Convergent evolution of berberine biosynthesis
小檗堿生物合成的趨同進化

摘要
小檗堿是一種有效的抗菌和抗糖尿病生物堿,主要從不同植物譜系中提取,特別是從小檗屬(毛茛目,早期分支的真雙子葉植物)和黃柏屬(無患子目,核心真雙子葉植物)中提取。與小檗屬物種中已知的小檗堿生物合成路徑相比,其在黃柏屬物種中的生物合成仍不清楚。通過使用染色體水平基因組組裝、共表達矩陣和生化測定,我們鑒定了黃柏屬小檗堿生物合成中的六個關鍵步驟,包括甲基化、羥基化和小檗堿橋形成。特別地,我們發現了一類特定的O-甲基轉移酶(NOMT),負責N-甲基化。對PaNOMT9的結構分析和誘變研究揭示了其獨特的底物結合構象。此外,與毛茛目經典的FAD依賴性小檗堿橋形成不同,黃柏屬使用NAD(P)H依賴性的單加氧酶(PaCYP71BG29)進行小檗堿橋的形成,該過程源于色氨酸胺5-羥化酶的新功能化。綜上所述,這些發現揭示了小檗堿生物合成在小檗屬和黃柏屬之間的趨同進化,并標志著趨同進化在植物特化代謝中的作用。
引言
植物來源的芐基異喹啉生物堿(BIA)是藥物的一個重要來源。許多BIA,如小檗堿(1–4)、嗎啡(5, 6)和血根堿(7, 8),已經用于治療各種疾病。關于BIA的分離和植物界中的分布,已有大量研究完成。一方面,令人感興趣的是,許多BIA主要集中在特定的被子植物目中,例如早期分支的真雙子葉植物(如毛茛目和木蘭目)和木蘭類植物(如木蘭目、月桂目和胡椒目)(9–12)。另一方面,少數BIA(如小檗堿)的分布則呈現不同的模式。小檗堿最初是從核心真雙子葉植物(無患子目)的黃木(Zanthoxylon clava)樹皮中分離出來的。后續的研究表明,黃柏屬(Phellodendron spp.)也能產生小檗堿(13)。截至目前,小檗堿的生產主要依賴于如毛茛目(Ranunculales)中的小檗屬(Berberis)和小檗屬(Coptis)以及無患子目(Sapindales)中的黃柏屬等植物來源(14)。
小檗堿是一種有效的廣譜抗菌和抗糖尿病藥物。過去的研究已經描述了小檗堿在小檗屬植物根部和根莖中的主要生物合成步驟(15)。其生物合成途徑始于多巴胺(1)和4-羥基苯乙醛(4HPAA;2)的偶聯反應,生成(S)-去氫可克勞林(3),這一過程由去氫可克勞林合酶(NCS)催化,NCS是PR10/Bet v1家族的成員(16, 17)。隨后的修飾反應,包括通過O-/N-甲基轉移酶(MTs)進行的O/N-甲基化和通過細胞色素P450進行的羥化,促使(S)-網狀堿(7)的形成(18–20),它是BIA生物合成途徑中的重要中間體。來自黃素腺嘌呤二核苷酸(FAD)依賴性氧化酶家族的小檗堿橋酶(BBE)催化7轉化為四環小檗堿骨架(S)-可克勞林(8)(21)。最后,9OMT(22)、CYP719A(23, 24)和STOX(BBE樣)(25)負責三個連續步驟——O-甲基化、亞甲基二氧橋形成和四電子氧化反應——將8轉化為小檗堿(11)(圖1A)。隨著小檗堿生物合成的闡明,最近的研究重點轉向了代謝工程和體外環境可持續生產。盡管已經實現了小檗堿的全新微生物合成,但由于催化效率和酶的多功能性限制,目前的產量尚未達到工業生產的要求(26, 27)。尋找替代生物合成酶的研究結果將為實現高效生產BIA提供重要的遺傳元素。
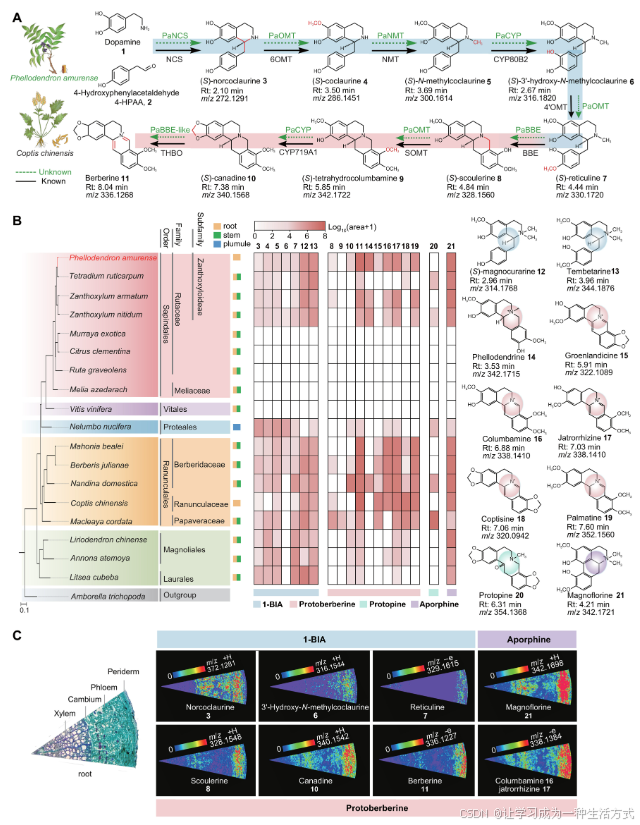
圖 1. 黃柏屬(P. amurense)中產生的原小檗堿和阿佛品類BIA。 (A) 小檗堿(11)的生物合成途徑。黑色箭頭表示來自小檗屬的已報道酶,虛線箭頭表示這些步驟在黃柏屬中仍不明確。1,多巴胺;2,4HPAA;3,(S)-去氫可克勞林;4,(S)-可克勞林;5,(S)-N-甲基可克勞林;6,(S)-3′-羥基-N-甲基可克勞林;7,(S)-網狀堿;8,(S)-可克勞林;9,(S)-四氫哥倫比亞堿;10,(S)-加拿丁;11,小檗堿。Rt,保留時間。 (B) 測試物種的系統發育樹和BIA代謝物譜。該系統發育樹是基于黃柏屬(P. amurense)和其他18個物種的轉錄組或基因組數據(表S1)使用單拷貝直系同源基因構建的。代謝物是從17個物種的根部(黃色)和/或莖部(綠色)提取的,還包括蓮子(N. nucifera)的蓮胚(藍色)。熱圖顯示BIA水平,通過log10(峰面積+1)的值表示。BIA類型:1-BIA,原小檗堿、前小檗堿和阿佛品類。12,(S)-木蘭啡;13,天貝他林;15,黃柏堿;15,格爾蘭啡;16,哥倫比亞堿;17,賈托里赫辛;18,小檗啡;19,棕櫚堿;20,前小檗堿;21,大花啡。 (C) 顯微圖像顯示黃柏屬(P. amurense)根部的橫截面,MALDI-MSI圖像生成的熱圖顯示了代謝物的積累模式。
盡管在小檗屬物種中已明確了解上述的生物合成途徑,但是否在遠緣關系的黃柏屬物種中,小檗堿的豐富物種也遵循相同的途徑仍不清楚。基于黃柏屬和小檗屬之間不同的譜系,我們假設黃柏屬物種可能已經進化出不同的機制來合成小檗堿和其他BIA。為了驗證這一假設,我們采用了基因組組裝、轉錄組學、誘變、基因組比較、系統發育分析、蛋白質結晶、酶學測定和代謝組學的綜合方法,解析了黃柏屬(P. amurense)中小檗堿的生物合成途徑。所得數據不僅確定了該譜系中小檗堿的六個生物合成步驟,還揭示了先前未知的酶學功能和機制。來自黃柏屬的OMT酶通過不同的機制催化BIA中間體的N-甲基化。與小檗屬中的FAD依賴性BBE不同,已鑒定出譜系特異性的CYP450酶催化黃柏屬中的小檗堿橋形成。這些發現揭示了小檗堿的生物合成在小檗屬和黃柏屬中經歷了不同的進化。小檗堿生物合成的分歧擴展了我們對植物BIA代謝的理解,并為代謝工程提供了重要的見解。
結果
黃柏屬(P. amurense)中小檗堿的豐度
為了了解黃柏屬(P. amurense)和其他17個植物物種在六個不同目(木蘭目、月桂目、毛茛目、木蘭目、葡萄目和無患子目)中的BIA分布,完成了液相色譜-質譜(LC-MS)分析,以概述各種組織中的19種BIA代謝物(表S1)。結果顯示,這些BIA主要在木蘭類植物(木蘭目和月桂目)和早期分支的真雙子葉植物中被檢測到。數據還揭示了原小檗堿類和阿佛品類BIA,尤其是小檗堿(11,[M + H]+質量/電荷比(m/z)336.1268)、黃柏堿(14,[M + H]+ m/z 342.1715)、哥倫比亞堿(16,[M + H]+ m/z 338.1410)、賈托里赫辛(17,[M + H]+ m/z 338.1410)、棕櫚堿(19,[M + H]+ m/z 352.1560)和大花啡(21,[M + H]+ m/z 342.1721),在黃木科物種(如黃柏、粗欖、刺木和光木)根部和/或莖部中高濃度積累(圖1B及圖S1和S2)。與這四個物種不同,其他無患子目物種和葡萄(Vitis vinifera)中未檢測到BIA。在毛茛目中,像小檗屬(如馬赫爾·比爾利、黃柏朱利安、南丁丁和中國小檗等)也積累了高水平的原小檗堿類BIA,這與黃柏屬相似(圖1B)。這些發現證實了原小檗堿類BIA,特別是小檗堿,在遠緣的無患子目(黃柏屬)和毛茛目(小檗屬)物種中具有獨立和譜系特異性的分布。小檗堿的生物合成途徑,尤其是在小檗屬中,已經得到了完全闡明(圖1A)。基于黃柏屬和小檗屬BIA代謝譜的相似性,我們提出這兩種植物可能共享類似的小檗堿生物合成步驟。此外,完成了基質輔助激光解吸/電離質譜成像(MALDI-MSI),用于空間定位黃柏屬(P. amurense)根部的BIA。所得圖像顯示,小檗堿途徑代謝物和小檗堿衍生物定位于根部的外皮和韌皮部(圖1C及圖S3)。
基因組組裝和P. amurense的全基因組重復倍增(WGD)
為了識別P. amurense中負責小檗堿生物合成的關鍵基因,我們生成了137.52 Gb的Illumina測序數據、73.14 Gb的PacBio Sequel II長讀長測序數據,以及324.14 Gb的Hi-C配對末端讀數,基于這些數據組裝了染色體級別的單倍型基因組(圖2A、圖S4和表S2)。基因組調查、初步組裝和染色體錨定分析構建了38條假染色體,覆蓋了2.81 Gb的基因組大小,支架N50長度為76.63 Mb(圖S5和表S3、S4)。該基因組的Benchmarking Universal Single-Copy Orthologs(BUSCO)完整性值達到了97.7%(表S5)。此外,P. amurense基因組中約87.03%由可轉移元件組成,其中長末端重復反轉錄轉座子(LTR-RTs)是最豐富的重復序列類別(表S6)。在P. amurense基因組中共預測了41,414個編碼蛋白的基因,BUSCO完整性為97.60%,這表明基因組組裝和基因預測的高完整性(表S5)。系統基因組學和時間推斷分析表明,兩種產生BIA的Zanthoxyloideae物種(P. amurense和Z. armatum)與未積累BIA的Aurantioideae和Rutoideae物種為姊妹關系(圖2B和圖S6),P. amurense與Z. armatum的分歧時間為2490萬年前(Ma),95%置信區間(CI)為1833萬至3153萬年前(圖S6)。
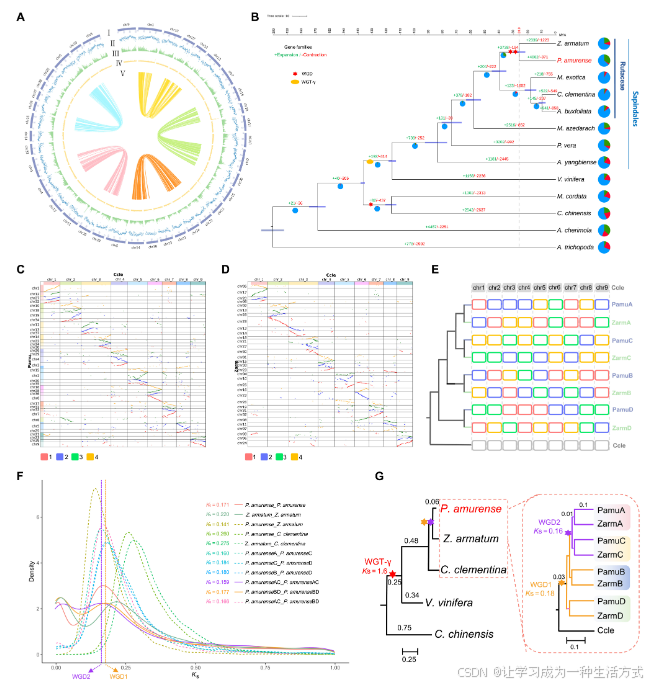
圖2. P. amurense基因組的基因組特征、系統發育樹和全基因組重復倍增(WGD)事件
(A) P. amurense的基因組特征。最外圈到最內圈的circos圖展示了38條假染色體(I),基因密度(每Mb基因數)(II),1 Mb窗口中的GC含量(III),重復序列的密度(IV),以及circos圖中心的每條連接線表示一對同源基因(V)。 (B) 基于P. amurense和12個候選物種的單拷貝直系同源基因構建的系統發育樹。每個分支線上的綠色和紅色數字分別表示擴展和收縮的基因家族數目。餅圖展示了經歷了基因家族收縮(紅色)或擴展(綠色)的比例。分歧時間及其95%置信區間(CI)在分支節點上通過紫色水平條表示。WGT-γ表示gamma三重倍增事件。 (C) P. amurense和C. clementina基因組之間的共線性。以C. clementina基因組為參考,識別P. amurense基因組中每條染色體的同源基因對和共線性區塊。 (D) Z. armatum和C. clementina染色體之間的共線性。 (E) 根據候選物種與C. clementina染色體(Chr1到Chr9)之間的共線性圖譜,分別使用P. amurense子基因組和Z. armatum子基因組中的同源基因構建的系統發育樹。P. amurense和Z. armatum中的紅色、藍色、綠色和橙色框代表與C. clementina的四種類型的共線性區塊。 (F) P. amurense、Z. armatum、P. amurense子基因組、Z. armatum子基因組和C. clementina之間的直系同源基因和旁系同源基因的KS分布。 (G) P. amurense和Z. armatum的預測WGD事件。WGD1和WGD2分別表示P. amurense和Z. armatum基因組之間共享的WGD事件。
基因組內共線性分析揭示了P. amurense基因組中至少存在兩次全基因組重復倍增(WGD)事件的遺跡(圖2A和圖S7、S8)。基因組間的共線性分析表明,P. amurense和Z. armatum基因組中的四個旁系同源段與Citrus clementina基因組中的一個直系同源區域相對應(圖2C和D),這表明P. amurense和Z. armatum基因組中的兩輪WGD事件可能發生在與C. clementina基因組分歧之后。P. amurense和Z. armatum的基因組分別映射到C. clementina基因組中。該映射在系統發育上將它們分為四個子基因組(PamuA、PamuB、PamuC和PamuD;以及ZarmA、ZarmB、ZarmC和ZarmD;圖2E和圖S9)。為了進一步探討P. amurense WGD的系統發育位置,通過成對的子基因組對旁系同源基因的Ks(同義替代每個同義位點的替代數)分布分析顯示了兩個經過調整速率的Ks峰值:PamuAC旁系同源基因的0.16和PamuBD旁系同源基因的0.18。這一結果確認了P. amurense和Z. armatum在分裂之前共享了兩輪WGD事件(圖2F和G,及圖S10)。這些結果表明,Rutaceae物種中可能發生了廣泛的WGD事件和復雜的染色體進化。
小檗堿生物合成途徑的闡明
為了識別參與P. amurense中小檗堿生物合成的基因,我們將先前對18個組織的轉錄組測序數據與小檗堿積累模式結合,進行了Pearson相關系數(r)分析。結果顯示了與小檗堿產生相關的高排名候選基因(r > 0.80)。這些基因包括兩個PaOMTs基因、一個PaNMT基因和四個PaCYPs基因,這些基因被選為功能分析的對象(圖3A)。
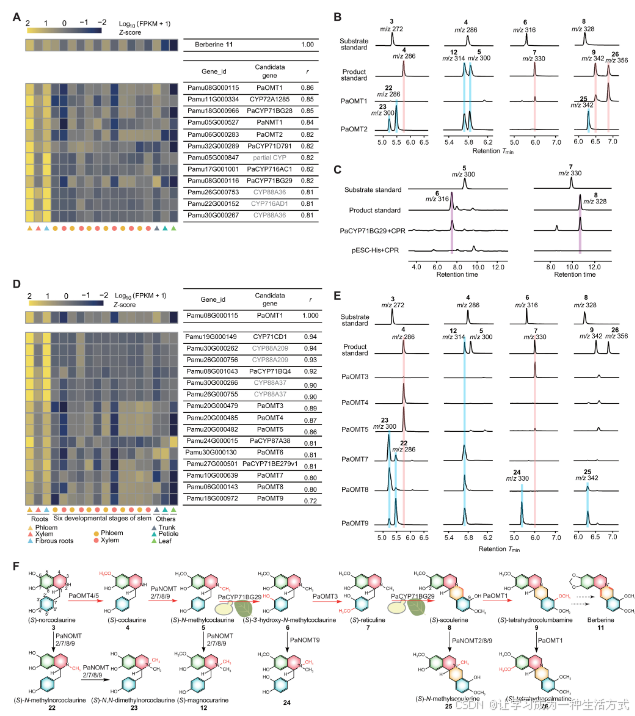
圖3. 小檗堿生物合成途徑的闡明
(A) P. amurense轉錄組數據與小檗堿含量之間的Pearson相關系數(r > 0.80)。熱圖展示了從log10(FPKM + 1)計算的z分數。灰色突出顯示的CYP450s是未成功克隆的部分基因或報告的limonin生物合成同源基因(圖S21)。FPKM表示每百萬個比對片段中的每千堿基外顯子模型的片段數。 (B) 使用3、4、6和8作為底物時,由純化的PaOMT1和PaOMT2催化的化合物的提取離子色譜圖。 (C) 使用5和7作為底物時,由PaCYP71BG29微體催化的化合物的提取離子色譜圖。 (D) P. amurense轉錄組數據與PaOMT1基因之間的Pearson相關系數。灰色突出顯示的基因是未成功克隆的或報告的limonin生物合成同源基因。 (E) 使用3、4、6和8作為底物時,由純化的PaOMT4/5/7/8/9催化的化合物的提取離子色譜圖。 (F) 本圖總結了本文報告中驗證的催化步驟。PaCYP71BG29的催化活性通過酵母和煙草表達系統進行了雙重確認。N-甲基化的OMT成員被重新命名為NOMTs。Tmin為分鐘時間。
首先,為了確定參與小檗堿生物合成的O-和N-甲基化反應,我們誘導重組的PaOMT1、PaOMT2和PaNMT1進行體外甲基化活性測試,使用了四種底物:(S)-norcoclaurine (3)、(S)-coclaurine (4)、(S)-3′-hydroxy-N-methylcoclaurine (6) 和 (S)-scoulerine (8)。這些測試確定PaOMT1和PaOMT2具有甲基化活性,而PaNMT1則沒有。PaOMT1催化8號底物C-2和C-8羥基的連續O-甲基化,生成(S)-tetrahydrocolumbamine (9)(m/z 342)和(S)-tetrahydropalmatine (26)(m/z 356),其功能與C. chinensis中的Cc9OMT相同(圖3B和圖S11)。意外的是,PaOMT2沒有表現出任何O-甲基化功能,但出乎意料地表現出對4號底物的N-甲基化活性,分別生成(S)-N-methylcoclaurine (5, m/z 300)和(S)-magnocurarine (12, m/z 314),通過單一和雙重N-甲基化反應,這與C. chinensis中的CcNMT的催化活性相當(圖3B和圖S12)。此外,PaOMT2還催化了3、4和8號中間體上未飽和NH或NCH3基團的N-甲基化和N-去甲基化,表現出明顯的底物寬容性(圖3F)。這些此前未識別的活性增進了對BIA生物合成中N-甲基化的理解。
其次,使用CYP蛋白測試了BIA的氧化反應。根據已有報告,CYP450酶CYP80B1/2(24, 28, 29)、CYP80G1(29, 30)和CYP719A1(24, 31)分別催化5號底物的C-3′羥基化、7號底物的C-C苯基偶聯反應以及(S)-tetrahydrocolumbamine (9)的美克倫二氧橋形成,四種候選PaCYPs—PaCYP71BG28、PaCYP71BG29、PaCYP71D791和PaCYP716AC1—在體外進行了催化功能研究,底物為5、7和9。結果表明,PaCYP71BG29對5和7的催化活性被檢測到,而其他酶的活性沒有被檢測到(圖S13)。PaCYP71BG29展示了在底物5的C-3′位上的羥化酶活性,生成6(m/z 316)(圖3C和圖S14)。此外,PaCYP71BG29還催化了7的黃連橋形成,生成8(m/z 328)(圖3C和圖S15),這與Coptis spp.中FAD依賴的氧化酶BBE的活性相同。此外,在Nicotiana benthamiana中瞬時表達PaCYP71BG29也確認了其對5的羥化活性(圖S16)和對7的黃連橋形成活性(圖S17)。
最后,通過使用PaOMT1作為誘餌基因進行共表達分析,闡明了小檗堿在黃檗屬中的剩余生物合成步驟,選擇了七個OMTs(PaOMT3到PaOMT9)和三個CYPs(PaCYP71BQ4、PaCYP71BE279v1和PaCYP87A38),這些基因的表達與PaOMT1高度相似(圖3D)。體外生化實驗顯示了三種類型的甲基化活性。(i) 如PaOMT2測試所述,PaOMT7、PaOMT8和PaOMT9催化了N-甲基化活性,并具有廣泛的底物寬容性(圖3E和圖S12)。(ii) PaOMT4和PaOMT5催化了3號底物C-6羥基的甲基化,生成4(圖3E和圖S18)。(iii) PaOMT3催化了6號底物C-4′羥基的甲基化,生成7(圖3E和圖S19)。此外,在不同底物的催化實驗中,未檢測到PaOMT6和三種PaCYP450s的活性(圖S13和S20)。總之,這些生化數據闡明了黃檗屬小檗堿途徑中的6個酶催化步驟(圖3F)。
PaNOMT9的晶體結構和催化機制
根據之前未識別的催化特性,N-甲基化OMT成員已重新命名為NOMT組(圖3F)。為了理解PaOMT在P. amurense中催化的N-甲基化機制,我們解析了三元復合物PaNOMT9/S-腺苷甲硫氨酸(SAM)/4的晶體結構(蛋白質數據銀行(PDB)ID:8ZN0),分辨率為1.8 ?(圖4A)。PaNOMT9的蛋白質結構形成了二聚體(標記為A和B)。這兩個不同的單體分別構成N端二聚體化域(1到165氨基酸,主要由α1到α10、β1到β3和η1組成)和C端Rossmann折疊的SAM/S-腺苷高半胱氨酸(SAH)結合域(199到359氨基酸,α12到α16、β4到β10和η2),兩者通過α11螺旋(166到198氨基酸)連接(圖4A)。在PaNOMT9的二聚體化域(α6和α10)、SAM/SAH結合域(α15和η2)以及α11螺旋的界面處,17個殘基距離底物4在5 ?范圍內(圖S22A和S23)。蛋白質-配體相互作用分析揭示,H127與C6-甲氧基和C7-羥基之間形成氫鍵,而Y159與NH基團之間形成氫鍵(圖4B)。核心底物4被F123、F126、W262、I265、M312、I315、G316、V320和L325等疏水性殘基環繞,并與這些殘基相互作用。此外,距離活性位點較遠的D185、D293和L295通過序列比對被鑒定為N-甲基化和O-甲基化OMT蛋白的差異殘基(圖4C和圖S22B及S23)。
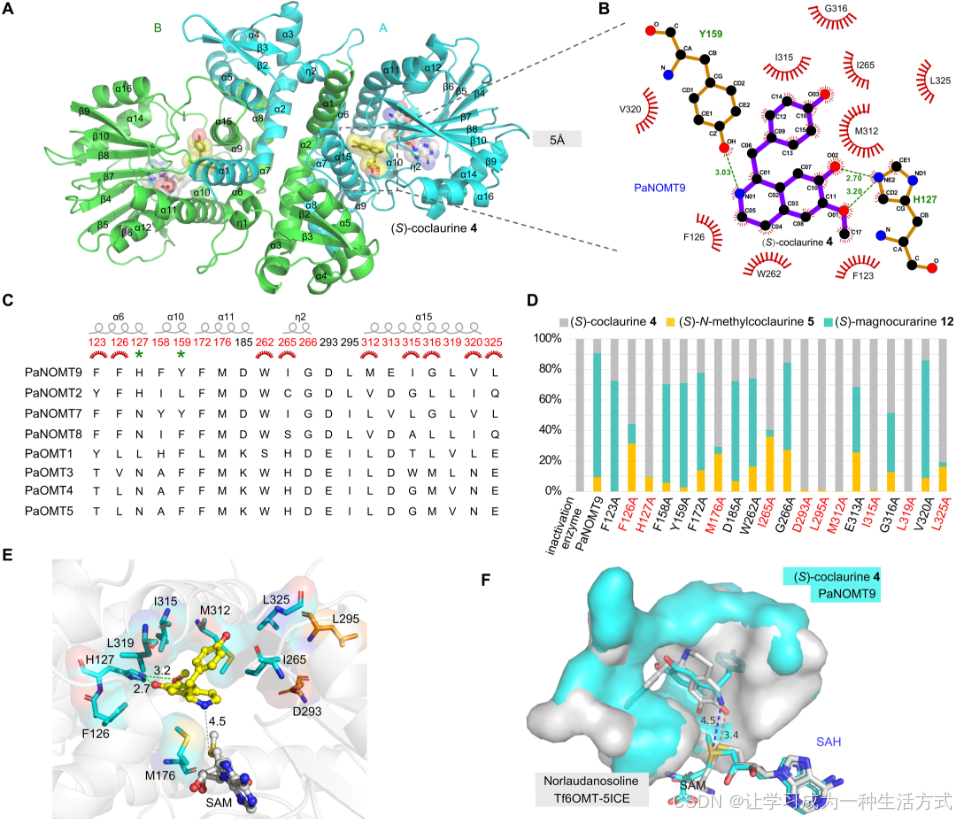
圖4. PaNOMT9的晶體結構和催化機制
(A) PaNOMT9/4/SAM三元復合物的晶體結構總體視圖。 (B) PaNOMT9與配體4之間的蛋白質-配體相互作用圖。紅色標記表示疏水性殘基。 (C) N-甲基化活性OMT蛋白PaNOMT9/2/7/8與O-甲基化OMT蛋白PaOMT1/3/4/5之間的氨基酸序列比對。 (D) PaNOMT9及其20個通過定向突變得到的變體的催化活性,以堆疊條形圖表示。 (E) 由PaNOMT9/4/SAM形成的三元復合物的晶體結構,其中突變這些關鍵殘基會降低催化活性。用青色突出顯示的殘基表示這些殘基與底物之間的距離小于5 ?,而用橙色表示的殘基超出了這一范圍。灰色虛線表示4的N原子與SAM甲基化基團之間的距離為4.5 ?。 (F) 兩個三元復合物晶體結構的疊加:Tf6OMT/norlaudanosoline/SAH和PaNOMT9/4/SAM。這兩個三元復合物的蛋白質-配體結合構象差異導致了O-/N-甲基化功能的差異。
上述PaNOMT9的20個殘基被逐一用丙氨酸(A)替代,生成了20個變體,然后測試了每個變體以4為底物的活性。反應中甲基化產物(5)或二甲基化產物(12)的含量通過LC-MS分析估算(圖4D)。一方面,結果表明,M312、I315和L319的丙氨酸替換幾乎完全廢除了N-甲基化活性(圖4D)。另一方面,四個變體—F126A、M176A、I265A和L325A—表現出明顯高于野生型的5/12(甲基化/二甲基化)比值(圖4D)。這些結果表明,疏水相互作用對于底物結合口袋的構建至關重要(圖4E)。此外,位于遠離活性位點的D293A和L295突變體幾乎完全失去了N-甲基化活性,這可能歸因于蛋白質結構的擾動。PaNOMT9的H127A變體只能催化無效的N-甲基化反應,表明H127與底物4之間的氫鍵對于底物結合構象的形成至關重要(圖4D和E)。我們進一步生成了11個額外的H127突變體,結果表明,保守替換(H127N)和具有相似性質的替換(H127K和H127R)保留了對4的野生型N-甲基化活性。相比之下,H127P突變體幾乎完全失去了N-甲基化活性(圖S24A)。H127A和H127P突變體,位于遠離C6-甲氧基和C7-羥基的地方,導致活性口袋內出現較大的空腔,這表明H127在底物結合構象中起著關鍵作用(圖S24B)。
為了理解PaNOMT9催化的N-甲基化機制,我們對晶體結構進行了比較。已報道的來自Thalictrum flavum的Tf6OMT(PDB ID:5ICE)和來自Coptis japonica的CjCNMT(PDB ID:6GKV)分別催化O-甲基化和N-甲基化,并已詳細解析了它們的晶體結構(32, 33)。基于這些數據,我們將Tf6OMT和CjCNMT的蛋白質結構與PaNOMT9進行了比較(圖S22)。一方面,Tf6OMT和PaNOMT9的整體結構相似,它們的SAM和SAH位置相對接近;然而,這兩種結構有明顯不同的蛋白質折疊(圖S22C)。將Tf6OMT/norlaudanosoline/SAH和PaNOMT9/4/SAM的復合物結構疊加,以比較它們的活性口袋和底物結合構象(圖4F和圖S22C)。構象比較揭示,Tf6OMT和PaNOMT9的活性位點口袋中的底物定向不同(圖4F)。底物4的NH基團與SAM供體的距離相對較近(4.5 ?),而在Tf6OMT復合物中,C-6 OH基團則與SAM供體的距離較近(3.4 ?)。此外,與PaNOMT9和底物3、6、8的對接模擬展示了與4相似的構象(圖S25)。另一方面,與CjCNMT(PDB ID:6GKV)的蛋白質結構相比,非同源的PaNOMT9呈現出完全不同的整體結構,包括SAM和底物結合區域、氫鍵和疏水性殘基的構象,盡管這兩種蛋白質展現出相似的N-甲基化活性。這些結果表明,PaNOMT9在這些區域及其周圍的構象靈活性和可塑性使得底物能夠進行N-甲基化。
PaCYP71BG29在小檗堿橋形成中的新功能化和催化機制
通過同源基因挖掘、系統發育分析和功能實驗,追溯了PaCYP71BG29催化的小檗堿橋形成的起源和進化。系統發育分析表明,來自P. amurense的PaCYP71BG29和另外五個基因、Z. armatum的九個基因以及C. clementina的兩個基因與水稻的OsCYP71P1(序列相似度為46%到58%)聚類在同一分支(圖5A、圖S26和表S7、S8)。進一步與氨基酸序列的比較顯示,PaCYP71BG29與OsCYP71P1(一個色胺5-羥化酶(T5H))具有47%的相似度(34)。
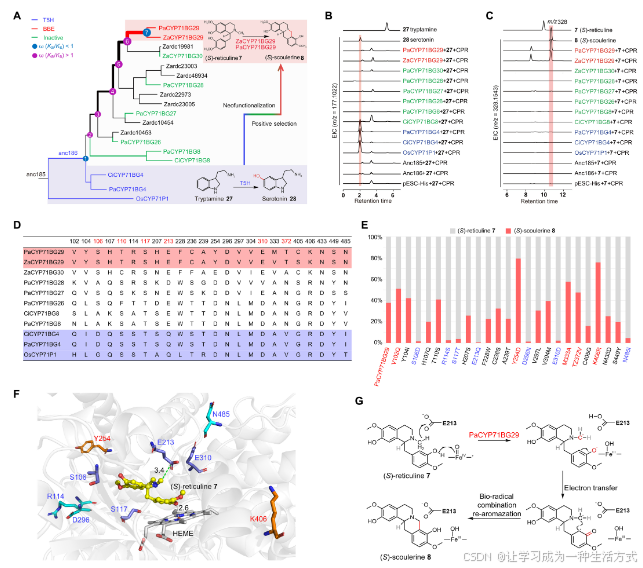
圖5. PaCYP71BG29的新功能化及其催化機制的確定
(A) 基于P. amurense、Z. armatum和C. clementina中PaCYP71BG亞家族成員構建的最大似然系統發育樹。OsCYP71P1作為外群。Ka/Ks是非同義(Ka)與同義(Ks)替代率。 (B) 和(C) 提取離子色譜圖(EIC),表征由候選CYP微粒體和兩個底物——色胺27和(S)-網狀堿7組成的酶促反應生成的化合物。 (D) PaCYP71BG29、ZaCYP71BG29和其他CYP71BG亞家族成員的氨基酸序列比對。展示了24個氨基酸,其中六個位點(紅色標記)與7相距5 ?以內。 (E) 堆疊條形圖展示了PaCYP71BG29及其24個變體對兩個底物的催化偏好:(S)-網狀堿7和(S)-小檗堿8。 (F) PaCYP71BG29/HEME/7的分子對接模型,顯示了那些關鍵殘基,它們增強(紅色)或降低(藍色)催化活性。底物7與關鍵殘基E213和HEME之間的距離分別為3.4和2.6 ?。 (G) 提出了由PaCYP71BG29催化的小檗堿橋形成的機制。
CYP71BG亞家族成員的系統發育樹被分為七個節點(節點1至節點7)。根據系統發育樹,選擇了九個CYP71BG基因及其兩個祖先基因(anc185和anc186)來誘導重組蛋白進行活性測試(圖5B和C)。首先,根據OsCYP71P1的催化活性,使用色胺(27)作為底物進行體外酶促實驗,并選擇OsCYP71P1作為陽性對照。結果顯示,PaCYP71BG4、CiCYP71BG4和OsCYP71P1將色胺27轉化為血清素28(圖5B和圖S27)。此外,實驗表明,祖先CYP71BG基因anc186也編碼T5H,盡管其催化活性較為溫和。相反,P. amurense和Z. armatum基因組中從基因擴展產生的節點2中的CYP719BG候選基因對色胺27沒有羥基化活性(圖5A和B)。 其次,選擇網狀堿7作為底物測試小檗堿橋活性。催化實驗顯示,節點7中的PaCYP71BG29和ZaCYP71BG29表現出了小檗堿橋活性,將(S)-網狀堿7轉化為(S)-小檗堿8(圖5A和C)。相比之下,P. amurense和Z. armatum中其他重復的CYP71BG基因無法催化7到8的轉化。這些結果表明,PaCYP71BG29和ZaCYP71BG29在植物進化過程中發生了新功能化和分化。 最后,使用雙比率分支模型檢測了正向選擇。結果顯示,從節點2到節點6的分支ω值大于1。這些值還表明,PaCYP71BG29和ZaCYP71BG29發生了新功能化。獲得的催化作用負責P. amurense和Z. armatum中小檗堿橋的形成(圖5A)。
為了理解PaCYP71BG29在小檗堿生物合成中的環化酶活性機制,使用(S)-網狀堿7作為配體,通過AlphaFold2完成了對接模擬(圖S28)。通過序列比對進一步選擇了在活躍與不活躍CYP71BG酶中顯著不同的殘基(圖5D)。通過比對選擇了24個不同的殘基,其中六個殘基,包括S106、T110、S117、E203、E310和T372,定位在7周圍5 ?以內(圖5D和圖S29)。這些PaCYP71BG29的殘基接受了一系列的突變,以研究其對T5H功能的貢獻,并測試了使用7作為底物的突變體的活性(進行三次重復實驗;圖5E)。幾個突變體增強了小檗堿橋的形成活性;例如,PaCYP71BG29的突變體Y254D和K406R表現出明顯有效的轉化率,分別為79.4%和75.9%,高于野生型的37.8%。PaCYP71BG29的七個突變體,包括S106D、R114S、S117T、E213Q、D296N、E310D和N485I,幾乎失去了小檗堿橋形成活性,表明它們在將7轉化為8中的關鍵作用(圖5E)。這些變體中的S106D、S117T、E213Q和E310D位于5 ?范圍內,可能會影響底物結合。另一方面,R114S、D296N和N485I這些位于遠離活性中心的變體,可能通過改變蛋白質構象和表面結構來影響PaCYP71BG29的催化活性(圖5F)。基于這些數據,我們提出這些殘基的變化導致了CYP71BG29的新功能化。
PaCYP71BG29/HEME/7的對接模型顯示,關鍵殘基E213的羧基與7的N-甲基基團接近(3.4 ?),而HEME鐵中心則靠近7的C3′-OH基團(2.6 ?)(圖5F)。進一步參考已報告的BBE(35),提出了PaCYP71BG29在小檗堿橋形成中的催化機制:HEME輔因子去質子化C3′-OH基團,增強其親核性,來自N-甲基基團的氫化物轉移到E213,反應中間體的再芳構化導致8的環化反應(圖5G)。因此,盡管迄今為止所有檢查過的Ranunculales植物都使用FAD依賴性氧化酶催化小檗堿橋反應,但Rutaceae科的成員(P. amurense和Z. armatum)可能通過趨同進化出一個獨特的CYP450成員,通過類似的化學機制來介導相同的氧化反應。
討論
盡管小檗堿的生物合成已經在小檗屬植物中得到闡明,但是否其他譜系植物也存在相同的生物合成途徑仍然不清楚。對此問題的回答不僅有助于理解小檗堿的生物合成,還能幫助我們了解不同植物中的多樣化代謝途徑。已報道的小檗屬植物中小檗堿的生物合成包括一個NCS、三個OMTs(6OMT、4′OMT和9OMT)、一個NMT(CNMT)、兩個CYPs(CYP80B和CYP719A)、一個BBE和一個類似BBE的酶(THBO)。在P. amurense基因組中對同源基因的注釋顯示,與小檗屬植物中的基因相比,NCS(33%到37%)、OMTs(26%到49%)、NMT(33%到37%)、CYPs(23%到42%)和BBE基因(29%到57%)的身份非常低(表S9)。此外,在P. amurense中未發現CYP80和CYP719基因。因此,這些特征表明,小檗堿的生物合成途徑在P. amurense和小檗屬植物之間可能存在差異。此外,基于這些特征,我們假設在P. amurense的小檗堿生物合成中可能涉及未知的甲基化和氧化反應機制。以下將通過OMT的N-甲基化和CYP酶的新功能化來驗證這一假設。
本文報告的PaNOMT9的催化活性揭示了一個涉及小檗堿生物合成的雙重甲基化機制。SAM依賴的MTs在植物天然產物多樣化中起著重要作用。以往的研究已表征了將甲基轉移到化合物的S、N、O或C原子上的MT成員,生成甲基化的天然產物(36)。根據S、N、O或C的修飾,MTs已被分類為SMT、NMT、OMT和CMT。迄今為止,BIA生物合成中的MT特異性表明,OMT和NMT成員嚴格地將甲基轉移到C-OH和NH基團上(37)。與此相反,已有報告表明OMT家族的某些II類和III類成員在黃嘌呤和鄰苯二甲酸中都具有O和N-甲基化活性(表S10)(38, 39)。在此,我們的研究數據增加了MT的另一個亞類,NOMTs。來自黃柏(Phellodendron)的PaNOMT2/7/8/9與Coptis的CNMT基因具有相似的催化活性,是首個能夠催化BIA生物合成中N-甲基化的OMT成員。來自P. amurense的與小檗堿生物合成相關的NOMT基因(PaNOMT2/7/8/9)與OMT家族II類亞家族呈姊妹群(圖S30A)。NOMT基因的系統發育分支包含來自P. amurense和Z. armatum的大量串聯重復基因,且僅在柑橘中觀察到一個同源基因(CiOMT2),與PaNOMT2/7/8/9的序列同源性為64%到66%(圖S30B和S31)。我們的催化實驗表明,CiOMT2不能對底物4執行N-甲基化活性(圖S30B),表明N-甲基化功能的獲得是在它們與柑橘的分離后演化而來的。PaNOMT9的N-甲基化催化機制與已報道的BIA OMT或NMT酶有所不同,提供了有價值的信息,有助于加深對BIA結構甲基化的理解,并推動潛在BIA藥物的代謝工程。
本文報告的PaCYP71BG29的小檗堿橋形成活性揭示了植物專用代謝產物生物合成中來自非同源酶的相同催化活性,這是一個先前未曾發現的案例。在以往的研究中,Ranunculales超家族中的FAD依賴性氧化酶BBE,如小檗、罌粟、千屈菜和小檗屬等植物的BBE在小檗堿生物合成中的小檗堿橋形成中起著保守作用(21, 40-42)。然而,來自P. amurense基因組的PaBBE基因僅有一個,與Ranunculales植物的BBE聚成同一分支。此外,基因表達分析顯示,PaBBE在所有測試的P. amurense組織中都是沉默的(圖S32)。這一數據表明,這種藥用植物中可能存在未知的機制。為了驗證這一點,我們挖掘了基因組和轉錄組序列,揭示了與小檗堿積累模式相關的CYP71BG成員。比較基因組分析發現,一方面,Ranunculales基因組中沒有注釋CYP71BG成員;另一方面,這些基因來自基因組擴展。這些數據為PaCYP71BG29催化的小檗堿橋形成和生物合成步驟提供了證據,表明這可能是P. amurense獨立進化的結果。此外,我們的生化實驗顯示,CYP71BG酶參與了與植物發育和應激反應相關的植物胺血清素和褪黑激素的生物合成。系統發育分析表明,CYP71BG成員的明顯擴展和正向選擇導致了Phellodendron中CYP71BG29的新功能化。
9OMT(PaOMT1)和BBE(CYP71BG29)在黃柏染色體8上形成一個生物合成基因簇,該基因簇進一步經歷了WGD1和WGD2事件,擴展了N-甲基化的PaNOMT7和PaNOMT9(圖S33),這與小檗屬植物中小檗堿生物合成基因的分散分布不同。此外,4′OMT(PaOMT3)和6OMT(PaOMT4和PaOMT5)在染色體20上聚集在一起,WGD事件也加速了共線性OMT的擴展。我們還發現,小檗堿生物合成基因在黃柏和花椒中是保守的,CYP450和OMT基因的重復和新功能化發生在它們與柑橘分開之后(圖S33)。小檗堿生物合成基因簇及其重復事件擴展了我們對代謝基因簇形成和獨立進化的理解(43)。
植物專用代謝物被視為復雜性狀,可以通過研究其進化軌跡來理解(44)。相同的代謝特征經常在遠緣物種中獨立進化出現,包括平行進化和趨同進化。例如,金絲菊和大麻中由同源酶催化的大麻素生物合成的平行進化(45)。盡管多項研究已報道了咖啡因(39)、藏紅花色素(46)和稻米乳酸酮(47)生物合成的趨同進化,但它們在不同譜系中的生物合成酶可能具有同源關系。參照平行進化和趨同進化的區別(48),我們的研究展示了一個經典的趨同進化案例,在兩個遠緣譜系中——小檗屬和黃柏,兩個完全非同源的酶和不同的蛋白質折疊,尤其是具有NMT催化功能的OMT基因和具有小檗堿橋酶活性的CYP450基因。這些數據表明,酶的新功能化是推動結構修飾和多樣化的驅動力。
總之,我們報告了黃柏的高質量基因組,并解密了一個替代的小檗堿生物合成途徑,特別是識別了N-甲基化OMT基因和由CYP450催化的小檗堿橋活性。所識別的小檗堿生物合成步驟來源于WGD事件和新功能化。這些發現揭示了小檗屬和黃柏物種中小檗堿生物合成的趨同進化模型。此外,我們的研究增強了我們對小檗堿生物合成酶的理解,為工程化具有多種藥理活性的復雜BIA藥物提供了支持。
材料與方法
植物材料與化學標準
黃柏(P. amurense)植物生長在中國哈爾濱東北林業大學的研究站內。新鮮的黃柏葉片被收集后迅速放入液氮中,并儲存于-80°C冰箱中以供基因組測序。新鮮的黃柏根部被收集并分成兩個部分,一個部分在液氮中冷凍用于代謝物提取,另一個部分用于MSI(MALDI-MSI)分析。其他16種植物的根和/或莖,以及荷花(N. nucifera)的干蓮子芽也被收集用于代謝分析(表S1)。所有化學標準如表S11所列,均從不同公司購買。
代謝物的LC-MS分析
所有樣品(含三次重復)在50°C下烘干后,研磨成細粉,并通過60目篩過濾。稱取200 mg細粉放入15 ml玻璃管中,加入10 ml甲醇:水混合液(6:4,v/v),并漩渦混合1分鐘。然后在室溫下靜置過夜,并在超聲波清洗機(240 W、40 Hz)中超聲處理40分鐘。玻璃管在9000g下離心10分鐘,收集上清液中的代謝物,轉移到清潔管中用于代謝物分析。接著,超聲清洗后的上清液再次在12,000g下離心10分鐘,所得的干凈上清液轉移至1.5 ml管中,并通過0.22 μm濾膜過濾。
樣品通過SHIMADZU UPLC-QTOF-MS系統進行檢測(LCMS-9030),配有SHIMADZU GIST C18色譜柱(2 μm,2.1 mm x 100 mm)。流動相由0.1%甲酸水溶液(A)和乙腈(B)組成,線性梯度洗脫程序如下:0到1分鐘,15% B;1到8分鐘,15%到45% B;8到10分鐘,45%到80% B;10到11分鐘,80%到15% B;11到14分鐘,15% B。流速為0.2 ml/min,柱溫為40°C。質譜儀在數據依賴采集模式下操作,電噴霧電離(ESI)源在正離子模式下運行(m/z 100到700)。氣體溫度維持在400°C,氣體流量為10升/分鐘,碎片電壓設置為120 V,碰撞能量為20到40 eV。
MALDI成像
黃柏的冷凍根部被包裹在5%的羧甲基纖維素(w/v)中,然后使用干冰將其固化為塊狀。冷凍根部在-20°C下被切割成30 μm厚的切片,切片立即粘附于涂有銦錫氧化物的玻片上以供后續成像分析。與此同時,將60 mg 2,5-二羥基苯甲酸(DHB)溶解在2 ml甲醇和水的混合液中(含0.1%三氟乙酸),比例為7:3(v/v)(49)。所得的DHB溶液用于正模式MALDI實驗。所有測量使用與Orbitrap質譜儀(“Q Exactive”,Thermo Fisher Scientific,德國不來梅)耦合的AP-SMALDI離子源(“AP SMALDI10”,TransMIT GmbH,德國吉森)進行。簡而言之,使用固態激光(λ = 343 nm),重復頻率為2000 Hz,用于在正離子模式下分析樣品。使用DHB矩陣增加電離效率。全掃描模式下的測量速率(掃描范圍m/z 150到1400)約為1.5秒/像素,質量分辨率為70,000,分辨率對應m/z 200時的質量精度為2 ppm。MSI分析的空間分辨率為30 μm。數據分析使用MirionV3軟件進行。
基因組測序、調查與組裝
使用DNeasy Plant Mini Kit(QIAGEN,德國)從冷凍葉片中提取高質量基因組DNA樣品。通過NanoDrop分光光度計(Thermo Fisher Scientific,美國)評估和測量DNA樣品的質量和數量。DNA樣品被消化為20-kb大小。然后,使用SMRTbell模板準備試劑盒構建DNA文庫。簡要而言,根據制造商的協議,DNA文庫構建步驟包括DNA濃縮、損傷修復、末端修復、發夾接頭連接和模板純化。基因組測序的環狀共識測序數據是在PacBio Sequel II平臺(Pacific Biosciences,美國)上產生的,遵循制造商的協議。所獲得的DNA序列用于下面描述的基因組組裝。所有比較包括三次獨立的生物學重復實驗。 從冷凍葉片、莖和根中提取總RNA樣品,使用RNAprep Pure Plant Kit(TIANGEN,中國)。隨后,使用Qubit RNA Assay Kit和Agilent 2100 Bioanalyzer(Agilent Technologies)評估RNA樣品的質量。RNA測序在Novogene使用Illumina HiSeq 2500平臺進行,以生成150-bp配對末端讀段。使用ProximoTM Hi-C Plant試劑盒從P. amurense的新鮮葉片中構建了Hi-C文庫。cDNA文庫在Illumina HiSeq平臺上進行測序,生成150-bp的長讀段。使用Illumina數據根據K-mer分布分析(K = 21)估算P. amurense的基因組大小。過濾PacBio Sequel讀段以去除短的和低質量的讀段。結果高質量的讀段用于使用Hifisam(v0.19.5)進行de novo組裝,采用默認參數(50)。使用Purge_dups(v1.2.5)(51)去除組裝的contig序列的雜交。使用ALLHiC(v0.9.8)(52)根據Hi-C數據生成一個支持等位基因的染色體級基因組。
基因注釋與質量評估
基因注釋通過de novo預測、同源蛋白證據和EST證據方法完成。組裝后,RNA測序(RNA-seq)數據通過HISAT2(v2.2.1)(53)映射到基因組上。對于ab initio預測,AUGUSTUS模型通過BRAKER2(v2.1.5)(54)使用RNA-seq數據訓練。此外,結合同源證據的ab initio預測與MAKER管道結合,生成最終的基因模型。使用BUSCO(v5.2.2)(55)和embryophyta_odb10數據庫評估基因組的完整性。注釋后,使用Tandem Repeat Finder(v4.07)(56)預測串聯重復。LTR_retriever(v2.6)(57)、LTR_FINDER(v1.0.6)(57)和RepeatModeler(v2.0)用于構建重復序列數據庫。對于de novo預測,生成的LTR和通過RepeatModeler生成的共識重復文庫被合并,并作為RepeatMasker的輸入數據。
比較基因組分析
使用P. amurense和其他14個已測序植物物種(包括Z. armatum(58, 59)、Murraya exotica(60)、C. clementina(61)、Atalantia buxfoliata(62)、Melia azedarach(63)、Pistacia vera(64)、Acer yangbiense(65)、V. vinifera(66)、Macleaya cordata(67)、C. chinensis(15)、Annona cherimola(68)和一個外群物種[Amborella trichopoda;(69)]的同源基因組群進行系統發育分析。使用OrthoFinder(v2.3.11)(70)獲得15個物種中的單拷貝家族,采用默認參數。通過RAxML(v8.0.17)(70)使用最大似然方法并進行1000次自舉重復,構建了包含221個單拷貝同源基因的系統發育樹。使用PAML(v4.9)(71)中的MCMCTREE估計15個物種之間的分歧時間,校準點來自TimeTree數據庫(www.timetree.org)。校準點包括P. amurense和C. clementina之間的分歧(25到69百萬年)、M. azedarach與P. vera(63到105百萬年)、A. yangbiense與V. vinifera(110到124百萬年)、A. cherimola與A. trichopoda(180到205百萬年)。 使用CAFE(v4.2.1)(72)分析了基因家族的擴展與收縮。基于Gene Ontology和京都基因與基因組百科全書數據庫,使用R包ClusterProfiler(v4.0)(73)分析了擴展基因家族的功能富集。
WGD分析
使用MCScan(Python版本)和默認參數建立基因組內和基因組間的同源區塊。基于檢測到的同源基因對識別同源區塊,并使用Whole-Genome Duplication Identifier(WGDI)管道(v0.6.5)(74)估算共線基因之間的Ks值。此外,為了檢測P. amurense基因組中可能的多倍體化遺跡,使用MCScan識別了P. amurense、Z. armatum和C. clementina基因組內的同源基因區塊。基于C. clementina基因組提取每個區塊的共線基因,并使用IQ-TREE2(v2.2.2.7)(75)構建共線基因樹。基因樹作為輸入上傳到ASTRAL(v5.6.1)(76),推斷子基因組系統發育。最后,使用ksrates包(GitHub - VIB-PSB/ksrates: ksrates is a tool to position whole-genome duplications relative to speciation events using substitution-rate-adjusted mixed paralog-ortholog Ks distributions.)根據調整后的混合圖追蹤平行基因和同源基因的Ks分布,追蹤WGD事件。
候選基因的鑒定與相關性分析
報告中的生物堿(BIA)生物合成基因,包括NCS、MTs和CYP450,被選作查詢序列,并通過BLASTp在P. amurense、Z. armatum和C. clementina基因組中進行同源基因的鑒定,E值為1 × 10?10。簡而言之,選用Papaver somniferum中的PsNCS1(AAX56303.1)和PsNCS2(AAX56304.1)、C. japonica中的CjNCS(BAF45338.2)、T. flavum中的TfNCS(ACO90248.1)作為查詢序列,鑒定候選的NCS編碼基因。P. somniferum中的Ps6OMT(AAQ01669.1)以及C. japonica中的Cj6OMT(BAB08004.1)、Cj4′OMT(BAB08005.1)和Cj9OMT(BAA06192.1)作為查詢序列,用于鑒定OMTs的同源基因。C. japonica中的CjNMT(AB061863.1)作為查詢序列,用于鑒定NMTs。C. japonica中的CjCYP719A1(BAB68769.1)、CjCYP80B2(BAB12433.1)、CjCYP80G2(BAF80448.1)、P. somniferum中的PsCYP80B1(AAF61400.1)和PsCYP719B1(ABR14720.1)、Berberis stolonifera中的BsCYP80A1(AAC48987.1)作為查詢序列,根據命名規則鑒定候選的CYP450亞家族(身份比> 55%)。
基于P. amurense的轉錄組(PRJNA859281)和代謝組數據,利用候選基因的標準化表達水平與berberine的含量水平,分析了Pearson相關系數(r)。篩選出與候選MTs和CYP450s基因表現出高相關性(r > 0.8)的基因用于功能驗證。然后,進一步選擇功能基因作為誘餌,通過共表達分析選擇額外的候選基因。
MTs基因在大腸桿菌中的異源表達與功能驗證
候選的MT基因被克隆或合成,并克隆到pET-28a載體中(見表S12)。隨后,將得到的陽性重組質粒導入大腸桿菌BL21(DE3)菌株。每個載體的陽性克隆都被選中并誘導重組蛋白的表達。開發了一種通用協議來表達每個候選基因并生產其重組蛋白。選中陽性克隆,接種20 ml含有50 μg/ml卡那霉素的液體Luria-Bertani(LB)培養基中,放置于250 rpm/min、37°C的搖床上。當細胞懸液的光密度(OD600)達到0.6時,加入異丙基-β-d-硫代半乳糖苷(IPTG;0.3 mM)以誘導蛋白表達。加入IPTG后,將培養箱溫度設為16°C。培養過夜后,通過離心(8000g,5分鐘,4°C)收獲細胞。將沉淀重懸于1 ml含有50 mM tris-HCl緩沖液(pH 7.4)、10%(v/v)甘油和5 mMβ-巰基乙醇的溶液中。通過超聲破碎冰上培養5分鐘。將裂解液以8000g離心10分鐘,收集上清液并存儲于?20°C進行酶活性檢測。
為了純化候選的重組蛋白,增大了每個重組載體的大腸桿菌培養體積至100 ml LB培養基。其他條件保持一致。將沉淀重懸于30 ml裂解緩沖液(pH 8.0;50 mM NaH2PO4,30 mM NaCl和10 mM咪唑)中。提取步驟與小規模提取相同。得到的30 ml上清液加載到Ni-NDA柱(Ni-NDA Beads,Smart-Lifesciences,中國)上進行重組蛋白純化。為結晶純化進一步使用凝膠過濾色譜法(與150 mM NaCl和20 mM Hepes,pH 8.0平衡)進一步純化蛋白,最終通過Amicon Ultra-15 Ultracel-30 K離心過濾器(Merck Millipore)濃縮蛋白。使用蛋白定量試劑盒(TransGen Biotech,中國)測定蛋白濃度,并通過SDS-聚丙烯酰胺凝膠電泳(SDS-PAGE)評估純度。
MTs的酶活性在37°C、200 rpm搖動下的100 μl反應體系中進行過夜反應,反應體系包括Gly緩沖液(pH 9.0),10 μg純化蛋白,2 mM SAM,底物(S)-norcoclaurine、(S)-coclaurine或(S)-scoulerine,濃度為50 μg/ml,或3′-hydroxy-N-methylcoclaurine,濃度為20 μg/ml,反應結束后加入50%甲醇(v/v)終止反應。選擇Cc6OMT、Cc4′OMT、Cc9OMT、CcNMT作為陽性對照,空載體作為陰性對照。
通過超高效液相色譜-串聯質譜(UPLC-MS/MS)檢測反應樣本。UPLC-MS/MS系統(SCIEX TripleTOF 6600+)配備三重四極體-線性離子阱質譜儀。簡而言之,1 μl提取液注入后,使用Kinetex C18 100A分析柱(4.6 mm×150 mm,2.6 μm)進行分離,柱溫設為35°C。流動相包括A相(0.1%甲酸)和B相(乙腈)。梯度程序如下:0至1分鐘,10%B;1至10分鐘,10至95%B;12.3至13分鐘,95%B;13至15分鐘,95至10%B,流速為0.5 ml/min。質譜儀工作在多重反應監測模式下,掃描時間為每個轉移35 ms。質譜儀的參數設置如下:正離子模式ESI模式;噴霧電壓為3.5 kV;噴霧溫度為550°C;氣簾氣體為35 psi;GAS1為40 psi,GAS2為60 psi。
S. cerevisiae中CYP450基因的異源表達與功能驗證
為了驗證候選CYP450的活性,選擇了轉基因的釀酒酵母Saccharomyces cerevisiae WAT11(包含擬南芥細胞色素P450還原酶AtCPR1)作為異源表達宿主。候選CYP450基因被克隆或合成,并克隆到pESC-His載體中(引物見表S12),然后轉入S. cerevisiae WAT11中。篩選陽性酵母菌落表達CYP450蛋白。經過培養和誘導后,酵母細胞被收獲、破碎并進行差速離心,得到微粒體,具體操作參考之前的研究。
對于酶活性檢測,選擇表達pESC-His空載體的酵母作為陰性對照。反應體系包括200 μl微粒體、0.5 mM還原型煙酰胺腺嘌呤二核苷酸磷酸和1 μl底物(1 mg/ml),在30°C下孵育2小時。反應樣本經過離心和過濾后,使用Agilent UPLC-QTOF-MS檢測。UPLC-QTOF-MS系統配備ACQUITY UPLC HSS-T3 C18柱(1.8 μm,2.1 mm×100 mm),流動相包括水中0.1%甲酸(A)和乙腈(B),線性梯度洗脫程序如下:0至2分鐘,5%B;2至10分鐘,5至18%B;10至15分鐘,18至95%B;15至17分鐘,95%B。流速設為0.3 ml/min,柱溫設為40°C。質譜儀使用Agilent 6430 QTOF,工作在正離子模式下,掃描范圍為m/z 100到800,氣體溫度保持在350°C,氣流速率為8升/分鐘,碎片電壓設置為120 V,碰撞能量為20 eV。
PaCYP71BG29在本氏煙草中的瞬時表達
為了進一步驗證PaCYP71BG29在體內的功能活性,該基因被克隆至pEAQ-eGFP載體中,并轉化至根癌農桿菌(Agrobacterium tumefaciens,GV3101)。陽性克隆在10 ml含有卡那霉素和利福平的LB培養基中培養。培養物以5000g離心5分鐘,沉淀重懸于滲透緩沖液(10 mM MES緩沖液、10 mM MgCl?和150 μM乙酰香豆素),并在28°C黑暗條件下孵育1小時。將Agrobacterium懸液(每個菌株OD600為0.3至0.6)滲透入5至6周齡的本氏煙草葉片。3天后,將底物5和7(50 μM,溶解于0.1%二甲基亞砜水溶液中)滲透入先前經根癌農桿菌滲透的葉片背面。1天后,收集葉片進行LC-MS/MS分析。生物學重復包括從三條不同基因型中收集的三至四片葉子。使用空載體滲透的葉片和無底物的候選基因作為對照。
PaNOMT9的結晶與突變分析
為了對PaNOMT9/4/SAM復合物進行結晶,純化的PaNOMT9蛋白(20 mg/ml)與5 mM(S)-coclaurine(4)和5 mM SAM共同孵育。然后,通過靜滴氣相擴散法在4°C下生長晶體。沉淀劑井液由20% w/v PEG1000、100 mM硫酸鋰一水合物和100 mM檸檬酸三鈉二水合物(pH 5.5)組成。晶體逐漸轉移到含有25%甘油的沉淀劑井液中,然后在液氮中快速冷凍以存儲。所有數據集均在上海同步輻射光源(SSRF)BL18U1束流線的低溫條件下(100 K)收集,結構通過分子置換法使用搜索模型6I70進行求解。然后使用Phenix軟件進行模型優化(77),并在Coot軟件中手動建模(78)。最終結構的優化結果顯示,工作R因子(Rwork)為15.9%(自由R因子Rfree = 19.3%),幾何學良好(見表S13)。
通過基因拼接重疊擴增PCR方法構建了PaNOMT9中選定殘基的突變體,并使用底物4進行突變體活性測試(進行三次重復)。







:將域名郵箱添加至Outlook客戶端)




![2025年滲透測試面試題總結-騰訊[實習]科恩實驗室-安全工程師(題目+回答)](http://pic.xiahunao.cn/2025年滲透測試面試題總結-騰訊[實習]科恩實驗室-安全工程師(題目+回答))




)

