哈嘍,我是 我不是小upper~
昨天,咱們分享了關于 L1 正則化和 L2 正則化核心區別的精彩內容。今天我來進一步補充和拓展。
首先,咱們先來聊聊 L1 和 L2 正則化,方便剛接觸的同學理解。
L1 正則化(Lasso):它會給模型的損失函數加上一個懲罰項,這個懲罰項是所有模型系數的絕對值之和。這會讓模型在訓練時傾向于把一些不那么重要的特征系數直接壓縮到零,相當于自動進行了特征選擇,模型會變得更簡單,也能一定程度上避免過擬合。
L2 正則化(Ridge):它在損失函數中加上的是模型系數的平方和作為懲罰項。這會使模型的系數都朝著零的方向收縮,但一般不會恰好變成零,而是都保持較小的絕對值,能讓模型對特征更“公平”地利用,對處理多重共線性問題比較有效。
接下來我們再深入看看:
Elastic Net:它把 L1 和 L2 正則化結合起來,既像 L1 那樣能做特征選擇,又像 L2 那樣能處理多重共線性,特別適合那種特征很多又相互關聯的高維數據場景。
過擬合和模型泛化能力與正則項的關系:過擬合就是模型在訓練數據上表現很好,但在新數據上就“不行了”。正則項通過限制模型的復雜度,讓模型在訓練時不能“死記硬背”訓練數據,而是學到更通用的規律,從而提升在新數據上的表現,也就是增強泛化能力。
從優化角度理解 L1 導致非光滑問題:L1 正則化由于其絕對值項的存在,使得目標函數在某些點上會出現“角”,導致函數在這些點上不可導,也就是非光滑。這給優化算法帶來了一定的挑戰,但同時正是這種“非光滑性”讓 L1 能產生稀疏解。相比之下,L2 正則化的目標函數是光滑的,更容易用傳統的優化方法處理。
總之,L1 和 L2 正則化各有特點,適用于不同的場景,理解它們的本質對模型優化和特征選擇都有很大的幫助。
正則化的本質:從損失函數到結構化風險最小化
在機器學習中,模型訓練的目標是最小化經驗風險(訓練誤差),但這會導致過擬合。正則化通過引入結構化風險(模型復雜度懲罰),將優化目標從單純擬合數據轉向平衡擬合能力與泛化能力:
:損失函數(如線性回歸的 MSE)
:正則項,控制模型復雜度
:正則化系數,平衡損失與復雜度
1. L1 正則化(Lasso):稀疏驅動的特征選擇
1.1 數學定義與幾何解釋
正則項形式:?
優化目標:
幾何意義(以二維參數為例):
- 等高線:損失函數的等高線表示訓練誤差相等的參數組合。
- 正則項約束:L1 正則化的約束區域是菱形,其頂點位于坐標軸上。
- 最優解:當損失函數等高線與菱形頂點相切時,解的某個維度參數為 0(如?
),實現特征稀疏化。
L1 正則化通過菱形約束迫使參數落在坐標軸上,導致稀疏解
1.2?稀疏性的數學根源
L1 正則化在??處的次梯度為?
(當?
?時次梯度為?[-1, 1]),這種非光滑特性使得優化過程中參數容易被 “推” 至 0 點。
次梯度推導:
當?,
;
當 ,
;
當 ,次梯度?
。
1.3?適用場景
特征選擇:當特征數遠大于樣本數()時,L1 能自動剔除無關特征,輸出可解釋的稀疏模型。
稀疏信號重構:如壓縮感知中恢復稀疏信號。
2. L2 正則化(Ridge):參數平滑與共線性緩解1. 數學定義與幾何解釋正則項形式:
優化目標:
幾何意義(以二維參數為例):正則項約束:L2 正則化的約束區域是圓形,邊界光滑。最優解:損失函數等高線與圓形邊界相切時,參數??均不為 0,但被壓縮至較小值。
L2 正則化通過圓形約束平滑參數,避免過擬合
2. 共線性問題的解決方案
當特征高度相關(多重共線性)時,普通最小二乘法(OLS)的解不穩定且方差大。L2 正則化通過引入正定項 ,使協方差矩陣滿秩,解的表達式為:
方差 - 偏差權衡:L2 正則化通過增加偏差(Bias)來降低方差(Variance),提升模型穩定性。
2.1?適用場景
多重共線性數據:如金融數據中多個高度相關的經濟指標。需要保留所有特征的場景:如醫學影像分析中不希望遺漏潛在相關特征。四、Elastic Net:L1 與 L2 的優勢融合1. 數學定義與權重機制正則項形式:
其中??為混合參數:
:退化為 Lasso;
:退化為 Ridge。優化目標:
2.2. 解決高維共線性的原理
- 分組效應(Grouping Effect):當多個特征高度相關時,Elastic Net 傾向于將它們的系數同時置為非零或零,避免 Lasso 的 “隨機選特征” 問題。
- 優化穩定性:L2 分量緩解了 L1 的非光滑性,使優化過程更穩定,適用于?\(p \gg n\)?場景。
2.3?適用場景
- 生物信息學:基因表達數據中數千個特征(基因)高度相關,需同時實現特征選擇與穩定建模。
- 圖像識別:高維像素特征中存在局部相關性,Elastic Net 可保留相鄰像素的協同作用。
正則化對比表格
| 特性 | L1 正則化(Lasso) | L2 正則化(Ridge) | Elastic Net |
|---|---|---|---|
| 正則項形式 | | ||
| 解的稀疏性 | 稀疏(部分系數為 0) | 稠密(系數均非零) | 部分稀疏(取決于 α) |
| 特征選擇能力 | 強(自動剔除無關特征) | 無 | 中(依賴 α,保留共線特征組) |
| 共線性處理 | 不穩定(隨機選特征) | 穩定(壓縮系數) | 穩定(成組選擇特征) |
| 優化難度 | 高(非光滑,需特殊算法) | 低(光滑,支持 SGD) | 中(混合光滑與非光滑項) |
| 典型場景 | 文本分類(特征稀疏) | 金融風控(共線性強) | 基因表達分析(高維 + 共線) |
優化算法對比
| 算法 | 適用正則化 | 核心思想 |
|---|---|---|
| 坐標下降法 | L1/L2/Elastic | 逐坐標優化,每次固定其他坐標更新當前坐標,適合稀疏場景 |
| LARS(最小角回歸) | Lasso | 通過逐步引入與殘差最相關的特征,動態構建模型,計算效率高 |
| 近端梯度下降 | L1/L2/Elastic | 將非光滑項的優化拆分為梯度下降與近端映射,處理 L1 的非光滑性 |
| 隨機梯度下降(SGD) | L2 | 光滑目標的高效優化,適合大規模數據 |
正則化系數 λ 的選擇
- 交叉驗證(CV):
- K 折交叉驗證選擇 λ,如 5 折 CV 計算不同 λ 下的均方誤差(MSE),選擇最優值。
- AIC/BIC 準則:
- AIC =?
,
,其中 k 為非零參數個數,L 為似然函數值。
- AIC =?
- 路徑搜索:
- Lasso Path:繪制不同 λ 下各特征系數的變化路徑,輔助判斷稀疏度與模型性能的平衡。
總結:從理論到實踐的選擇邏輯
- 優先選 L2 的場景:
- 特征間高度相關,需穩定模型;
- 不希望丟失任何潛在特征(如探索性分析階段)。
- 優先選 L1 的場景:
- 特征數量遠大于樣本量,需降維;
- 模型可解釋性要求高(如醫學診斷模型)。
- 選擇 Elastic Net 的場景:
- 高維數據中存在特征組相關性(如時間序列的滯后特征);
- 希望同時實現稀疏性與穩定性(如生物標志物篩選)。
通過正則化的合理選擇,可有效控制模型復雜度,在過擬合與欠擬合之間找到最優平衡點,提升機器學習模型的泛化能力。
代碼說明
Lasso 正則路徑圖
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso, Ridge, ElasticNet
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import lars_pathnp.random.seed(42)# 數據集
n_samples, n_features = 100, 50
X = np.random.randn(n_samples, n_features)# 構造稀疏的真實系數 beta(只有前 5 個非零)
true_beta = np.zeros(n_features)
true_beta[:5] = [5, -4, 3, 0, 2]
y = X @ true_beta + np.random.randn(n_samples) * 0.5 # 加入噪聲# 標準化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 拆分訓練和測試集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 模型訓練
lasso = Lasso(alpha=0.1).fit(X_train, y_train)
ridge = Ridge(alpha=1.0).fit(X_train, y_train)
enet = ElasticNet(alpha=0.1, l1_ratio=0.5).fit(X_train, y_train)# 預測
lasso_pred = lasso.predict(X_test)
ridge_pred = ridge.predict(X_test)
enet_pred = enet.predict(X_test)# 均方誤差
lasso_mse = mean_squared_error(y_test, lasso_pred)
ridge_mse = mean_squared_error(y_test, ridge_pred)
enet_mse = mean_squared_error(y_test, enet_pred)# 正則路徑圖:LARS 方法(用于 Lasso 路徑圖)
alphas_lasso, _, coefs_lasso = lars_path(X_scaled, y, method='lasso', verbose=True)# 圖像 1: Lasso 正則路徑圖
plt.figure(figsize=(10, 6))
colors = plt.cm.tab20(np.linspace(0, 1, n_features))
for i in range(n_features):plt.plot(-np.log10(alphas_lasso), coefs_lasso[i], label=f'Feature {i+1}', color=colors[i])
plt.xlabel(r'$-\log_{10}(\alpha)$')
plt.ylabel('Coefficient value')
plt.title('Lasso 正則路徑圖(正則化程度 vs 系數變化)')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', ncol=2)
plt.tight_layout()
plt.grid(True)
plt.show()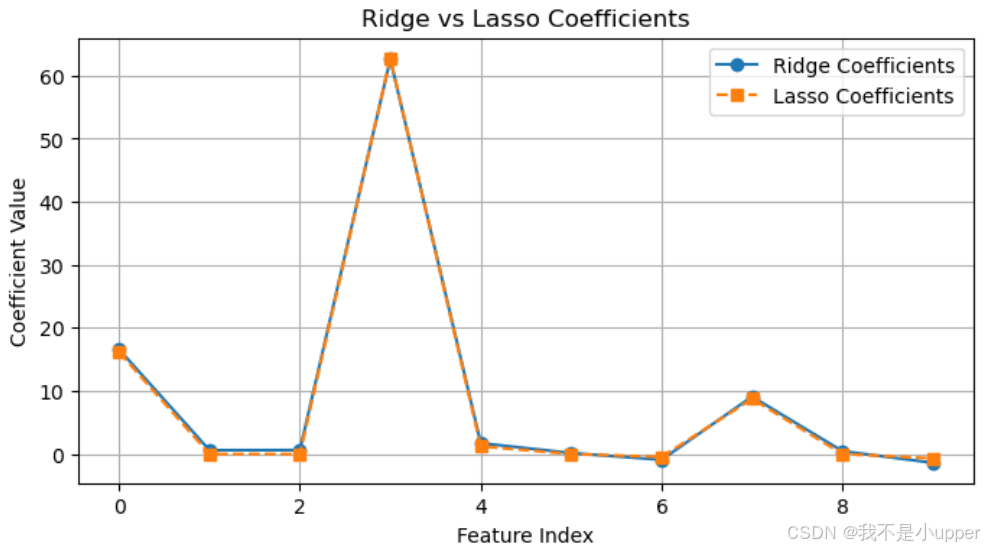
首先代碼里用?make_regression?生成了 100 個樣本、10 個特征的數據,其中只有 3 個是真正帶有用信號的(n_informative=3),還加了噪聲。然后分別用 Ridge(L2 正則)和 Lasso(L1 正則)去訓練模型,最后畫出它們的系數。
先看橫軸,是特征的索引(0 到 9,因為有 10 個特征),縱軸是模型學到的系數值。藍色的是 Ridge 的系數,橙色的是 Lasso 的。
對于 Ridge 模型(藍色線),它的系數整體上比較 “分散”,大部分特征的系數都不是 0 。因為 L2 正則化是給系數的平方和加懲罰,它會讓系數變小,但不會把它們直接壓到 0 。所以即使是那些原本在生成數據時 “沒用” 的特征(也就是?n_informative?之外的 7 個),Ridge 也會給它們分配一些小的系數,讓所有特征都參與到模型里,只是影響力不同。比如特征索引 0 、3 這些,系數相對大一些,可能對應生成數據時的 “有用” 特征,但其他索引的特征系數也沒被完全消除。
再看 Lasso 模型(橙色線),就很不一樣了。它的系數有很明顯的 “稀疏性”—— 很多特征的系數直接變成了 0 。像特征索引 1、2、5、6 這些,系數幾乎是 0 ,說明 Lasso 把這些它認為 “沒用” 的特征給 “篩選掉” 了。而在特征索引 3 那里,系數特別高,可能對應生成數據里最關鍵的有用特征。這是因為 L1 正則化是給系數的絕對值和加懲罰,它會強烈地把不重要特征的系數往 0 壓,直到變成 0 ,從而實現特征選擇的效果。
結合生成數據的設定(只有 3 個有用特征),Lasso 在這里確實識別出了大概 3 個左右非零的系數(比如索引 0、3、7 附近?得具體看數值),而 Ridge 則是讓所有特征都保留了系數,只是大小不同。這就能直觀看到 L1 和 L2 正則化在處理特征系數時的核心區別:Lasso 會產生稀疏解,做特征選擇;Ridge 更傾向于讓系數平滑收縮,保留所有特征但減小它們的影響,尤其在有共線性或者想避免過擬合時有用。這樣對比下來,就清楚為啥不同場景要選不同的正則化方法了,比如想簡化模型、篩選關鍵特征用 Lasso ,想穩定系數、讓所有特征都參與就用 Ridge 。
Lasso / Ridge / ElasticNet 系數對比條形圖(前 20 特征)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.datasets import make_regression
import pandas as pd# 生成合成數據
X, y, true_beta = make_regression(n_samples=100, # 100 samplesn_features=20, # 20 featuresn_informative=3, # Only 3 features are informativenoise=10, # Noise levelcoef=True, # Return true coefficientsrandom_state=42)# 訓練三種模型
ridge = Ridge(alpha=1.0).fit(X, y)
lasso = Lasso(alpha=0.5, max_iter=10000).fit(X, y)
enet = ElasticNet(alpha=0.5, l1_ratio=0.5, max_iter=10000).fit(X, y)# 創建系數對比數據框
coef_df = pd.DataFrame({'Feature': [f'Feature {i+1}' for i in range(X.shape[1])],'True Coef': true_beta,'Lasso Coef': lasso.coef_,'Ridge Coef': ridge.coef_,'ElasticNet Coef': enet.coef_
})# 繪制前20個特征的系數對比圖
top_n = min(20, X.shape[1]) # 確保不超過實際特征數量
colors = plt.cm.get_cmap('tab10', 4)fig, ax = plt.subplots(figsize=(14, 7))
index = np.arange(top_n)
bar_width = 0.2plt.bar(index, coef_df['True Coef'][:top_n], bar_width, color=colors(0), label='True Coef')
plt.bar(index + bar_width, coef_df['Lasso Coef'][:top_n], bar_width, color=colors(1), label='Lasso')
plt.bar(index + 2 * bar_width, coef_df['Ridge Coef'][:top_n], bar_width, color=colors(2), label='Ridge')
plt.bar(index + 3 * bar_width, coef_df['ElasticNet Coef'][:top_n], bar_width, color=colors(3), label='ElasticNet')plt.xlabel('Feature Index')
plt.ylabel('Coefficient Value')
plt.title('Comparison of Top 20 Feature Coefficients Across Models')
plt.xticks(index + bar_width * 1.5, [f'F{i+1}' for i in range(top_n)], rotation=45)
plt.legend()
plt.tight_layout()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()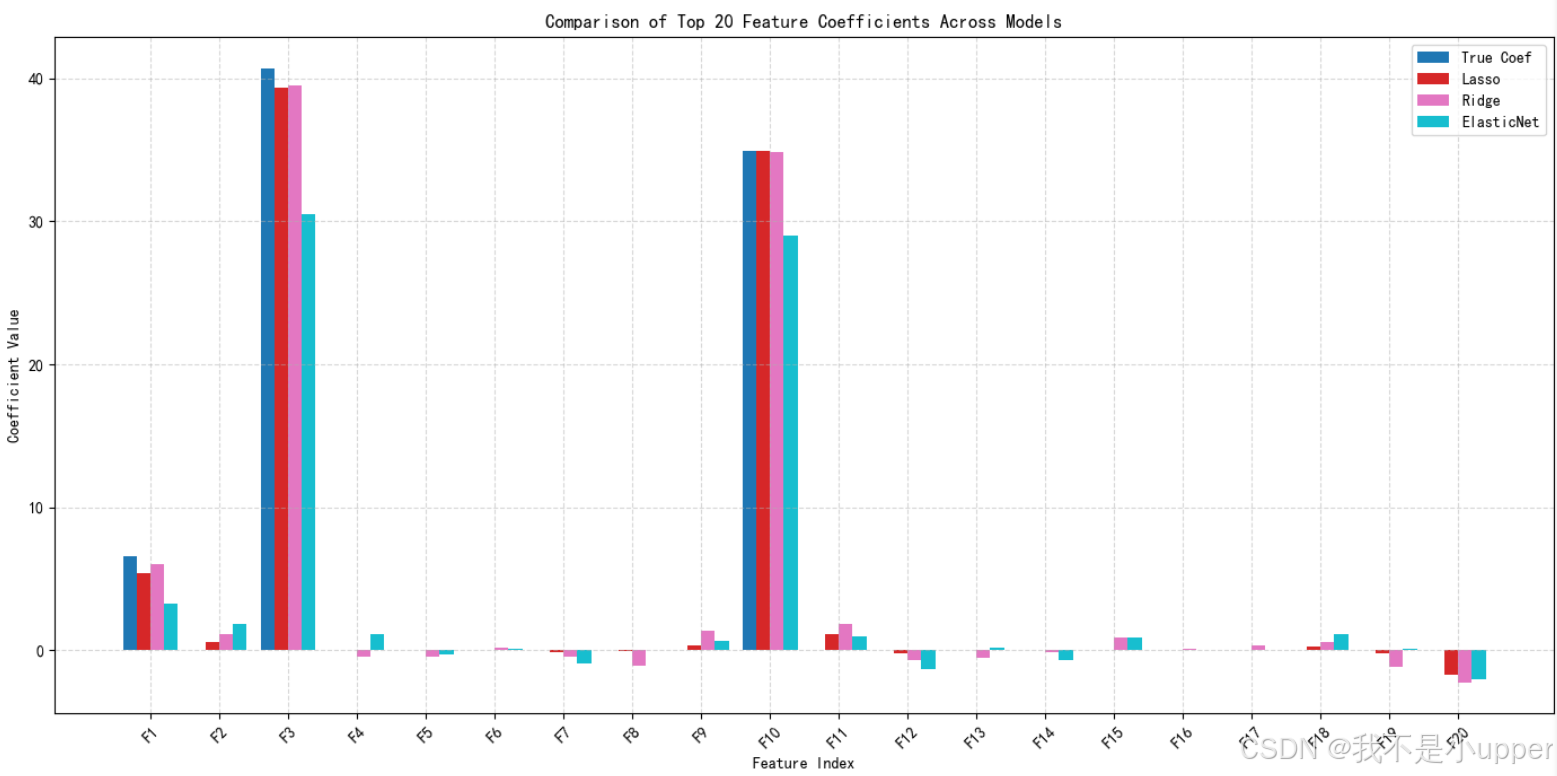
能清晰看到各模型對特征系數的處理差異。從真實系數(True Coef)來看,F3 和 F10 等特征原本就帶有較強信號,系數值明顯高于其他特征。Lasso 模型對系數的壓縮效果顯著,很多特征(像 F5 - F9 、F12 - F20 里的大部分)系數被壓至接近 0 ,只保留了 F3、F10 這類強信號特征的明顯系數,體現出它做特征選擇、剔除弱相關特征的特點。Ridge 模型則不同,它讓更多特征保留了非零系數,即使是 F5 - F9 這些在 Lasso 里系數近 0 的特征,Ridge 也給予了一定數值,不過整體系數大小相較于真實值有收縮,展現出它讓所有特征參與、但減小單個特征影響的作用。ElasticNet 模型的系數表現介于兩者之間,既不像 Lasso 那樣極端稀疏,也沒有 Ridge 那么多特征都有明顯系數,對 F3、F10 等強特征系數保留較好,同時對其他特征系數的壓縮程度比 Ridge 弱、比 Lasso 強,體現出它融合 L1 和 L2 正則化,平衡特征選擇與系數平滑的特性。綜合來看,不同正則化模型在處理特征系數時策略各異,Lasso 側重篩選關鍵特征,Ridge 強調系數整體收縮,ElasticNet 則在兩者間找平衡,這些差異會直接影響模型對特征的利用方式和最終的擬合、泛化效果 。
三種模型的預測誤差對比(MSE 越低越好)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn.datasets import make_regression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split# 生成合成數據
X, y = make_regression(n_samples=100, # 100個樣本n_features=20, # 20個特征n_informative=3, # 只有3個特征是有信息的noise=10, # 噪聲水平random_state=42)# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 訓練三種模型并計算MSE
lasso = Lasso(alpha=0.5, max_iter=10000).fit(X_train, y_train)
ridge = Ridge(alpha=1.0).fit(X_train, y_train)
enet = ElasticNet(alpha=0.5, l1_ratio=0.5, max_iter=10000).fit(X_train, y_train)lasso_mse = mean_squared_error(y_test, lasso.predict(X_test))
ridge_mse = mean_squared_error(y_test, ridge.predict(X_test))
enet_mse = mean_squared_error(y_test, enet.predict(X_test))# 創建MSE字典
mse_values = {'Lasso': lasso_mse,'Ridge': ridge_mse,'ElasticNet': enet_mse
}# 繪制MSE對比圖
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(mse_values.keys(), mse_values.values(), color=['orange', 'green', 'purple'])# 添加數值標簽
for bar in bars:yval = bar.get_height()ax.text(bar.get_x() + bar.get_width() / 2, yval + 0.02, f'{yval:.3f}', ha='center', va='bottom', fontsize=12)plt.ylabel('Mean Squared Error')
plt.title('Comparison of Prediction Errors (Lower is Better)')
plt.grid(True, axis='y', linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()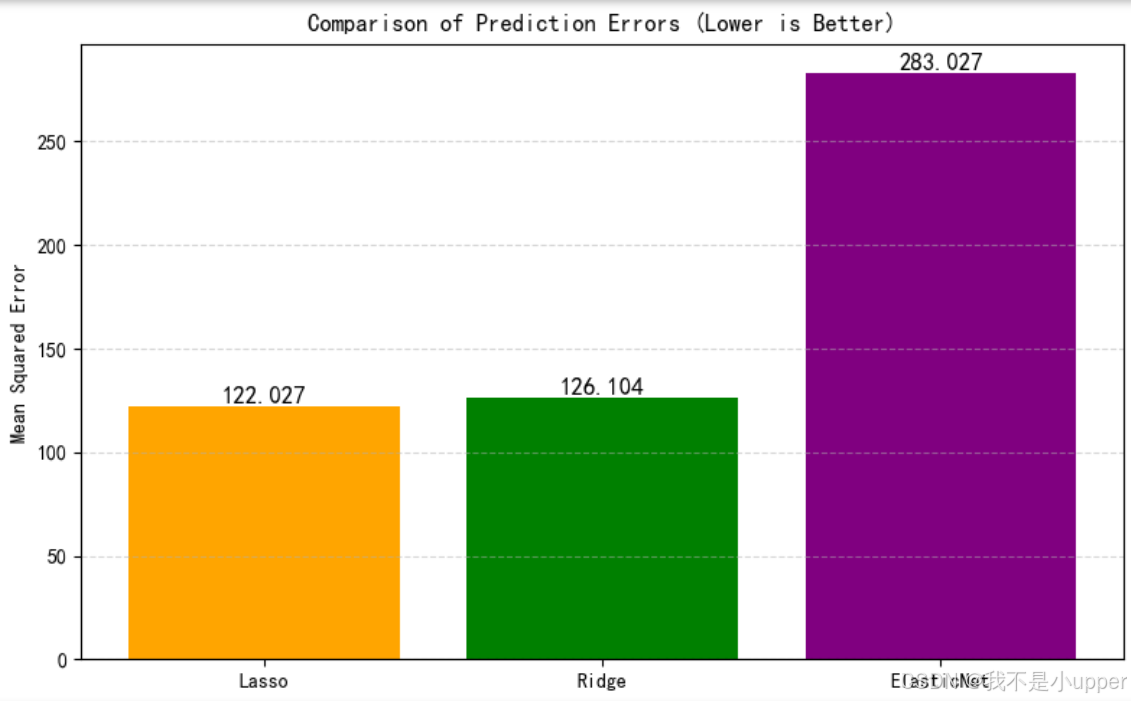
Lasso 的均方誤差(MSE)是 122.027,Ridge 稍高些,為 126.104,而 ElasticNet 的 MSE 高達 283.027。這說明在當前的數據集和參數設置下,Lasso 模型的預測精度相對更好,Ridge 次之,ElasticNet 表現則差很多。不過這結果可能和數據本身特點(像特征數量、相關性、噪聲等)以及模型的正則化參數(比如 alpha 值、l1_ratio 等)有關。后續或許可以調整 ElasticNet 的參數,或者對數據做更多預處理,看看能不能改善它的表現,也可以進一步對比不同模型在更多數據集上的表現,來確定哪種模型更適合這類數據場景 。
ElasticNet 中?l1_ratio?從 0 到 1 的變化對稀疏程度和系數的影響(熱力圖或線圖)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import ElasticNet
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split# 設置中文字體顯示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]# 生成合成數據
X, y = make_regression(n_samples=100, n_features=50, # 增加特征數量以更好展示稀疏性n_informative=5, noise=10,random_state=42)# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 計算不同l1_ratio下的非零系數數量
l1_ratios = np.linspace(0, 1, 11)
nonzero_counts = []for ratio in l1_ratios:model = ElasticNet(alpha=0.1, l1_ratio=ratio, max_iter=10000)model.fit(X_train, y_train)nonzero_count = np.sum(model.coef_ != 0)nonzero_counts.append(nonzero_count)# 繪制稀疏性變化圖
fig, ax = plt.subplots(figsize=(10, 6))
plt.plot(l1_ratios, nonzero_counts, marker='o', linewidth=2, color='crimson')# 添加數據標簽
for x, y in zip(l1_ratios, nonzero_counts):plt.annotate(f'{int(y)}', (x, y), textcoords="offset points",xytext=(0,10), ha='center')plt.xlabel('l1_ratio')
plt.ylabel('Number of Non-zero Coefficients')
plt.title('ElasticNet 稀疏性變化與 l1_ratio 的關系')
plt.grid(True, linestyle='--', alpha=0.7)
plt.xticks(l1_ratios, rotation=45)
plt.tight_layout()
plt.show()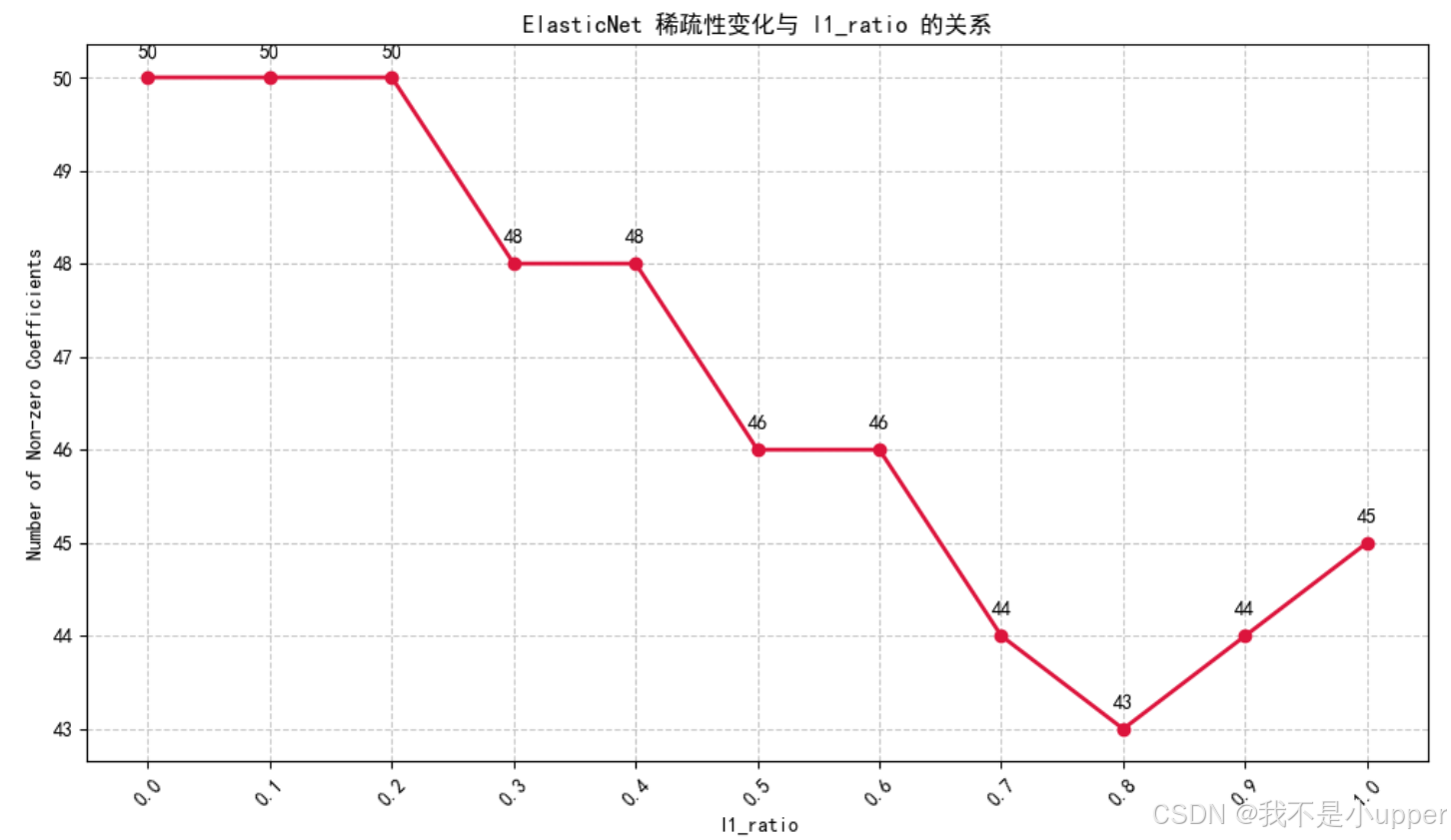
從圖中能清晰看到隨著?l1_ratio?從 0 逐漸增加到 1,非零系數數量呈現出動態的變化趨勢。當?l1_ratio?較小時(比如 0、0.1、0.2 ),非零系數數量一直維持在 50 ,這時候模型更偏向于 Ridge 正則化的特性,對系數的壓縮程度低,大部分特征都能保留非零系數參與建模。隨著?l1_ratio?繼續增大(到 0.3、0.4 ),非零系數數量開始下降到 48 ,說明 L1 正則化的影響逐漸顯現,開始有部分特征的系數被壓縮至 0 。當?l1_ratio?增加到 0.5、0.6 時,非零系數數量進一步降到 46 ,更多特征因 L1 正則的作用被篩選掉。到?l1_ratio?為 0.7 時,數量變為 44 ,而 0.8 時降到 43 ,此時 L1 正則化的主導作用很明顯,大量特征系數被置 0 。不過到?l1_ratio?為 0.9 時,非零系數數量又回升到 44 ,1.0 時到 45 ,這可能是模型在極端?l1_ratio(純 L1 正則)下,對特征篩選的策略出現了一些調整,或者是數據本身的特點導致。整體來看,l1_ratio?越小,模型越接近 Ridge ,保留更多特征;l1_ratio?越大,L1 正則的特征選擇作用越強,非零系數越少,但在極端值時變化出現了波動,這也反映出 ElasticNet 模型通過?l1_ratio?平衡 L1 和 L2 正則化的特點,不同的?l1_ratio?會顯著影響模型的稀疏性,進而影響特征的選擇和模型的復雜度 。





 — 一級架構主從架構)

)









安裝docker)

