在企業運營過程中,時常會面臨處理海量 PDF 文件的挑戰。從 PDF 指定區域提取內容并用于重命名文件,能極大地優化企業內部的文件管理流程,提升工作效率。以下為您詳細介紹其在企業中的應用場景、具體使用步驟及注意事項。?
詳細使用步驟?
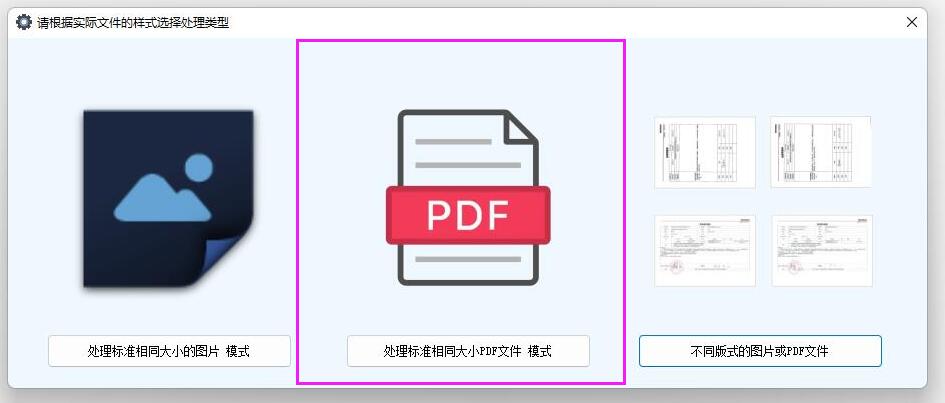
選擇處理模式:啟動軟件后,若處理的是普通文本型 PDF 文件,選擇 “PDF 識別模式”;若是圖片型 PDF 文件(如掃描件),必須選擇此模式,以保障軟件能正確識別文件中的文字內容。?
框選識別區域:將一份具有代表性的樣本 PDF 文件拖入軟件操作界面,利用軟件提供的區域選擇工具,在 PDF 頁面上精準框選出需要識別文字的區域。
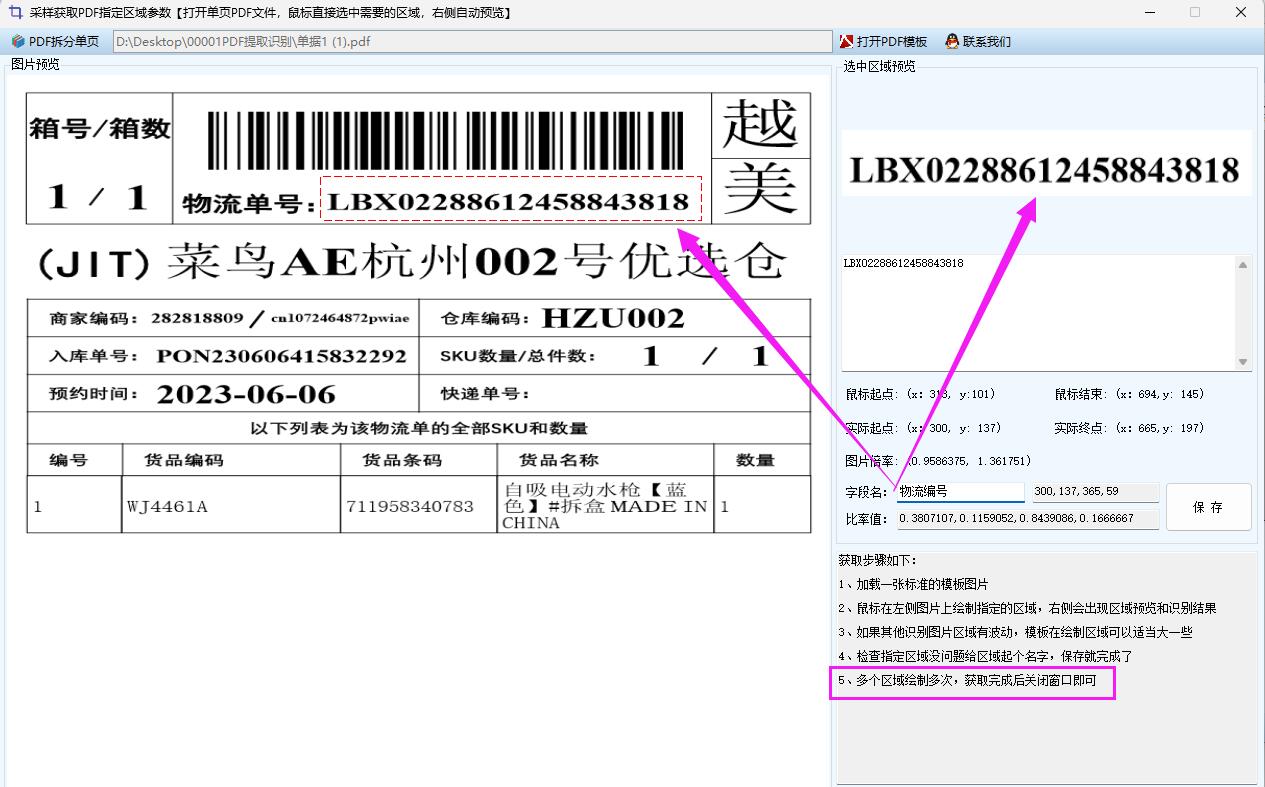
框選時應注意確保完全覆蓋目標文字,同時避免選取過多無關區域,以免降低識別效率和準確性。若需識別多個區域,可多次進行框選操作。完成框選后,為每個框選區域賦予有意義的名稱,如 “合同編號”“發票金額”“項目階段” 等,這些名稱將作為后續導出表格的列名,方便對識別結果進行整理和分析。?保存區域坐標:完成所有識別區域的框選和命名后,保存每個繪制區域的坐標信息。若存在多個識別區域,需分別保存各區域的坐標,以便后續對其他 PDF 文件進行相同區域的識別操作。?
導入待處理文件:點擊軟件界面中的 “導入 PDF” 按鈕,在彈出的文件選擇對話框中,選中包含待處理 PDF 文件的文件夾,將所有相關文件導入軟件。?
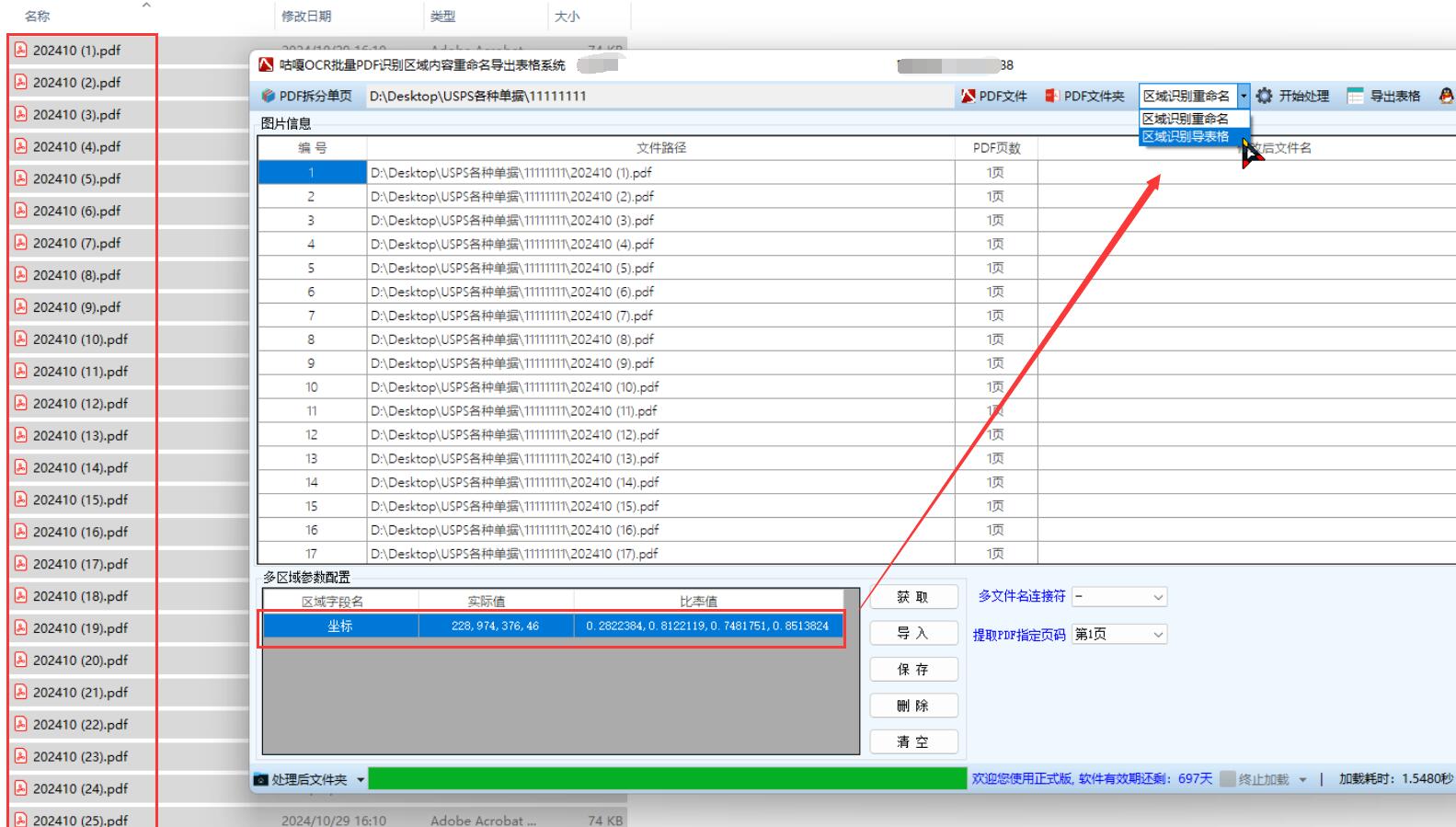
加載區域坐標:文件導入完成后,加載之前保存的區域坐標,確保軟件在后續處理過程中,能按照預設的指定區域對每個 PDF 文件進行識別。?
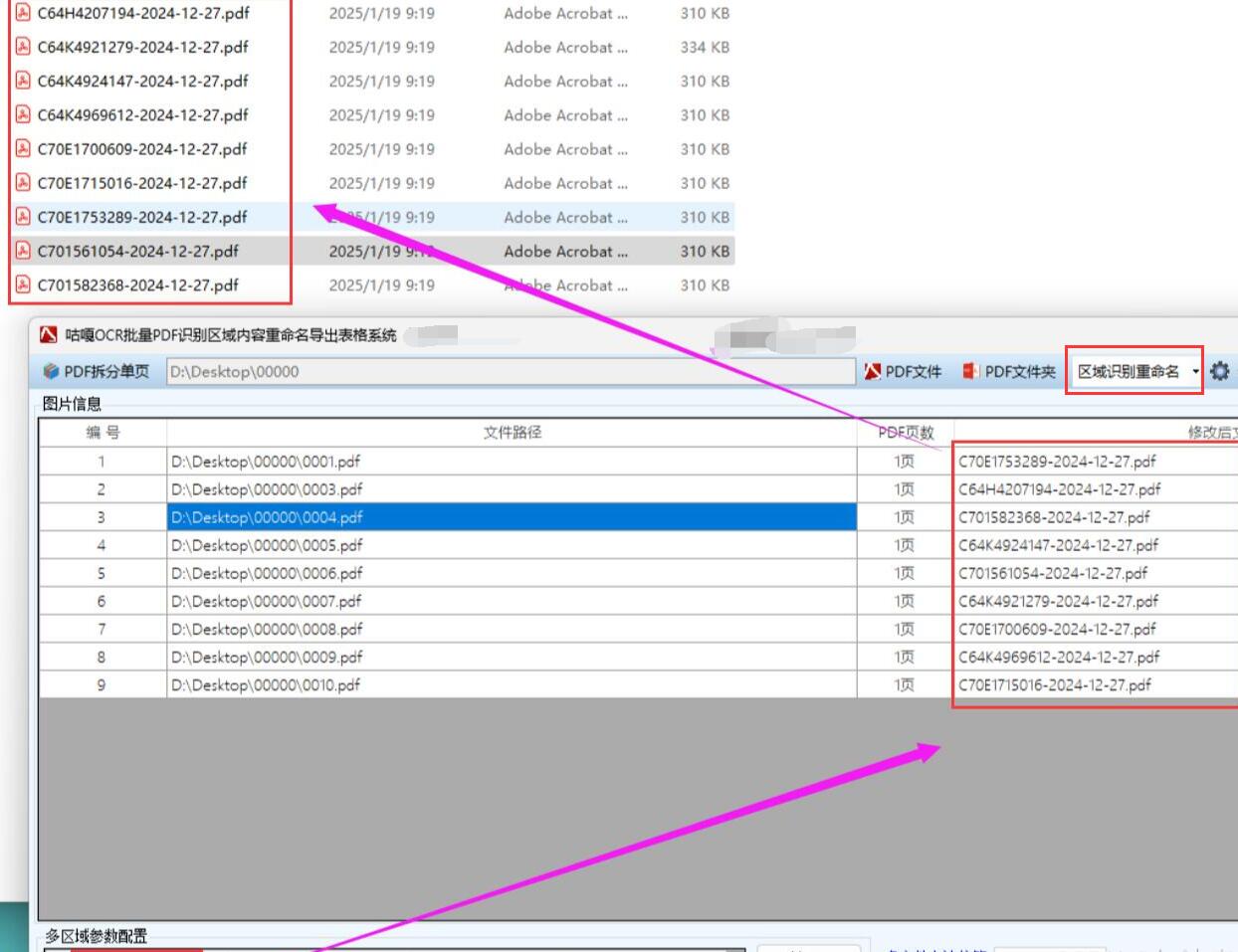
開始批量處理:確認所有設置無誤后,點擊 “開始處理” 按鈕,軟件將自動遍歷導入的所有 PDF 文件,提取指定區域的文字內容,并按照設定的重命名規則對文件進行重命名。若同時選擇了導出表格功能,軟件還會將識別結果整理成表格形式。?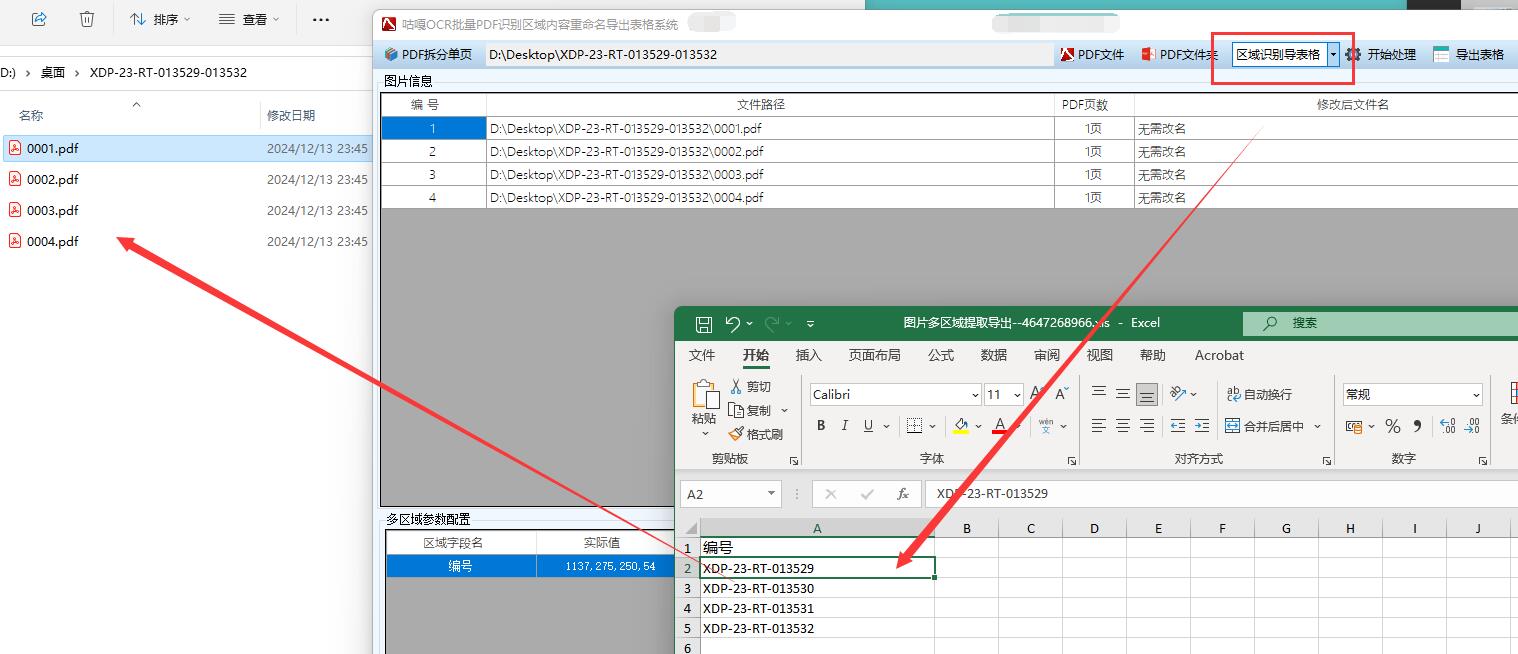
校驗結果:批量處理完成后,仔細檢查文件名是否準確反映了文件中指定區域的文字內容,確保所有文件都已成功重命名,無遺漏或重命名錯誤的情況。若選擇了 “區域識別導表格” 功能,還需檢查導出表格中的內容是否完整、準確,數據與 PDF 文件中的識別結果是否一致。如有錯誤或不符合預期的地方,及時返回相應步驟進行修正,如重新調整識別區域、修改重命名規則等,然后再次執行識別和重命名操作,直至結果符合要求。
還有操作不會或不懂的地方歡迎私信交流 !
)










)



實現外網連接使用)



重構java郵件發獎系統實戰)