smolvlm-realtime-webcam 是一個開源項目,結合了輕量級多模態模型 SmolVLM 和本地推理引擎 llama.cpp,能夠在本地實時處理攝像頭視頻流,生成自然語言描述,?開源項目地址
https://github.com/ngxson/smolvlm-realtime-webcam![]() https://github.com/ngxson/smolvlm-realtime-webcam需要依賴https://github.com/ggml-org/llama.cpp/releases/tag/b5581
https://github.com/ngxson/smolvlm-realtime-webcam需要依賴https://github.com/ggml-org/llama.cpp/releases/tag/b5581![]() https://github.com/ggml-org/llama.cpp/releases/tag/b5581但是問題來了,如果直接下載現成的llama-b5581-bin-ubuntu-arm64.zip?,
https://github.com/ggml-org/llama.cpp/releases/tag/b5581但是問題來了,如果直接下載現成的llama-b5581-bin-ubuntu-arm64.zip?,
下載命令資源后會提示
Illegal instruction
需要自己編譯一下https://github.com/ggml-org/llama.cpp?才可以在rk3588上運行
Build llama.cpp locallyThe main product of this project is the llama library. Its C-style interface can be found in include/llama.h.The project also includes many example programs and tools using the llama library. The examples range from simple, minimal code snippets to sophisticated sub-projects such as an OpenAI-compatible HTTP server.To get the Code:git clone https://github.com/ggml-org/llama.cpp
cd llama.cppThe following sections describe how to build with different backends and options.
CPU BuildBuild llama.cpp using CMake:sudo apt install curl
sudo apt install libcurl4-openssl-dev
cmake -B build
cmake --build build --config Release在rk3588上大約要編譯個十來分鐘,算是大工程了。最后生成的文件在
/build/bin中
運行試一下,要用代理下載哦
export http_proxy=http://你的代理IP:端口
export https_proxy=http://你的代理IP:端口./llama-server -hf ggml-org/SmolVLM-500M-Instruct-GGUF最后出現
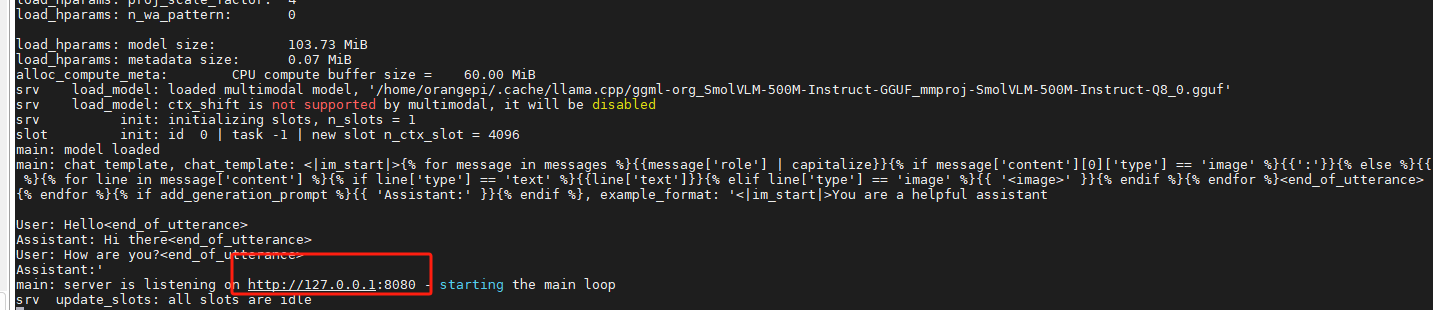
?
就表示成功了,這時運行,https://github.com/ngxson/smolvlm-realtime-webcam.git?工程中的index.html就會打開攝像頭
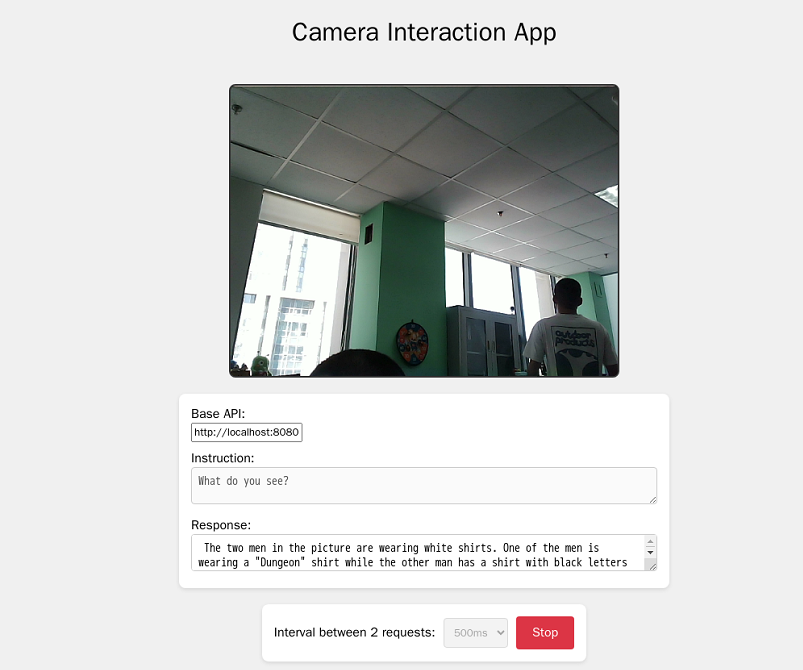
?另外這個缺省的模型對中文不太友好,可以換成 中文的,但是速度就不太行了,推薦在有gpu的情況下使用。
# Gemma 3
(tool_name) -hf ggml-org/gemma-3-4b-it-GGUF
(tool_name) -hf ggml-org/gemma-3-12b-it-GGUF
(tool_name) -hf ggml-org/gemma-3-27b-it-GGUF# SmolVLM
(tool_name) -hf ggml-org/SmolVLM-Instruct-GGUF
(tool_name) -hf ggml-org/SmolVLM-256M-Instruct-GGUF
(tool_name) -hf ggml-org/SmolVLM-500M-Instruct-GGUF
(tool_name) -hf ggml-org/SmolVLM2-2.2B-Instruct-GGUF
(tool_name) -hf ggml-org/SmolVLM2-256M-Video-Instruct-GGUF
(tool_name) -hf ggml-org/SmolVLM2-500M-Video-Instruct-GGUF# Pixtral 12B
(tool_name) -hf ggml-org/pixtral-12b-GGUF# Qwen 2 VL
(tool_name) -hf ggml-org/Qwen2-VL-2B-Instruct-GGUF
(tool_name) -hf ggml-org/Qwen2-VL-7B-Instruct-GGUF# Qwen 2.5 VL
(tool_name) -hf ggml-org/Qwen2.5-VL-3B-Instruct-GGUF
(tool_name) -hf ggml-org/Qwen2.5-VL-7B-Instruct-GGUF
(tool_name) -hf ggml-org/Qwen2.5-VL-32B-Instruct-GGUF
(tool_name) -hf ggml-org/Qwen2.5-VL-72B-Instruct-GGUF# Mistral Small 3.1 24B (IQ2_M quantization)
(tool_name) -hf ggml-org/Mistral-Small-3.1-24B-Instruct-2503-GGUF# InternVL 2.5 and 3
(tool_name) -hf ggml-org/InternVL2_5-1B-GGUF
(tool_name) -hf ggml-org/InternVL2_5-4B-GGUF
(tool_name) -hf ggml-org/InternVL3-1B-Instruct-GGUF
(tool_name) -hf ggml-org/InternVL3-2B-Instruct-GGUF
(tool_name) -hf ggml-org/InternVL3-8B-Instruct-GGUF
(tool_name) -hf ggml-org/InternVL3-14B-Instruct-GGUF# Llama 4 Scout
(tool_name) -hf ggml-org/Llama-4-Scout-17B-16E-Instruct-GGUF# Moondream2 20250414 version
(tool_name) -hf ggml-org/moondream2-20250414-GGUF
使用下面的模型就可以返回中文了?
?llama-server -hf ggml-org/Qwen2.5-VL-3B-Instruct-GGUF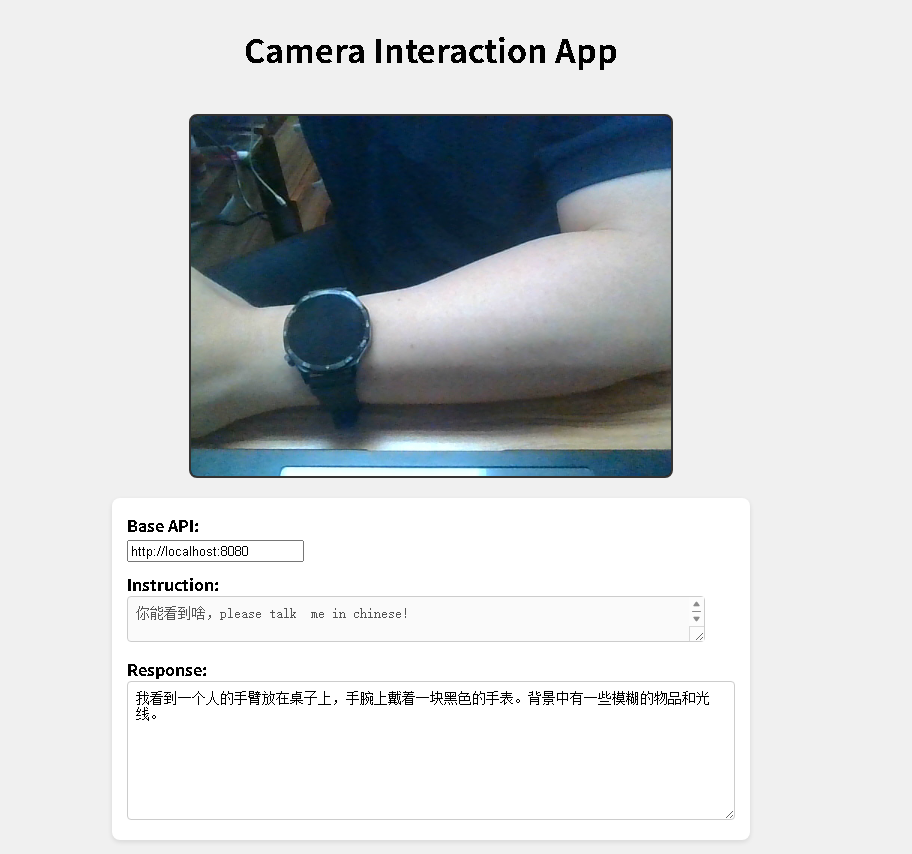
smolvlm-realtime-webcam 是一個開源項目,結合了輕量級多模態模型 SmolVLM 和本地推理引擎 llama.cpp,能夠在本地實時處理攝像頭視頻流,生成自然語言描述。?
🧠 項目概述
-
實時圖像理解:通過調用攝像頭,項目將捕獲的圖像發送到本地運行的 llama.cpp 服務器,使用 SmolVLM 模型進行處理,返回對圖像的自然語言描述。
-
輕量級部署:SmolVLM 模型參數量在 256M 到 500M 之間,設計上優化了計算效率,適合在資源受限的設備上運行。
-
本地運行,無需聯網:所有處理均在本地完成,增強了隱私保護,降低了部署門檻?
🚀 實際用途
-
輔助視覺障礙者:為視力受限人士提供實時的環境描述,增強其獨立性。
-
智能家居監控:識別家中異常情況,如寵物行為、火災跡象等,提升家庭安全。
-
教育與學習:在教學中實時描述實驗過程或自然現象,增強學習體驗。
-
工業質量控制:在生產線上實時檢測產品缺陷,提高生產效率。
-
機器人視覺系統:為機器人提供實時環境理解,提升其自主導航和操作能力。
🌈 創意擴展
-
實時字幕生成:為視頻或直播內容生成實時字幕,提升可訪問性。
-
個性化虛擬助手:結合語音識別和圖像理解,創建更智能的個人助手。
-
增強現實(AR)應用:在 AR 設備中實時識別和標注現實世界中的物體,增強用戶體驗。
-
藝術創作工具:將實時圖像描述轉化為詩歌或故事,激發創作靈感。
-
環境數據收集:在野外部署設備,實時記錄和描述自然環境變化,用于科研。
🔧 快速上手
-
安裝 llama.cpp:按照官方指南編譯并運行 llama.cpp。
-
下載 SmolVLM 模型:獲取適用于 llama.cpp 的 SmolVLM 模型文件。
-
運行服務器:啟動 llama.cpp 服務器,并加載 SmolVLM 模型。
-
啟動前端界面:打開項目中的
index.html文件,連接攝像頭,開始實時描述。
該項目展示了在本地設備上實現實時多模態 AI 應用的可能性,為邊緣計算和隱私保護提供了新的解決方案。
)





![瀏覽器工作原理06 [#]渲染流程(下):HTML、CSS和JavaScript是如何變成頁面的](http://pic.xiahunao.cn/瀏覽器工作原理06 [#]渲染流程(下):HTML、CSS和JavaScript是如何變成頁面的)
:TUI基本框架搭建)


+GPS模塊+TFT屏幕實現GPS碼表)

了解空閑函數(prvIdleTask)和TCB)






