DAY 43 復習日
作業:
kaggle找到一個圖像數據集,用cnn網絡進行訓練并且用grad-cam做可視化
@浙大疏錦行
數據集使用貓狗數據集,訓練集中包含貓圖像4000張、狗圖像4005張。測試集包含貓圖像1012張,狗圖像1013張。以下是數據集的下載地址。
貓和狗 --- Cat and Dog
1.數據集加載與數據預處理
我這里對數據集文件路徑做了改變
C:\Users\vijay\Desktop\1\
├── train\
│? ? ? ├── cats\?
│? ? ? └── dogs\
└── test\
? ? ? ? ├── cats\?
? ? ? ? └── dags\?
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as F# 設置隨機種子確保結果可復現
torch.manual_seed(42)
np.random.seed(42)# 設置中文字體支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題# 檢查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用設備: {device}")# 1. 數據預處理
# 訓練集:使用多種數據增強方法提高模型泛化能力
train_transform = transforms.Compose([# 新增:調整圖像大小為統一尺寸transforms.Resize((32, 32)), # 確保所有圖像都是32x32像素transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])# 測試集:僅進行必要的標準化,保持數據原始特性
test_transform = transforms.Compose([# 新增:調整圖像大小為統一尺寸transforms.Resize((32, 32)), # 確保所有圖像都是32x32像素transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])# 定義數據集根目錄
root = r'C:\Users\vijay\Desktop\1'train_dataset = datasets.ImageFolder(root=root + '/train', # 指向 train 子文件夾transform=train_transform
)
test_dataset = datasets.ImageFolder(root=root + '/test', # 指向 test 子文件夾transform=test_transform
)# 打印類別信息,確認數據加載正確
print(f"訓練集類別: {train_dataset.classes}")
print(f"測試集類別: {test_dataset.classes}")# 3. 創建數據加載器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)2.模型訓練與評估?
# 定義一個簡單的CNN模型
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 第一個卷積層,輸入通道為3(彩色圖像),輸出通道為32,卷積核大小為3x3,填充為1以保持圖像尺寸不變self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)# 第二個卷積層,輸入通道為32,輸出通道為64,卷積核大小為3x3,填充為1self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)# 第三個卷積層,輸入通道為64,輸出通道為128,卷積核大小為3x3,填充為1self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)# 最大池化層,池化核大小為2x2,步長為2,用于下采樣,減少數據量并提取主要特征self.pool = nn.MaxPool2d(2, 2)# 第一個全連接層,輸入特征數為128 * 4 * 4(經過前面卷積和池化后的特征維度),輸出為512self.fc1 = nn.Linear(128 * 4 * 4, 512)# 第二個全連接層,輸入為512,輸出為2(對應貓和非貓兩個類別)self.fc2 = nn.Linear(512, 2)def forward(self, x):# 第一個卷積層后接ReLU激活函數和最大池化操作,經過池化后圖像尺寸變為原來的一半,這里輸出尺寸變為16x16x = self.pool(F.relu(self.conv1(x)))# 第二個卷積層后接ReLU激活函數和最大池化操作,輸出尺寸變為8x8x = self.pool(F.relu(self.conv2(x)))# 第三個卷積層后接ReLU激活函數和最大池化操作,輸出尺寸變為4x4x = self.pool(F.relu(self.conv3(x)))# 將特征圖展平為一維向量,以便輸入到全連接層x = x.view(-1, 128 * 4 * 4)# 第一個全連接層后接ReLU激活函數x = F.relu(self.fc1(x))# 第二個全連接層輸出分類結果x = self.fc2(x)return x# 初始化模型
model = SimpleCNN()
print("模型已創建")# 如果有GPU則使用GPU,將模型轉移到對應的設備上
model = model.to(device)# 訓練模型
def train_model(model, train_loader, test_loader, epochs=10):# 定義損失函數為交叉熵損失,用于分類任務criterion = nn.CrossEntropyLoss()# 定義優化器為Adam,用于更新模型參數,學習率設置為0.001optimizer = torch.optim.Adam(model.parameters(), lr=0.001)for epoch in range(epochs):# 訓練階段model.train()running_loss = 0.0correct = 0total = 0for i, data in enumerate(train_loader, 0):# 從數據加載器中獲取圖像和標簽inputs, labels = data# 將圖像和標簽轉移到對應的設備(GPU或CPU)上inputs, labels = inputs.to(device), labels.to(device)# 清空梯度,避免梯度累加optimizer.zero_grad()# 模型前向傳播得到輸出outputs = model(inputs)# 計算損失loss = criterion(outputs, labels)# 反向傳播計算梯度loss.backward()# 更新模型參數optimizer.step()running_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()if i % 100 == 99:# 每100個批次打印一次平均損失和準確率print(f'[{epoch + 1}, {i + 1}] 損失: {running_loss / 100:.3f} | 準確率: {100.*correct/total:.2f}%')running_loss = 0.0# 測試階段model.eval()test_loss = 0correct = 0total = 0with torch.no_grad():for data in test_loader:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = model(images)test_loss += criterion(outputs, labels).item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()print(f'測試集 [{epoch + 1}] 損失: {test_loss/len(test_loader):.3f} | 準確率: {100.*correct/total:.2f}%')print("訓練完成")return model# 訓練模型
try:# 嘗試加載預訓練模型(如果存在)model.load_state_dict(torch.load('cat_classifier.pth'))print("已加載預訓練模型")
except:print("無法加載預訓練模型,訓練新模型")model = train_model(model, train_loader, test_loader, epochs=10)# 保存訓練后的模型參數torch.save(model.state_dict(), 'cat_classifier.pth')# 設置模型為評估模式
model.eval()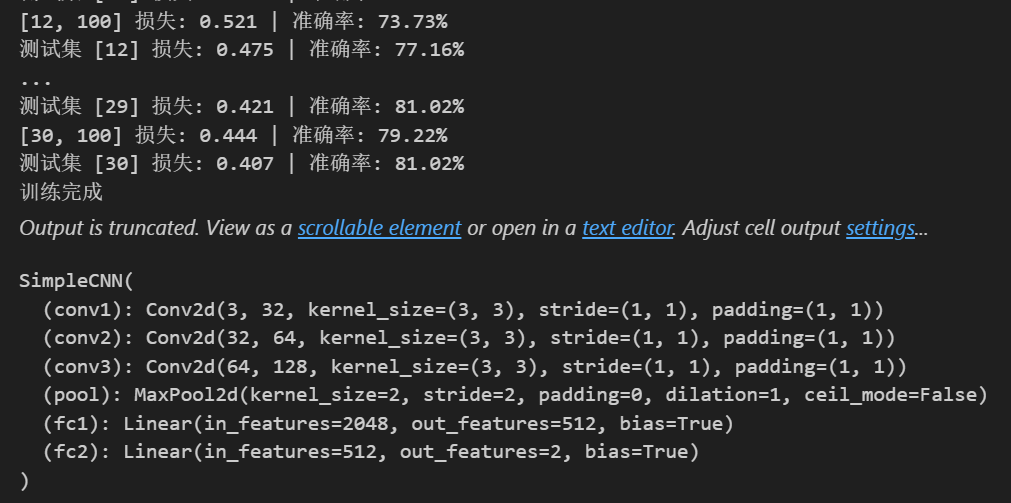
3.?Grad-CAM實現
# Grad-CAM實現
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注冊鉤子,用于獲取目標層的前向傳播輸出和反向傳播梯度self.register_hooks()def register_hooks(self):# 前向鉤子函數,在目標層前向傳播后被調用,保存目標層的輸出(激活值)def forward_hook(module, input, output):self.activations = output.detach()# 反向鉤子函數,在目標層反向傳播后被調用,保存目標層的梯度def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()# 在目標層注冊前向鉤子和反向鉤子self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):# 前向傳播,得到模型輸出model_output = self.model(input_image)if target_class is None:# 如果未指定目標類別,則取模型預測概率最大的類別作為目標類別target_class = torch.argmax(model_output, dim=1).item()# 清除模型梯度,避免之前的梯度影響self.model.zero_grad()# 反向傳播,構造one-hot向量,使得目標類別對應的梯度為1,其余為0,然后進行反向傳播計算梯度one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot)# 獲取之前保存的目標層的梯度和激活值gradients = self.gradientsactivations = self.activations# 對梯度進行全局平均池化,得到每個通道的權重,用于衡量每個通道的重要性weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加權激活映射,將權重與激活值相乘并求和,得到類激活映射的初步結果cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活,只保留對目標類別有正貢獻的區域,去除負貢獻的影響cam = F.relu(cam)# 調整大小并歸一化,將類激活映射調整為與輸入圖像相同的尺寸(32x32),并歸一化到[0, 1]范圍cam = F.interpolate(cam, size=(32, 32), mode='bilinear', align_corners=False)cam = cam - cam.min()cam = cam / cam.max() if cam.max() > 0 else camreturn cam.cpu().squeeze().numpy(), target_class# 可視化Grad-CAM結果的函數
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
# 設置中文字體支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題
# 選擇一個隨機圖像
# idx = np.random.randint(len(test_dataset))
idx = 102 # 選擇測試集中的第101張圖片 (索引從0開始)
image, label = test_dataset[idx]
print(f"選擇的圖像類別: {test_dataset.classes[label]}")# 轉換圖像以便可視化
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])img = std * img + meanimg = np.clip(img, 0, 1)return img# 添加批次維度并移動到設備
input_tensor = image.unsqueeze(0).to(device)# 初始化Grad-CAM(選擇最后一個卷積層)
grad_cam = GradCAM(model, model.conv3)# 生成熱力圖
heatmap, pred_class = grad_cam.generate_cam(input_tensor)# 可視化
plt.figure(figsize=(12, 4))# 原始圖像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"原始圖像: {test_dataset.classes[label]}")
plt.axis('off')# 熱力圖
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM熱力圖: {test_dataset.classes[pred_class]}")
plt.axis('off')# 疊加的圖像
plt.subplot(1, 3, 3)
img = tensor_to_np(image)
heatmap_resized = np.uint8(255 * heatmap)
heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]
superimposed_img = heatmap_colored * 0.4 + img * 0.6
plt.imshow(superimposed_img)
plt.title("疊加熱力圖")
plt.axis('off')plt.tight_layout()
plt.savefig('grad_cam_result.png')
plt.show()print("Grad-CAM可視化完成。已保存為grad_cam_result.png")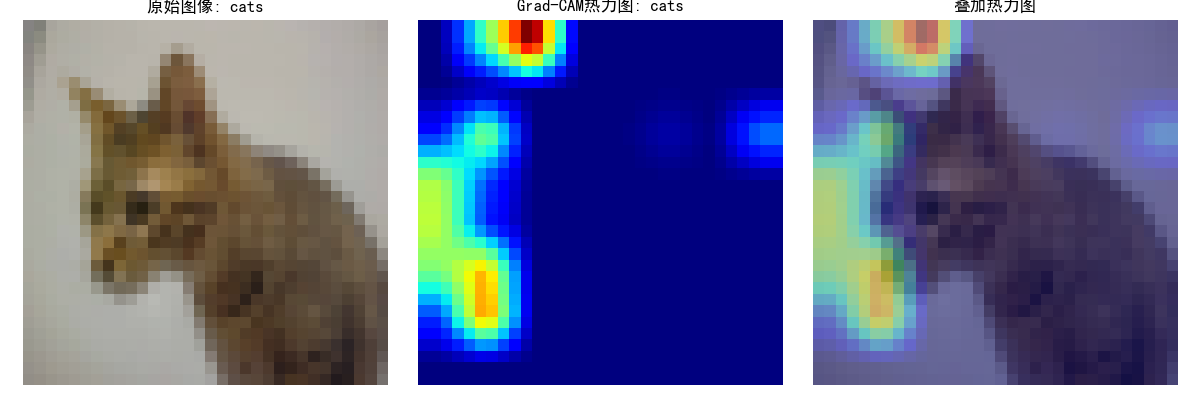














)




