目? 錄
一、order by 優化
1.未添加索引?
2.添加索引?
3.復合索引默認升序排列
4.復合索引降序排列
5.復合索引升序降序排列并用
6.總結
?二、group by 優化
1.未添加索引?
2.添加索引
3.添加復合索引?
三、limit 優化
四、主鍵優化?
1.主鍵設計原則
?五、insert 優化
1.原則
2.load
六、count 優化
七、update 優化
1.說明
2.行級鎖
(1)修改同一條記錄?
(2)修改不同記錄
3.表級鎖
一、order by 優化
# 初始化
drop table if exists t_workers;
create table t_workers(id int primary key auto_increment,name varchar(10),age int,sal int
);
insert into t_workers(name, age, sal) values('王棟梁', 18, 3000),('李建', 23, 5000),('張昊晟', 31, 2500);
- 使用【explain】查看帶有【order by】語句的執行計劃時,【Extra】字段會顯示 using index 或 using filesort。區別如下:
- using index:表示使用索引,因為索引提前排好序,所以效率很高;
- using filesort:表示使用文件排序,排序時將硬盤中的數據讀取到內存中,在內存中排序,效率較低。
- 初始化中的實例如下。
1.未添加索引?
-- 未添加索引,根據name進行文件排序,效率較低
explain select id, name from t_workers order by name;

2.添加索引?
-- 創建索引,效率提高
create index index_tworkers_name on t_workers(name);
explain select id, name from t_workers order by name;
3.復合索引默認升序排列
-- 若需要通過兩個字段排序,建議添加復合索引。按照age升序排,age相同按照sal升序
create index index_tworkers_as on t_workers(age, sal);
explain select id, age, sal from t_workers order by age, sal;
4.復合索引降序排列
? ? ? ? B+樹葉子結點上所有數據默認升序排列。添加聯合索引,若按照 age 降序排列,age 相同則按照 sal 降序排列,會使用索引嗎?
explain select id, age, sal from t_workers order by age desc, sal desc;
? ? ? ? 答案是會的,可以看到進行了 反向索引掃描。
? ? ? ? B+樹葉子節點之間采用雙向指針,可以從左向右升序,也可以從右往左降序。
5.復合索引升序降序排列并用
-- age升序,sal降序
explain select id, age, sal from t_workers order by age asc, sal desc;
? ? ? ? 可以看到 age 使用了索引,而 sal 沒有使用索引。
? ? ? ? 但是,可以創建對應的指定排序索引解決此問題。
-- 創建指定排序索引
create index index_tworkers_as2 on t_workers(age asc, sal desc);
explain select id, age, sal from t_workers order by age asc, sal desc;
6.總結
排序也遵循最左前綴原則;
使用覆蓋索引;
針對不同排序規則,創建不同索引。若所有字段都是升序或都是降序,則不需要創建指定排序索引;
若無法避免 filesort,要注意排序緩存大小,默認緩存大小是 256KB,可以修改系統變量 sort_buffer_size。?
?二、group by 優化
# 初始化
drop table if exists t_employees;
create table t_employees(id int primary key auto_increment,name varchar(10),age int,gender varchar(2),job varchar(10)
);
insert into t_employees(name, age, gender, job) values('劉佳佳', 21, '女', '業務員'),('王平', 23, '男', '業務員'),('郭東', 37, '男', '業務員'),('張筱雨', 32, '女', '經理'),('馬菲燕', 45, '女', '經理'),('張強', 52, '男', '安保'),('寇愛國', 49, '男', '安保'),('邱政琪', 38, '男', '會計');1.未添加索引?
explain select job, count(*) from t_employees group by job;
? ? ? ? ?可以看到,使用了臨時表,效率較低。
2.添加索引
create index index_temployees_job on t_employees(job);
explain select job, count(*) from t_employees group by job;
3.添加復合索引?
create index index_temployees_aj on t_employees(job, age);
explain select age, count(*) from t_employees group by age;
explain select age, count(*) from t_employees where job = '經理' group by age;

? ? ? ? 可以看到,group by 也遵循最左前綴原則。?
三、limit 優化
? ? ? ? 數據量特別龐大時,使用 limit 讀取數據時,越往后效率越低。可以使用【覆蓋索引 + 子查詢】的方式提升效率。
四、主鍵優化?
1.主鍵設計原則
- 主鍵值不要太長,二級索引葉子結點上存儲的是主鍵值。主鍵值太長會導致索引占用空間較大;
- 盡量使用【auto_increment】生成主鍵,盡量不使用 uuid 作為主鍵,因為 uuid 不是順序插入;
- 插入數據時,主鍵值盡量順序插入,因為亂序插入可能會導致 B+樹 的葉子結點頻繁進行頁分裂和頁合并操作,效率較低。
- 在 InnoDB 中,主鍵值對應聚集索引,插入主鍵值如果是亂序的,B+樹葉子結點需要不斷重新排序,重新排序過程中頻繁涉及頁分裂和頁合并操作,效率較低;
- B+樹每個結點都存儲在頁中,一個頁面中存儲一個結點;
- MySQL 的 InnoDB 存儲引擎,一個頁可以存儲 16KB 的數據;
若主鍵值不是順序插入,就會導致頻繁的頁分裂和頁合并。在一個B+樹中,頁分裂和頁合并是樹自動調整機制的一部分。當一個頁已經滿了,再插入一個新的關鍵字時就會觸發頁分裂操作,將頁中的關鍵字分配到兩個新的頁中,同時調整樹的結構。相反,當一個頁中的關鍵字數量下降到一個閾值以下時,就會觸發頁合并操作,將兩個相鄰的頁合并成一個新的頁。如果主鍵值是隨機的、不是順序插入的,那么頁的利用率會降低,頁分裂和頁合并的次數就會增加。由于頁的分裂和合并是比較耗時的操作,頻繁的分裂和合并會降低數據庫系統的性能。因此,為了優化B+樹的性能,可以將主鍵值設計成順序插入的,這樣可以減少頁的分裂和合并的次數,提高B+樹的性能。在實際應用中,如果對主鍵值的順序性能要求不是特別高,也可以采用一些技術手段來減少頁分裂和合并,例如B+樹分裂時采用“延遲分裂”技術,或者通過調整頁的大小和結點的大小等方式來優化B+樹的性能。
盡量不使用業務主鍵,因為業務的變化會導致主鍵值頻繁修改。不建議主鍵值修改,因為主鍵值修改,聚集索引一定會重新排序。
?五、insert 優化
1.原則
- 數據量較大時,可以批量插入。建議一次插入數據不超過 1000 條;
- MySQL 默認自動提交事務,只要執行一條?DML 語句就會自動提交一次。因此,當插入大量數據時,建議手動開啟事務和手動提交事務;
- 主鍵值建議順序插入,效率較高;
- 超大數據量插入可以考慮使用 load 命令,可以將 csv 文件中的數據批量導入到數據庫表中,效率較高。每個字段間使用 “,” 隔開,每條數據另起一行。
2.load
# 1.登錄MySQL時指定參數
mysql --local-infile -u[用戶名] -p[密碼]# 2.開啟local_infile功能
set global local_infile = 1;# 3.執行load指令
-- 首先,創建表
load data local infile '文件存放路徑' into table [表名] fields terminated by ',' lines terminated by '\n';六、count 優化
- 使用:
- count(主鍵):將每個主鍵值取出累加;
- count(常量值):獲取每個常量值累加;
- count(字段):取出字段的每個值,判斷是否為 NULL,不為 NULL則累加;
- count(*):不取值,直接統計總行數,效率最高。若統計一張表中總行數,建議使用。
- 注意:
- 對于 InnoDB 存儲引擎,count 計數實現原理就是將表中每一條數據取出,然后累加。若想真正提高效率,可以使用其他程序實現;
- 對于 MyISAM 存儲引擎,當一個 select 語句沒有 where 條件時,獲取總行數效率極高,不需要統計,因為 MyISAM 存儲引擎單獨維護了一個總行數。
七、update 優化
1.說明
- 存儲引擎是 InnoDB 時,表的行級鎖是針對索引添加的鎖,若索引失效或不是索引列時,會提升為表級鎖;
- 行級鎖:有 A、B 兩個事務,開啟 A 事務后,通過 A 事務修改表中某條記錄。修改后未提交,B 事務去修改同一條記錄時無法繼續,直到 A 事務提交,B 事務才可以繼續;
- 為了提高效率,建議為 update 語句中的 where 條件添加索引。
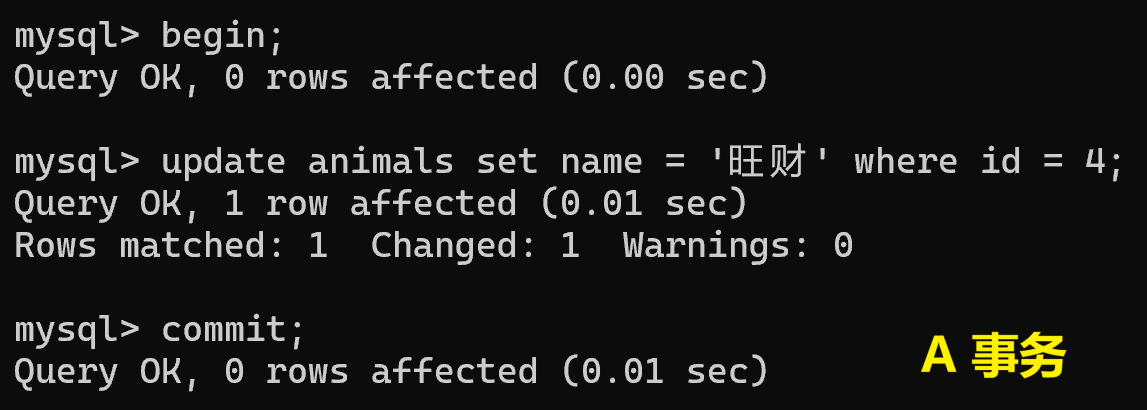
2.行級鎖
(1)修改同一條記錄?
? ? ? ? 行級鎖,A 事務修改未提交,B 事務修改同一條記錄,會無法繼續執行。

(2)修改不同記錄
? ? ? ? 行級鎖,A 事務修改未提交,B 事務修改其他記錄,不會影響。


3.表級鎖
? ? ? ? 條件為非索引列或索引失效會升級為表級鎖。表級鎖,A 事務修改未提交。B 事務無論修改哪一條記錄,都不會繼續執行。

![]()

:小版本迭代,問題修復與功能優化)














![[創業之路-410]:經濟學 - 國富論的核心思想和觀點,以及對創業者的啟發](http://pic.xiahunao.cn/[創業之路-410]:經濟學 - 國富論的核心思想和觀點,以及對創業者的啟發)


)