講解三篇神經符號集成的綜述,這些綜述沒有針對推薦系統的,所以大致過一下,下一篇帖子會介紹針對KG的兩篇綜述。綜述1關注的是系統集成和數據流的宏觀模式“是什么”;綜述3關注的是與人類理解直接相關的中間過程和決策邏輯的透明度與可讀性“怎么樣”。綜述2短文,在神經網絡和符號系統上加入了概率方法,帖子最后有總結。
綜述1 23年

這篇綜述主要闡述了神經符號學習系統,旨在將神經系統和符號系統 結合到一個統一的框架中。 核心觀點是,神經系統在學習能力和感知智能方面表現出色,但缺乏有效的推理和認知能力。 相反,符號系統擁有出色的認知智能,但在學習能力上不如神經系統。 因此,將兩者的優勢結合起來,創建既能進行強大感知又能進行認知推理的神經符號學習系統。從四個不同的視角對神經符號學習系統的進展進行了調研:挑戰 (challenges)、方法 (methods)、應用 (applications) 和未來方向 (future directions)。
神經符號學習系統是結合了神經系統和符號系統優勢的混合模型 。
符號系統 (Symbolic systems):采用基于推理的方法來尋找解決方案 。它們通常處理結構化數據,如邏輯規則、知識圖譜或時間序列數據,其基本信息處理單元是符號 。通過訓練,符號系統獲取特定任務搜索算法的解空間,并輸出更高級別的推理結果 。
神經系統 (Neural systems):擅長使用基于學習的方法來逼近真實情況 。神經系統通常處理非結構化數據,如圖像、視頻或文本,其主要信息處理單元是向量 。通過訓練,神經系統學習特定任務的映射函數,并輸出較低級別的學習結果 。
神經符號學習系統 (Neural-symbolic learning systems):包含了符號系統和神經系統的特性 。這些系統結合了符號系統的推理能力和神經系統的學習能力。?最終目標是找到一個函數 F,能夠有效地將數據 x 和符號 s(預定義或通過計算獲得)映射到真實標簽 y 。其形式化定義如下:
![]()
分類
該論文的分類方法取決于神經系統和符號系統之間的集成模式,主要有三種集成方法 。
為推理而學習 (Learning for reasoning)
目標:利用符號系統進行推理,同時結合神經網絡的優勢來促進解決方案的尋找 。這類模型以串行化過程為特征,其中神經網絡組件和符號推理組件按順序連接 。
基本思想:利用神經網絡減少符號系統搜索空間,從而加速計算 。這可以通過用神經網絡替代傳統的符號推理算法來實現 。神經網絡有效地減少了搜索空間,使計算更加高效。或者利用神經網絡從數據中抽象或提取符號,以促進符號推理 。在這種情況下,神經網絡作為獲取符號推理任務知識的一種手段 。它們學習從輸入數據中提取有意義的符號,并將其用于后續的推理過程 。
基本框架?:神經網絡提取輸入數據中的相關特征或符號,然后這些特征或符號被符號推理模塊用于執行更高級別的推理任務 。(a)展示了神經網絡加速符號推理的方面,而(b)展示了神經網絡將非結構化數據轉換為符號以供符號推理的方面 。其目標是將神經網絡引入到主要通過推理技術解決的問題中 。
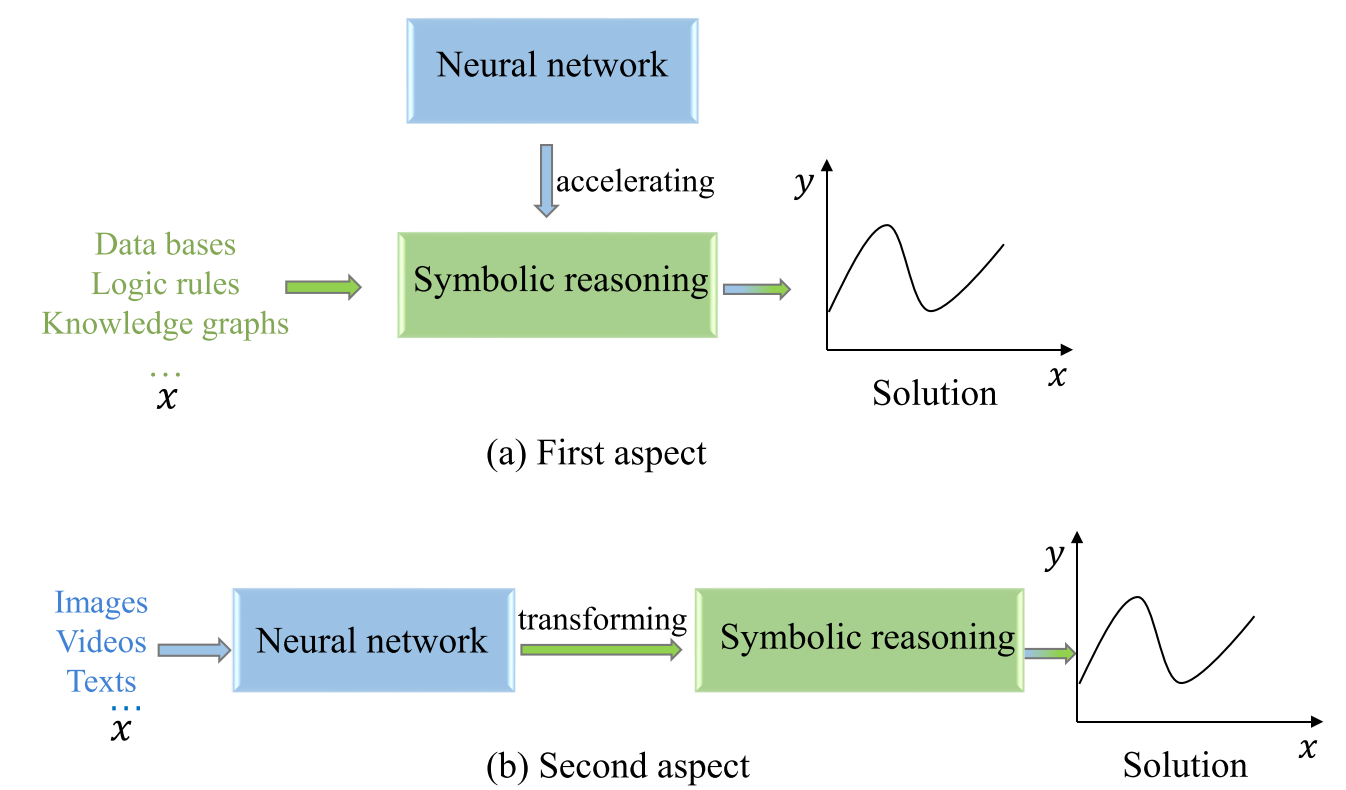
為學習而推理 (Reasoning for learning)
目標:利用符號系統來支持神經系統的學習過程 。這類模型以并行化為特征,神經系統和符號系統在學習過程中并行操作 。
基本思想:利用神經系統執行機器學習任務,同時將符號知識整合到訓練過程中,以增強性能和可解釋性 。符號知識通常被編碼成適合神經網絡的格式,并用于指導或約束學習過程 。例如,符號知識可以表示為特定任務損失函數中的正則化項 。這種符號知識的整合有助于改進學習過程,并能帶來更好的泛化能力和模型可解釋性 。
基本框架? :神經網絡組件從數據中學習,而符號系統提供額外的知識或約束來指導學習過程 。它將符號知識引入神經網絡,主體依靠神經網絡獲得解決方案 。
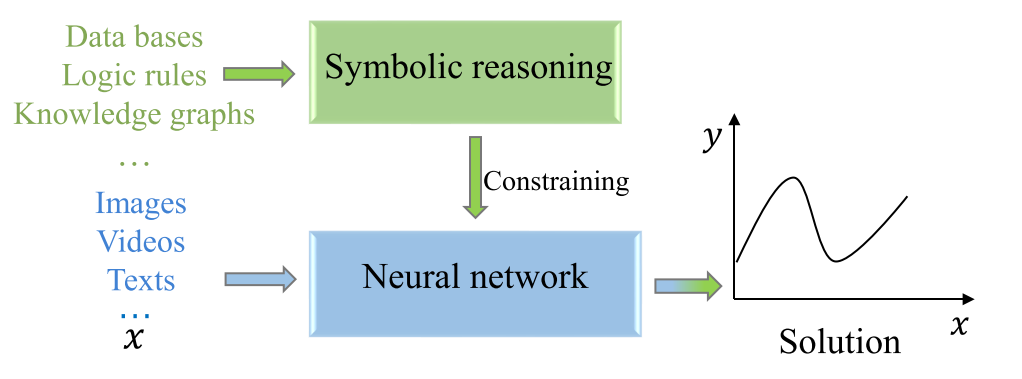
學習-推理 (Learning-reasoning)
目標:神經系統和符號系統之間的交互是雙向的,兩種范式發揮同等作用并以互利的方式協同工作 。其目標是在解決問題的過程中平衡神經系統和符號系統的參與度 。
基本思想:在這種方法中,神經網絡的輸出成為符號推理組件的輸入,而符號推理的輸出也成為神經網絡的輸入 。通過允許神經系統和符號系統迭代地交換信息并相互影響,該方法旨在利用兩種范式的優勢并增強整體問題解決能力 。例如,結合像溯因推理(abductive reasoning)這樣的符號推理技術,可以設計深度神經網絡和符號推理框架之間的連接 。在這種情況下,神經網絡組件生成假設或預測,然后符號推理組件使用這些假設或預測執行邏輯推理或推斷 。來自符號推理的結果隨后可以反饋給神經網絡,以優化和改進預測 。
基本框架 :神經系統和符號系統之間的交互以交替方式發生 。這種結合兩種技術的方式允許迭代學習和推理,從而實現神經和符號方法的更深度集成 。通過神經系統和符號系統之間的雙向交互和信息迭代交換,學習-推理方法旨在最大化兩種范式的優勢,并在各個領域實現增強的問題解決能力 。它將神經網絡和推理技術結合為一個交替過程,兩者共同輸出解決方案 。

方法
1 為推理而學習 (Learning for reasoning)
這類方法利用神經網絡來輔助符號推理,要么加速推理,要么從數據中提取符號供推理使用 。
pLogicNet 和 ExpressGNN
核心思想:這兩模型旨在解決知識圖譜中的三元組補全問題,將其視為概率圖中的隱變量推理問題 。它們結合了變分期望最大化(Variational EM)和神經網絡來近似推理過程 。ExpressGNN 通過使用圖神經網絡(GNN)改進了 pLogicNet 的推理網絡 。
神經邏輯歸納學習 (Neural Logic Inductive Learning, NLIL)
核心思想:NLIL 是一種可微的歸納邏輯編程(ILP)模型,它能自動從數據中歸納出新的邏輯規則,用于模型學習和推理 。它可以學習復雜的邏輯規則,例如樹狀和合取規則,并提供對數據中觀察到的模式的解釋 。
2 為學習而推理 (Reasoning for learning)
這類方法利用符號系統來支持神經網絡的學習過程,例如通過正則化或知識遷移 。
正則化模型 (Regularization models):這些模型通過在模型的目標函數中添加正則項來將符號知識整合到訓練過程中 。
HDNN (Harnessing Deep Neural Networks with Logic Rules)
核心思想:HDNN 利用知識蒸餾的概念,讓一個編碼了邏輯規則的“教師網絡”在訓練過程中指導“學生網絡”(一個深度神經網絡) 。
基于語義的正則化 (Semantic-based Regularization, SBR) 和語義損失 (Semantic Loss, SL)
核心思想:這些方法將邏輯知識(命題邏輯或一階邏輯)編碼為一個實值函數,作為神經模型損失函數的一部分 。SL 使用算術電路(特別是句子決策圖 SDD)來編碼邏輯規則,并將其作為正則化項整合到現有損失函數中 。
上下文感知零樣本識別 (Context-Aware Zero-Shot recognition, CA-ZSL)
核心思想:CA-ZSL 利用知識圖譜(表示類別間的語義關系)來輔助識別來自未見過的類別的對象 。它在一個基于深度學習和條件隨機場(CRF)的模型中,使用知識圖譜生成CRF的二元勢函數
知識遷移模型 (Knowledge transfer models):這類模型通過在不同領域或空間(如視覺空間和語義空間)之間建立聯系,并將符號知識從一個領域轉移到另一個領域來支持學習過程 。
SEKB-ZSL 和 DGP
核心思想:這些是零樣本識別模型,它們使用從知識圖譜(包含已見和未見類別)中派生出來的語義分類器權重,來指導或監督視覺分類器權重的學習,從而實現知識遷移 。DGP 通過減少圖卷積層數和使用注意力機制改進了 GCN 中的過平滑問題 。
知識圖譜遷移網絡 (Knowledge Graph Transfer Network, KGTN)
核心思想:KGTN 利用知識圖譜來捕獲和建模已見類別與未見類別之間的相關性,以解決小樣本分類問題 。它使用門控圖神經網絡(GGNN)學習知識圖譜節點嵌入,以捕獲類別間的相關性 。
命題邏輯網絡 (Propositional Logic Nets, PROLONETS)
核心思想:PROLONETS 將領域知識編碼為神經網絡內的一組命題規則,并允許基于訓練的神經網絡對這些領域知識進行提煉 。它通過將從規則轉換來的決策樹直接初始化神經網絡的權重,從而為深度強化學習提供“熱啟動” -強化學習
3 學習-推理 (Learning-reasoning)
DeepProbLog
核心思想:DeepProbLog 通過使用“神經謂詞”將深度學習與概率邏輯編程語言 ProbLog 無縫集成 。神經網絡處理簡單概念或非結構化數據,為 ProbLog 中的符號推理生成輸入(邏輯事實) 。它支持神經網絡和邏輯推理在一個統一框架下的端到端訓練 。
溯因學習 (Abductive Learning, ABL)
核心思想:ABL 框架結合了溯因推理(推斷對給定觀察的最佳解釋)和歸納(機器學習的核心組成部分)。它通過一個初始化的分類器獲得偽標簽,然后利用邏輯推理(基于知識庫,如ProLog)來最小化偽標簽與符號知識之間的不一致性,從而修正偽標簽,并用修正后的標簽重新訓練分類器,此過程迭代進行 。
雙層概率圖推理框架 (Bi-level Probabilistic Graphical Reasoning framework, BPGR)
核心思想:BPGR 最初用于視覺關系檢測,它使用馬爾可夫邏輯網絡(MLN)來建模所有邏輯規則,并量化符號知識被觸發的程度 。它包含一個視覺推理模塊(VRM)和一個符號推理模塊(SRM),SRM 利用符號知識指導 VRM 的推理,起到糾錯作用 。該模型不僅描述預測結果與符號知識的匹配程度,還明確說明哪些符號知識正在被擬合以及擬合該符號知識的概率,以此作為模型預測的解釋 。
應用
1. 對象/視覺關系檢測 (Object/visual-relationship detection)
目標:識別圖像中的對象或對象之間的關系 。
挑戰與方案:僅依賴視覺特征通常性能較弱 ,因此神經符號學習系統通過引入外部知識來增強檢測性能 。
代表性工作:Donadello 等人提出的邏輯張量網絡 (Logic Tensor Networks, LTN),將神經網絡與一階邏輯結合,能夠從嘈雜圖像中進行有效推理,并通過邏輯規則描述數據特征,從而增強圖像識別任務的可解釋性 。在遙感領域,Marszalek 和 Forestier 等人強調利用領域專家的符號知識來改進檢測能力 。Zhu 和 Nyga 等人采用馬爾可夫邏輯網絡 (Markov Logic Networks, MLN) 來建模符號知識,并將其整合到深度學習模型中,用于學習評分函數并預測輸入圖像與特定對象或概念之間的關系,例如馬和人之間的“可騎乘”關系 。
2. 知識圖譜推理 (Knowledge graph reasoning)
背景:知識圖譜常常存在不完整性,需要通過補全或鏈接預測技術來提高其質量 。Zhang 等人對神經符號學習系統中的知識圖譜推理的益處進行了綜述 。
代表性工作:Wang 等人提出一種方法,將三元組或基本規則轉換為一階邏輯 (FOL) 語句,然后基于實體和關系嵌入的向量/矩陣運算對這些FOL語句進行評分,以執行知識圖譜中的鏈接預測 。
基于路徑的推理方法致力于通過探索給定實體周圍的多跳鄰居來擴展推理,并使用神經網絡在這些鄰域內預測答案 。例如,DeepPath 使用強化學習來評估采樣路徑,從而減少搜索空間并提高效率 。Teru 等人提出的 GraIL 是一個基于圖的推理框架,它提取頭實體和尾實體k跳鄰居組成的子圖,然后使用圖神經網絡 (GNN) 基于提取的子圖推理兩個實體之間的關系 。
3. 分類/小樣本分類 (Classification/ few-shot classification)
代表性工作:Marra 等人引入了關系神經機器 (Relational Neural Machines, RNM),這是一個允許學習器和推理器聯合訓練的框架,能夠整合學習和推理過程以提高性能 。
針對小樣本學習問題,Sikka 等人將常識知識整合到深度神經網絡中,并使用邏輯知識作為神經符號損失函數來正則化視覺語義特征,從而在模型學習過程中利用來自未見類別的信息,增強了零樣本學習能力 。
Altszyler 等人將邏輯規則整合到神經網絡架構中,用于多領域對話識別任務,使得模型能夠識別未見類別的標簽而無需額外的訓練數據 。
4. 智能問答 (Intelligent question answering)
概述:智能問答是神經符號推理在自然語言處理和視覺推理任務中的一個突出應用 。其目標是開發能夠通過利用文本和圖像的上下文信息準確推斷答案的模型 。
代表性工作:Andreas 等人提出的神經模塊網絡 (Neural Module Network, NMN) 框架,使用深度神經網絡生成符號結構以解決后續的推理問題 。Gupta 等人擴展了 NMN,并提出了一種無監督輔助損失來幫助提取與文本中事件相關的論點,并為文本引入了一個推理模塊,能夠以概率或可微分的方式對數字和日期進行符號推理(如算術、排序和計數) 。Hudson 等人提出的 MAC 模型是一個具有循環記憶、注意力和組合功能的全可微分網絡模型,它將圖像和問題分解為序列單元,輸入循環網絡進行序列推理 。Tran 和 Poon 等人使用 MLN 對領域常識進行建模,并使用概率推理方法進行查詢 。Sun 等人學習了一個神經語義解析器,并基于元學習訓練了一個模型無關的模型,以提高涉及有限簡單規則的語言問答任務的預測能力 。Oltramariet 等人提出在常識問答中整合神經語言模型和知識圖譜,并基于語言模型架構提出了一種基于注意力的知識注入方法 。對于視覺問答任務 (VQA),Hudson 等人提出了神經狀態機 (Neural State Machine, NSM),它基于圖像中的概念構建一個概率場景圖,然后對該概率場景圖執行順序推理,以回答問題或發現新結論 。
5. 強化學習 (Reinforcement learning)
背景與挑戰:深度強化學習是一個熱門領域,但當前的深度強化學習方法在推理能力方面存在局限性 。研究人員開始將符號知識整合到強化學習中以應對這一挑戰 。論文探討了兩種方法:將符號知識與深度強化學習相結合,以及將符號知識與分層強化學習相結合 。
代表性工作:Garnelo 等人提出的深度符號強化學習 (Deep Symbolic Reinforcement Learning, DSRL) 方法,將符號先驗整合到智能體的學習過程中以增強模型的泛化能力 。DSRL 智能體由一個神經后端和一個符號前端組成,神經后端學習將原始傳感器數據映射到符號表示,符號前端則利用該表示學習有效策略 。Garcez 等人擴展了 DSRL 并引入了帶常識的符號強化學習方法 (SRL+CS),該方法基于 DSRL 改進了學習階段(獎勵分配考慮智能體與對象的交互)和決策階段(基于對象與智能體的距離為每個Q函數分配重要性權重) 。Yang 等人提出的 PEORL 框架整合了符號規劃和分層強化學習 (HRL),以解決動態環境中具有不確定性的決策問題 。符號規劃用于指導智能體的任務執行和學習過程,而學習到的經驗則反饋給符號知識以增強規劃階段 。這是首次在HRL框架內利用符號規劃進行選項發現 。
Lyu 等人提出的符號深度強化學習 (Symbolic Deep Reinforcement Learning, SDRL) 框架,與PEORL類似,包含規劃器、控制器、元控制器以及符號知識,旨在實現任務級的可解釋性 。規劃器利用先驗符號知識通過一系列符號動作(子任務)進行長期規劃;控制器利用深度強化學習算法學習每個子任務的子策略;元控制器通過評估控制器的訓練性能來學習外部獎勵,并向規劃器建議新的內在目標 。PEORL 和 SDRL 都利用符號知識來指導強化學習過程并促進決策制定 。
未來方向
1. 高效方法 (Efficient methods)
挑戰:在神經符號學習系統中,符號推理技術(如使用馬爾可夫邏輯網絡 MLNs 進行概率推理)經常面臨精確推理難以解決的問題 。例如,當處理大量邏輯規則和常量時,基元(groundings)的數量會指數級增長,這會顯著降低模型推理的速度 。
現有問題:盡管已經提出了一些緩解方法,如基于學習的方法,但它們仍有局限性 。常用的近似推理技術雖然能提高推理速度,但往往以犧牲準確性為代價 。
未來方向:因此,研究人員探索神經網絡在解決符號系統計算難題方面的潛力至關重要 。設計利用神經網絡計算優勢來處理傳統符號系統中計算困難任務的方法,是推進推理方法向前發展的關鍵研究方向 。
2. 符號知識的自動構建 (Automatic construction of symbolic knowledge)
現狀:論文中討論的符號知識包括邏輯知識和知識圖譜 。自動構建符號知識(尤其是知識圖譜)已經相對成熟 。
挑戰:然而,神經符號方法中邏輯規則的構建通常依賴領域專家的手動努力,這個過程耗時、費力且不易擴展 。對于神經符號學習系統而言,一個重大的挑戰是實現描述從數據中派生出的先驗知識規則的端到端學習 。
未來方向:盡管存在像基于歸納邏輯編程(ILP)的方法用于知識提取,但從數據中自動學習邏輯規則在很大程度上仍未被充分探索 。因此,規則的自動構建是神經符號學習系統領域一個重要的未來研究方向 。
3. 符號表示學習 (Symbolic representation learning)
重要性:精心設計的符號表示在簡化和提高復雜學習任務效率方面起著至關重要的作用 。
挑戰:例如,在零樣本圖像分類中,學習到的符號表示如果包含有限的語義信息,會妨礙模型有效處理復雜分類任務的能力 。因此,符號知識中精確的語義信息對于提升這些模型的性能至關重要 。然而,大多數現有的符號表示學習方法難以處理具有強相似性的謂詞(例如,“next to” 和 “near” 可能語義相似但邏輯公式不同)。當前的符號表示學習方法未能捕捉到這種語義相似性,從而妨礙了模型的推理能力 。
未來方向:因此,設計更魯棒和高效的符號表示學習方法是神經符號學習系統領域的一個重大挑戰 。圖表示學習的發展為應對這一挑戰提供了一個有前景的途徑,它通過將節點映射到低維、密集和連續的向量中,可以靈活支持各種學習和推理任務 。鑒于符號知識通常表現出異構性、多重關系甚至多模態性,探索異構圖表示學習方法的開發和利用成為克服神經符號學習系統面臨挑戰的另一個重要方向 。
4. 應用領域擴展 (Application field expansion)
現狀:神經符號學習系統已在多個領域得到應用,包括計算機視覺、自然語言處理和推薦系統 。
新探索:最近,研究人員也開始探索將神經符號學習系統應用于其他領域,如COVID-19疫情研究和先進機器人技術 。例如,在COVID-19疫情背景下,它們已被用于從醫學文獻中提取相關信息等任務 。同樣,在先進機器人領域,神經符號學習系統可用于增強機器人的智能和決策能力

綜述2 24年
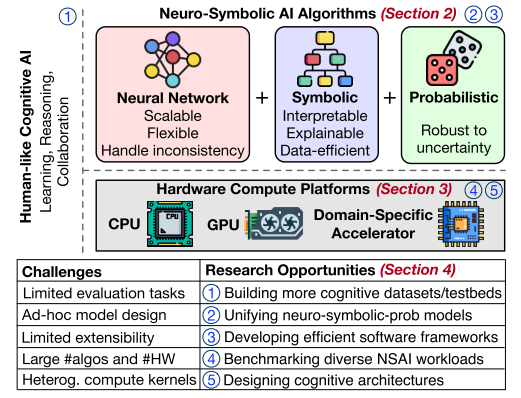
Human-like Cognitive AI: Learning, Reasoning, Collaboration”指出了NSAI系統旨在實現的目標——像人類一樣的學習、推理和協作能力 。這部分指向了NSAI算法的構成。NSAI算法被描繪成三種關鍵技術組件的融合 :
神經網絡 (Neural Network):具有可擴展 (Scalable)、靈活 (Flexible) 和處理不一致性 (Handle inconsistency) 的特點 。
符號方法 (Symbolic):具有可解釋 (Interpretable)、可說明 (Explainable) 和數據高效 (Data-efficient) 的特點 。
概率方法 (Probabilistic):具有對不確定性的魯棒性 (Robust to uncertainty) 。
該圖清晰地展示了神經符號AI (NSAI) 系統的核心組成、硬件平臺以及面臨的挑戰和未來研究方向。?相較于綜述1,入上圖的部分還增加了一個概率方法。同時還增加了硬件計算平臺包括CPU,GPU。最后列出了當前NSAI領域面臨的主要挑戰以及未來方向:
挑戰 (Challenges) :有限的評估任務 (Limited evaluation tasks)
臨時的模型設計 (Ad-hoc model design)
有限的可擴展性 (Limited extensibility)
大量的算法和硬件 (Large #algos and #HW)
異構的計算核心 (Heterog. compute kernels)
方向:
① 構建更多的認知數據集/測試平臺 (Building more cognitive datasets/testbeds) 。
② 統一神經-符號-概率模型 (Unifying neuro-symbolic-prob models) 。
③ 開發高效的軟件框架 (Developing efficient software frameworks) 。
④ 對多樣化的NSAI工作負載進行基準測試 (Benchmarking diverse NSAI workloads) 。
⑤ 設計認知架構 (Designing cognitive architectures) 。這與數字④和⑤以及認知AI的總體目標相關。
概率方法:主要貢獻在于使認知系統能夠更有效地處理不確定性。通過有效處理不確定性,概率方法能夠幫助NSAI系統在非結構化條件下實現改進的魯棒性。神經方法、符號方法和概率方法的協同融合,使得NSAI成為一個有前景的、能夠引領人工智能第三次浪潮的范式 。
但并沒有為“概率方法”定義一個獨立通用的、像神經網絡訓練那樣的分步流程。而是列舉了一些工作,例如:NeaPSL (Neuro-probabilistic Soft Logic) 其底層操作結合了神經網絡和模糊邏輯 ;DeepProbLog (Neural Probabilistic Logic Programming) 這樣的系統中,神經網絡學習到的參數或事實會帶有概率,然后在一個概率邏輯編程的框架下進行推理 ;NVSA (Neuro-Vector-Symbolic Architecture) 使用符號推理器進行“概率溯因推理。
綜述3 24年

提供了一個以可解釋性為核心視角來審視和分類神經符號AI研究的框架,回顧了從2013年以來的191項研究,并提出了一個針對可解釋性的分類方法 。這個分類方法同時考慮了模型的設計因素 (design factor) 和行為因素 (behavior factor)?,探討了在提升可解釋性方面所面臨的挑戰和未來的發展方向。原文:解釋神經網絡的難點在于其特征提取和基于特征的推理過程。
可解釋分析
模型的透明度分為設計期可解釋性和事后可解釋性,“設計期可解釋性”指的是在模型構建過程中就使其易于人類理解,或者嵌入邏輯規則和約束,從而讓神經符號AI系統天生透明且可解釋,從根本上避免黑箱模型的影響 。“事后可解釋性”則是在系統設計、開發和部署之后,通過分析模型行為來解釋其決策過程,例如通過生成解釋性文本、可視化技術和模型簡化等方法 。
并將191項研究分為了五個可解釋性級別:低、中低、中、中高和高 。
分類標準:第一個標準關注神經網絡提取的特征與符號邏輯處理的信息形式之間的差異 。這個視角聚焦于這兩種表示之間的兼容性和轉換機制 。除了神經網絡本身的可解釋性外,這種轉換的形式也影響集成模型的可解釋性,構成了分類的第一個標準,即衡量連接神經表示和邏輯符號表示的中間表示的可讀性 。
第二個標準關注神經符號AI模型中決策或預測邏輯的可解釋性 。具體來說,即使考慮到神經網絡黑箱處理不可避免的影響,仍然可以在不同程度上理解知識處理方法的本質,這將有助于在一定程度上解釋決策或預測 。
可解釋性分析框架
詳細描述了神經符號方法(基于191項研究)的五個具體分類,并對每個類別進行了討論,后續名詞解釋:
中間表示:神經網絡通常用于從原始數據(如圖像、文本)中提取特征,這些特征通常是以向量或高維嵌入的形式存在的。然而,符號邏輯系統通常處理的是離散的、結構化的符號和邏輯表達式 。因此,當這兩類系統需要協同工作時,往往需要一個“中間表示”來充當橋梁,轉換或連接神經網絡的輸出(神經表示)和符號邏輯系統的輸入(符號表示)。隱式中間表示:不直接具備人類可讀性的、難以直接理解其語義內容的表示形式,通常是神經網絡內部產生的潛在向量嵌入。顯式中間表示 : 指的是那些具有清晰結構、可以直接被人類閱讀和理解其含義的表示形式。
決策:神經符號AI模型如何基于輸入數據和內部處理,最終做出一個決策或生成一個預測的整個過程或其核心邏輯。隱式決策(預測)邏輯 : 當模型的決策過程主要隱藏在神經網絡的權重、偏置和激活函數中時,其決策邏輯就是隱式的 。我們很難確切地知道網絡內部數百萬參數是如何相互作用,從而精確地推導出一個特定決策的完整邏輯鏈條。顯式決策(預測)邏輯 (Explicit Decision Making/Prediction): 當模型的決策過程是基于清晰、可追溯、可理解的規則、步驟或符號運算時,其決策邏輯就是顯式的 。
1 隱式中間表示與隱式決策制定(預測) - (Category I: 低可解釋性)
研究數量:此類別包含74項神經符號AI研究 。
共同特征:它們都使用神經網絡從數據中提取特征 。然而,這些特征的表示不能直接被符號邏輯處理,因此需要一個中間表示來填補空白 。連接兩者的中間表示通常是潛在的向量嵌入,或者與結構化表示相結合,但僅部分顯式且不能直接被人類閱讀 。
大部分整體決策邏輯或預測方法是通過神經網絡的權重和激活函數隱式表達的 。一些方法可能直接將符號邏輯整合到決策過程中,或者通過設計可解釋的接口(如注意力機制和邏輯規則生成器)來提供對決策邏輯的間接理解,但整體的決策邏輯仍然需要解釋 。
代表性案例討論:論文討論了Lemos等人 [114] 在知識圖譜上的關系推理和鏈接預測模型、Ahmed等人 [2] 解決概率推理問題的方法、Marconato等人 [129] 提出的神經符號持續學習方法,以及Furlong和Eliasmith [78] 通過向量符號架構(VSA)和空間語義指針(SSP)實現概率計算的方法。這些案例的共同點在于,盡管它們結合了神經和符號成分,但由于中間表示(通常是高維向量)的隱式性以及決策邏輯主要依賴神經網絡內部運作,其可解釋性被評為較低。
結論:該類別下的研究,其解釋性努力未能完全擺脫神經網絡的“黑箱效應” 。
2 部分顯式中間表示與部分顯式決策制定(預測) - (Category II: 中低可解釋性)
研究數量:此類別涉及110項神經符號AI研究 。
共同特征:它們都使用神經網絡從數據中提取特征 。這些嵌入的表示不能直接被符號邏輯處理,需要中間表示 。大多數中間表示是符號邏輯表達式、數學表達式、結構化程序、邏輯電路、概率分布、虛擬電路和虛擬機指令等 。這些表示是部分顯式的并且是人類可讀的 。決策邏輯結合了來自神經網絡的隱式表示和符號邏輯的顯式表示,因此是部分顯式和可讀的 。
代表性案例討論:論文討論了Petersen等人 [143] 提出的深度符號回歸(DSR)方法、[172] 提出的用于自動駕駛系統設計的神經符號程序搜索(NSPS)方法,以及Finzel等人 [74] 提出的使用GNN分類關系數據并通過ILP生成解釋的方法。這些方法的中間表示(如符號表達式樹、領域特定語言DSL、Prolog事實和規則)或決策過程(如表達式評估、程序搜索)具有一定的顯式性,但仍有部分(如RNN內部狀態、程序搜索算法的內部工作方式)是隱式的。
3 顯式中間表示 或 顯式決策制定(預測)- (Category III: 中等可解釋性)
研究數量:此類別中有3項神經符號AI研究 。
共同特征:使用神經網絡從數據中提取特征 。這些特征的表示不能直接被符號邏輯處理,因此必須使用中間表示來填補空白 。要么是中間表示完全顯式,要么是整體決策邏輯完全顯式 。
代表性案例討論:論文討論了Jiang等人 [102] 提出的基于LNN的實體鏈接方法LNN-EL、Kapanipathi等人 [103] 提出的基于語義解析和推理的NSQA(神經符號問答)系統,以及Katz等人 [105] 提出的在機器人操作任務中集成高級推理和低級動作控制的方法(基于神經虛擬機NVM結構)。這些方法的特點是,或者中間產物(如AMR圖到邏輯查詢的轉換)較為清晰,或者推理過程(如LNN中的邏輯操作)是顯式的,但由于特征提取階段仍依賴深度模型,或表示空間是高維向量空間,整體的可解釋性被評為中等。
4 顯式中間表示 與 顯式決策制定(預測) - (Category IV: 中高可解釋性)
研究數量:此類別中有1項神經符號AI研究 。
主要特點:與前一類別最顯著的區別在于,中間表示和整體決策邏輯都是顯式的 。然而,仍然需要一個中間表示來填補提取的特征和符號處理之間的空白 。
代表性案例討論:論文討論了Kimura等人 [108] 提出的解決基于文本游戲的強化學習問題的神經符號框架。該方法首先通過語義解析器從文本觀察中提取基本的命題邏輯,然后使用外部知識庫(如ConceptNet)來理解詞匯的語義類別并優化提取的命題邏輯,最后將這些組合成一階邏輯事實作為LNN的訓練輸入。文本到邏輯的轉換過程是清晰和顯式的,LNN的推理和學習過程也是基于清晰的邏輯規則,因此決策過程也是顯式和可解釋的。
5 統一表示 與 顯式決策制定(預測)- (Category V: 高可解釋性)
研究數量:此類別中有3項神經符號AI研究 。
共同特征:盡管它們使用神經網絡獲取特征,但神經網絡的輸出保持了可以被符號邏輯處理的相同表示形式 。這意味著不需要額外的中間表示來彌合差距,或者說它們在某種程度上實現了表示的統一。整體的決策邏輯是完全顯式和可解釋的 。
代表性案例討論:該類別主要以Riegel等人 [149] 提出的邏輯神經網絡 (Logical Neural Network, LNN) 及其應用為例。LNN通過將其每個神經元映射到邏輯公式中的元素來直接解釋和操作邏輯運算,使得模型的計算過程等同于執行一系列邏輯判斷,每個神經元的輸出不僅代表邏輯命題的真值,還能反映該真值是如何通過邏輯運算從輸入中得出的,這使其具有高度可解釋性。LNN還能通過擴展真值范圍來處理不確定性、邏輯矛盾和不完整知識。Sen等人 [160] 提出的基于LNN的歸納邏輯編程方法和Sen等人 [159] 提出的使用LNN完成知識庫的方法也屬于此類,它們都能生成可解釋的邏輯規則或基于顯式邏輯進行操作。論文還提及Arrotta等人 [16, 17]、He等人 [89]、Xu等人 [197] 提出了適用于神經符號學習的損失函數,以及[4]提出了正則化方法,但指出這些研究并未提升模型的可解釋性 。
通過這五種分類詳細闡述了不同神經符號AI方法在可解釋性方面的具體表現和原因。
趨勢
使用了關鍵詞 'neuro-symbolic', 'neuro symbolic', 和 'neuro symbolic learning' 在 Google Scholar 和 Research Gate 上調研了從2014年至今(截止到2024年2月)的相關研究 。在2020年至2023年之間,發表的論文數量呈上升趨勢,其中2023年發表的論文數量最多,根據呈現的數據共有55篇 。這反映了對神經符號系統研究興趣和活動的初步增長 。
輸入數據類型:在當前的神經符號方法中,圖像和文本是最常見的輸入數據類型,這反映了它們在神經符號系統研究中的普遍性和重要性 。表示空間:絕大多數研究使用了單模態和非異構的表示空間,這表明在神經符號系統研究中,單一類型的數據(如文本、圖像或結構化數據)仍然是更常見的研究對象 。可解釋性水平:絕大多數論文的可解釋性水平為中低 (medium-low) 和低 (low) 。這一數字表明該領域的大多數研究成果在可解釋性方面仍有待提高 。
挑戰
神經網絡與符號邏輯中的統一表示
目前常見的方式(神經網絡增強符號邏輯特征提取,或符號知識嵌入為神經網絡提供規則約束)通常是針對特定任務優化的,難以適應或遷移到新任務或數據集,當需求改變時需要重新訓練模型或調整符號邏輯規則,這限制了模型的整體泛化能力 。理想的統一表示可以讓神經網絡和符號邏輯模塊直接利用提取的特征或學習到的知識,從而提高訓練和推理效率 。
設計理想的統一表示仍面臨許多障礙 :它需要能捕捉符號邏輯的結構特性,同時保持數據的本質模式 。這要求對數據分布及其與邏輯實體的潛在關系有深刻理解 。例如,如何在同一表示空間中有效地關聯抽象定義(如“危險”)的圖像特征與其符號定義,需要對不同類型數據間定義的內在語義“同一性”有深刻洞察,并找到合理的空間形式來反映這種洞察 。
基于統一表示的知識對齊必須明確驗證新知識的可靠性,并確保更新前后輸出的一致性,且過程應透明可解釋 。這可能更接近于解決當前聯結主義的概念穩定性問題,因為基于統一表示的概念結構在形成和更新時受到固定邏輯規則的約束 。傳統的符號邏輯推理依賴明確定義的邏輯規則和結構,而神經網絡通過模糊的概率分布進行推理,兩者在推理機制上存在根本差異 。在統一表示中集成這兩種推理架構意味著需要探索新的推理框架,并開發能夠同時處理模糊邏輯和確定性邏輯的邏輯算法 。
可解釋性與透明度
神經網絡在與符號學習的合作中引入了不可避免的黑箱特征和推理過程 。對于松散耦合的情況,神經網絡的可解釋性無法得到任何改善,因為即使邏輯符號以嵌入向量的形式為神經網絡提供規則或約束,嵌入過程本身也不直觀,并且兩者之間的交互增加了復雜性,還需要額外的復雜邏輯符號推理 。當神經網絡和符號邏輯利用統一表示時,它們的語義重疊至少可以形成部分互補的可解釋性
充分合作
當前神經網絡和符號邏輯的集成難以避免兩種模式各自的內在問題,例如,神經網絡的不可解釋推理和訓練成本,或符號邏輯的表達限制和泛化問題,都可能被引入到集成的神經符號模型中 。
一個有前景的解決途徑是開發新的模型架構,該架構將為神經網絡組件和符號邏輯組件的輸出應用一個集成層,從而可能克服當前集成的局限性 。可以利用一種彈性的雙向學習機制來同步它們的知識 。然而,至關重要的是從設計過程一開始就考慮可解釋性。
未來研究方向
統一表示和表示空間
增強模型可解釋性:首先必須建立可解釋性的基礎 。例如,數學和物理定律在一定程度上可被視為正確的標準,而人類的常識邏輯可能充滿矛盾和邏輯謬誤 。同樣,神經符號AI中的可解釋性必須基于相對穩定的概念才能更具說服力 。因此,驗證和更新大語言模型 (LLMs) 中的知識也是一個開放性課題 。對神經符號AI的可解釋性要求主要分為兩部分:過程透明度和結果透明度 。前者可能基于嚴謹的邏輯或公式化論證,這意味著即使使用神經網絡為邏輯推理生成符號,這個過程也應該足夠透明和可解釋,以便驗證其正確性 。后者表明,還應考慮一些獨特的思維習慣,例如在為推理結果提供上下文證據時的常識 。
倫理考量與社會影響:如果未來我們大部分內容將來自生成式AI,那么這些內容的意義將遠遠超出僅用可信度來衡量的范圍 。當今社會的所有道德要求,如公平正義、隱私保護、偏見與歧視、環境倫理、技術倫理、人道主義,甚至宗教,都應被納入AI算法的評估標準中 。
?總結
神經符號AI融合了神經網絡強大的學習能力、符號系統的邏輯推理與可解釋性。
綜述1 偏向基礎理論與算法方法論。它系統梳理了神經符號結合的基本模式和代表性算法。基于神經系統和符號系統之間的集成模式分為了三個范式:
- 為推理而學習 (Learning for reasoning):主要目標是利用符號系統進行推理,而神經網絡則用于促進這一過程(例如,加速計算或提取符號)。這是一種串行化的集成 。
- 為學習而推理 (Reasoning for learning):主要目標是利用符號系統來支持和增強神經網絡的學習過程(例如,通過提供知識約束或正則化)。這是一種并行化的集成 。
- 學習-推理 (Learning-reasoning):這是一種更緊密耦合的模式,神經系統和符號系統之間存在雙向、迭代的交互,共同完成任務 。
綜述2 涵蓋算法到系統實現、硬件架構,并創新性地將概率方法明確納入NSAI的核心框架,為構建真正魯棒、高效的下一代智能系統提供了多維度的思考。
綜述3針對可解釋性。專門為了評估和理解神經符號AI模型的可解釋性等級 ,并對如何真正實現“可解釋的神經符號AI”提出了前瞻性的思考。并且基于中間表示的可讀性和決策(預測)邏輯的可理解性(文中使用顯示和隱示),將可解釋性由低到高排列,分為了五類。
總結:將離散邏輯運算(如AND, OR)變為連續形式的方法多樣,包括模糊邏輯、學習近似的神經模塊、嵌入空間操作、概率邏輯和編譯為算術電路等。
這種連續化本身不直接等同于可解釋性。可解釋性來源于:(a) 連續邏輯本身是否具有清晰的、可追溯的語義(如LNN);(b) 系統是否能基于這些連續表示生成人類可讀的符號輸出(如規則);(c) 系統是否能透明化這些連續表示如何影響最終決策。
不同的集成范式(如綜述1的“為推理而學習”、“為學習而推理”、“學習-推理”)會以不同的方式引入和使用這些連續化的邏輯運算,其對可解釋性的貢獻路徑和程度也因此各異。




)














