時間復雜度的重要性
雖然scikit-learn等庫讓機器學習算法的實現變得異常簡單(通常只需2-3行代碼),但這種便利性往往導致使用者忽視兩個關鍵方面:
-
算法核心原理的理解缺失
-
忽視算法的數據適用條件
典型算法的時間復雜度陷阱
-
SVM:訓練時間呈
增長,樣本量過萬時計算代價急劇上升
-
t-SNE:
的時間復雜度使其難以處理大規模數據集
時間復雜度帶來的深層理解
分析運行時行為能幫助我們:
-
掌握算法端到端的工作機制
-
預判算法在不同數據規模下的表現
-
做出更合理的實現選擇(如kNN中優先隊列比排序更高效)
關鍵算法的時間復雜度分析
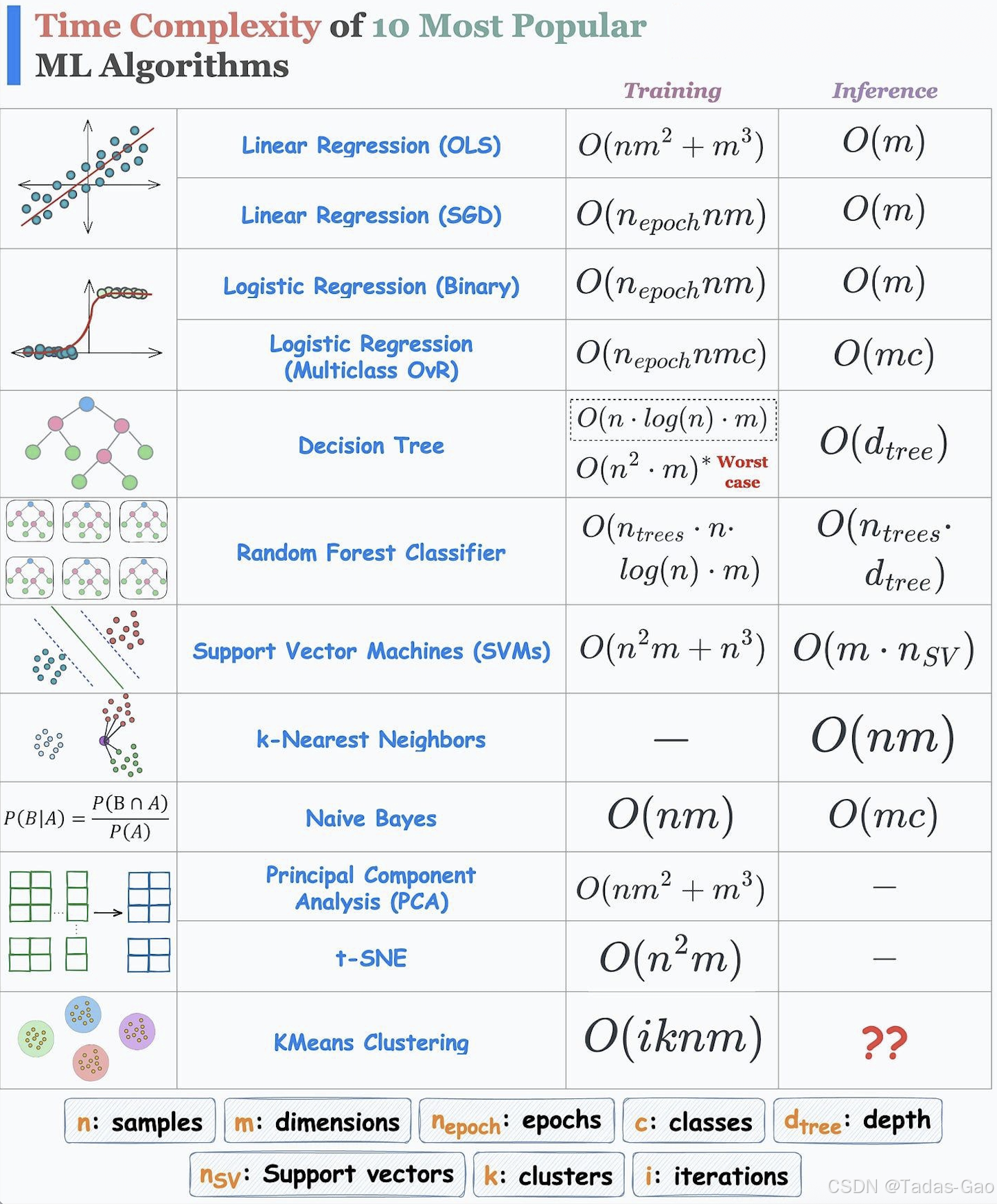
線性模型
1. Linear Regression (OLS)
訓練時間復雜度:
-
:來自計算
矩陣(
矩陣乘法)
-
:來自對
矩陣求逆運算
推理時間復雜度:
- 只需計算
(權重向量與特征向量的點積)
2. Linear Regression (SGD)
訓練時間復雜度:
-
每epoch處理
個樣本,每個樣本計算
維梯度
-
相比OLS省去了矩陣運算,適合大規模數據
-
收斂速度:通常需要更多epoch達到相同精度
-
每次迭代只需計算單個樣本的梯度
推理時間復雜度:
- 適合大規模數據,但需要調參(學習率、迭代次數)
邏輯回歸
3. Logistic Regression (Binary)
訓練時間復雜度:
-
與線性回歸SGD類似,但:
-
需要計算sigmoid函數
-
通常需要更多迭代收斂
-
推理時間復雜度:
4. Logistic Regression (Multiclass OvR)
訓練時間復雜度:
-
為類別數,需要訓練
推理時間復雜度:
- 類別數增加會線性增加計算成本
樹模型
5. Decision Tree
訓練時間復雜度:
-
分割選擇:對
計算
-
樹深度:平衡樹約
層
-
對于平衡樹,每層需要
時間,共
層
推理時間復雜度:
-
對特征縮放不敏感,適合類別特征
-
只需從根節點遍歷到葉節點
6. Random Forest Classifier
訓練時間復雜度:
-
棵樹的獨立訓練(可并行)
-
特征采樣:實際
推理時間復雜度:
-
可通過并行化加速訓練,但內存消耗大
-
需要所有樹的投票
其他關鍵算法
7. Support Vector Machines
訓練時間復雜度:
-
取決于核函數和優化算法
推理時間復雜度:(sv為支持向量數)
-
大數據集性能差,適合小規模高維數據
-
只依賴支持向量
8. K-Nearest Neighbors
訓練時間復雜度:
-
僅存儲訓練數據
推理時間復雜度:
-
推理慢但訓練快,適合低維數據
9. Naive Bayes
訓練時間復雜度:
-
只需計算特征統計量
推理時間復雜度:
-
線性復雜度,適合文本分類等高維數據
-
對
10. Principal Component Analysis
訓練時間復雜度:
-
來自協方差矩陣特征分解
-
大數據優化:可用隨機SVD
-
特征數很大時計算成本高
11. t-SNE
訓練時間復雜度:
-
成對相似度計算占主導
-
內存瓶頸:需要存儲
矩陣
-
難以擴展到大規模數據
推理時間復雜度:不適用(通常只用于可視化)
12. KMeans Clustering
訓練時間復雜度:
-
每次迭代計算所有點到
中心的距離
-
Lloyd算法:線性收斂但可能陷入局部最優
推理時間復雜度:
實踐建議
-
大數據集:優先考慮線性時間復雜度算法
-
高維數據:注意維度對距離計算的影響
-
模型選擇:不僅要考慮準確率,還要評估計算成本
理解這些時間復雜度特性,能幫助你在實際項目中做出更明智的算法選擇,避免在大型數據集上遭遇性能瓶頸。
擴展閱讀
- 線性模型選擇中容易被忽視的關鍵洞察-CSDN博客
- 不會選損失函數?16種機器學習算法如何“扣分”?-CSDN博客
- 10 個最常用的損失函數-CSDN博客
)
)




)







 — 一級架構主從架構)

)


