1. 預訓練的通俗理解:AI的“高考集訓”
我們可以將預訓練(Pre-training) 形象地理解為大模型AI的“高考集訓”。就像學霸在高考前需要刷五年高考三年模擬一樣,大模型在正式誕生前,也要經歷一場聲勢浩大的“題海戰術”。
這個“題海戰術”的核心就是將海量的文本、圖片、視頻等數據“喂”給AI。通過這種大規模的數據投喂,AI會進行自監督學習,瘋狂地吸收知識,自主挖掘數據中的內在規律和模式。最終,通過這個過程,AI才能煉成能寫詩、能看病、會作畫的全能大腦。

2. 預訓練的技術定義:構建基礎認知能力
從技術角度來看,預訓練是指在AI模型應用于特定任務之前,先利用海量無標注數據,讓模型自主挖掘語言、視覺、邏輯等方面的通用規律,從而構建其基礎認知能力的訓練過程。
通過從大規模未標記數據中學習通用特征和先驗知識,預訓練能夠顯著減少模型對標記數據的依賴。這不僅能夠加速模型在有限數據集上的訓練過程,還能在很大程度上優化模型的性能,使其在后續的下游任務中表現更出色。
預訓練的核心邏輯與關鍵操作
預訓練過程并非簡單的數據堆砌,其背后包含了一系列精妙的核心邏輯和技術操作。
1. 數據投喂:構建AI的“知識庫”
高質量、多樣化、大規模的數據集是預訓練的基石。
- 海量數據抓取與投喂:
- 文本數據: 包括書籍、網頁、論文、對話記錄、代碼、新聞文章等。例如,GPT-3的訓練數據包含了Common Crawl、WebText2、Books1、Books2、Wikipedia等海量語料。
- 圖像數據: 帶有
alt標簽的圖片(用于圖像描述)、視頻幀、圖像-文本對等。例如,CLIP模型就通過大量的圖像-文本對進行預訓練。 - 結構化數據: 如知識圖譜、表格數據等,用于增強模型的邏輯推理和事實性知識。
- 數據清洗與過濾: 在數據投喂前,必須進行嚴格的清洗和過濾,以確保數據質量。這包括剔除亂碼、重復內容、低質量內容、以及涉及黃賭毒等不合規內容。數據質量直接影響模型的學習效果和泛化能力。
- Tokenizer分詞: 對于文本數據,需要通過Tokenizer(分詞器) 將原始文本切分成AI能夠理解的“單詞積木”,即Token。Token可以是單詞、子詞或字符,其目的是將連續的文本轉化為離散的數值表示。
- 關鍵操作: 構建一個量級在50k-100k的詞表(Vocabulary)。例如,像
"深度"和"學習"這樣的詞匯可能會被分別編碼,而"深度學習"這個短語則可能被作為一個獨立的Token進行編碼,從而更好地捕捉語義信息。常用的分詞算法包括BPE (Byte Pair Encoding)、WordPiece和SentencePiece。
- 關鍵操作: 構建一個量級在50k-100k的詞表(Vocabulary)。例如,像
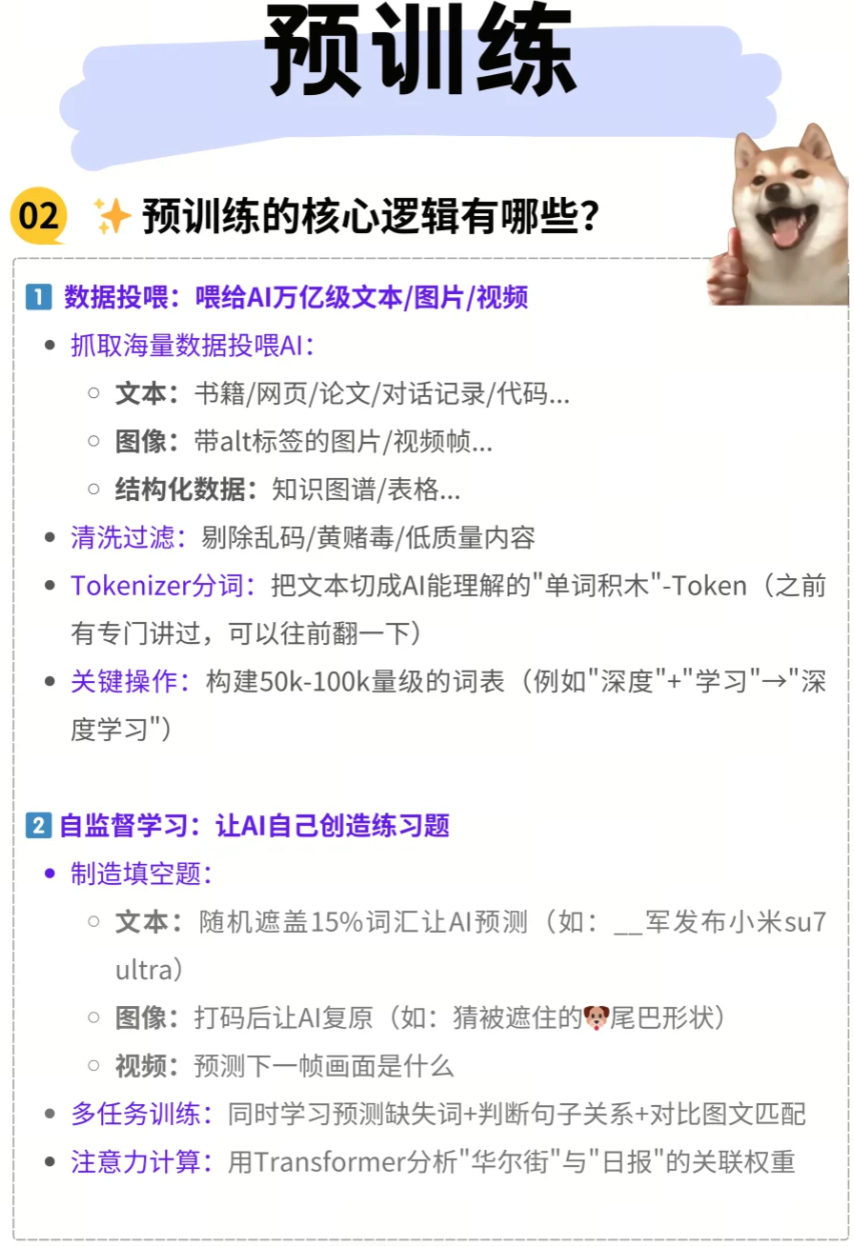
2. 自監督學習:讓AI“自己創造練習題”
自監督學習(Self-supervised Learning) 是預訓練的核心機制,它允許模型在沒有人工標注的情況下,從大規模數據中學習有用的表示。
- 制造“填空題”: 模型通過預測數據中缺失的部分來學習。
- 文本領域(如BERT的MLM任務): 隨機遮蓋文本中15%的詞匯(Token),然后讓AI預測被遮蓋的詞。例如,在句子
"__軍發布小米su7 ultra"中,模型需要預測出"小"字。這種機制迫使模型理解上下文語境和詞匯間的關系。 - 圖像領域(如MAE): 隨機遮蓋圖像的部分區域(打碼),然后讓AI復原被遮蓋的像素或特征。例如,
"猜被遮住的🐶尾巴形狀",模型需要根據未被遮蓋的部分推斷出尾巴的形態。 - 視頻領域: 預測視頻的下一幀畫面是什么,或預測被遮蓋的幀內容。這有助于模型學習時序信息和運動模式。
- 文本領域(如BERT的MLM任務): 隨機遮蓋文本中15%的詞匯(Token),然后讓AI預測被遮蓋的詞。例如,在句子
- 多任務訓練: 為了讓模型學習更全面的能力,預訓練通常會包含多個自監督任務。
- 文本: 除了預測缺失詞,還可能包含下一句預測(NSP) 任務,即判斷兩個句子之間是否存在前后關系。
- 圖像與文本: 學習圖文匹配,讓模型判斷圖像和文本描述是否匹配,從而理解多模態信息。
- 注意力計算(Transformer): 在預訓練過程中,Transformer 架構的自注意力機制(Self-Attention) 至關重要。它允許模型在處理序列數據時,動態地計算不同部分之間的關聯權重。例如,在分析
"華爾街日報"時,模型能夠計算"華爾街"和"日報"這兩個詞之間的關聯權重,從而理解其作為一個整體的特定含義。
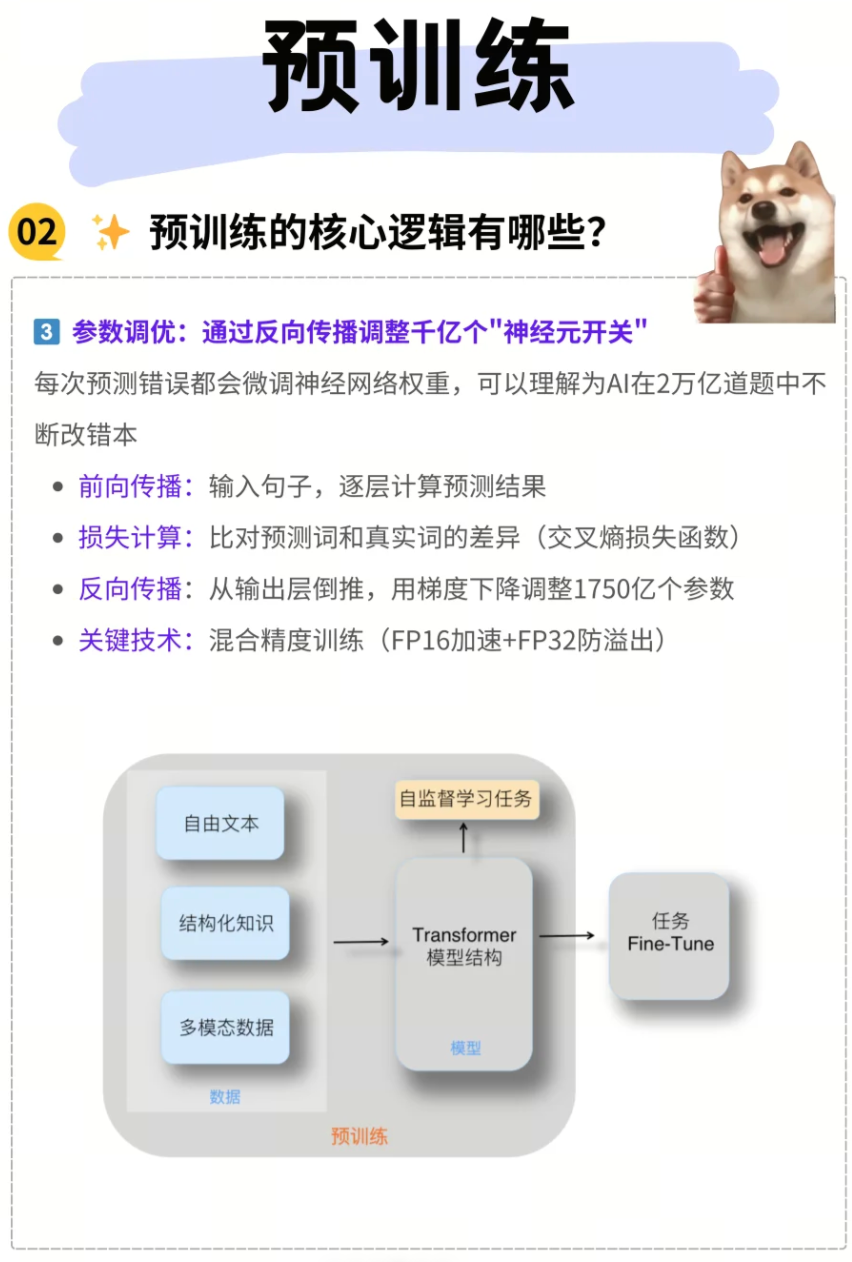
3. 參數調優:微調千億個“神經元開關”
反向傳播(Backpropagation) 和梯度下降(Gradient Descent) 是模型優化的核心算法。
- 誤差糾正與權重調整: 每次模型進行預測后,都會將預測結果與真實值進行比較,計算出損失(Loss)。這個損失值通過反向傳播算法,用于微調神經網絡中數千億個參數(權重)。
- AI的“改錯本”: 可以把這個過程理解為AI在面對數萬億道題目時,不斷地批改自己的“錯題本”。每當預測錯誤時,模型就會根據錯誤程度和方向,對內部的“神經元開關”(即參數)進行細微調整,以期在下一次預測中做得更好。這個迭代優化的過程,使得模型能夠逐步收斂,并學到更精確的特征表示。
相關推薦
-
2025大模型技術架構揭秘:GPT-4、Gemini、文心等九大模型核心技術對比與實戰選型指南-CSDN博客
-
💡大模型中轉API推薦
-
?中轉使用教程
技術交流:歡迎在評論區共同探討!更多內容可查看本專欄文章,有用的話記得點贊收藏嚕!










)




)




)