作者:IvanCodes
日期:2025年5月30日
專欄:Sqoop教程
在大數據時代,數據往往分散存儲在各種不同類型的系統中。其中,傳統的關系型數據庫 (RDBMS) 如 MySQL, Oracle, PostgreSQL 等,仍然承載著大量的關鍵業務數據。而Hadoop生態系統 (包括 HDFS, Hive, HBase 等) 則以其強大的分布式存儲和計算能力,成為處理和分析海量數據的首選平臺。如何高效、便捷地在這兩種體系之間遷移數據,成為了一個亟待解決的問題。正是在這樣的需求背景下,Apache Sqoop 應運而生,它扮演了數據導入導出工具的重要角色。
一、Sqoop 是什么?—— 數據遷移的瑞士軍刀
Sqoop (SQL-to-Hadoop and Hadoop-to-SQL) 是一個專門設計用來在 Apache Hadoop (及其相關項目如 Hive 和 HBase) 與結構化數據存儲 (如關系型數據庫) 之間傳輸批量數據的命令行工具。
簡單來說,Sqoop 的核心功能是:
- 導入 (Import):將數據從關系型數據庫 (如 MySQL 中的表) 抽取出來,并加載到 Hadoop 的分布式文件系統 HDFS 中,通常存儲為文本文件 (如 CSV, TSV) 或更高效的序列化格式 (如 Avro, Parquet)。數據也可以直接導入到 Hive 表或 HBase 表中。
- 導出 (Export):將存儲在 HDFS (或其他 Hadoop 系統) 中的數據抽取出來,并加載回到關系型數據庫的表中。
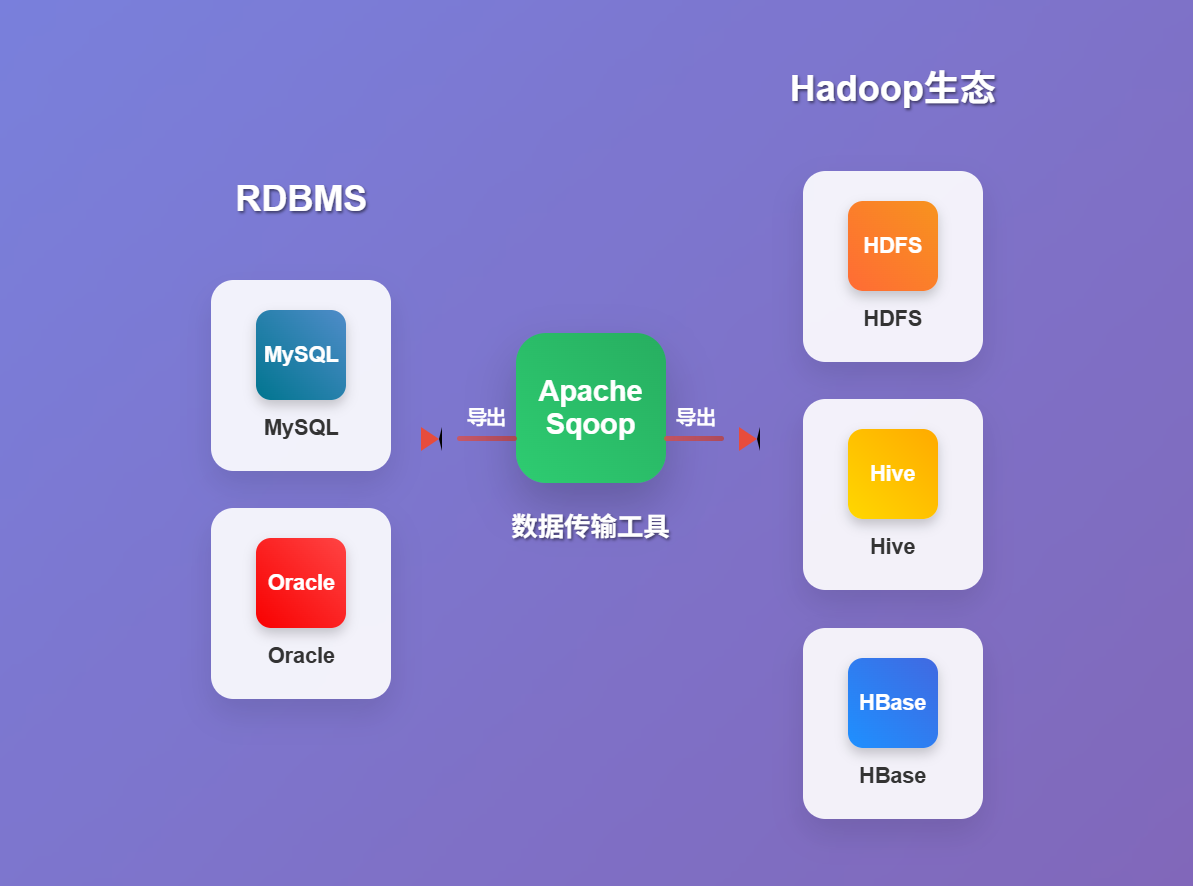
Sqoop 利用 MapReduce 來并行處理數據的導入和導出任務,從而實現高效的數據傳輸,尤其擅長處理 大規模數據集。它支持多種主流的關系型數據庫,并提供了豐富的命令行選項來控制數據遷移的各個方面,如數據過濾、并行度調整、數據格式轉換等。
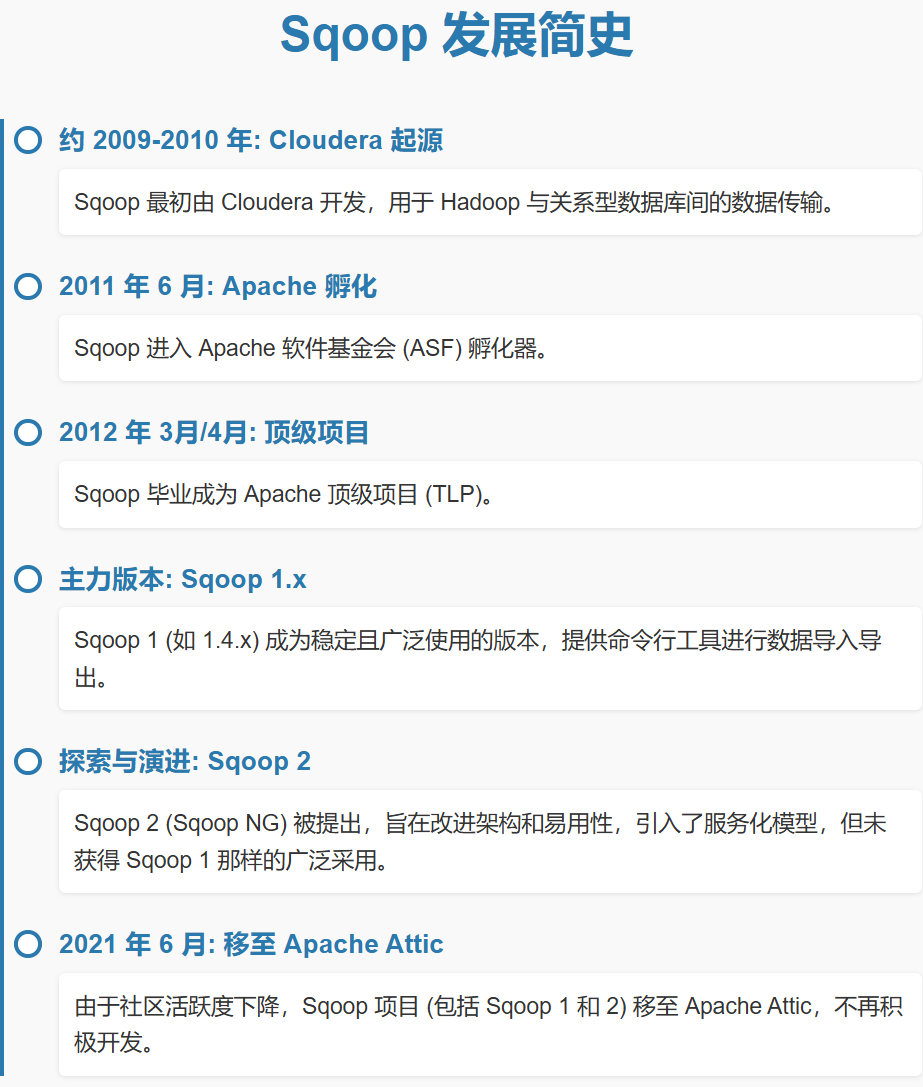
二、Sqoop 的發展簡史
Sqoop 的發展歷程與其在大數據生態中的重要性緊密相關:
-
起源與早期發展 (約 2009 - 2011 年):
- Sqoop 最初是由 Cloudera 公司開發的。隨著 Hadoop 在企業中的應用逐漸增多,將現有關系型數據庫中的歷史數據導入 Hadoop 進行分析的需求日益迫切。
- 早期的數據遷移往往需要編寫自定義的腳本或程序,效率低下且容易出錯。Sqoop 的出現旨在簡化這一過程。
- 2011 年,Sqoop 被貢獻給 Apache 軟件基金會 (ASF),進入孵化器項目。
-
成為 Apache 頂級項目與 Sqoop 1 的成熟 (約 2012 - 至今):
- 2012 年 3 月,Sqoop 成功畢業成為 Apache 頂級項目 (TLP),這標志著其技術成熟度和社區活躍度得到了廣泛認可。
- Sqoop 1 (主要是 1.4.x 系列版本) 成為了最穩定、應用最廣泛的版本。它提供了穩定的導入導出功能,支持眾多數據庫,并與Hadoop 生態中的其他組件 (如 Hive, Oozie) 良好集成。
-
Sqoop 2 的探索與演進 (Sqoop1 的后續版本):
- 為了解決 Sqoop 1 在易用性、安全性、可擴展性等方面的一些局限,社區啟動了 Sqoop 2 (也稱 Sqoop NG - Next Generation) 項目。
- Sqoop 2 的設計目標包括:提供REST API 和 Web UI 以方便管理,更強的安全性 (如基于角色的訪問控制),以及更好的連接器模型以支持更多數據源。
- 然而,Sqoop 2 的發展和推廣相對 Sqoop 1 較為緩慢,Sqoop 1.4.x 仍然是目前許多生產環境中的主力版本。
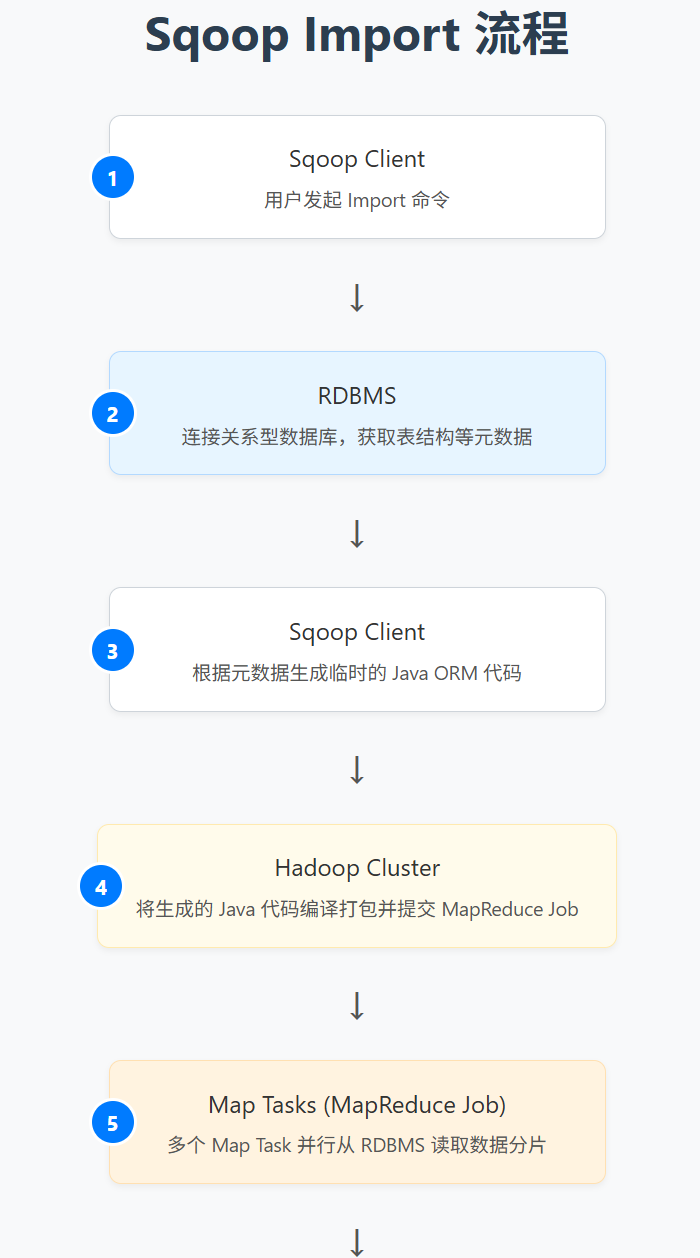
三、Sqoop 的工作原理
Sqoop 的核心工作原理是將數據傳輸任務轉換為一系列的 MapReduce 作業 (或在較新版本中可能利用 Tez/Spark 等引擎,但經典原理基于 MapReduce)。
3.1 導入 (Import) 原理:
-
連接數據庫與元數據獲取:用戶通過命令行指定數據庫連接信息 (JDBC URL, 用戶名, 密碼) 和要導入的表 (或 SQL 查詢)。Sqoop 首先連接到數據庫,獲取表的元數據信息 (如列名、數據類型)。
-
代碼生成 (Code Generation):Sqoop 根據表的元數據自動生成一個特定于該表的 Java 類。這個類知道如何從數據庫讀取記錄并將其序列化 (或反序列化)。
-
MapReduce 作業提交:Sqoop 將導入任務作為一個 MapReduce 作業提交到 Hadoop 集群。
- 分片 (Splitting):Sqoop 嘗試將要導入的表數據進行邏輯分片 (splitting)。默認通常基于主鍵或其他數值型列的范圍進行分片。每個分片會分配給一個 Map Task 處理。分片的目的是實現并行導入。
- Map Tasks 執行:每個 Map Task 使用生成的 Java 類和 JDBC 連接到數據庫,讀取其負責分片的數據。然后,Map Task 將讀取到的數據 寫入到 HDFS 上的目標位置,可以指定輸出文件的格式 (如文本、Avro、Parquet)。
- Reduce Tasks (通常不需要):對于大多數導入操作,不需要 Reduce 階段,因為 Map 任務可以直接將數據寫入 HDFS。

3.2 導出 (Export) 原理:
-
連接數據庫與元數據獲取:用戶指定 HDFS 上的數據源路徑、目標數據庫連接信息和目標表名。Sqoop 連接數據庫獲取目標表的元數據。
-
代碼生成:與導入類似,Sqoop 生成一個Java 類,該類知道如何將 HDFS 中的數據解析并轉換為適合插入到目標數據庫表的格式。
-
MapReduce 作業提交:
- Map Tasks 執行:每個 Map Task 讀取 HDFS 上分配給它的部分數據文件。它使用生成的 Java 類解析數據,并將每條記錄轉換為數據庫記錄。
- 寫入數據庫:Map Task 通過 JDBC 將轉換后的記錄 批量插入到目標數據庫表中。為了提高性能和保證事務性 (一定程度上),Sqoop 通常會分批次執行
INSERT語句,并可能使用臨時表或分階段提交的策略。 - Reduce Tasks (通常不需要):導出操作通常也主要由 Map 任務完成。
四、Sqoop 的價值與意義
Sqoop 的出現和廣泛應用,對于大數據生態的發展具有重要的價值和意義:
-
打通數據孤島:Sqoop 最直接的價值在于打破了傳統關系型數據庫與Hadoop 大數據平臺之間的數據壁壘。它使得企業能夠方便地將存量業務數據遷移到 Hadoop 中進行更深入、更復雜的分析,挖掘數據價值。
-
降低數據遷移門檻:在 Sqoop 出現之前,進行大規模數據遷移往往需要編寫復雜的ETL腳本或Java程序。Sqoop 通過簡單的命令行接口和自動代碼生成,極大地簡化了這一過程,降低了技術門檻,使得數據工程師和分析師可以更專注于數據本身。
-
提升數據遷移效率:Sqoop 利用 MapReduce 的并行處理能力,可以同時啟動多個任務并發地進行數據讀寫,顯著提高了大規模數據遷移的效率,縮短了數據準備時間。
-
支持多種數據格式與目標:Sqoop 不僅支持將數據導入為簡單的文本文件,還支持導入為更高效、更適合分析的列式存儲格式 (如 Avro, Parquet)。同時,它可以直接將數據導入 Hive 表 (自動創建表結構) 或 HBase,方便后續的數據分析和應用。
-
促進數據倉庫和數據湖建設:Sqoop 是構建企業級數據倉庫和數據湖的關鍵組件之一。它負責從各種業務系統 (通常是RDBMS) 定期抽取數據到中央數據平臺,為后續的數據整合、清洗、分析和挖掘提供原始數據源。
-
與調度系統集成,實現自動化:Sqoop 可以方便地與 Oozie, Azkaban, Airflow 等工作流調度系統集成,實現數據遷移任務的自動化調度和監控,構建穩定可靠的數據管道。
結語:不可或缺的數據搬運工
盡管隨著技術發展,新的數據集成工具 (如 Spark SQL 的 JDBC 數據源、Flink CDC 等) 不斷涌現,但 Sqoop 憑借其成熟穩定、簡單易用、專注于批量數據遷移的特性,在許多大數據場景下,尤其是在將傳統關系型數據庫數據接入 Hadoop 生態的初始加載和周期性批量同步方面,仍然扮演著 不可或缺的角色。它是連接結構化數據世界與大數據分析平臺的重要橋梁和勤懇的數據搬運工。



:從容器到底層奧秘-全面解析String類高效技巧(上篇))




![[HNCTF 2022 Week1]silly_zip](http://pic.xiahunao.cn/[HNCTF 2022 Week1]silly_zip)








)

