: {len(kmer_results[name])} 個k-mer")
所以,如果僅僅只是簡單的文本文件處理,只要不涉及到非常復雜的數據處理,pandas能夠簡單應付的任務,還是直接用awk算了(也就是shell中批量處理得了)





 原理與實踐指南)









 ---- Stack 類)


:深入理解字符與函數的使用)
